Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
builderscon2018 airflowを用いて、 複雑大規模なジョブフロー管理 に...
Search
Tatsuya Atsumi
September 07, 2018
Technology
2.6k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
builderscon2018 airflowを用いて、 複雑大規模なジョブフロー管理 に立ち向かう
builderscon2018で発表した資料。
Tatsuya Atsumi
September 07, 2018
More Decks by Tatsuya Atsumi
See All by Tatsuya Atsumi
dbt運用の7つの疑問と対策
attsun1031
3
2.2k
実践Play2+Kubernetes
attsun1031
0
230
Pythonで入門するApache Spark
attsun1031
1
320
Other Decks in Technology
See All in Technology
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
830
AI驚き屋発見器
yama3133
1
260
文字起こし基盤の信頼性
abnoumaru
0
130
Git 研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
280
AI時代こそ、スケールしないことをしよう -「作る人」から「なぜ作るか」を考える人へ / Do Things That Don't Scale in the AI Era — From How to Why
kaminashi
1
140
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
480
コンテナ・K8s研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
160
Jitera Company Deck
jitera
0
550
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
150
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.5k
発表と総括 / Presentations and Summary
ks91
PRO
0
210
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
2
610
Featured
See All Featured
WENDY [Excerpt]
tessaabrams
11
39k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Accessibility Awareness
sabderemane
1
160
How STYLIGHT went responsive
nonsquared
100
6.2k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
420
Code Reviewing Like a Champion
maltzj
528
40k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Transcript
airflowを用いて、 複雑大規模なジョブフロー管理 に立ち向かう builderscon 2018
• 渥美 達也 と申します • ブレインパッドの自社サービス開発部署のVP of Engineering • VPoEのかたわら、サービス開発もやってます。 •
Python, k8s, GCP, ボルダリングあたりが好きです。 自己紹介 最近話題のブレインパッドってデータサイエンスの堅い会社なの? 本イベントに合わせて、builderscon運営さん に素敵なインタビュー記事を作っていただき ました!
アジェンダ 1. airflowの簡単な紹介 2. airflowを導入したプロダクトについて 3. airflow導入以前の課題 4. airflowの導入 5.
規模拡大への対処 6. 運用TIPS
airflowの簡単な紹介
airflowって? “Airflow is a platform to programmatically author, schedule and
monitor workflows.” 公式ドキュメントから抜粋 ざっくり言ってしまうと、 ワークフローを管理するためのソフトウェア。
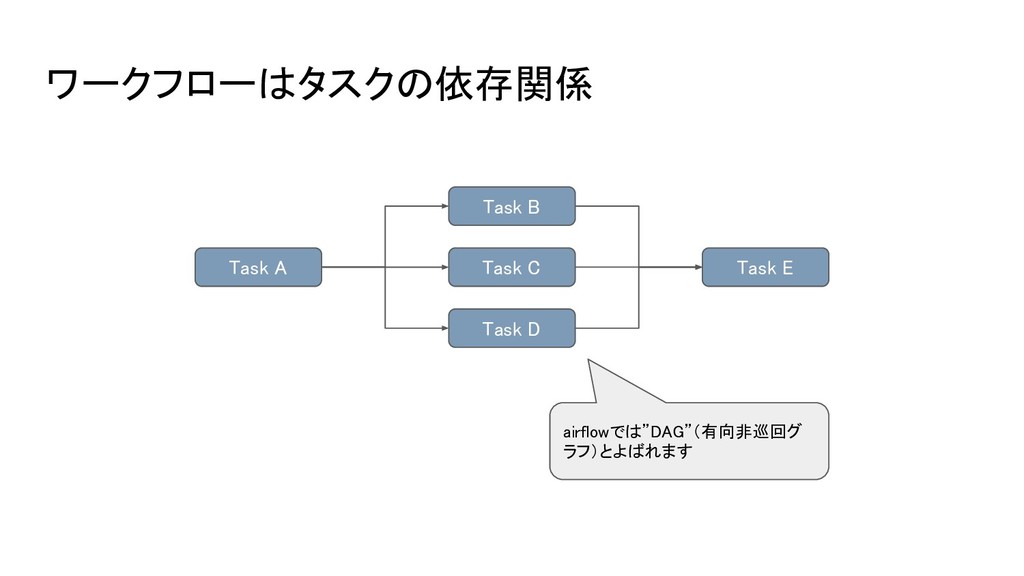
ワークフローはタスクの依存関係 Task A Task B Task C Task D Task
E airflowでは”DAG”(有向非巡回グ ラフ)とよばれます
airflowは、ワークフローを実行・管理する 例えばこんなことができます • Pythonによるワークフローの実装 • スケジュール実行 • 実行履歴の可視化 • 自動・手動リトライ
• 並列処理
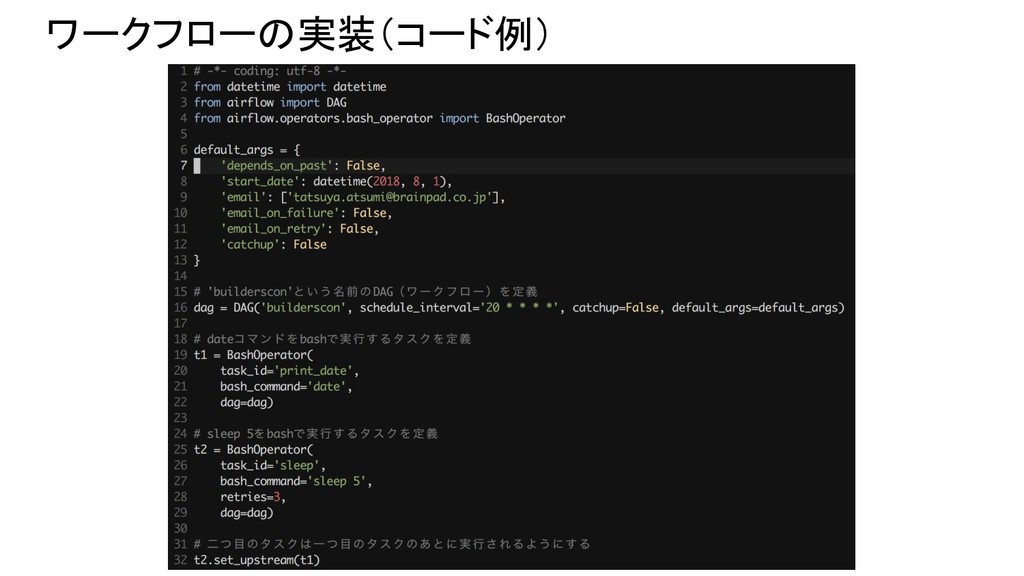
ワークフローの実装方法 airflowのPythonライブラリを利用します。主にDAGクラスとOperatorクラス(のサブクラ ス)を利用します。 DAG Operator Operator Operator ワークフローを表現するクラス。 オペレータ間の依存関係やスケジュールな どを持っている。
タスクそのものを表現するクラス。 BashOperatorやPythonOperatorなど様々な ものがある。
ワークフローの実装(コード例)
豊富なオペレータ • BashOperator ◦ Bashスクリプトを実行する • PythonOperator ◦ Pythonコードを実行する •
BranchPythonOperator ◦ Pythonでの条件式に基づき、どのOperatorを次に実行するか判定する • その他、 ◦ DockerOperator, BigQueryOperator, SlackAPIOperatorのような外部との連携も ◦ 既存のOperatorを継承した自前実装も結構簡単です。 ▪ 私たちもBranchPythonOperatorを拡張した実装を一部使っています。
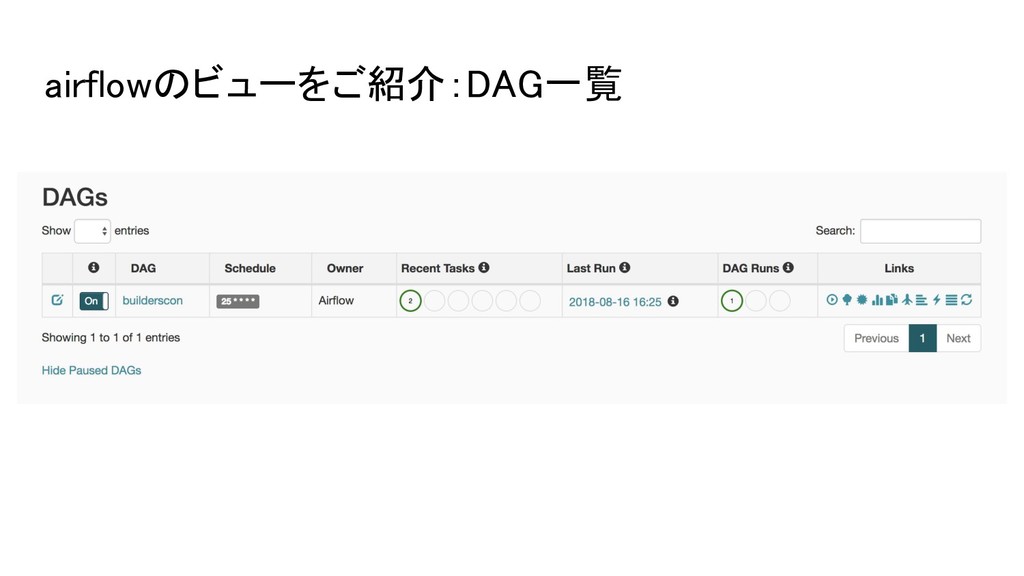
airflowのビューをご紹介:DAG一覧
airflowのビューをご紹介:グラフビュー
airflowの実行モードとスケーラビリティ airflowでは、Executorというクラスの実装を切り替えることで環境に応じた実行モードを 切り替えます。 • SequentialExecutor ◦ 一番単純な実行モード。タスクを直列にしか実行できない。 ◦ お試し用という位置付け。 •
CeleryExecutor ◦ RabbitMQなどのキューを利用した実行モードで、スケジューラとワーカーが分離される ◦ ワーカーを並列実行でき、サーバー増設によるスケールも簡単になるため、本番環境での利用に 向いている。
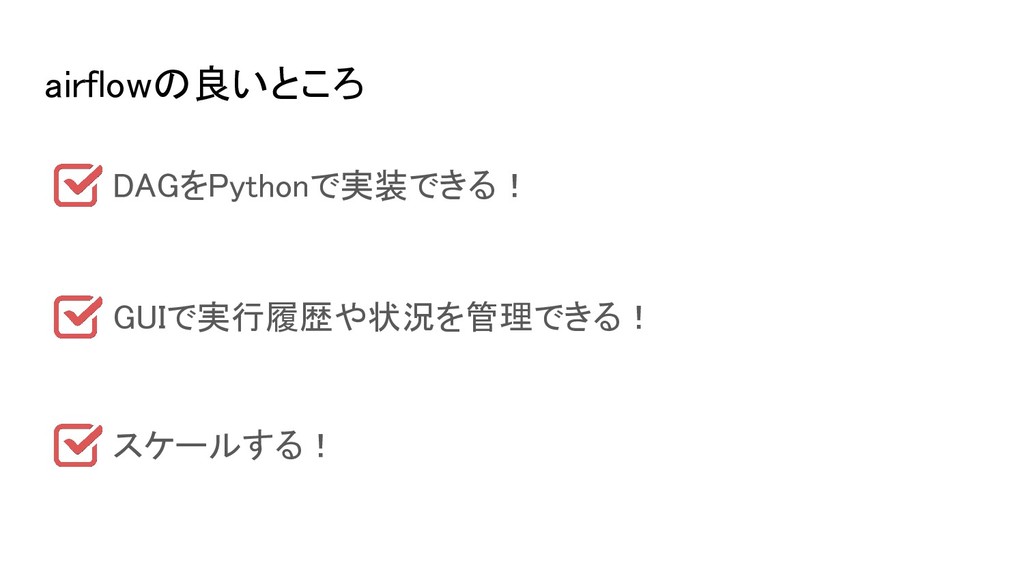
airflowの良いところ DAGをPythonで実装できる! GUIで実行履歴や状況を管理できる! スケールする!
次のセクションに行く前に・・・ ここで紹介した機能やビューは本当に一部のものです。 airflowにはたくさんの機能がありますので、 ぜひドキュメントをご一読ください!
導入プロダクトについて
airflowを使っているプロダクト レコメンドエンジン搭載プライベートDMP Rtoaster(アール・トースター) 今年13年目を迎え、導入250社を超える大規模自社サービス!
Rtoasterとは • 「レコメンドエンジン搭載プライベートDMP」 • ECサイトなどに導入することで、訪問ユーザーの行動ログをはじめとした、多様な データを蓄積します • 蓄積した行動ログをもとに、様々なアクションが行えます ◦ 訪問ユーザーの嗜好に応じたレコメンド(オススメ的な)
◦ ユーザーのセグメンテーション(グループ分け) ◦ などなどなど・・
Rtoasterのシステム的特徴 • 100億件を超える大量のログデータ • 単純な集計処理から、機械学習処理まで様々なタスク • クライアントごとの独立性 ◦ 契約クライアントごとに集計などのデータ処理は独立している ◦
あるクライアントのトラブルが他のクライアントに影響を与えてはいけない このようなシステムではオンラインでのビッグデータ処理だけではなく、 オフライン(バッチ処理)で大量のワークフローが日夜実行される
Rtoasterシステムについて補足 Rtoasterは非常に巨大なプロダクトなのですが、 実態は複数の疎結合なサブシステムが連動することで成り立っています。 airflowは、その一部のサブシステムにのみ導入しました。 そのサブシステムは当初別プロダクトとして細々と展開されていましたが、今年はじめに Rtoasterのサブシステムとして正式に統合されました。
airflow導入サブシステムの歴史 2014年 β版リリース(私はリリース後に入社) 2015年 GA版リリース 2016年 airflowを導入 2018年 Rtoasterへの正式統合に伴う規模の大幅な拡大
airflow導入以前の課題
β版リリース時のワークフロー ログロードタスク (クライアントA) データ転送タスク (クライアントA) cron ログロードタスク (クライアントB) データ転送タスク (クライアントB)
• タスク間の依存関係はなかった • クライアントごとにタスク実行 • cron設定行数は、2 * クライアント数となる • クライアント追加ごとにcron設定が必要 • 通知はメール • 当時は処理も単純でクライアント数も非常に少な かったので特に問題なかった
GA版リリース時のワークフロー ログロードタスク (クライアントA) データ転送タスク (クライアントA) cron ログロードタスク (クライアントB) データ転送タスク (クライアントB)
• ログロードタスクと集計タスクの間には依存関係があ り、ログロードが終わらないと集計が実行できない ◦ つまり、ワークフロー • 上記のような問題にcron時間調整による職人芸で対 処していた ◦ 例えば「ログロードがAM 4:00起動で10分くらい で終わるから、集計タスクはAM 4:20の起動」 ◦ これをクライアントごとにやる・・! • GAと言いつつも積極展開していなかったので運用ダ メージは浅めだった 集計タスク (クライアントA) 集計タスク (クライアントB) 暗黙の関連 暗黙の関連
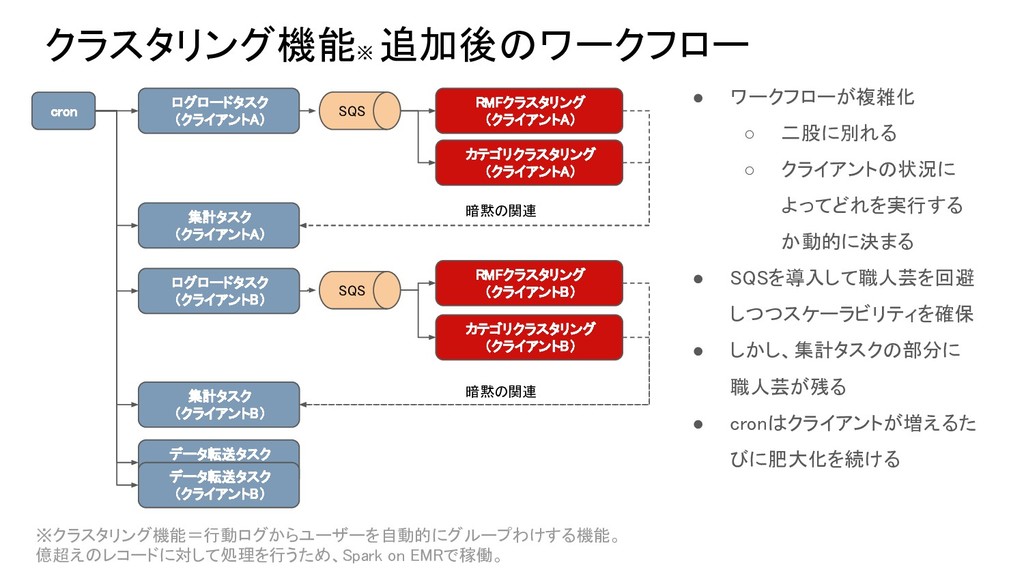
クラスタリング機能※ 追加後のワークフロー ログロードタスク (クライアントA) データ転送タスク (クライアントA) cron ログロードタスク (クライアントB) データ転送タスク
(クライアントB) 集計タスク (クライアントA) 集計タスク (クライアントB) 暗黙の関連 RMFクラスタリング (クライアントA) カテゴリクラスタリング (クライアントA) SQS 暗黙の関連 RMFクラスタリング (クライアントB) カテゴリクラスタリング (クライアントB) SQS • ワークフローが複雑化 ◦ 二股に別れる ◦ クライアントの状況に よってどれを実行する か動的に決まる • SQSを導入して職人芸を回避 しつつスケーラビリティを確保 • しかし、集計タスクの部分に 職人芸が残る • cronはクライアントが増えるた びに肥大化を続ける ※クラスタリング機能=行動ログからユーザーを自動的にグループわけする機能。 億超えのレコードに対して処理を行うため、Spark on EMRで稼働。
さすがに辛くなってきた クライアント増加にともなうcron設定の肥大化 ワークフローの複雑化 タスクの失敗も増え、リランがツラい 現在・過去の状況もログやメールから追うしかない ワークフローの複雑化とクライアントの増加に伴い、運用負荷が拡大していた
airflowの導入
なんとかしないと、ということで対策 主に検討したのは以下 Amazon SWF(Simple Workflow) Azkaban awsサービスの一つ。弊社では他サービスでかなりヘビーに利用している。あまり利用者は多くない気がする。 元はLinkedInで開発されていたOSS。適度に枯れていそうな印象。採用事例をちらほら見かける。 Airflow 元はAirbnbで開発されていたOSS。事例があまりなく、枯れていない印象。
ちなみに、digdagも現在なら選択肢 に上がると思うが、当時はまだな かった。
• 運用のしやすさ ◦ GUIでの実行管理やリランの仕組み ◦ エラー発生時・規定実行時間をオーバーしたときの通知 ◦ 現状のチームで管理できる • きめ細かい制御
◦ 複雑なワークフローの記述 ▪ 並列実行, 条件分岐, タスク間での値の受け渡し、動的なワークフロー生成など ◦ 細かい実行制御 ▪ ワークフローごと・タスクごと・キューごとの同時実行数制限など • 特定の種類のタスクや、特定のクライアントのタスクが他のタスクをブロックしてしまう のは極力避けたい • スケーラビリティ 選定の観点
比較 SWF Azkaban Airflow 運用のしやすさ 管理画面は必要最低限で、使い勝手もイマ イチ・・。 タスク間の関係を制御をするのは完全に実 装側の責任。 管理画面はワークフローの可視化や再実
行の仕組みなどあり使いやすそう。 様々な観点でのワークフロー可視化やリラ ンなど、管理画面が使いやすそう。 きめ細かい制御 制御するのは実装側なので、いかようにも 可能。 条件分岐や動的なワークフロー生成がな かった。 並列性の制御はexecutor(ワーカー)ごと のみ。 条件分岐など複雑なケースに対応。 並列性制御もワーカーごとだけでなく、Pool の仕組みを使ったきめ細かい制御が可能。 スケーラビリティ 問題なくスケールする。 複数ワーカーの実行をサポートしているの で大丈夫そう。バックエンドのDBが気にな るが・・。 複数ワーカーの実行をサポートしているので 大丈夫そう。バックエンドのDBが気になるが ・・。 所感 運用の経験から、やりたいことはだいたいで きるしスケールもするが、実装も運用も結構 ツラい。 シンプルなケースには最も向いていそうだ が、今回の要件には機能不足感は否めな い。 管理が簡単そうな他、複雑なケースにも対 処できそう。 ジョブ定義がPythonというのも良い。 airflowは我々の要件を満たしてくれそうと感じた! ※2015〜2016年時点での比較であることにご注意ください。
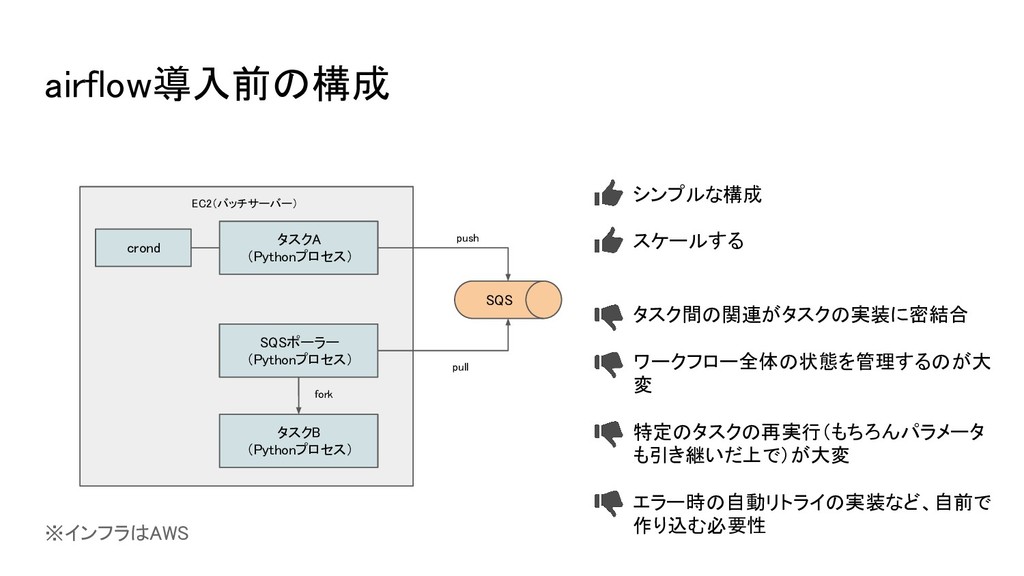
airflow導入前の構成 EC2(バッチサーバー) crond タスクA (Pythonプロセス) SQS タスクB (Pythonプロセス) SQSポーラー (Pythonプロセス)
push pull fork ※インフラはAWS シンプルな構成 スケールする タスク間の関連がタスクの実装に密結合 ワークフロー全体の状態を管理するのが大 変 特定のタスクの再実行(もちろんパラメータ も引き継いだ上で)が大変 エラー時の自動リトライの実装など、自前で 作り込む必要性
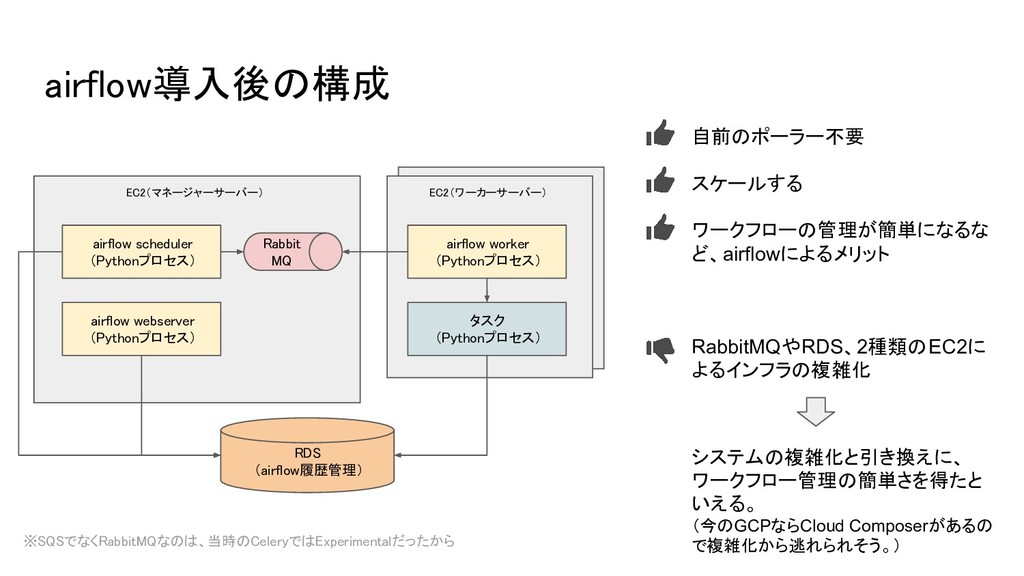
ワーカーサーバー airflow導入後の構成 EC2(マネージャーサーバー) airflow scheduler (Pythonプロセス) airflow webserver (Pythonプロセス) EC2(ワーカーサーバー)
airflow worker (Pythonプロセス) タスク (Pythonプロセス) RDS (airflow履歴管理) Rabbit MQ 自前のポーラー不要 スケールする ワークフローの管理が簡単になるな ど、airflowによるメリット RabbitMQやRDS、2種類のEC2に よるインフラの複雑化 システムの複雑化と引き換えに、 ワークフロー管理の簡単さを得たと いえる。 (今のGCPならCloud Composerがあるの で複雑化から逃れられそう。) ※SQSでなくRabbitMQなのは、当時のCeleryではExperimentalだったから
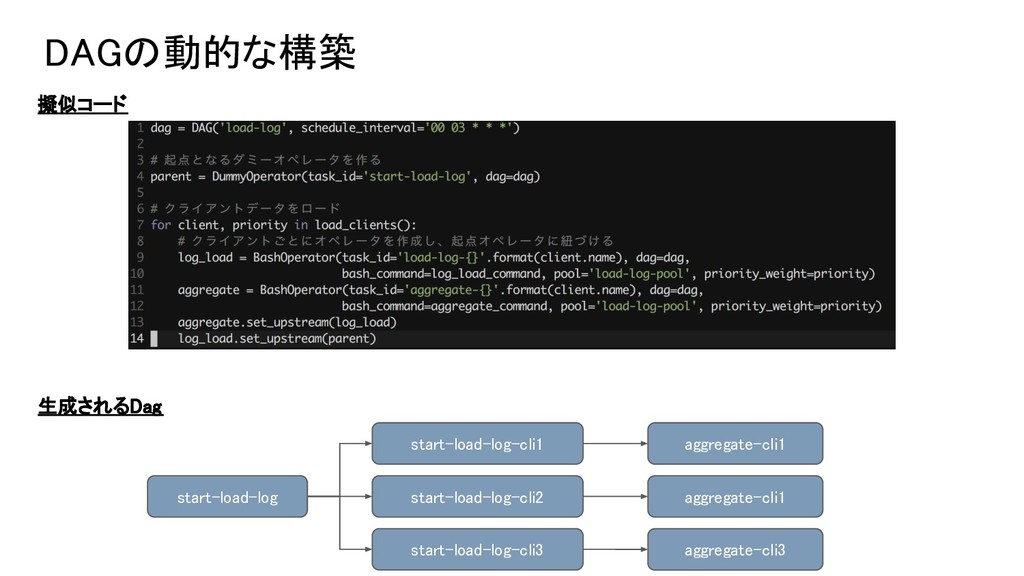
DAGの動的な構築を活用 クライアント増加 -> cron設定を追加する というオペレーションは、動的なDAG生成により回避した。 DAG構築時に、DBから顧客マスタをロードしてタスクを動的に構築する。
DAGの動的な構築 擬似コード 生成されるDag start-load-log start-load-log-cli1 start-load-log-cli2 start-load-log-cli3 aggregate-cli1 aggregate-cli1 aggregate-cli3
airflowを導入してみて • 自前でやっていた依存関係管理は全部airflowにお任せできた • ビューも見やすいので何かあっても状況確認が超簡単になった • インフラが複雑化した面は否めないが、それ以上のメリットがもたらされた • 検証・導入当時はバグを踏むことも何度かあった ◦
PR出せばすぐチェックしてマージしてくれた • 思った以上に安定稼働した • airflow特有のクセに慣れる必要もあった 全体的には、運用が楽になり導入してよかったと感じられた
規模の拡大
Rtoasterへの統合 ついにRtoasterに統合される計画が始動。 つまり、 クライアントとデータの爆発的増加を意味する・・!! 大丈夫なのか??
どのくらい規模拡大したのか? クライアント数 65 938 (x 14) ジョブ実行数(1日) 9,042 (x 8)
1,120
乗り切るためにインフラ増強 airflow manager airflow worker t2.small x 1 c4.xlarge x
1 c4.large x 1 c4.2xlarge x 4 RDS t2.small x 1 t2.small x 1 ※アプリとairflowデータ共存 ※airflow専用インスタンスを新たに構築
思ったより大丈夫だったという結論 • インフラ増強+同時実行数制限を大きくするといったパラメータチューニング程度で 乗り切れた! ◦ 同時実行数制限のお話は「運用TIPS」を参照(多分時間切れになっている) • 特に事故らしい事故もなかった! • 仮にairflow導入前のアーキテクチャで規模拡大がやってきたら、地獄が待っていた
に違いない(震え) ◦ 大きなリスクには早めの対処を!
運用のTIPSや困った点など
タスクの同時実行数制御について airflowには同時実行数を制御できる設定値がたくさんある。 • タスクの同時実行数(dag_concurrency) • ワークフロー種類ごとの同時実行数(max_active_runs_per_dag) • airflow workerごとの同時実行数(celeryd_concurrency) •
Pool(後述) 他にもあったかも・・・
Poolについて Operator A pool=”p-1” priority=1 Operator B pool=”p-1” priority=2 Operator
C pool=”p-2” priority=1 Pool: p-1 slot=1 Pool: p-2 slot=2 Operator A-1 Operator B-1 Operator C-1 オペレータ(タスク)ごとに、所属するプール名と優 先度を定義する スケジュールされるオペレータの数がPoolのスロットを超 える場合、同じプールに属するものは優先度順に実行さ れる。 この場合、Operator A-1、B-1がPool p-1に属しているが、 p-1のslotは1なので、優先度が劣るOperator A-1はB-1が 終わるまで待機となる。 Operator C-2 Pool: p-1 slot=1 Pool: p-2 slot=2 プールを定義する。slotは、そのプールの容量= 並列度
同時実行数制御のポリシー • Poolを使う ◦ 特定のタスクのまとまりごとに同じプールを使うことで、特定のタスクがワーカーを占拠してしまうこ とによるタスク全体の目詰まりを防ぐ。 ◦ 各クライアントの契約状況等に基づいて優先度を設定する • それ以外の設定は、基本的にはサーバーインフラに応じて大きめに設定する
◦ 極力シンプルにしておきたい ◦ 基本的にはPoolで制御されてしまう
ワークフロー(DAG)の実装について • オペレータはクライアントごとに個別かつ並列に実行したい。 ◦ あるクライアントの処理が別のクライアントの処理をブロックしてほしくない ◦ 一部のクライアントの処理だけ失敗した場合、そこだけに影響範囲を絞りつつ、リトライもしたい ◦ クライアントが増えたり減ったりするたびに運用が発生して欲しくない =>
DAG定義ファイルの中で、DBからクライアントデータをロードして動的にDAGオブジェ クトを構築する
バックフィルの挙動が厄介 • 例えばデイリーで動くワークフローがあったとして、そのワークフローを8/1〜8/3まで停止したとする (airflowの機能でスケジュールを停止できる) • 8/4に再開すると、8/1, 8/2, 8/3の動かなかった分のワークフローが動き出す • 再開するたびに動く必要のない過去分が全部動くのはかなり邪魔臭かったので、タスクを再度起動する
場合はstart_dateパラメータを昨日など直近に更新してから再起動する運用が必要。 • 本番環境でタスクを停止することはほぼないので良いが、テスト環境ではよくあるので面倒だった。。 • 1.8からcatchupパラメータが追加され、Falseにすればバックフィルを無効にできるようになった!
タスクのスケジュール日時がわかりにくい • airflowでは、一つ前の日時のタスクをスケジューリングする。 • 例えば毎日10時に起動されるタスクがあるとして、8/10の10時に起動されるタスク の日時は8/9の10時となる。 ◦ {{ ds }}パラメータから取得できる値も”2018-08-09”となる・・!
◦ オペレータの実装では気をつける必要がある。
まとめ
まとめ:airflowに対する印象 • 複雑なユースケースや実行制御なども可能で、やりたいことはだいたいできそう • 設定が多いので、それなりのキャッチアップが必要 • ツールとしてのクセがやはりあるので、慣れが必要 • Python使いにはオススメ •
GCPがCloud Composerとしてマネージドairflowをサポートしだしたのはアツい ◦ 自前で色々用意しなくても導入がとても簡単に ◦ 開発が多分活発化する
We’re HIRING !!! ブレインパッドは、 ビッグデータとテクノロジーを駆使して、 “データ活用技術”を極めたいエンジニアを大募集中です!!
ご静聴ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}