costs too high Code optimizations are hidden behind computing power Mission critical? Offload to PaaS selectively, e.g. Parse EOL, death by acquisition...
& anomalies Multiple log files from diff services Manual tailing is difficult Get pre configured graphs based on logs All server traffic is logged, access_log
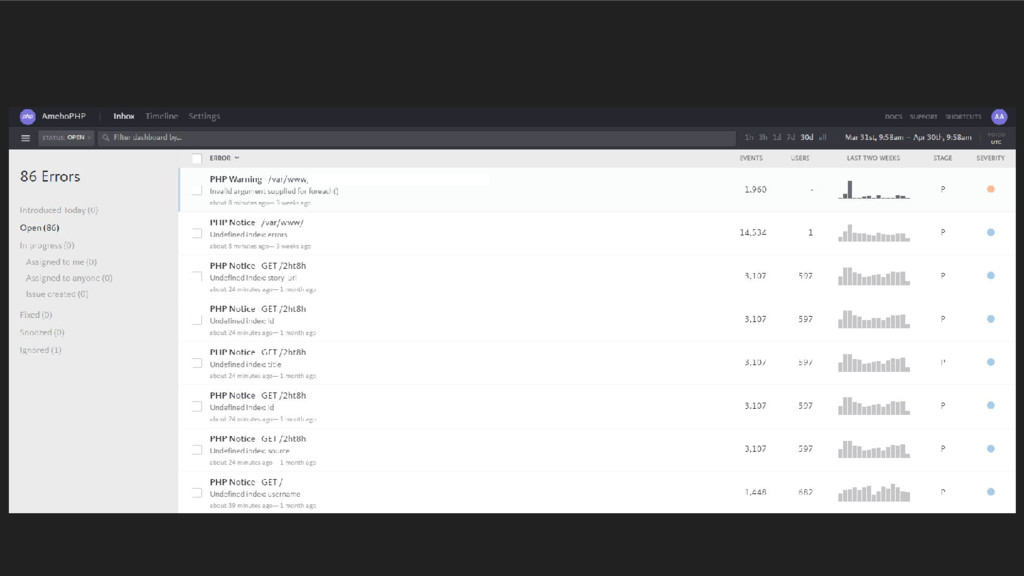
version & device insight Very handy at debug time & post Catch all errors …. mostly Memory leaks & stack traces 3rd party library errors or platform errors
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
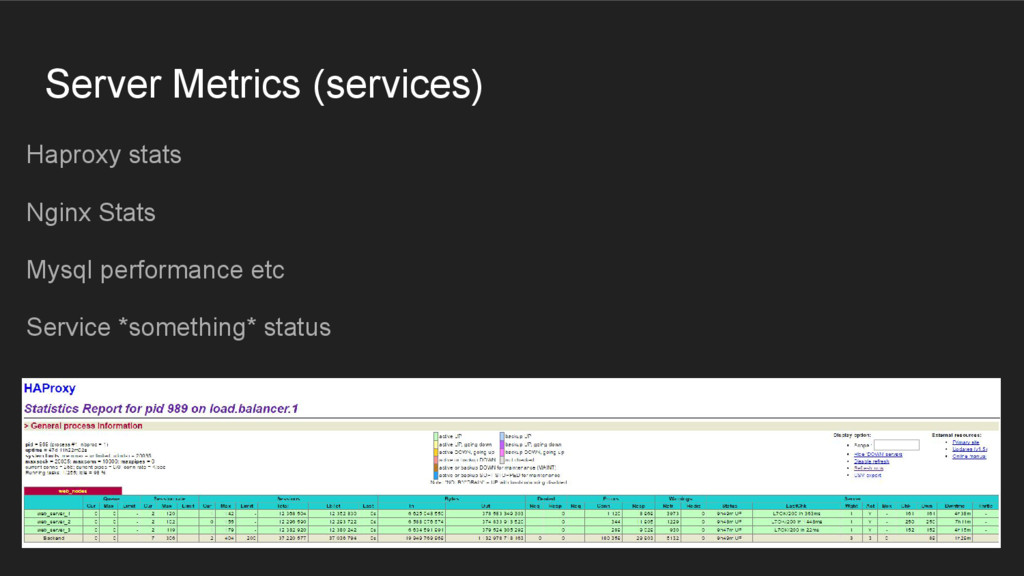{kind=link}
{kind=link}
{kind=link}
{kind=link}
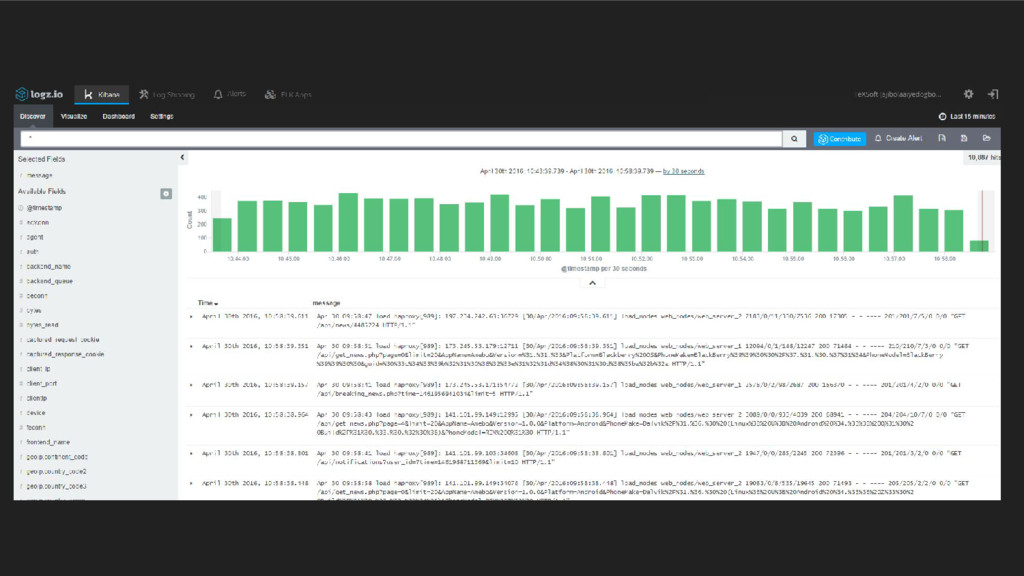{kind=link}
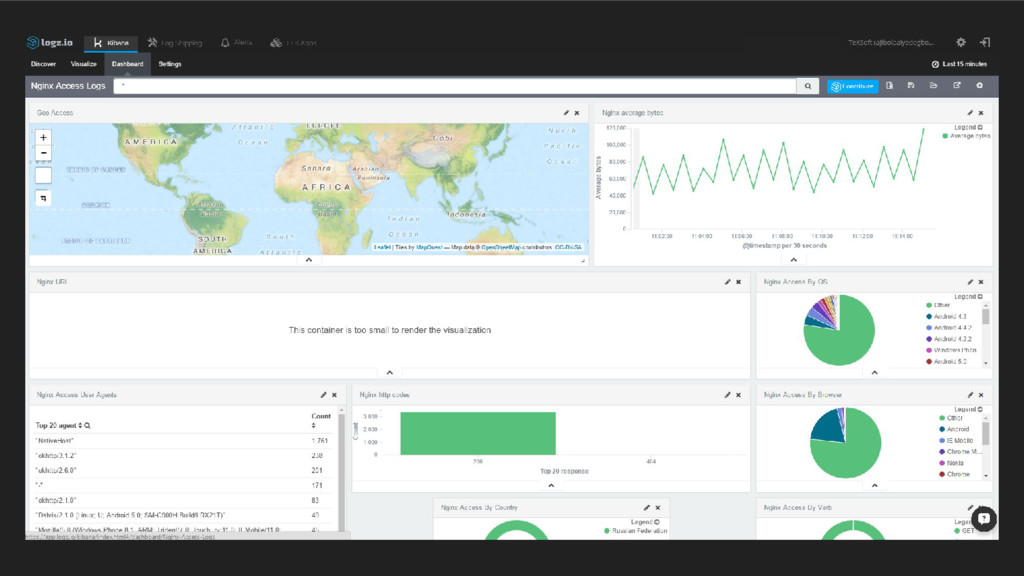{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}