is a fast and general-purpose cluster computing system. つまり、「⾼速」と「多⽬的」を特徴とした分散処理システム。 n 複数台のサーバを使って、⼤量のデータを⾼速に処理できる。 n タスクのスケジューリングや障害発⽣時の復旧のような分散処理にまつわる⾯倒 な点はSparkがカバーしてくれる。 n MapReduceで⾏われていたようなログ集計から、レコメンドシステム、リアル タイム処理まで幅広い⽤途で使われている。 6 Sparkとは
本を買ってみましょう。 n GraphXやSpark Streamingなど、今回触れなかったライブラリについて調べて みましょう。 n DriverやExecutorといった実⾏モデルについて調べてみましょう。 n Shuffle処理について調べてみましょう。 – パフォーマンス改善の勘所の⼀つ 37 さらに知りたい⽅へ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
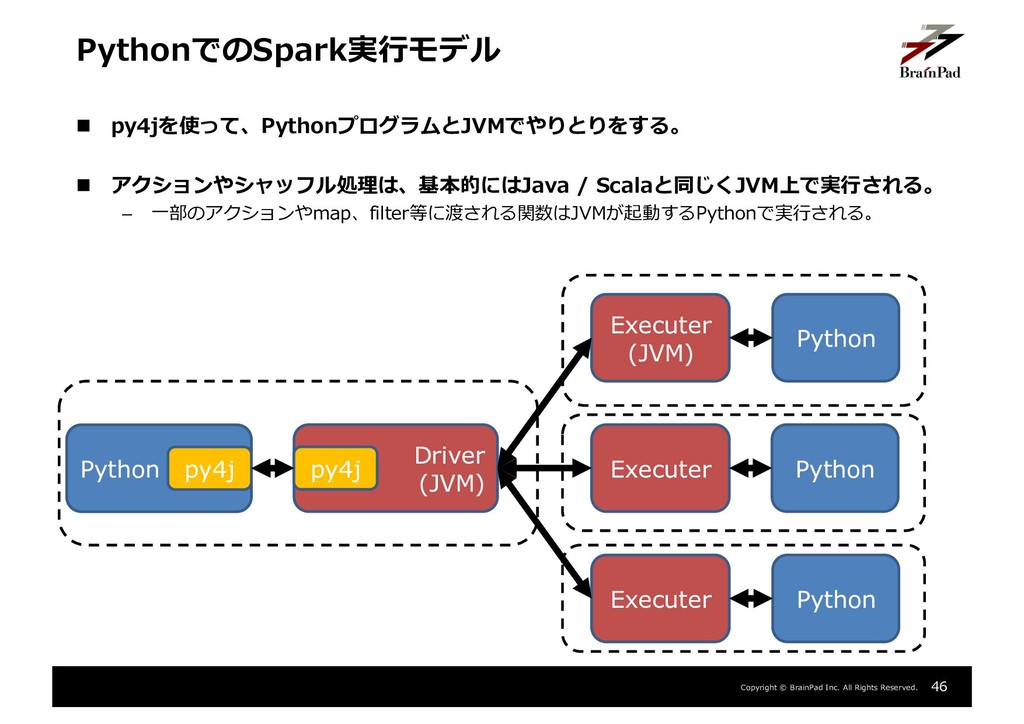{kind=link}