use of data. Designed for how we build and run application today. MongoDB Meetup at Free online formation: Mongo University 5.000.000+ Download MongoDB Management Service (MMS) ◦ Cloud based suite ◦ Monitoring & Backup
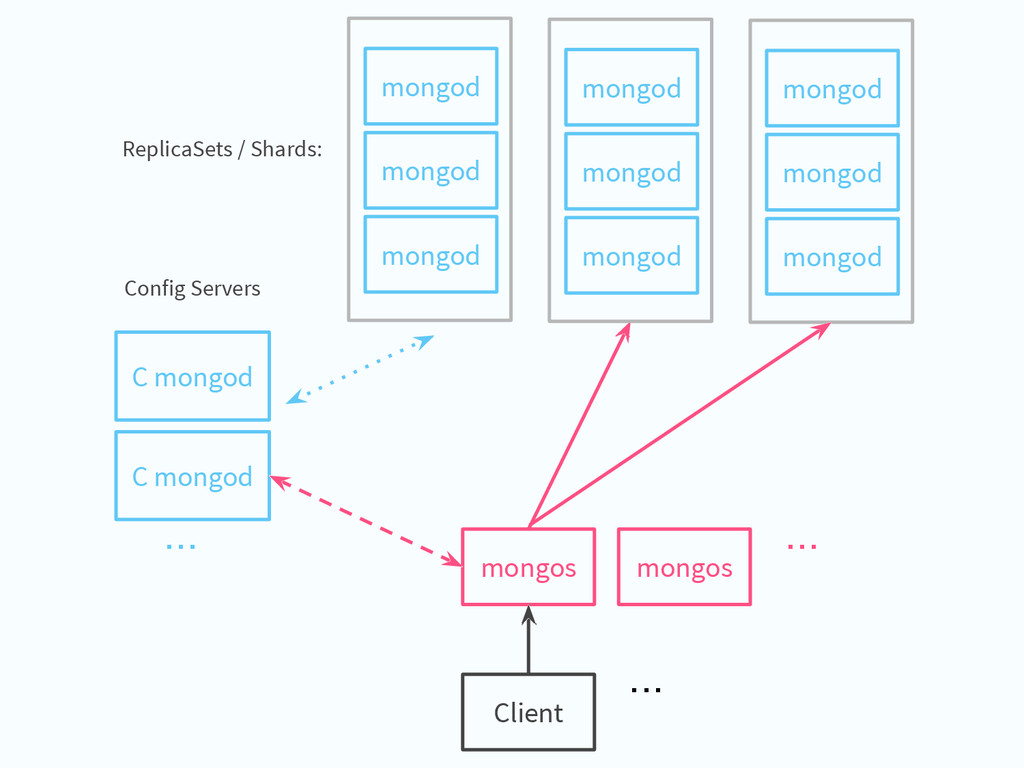
one or more fields that define a range of data (key space) Sharding balancer keep data evenly distributed on all shards Config Servers (mongod processes) servers that stores chunk ranges/location Routers (mongos processes) router balancer
(like an index) Each chunk contains a non overlapping range of shard key Shard key needs high cardinality & not be continuously increasing (_id might be a bad idea)
shard #ideal Without the shard key Scatter (query on all shards) & gather Sorted without shard key distributed merge sort query on all shards and merged and sorted in mongos
by user. hint will try to force the query to use the index. Do I use an index? db.collection.find(...).hint(...) n number of doc matching the query nscanned number of index entries scanned nscannedObjects number of actual objects scanned if cursor 'Basic Cursor' then no index was used db.collection.find(...).explain(...)
indexes: effective only if query is a prefix fit Using low selectivity indexes (status versus status/created_at) Misusing Regex: Only left anchored regex can use the index Expecting negation query to use the index
V8 Engine mapReduce commands run in its own thread Aggregation Framework Pipeline model for aggregating and processing document developed by MongoDB Hadoop De facto technology for large scale processing of data-sets
Real-time Very simple & Powerful (pipeline) Declared in JSON (no JS/C++ translation) Local data Leverage existing data processing infrastructure Horizontally scale data processing Load to DB Challenging debug Expensive operation translation JS/C++ Add load to DB Limited set of operation Data output limited to 16MB Away from data store Offline Batch Sync between store & processor Complex setup
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
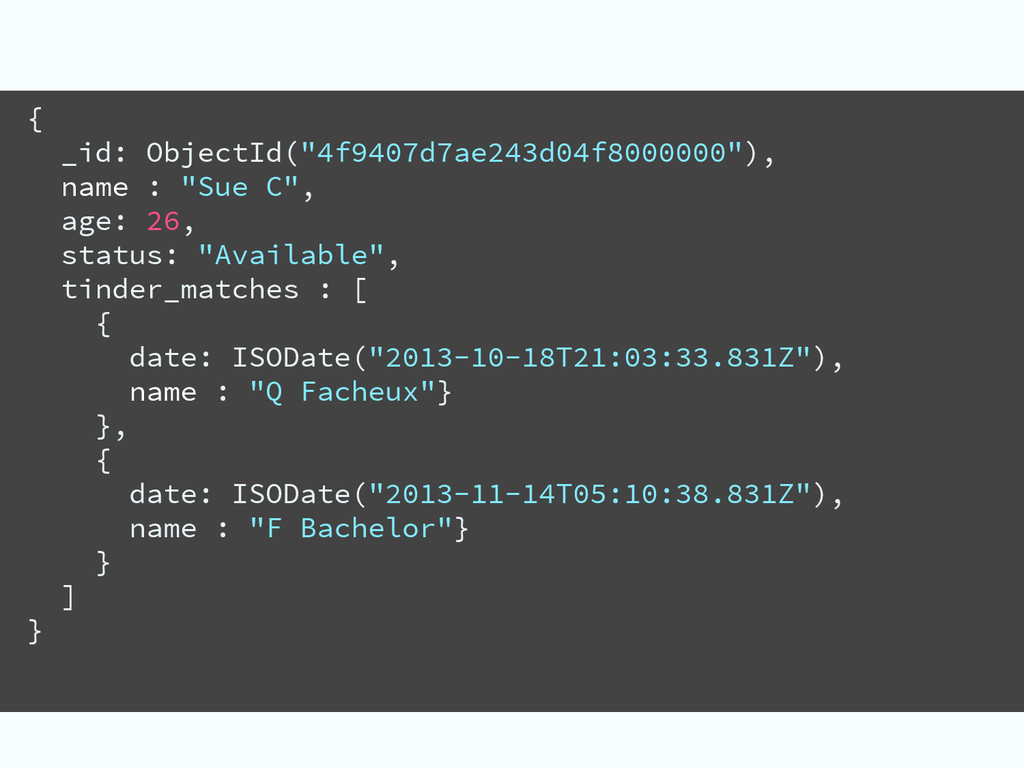{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
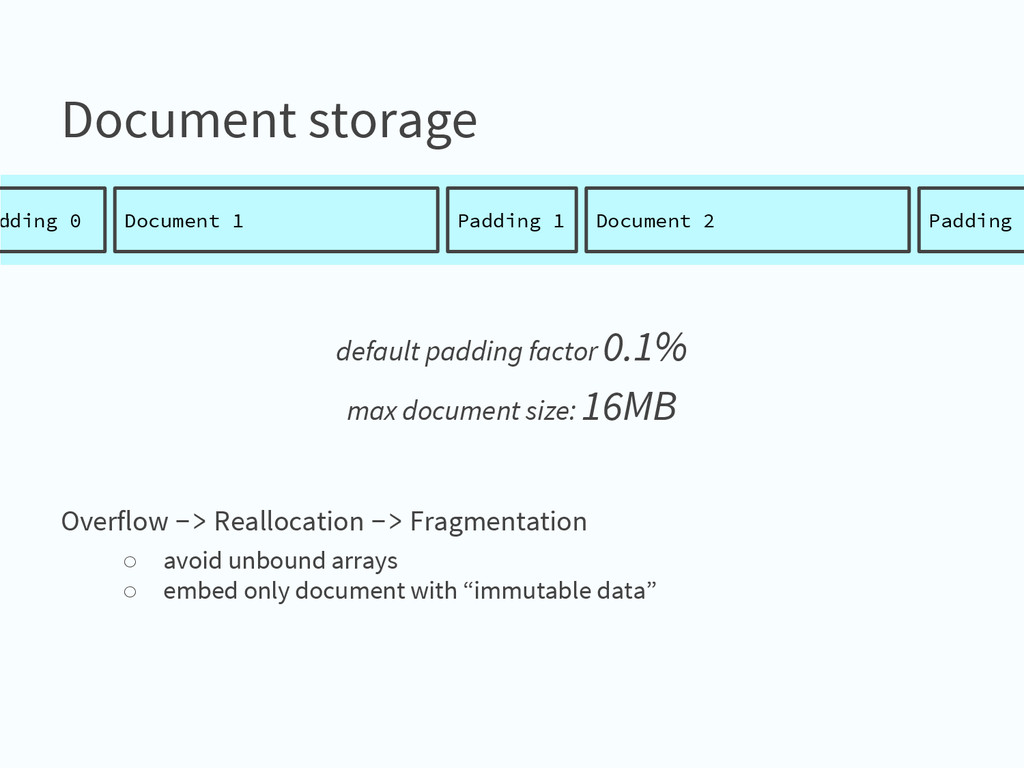{kind=link}
{kind=link}
{kind=link}
{kind=link}
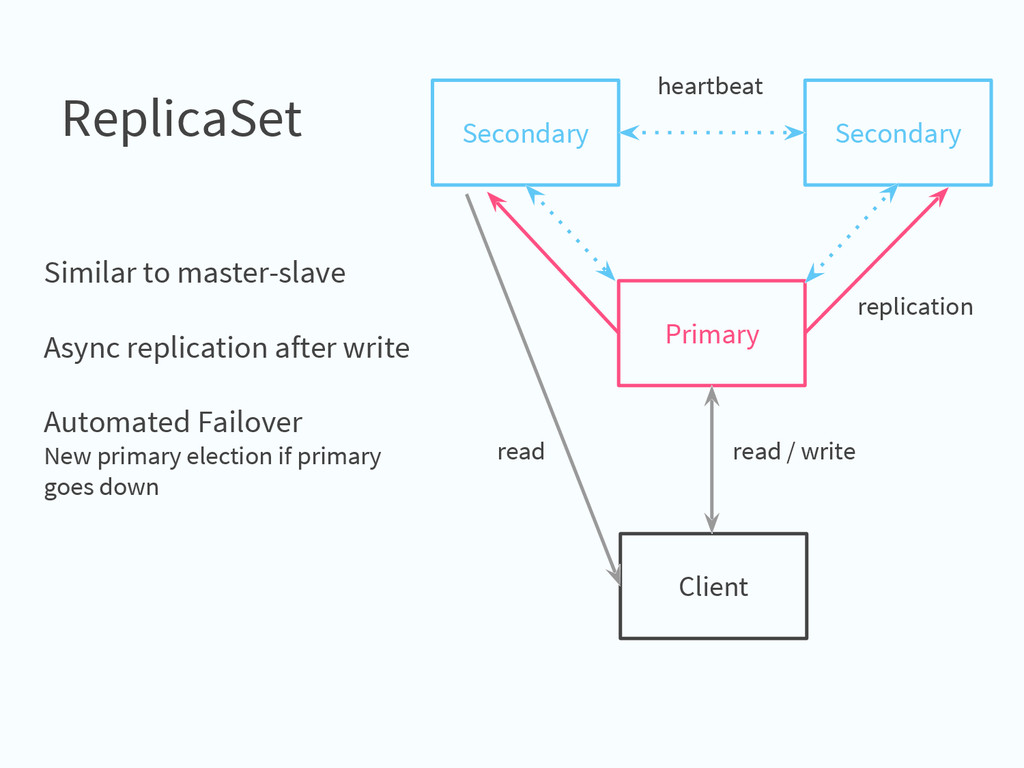{kind=link}
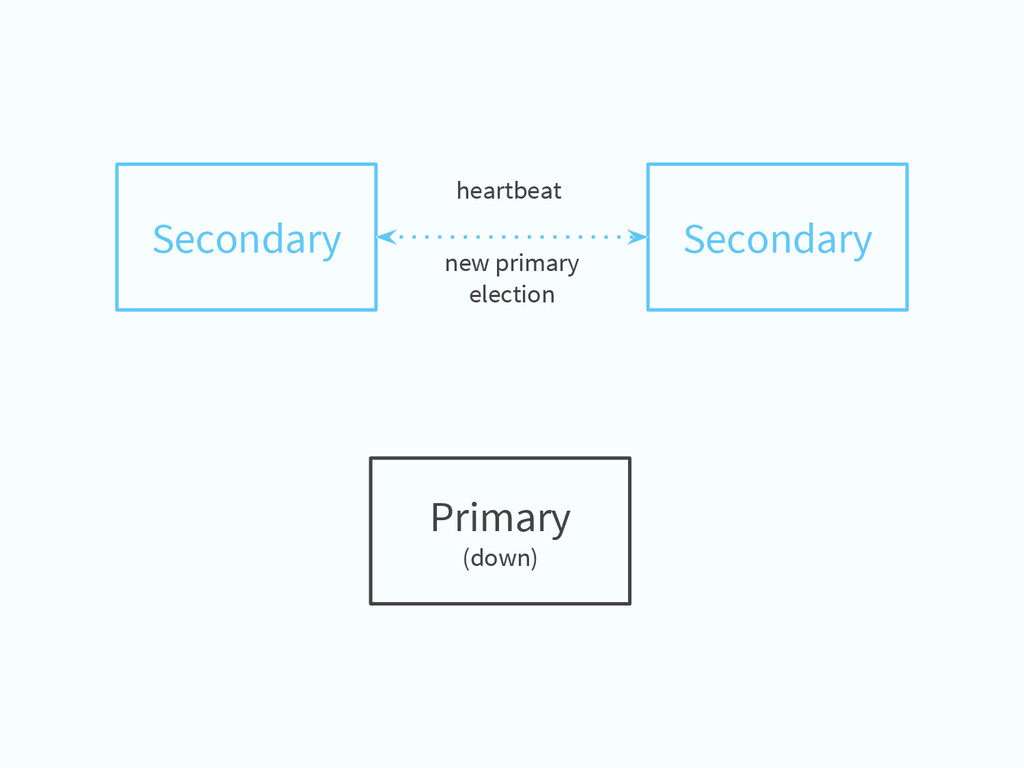{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}