Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
dbt運用の7つの疑問と対策
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Tatsuya Atsumi
December 14, 2021
Technology
2.2k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
dbt運用の7つの疑問と対策
dbt運用の7つの疑問と対策
Tatsuya Atsumi
December 14, 2021
More Decks by Tatsuya Atsumi
See All by Tatsuya Atsumi
builderscon2018 airflowを用いて、 複雑大規模なジョブフロー管理 に立ち向かう
attsun1031
1
2.6k
実践Play2+Kubernetes
attsun1031
0
230
Pythonで入門するApache Spark
attsun1031
1
320
Other Decks in Technology
See All in Technology
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
480
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
490
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
320
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
200
OPENLOGI Company Profile for engineer
hr01
1
75k
CloudWatchから始めるAWS監視
butadora
0
170
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
160
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
960
システム監視入門
grimoh
2
550
WEBフロントエンド研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
240
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
320
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
1.1k
Featured
See All Featured
HDC tutorial
michielstock
2
750
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Building AI with AI
inesmontani
PRO
1
1.1k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
The untapped power of vector embeddings
frankvandijk
2
1.8k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Chasing Engaging Ingredients in Design
codingconduct
0
240
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
Paper Plane
katiecoart
PRO
2
52k
Transcript
dbt 運用の7つの疑問と対策 2021 / 12 / 14
2 自己紹介 • 名前: Tatsuya Atsumi • Twitter: @__Attsun__ •
Job: Data Engineer • 最近の関心事 ◦ Data Discovery Tools ◦ 強靭で大きな組織をつくる ◦ 年末年始の予定
3 今日のテーマ dbt 便利ですよね! でも、 導入にあたって考えること・決めなきゃいけないこと たくさんありますよね・・。 今日は、Ubie Discovery での
dbt 導入と運用について、 どのような課題を持ち、 どのような解決策を講じたか、 QA 形式で発表します!
4 前提事項 • dbt cloud ではなく、OSS 版 dbt (0.21) を利用しています
• データソースには BigQuery を利用しています • dbt の基本的なことについては説明しません ◦ 気になる方は、bq sushi での資料を御覧ください • Ubie Discovery 個別の事例としてお聞きください
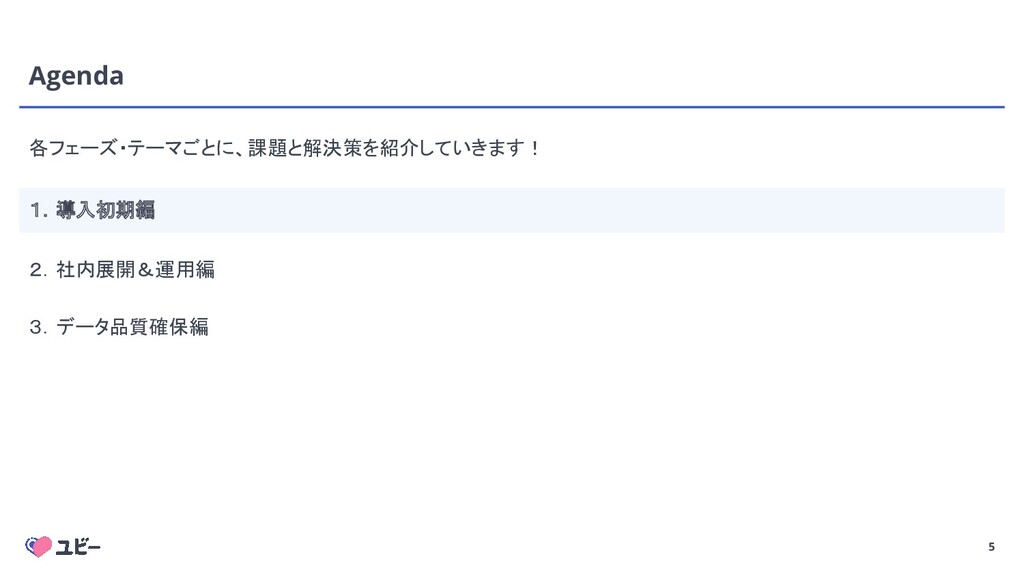
5 Agenda 1.導入初期編 2.社内展開&運用編 3.データ品質確保編 各フェーズ・テーマごとに、課題と解決策を紹介していきます!
6 Q. 初期のディレクトリ構成はどうしよう? `dbt init` で構築されるのは最低限の構成。多くのモデルを管理していくには、考えるべき余白が残されています。 • models ディレクトリ配下をどういう構成で管理すればいいのか? •
model name はどのようなルールにすれば? • 複数の schema (=bigquery dataset) はどう管理するか? • 複数の database (=gcp project) はどう管理するか? • etc…
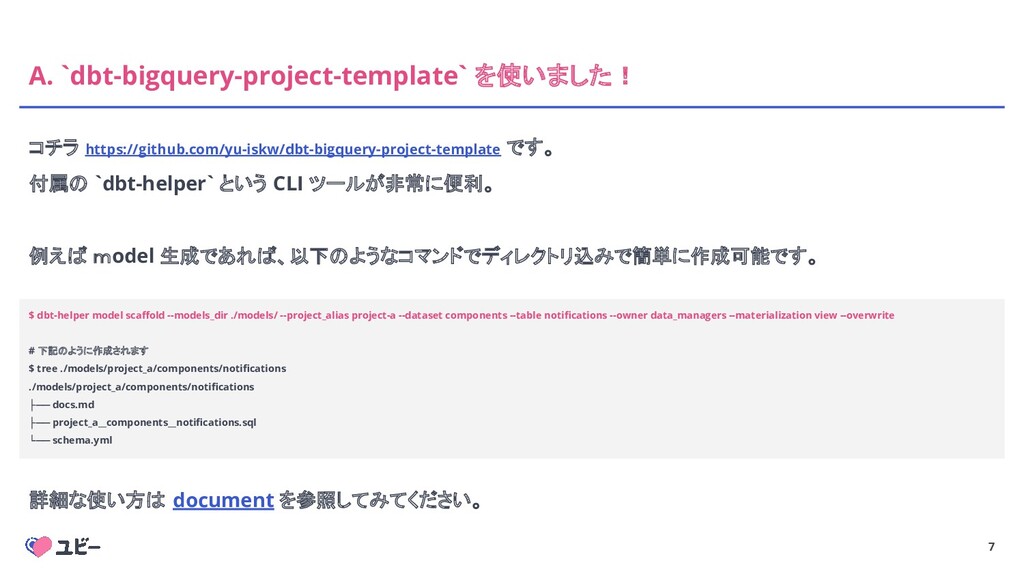
7 A. `dbt-bigquery-project-template` を使いました! コチラ https://github.com/yu-iskw/dbt-bigquery-project-template です。 付属の `dbt-helper` という
CLI ツールが非常に便利。 例えば model 生成であれば、以下のようなコマンドでディレクトリ込みで簡単に作成可能です。 $ dbt-helper model scaffold --models_dir ./models/ --project_alias project-a --dataset components --table notifications --owner data_managers --materialization view --overwrite # 下記のように作成されます $ tree ./models/project_a/components/notifications ./models/project_a/components/notifications ├── docs.md ├── project_a__components__notifications.sql └── schema.yml 詳細な使い方は document を参照してみてください。
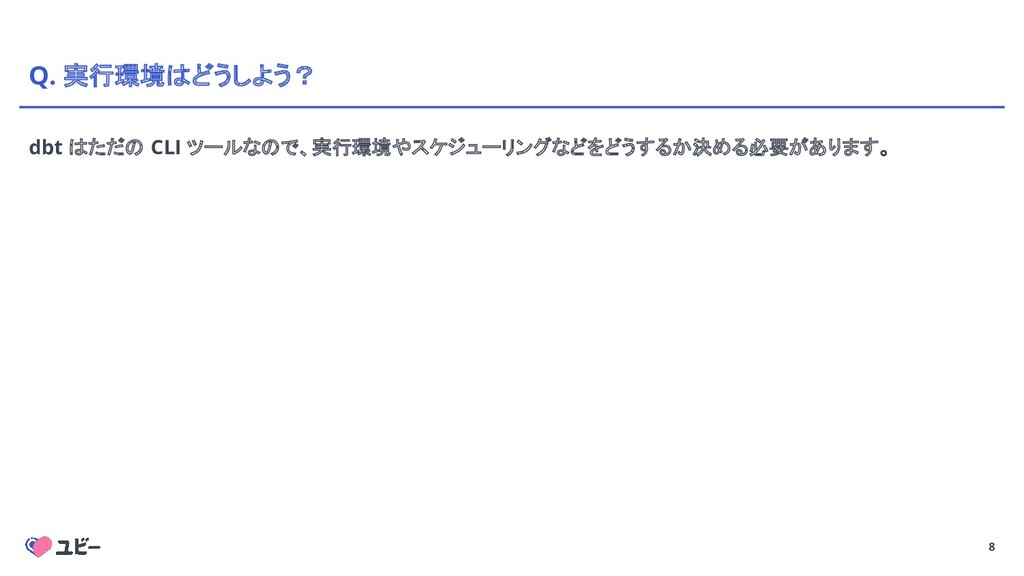
8 Q. 実行環境はどうしよう? dbt はただの CLI ツールなので、実行環境やスケジューリングなどをどうするか決める必要があります。
9 A. Cloud Composer を使っています! • 以前から Cloud Composer を運用していましたので、
DAG のひとつとして dbt を追加しました。 • `airflow-dbt` は利用せず、コンテナを自前でビルドして KubernetesOperator で動かしています。 ◦ シンプルなラッパーなので、自前のほうがやりたいことがストレートにできそう ◦ メンテの容易性を保つため、 Cloud Composer 環境に PyPI パッケージを直接入れたくない • 日次実行は tag と selector を利用して管理しています。 ◦ 毎日実行してほしい model に `daily` という tag をつける ◦ `tag:daily` を抜き出す selector を selectors.yml に定義 ◦ airflow では、 `--selector daily` を指定して実行
10 Q. dev / QA / production の環境分離はどうしよう? • project
を直接 model に記載してしまうと、環境ごとに model を用意することになってしまう • 「この model は production にしかない」という特殊ケースも存在
11 A. vars と tag を使って分離しています! プロジェクト名のエイリアスと実際のプロジェクト名のマッピングを環境ごとに用意します。 (model 名やディレクトリは、エイリアスの名前を使って作られています) $
cat vars/production/vars.yml projects: project-a: “project-a-production” project-b: “project-b-production” 下記のような selector を selectors.yml に定義します。 - name: daily-prod definition: intersection: - "tag:daily" - exclude: - 'tag:only_dev' - name: daily-dev definition: intersection: - "tag:daily" - exclude: - 'tag:only_prod'
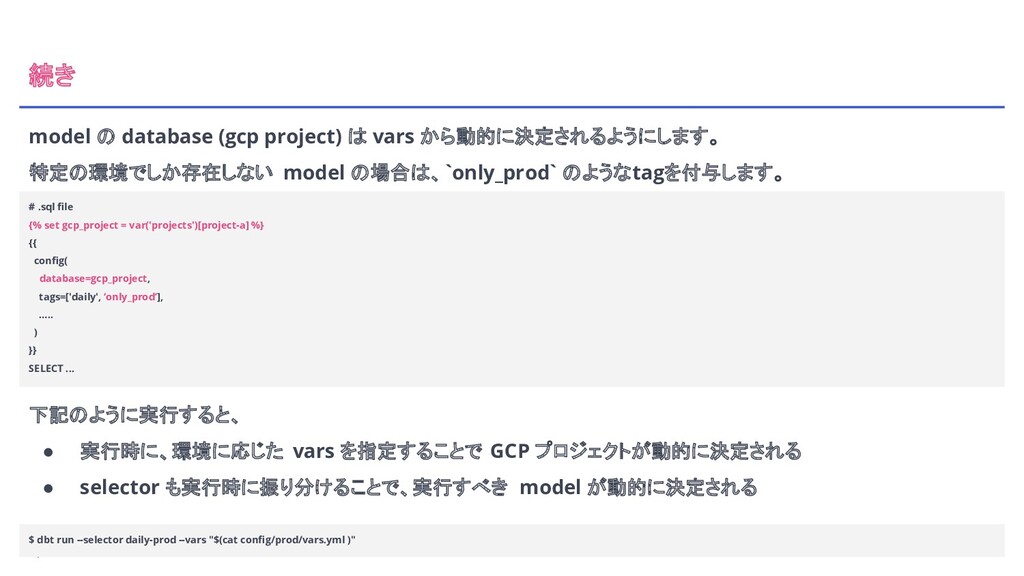
12 続き 下記のように実行すると、 • 実行時に、環境に応じた vars を指定することで GCP プロジェクトが動的に決定される •
selector も実行時に振り分けることで、実行すべき model が動的に決定される $ dbt run --selector daily-prod --vars "$(cat config/prod/vars.yml )" model の database (gcp project) は vars から動的に決定されるようにします。 特定の環境でしか存在しない model の場合は、`only_prod` のようなtagを付与します。 # .sql file {% set gcp_project = var('projects')[project-a] %} {{ config( database=gcp_project, tags=['daily', ‘only_prod’], ….. ) }} SELECT ...
13 導入編終わり これで、以下のような課題への対応ができました。 • ディレクトリ構成 • 実行環境 • 複数環境への対応 基本的には、最初に紹介した
dbt-bigquery-project-template を利用すれば、自然と紹介したような構成に行 き着きます。
14 Agenda 1.導入初期編 2.社内展開&運用編 3.データ品質確保編
15 Q. dbt modelはどのように設計すれば良い? dbt model が増えてくると、以下のような課題が出てきます。 • 巨大な SQL
• 命名ルール • model の粒度
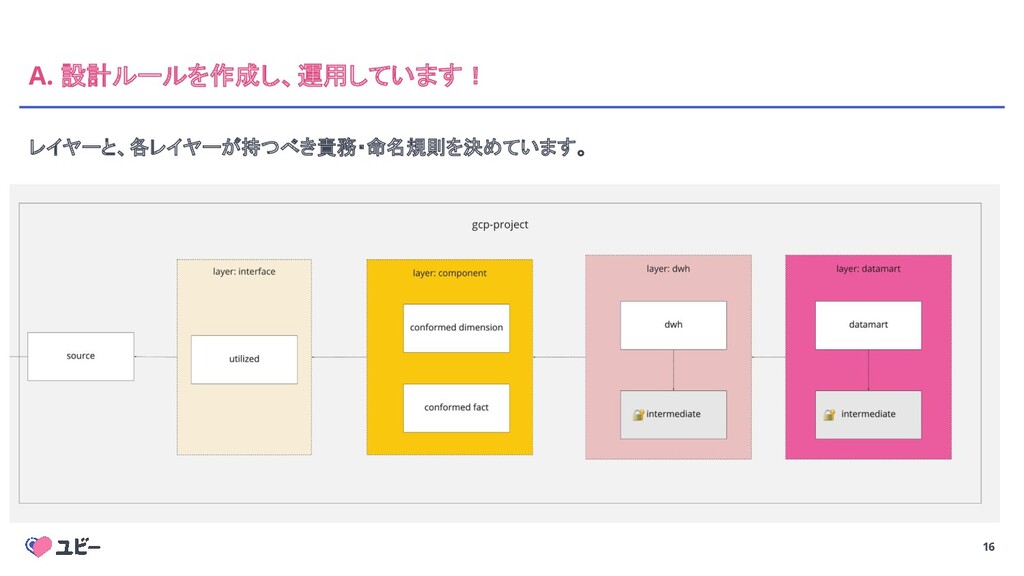
16 A. 設計ルールを作成し、運用しています! レイヤーと、各レイヤーが持つべき責務・命名規則を決めています。
17 各レイヤーの説明 • Interface layer ◦ ソースデータから、重複排除や不正データ除去などをした、「綺麗なソースデータ」 • Data Component
layer ◦ 再利用可能な、意味のあるデータのまとまり。 ◦ スタースキーマにおける dimension / fact に相当。 • DWH layer ◦ Data Component / Interface / Source を結合させたデータ。 • Datamart layer ◦ 特定のダッシュボードや分析用途に特化したデータ。 必ずしもすべてのレイヤーを作成しなければいけないわけではありません。
18 レイヤーを作るメリット • 命名と責務が一致し、利用者からどのようなデータか判別がしやすい • 再利用可能な部分とそうでない固有の部分を分離することができ、 SQL の再利用性が高まる • 巨大
SQL を適切なまとまりに分解することができ、利用者にもレビュアーにも優しい • 各レイヤーにテストを仕込むことで、どのレイヤーでデータが壊れたのかトラックしやすい レイヤーの分け方は事業や組織の状況によりかわりますが、一定のルールを作ることをオススメします。
19 Q. CI/CD はどうしよう? 開発を安定的に進めていくに当たり、以下のような課題がでてきます。 • 開発・レビュー・リリースの一連のフローをどう設計しよう? • 各ステップで必要な品質担保を行っていくには?
20 A. 以下のような形で CI/CD を進めています! ざっくりの流れ 1. ローカルで各自開発 2. github
で PR 3. QA リリース (github action) 4. 定期的 or adhoc に production リリース (github action)
21 ローカル開発 • 共通の sandbox GCP プロジェクトを用意します。 • 上記に対し、手元から自由に dbt
run を実行できるようにしています。 • 共通プロジェクトはバッティングの可能性があるので、今後は開発者ごとに独立した環境を用意したいと考え ています。
22 githubでPR PRに伴うCIとして、以下をチェックしています。 • dbt compileが実行可能か? • compile した SQL
を bq --dry-run してエラーがないか? • 変更した model を参照している model でも、bq --dry-run 可能か? • 各種lint ◦ bash script (shellcheck) ◦ yaml (yamllint) ◦ dockerfile (hadolint)
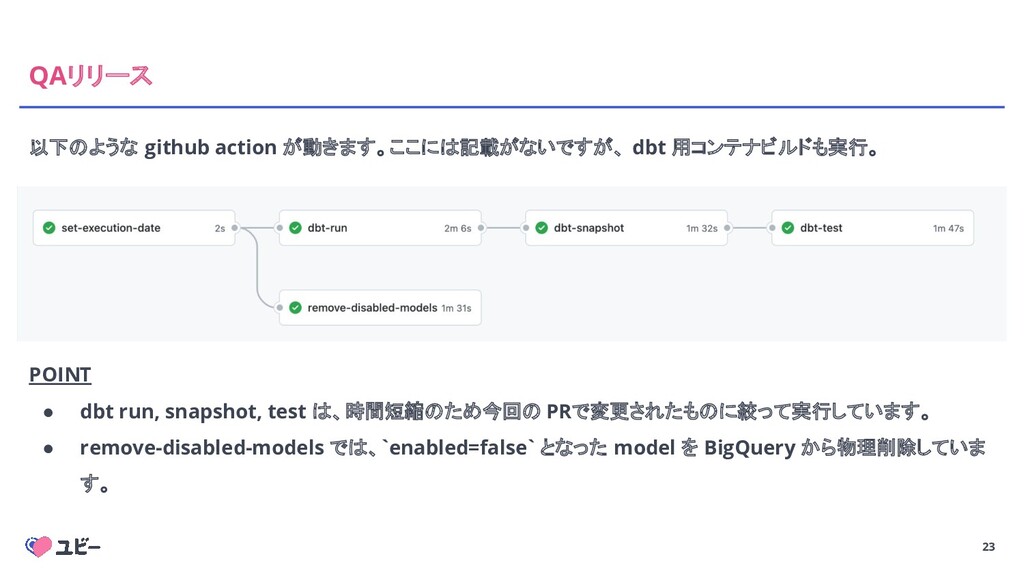
23 QAリリース 以下のような github action が動きます。ここには記載がないですが、 dbt 用コンテナビルドも実行。 POINT •
dbt run, snapshot, test は、時間短縮のため今回の PRで変更されたものに絞って実行しています。 • remove-disabled-models では、`enabled=false` となった model を BigQuery から物理削除していま す。
24 定期的 or adhoc に production リリース main ブランチとは別に stable
ブランチを用意し、 stable にマージされたら production にリリースされるように しています。 基本的には QA と同じ job が実行されますが、以下が production 特有です。 • dbt docs の更新をします(社内でサーブしている) • main -> stable へのマージ PR は、以下2つのタイミングで起動されます ◦ PR作成アクションを github 上から adhoc に実行(すぐリリースしたい場合) ◦ 毎日朝に自動実行( QA での確認事項は多くないので、できるだけ production には最新の model がデプロイされている状態にしたい) • reviewer は、差分に含まれる commit から自動でアサインされます。
25 Agenda 1.導入初期編 2.社内展開&運用編 3.データ品質確保編
26 Q. test, 標準の関数だけだと足りない・・ dbt test には以下のような関数が用意されています。 - not_null -
unique - accepted_values - relationships しかし、例えば「カラム AとBで unique 」などの複雑な条件は表現できません。
27 A. dbt_utils, dbt_expectations を利用しています。 dbt_utils • unique_combination_of_columns • expression_is_true
など。 “get_url_parameter” など、 test 以外でも利用可能な便利関数もあります。
28 A. dbt_utils, dbt_expectations を利用しています。 dbt_expectations • expect_table_row_count_to_be_between • expect_column_value_lengths_to_be_between
など。 dbt_utils よりも、より複雑な条件をサポートしています。 その他 • data test は使っていません(あえて避けているわけではないですが) • testのwhere config が便利です。(v0.20.0以降)
29 Q. test を書いた!どうやって監視しよう? dbt test の結果は標準エラーとして出力されますが、以下のような問題があります。 1. 何が失敗しているかをどう簡単に見つけるか? model
数が多くなると log から目 grep はキツイ・・ 2. 失敗したテストの推移は?今日はじめて失敗したのか、毎日失敗し続けているテストなのか。
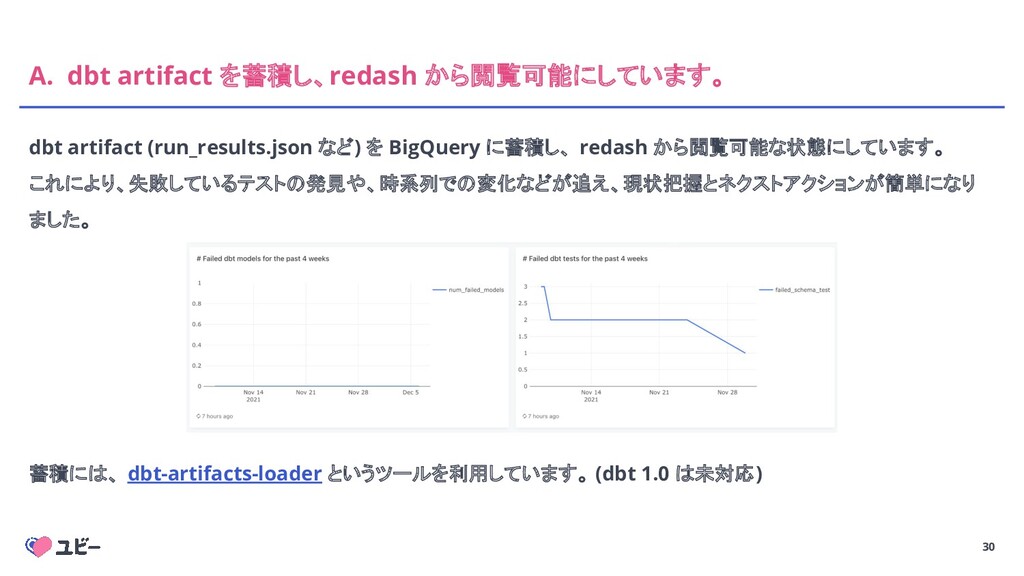
30 A. dbt artifact を蓄積し、redash から閲覧可能にしています。 dbt artifact (run_results.json など)
を BigQuery に蓄積し、 redash から閲覧可能な状態にしています。 これにより、失敗しているテストの発見や、時系列での変化などが追え、現状把握とネクストアクションが簡単になり ました。 蓄積には、 dbt-artifacts-loader というツールを利用しています。 (dbt 1.0 は未対応)
31 Next Action の判断など さきほどのダッシュボードを各事業のデータ担当とデータ基盤担当で定期的に眺め、 • 失敗しているテストの概要の把握 • テスト失敗の緊急性の判断 •
テスト失敗の調査・修正の方針 を話しています。 緊急性の判断については、今後は仕組みとしてもうまく把握できるような状況にしていきたい。
32 まとめ dbt 導入には、導入者自身が決め、解決していかなければいけないことが多くありました。 課題に対して随時解決策を講じていくことで、徐々に安定した開発・運用フローができてきました。
33 最後に宣伝を2つほど・・
34 Q. Ubie Discovery 以外にも、他の会社さんがどうしてるかも気になります A. 12/21に行われる dbt 座談会に是非ご参加ください! ご興味ある方は、
こちらのリンク に記載のslackにご参加ください!
35 Q. Ubie Discovery のデータ活用・データ基盤・事業について詳しく知りたい! A. データチーム紹介資料 を御覧ください!→→→→→→→ 募集中JDはコチラ •
Data Engineer • ML Engineer • Data Analyst • [New!] Analytics Engineer ◦ JD準備中。公開作業できてないだけなので、興味ある方は聞いてみてください ◦ dbt等で安心安全データマートを作っていく人です!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}