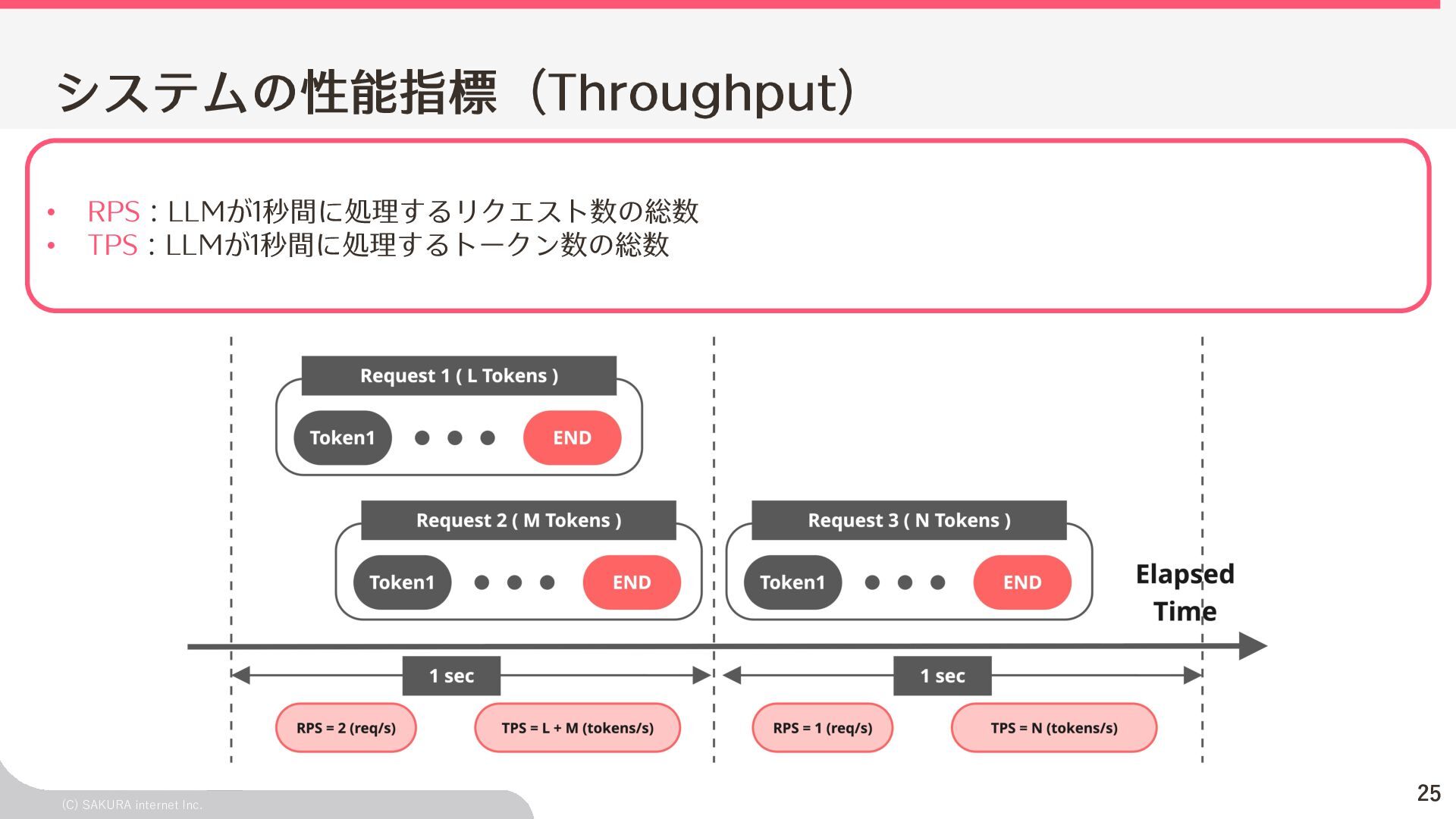
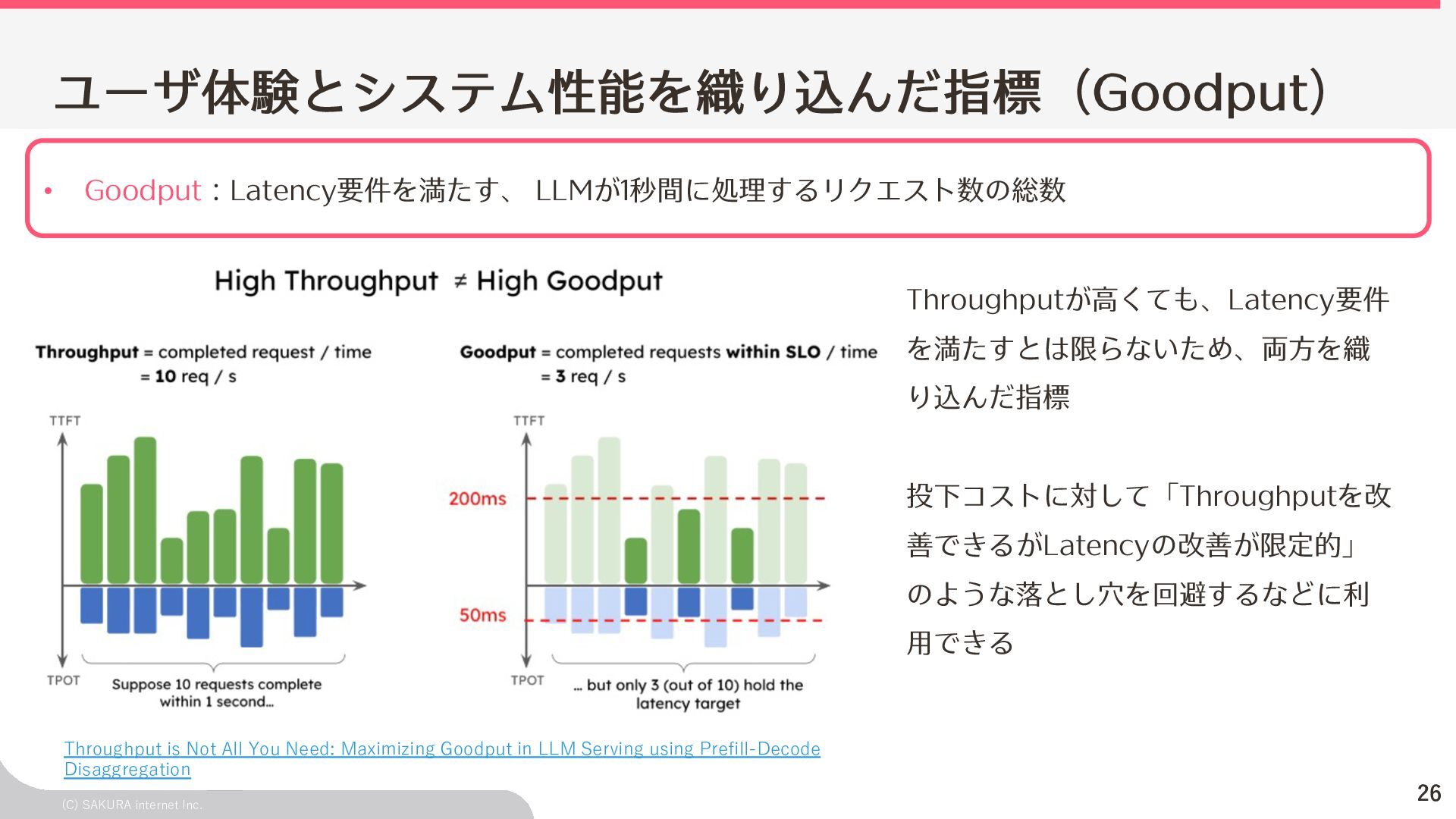
Goodput:Latency要件を満たす、 LLMが1秒間に処理するリクエスト数の総数 ユーザ体験とシステム性能を織り込んだ指標(Goodput) Throughputが⾼くても、Latency要件 を満たすとは限らないため、両⽅を織 り込んだ指標 投下コストに対して「Throughputを改 善できるがLatencyの改善が限定的」 のような落とし⽳を回避するなどに利 ⽤できる Throughput is Not All You Need: Maximizing Goodput in LLM Serving using Prefill-Decode Disaggregation
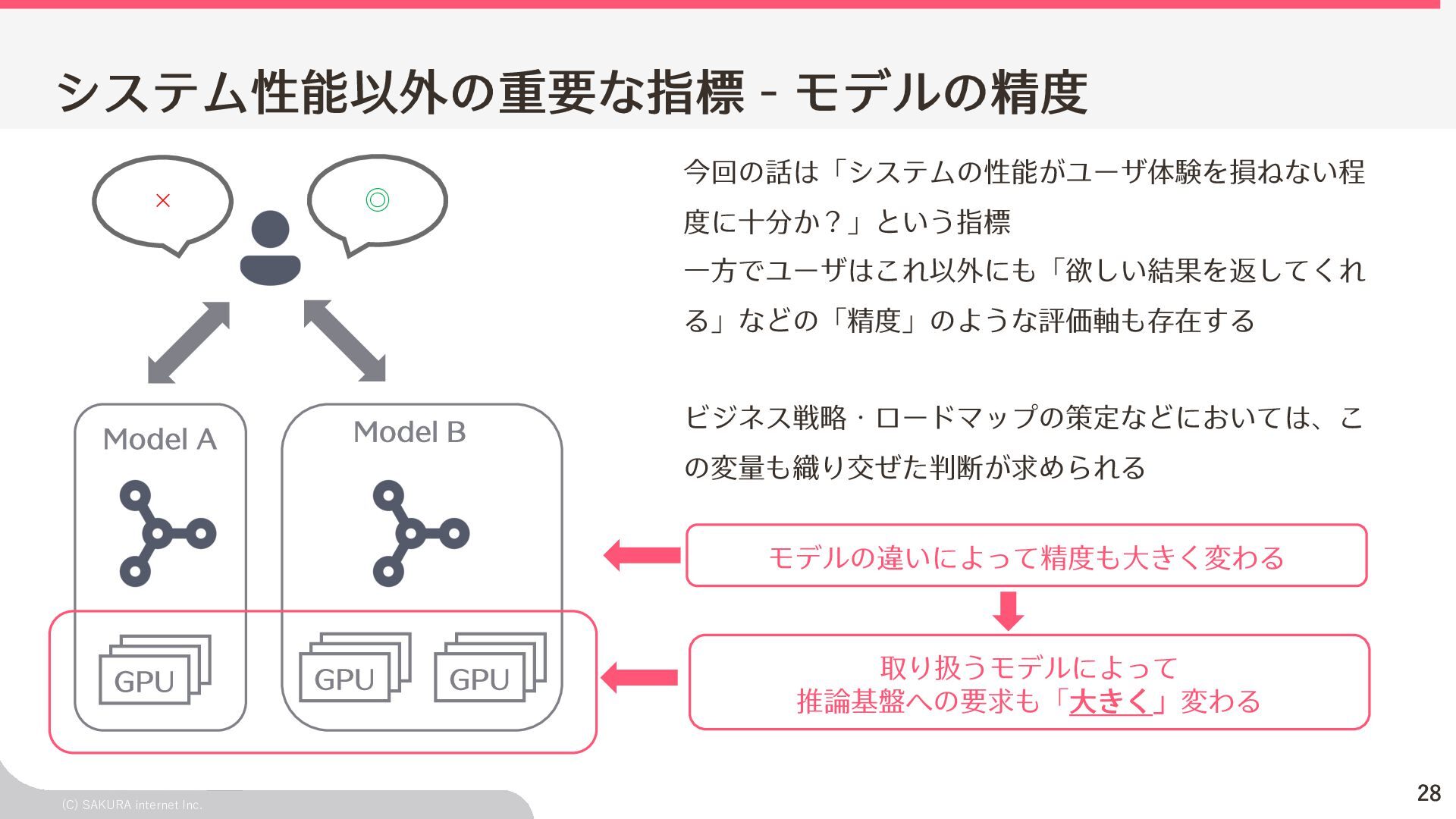
- モデルの精度 今回の話は「システムの性能がユーザ体験を損ねない程 度に⼗分か?」という指標 ⼀⽅でユーザはこれ以外にも「欲しい結果を返してくれ る」などの「精度」のような評価軸も存在する ビジネス戦略・ロードマップの策定などにおいては、こ の変量も織り交ぜた判断が求められる Model A GPU GPU GPU Model B 取り扱うモデルによって 推論基盤への要求も「⼤きく」変わる モデルの違いによって精度も⼤きく変わる ◎ ×
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
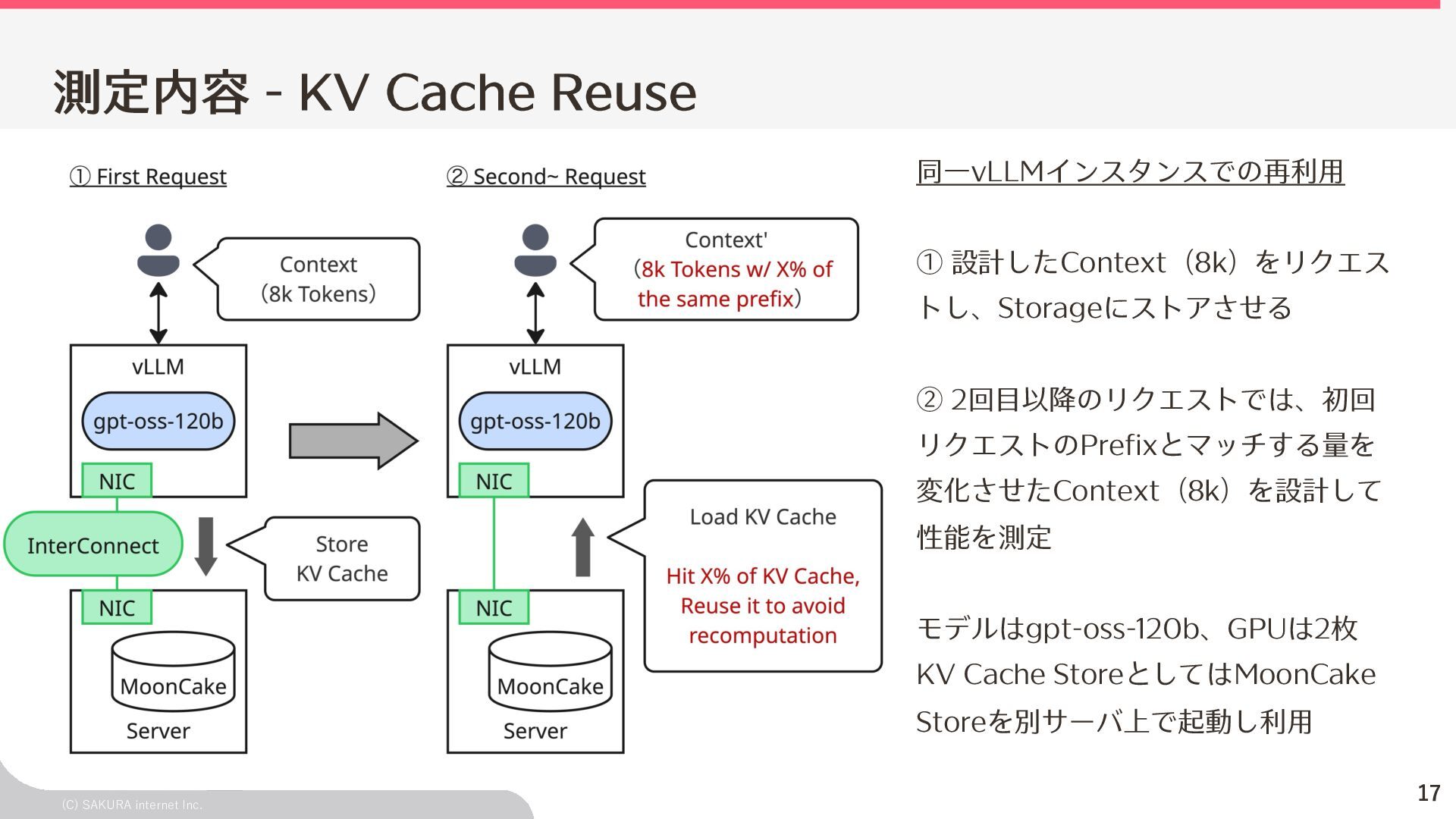{kind=link}
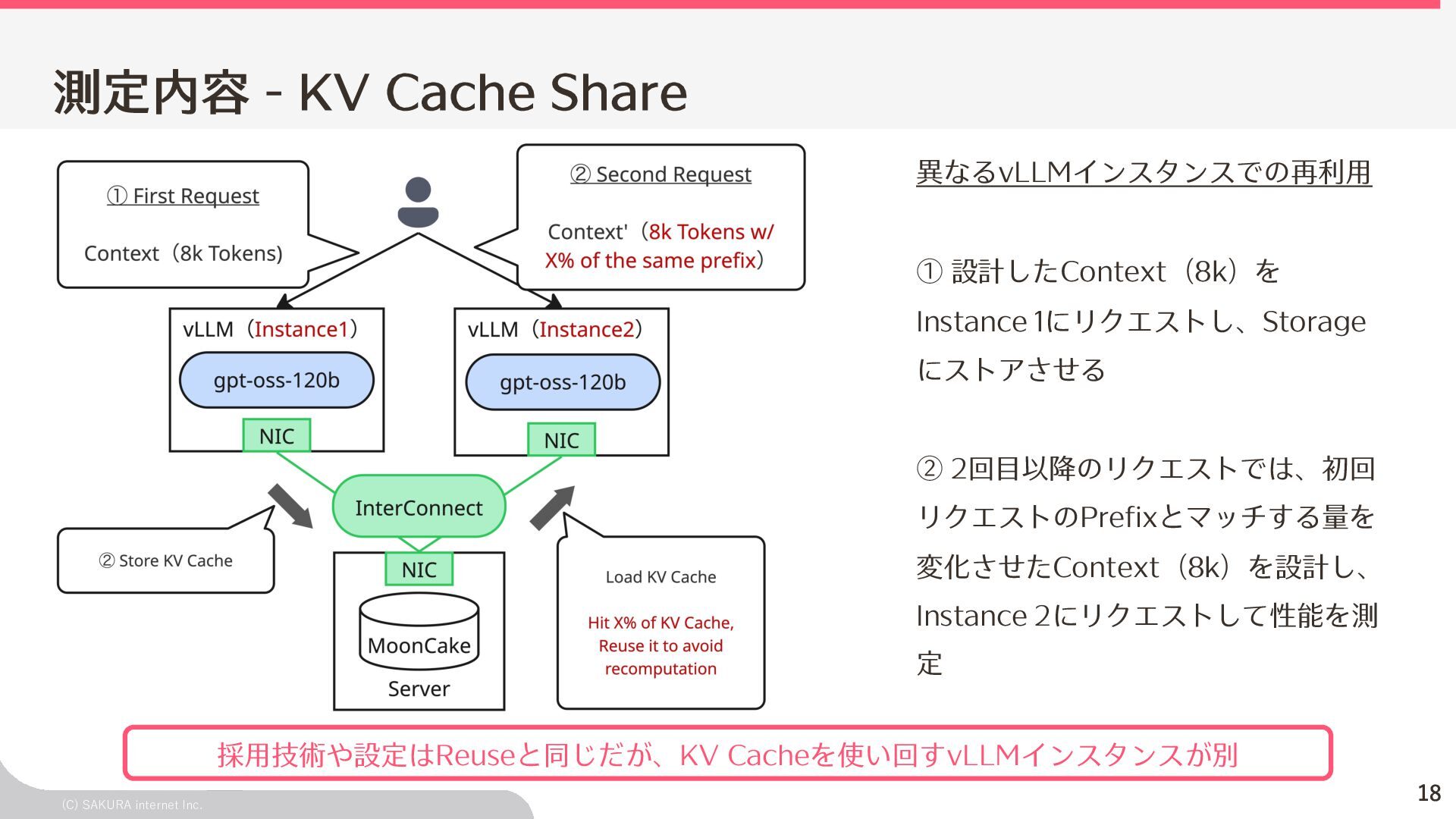{kind=link}
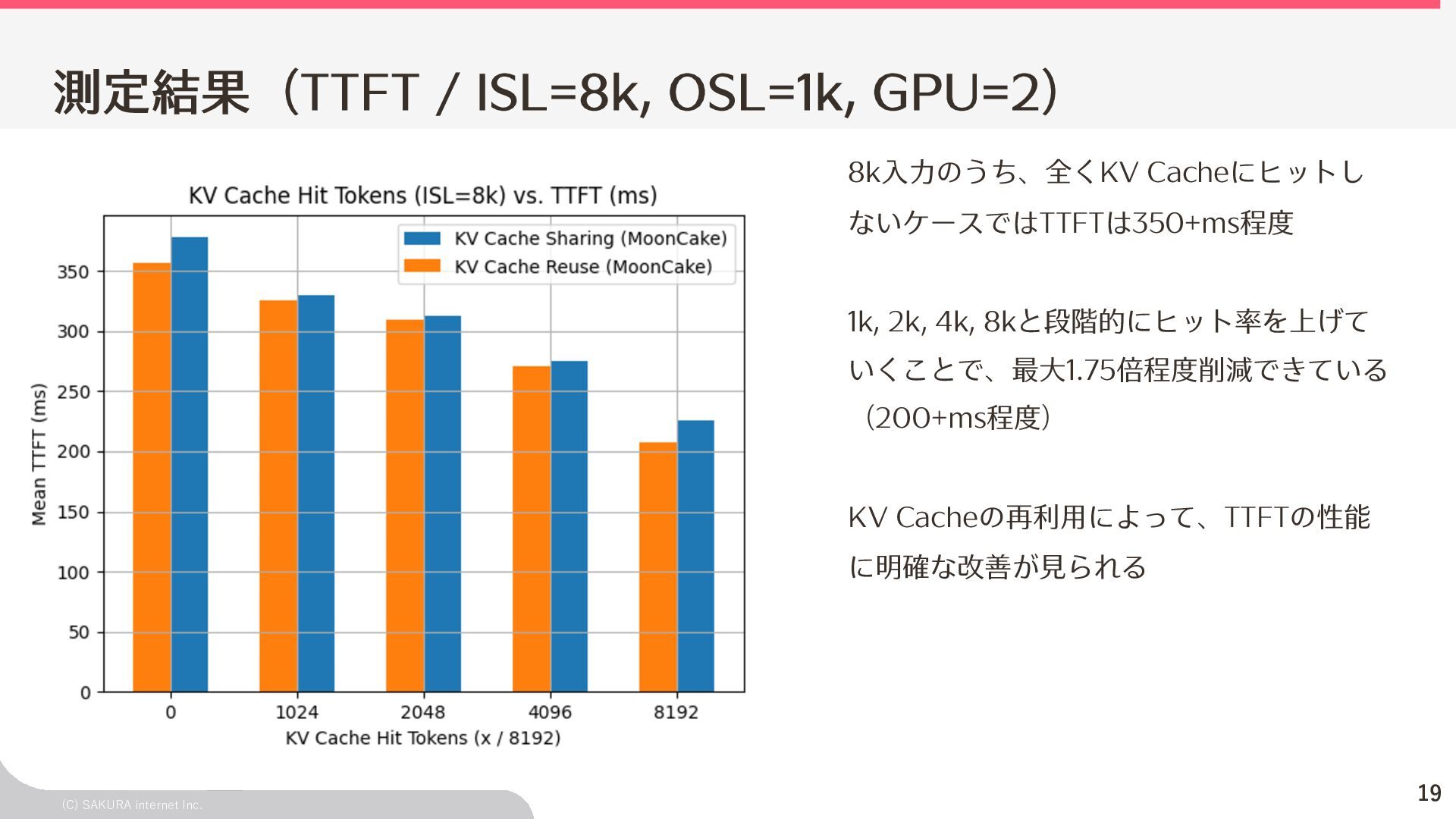{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
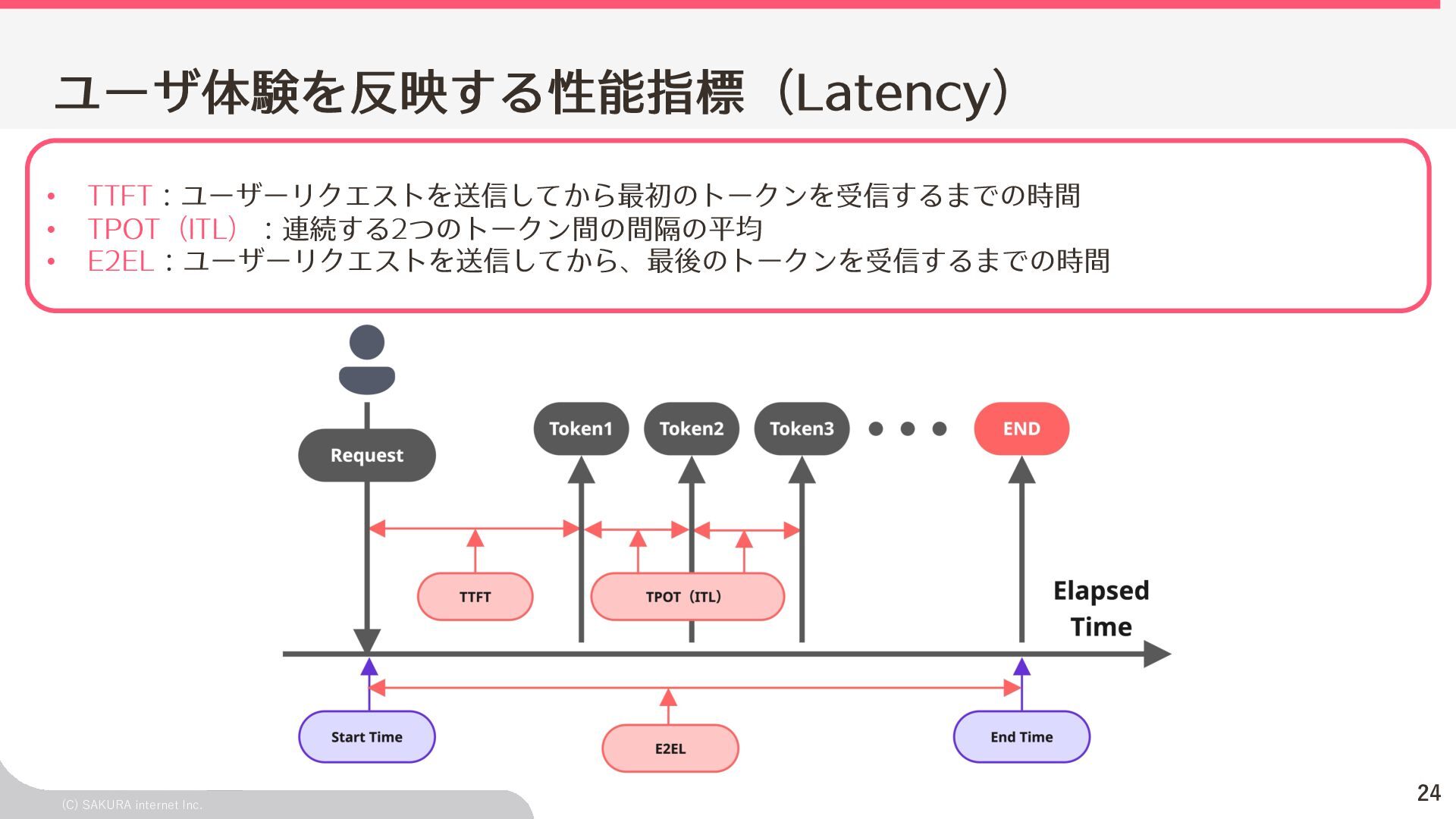{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}