Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【初心者向け】ローカルLLMの色々な動かし方まとめ
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Aratako
September 05, 2025
Technology
5.2k
8
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【初心者向け】ローカルLLMの色々な動かし方まとめ
生成AIなんでも展示会 Vol.4 LT資料
Aratako
September 05, 2025
More Decks by Aratako
See All by Aratako
松尾研LLM講座2025 応用編Day3「軽量化」 講義資料
aratako
15
6.2k
安いGPUレンタルサービスについて
aratako
3
4.2k
Liquid AI Hackathon Tokyo プレゼン資料
aratako
0
290
松尾研LLM講座2024 最終コンペ解法
aratako
1
500
Other Decks in Technology
See All in Technology
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
870
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
3.3k
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
7
1k
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
150
AI時代こそ、スケールしないことをしよう -「作る人」から「なぜ作るか」を考える人へ / Do Things That Don't Scale in the AI Era — From How to Why
kaminashi
1
140
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
150
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
5
490
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
280
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
200
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
1.1k
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.2k
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
450
Featured
See All Featured
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Visualization
eitanlees
152
17k
Believing is Seeing
oripsolob
1
170
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
740
Agile that works and the tools we love
rasmusluckow
331
22k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
Building Adaptive Systems
keathley
44
3.1k
The browser strikes back
jonoalderson
0
1.4k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Transcript
【初心者向け】 ローカルLLMの色々な動かし方まとめ 2025/9/6 生成AIなんでも展示会 Vol.4 Aratako
自己紹介 主にLLMのモデルやデータセットなどを個人開発しています 各種リンク X (Twitter) @Aratako_LM
概要 ローカルLLMの色々な動かし方を簡単に紹介します • フロントエンド(Open WebUI、SillyTavernなど)は紹介しません • 触ったことのない環境・ライブラリについても紹介しません(できません) • 高度な使い方やパフォーマンス最適化などにも触れません •
2025年9月頭の情報に基づいています
Hugging Face Transformers リポジトリ:https://github.com/huggingface/transformers Hugging Faceが開発、各種機械学習モデルを簡単に動かすためのライブラリ 推論だけでなく、学習などの基盤にもなる gpt-oss-20bの推論例: # pip
install -U transformers kernels torch from transformers import pipeline import torch model_id = "openai/gpt-oss-20b" pipe = pipeline( "text-generation", model=model_id, torch_dtype="auto", device_map="auto", ) messages = [ {"role": "user", "content": "Explain quantum mechanics clearly and concisely."}, ] outputs = pipe( messages, max_new_tokens=256, ) print(outputs[0]["generated_text"][-1])
Hugging Face Transformers 良い点:簡単に使える、HF上にあるほとんどのモデルが動く 微妙な点: 推論が遅い、サーバなどは立てられない 用途:推論においては基本的に動作確認程度 コメント: 推論は非常に遅いので、基本動作確認をするときだけ利用
llama.cpp リポジトリ:https://github.com/ggml-org/llama.cpp C/C++で実装されたLLMの高速推論エンジン GGUFを動かすことができ、様々なツールのバックエンドとして統合されている gpt-oss-20bの推論例: apt-get update apt-get install pciutils
build-essential cmake curl libcurl4-openssl-dev -y git clone https://github.com/ggml-org/llama.cpp cmake llama.cpp -B llama.cpp/build \ -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-gguf-split cp llama.cpp/build/bin/llama-* llama.cpp ./llama.cpp/llama-cli \ -hf unsloth/gpt-oss-20b-GGUF:F16 \ --jinja -ngl 99 --threads -1 --ctx-size 16384 \ --temp 1.0 --top-p 1.0 --top-k 0
llama.cpp 良い点:推論が早め、GGUFを動かせる、互換性が高い、 OpenAI API互換サーバが立てられる、GGUF変換や量子化が可能 微妙な点: 導入がやや難しい、GUIがしょぼい、vLLMなどと比べると 大規模servingには向いていない 用途:ある程度詳しい方向け、フロントエンドは別で用意する方向け productionレベルというよりは個人開発で量子化などを行いたい場合に コメント:
自分で学習したモデルをGGUF化・量子化する時によく使う 単にモデルを使うだけなら後述のラッパーで十分な場合が多い
ollama / LMStudio / KoboldCpp 基本的にはllama.cppのラッパー 推論エンジンとChatbot的なGUIなどを統合したもの あまり大きな違いはないので、基本的に好みで使うのが良い 良い点:簡単にLLM推論サーバが立てられる、GUIのフロントエンドがある 微妙な点:
一部クローズドソース、productionレベルには向いていない 用途:初心者の方が簡単に使ってみたいときにおすすめ コメント: かなり使いやすいので、初心者にお勧め。ollamaなどは最近 クローズドになりつつあり、ややコミュニティで嫌われ気味 ollama:https://ollama.com/ LMStudio:https://lmstudio.ai/ KoboldCpp:https://github.com/LostRuins/koboldcpp
ExLlamaV2 / ExLlamaV3 ExLlamaV2:https://github.com/turboderp-org/exllamav2 ExLlamaV3:https://github.com/turboderp-org/exllamav3 EXL2 / EXL3形式への量子化、及びそれを推論するためのライブラリ 推論サーバとしての機能はTabbyAPIでサポート Qwen3-8Bの推論例:
git clone https://github.com/turboderp-org/exllamav3 cd exllamav3 # torchなどはあらかじめ入れておく pip install -r requirements.txt pip install -r requirements_examples.txt pip install . # EXL3形式のモデルをダウンロード(または自分で量子化) hf download turboderp/Qwen3-8B-exl3 --revision 4.0bpw --local-dir ./Qwen3-8B-exl3-4.0bpw python examples/chat.py -m ./Qwen3-8B-exl3-4.0bpw -mode chatml
ExLlamaV2 / ExLlamaV3 良い点:推論が早め(GGUFより速いといわれる)、量子化が柔軟、 量子化後モデルの精度(PPL)が優秀 微妙な点: ややマイナーで情報が少ない、開発速度遅め 用途:EXL3などの形式で配布されている量子化モデルを使いたい時など コメント: llama.cppよりやや推論が早いと言われているが、知名度は微妙
使う場面は少ないと思われる
Text Generation Inference リポジトリ:https://github.com/huggingface/text-generation-inference Hugging Face製のLLM推論ライブラリ、通称TGI HuggingChatのバックエンドとして実際に使われている Qwen3-4Bの推論例: model=Qwen/Qwen3-4B-Thinking-2507 volume=$PWD/data
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data \ ghcr.io/huggingface/text-generation-inference:3.3.4 --model-id $model
Text Generation Inference 良い点:Hugging Face謹製、バックエンドにTRT-LLMなども選択可能 微妙な点: 開発がやや遅い、マイナーなので情報が少ない 用途:動作検証~productionレベルでのサービング コメント: 正直あまり使われているのを見ないし、あまり使ったことはない
開発が遅いのもあり、使う場面は少ない
vLLM リポジトリ:https://github.com/vllm-project/vllm オープンソースで非常にメジャーなLLM高速推論エンジン かなり老舗で開発も非常に活発、新モデルのDay 0サポートも多い gpt-oss-20bの推論例: # Dockerで動かす docker run
--gpus all -p 8000:8000 --ipc=host \ vllm/vllm-openai:v0.10.1 --model openai/gpt-oss-20b # またはuvで環境構築 uv pip install vllm --torch-backend=auto vllm serve openai/gpt-oss-20b
vLLM 良い点:推論が早い、Productionレベルで使える、オープンソース、 新モデル対応が早い、セットアップが非常に簡単 微妙な点: マルチノード推論が(個人的に)使いづらい 用途:個人開発から大規模Servingまで コメント: 個人開発レベル~Productionレベルまで幅広くおすすめ 開発が早く使いやすい。K8s統合も公式で提供
SGLang リポジトリ:https://github.com/sgl-project/sglang LMSYS製のオープンソースなLLM高速推論エンジン vLLMより高速な場合もある。Grokの推論エンジンとして採用されている gpt-oss-20bの推論例: # Dockerで動かす docker run --gpus
all --shm-size 32g -p 30000:30000 \ -v ~/.cache/huggingface:/root/.cache/huggingface --ipc=host \ lmsysorg/sglang:latest \ python3 -m sglang.launch_server --model-path Qwen/Qwen3-4B-Thinking-2507--host 0.0.0.0 --port 30000 # またはuvで環境構築 uv pip install "sglang[all]>=0.5.2rc1" python3 -m sglang.launch_server --model-path Qwen/Qwen3-4B-Thinking-2507 --host 0.0.0.0 --port 30000
SGLang 良い点:推論が早い、Productionレベルで使える、マルチノード推論が比較的簡単 微妙な点: ドキュメントが少ない(日本語)、互換性の問題など 用途:Productionレベルでの大規模Servingなど コメント: Grokの推論に実際に使われている。vLLMの対抗馬的な存在 利用側としては適宜使い分ければ良い
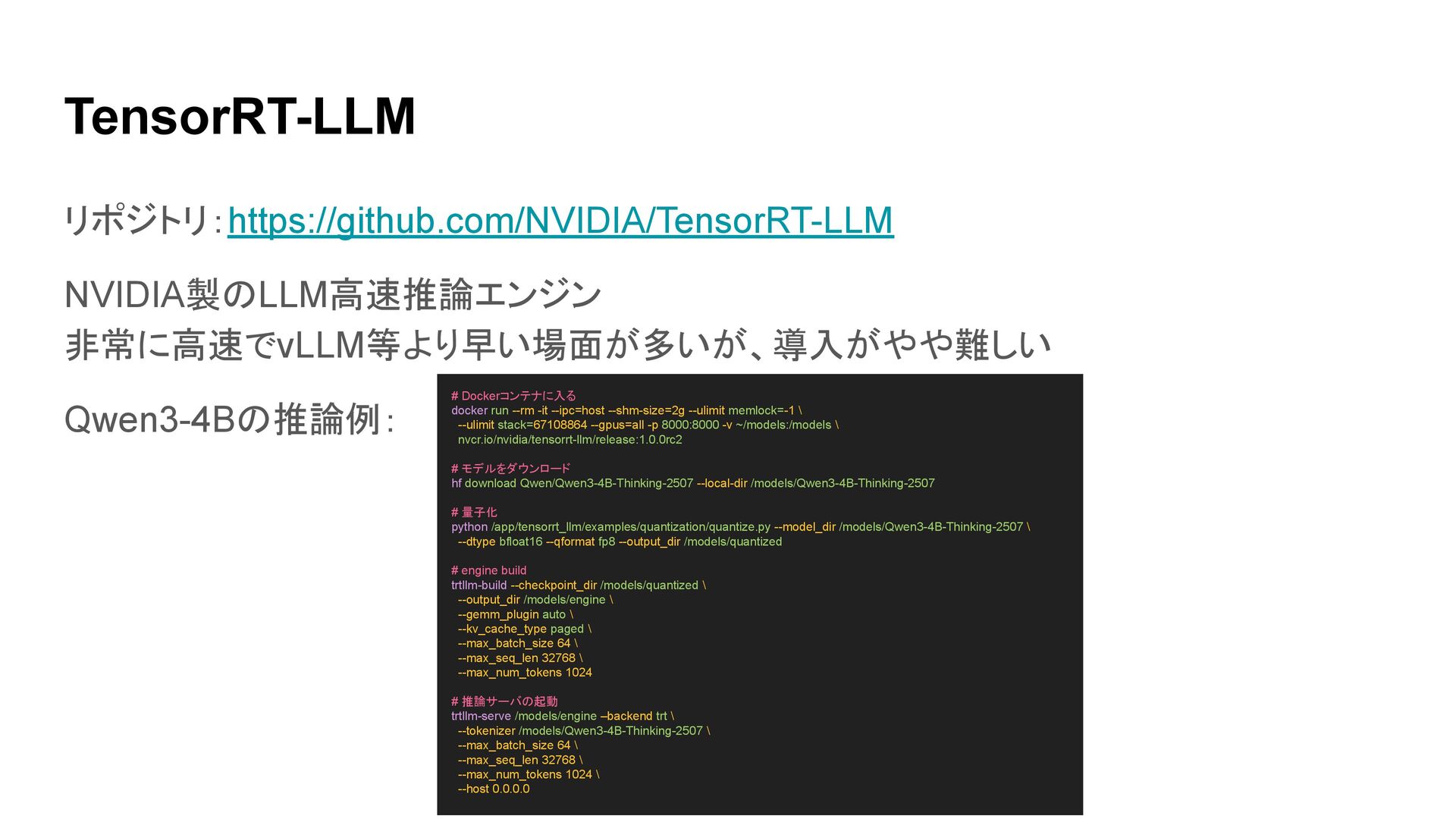
TensorRT-LLM リポジトリ:https://github.com/NVIDIA/TensorRT-LLM NVIDIA製のLLM高速推論エンジン 非常に高速でvLLM等より早い場面が多いが、導入がやや難しい Qwen3-4Bの推論例: # Dockerコンテナに入る docker run --rm
-it --ipc=host --shm-size=2g --ulimit memlock=-1 \ --ulimit stack=67108864 --gpus=all -p 8000:8000 -v ~/models:/models \ nvcr.io/nvidia/tensorrt-llm/release:1.0.0rc2 # モデルをダウンロード hf download Qwen/Qwen3-4B-Thinking-2507 --local-dir /models/Qwen3-4B-Thinking-2507 # 量子化 python /app/tensorrt_llm/examples/quantization/quantize.py --model_dir /models/Qwen3-4B-Thinking-2507 \ --dtype bfloat16 --qformat fp8 --output_dir /models/quantized # engine build trtllm-build --checkpoint_dir /models/quantized \ --output_dir /models/engine \ --gemm_plugin auto \ --kv_cache_type paged \ --max_batch_size 64 \ --max_seq_len 32768 \ --max_num_tokens 1024 # 推論サーバの起動 trtllm-serve /models/engine –backend trt \ --tokenizer /models/Qwen3-4B-Thinking-2507 \ --max_batch_size 64 \ --max_seq_len 32768 \ --max_num_tokens 1024 \ --host 0.0.0.0
TensorRT-LLM 良い点:推論が非常に早い、Productionレベルで使える 微妙な点: 新モデルの対応がやや遅め、一部クローズドソース、 導入がやや面倒、NVIDIA GPU専用、別途フロントエンドが必要 用途:Productionレベルでの大規模Servingなど コメント: 速度を追い求めるなら。セットアップが面倒なので、 基本はvLLMなどで十分なことが多い
最近PyTorch Backendに移行が進んでいる
その他触ったことのないもの たまに名前を見るが触れてないもの、環境的に触ったことのないものなど • LMDeploy • KTransformers • MLX系 • AWS
Neuron、Google TPU、Intel GPUなどを使った推論
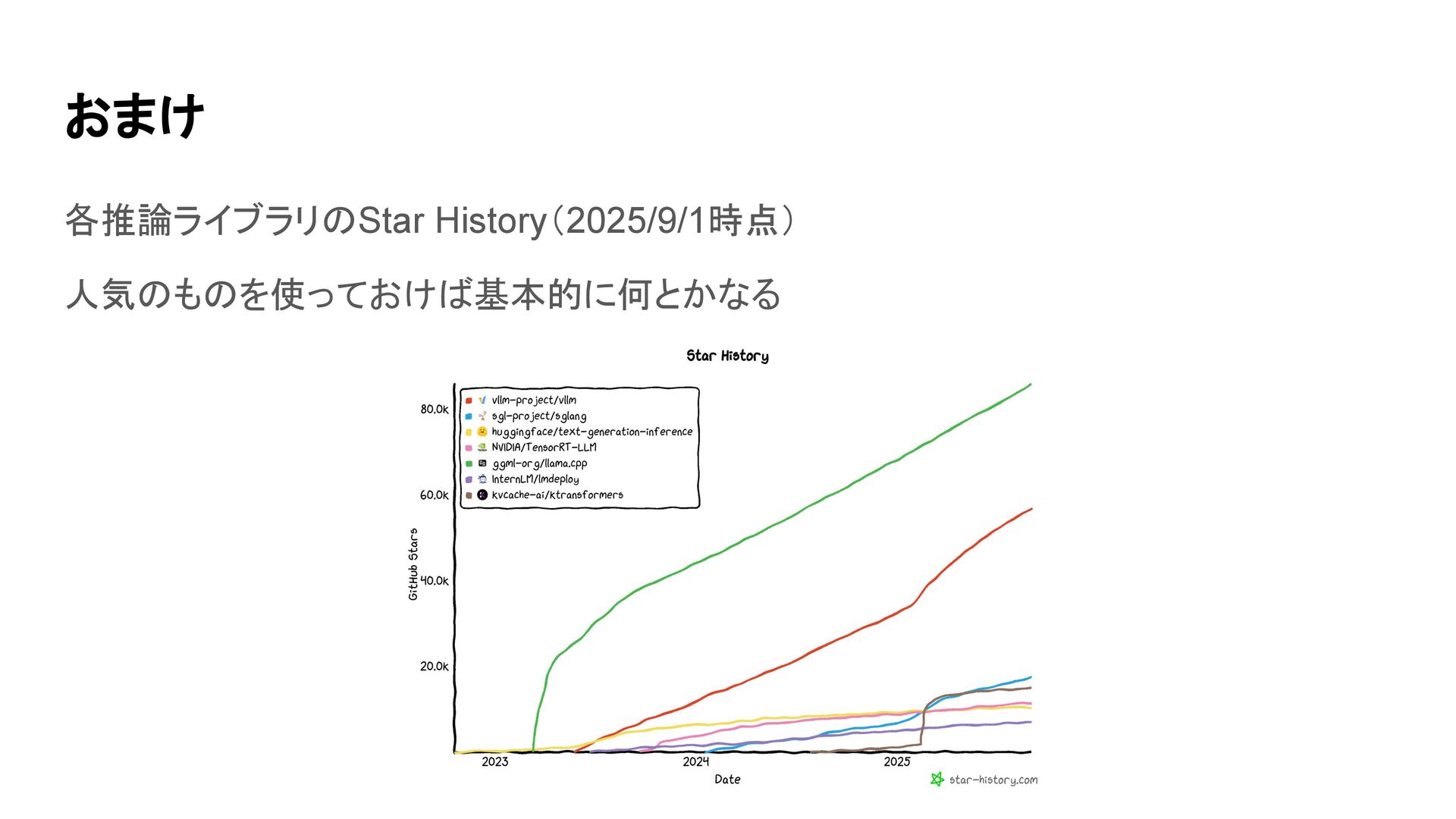
おまけ 各推論ライブラリのStar History(2025/9/1時点) 人気のものを使っておけば基本的に何とかなる
まとめ 用途によって色々と使い分けると良い • とりあえず動作確認だけしたい! →Hugging Face Transformers • 高速な推論環境を簡単に使いたい! →llama.cppラッパー(ollama
/ LMStudioなど) • 自分でGGUFを作ったり量子化してみたい! →llama.cpp • Productionレベルで大規模 Servingしたい! →vLLM、SGLang、TensorRT-LLM →(本当に大規模ならllm-dやNVIDIA Dynamoなども)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}