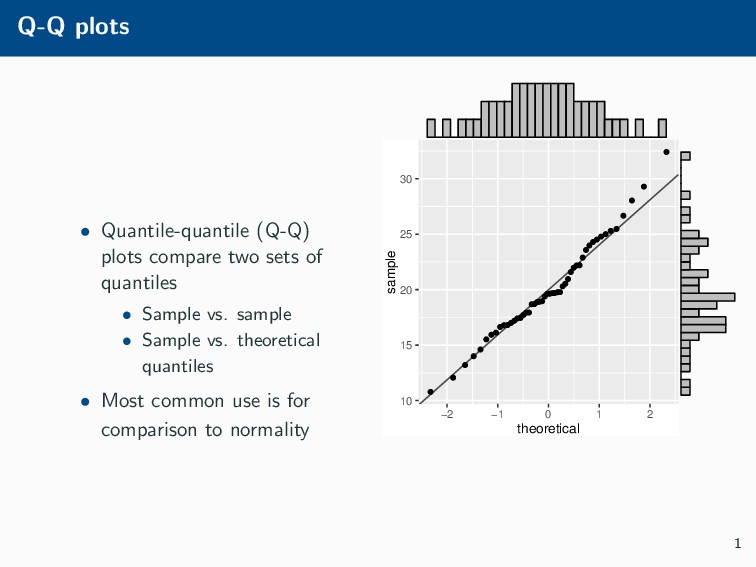
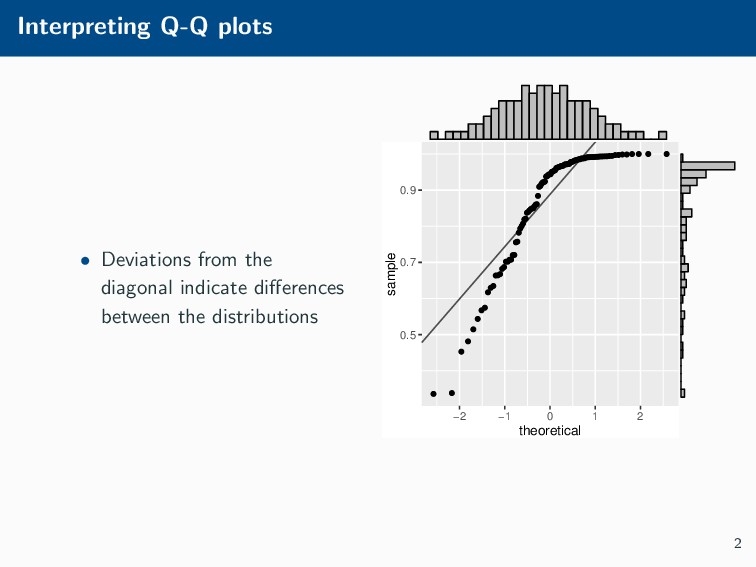
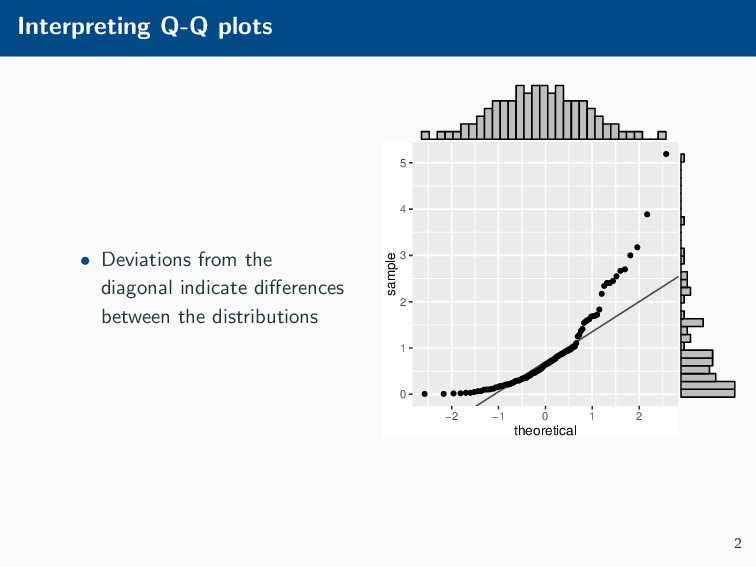
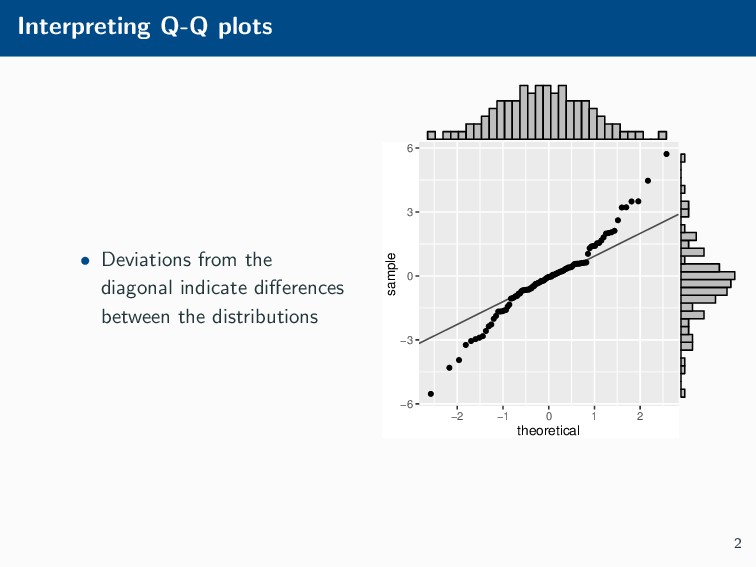
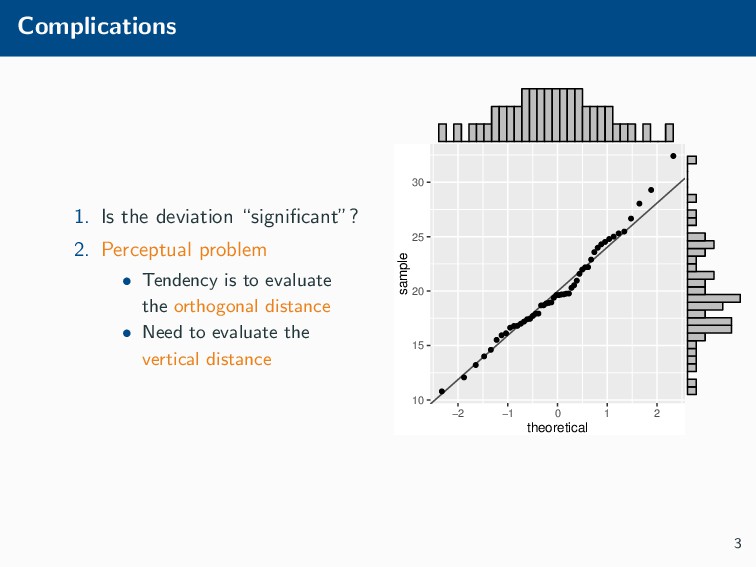
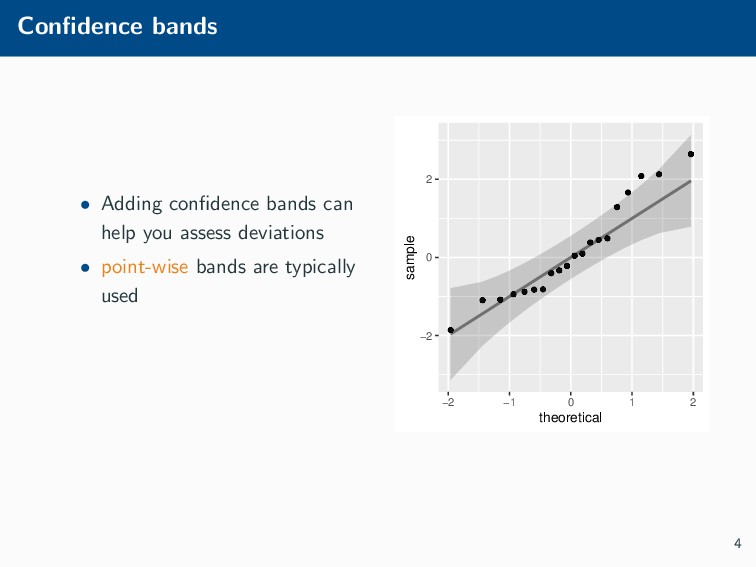
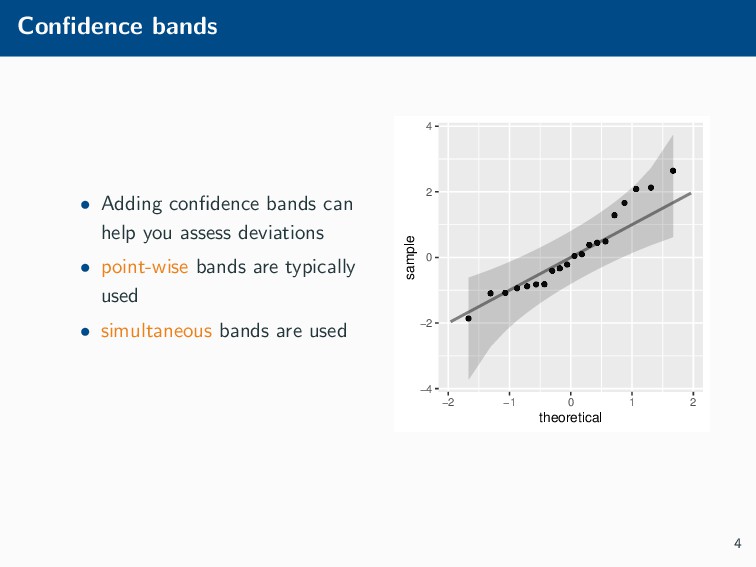
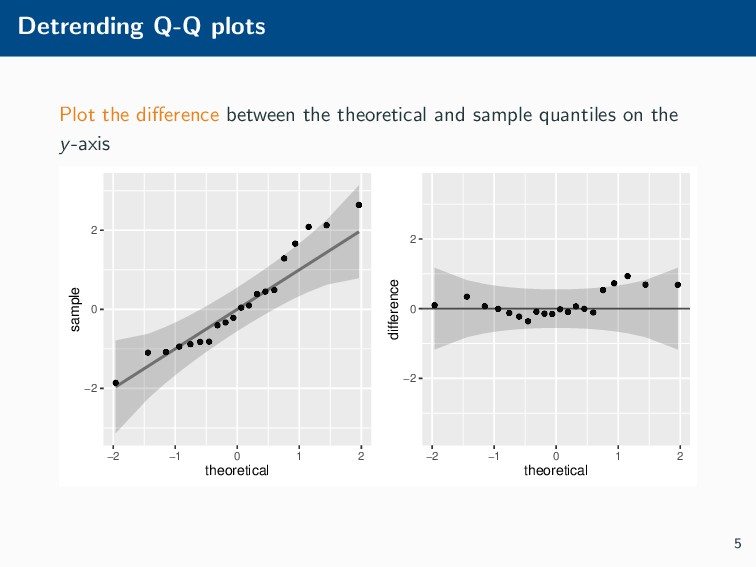
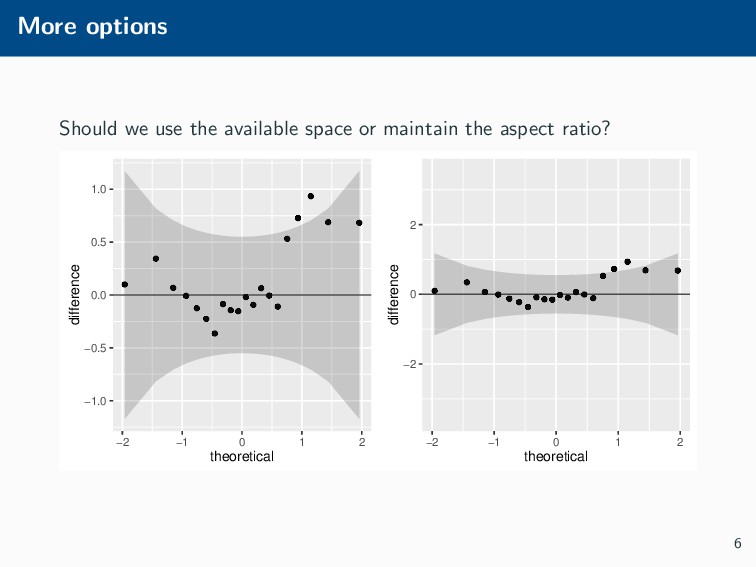
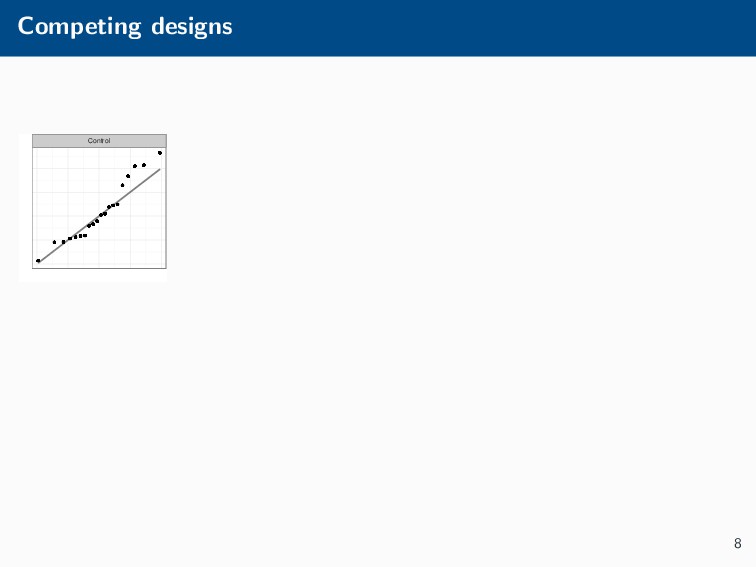
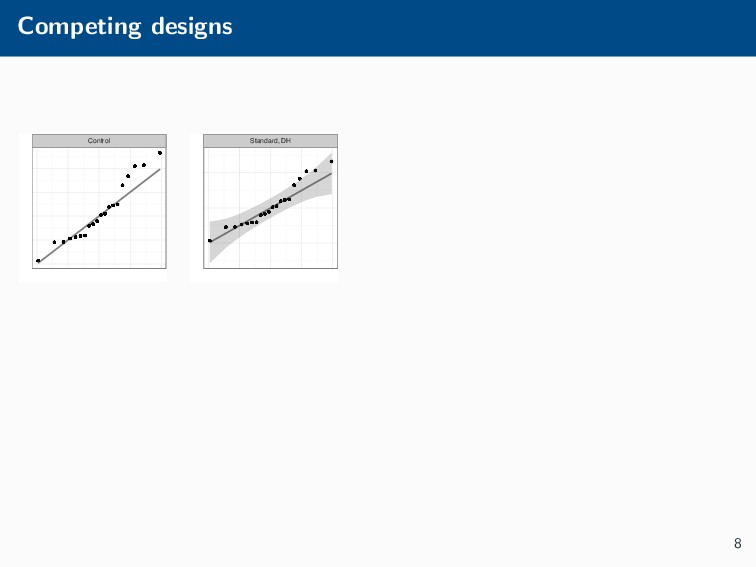
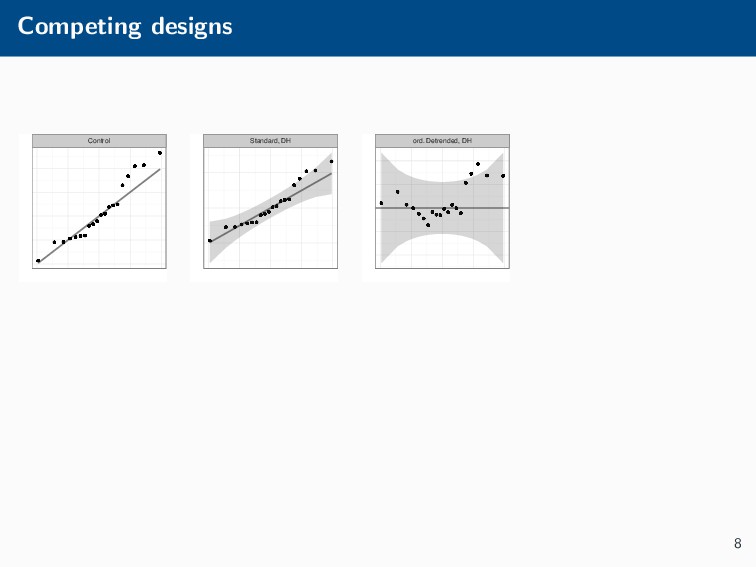
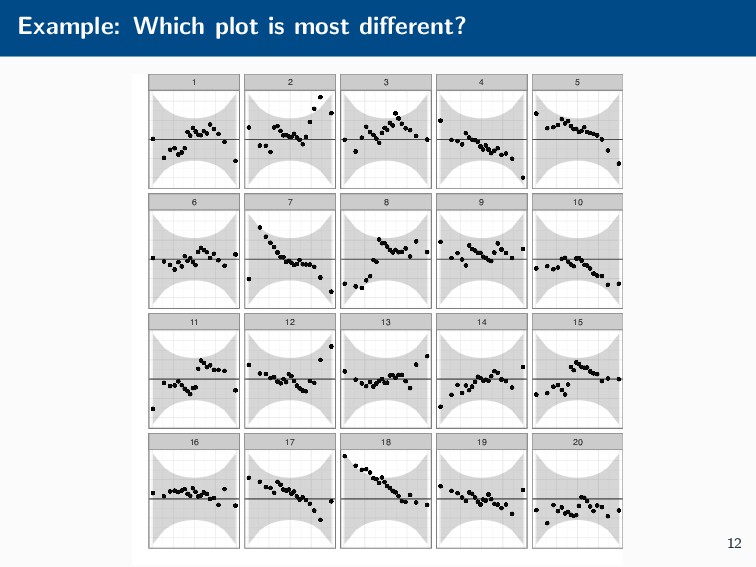
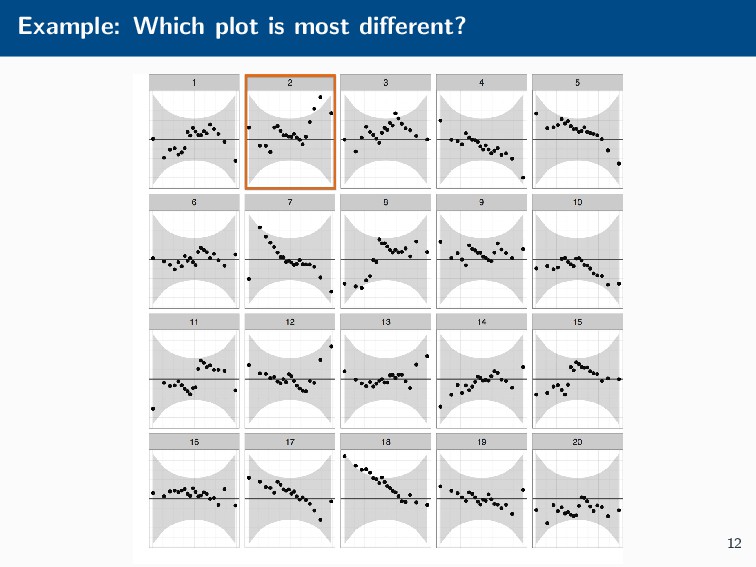
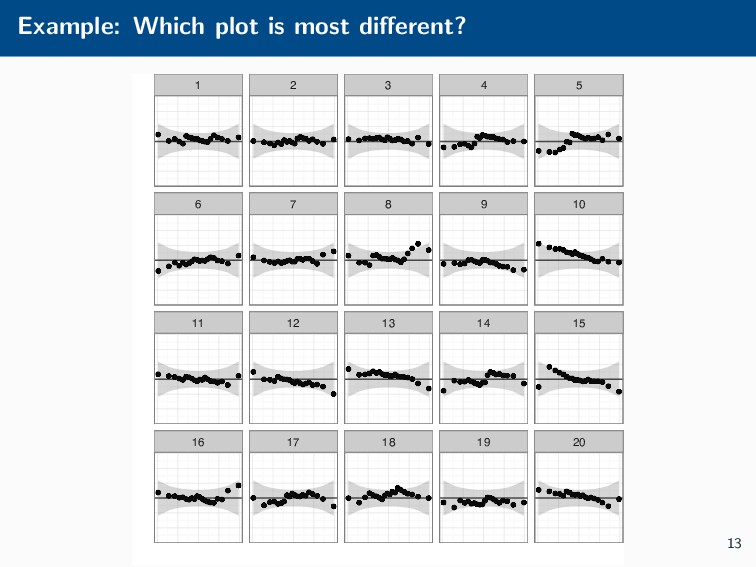
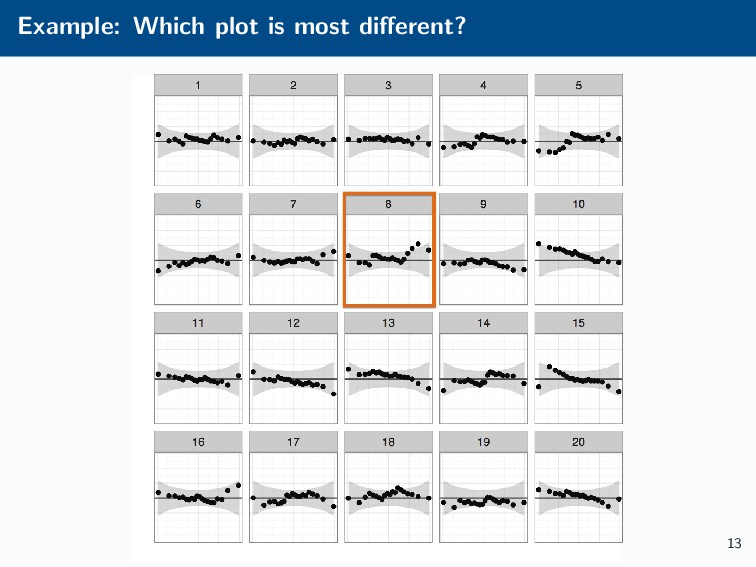
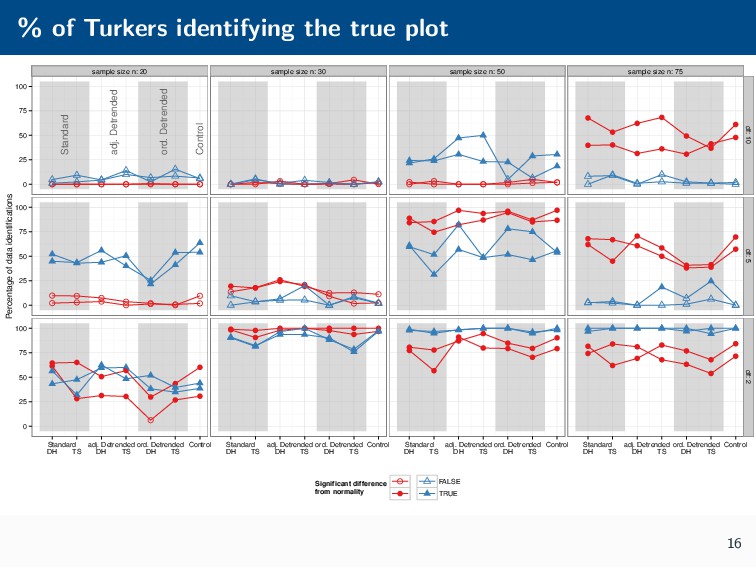
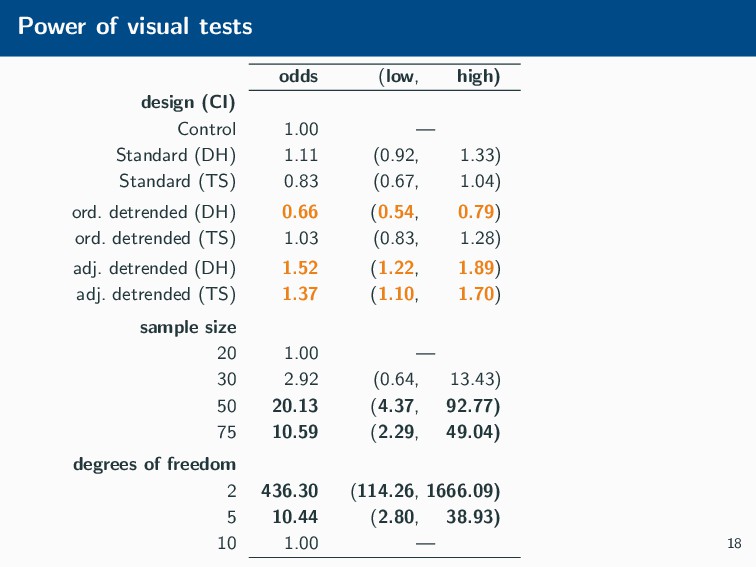
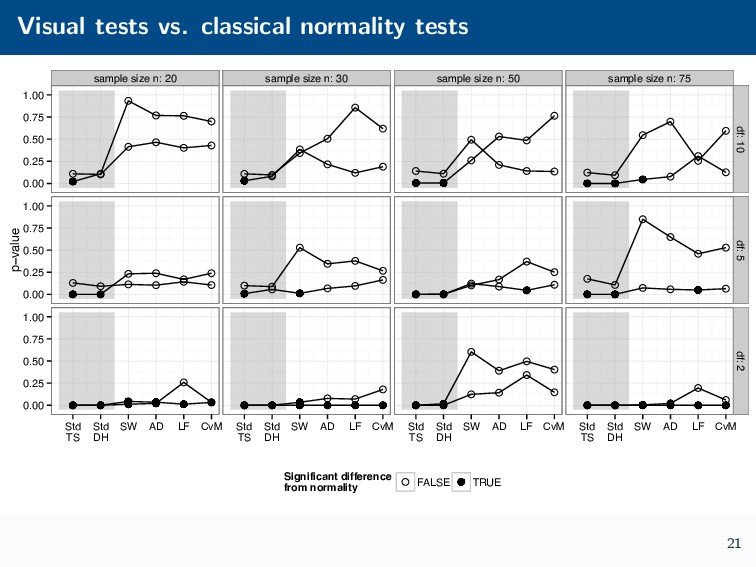
Histograms, scatterplots with smoothers, and other statistical graphics are commonplace in many quantitative courses, and even popular news outlets. While using statistical graphics has become so familiar to many, the process behind the selection and the refinement of statistical graphics is often overlooked. This talk will use the quantile-quantile (Q-Q) plot as an example of how to conduct statistical graphics research. The discussion will include the perceptual problems associated with the standard Q-Q plot often seen in textbooks, possible solutions to this problem, and the experiment used to test these possible solutions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}