Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Vision Transformer 入門 2章
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Takuya Mouri
October 23, 2023
170
1
Share
Vision Transformer 入門 2章
Takuya Mouri
October 23, 2023
Featured
See All Featured
RailsConf 2023
tenderlove
30
1.4k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
160
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
1
1.5k
Thoughts on Productivity
jonyablonski
75
5.1k
BBQ
matthewcrist
89
10k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.4k
Utilizing Notion as your number one productivity tool
mfonobong
4
280
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.2k
Believing is Seeing
oripsolob
1
99
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
210
A Tale of Four Properties
chriscoyier
163
24k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Transcript
画像エンジニアのための ゼロから始めるVision Transformer 1
AIスタートアップでテーブルデータを使った機械学習システムの構築を支援 6月にLightGBMの本を執筆 自己紹介:毛利拓也 2
Vision Transformer入門の 2章「Vision Transformerの基礎と実装」を理解 本勉強会のスコープ 3
Vision Transformer は MLPの応用、MLPとViTのギャップを埋めたい MLP(Multilayer perceptron)は 名著「ゼロから作るDeep Learning」を参照 モチベーション 4
ゼロから作るDeep Learning より引用
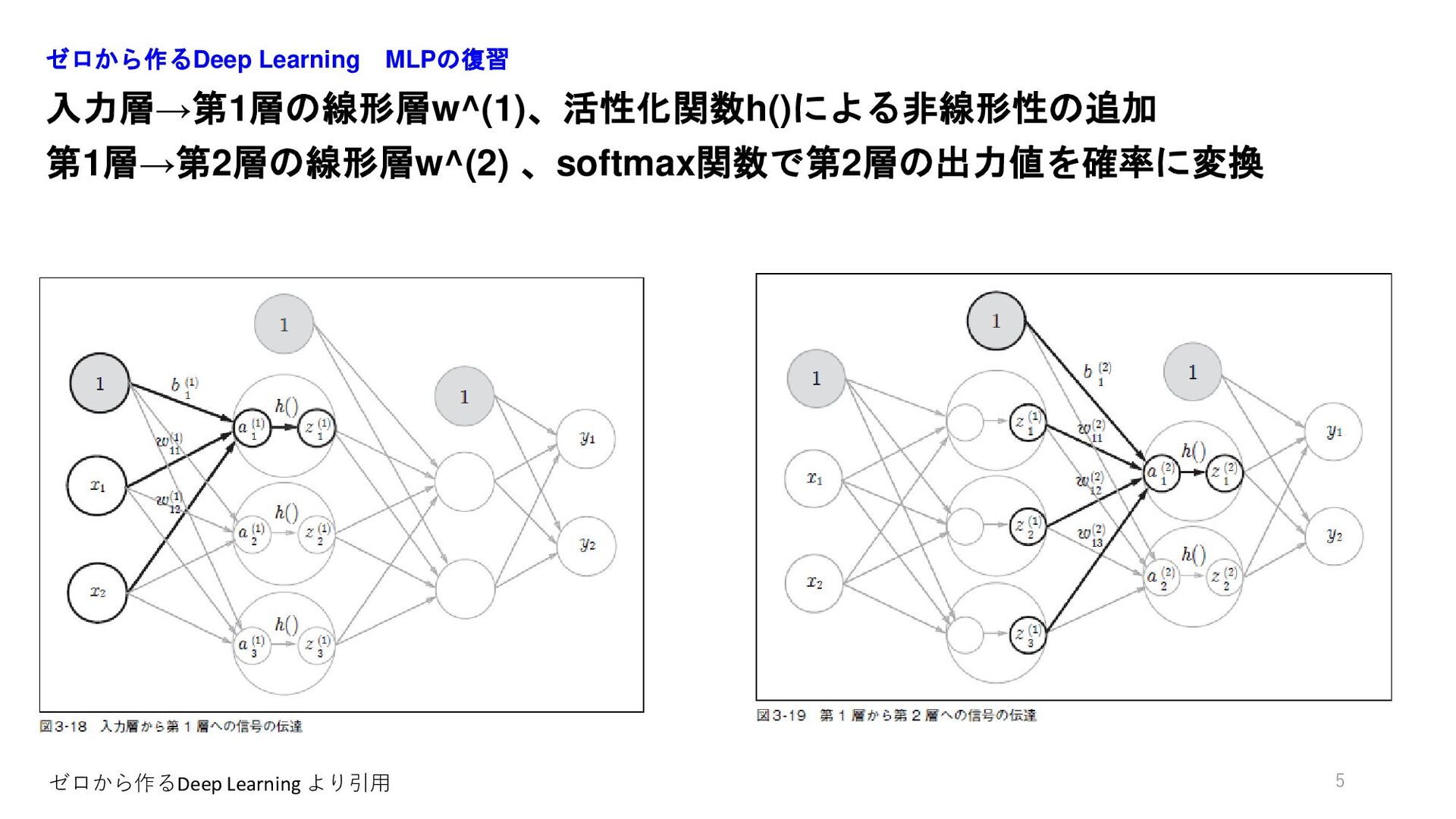
入力層→第1層の線形層w^(1)、活性化関数h()による非線形性の追加 第1層→第2層の線形層w^(2) 、softmax関数で第2層の出力値を確率に変換 ゼロから作るDeep Learning MLPの復習 5 ゼロから作るDeep Learning より引用
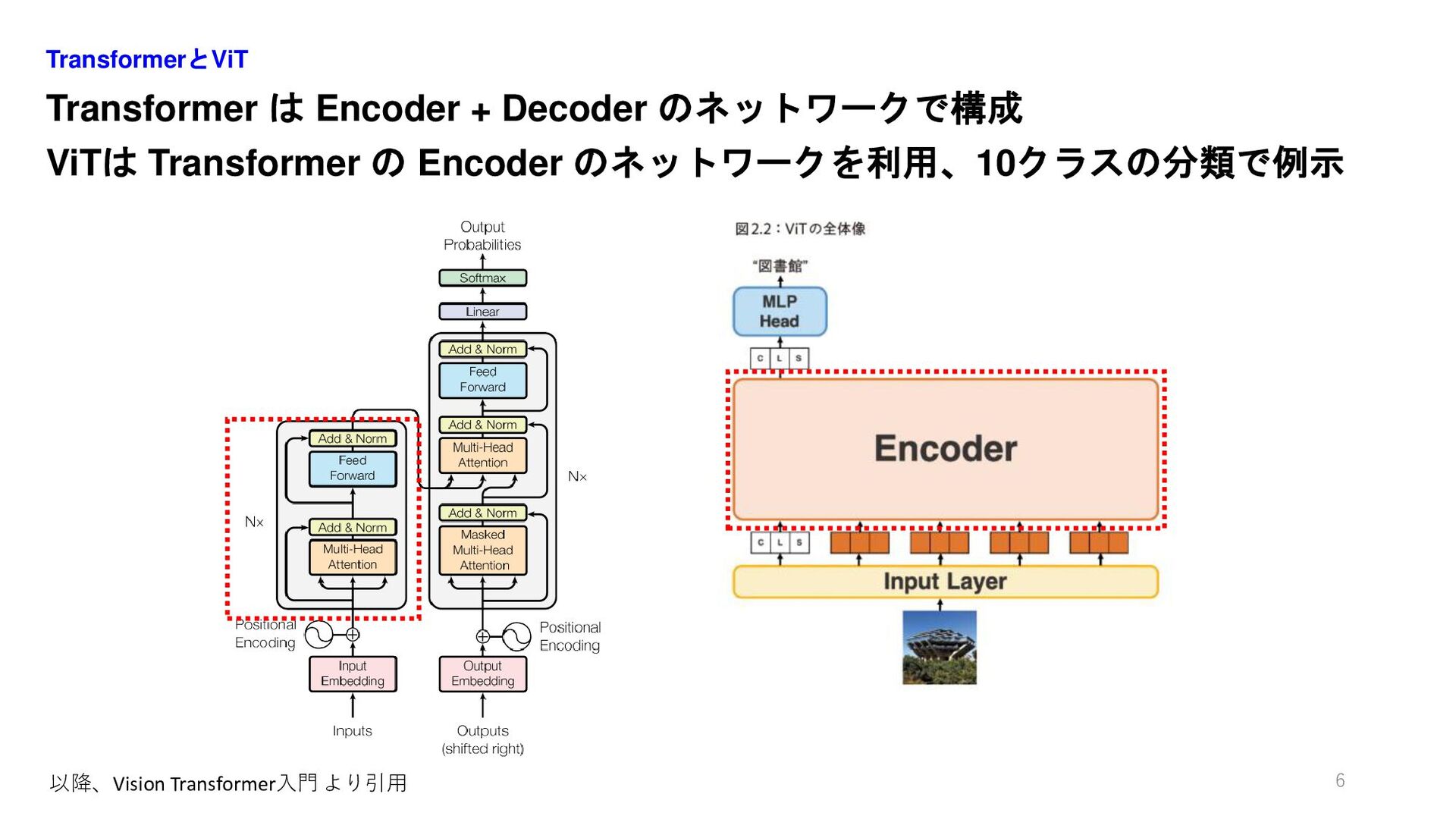
Transformer は Encoder + Decoder のネットワークで構成 ViTは Transformer の Encoder
のネットワークを利用、10クラスの分類で例示 TransformerとViT 6 以降、Vision Transformer入門 より引用
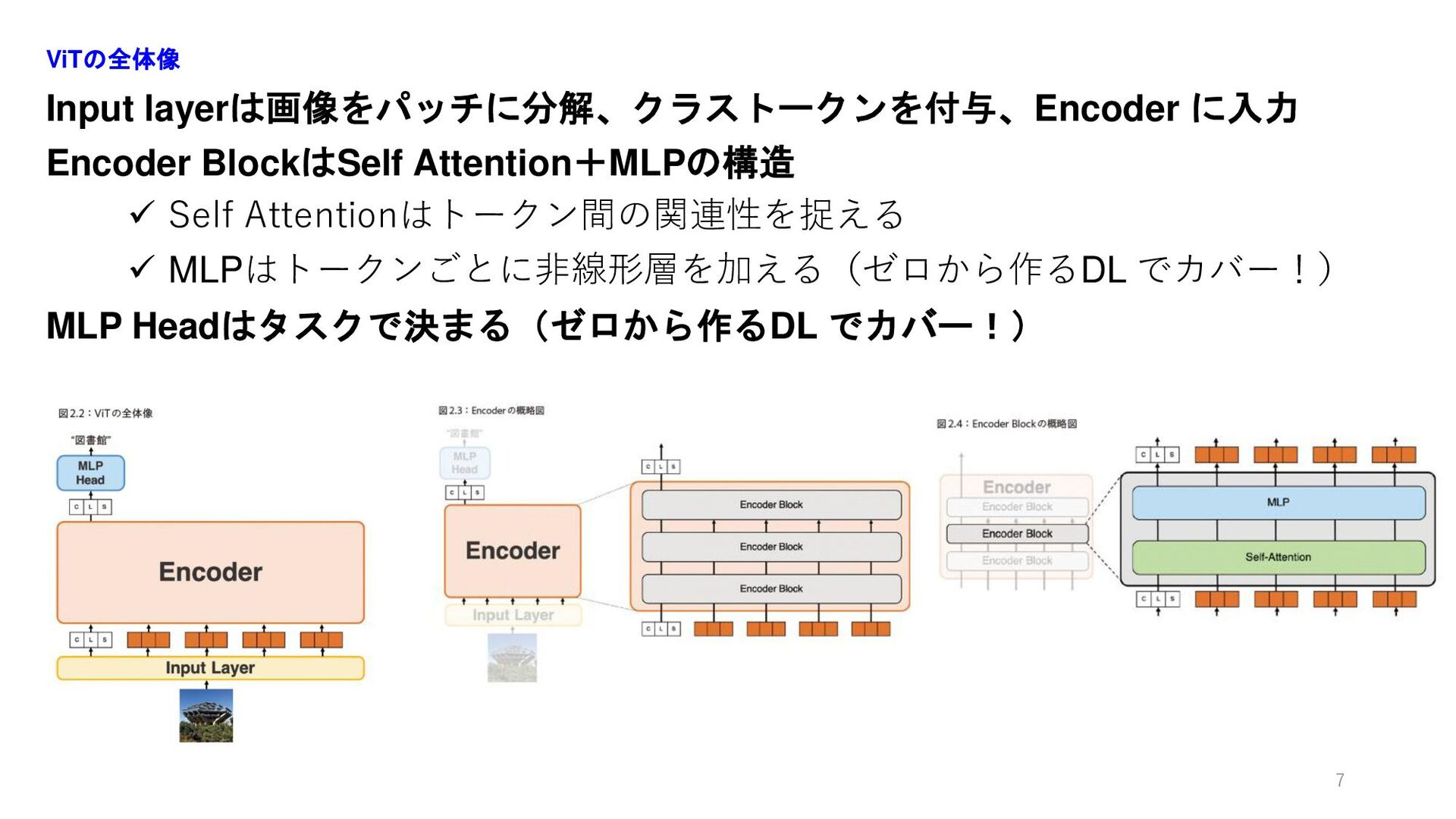
Input layerは画像をパッチに分解、クラストークンを付与、Encoder に入力 Encoder BlockはSelf Attention+MLPの構造 ✓ Self Attentionはトークン間の関連性を捉える ✓
MLPはトークンごとに非線形層を加える(ゼロから作るDL でカバー!) MLP Headはタスクで決まる(ゼロから作るDL でカバー!) ViTの全体像 7
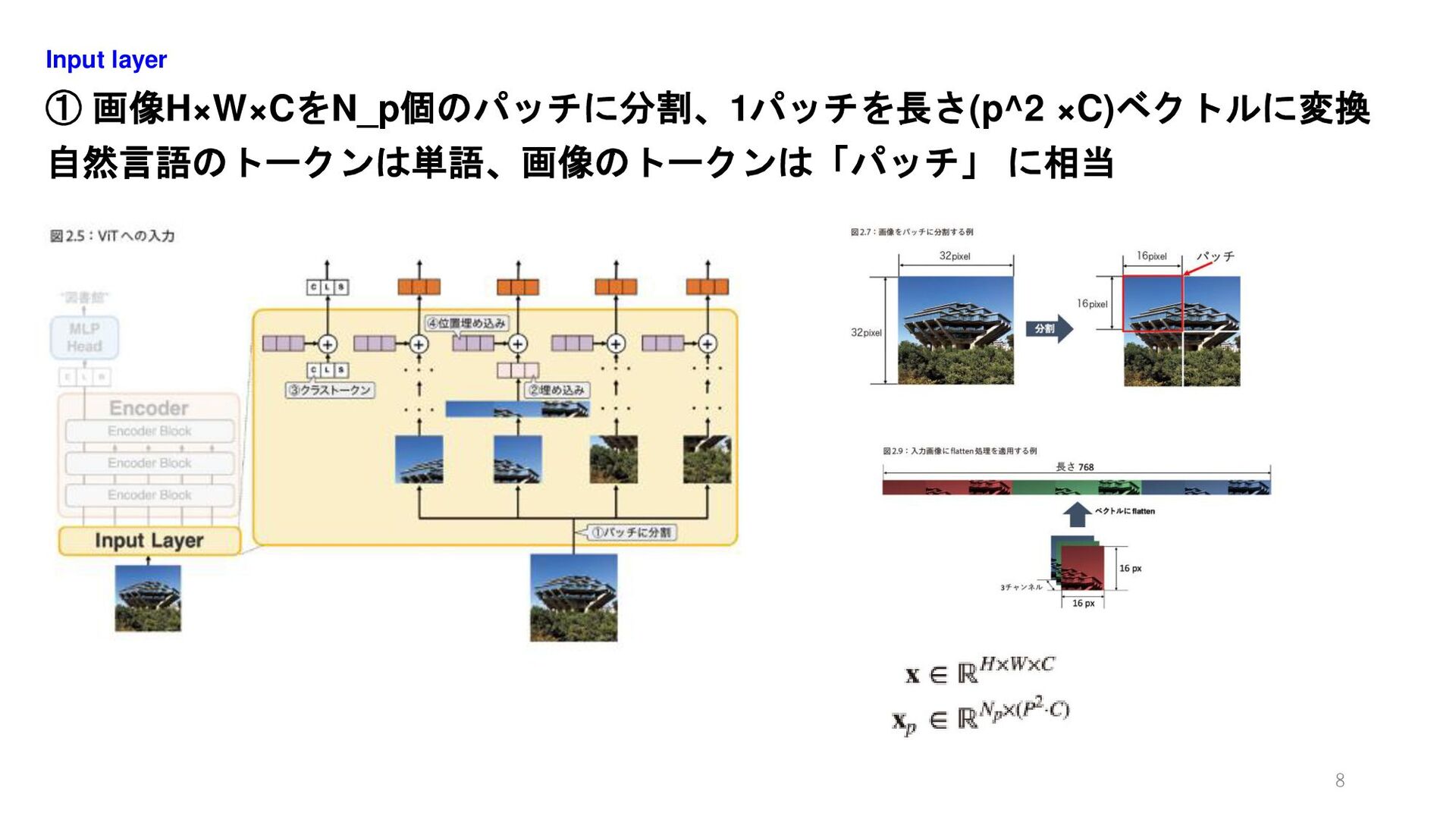
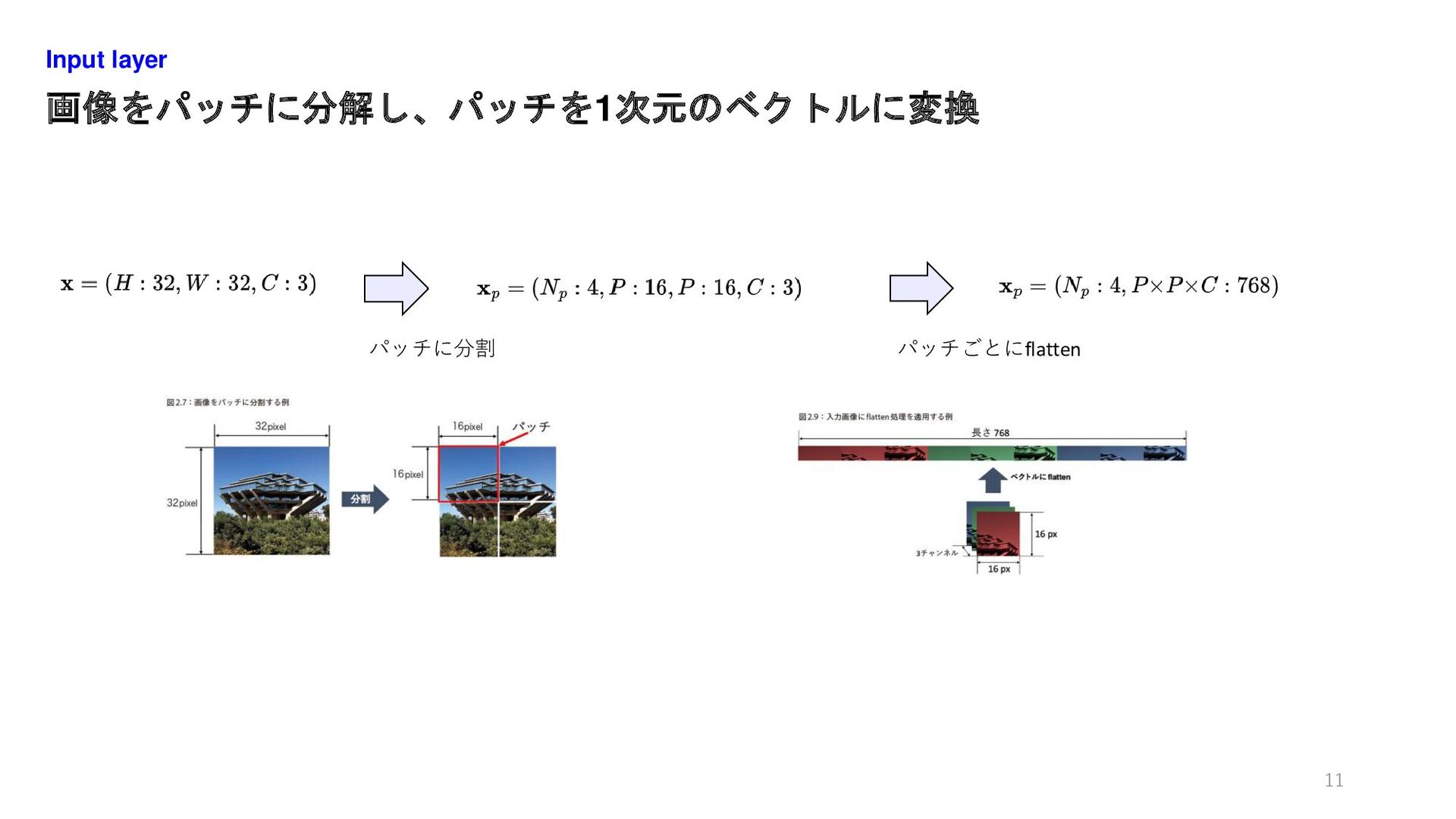
① 画像H×W×CをN_p個のパッチに分割、1パッチを長さ(p^2 ×C)ベクトルに変換 自然言語のトークンは単語、画像のトークンは「パッチ」 に相当 Input layer 8
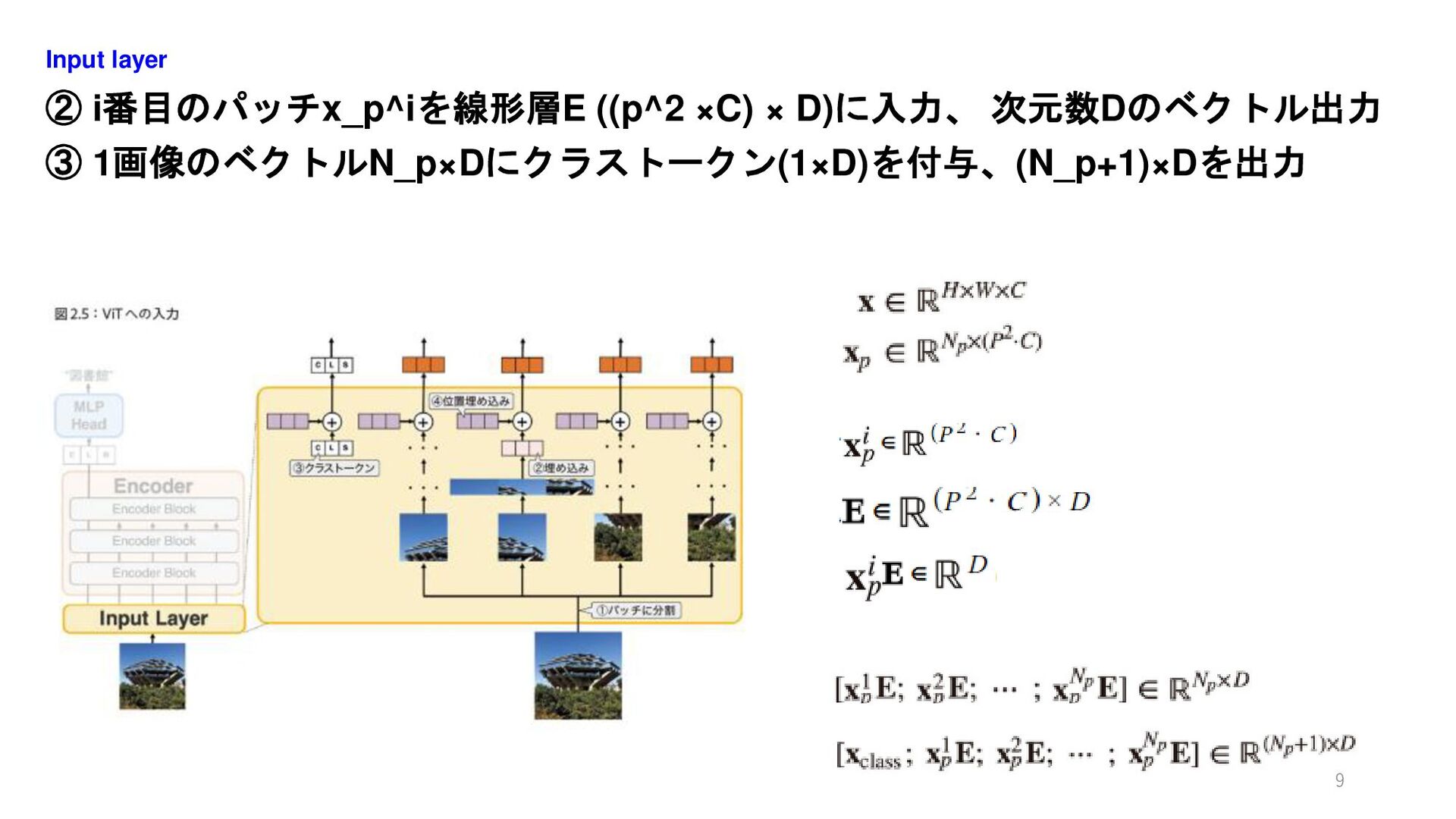
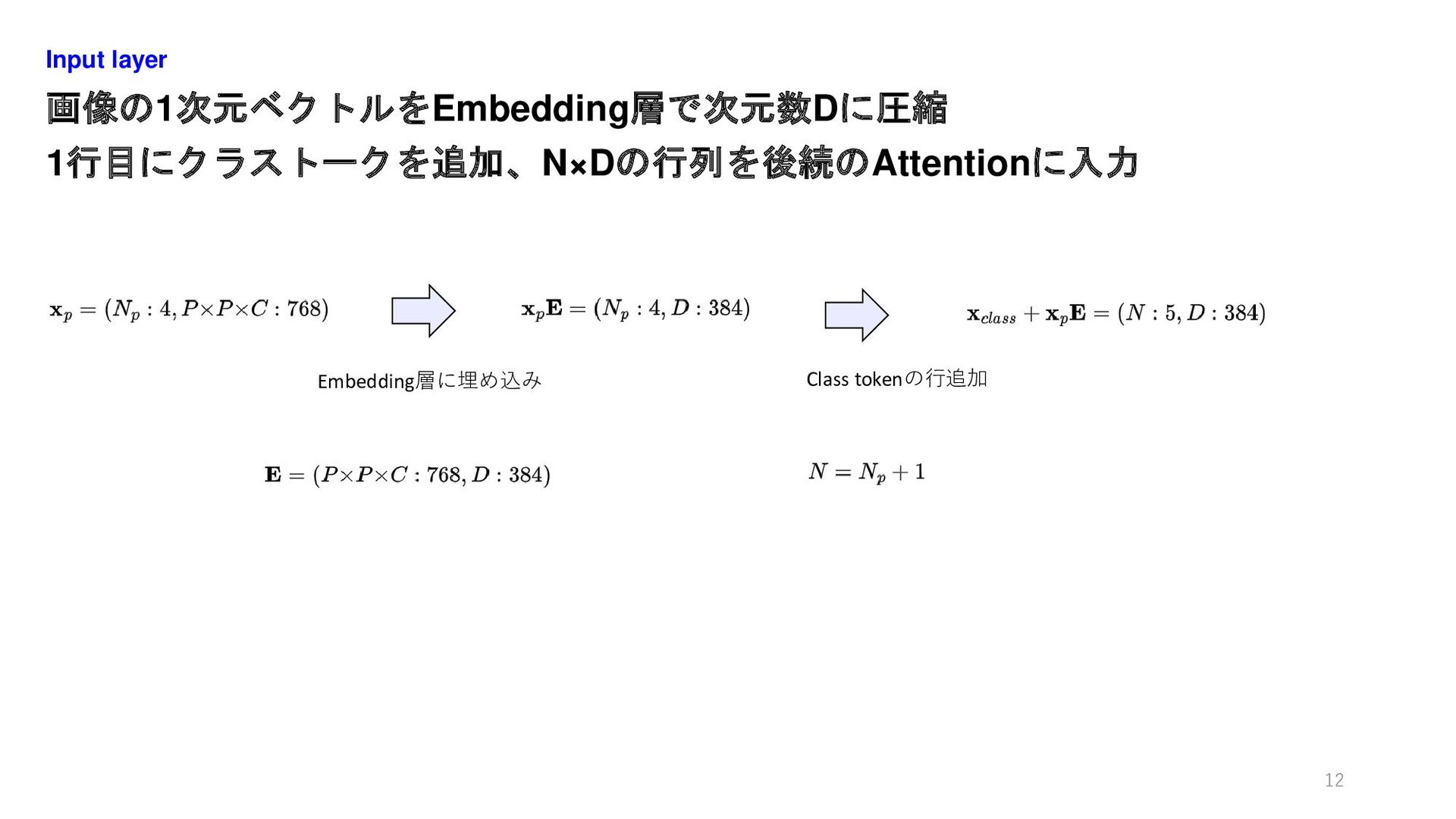
② i番目のパッチx_p^iを線形層E ((p^2 ×C) × D)に入力、 次元数Dのベクトル出力 ③ 1画像のベクトルN_p×Dにクラストークン(1×D)を付与、(N_p+1)×Dを出力 Input
layer 9
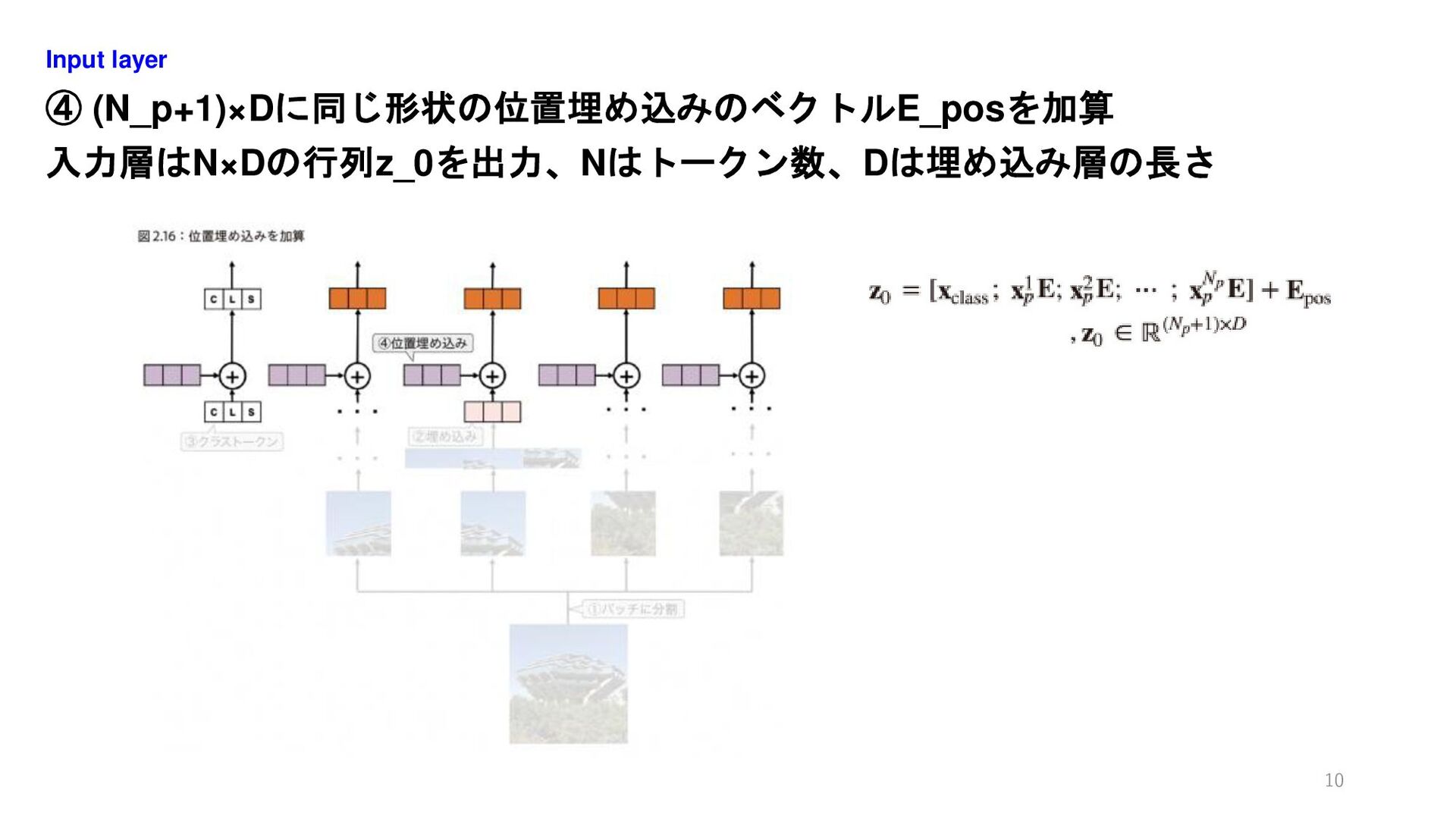
④ (N_p+1)×Dに同じ形状の位置埋め込みのベクトルE_posを加算 入力層はN×Dの行列z_0を出力、Nはトークン数、Dは埋め込み層の長さ Input layer 10
画像をパッチに分解し、パッチを1次元のベクトルに変換 Input layer 11 パッチに分割 パッチごとにflatten
画像の1次元ベクトルをEmbedding層で次元数Dに圧縮 1行目にクラストークを追加、N×Dの行列を後続のAttentionに入力 Input layer 12 Embedding層に埋め込み Class tokenの行追加
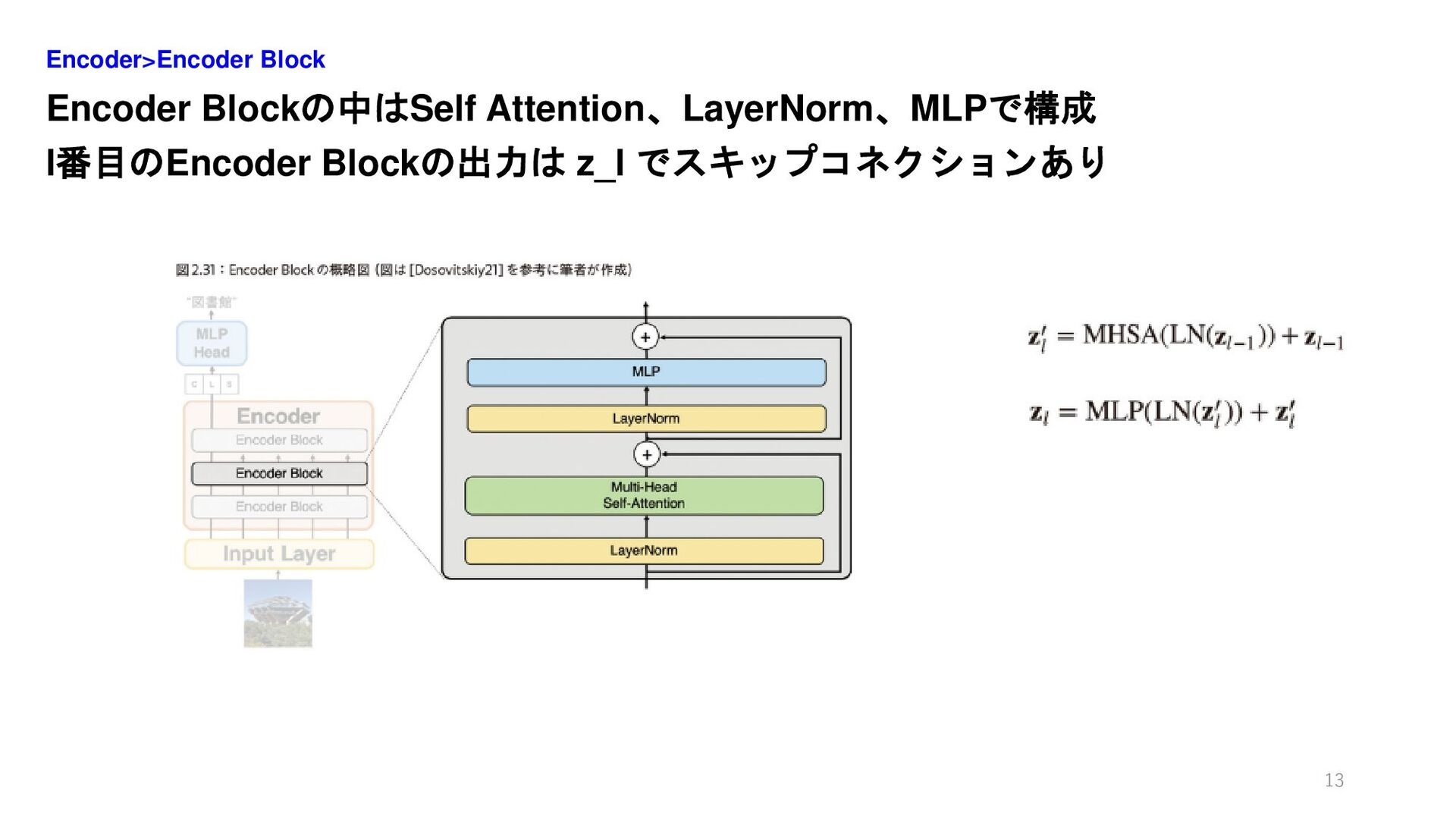
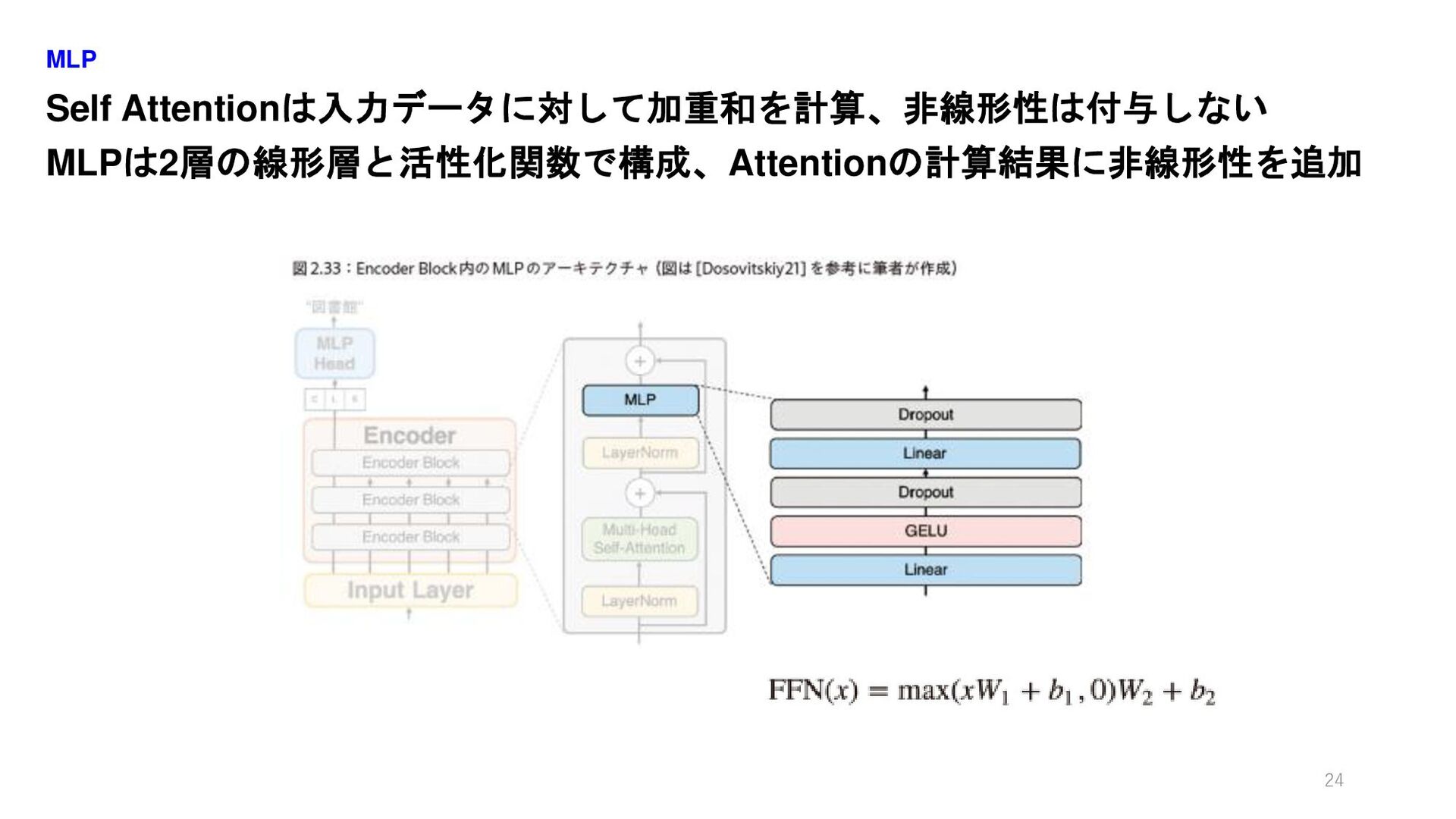
Encoder Blockの中はSelf Attention、LayerNorm、MLPで構成 l番目のEncoder Blockの出力は z_l でスキップコネクションあり Encoder>Encoder Block 13
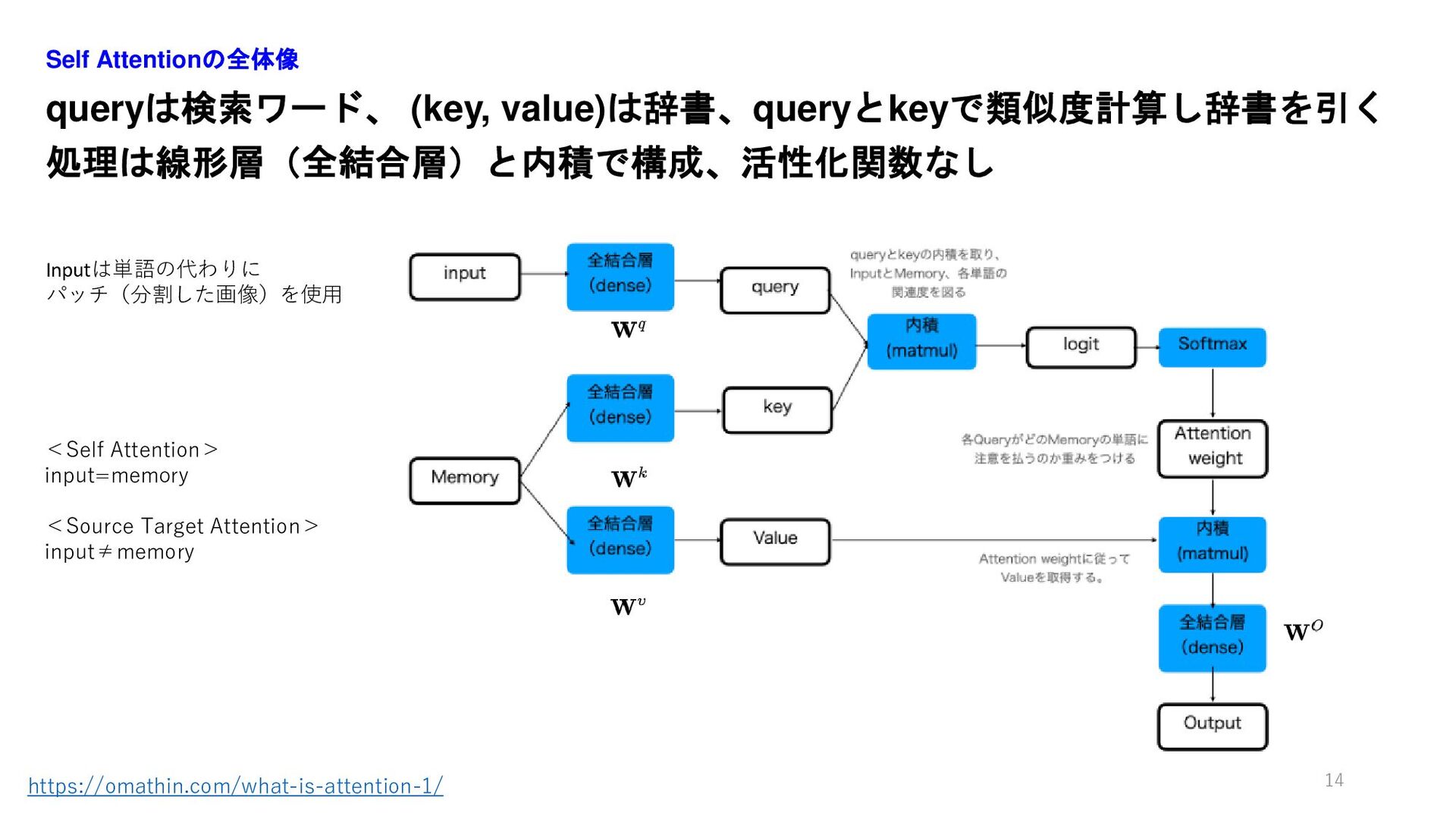
queryは検索ワード、 (key, value)は辞書、queryとkeyで類似度計算し辞書を引く 処理は線形層(全結合層)と内積で構成、活性化関数なし Self Attentionの全体像 14 https://omathin.com/what-is-attention-1/ <Self Attention>
input=memory <Source Target Attention> input≠memory Inputは単語の代わりに パッチ(分割した画像)を使用
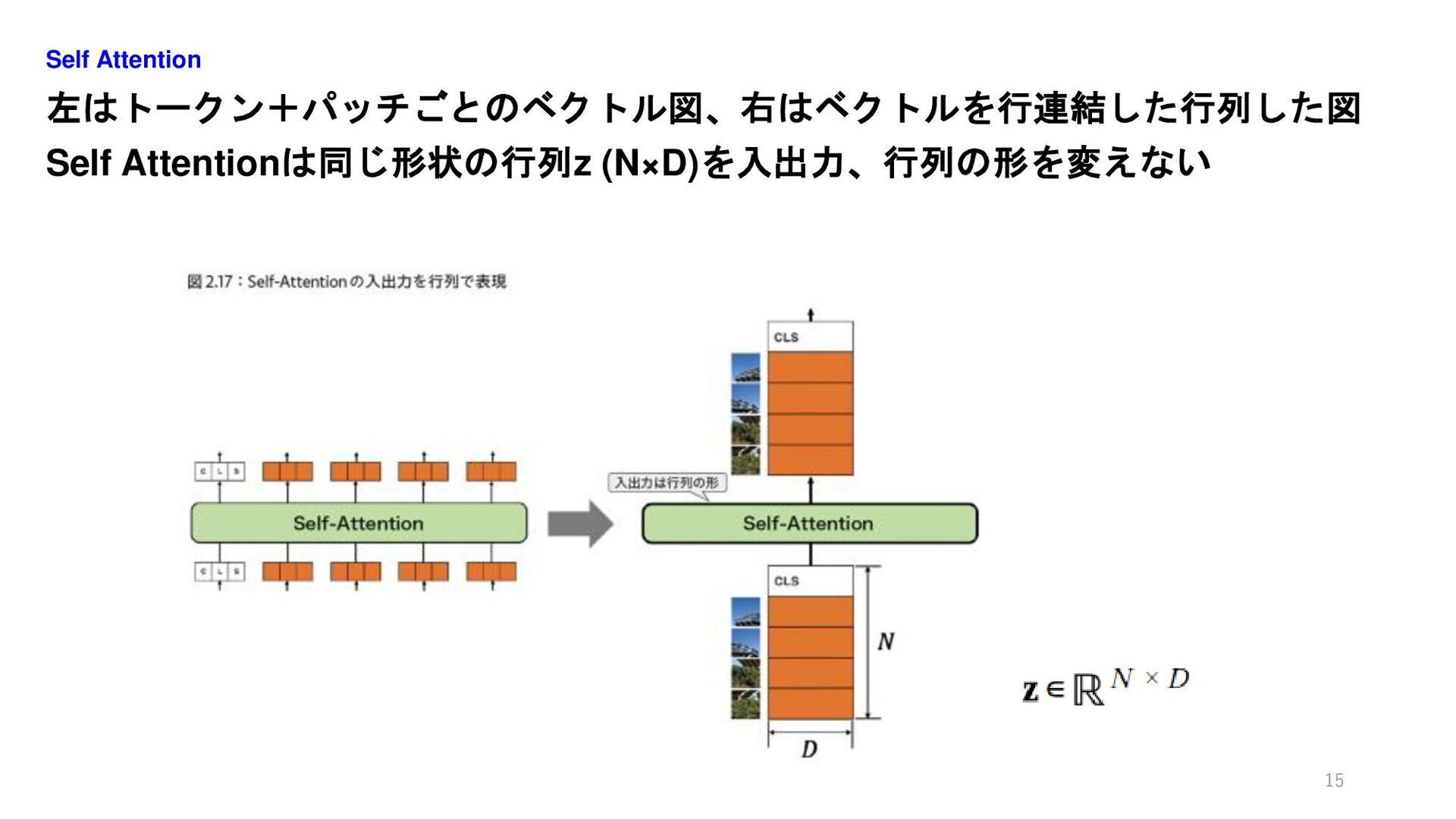
左はトークン+パッチごとのベクトル図、右はベクトルを行連結した行列した図 Self Attentionは同じ形状の行列z (N×D)を入出力、行列の形を変えない Self Attention 15
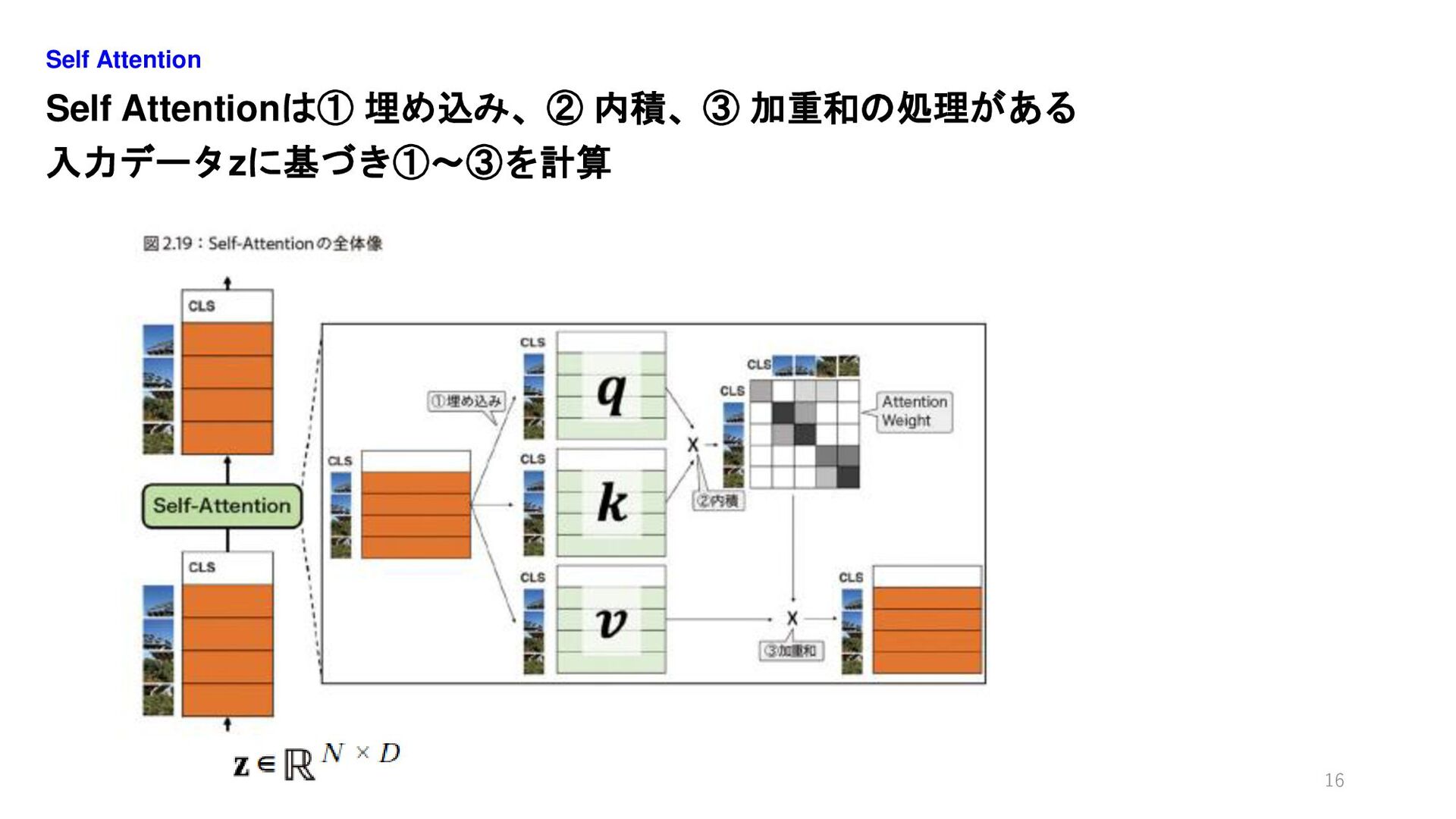
Self Attentionは① 埋め込み、② 内積、③ 加重和の処理がある 入力データzに基づき①~③を計算 Self Attention 16
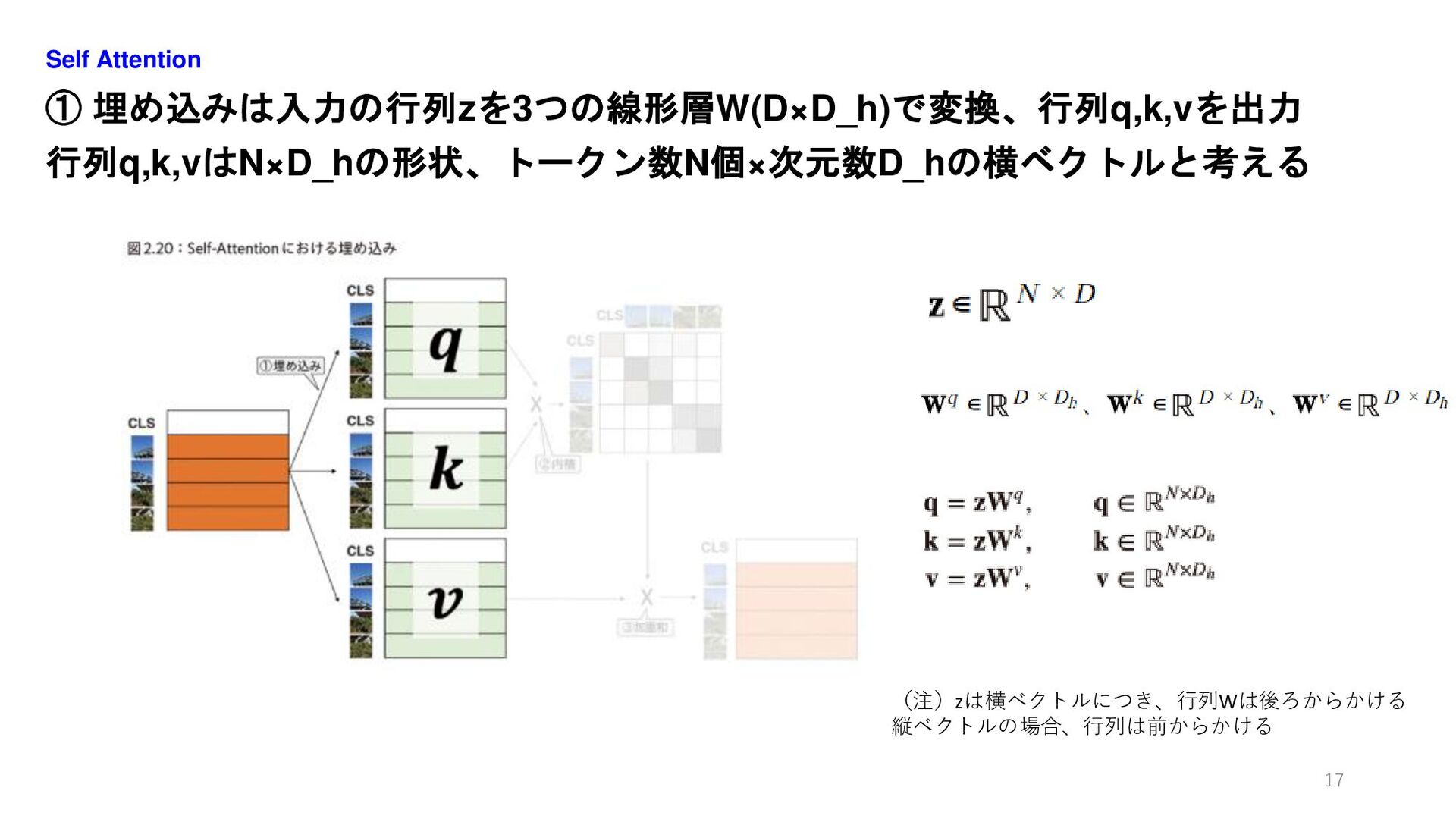
① 埋め込みは入力の行列zを3つの線形層W(D×D_h)で変換、行列q,k,vを出力 行列q,k,vはN×D_hの形状、トークン数N個×次元数D_hの横ベクトルと考える Self Attention 17 (注)zは横ベクトルにつき、行列Wは後ろからかける 縦ベクトルの場合、行列は前からかける
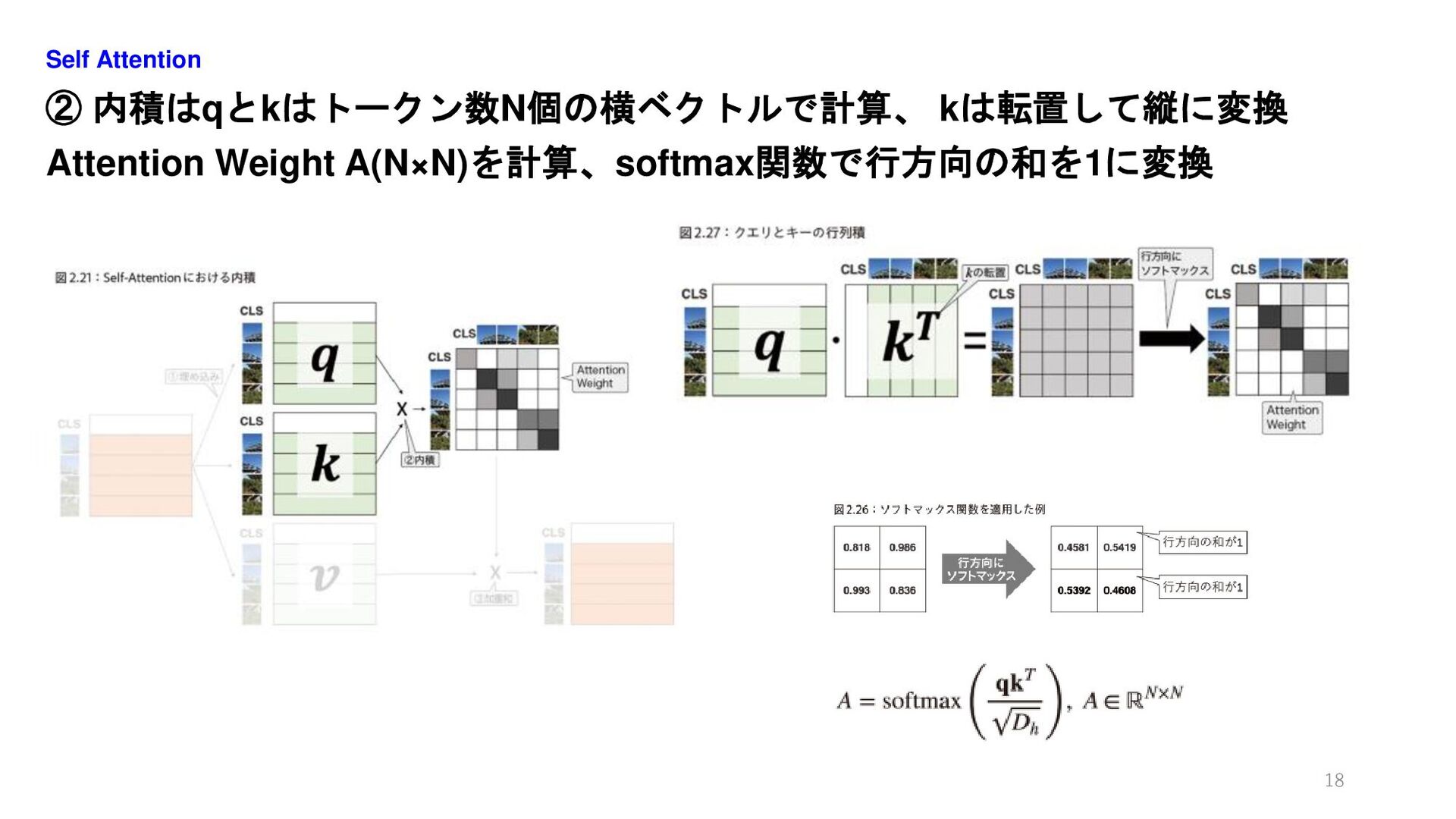
② 内積はqとkはトークン数N個の横ベクトルで計算、 kは転置して縦に変換 Attention Weight A(N×N)を計算、softmax関数で行方向の和を1に変換 Self Attention 18
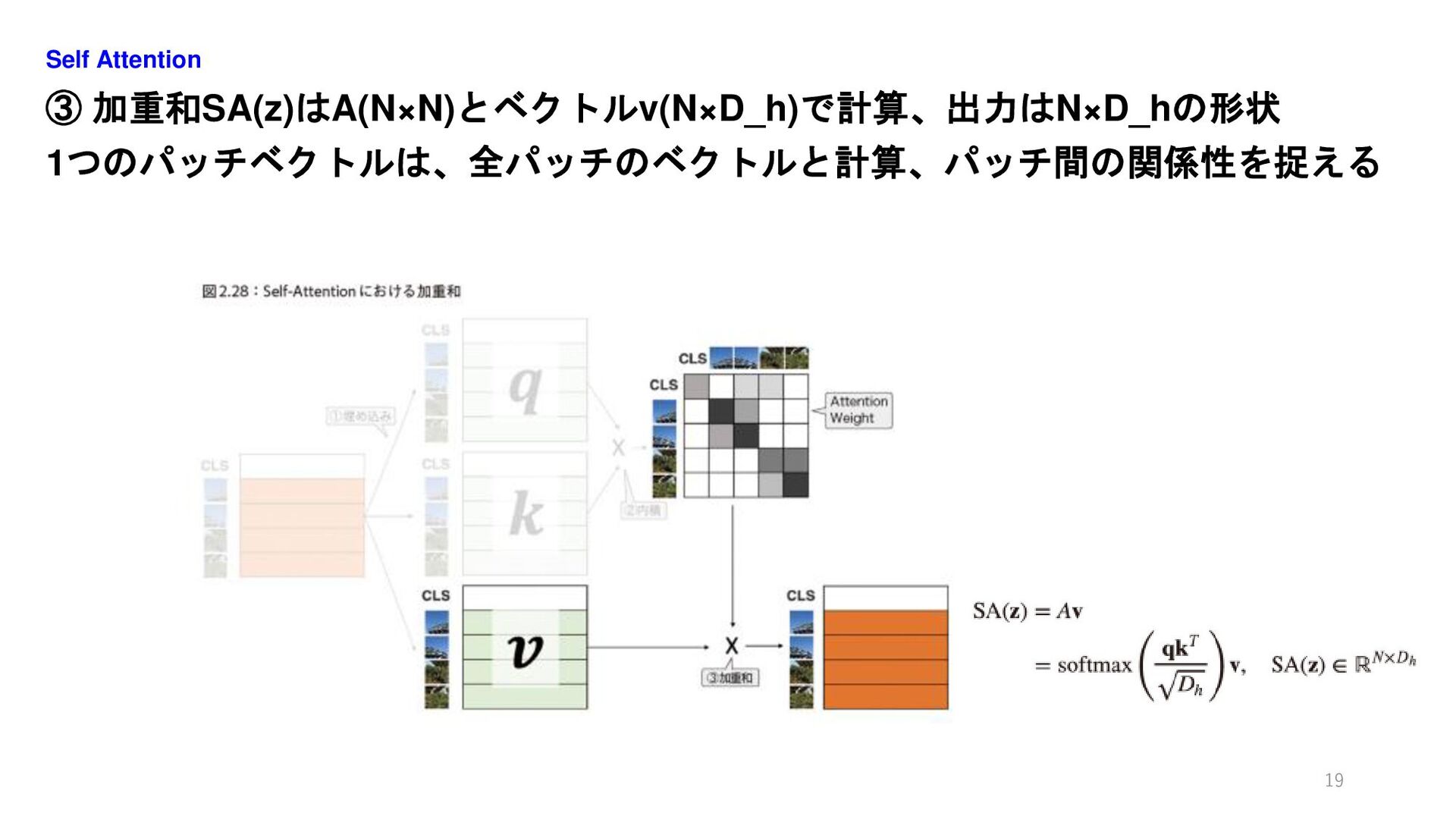
③ 加重和SA(z)はA(N×N)とベクトルv(N×D_h)で計算、出力はN×D_hの形状 1つのパッチベクトルは、全パッチのベクトルと計算、パッチ間の関係性を捉える Self Attention 19
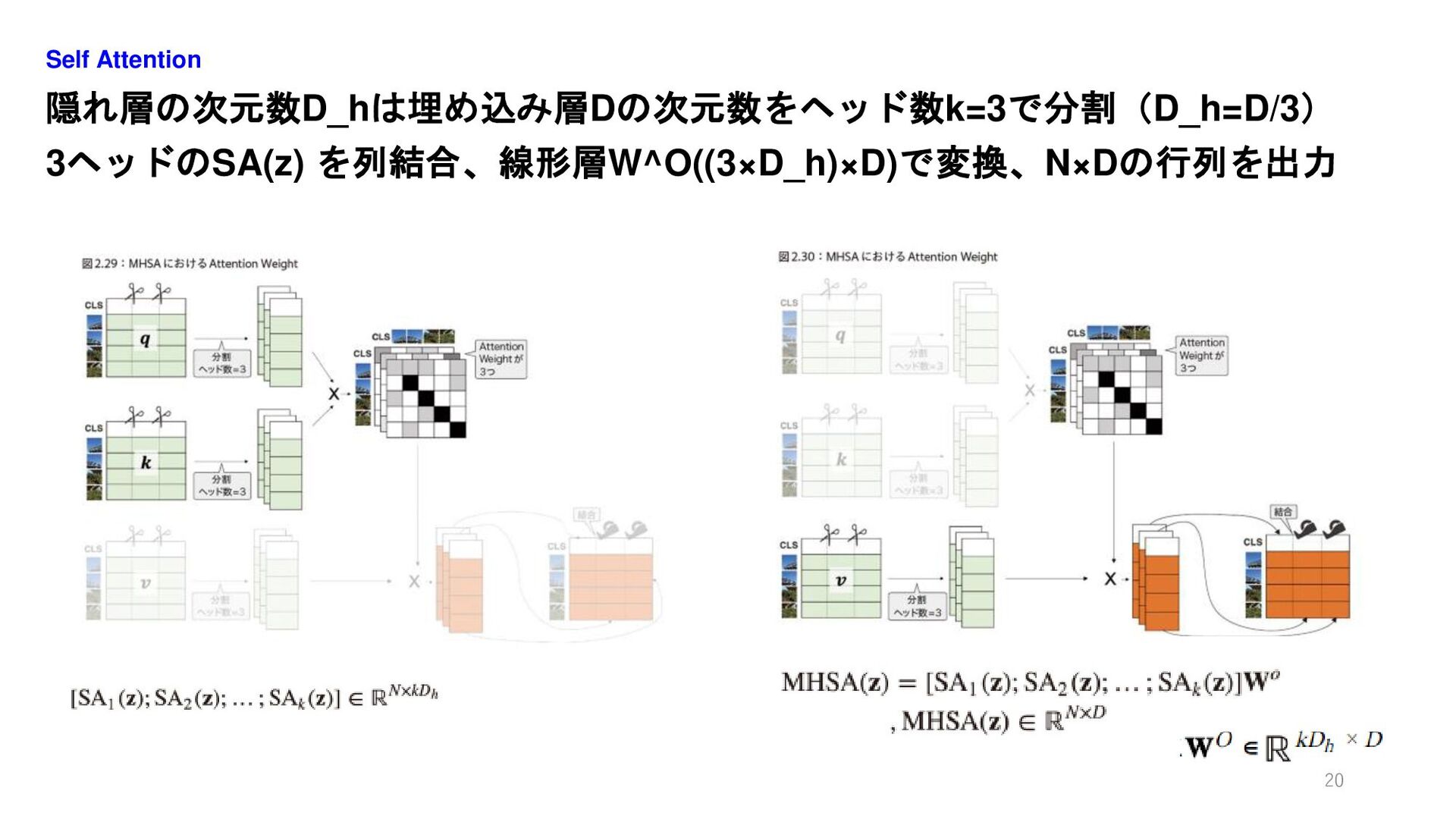
隠れ層の次元数D_hは埋め込み層Dの次元数をヘッド数k=3で分割(D_h=D/3) 3ヘッドのSA(z) を列結合、線形層W^O((3×D_h)×D)で変換、N×Dの行列を出力 Self Attention 20
線形層を使いEmbedding層の次元数をヘッド数3で割った次元数に変換 3ヘッドそれぞれの行列を列方向に結合 Self Attention 21 q,k,vそれぞれで線形層 3ヘッドを列方向に結合
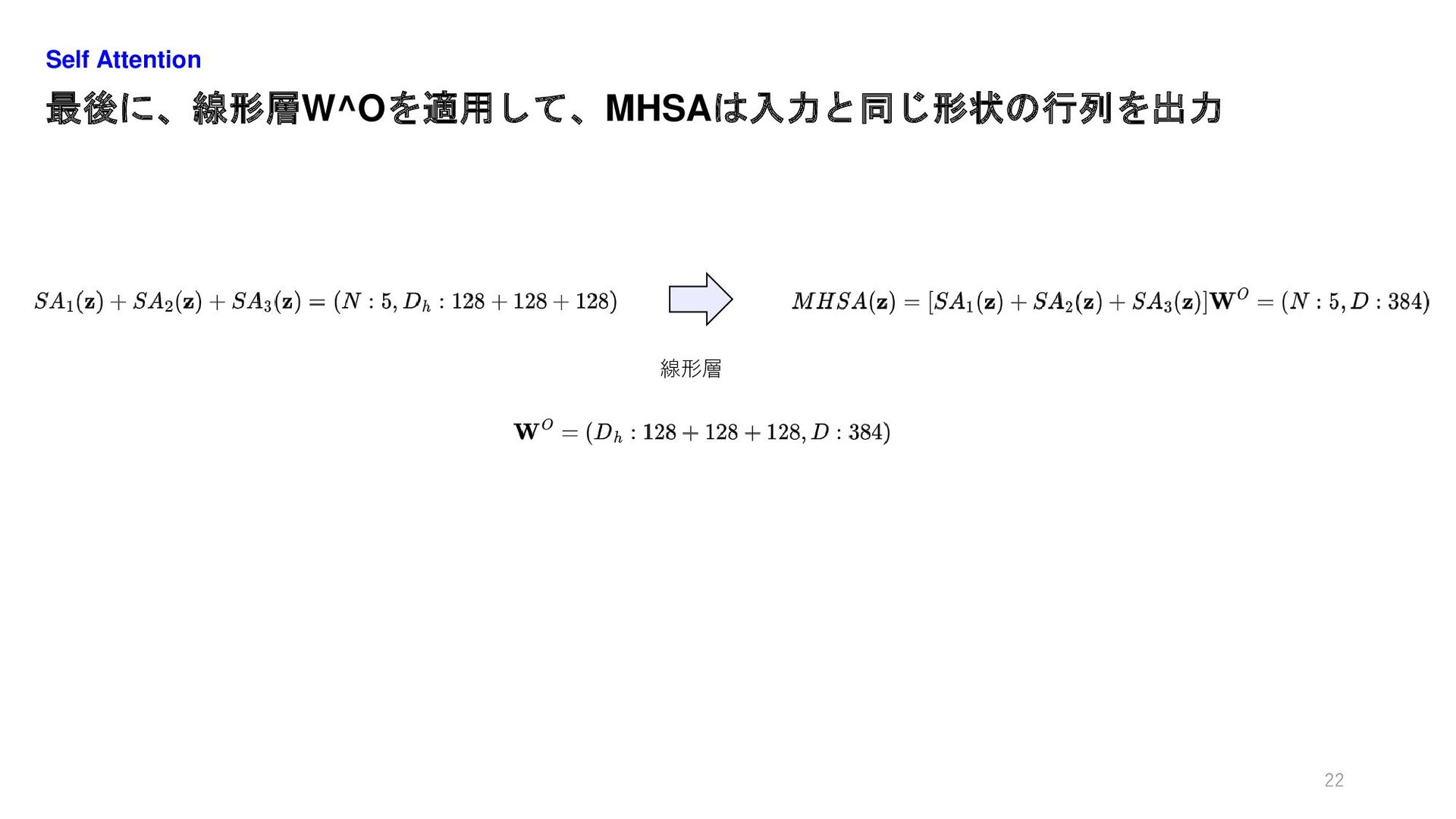
最後に、線形層W^Oを適用して、MHSAは入力と同じ形状の行列を出力 Self Attention 22 線形層
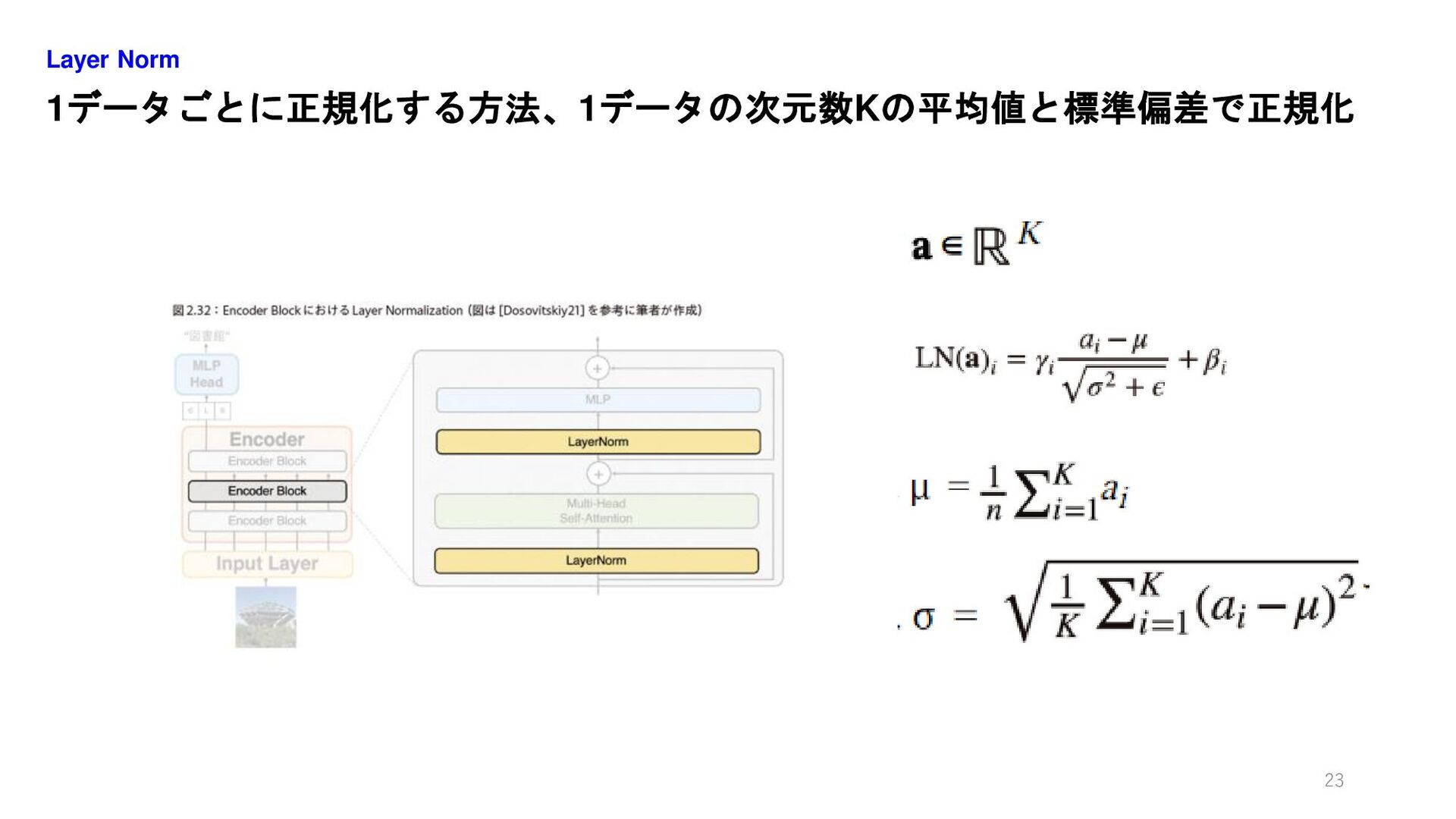
1データごとに正規化する方法、1データの次元数Kの平均値と標準偏差で正規化 Layer Norm 23
Self Attentionは入力データに対して加重和を計算、非線形性は付与しない MLPは2層の線形層と活性化関数で構成、Attentionの計算結果に非線形性を追加 MLP 24
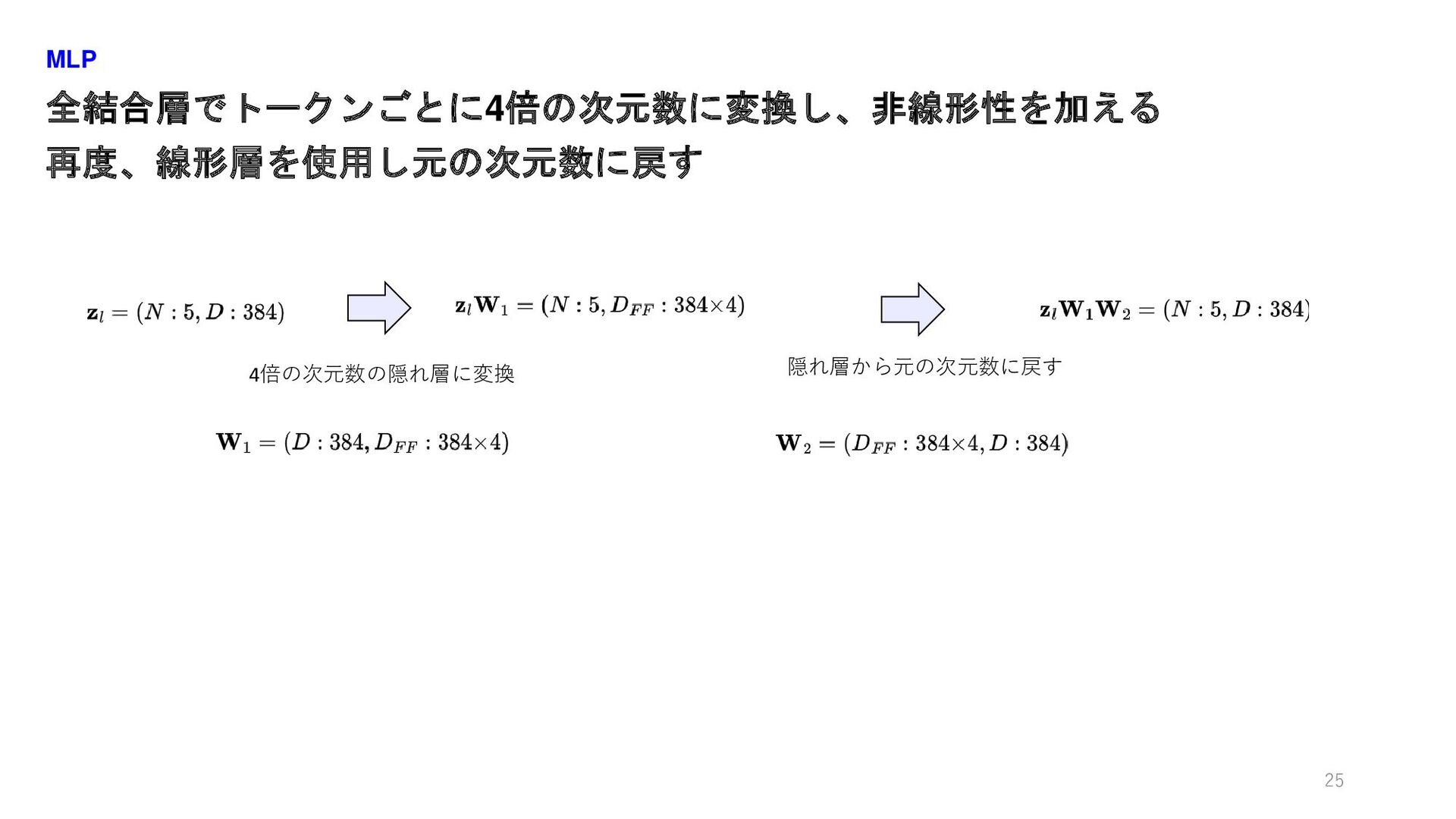
全結合層でトークンごとに4倍の次元数に変換し、非線形性を加える 再度、線形層を使用し元の次元数に戻す MLP 25 4倍の次元数の隠れ層に変換 隠れ層から元の次元数に戻す
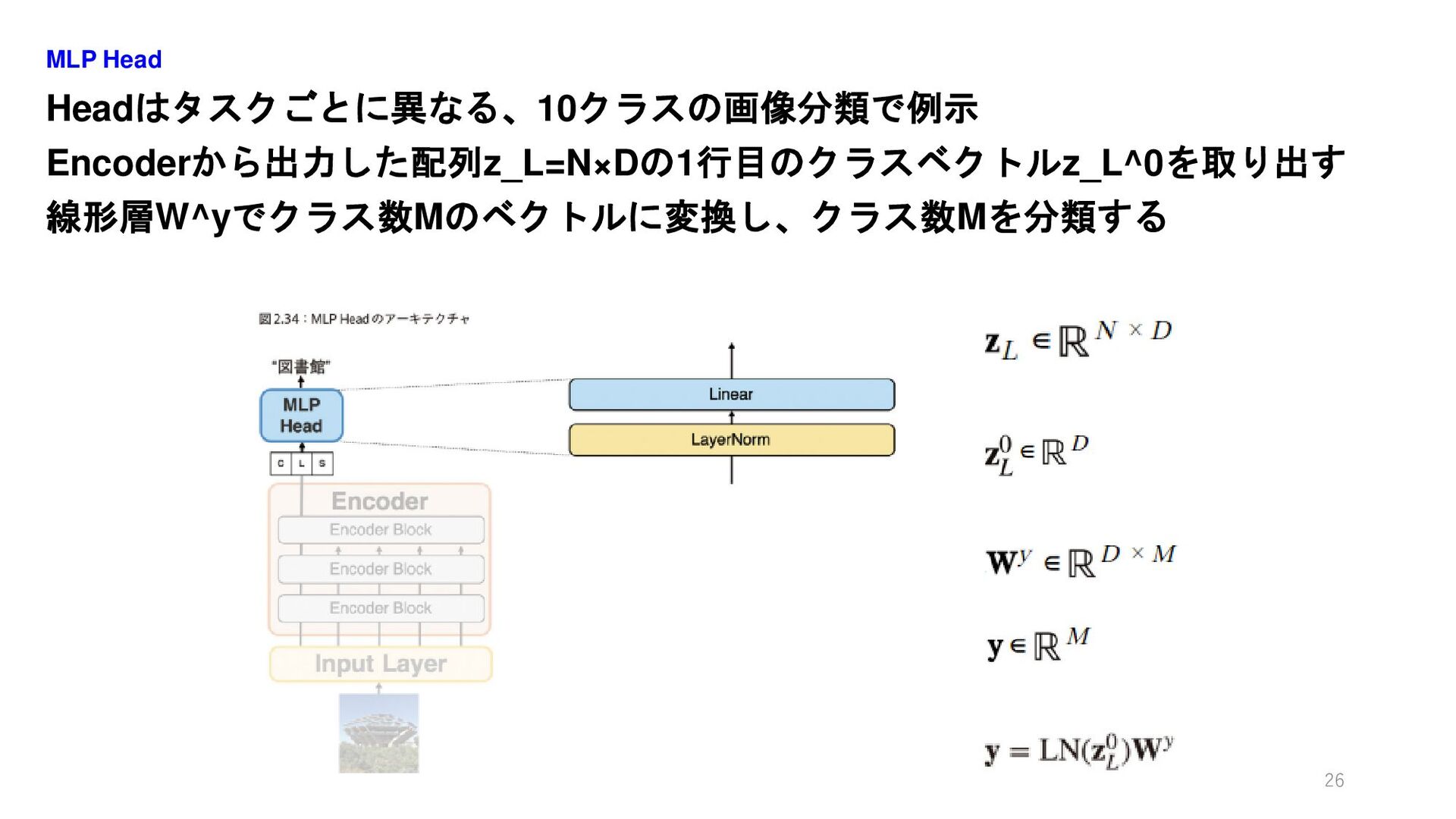
Headはタスクごとに異なる、10クラスの画像分類で例示 Encoderから出力した配列z_L=N×Dの1行目のクラスベクトルz_L^0を取り出す 線形層W^yでクラス数Mのベクトルに変換し、クラス数Mを分類する MLP Head 26
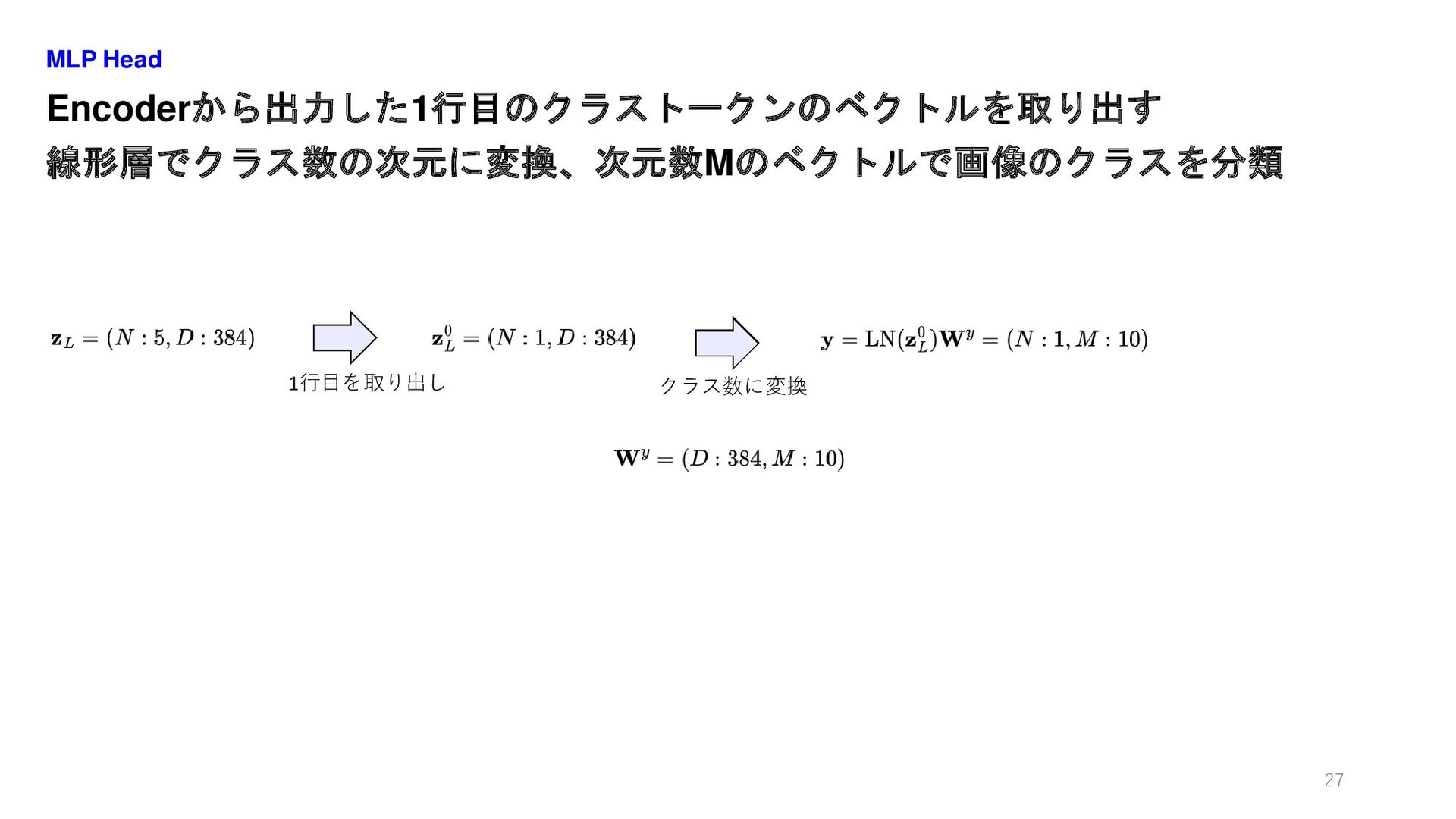
Encoderから出力した1行目のクラストークンのベクトルを取り出す 線形層でクラス数の次元に変換、次元数Mのベクトルで画像のクラスを分類 MLP Head 27 1行目を取り出し クラス数に変換
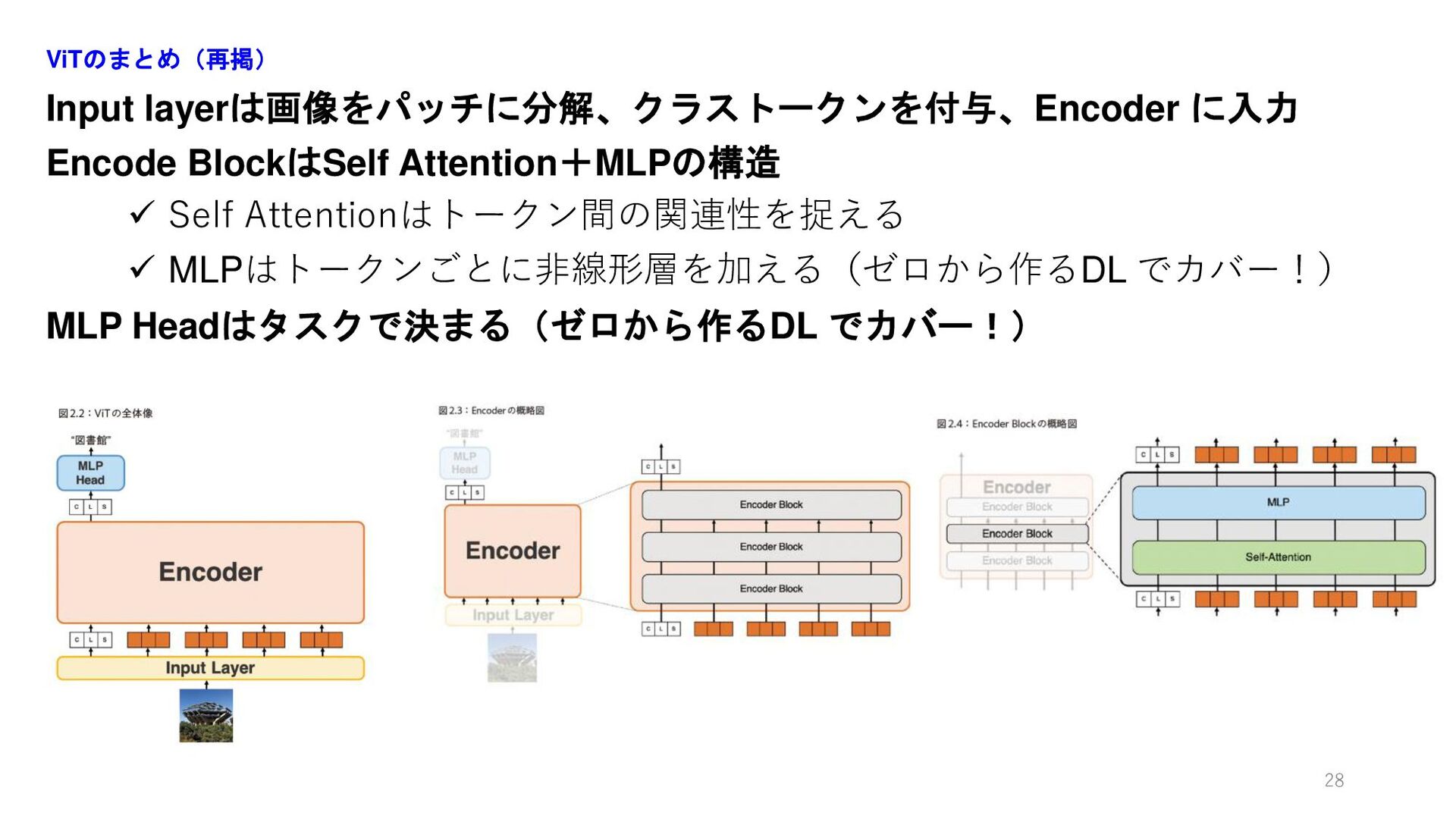
Input layerは画像をパッチに分解、クラストークンを付与、Encoder に入力 Encode BlockはSelf Attention+MLPの構造 ✓ Self Attentionはトークン間の関連性を捉える ✓
MLPはトークンごとに非線形層を加える(ゼロから作るDL でカバー!) MLP Headはタスクで決まる(ゼロから作るDL でカバー!) ViTのまとめ(再掲) 28
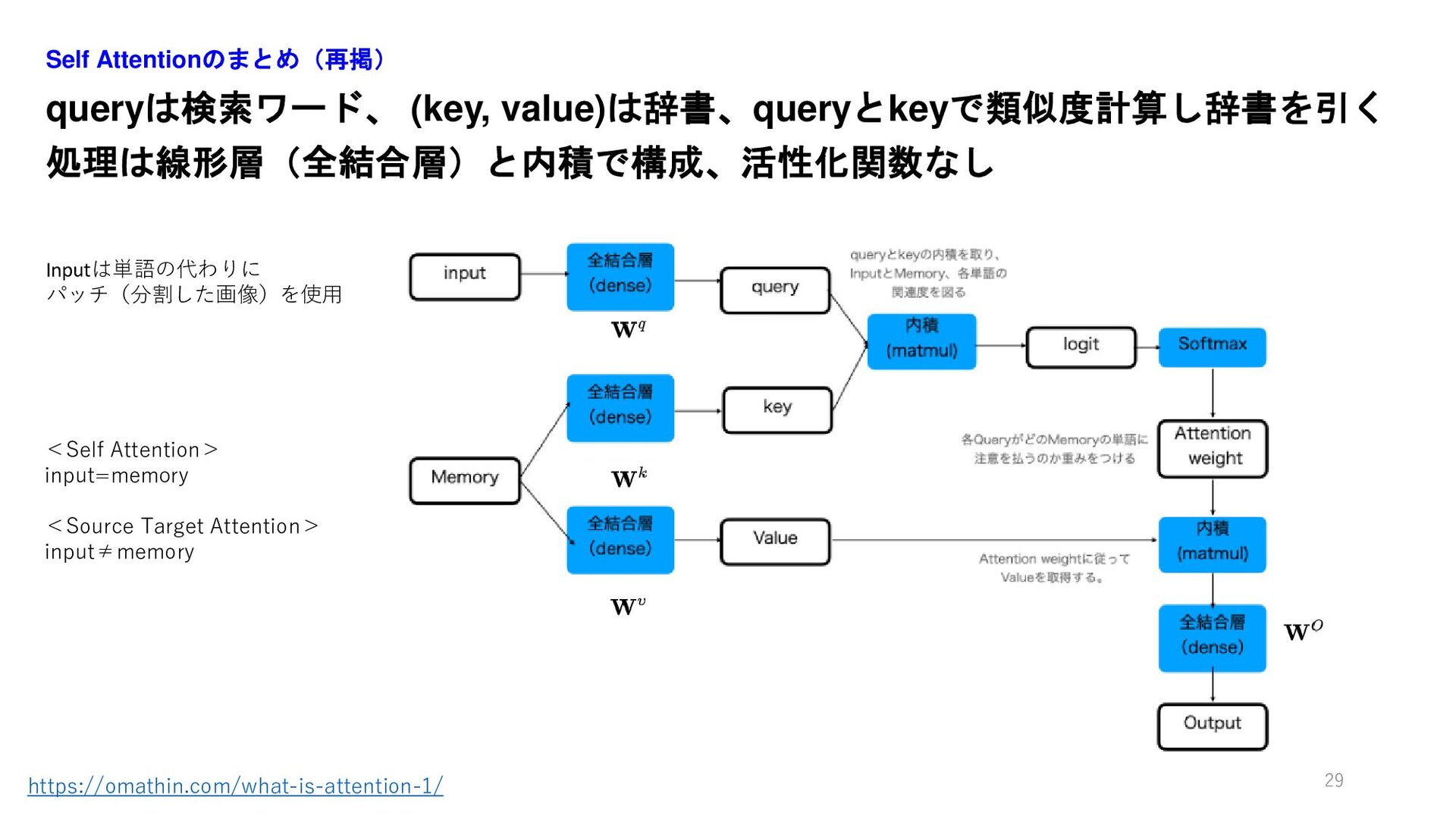
queryは検索ワード、 (key, value)は辞書、queryとkeyで類似度計算し辞書を引く 処理は線形層(全結合層)と内積で構成、活性化関数なし Self Attentionのまとめ(再掲) 29 https://omathin.com/what-is-attention-1/ <Self Attention>
input=memory <Source Target Attention> input≠memory Inputは単語の代わりに パッチ(分割した画像)を使用
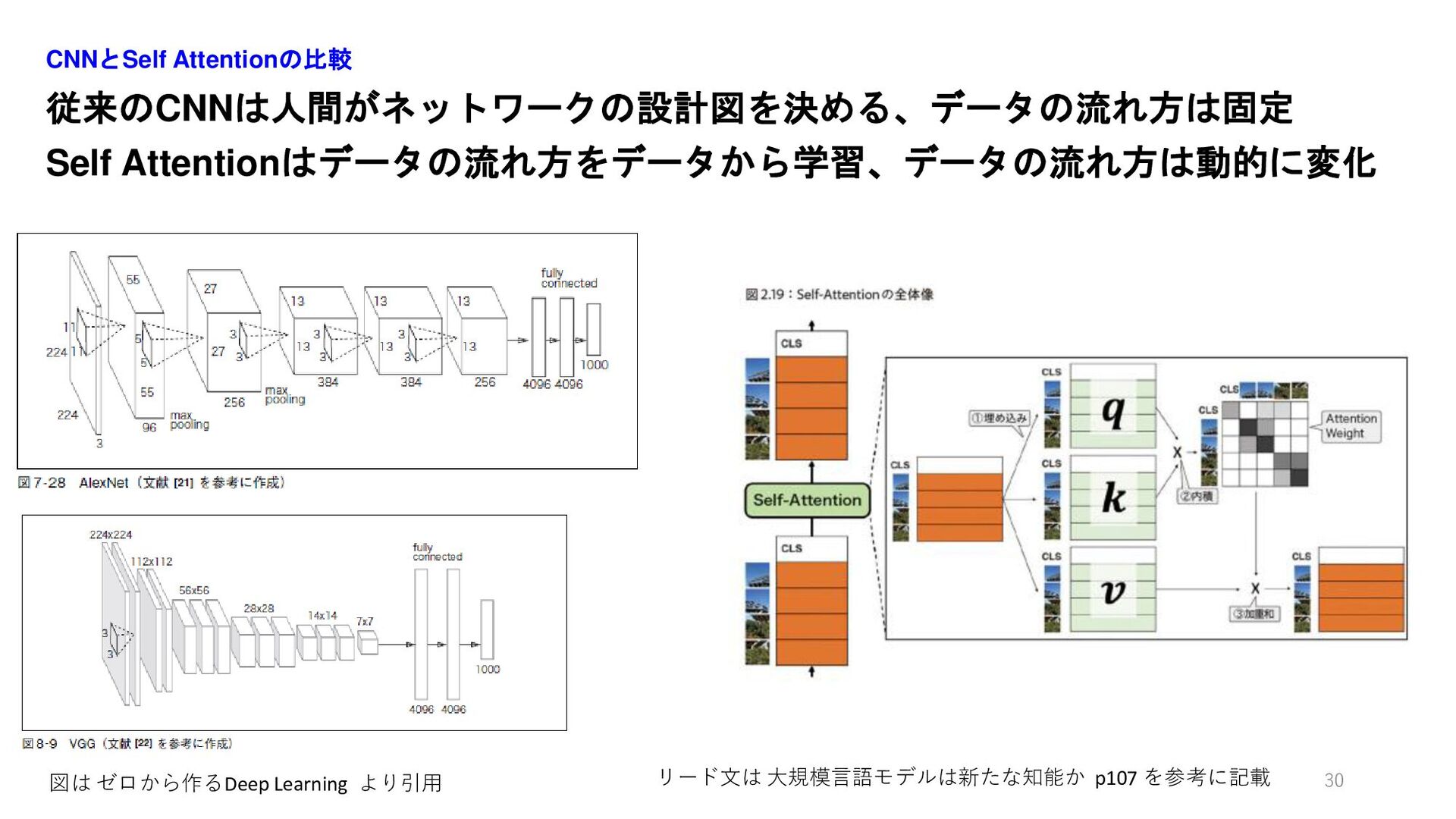
従来のCNNは人間がネットワークの設計図を決める、データの流れ方は固定 Self Attentionはデータの流れ方をデータから学習、データの流れ方は動的に変化 CNNとSelf Attentionの比較 30 図は ゼロから作るDeep Learning より引用
リード文は 大規模言語モデルは新たな知能か p107 を参考に記載
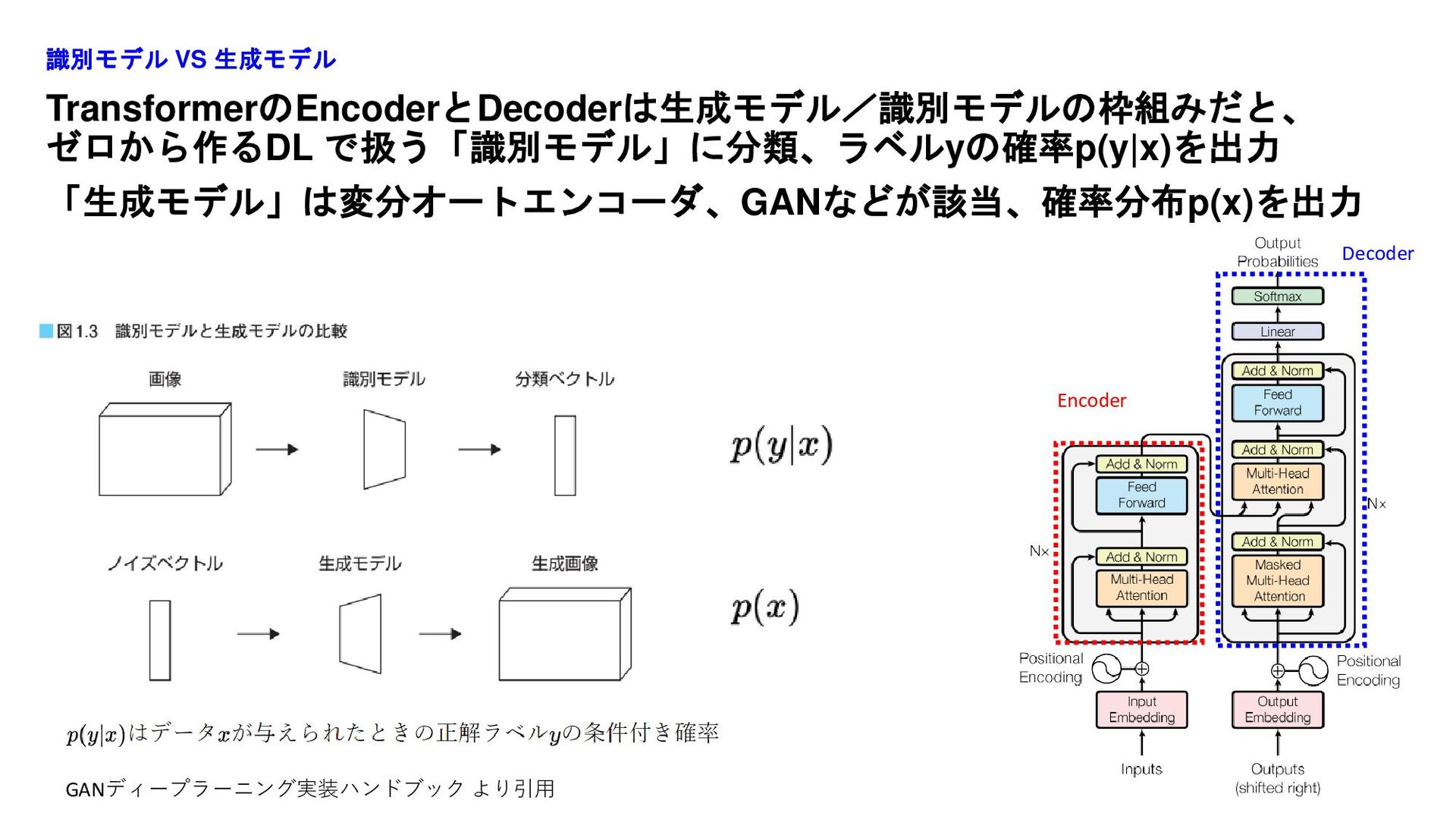
TransformerのEncoderとDecoderは生成モデル/識別モデルの枠組みだと、 ゼロから作るDL で扱う「識別モデル」に分類、ラベルyの確率p(y|x)を出力 「生成モデル」は変分オートエンコーダ、GANなどが該当、確率分布p(x)を出力 識別モデル VS 生成モデル 31 GANディープラーニング実装ハンドブック より引用
Encoder Decoder
生成モデルの勉強には基本から学べるGANハンドブックがおすすめ 画像案件は大政代表のweb farmerまでご相談ください 生成モデルのおすすめ本、画像案件相談(宣伝) 32 https://web-farmer.net/company/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}