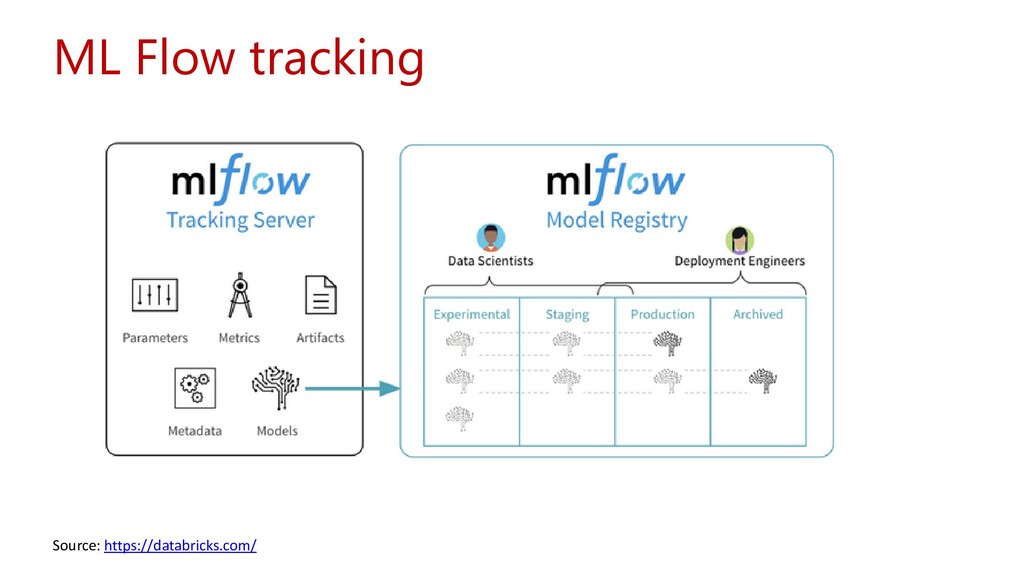
Apache Spark founders - One-click set up; streamlined workflows - Interactive workspace that enables collaboration between data scientists, data engineers, and business analysts - Native Integration with Azure Services (HDFS / Blob storage, Azure DW, Power BI, Functions, ADF gen2,...) - Integrated Azure security and identity management (AD integration, compliance, enterprise-grade SLAs) - March 2019 – MLFlow integration - June 2019 – Delta Lake upgraded version - September 2019 – Databricks ver 6.x + Databricks Koalas - March 2020 – Integration of the Models and MLFlow (+logo redesign) - June 2020 – Spark 3.0 GA release - April 2021 – Databricks Runtime 8.0 - As we speak ☺ Data + AI Databricks Summit 27, 28 May, 2021 A fast, easy and collaborative Apache Spark based analytics platform optimized for Azure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
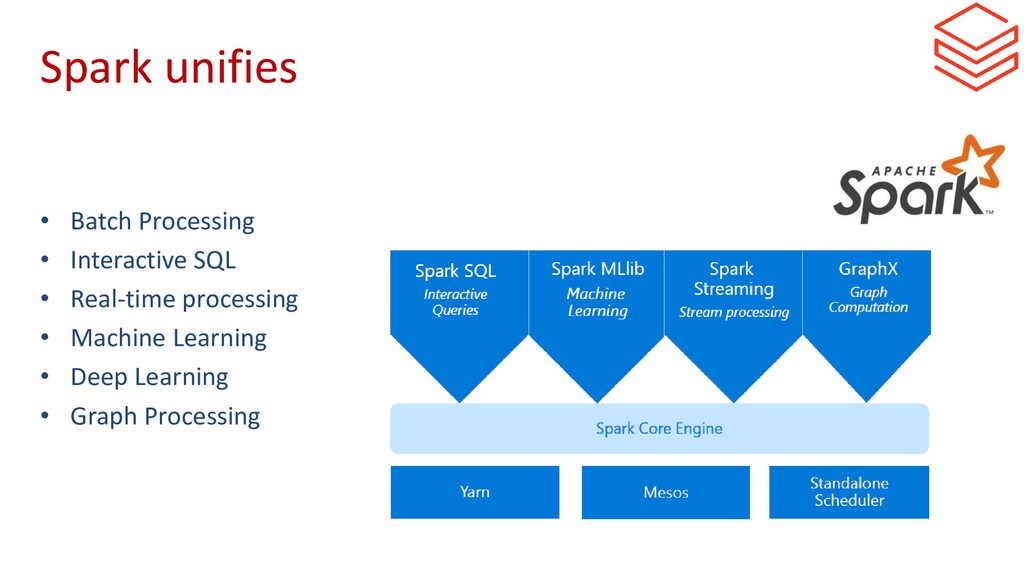{kind=link}
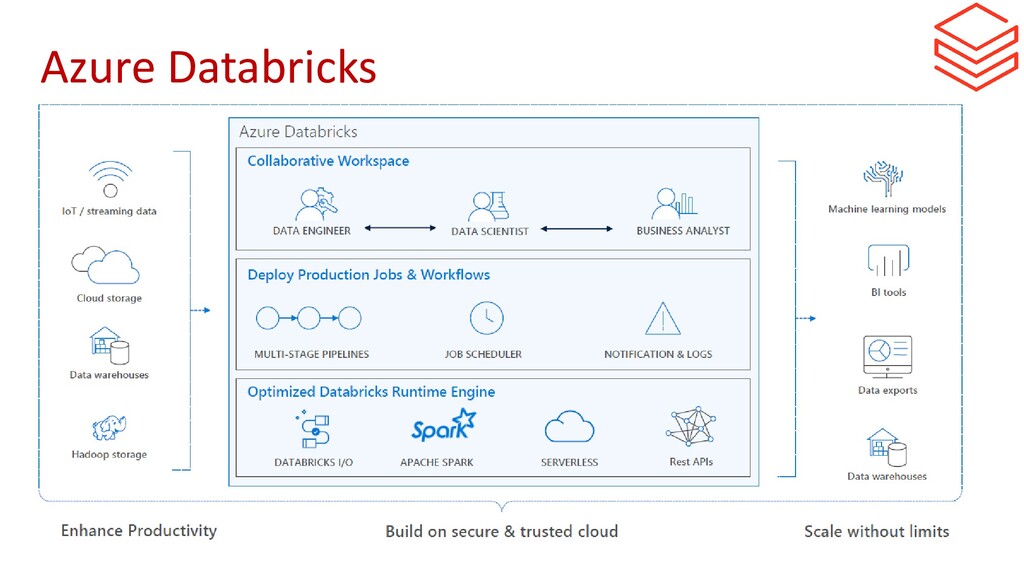{kind=link}
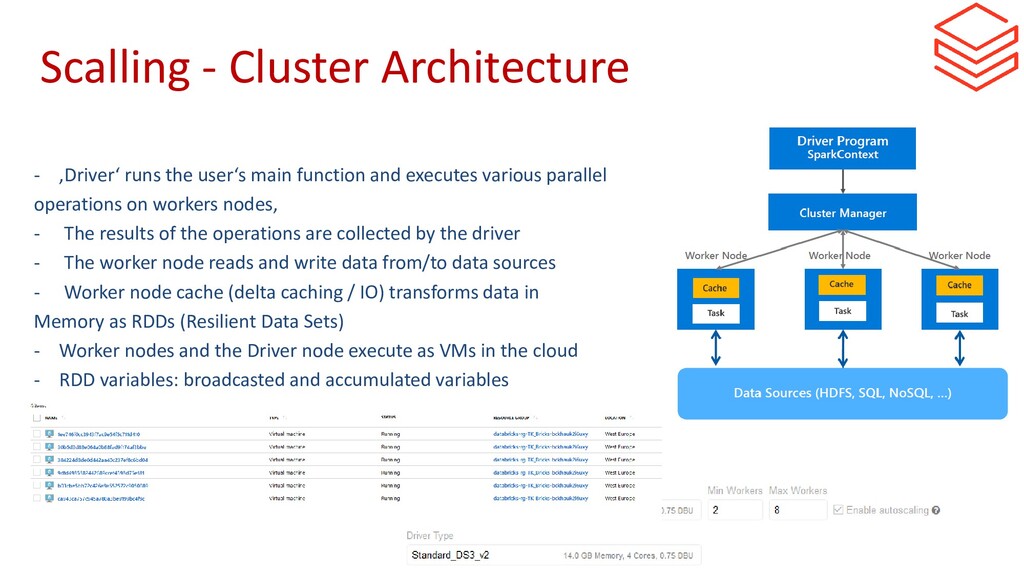{kind=link}
{kind=link}
{kind=link}
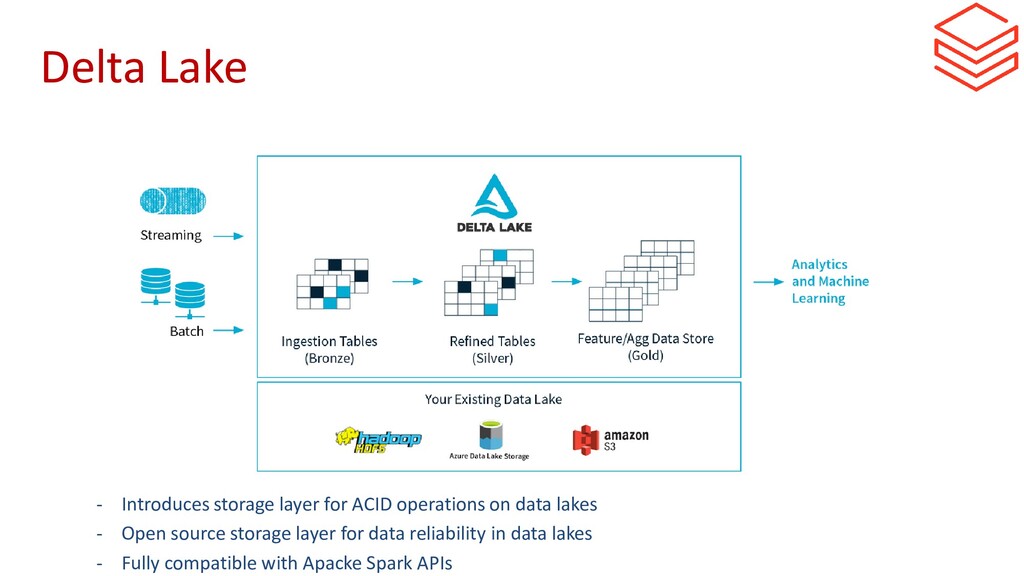{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}