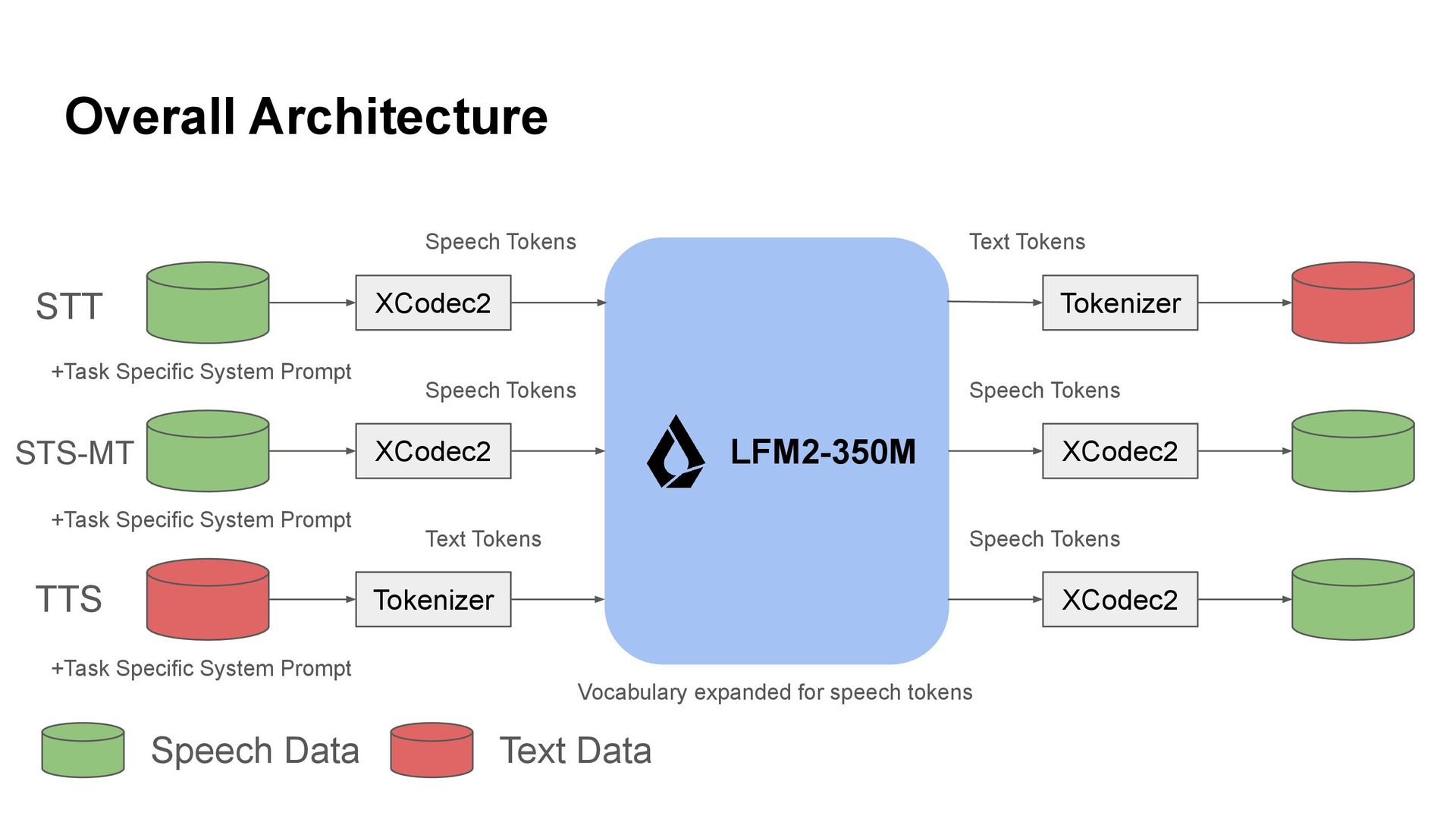
TTS STS-MT Speech Data Text Data Speech Tokens Speech Tokens Text Tokens Text Tokens Speech Tokens Speech Tokens +Task Specific System Prompt +Task Specific System Prompt +Task Specific System Prompt Vocabulary expanded for speech tokens
is not readily available, so I created my own. Process: 1. Start with the Emilia Dataset (a multilingual text and speech dataset). 2. Use LFM2-ENJP-MT to translate the text (JP↔EN). 3. Use Llasa-3B (EN) and Anime-Llasa-3B (JP) TTS models to synthesize audio from the translated text. Resulting Dataset: • Original JP → Synthetic EN: 492.32 hours • Original EN → Synthetic JP: 488.28 hours • Total: ~980 hours of parallel speech data.
base LFM2 model has no prior knowledge of audio tokens. The STS task [Audio] -> [Audio] involves completely new "words". Solution: Continual Pre-Training (CPT) I performed unsupervised CPT on a large, mixed corpus of audio and text to familiarize the model with the audio token space. Data Used: • Audio: ◦ Emilia-JA: ~2,800 hours ◦ Emilia-EN: ~5,000 hours (estimated) • Text: ◦ Japanese Wikipedia (Full) ◦ English Wikipedia (~20% of full) https://api.wandb.ai/links/aratako-lm/r5sb7xpe
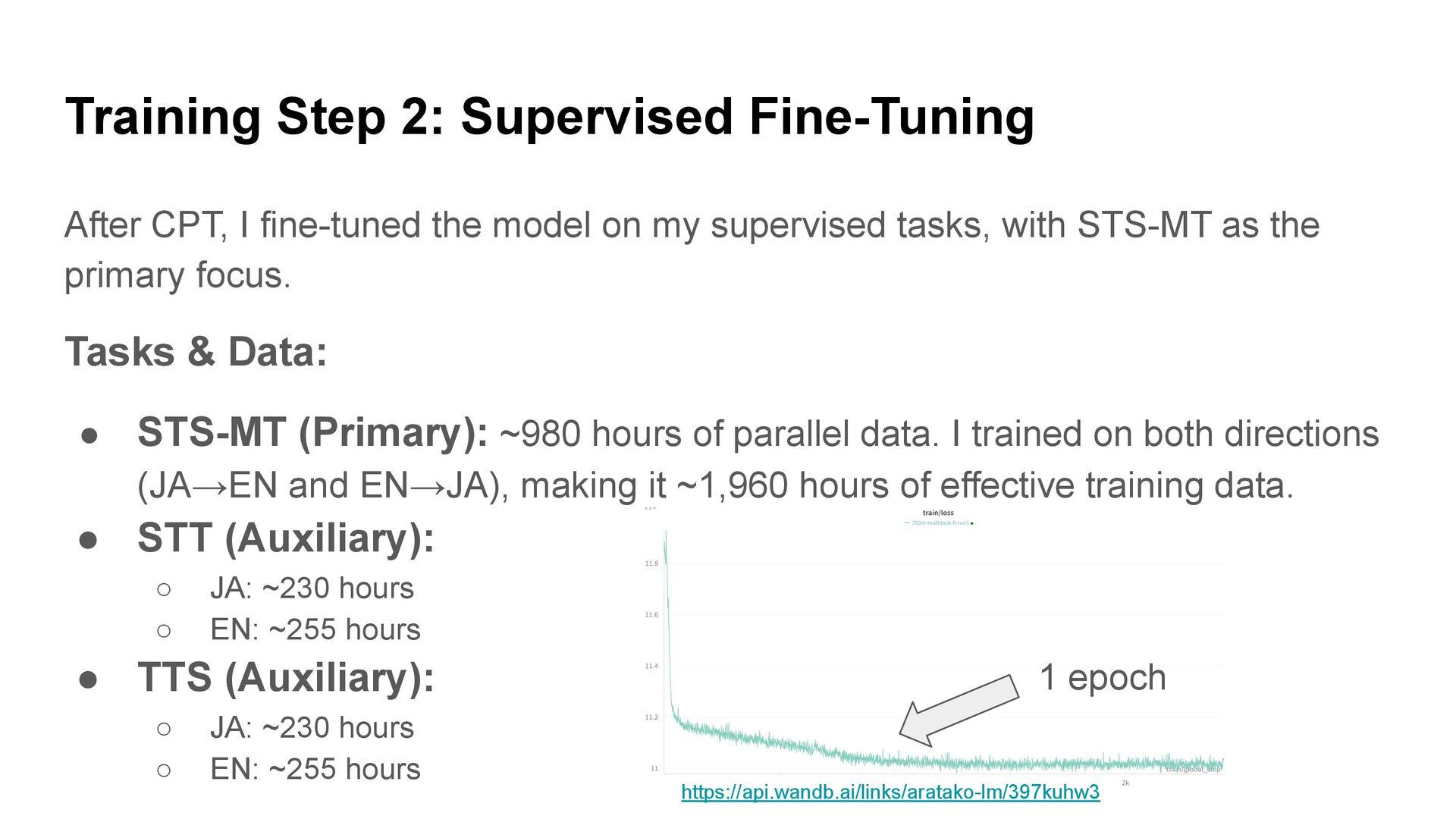
the model on my supervised tasks, with STS-MT as the primary focus. Tasks & Data: • STS-MT (Primary): ~980 hours of parallel data. I trained on both directions (JA→EN and EN→JA), making it ~1,960 hours of effective training data. • STT (Auxiliary): ◦ JA: ~230 hours ◦ EN: ~255 hours • TTS (Auxiliary): ◦ JA: ~230 hours ◦ EN: ~255 hours 1 epoch
was not achieved. • Audio Generation (STS & TTS): The model generated audio tokens, but they immediately fell into a repetitive loop and did not form coherent speech. • Task Differentiation (STT): When prompted with the STT task, the model correctly produced text tokens instead of audio tokens. This indicates it learned to distinguish tasks based on the prompt, even though the transcribed text was gibberish (like えっと、えっ と、えっと、...). Overall, the model learned a very basic aspect of task differentiation but failed completely at the core generation tasks.
was insufficient data. • Scale Mismatch: Modern LLM-based TTS models are often trained on over 100k hours of data from scratch. My ~2,000 hours of total supervised data was likely far too little for the model to learn the complex patterns of speech generation. • Learning Did Occur: The model did learn to differentiate tasks (outputting audio tokens for STS/TTS vs. text tokens for TTS). This suggests the multi-task setup was partially effective, but the generation quality suffered from data scarcity. • Better Approach: Instead of fine-tuning from a base text LFM2, starting from a pre-trained audio-centric model (like LFM2-Audio) might have provided a much better foundation and yielded more successful results.
direct Speech-to-Speech translation model by fine-tuning LFM2 on multiple tasks. • Method: I created a ~1000-hour synthetic parallel speech corpus and implemented a two-step training process: continued pre-training followed by multi-task fine-tuning. • Outcome: The model failed to generate coherent speech, likely due to a significant lack of training data. However, it demonstrated a basic ability to handle audio inputs for STT. For future work, starting from a pre-trained audio model is highly recommended.
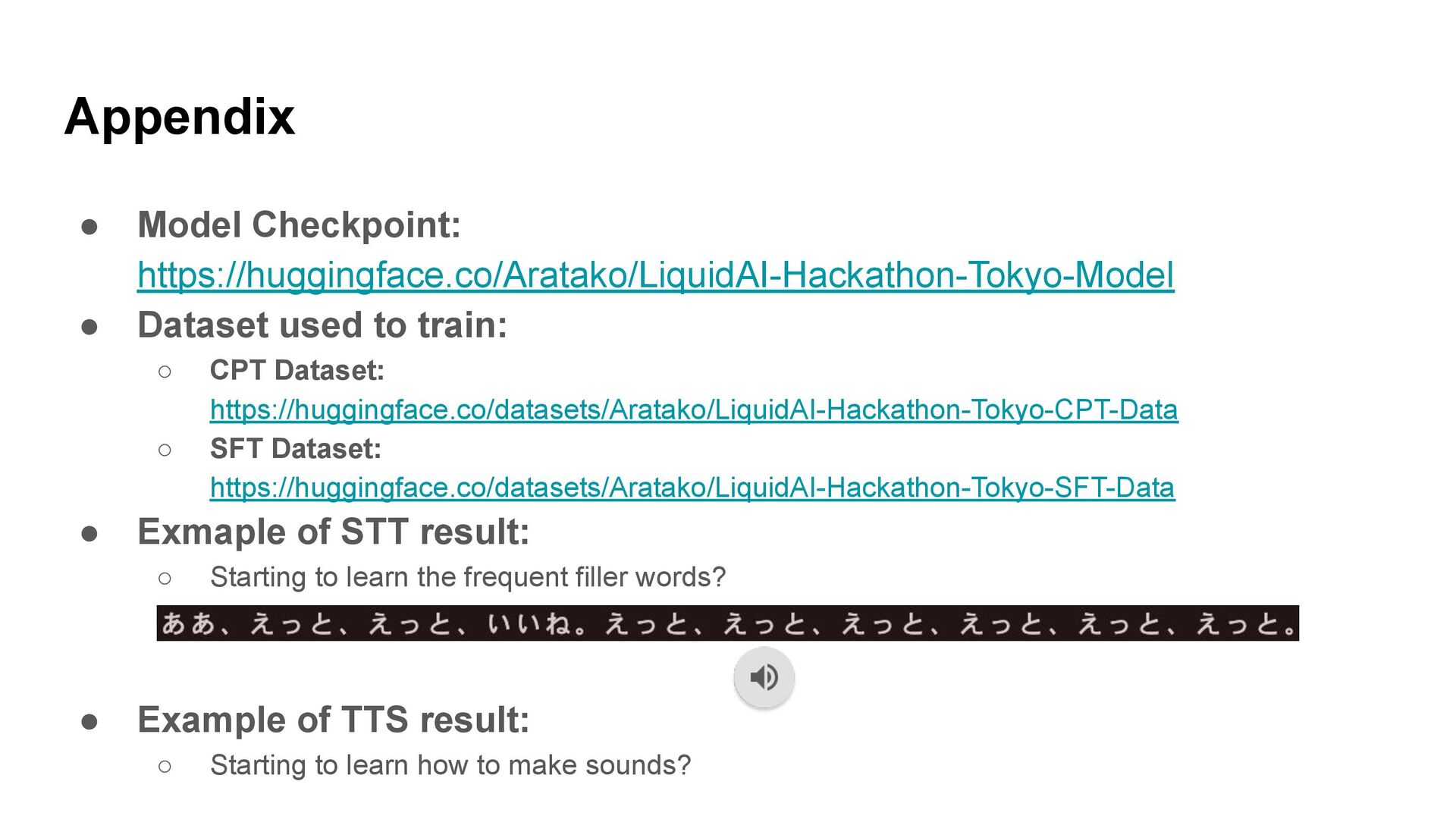
◦ CPT Dataset: https://huggingface.co/datasets/Aratako/LiquidAI-Hackathon-Tokyo-CPT-Data ◦ SFT Dataset: https://huggingface.co/datasets/Aratako/LiquidAI-Hackathon-Tokyo-SFT-Data • Exmaple of STT result: ◦ Starting to learn the frequent filler words? • Example of TTS result: ◦ Starting to learn how to make sounds?
axolotl: https://github.com/axolotl-ai-cloud/axolotl • vLLM: https://github.com/vllm-project/vllm • Emilia: https://huggingface.co/datasets/amphion/Emilia-Dataset • Liquid AI, Weights and Biases, and Lambda • and other ML community and projects!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}