Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Finetuning LLMs on consumer GPUs
Search
Aniket Maurya
November 07, 2023
Programming
170
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Finetuning LLMs on consumer GPUs
Aniket Maurya
November 07, 2023
More Decks by Aniket Maurya
See All by Aniket Maurya
Building RAG powered applications - PyData London 2nd April
aniketmaurya
0
64
Contributing to Lightning AI OSS
aniketmaurya
0
82
Other Decks in Programming
See All in Programming
Signal Forms: Beyond the Basics @ngBaguette 2026 in Paris
manfredsteyer
PRO
0
250
Go1.27で導入されるジェネリクスメソッドでできること
mackee
0
130
Oxlintのカスタムルールの現況
syumai
6
1.1k
正しくソフトウェアを作る、前提を疑うための認知の視点 / doubt-premise
minodriven
21
6.7k
Skillsは効率化、Agentsは"自分の拡張"——Builder時代のエージェント編成(CC Night 2026)
wemra
1
140
ふつうのFeature Flag実践入門
irof
7
4k
Oxcを導入して開発体験が向上した話
yug1224
4
320
並列実装の現場、2ヶ月間実務でAIを使い倒したAIもPCも私も限界が近い
ming_ayami
0
130
Agentic UI
manfredsteyer
PRO
0
170
生成AI時代にこそ効くGo | Why Go Works in the Age of Generative AI
mom0tomo
8
3.3k
エージェンティックRAGにAWSで入門しよう!
har1101
8
1.6k
New "Type" system on PicoRuby
pocke
1
960
Featured
See All Featured
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
230
The World Runs on Bad Software
bkeepers
PRO
72
12k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.9k
First, design no harm
axbom
PRO
2
1.2k
Unsuck your backbone
ammeep
672
58k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Are puppies a ranking factor?
jonoalderson
1
3.6k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
440
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
22k
Transcript
November 2023 1. Finetuning LLMs on consumer GPUs 2. LLM
Evaluation framework and datasets 3. Deep Dive into Transformers 4. Effortlessly analyze multifaceted financial documents with LlamaIndex
Finetuning LLMs on custom datasets Aniket Maurya, Developer Advocate at
Lightning AI November 2023 X.com/aniketmaurya linkedin.com/in/aniketmaurya
• Overview of LLMs • Parameter efficient finetuning with instruction
dataset • Training on consumer GPUs Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 3 Agenda
What are LLMs Lightning AI ©2023 Proprietary and Confidential. All
Rights Reserved. 4
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 5
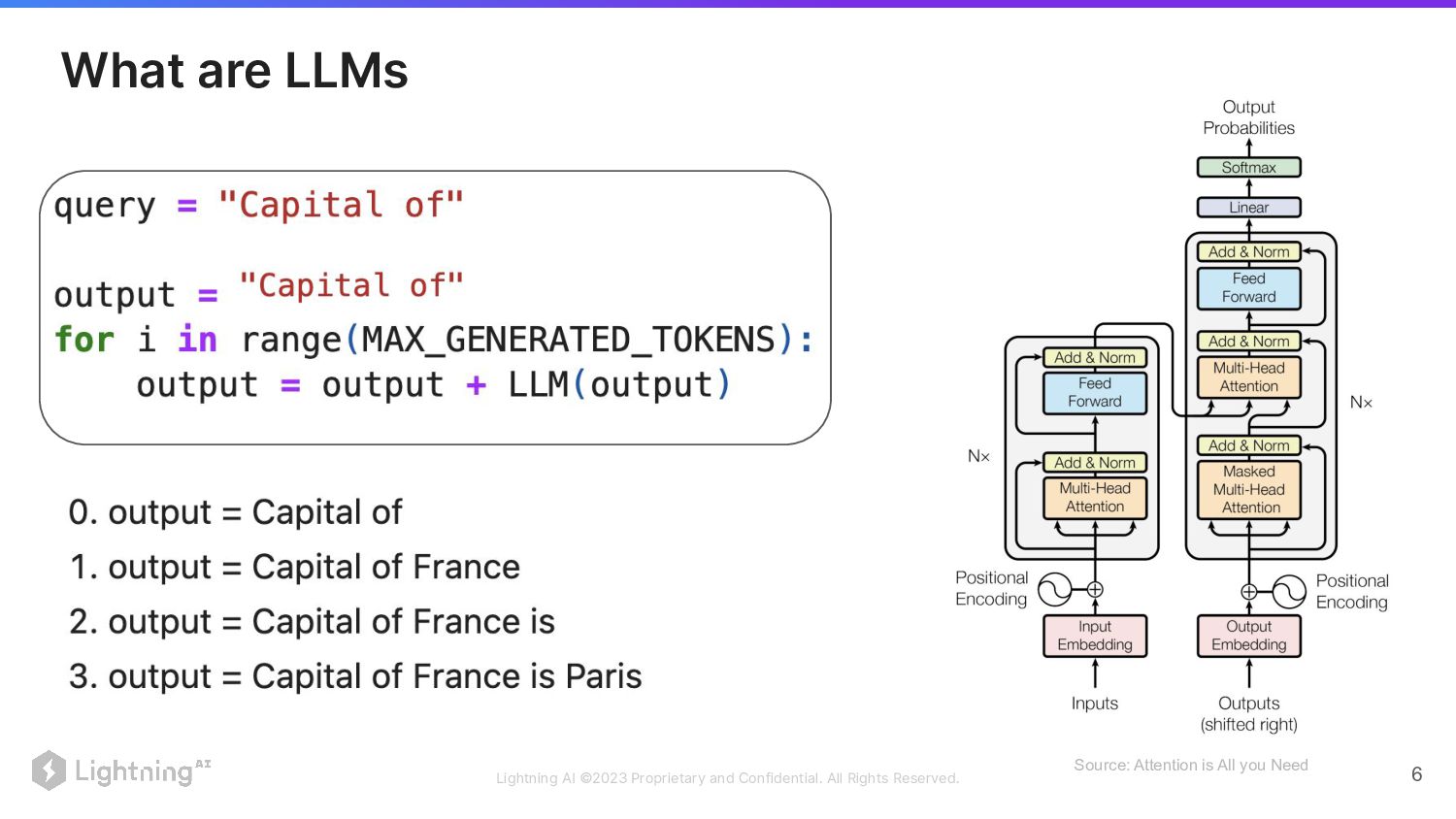
What are LLMs
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 6
What are LLMs Source: Attention is All you Need
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 7
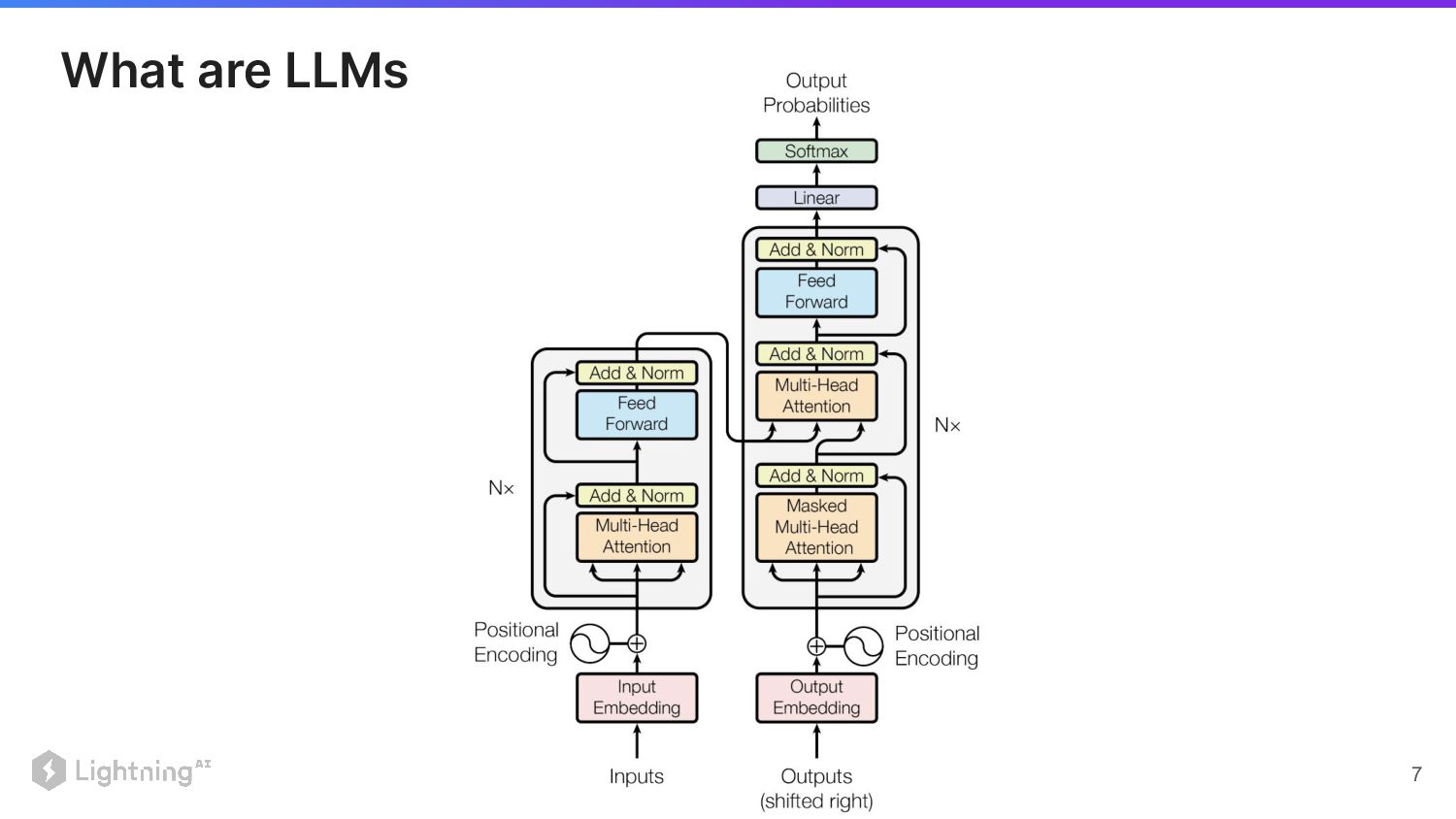
What are LLMs
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 8
What are LLMs
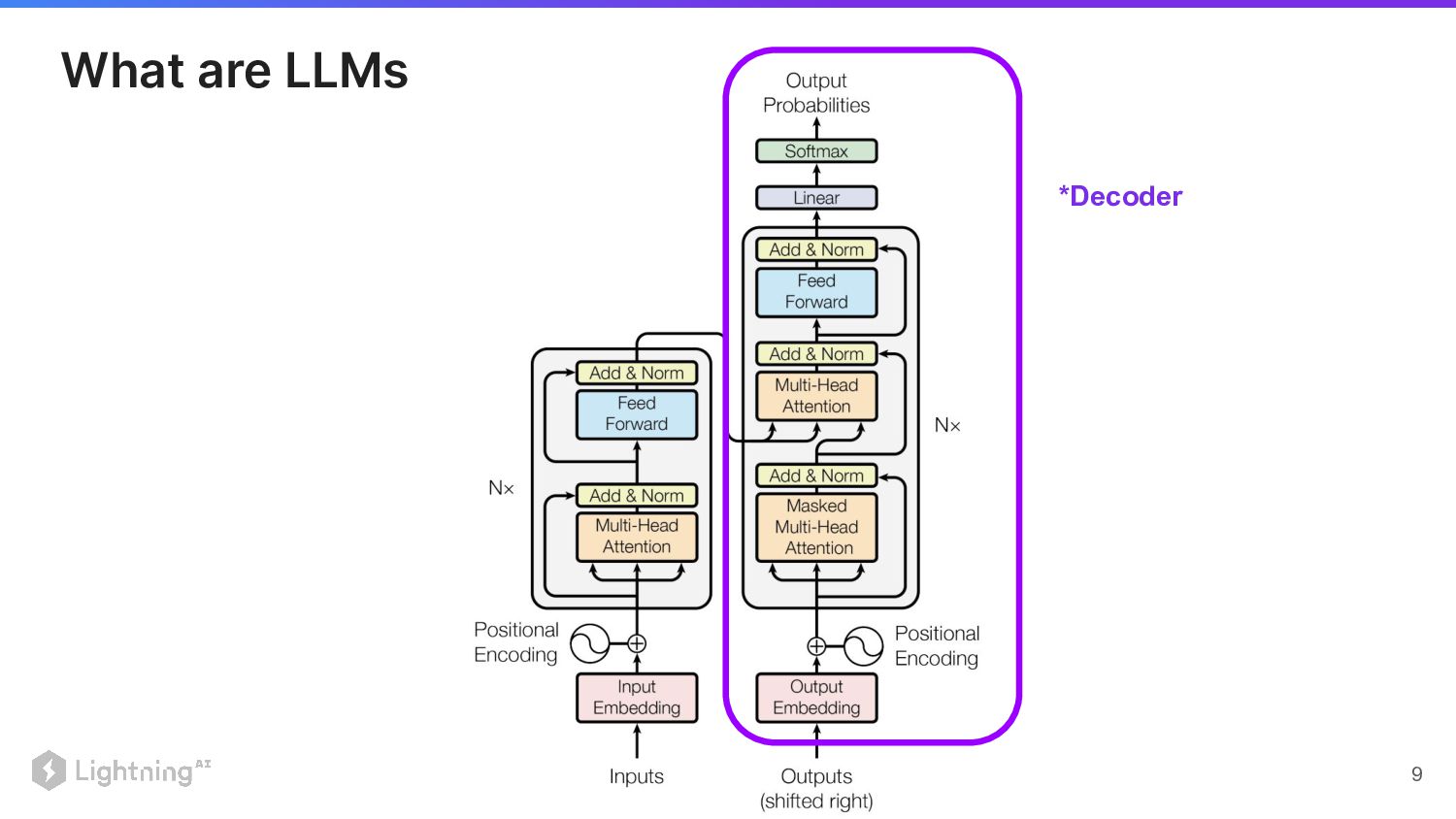
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 9
What are LLMs *Decoder
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 10
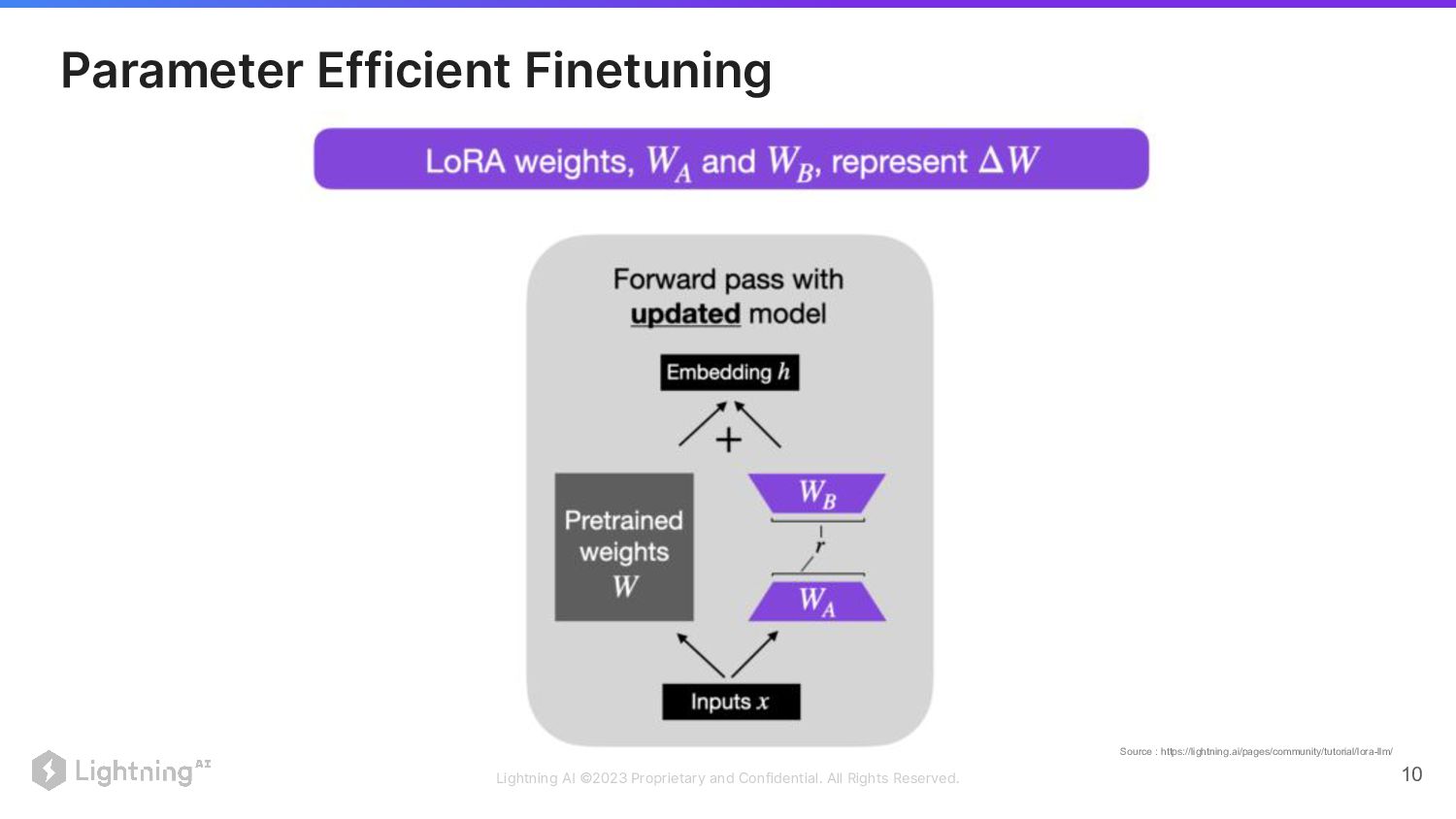
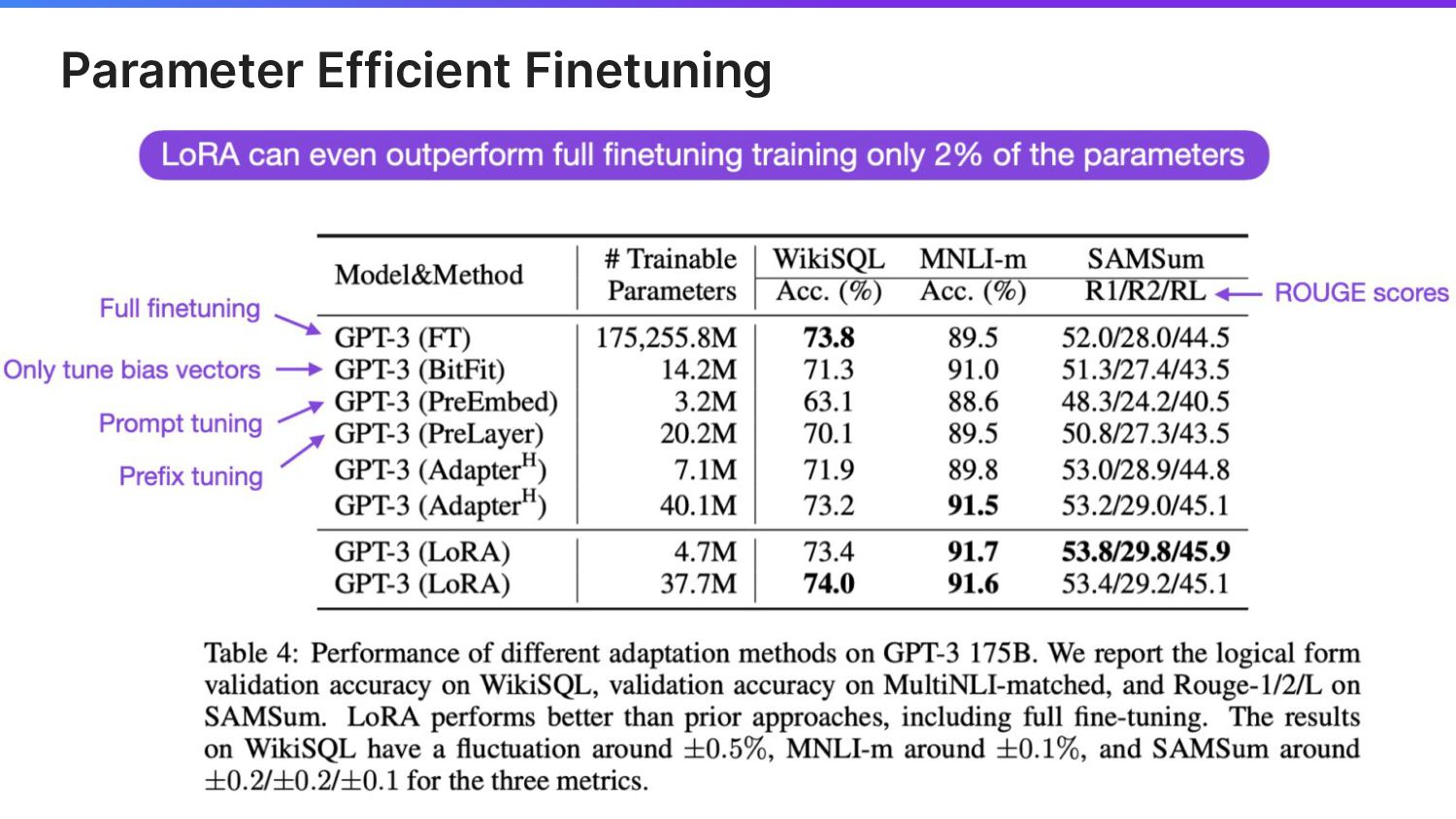
Parameter Efficient Finetuning Source : https://lightning.ai/pages/community/tutorial/lora-llm/
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 11
Parameter Efficient Finetuning
• Remove untruthfulness and toxicity • Customize the output and
tone of language • Privacy and control Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 12 Why Finetune LLMs
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 13
Finetuning LLMs on instruction dataset
• Setup model • Prepare data • Finetune the model
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 14 Finetuning LLMs
• Setup model • Prepare data • Finetune the model
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 15 Finetuning LLMs
• Setup model • Prepare data • Finetune the model
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 16 Finetuning LLMs
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 17
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 18
• 4-bit quantized finetuning and inference • Minimal code, easy
to debug and hack • TPU support • Flash-Attention 2 Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 19 Lit-GPT
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 20
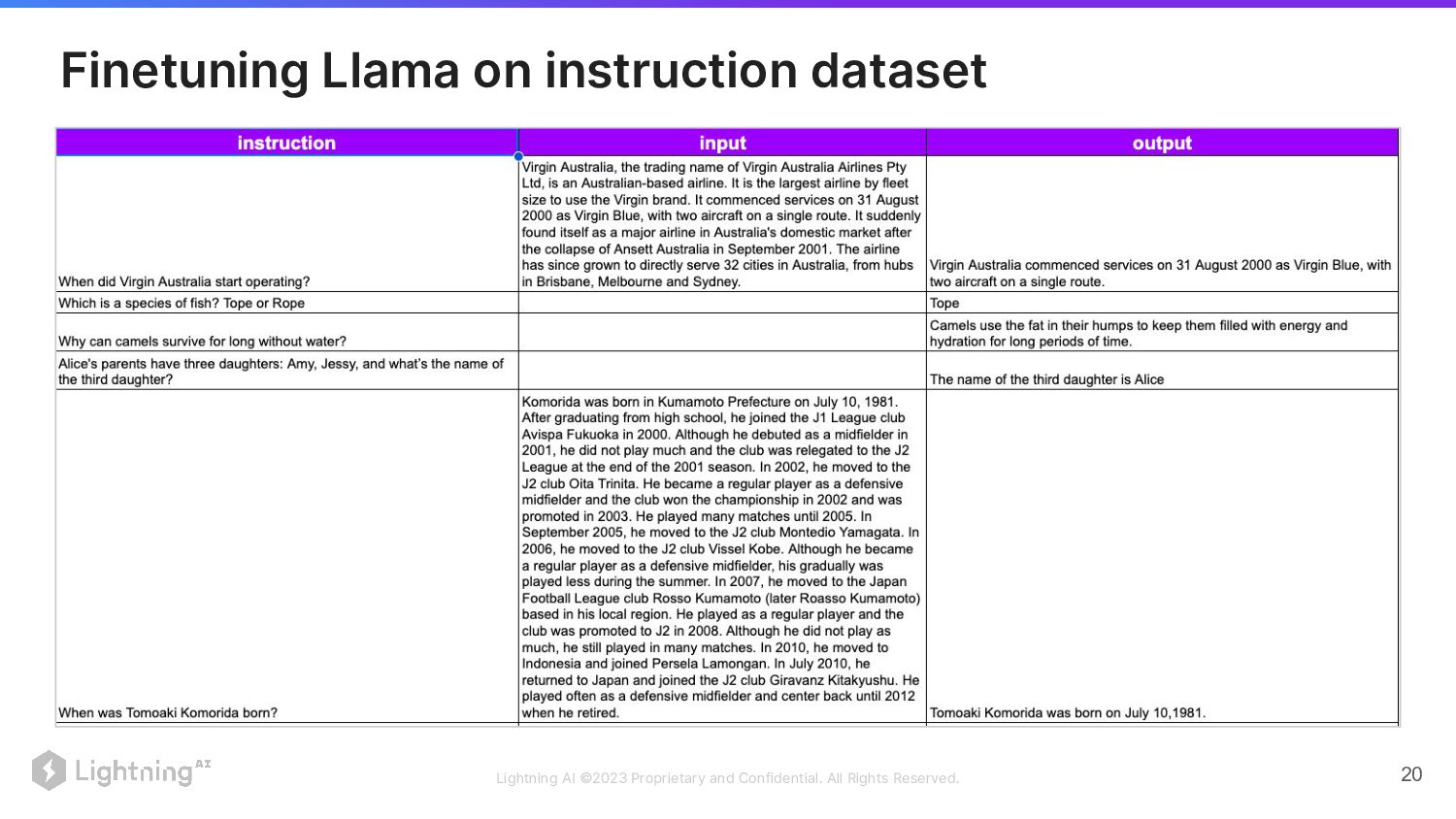
Finetuning Llama on instruction dataset
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 21
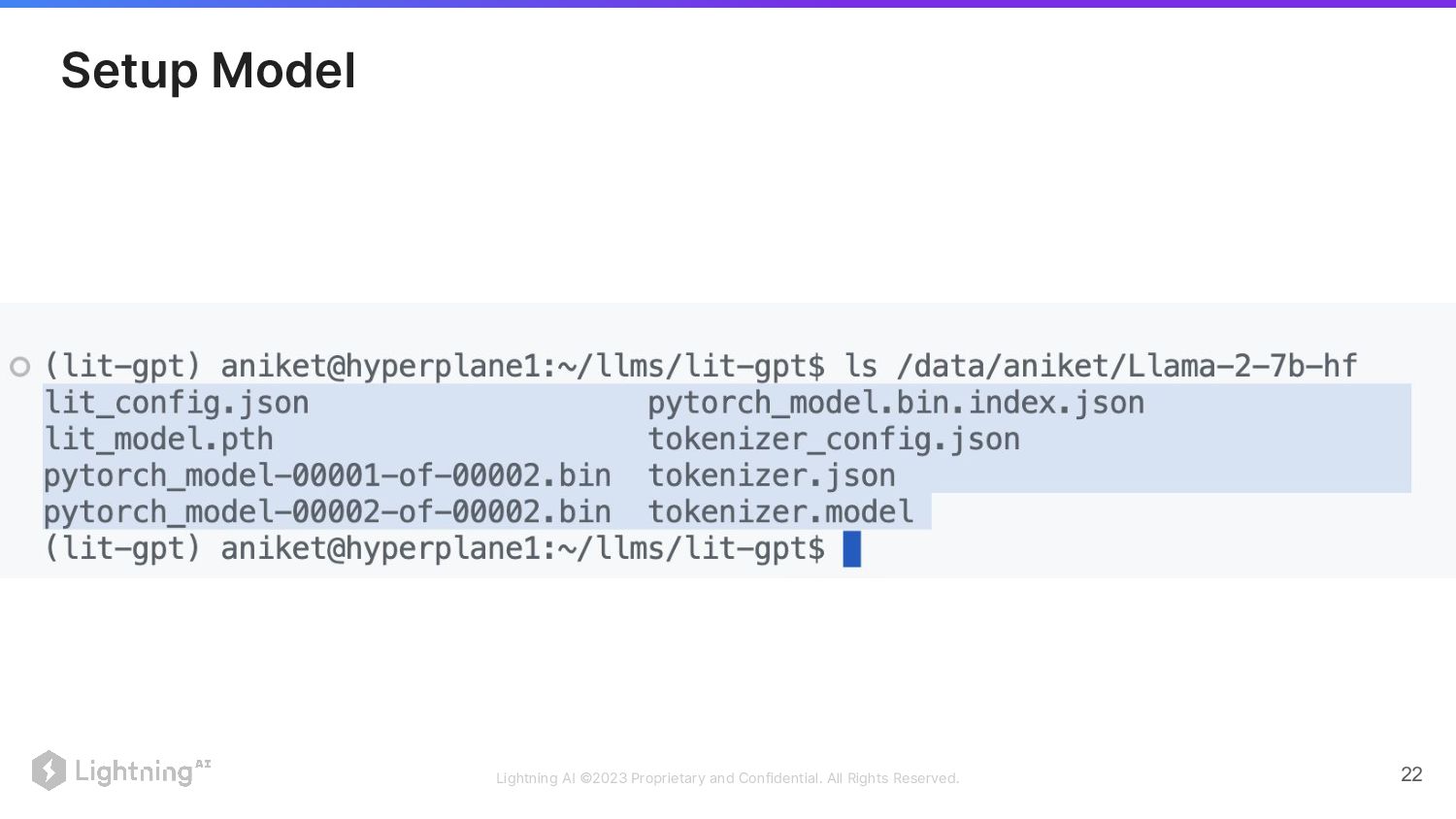
Setup Model
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 22
Setup Model
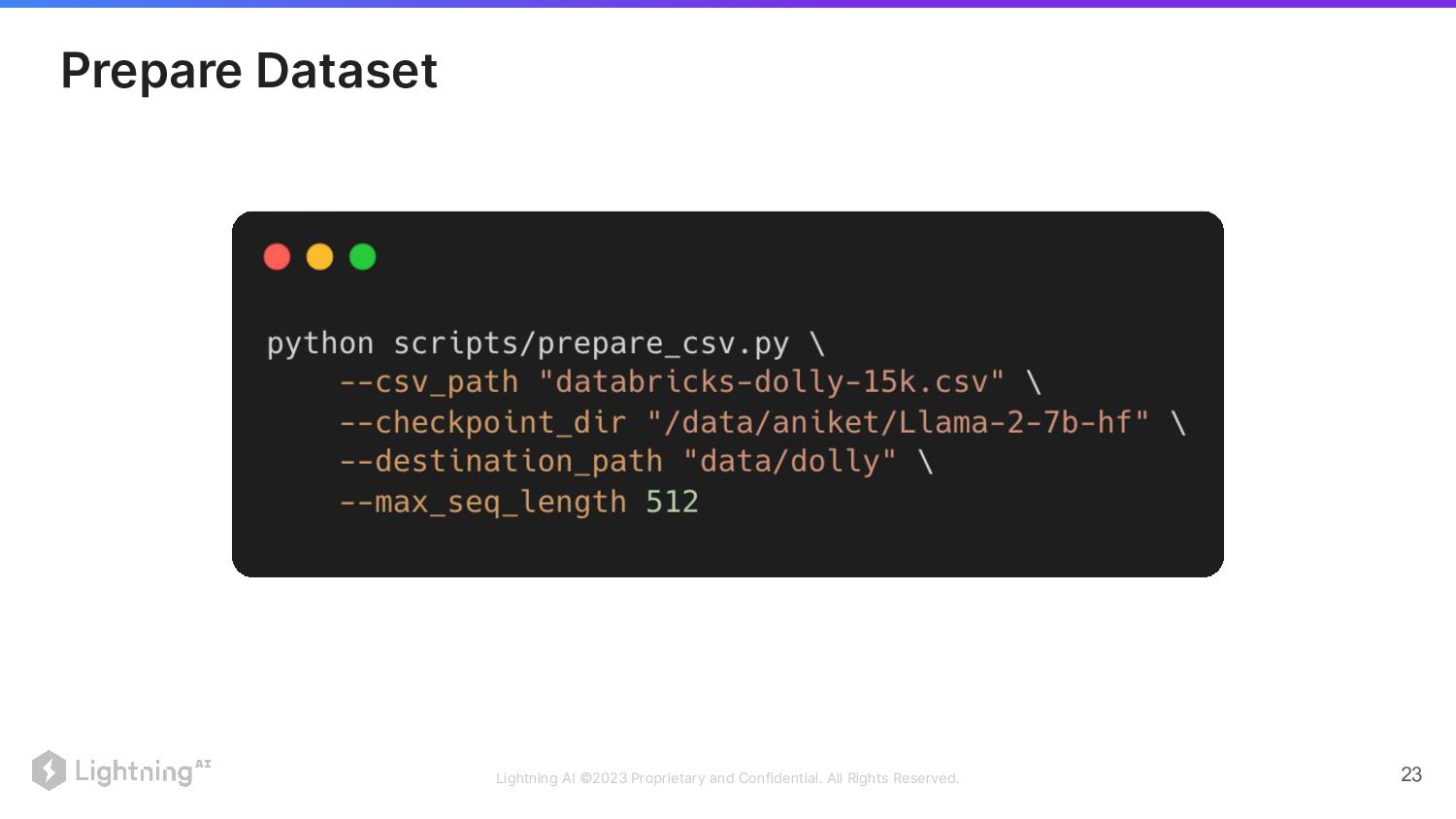
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 23
Prepare Dataset
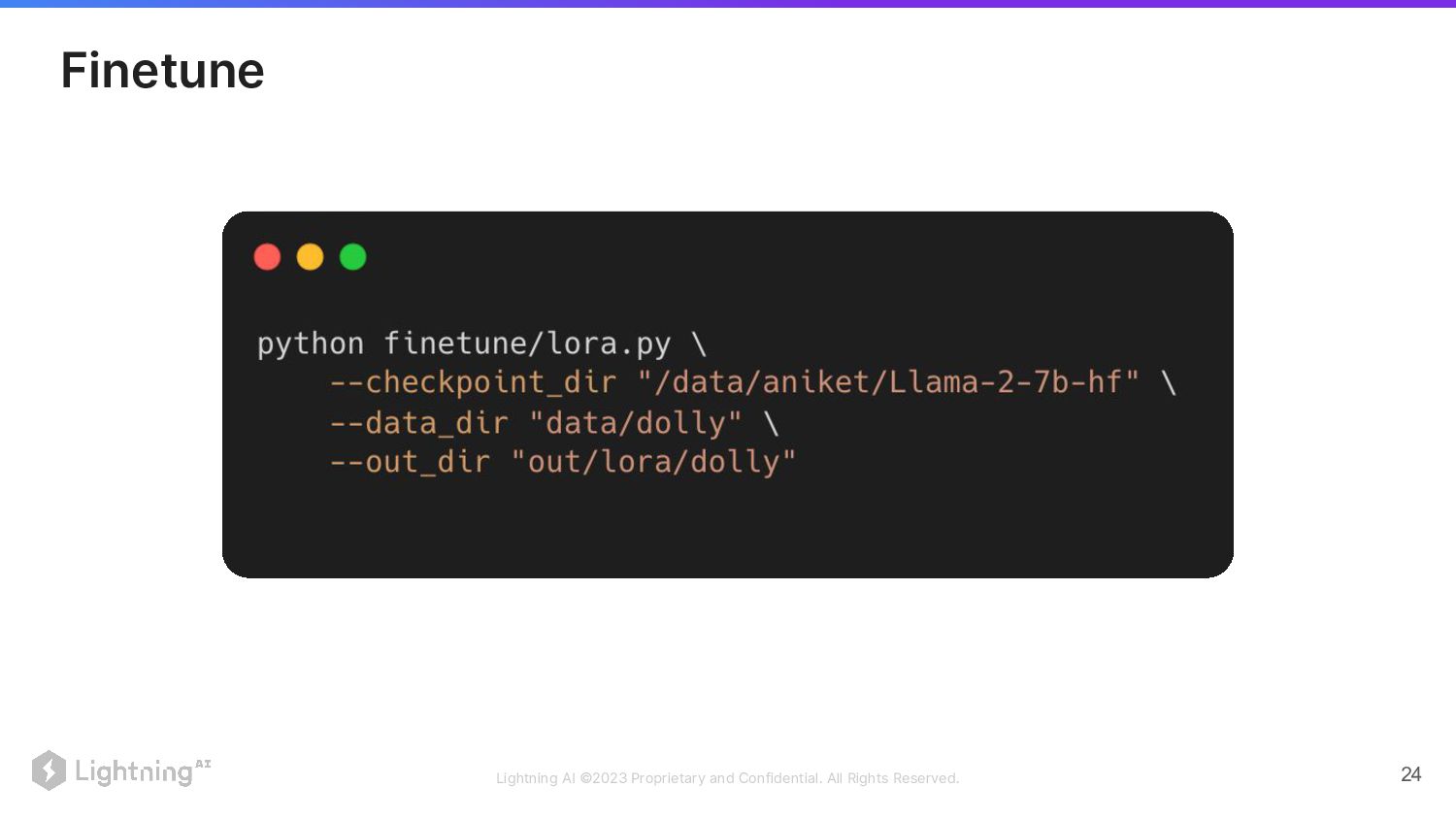
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 24
Finetune
CUDA Out Of Memory Lightning AI ©2023 Proprietary and Confidential.
All Rights Reserved. 25
• Llama 7B, fp32: ~28GB • Llama 7B, fp16: ~14GB
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 26 Memory Required to load Llama
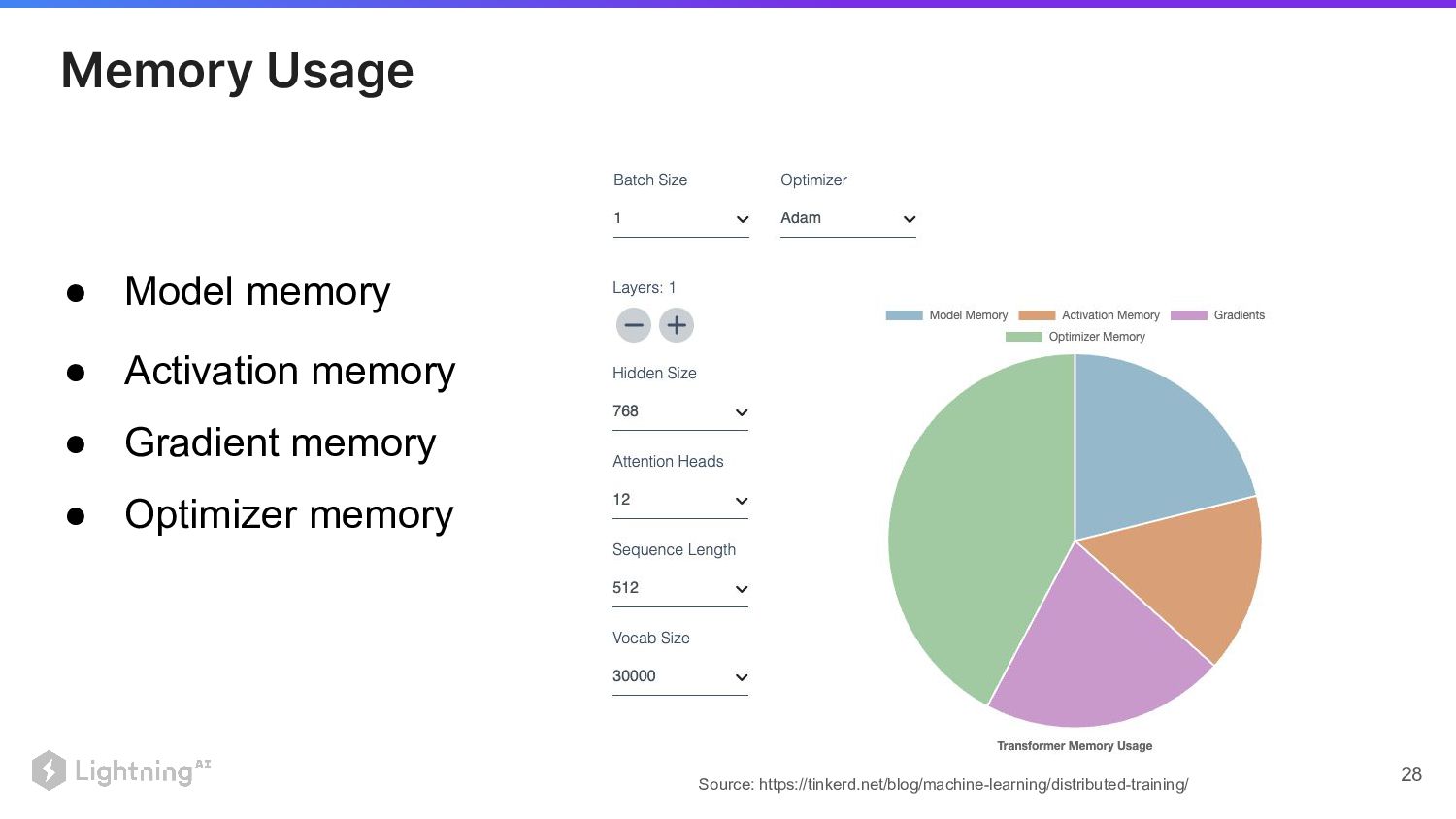
• Activation memory • Gradient memory • Optimizer memory •
Model memory Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 27 Memory Usage
• Activation memory • Gradient memory • Optimizer memory •
Model memory Source: https://tinkerd.net/blog/machine-learning/distributed-training/ 28 Memory Usage
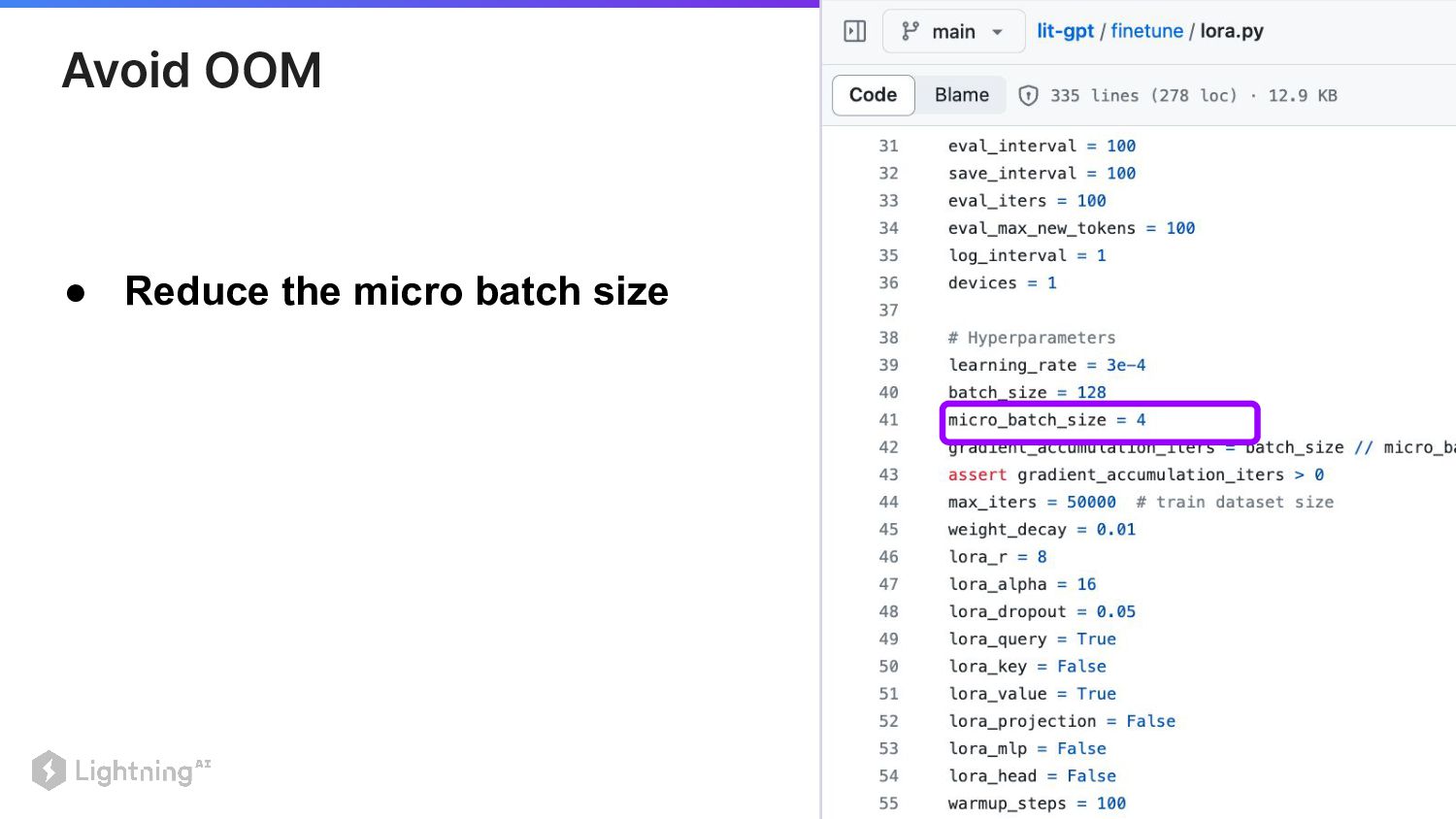
29 • Reduce the micro batch size Avoid OOM
30 • Reduce the model's context length • Reduce the
micro batch size Avoid OOM
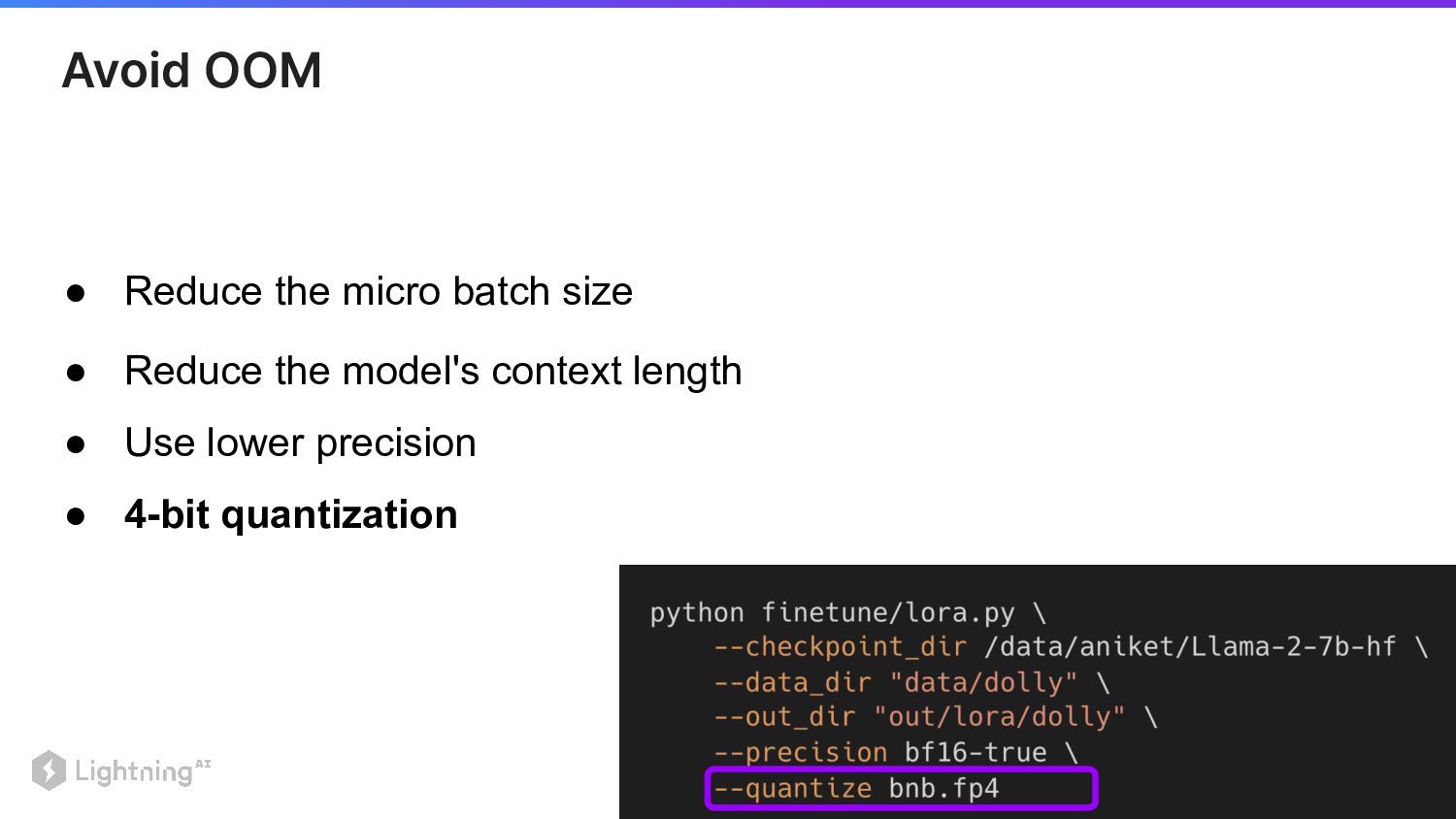
31 • Reduce the model's context length • Use lower
precision • Reduce the micro batch size Avoid OOM
• 4-bit quantization 32 • Reduce the model's context length
• Use lower precision • Reduce the micro batch size Avoid OOM
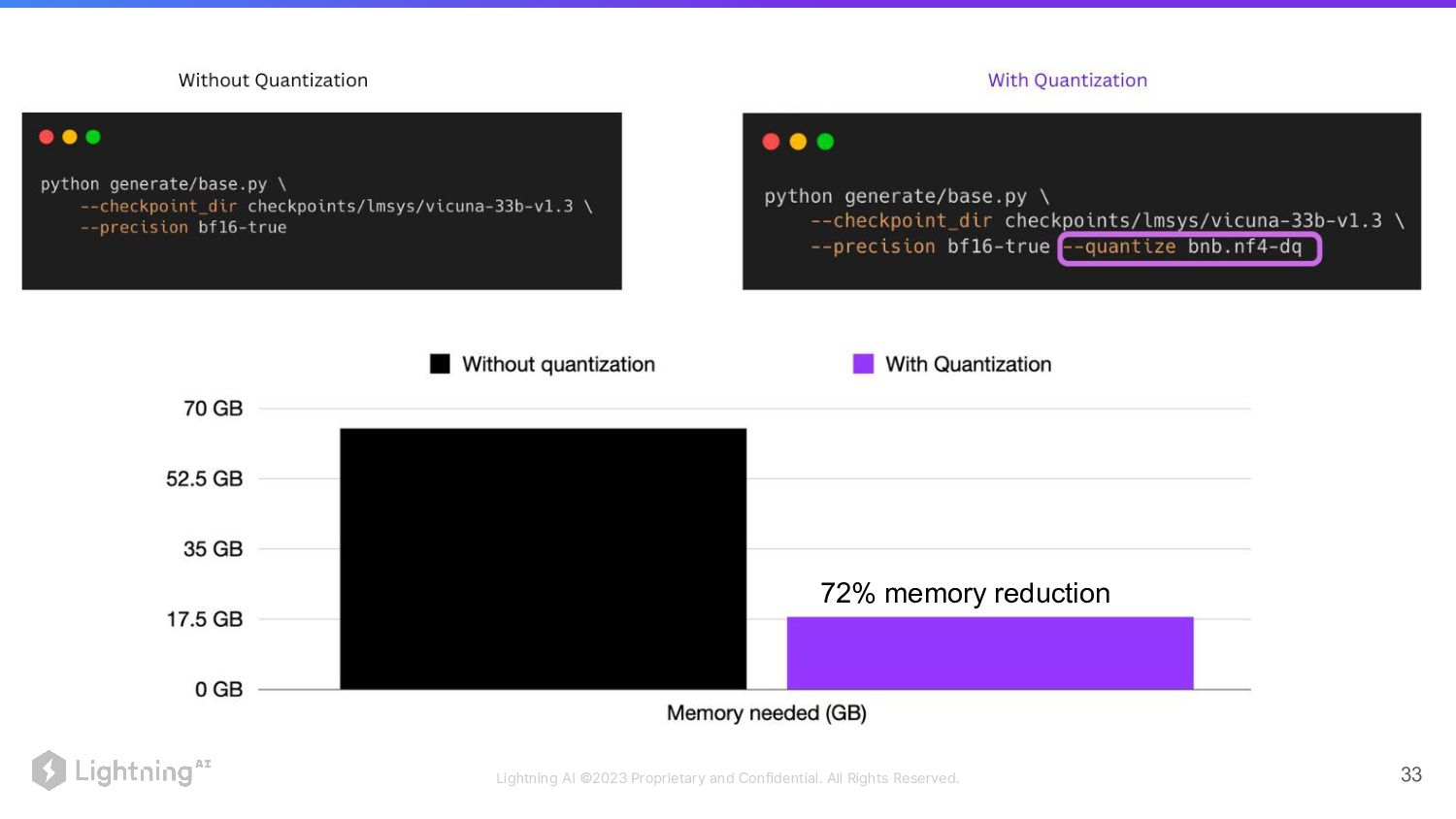
72% memory reduction Lightning AI ©2023 Proprietary and Confidential. All
Rights Reserved. 33
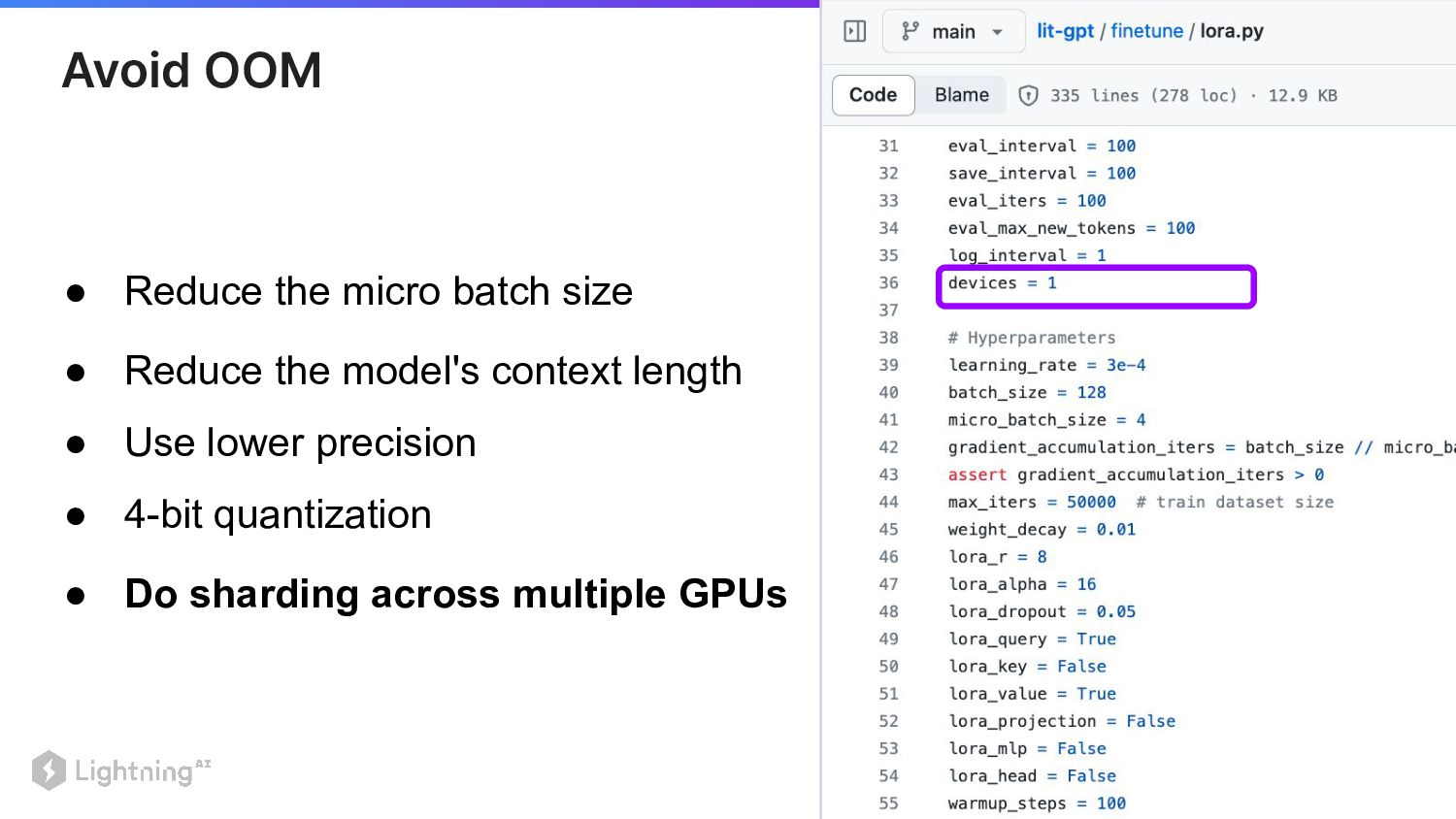
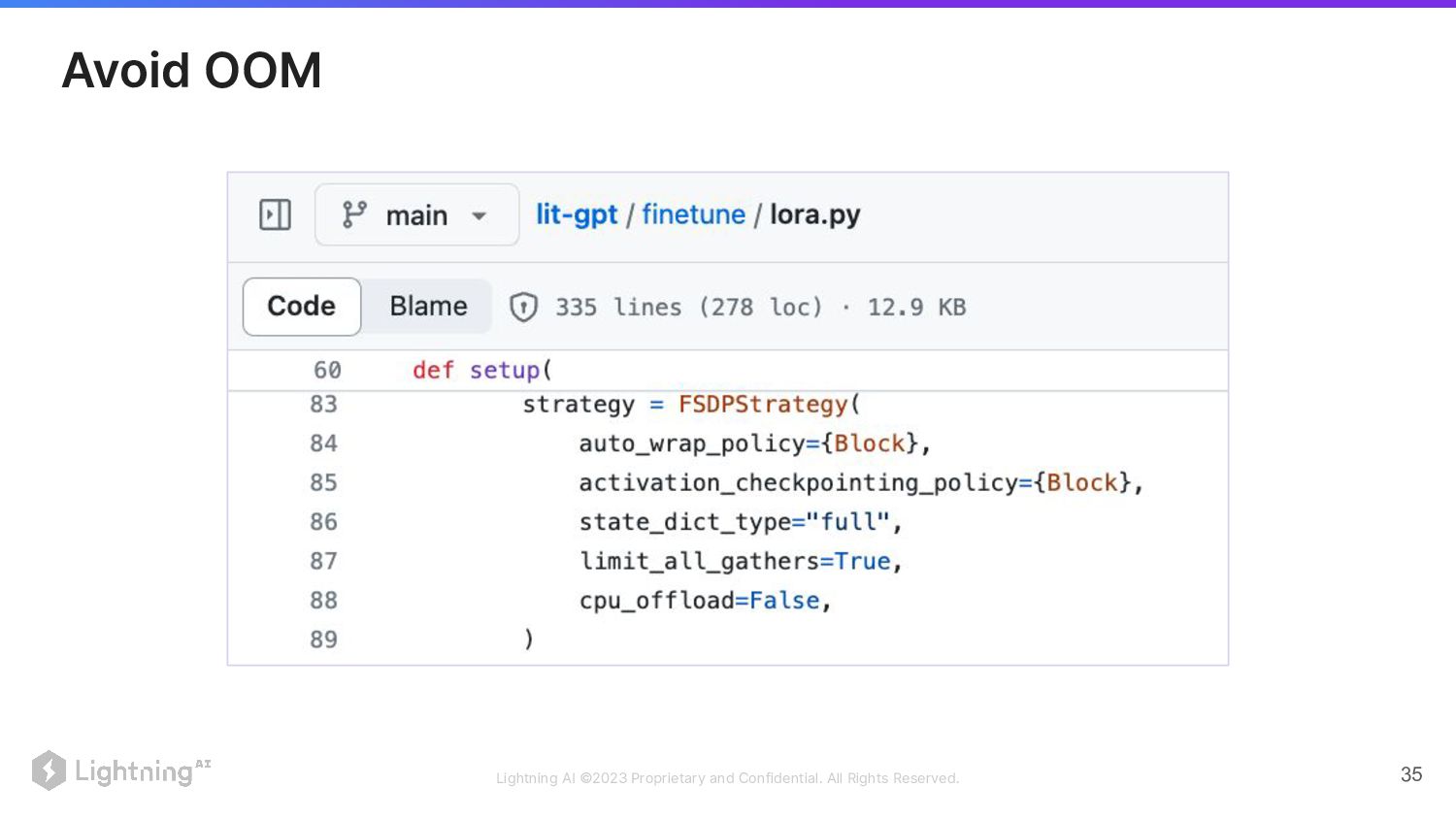
34 • Reduce the model's context length • Use lower
precision • 4-bit quantization • Do sharding across multiple GPUs • Reduce the micro batch size Avoid OOM
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 35
Avoid OOM
• Lit-GPT with LoRA finetuning • Lower Precision and 4-bit
quantization • Distributed training and activation checkpointing Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 36 Conclusion
Lightning AI ©2023 Proprietary and Confidential. All Rights Reserved. 37
Aniket Maurya
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}