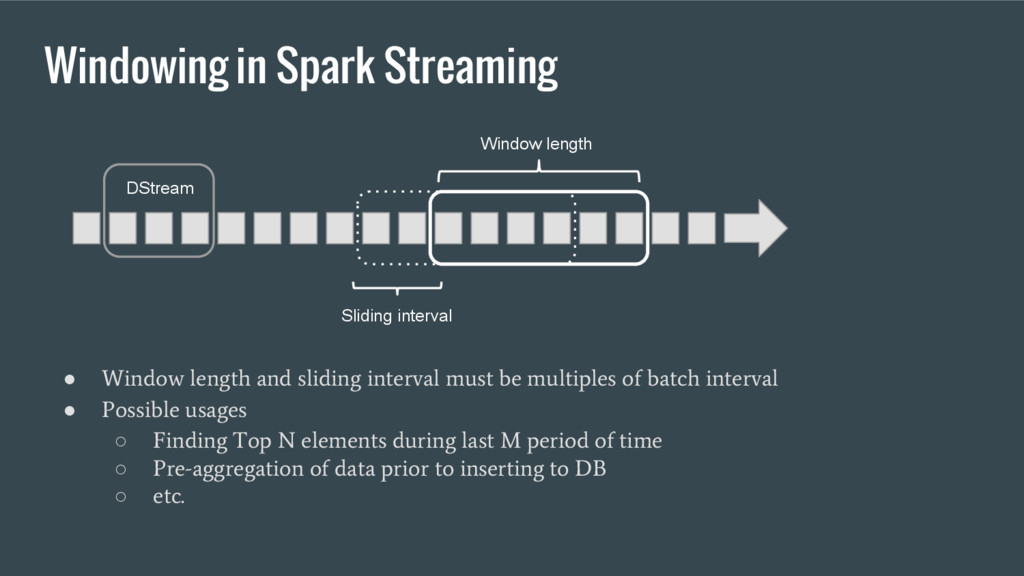
must be multiples of batch interval • Possible usages ◦ Finding Top N elements during last M period of time ◦ Pre-aggregation of data prior to inserting to DB ◦ etc. DStream Window length Sliding interval
Stream processor ◦ Tracking state (checkpointing) ◦ Resilient components • Consumer ◦ Reads only new messages “Easy” way: • Message deduplication based on some ID • Idempotent output destination
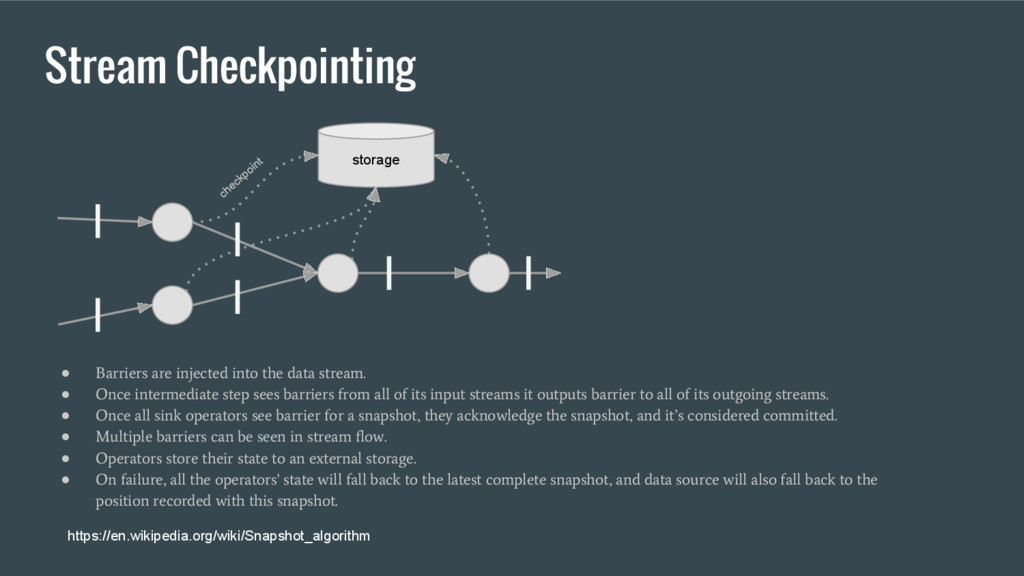
stream. • Once intermediate step sees barriers from all of its input streams it outputs barrier to all of its outgoing streams. • Once all sink operators see barrier for a snapshot, they acknowledge the snapshot, and it’s considered committed. • Multiple barriers can be seen in stream flow. • Operators store their state to an external storage. • On failure, all the operators' state will fall back to the latest complete snapshot, and data source will also fall back to the position recorded with this snapshot. storage checkpoint
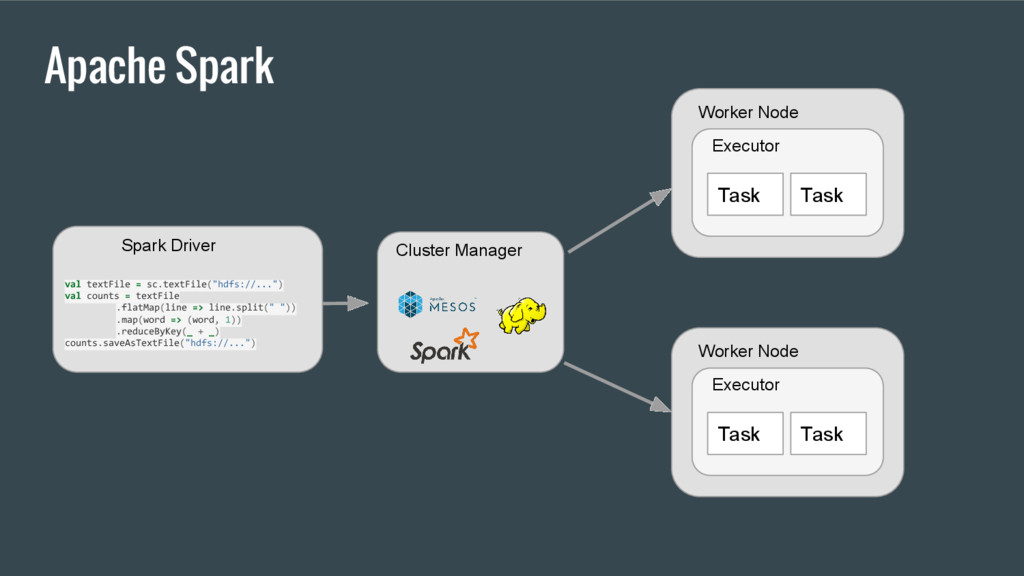
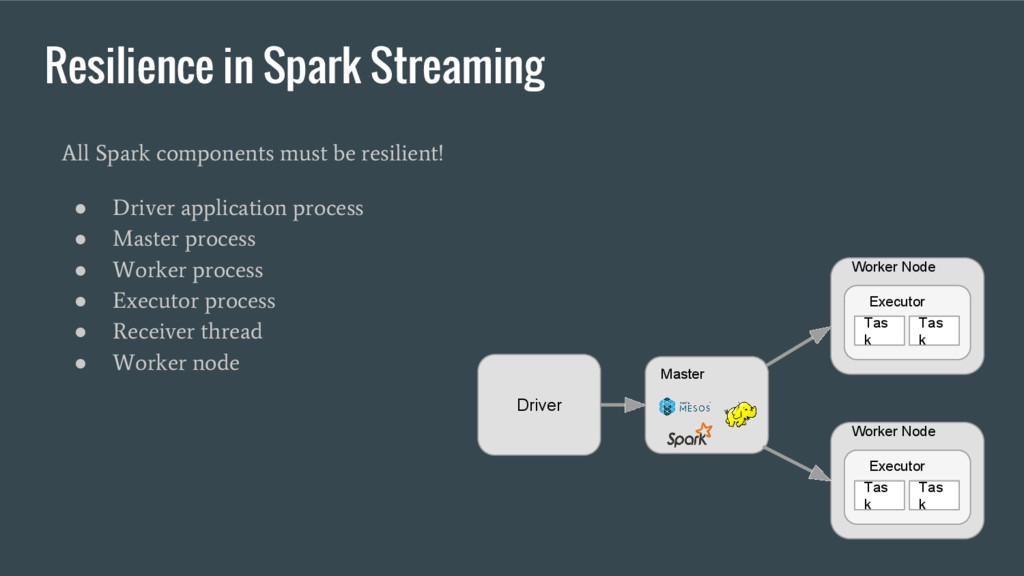
• Driver application process • Master process • Worker process • Executor process • Receiver thread • Worker node Driver Master Worker Node Executor Tas k Tas k Worker Node Executor Tas k Tas k
running inside the “spark-submit” process. ◦ If this process dies the entire application is killed. • Cluster mode ◦ Driver application runs on one of worker nodes. ◦ “--supervise” option makes driver restart on a different worker node. • Running through Marathon ◦ Marathon can re-start failed applications automatically. Master Worker Node Executor Tas k Tas k Worker Node Executor Tas k Tas k
killed. • Multi-master mode ◦ A standby master is elected active. ◦ Worker nodes automatically register with new master. ◦ Leader election via ZooKeeper. Driver Master Worker Node Executor Tas k Tas k Worker Node Executor Tas k Tas k
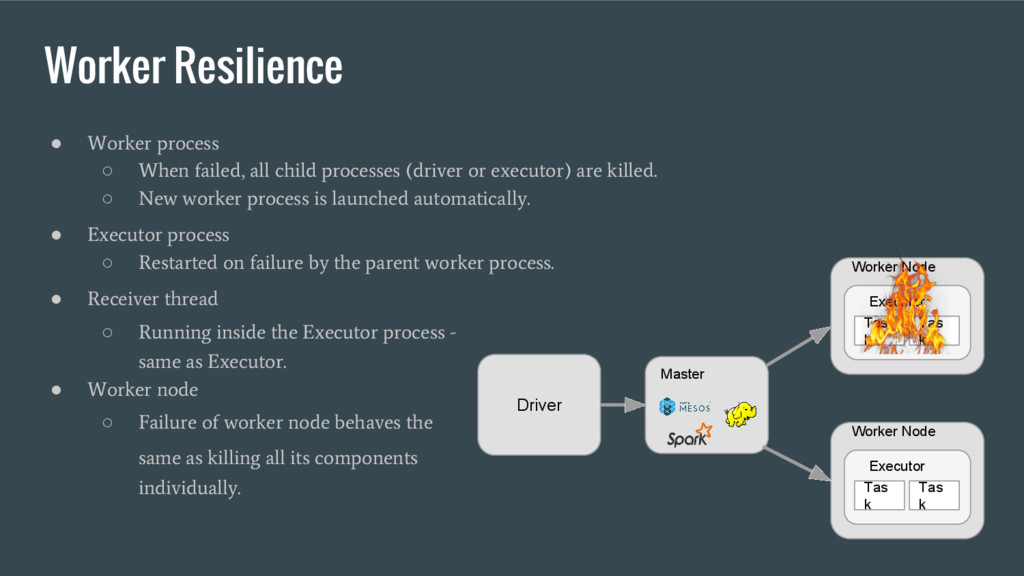
processes (driver or executor) are killed. ◦ New worker process is launched automatically. • Executor process ◦ Restarted on failure by the parent worker process. • Receiver thread ◦ Running inside the Executor process - same as Executor. • Worker node ◦ Failure of worker node behaves the same as killing all its components individually. Driver Master Worker Node Executor Tas k Tas k Worker Node Executor Tas k Tas k
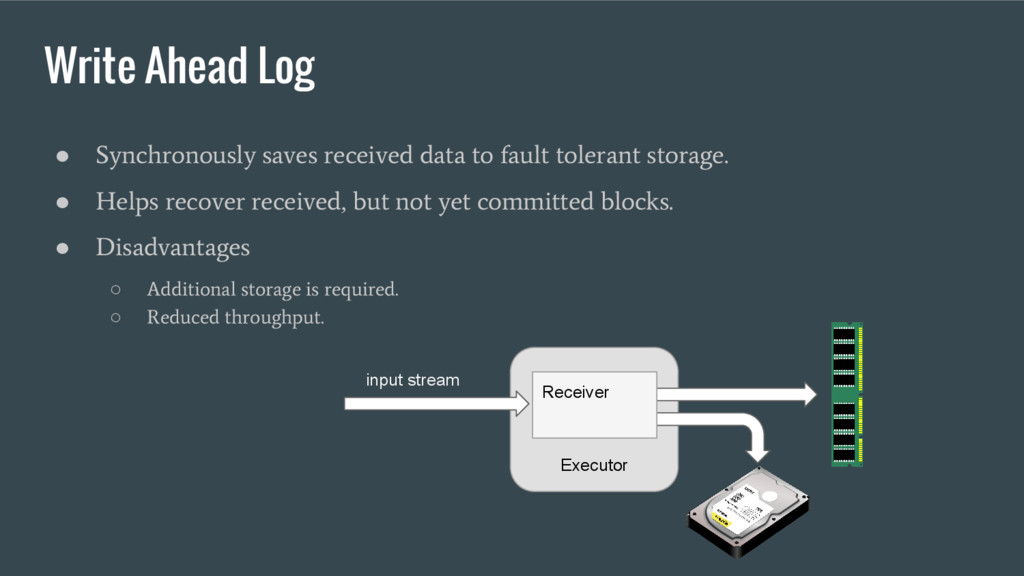
computation graph to some fault tolerant place (like HDFS or S3). • What is saved as metadata ◦ Metadata of queued but not processed batches ◦ Stream operations (code) ◦ Configuration • Disadvantages ◦ Frequent checkpointing reduces throughput. ◦ As the code itself is saved, upgrade is not possible without removing checkpoints.
even when using checkpointing (batches hold in memory will be lost on driver failure). • Checkpointing and WAL prevent data loss, but do not provide “exactly once” semantics. • If receiver fails before updating offsets in ZooKeeper - we are in trouble. • In this case data will be re-read from Kafka and from WAL. • Still not exactly once!
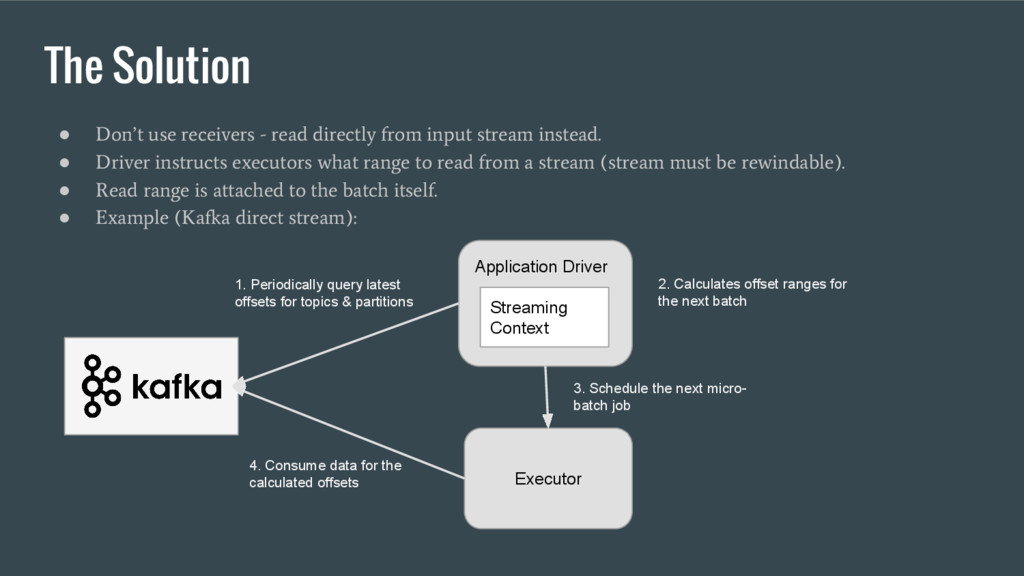
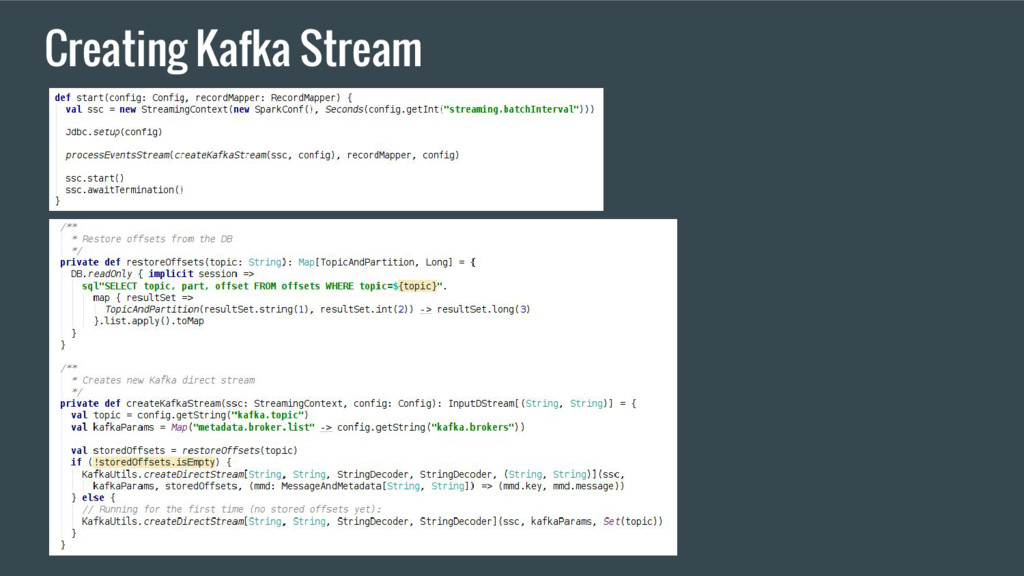
input stream instead. • Driver instructs executors what range to read from a stream (stream must be rewindable). • Read range is attached to the batch itself. • Example (Kafka direct stream): Application Driver Streaming Context 1. Periodically query latest offsets for topics & partitions 2. Calculates offset ranges for the next batch Executor 3. Schedule the next micro- batch job 4. Consume data for the calculated offsets
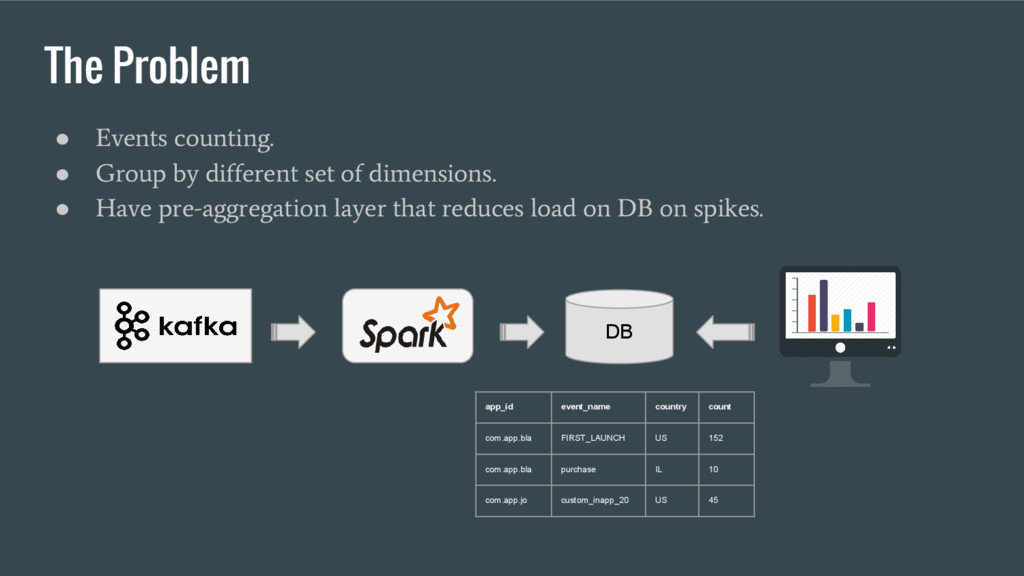
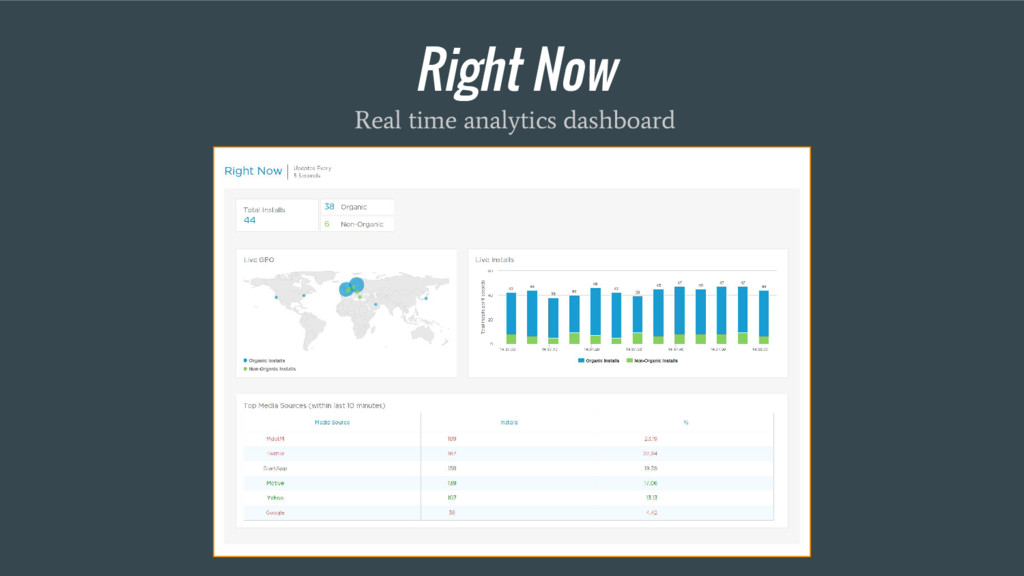
of dimensions. • Have pre-aggregation layer that reduces load on DB on spikes. DB app_id event_name country count com.app.bla FIRST_LAUNCH US 152 com.app.bla purchase IL 10 com.app.jo custom_inapp_20 US 45
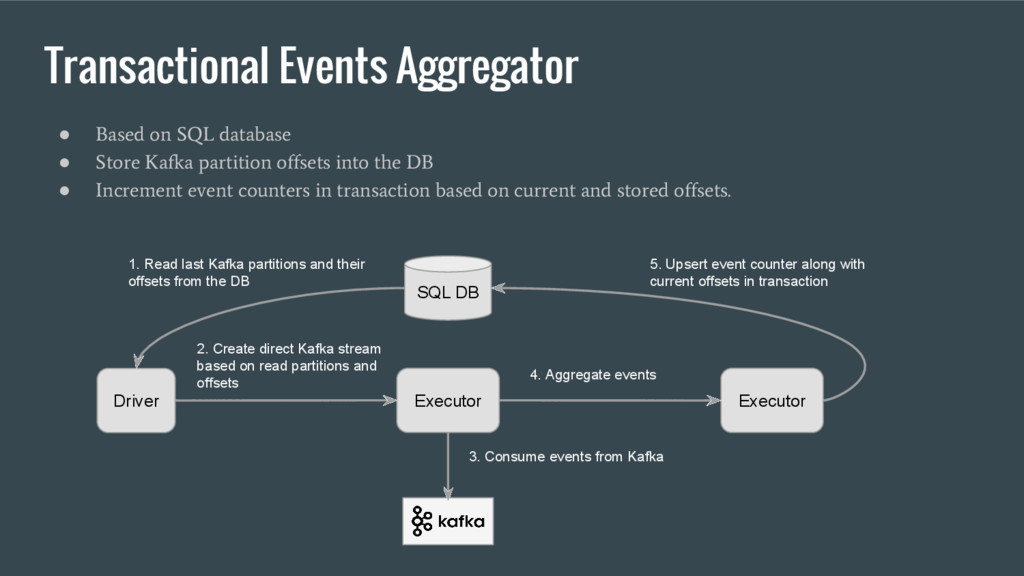
Kafka partition offsets into the DB • Increment event counters in transaction based on current and stored offsets. SQL DB Driver Executor Executor 1. Read last Kafka partitions and their offsets from the DB 2. Create direct Kafka stream based on read partitions and offsets 3. Consume events from Kafka 4. Aggregate events 5. Upsert event counter along with current offsets in transaction
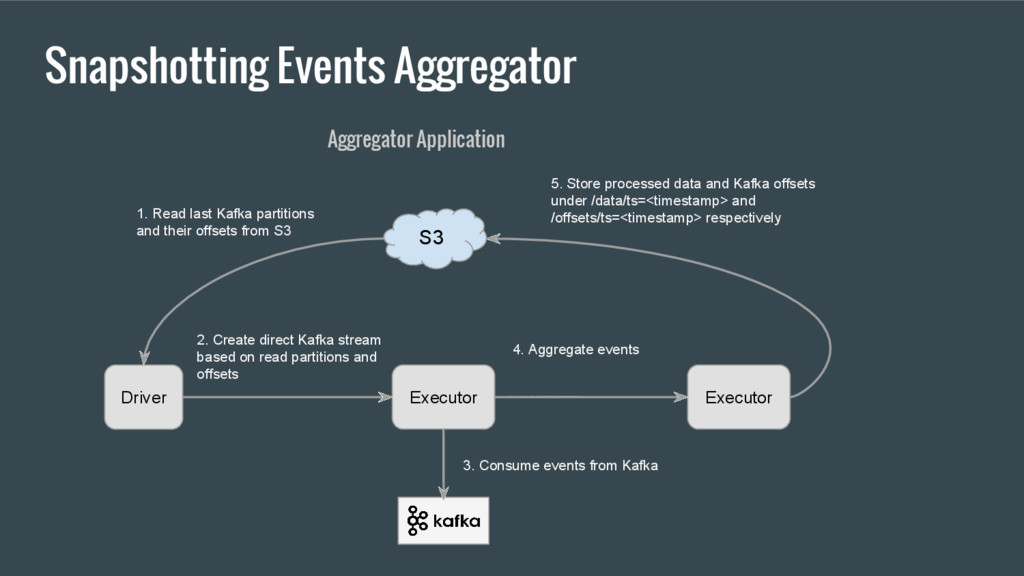
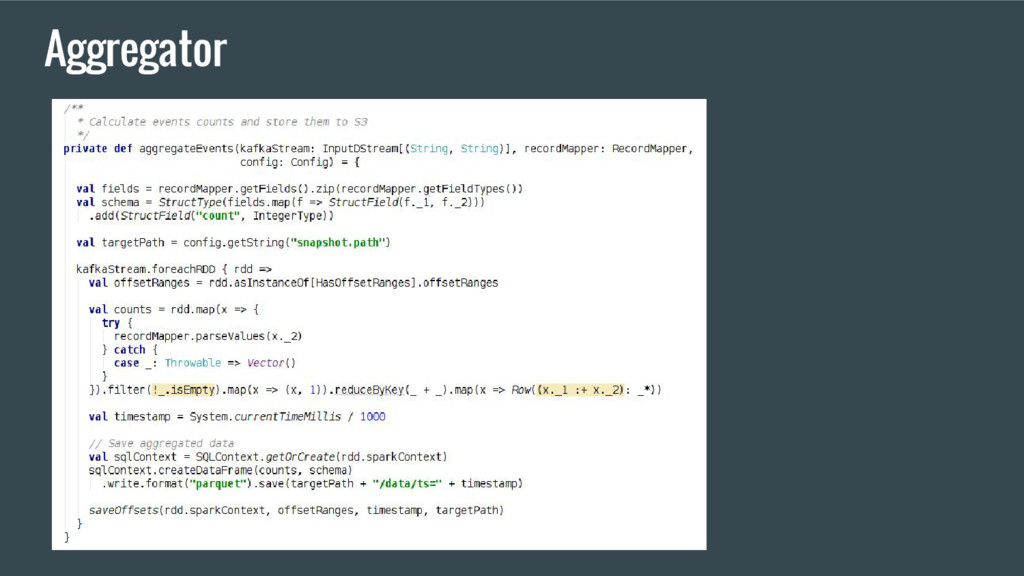
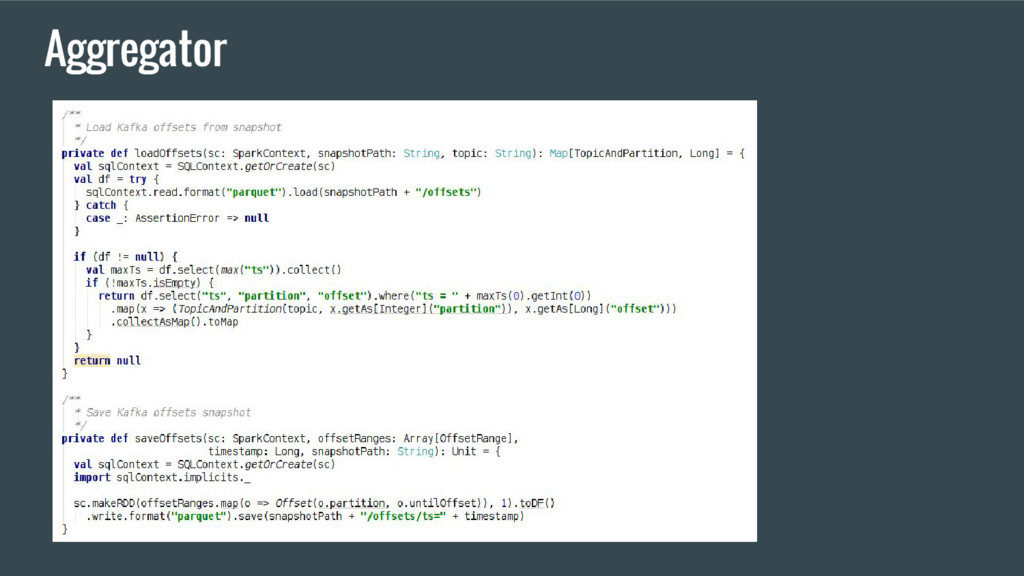
partitions and their offsets from S3 2. Create direct Kafka stream based on read partitions and offsets 3. Consume events from Kafka 4. Aggregate events 5. Store processed data and Kafka offsets under /data/ts=<timestamp> and /offsets/ts=<timestamp> respectively S3 Aggregator Application
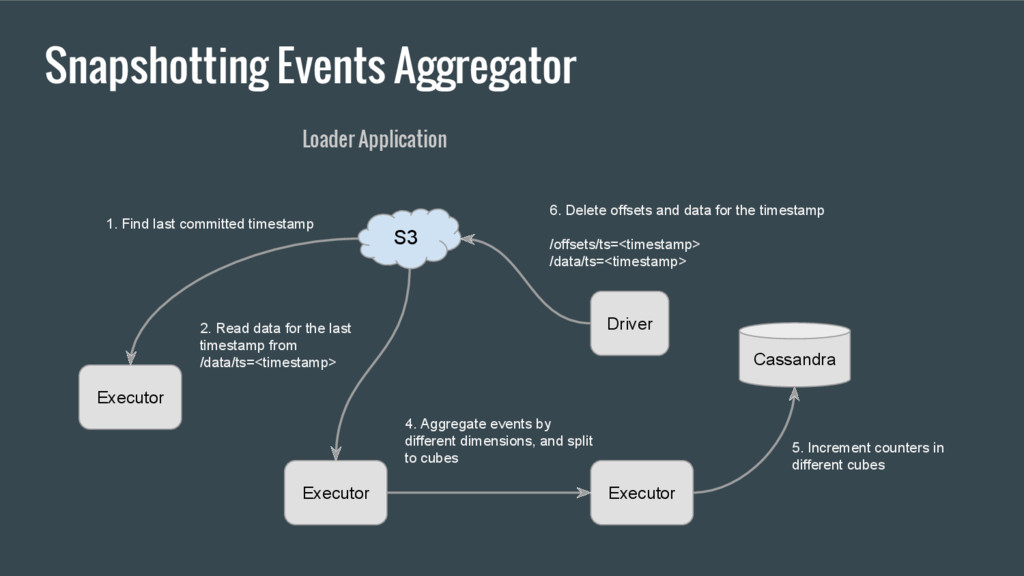
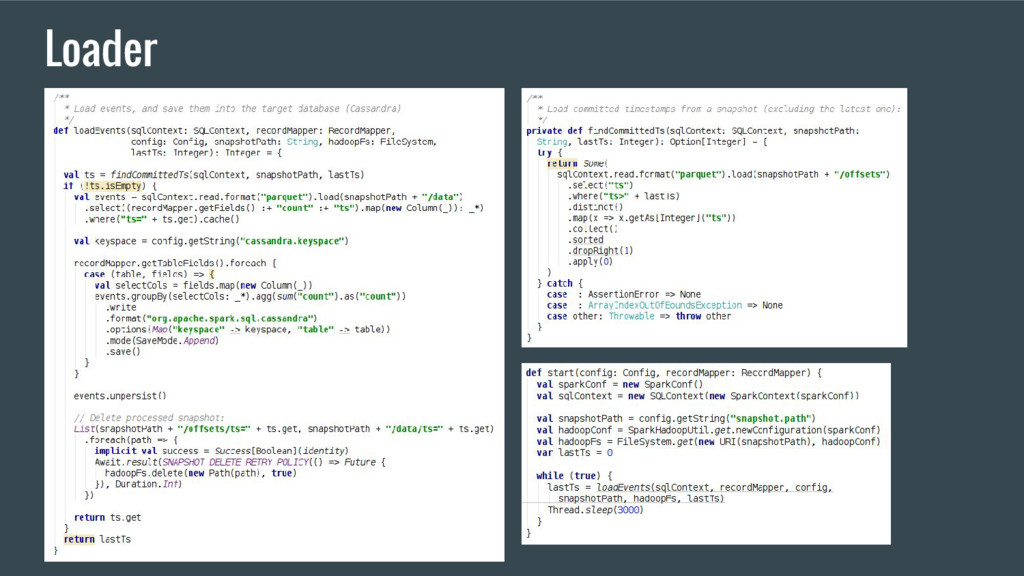
timestamp 2. Read data for the last timestamp from /data/ts=<timestamp> 4. Aggregate events by different dimensions, and split to cubes 6. Delete offsets and data for the timestamp /offsets/ts=<timestamp> /data/ts=<timestamp> S3 Loader Application Cassandra 5. Increment counters in different cubes Driver
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}