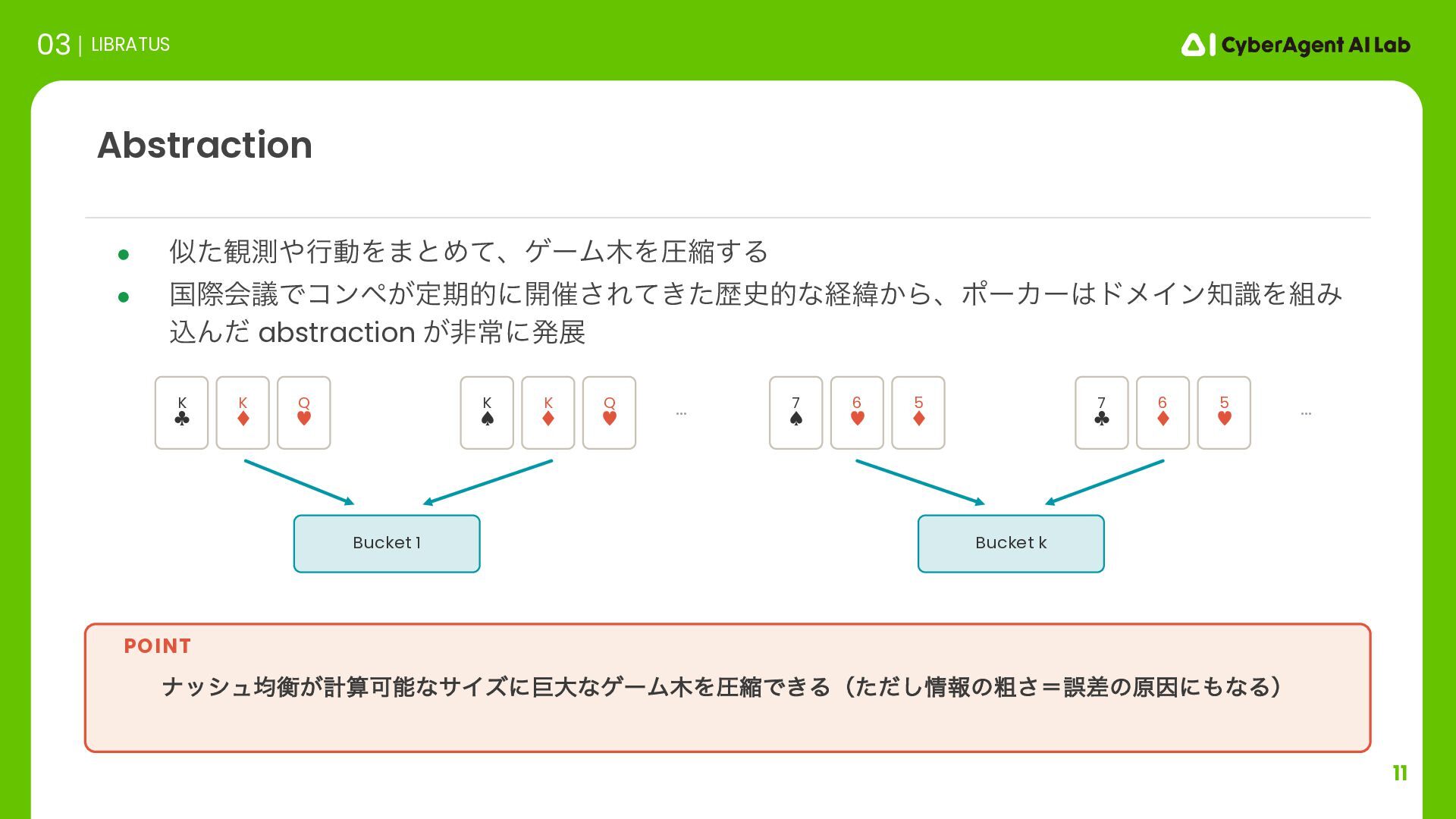
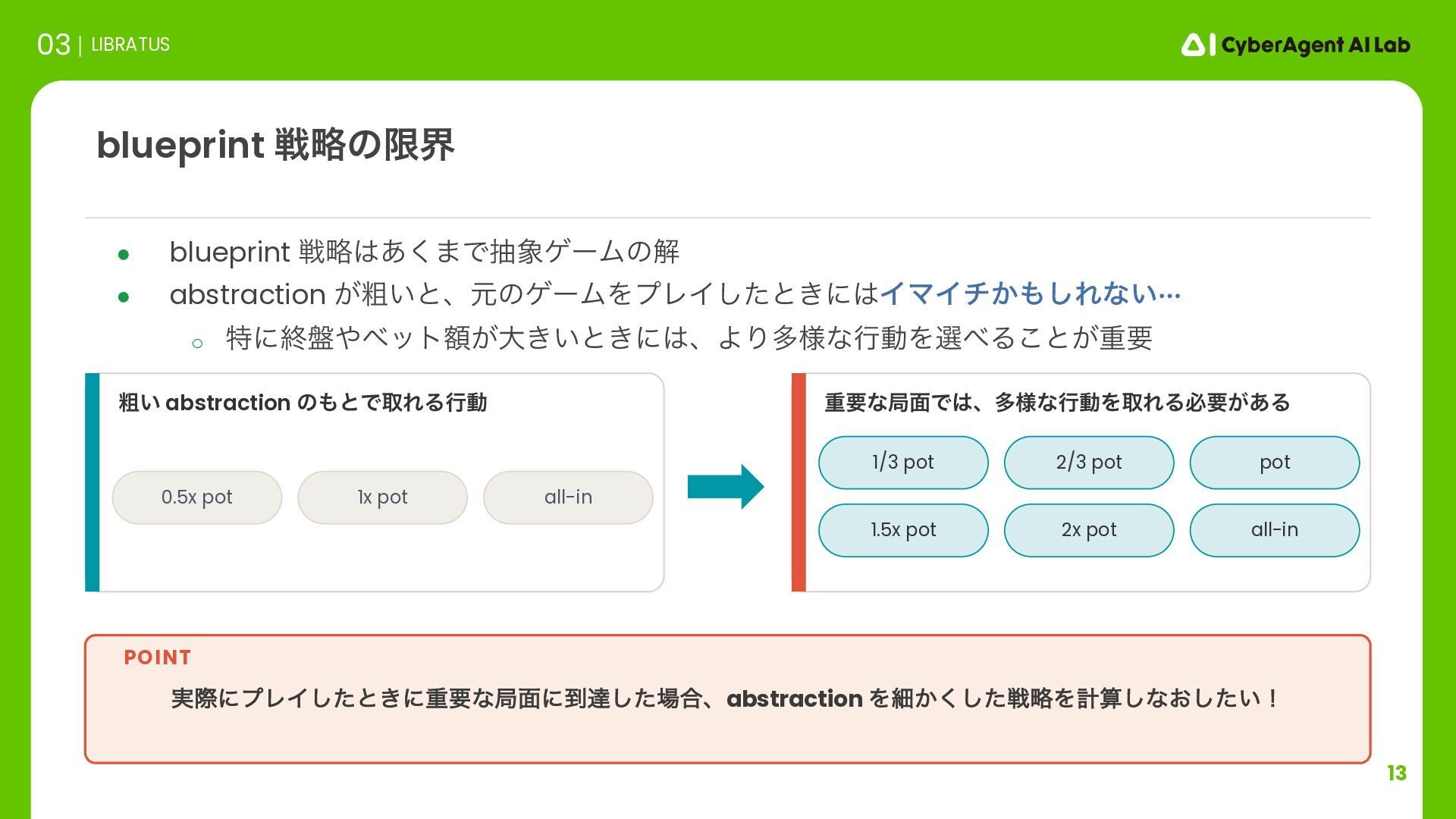
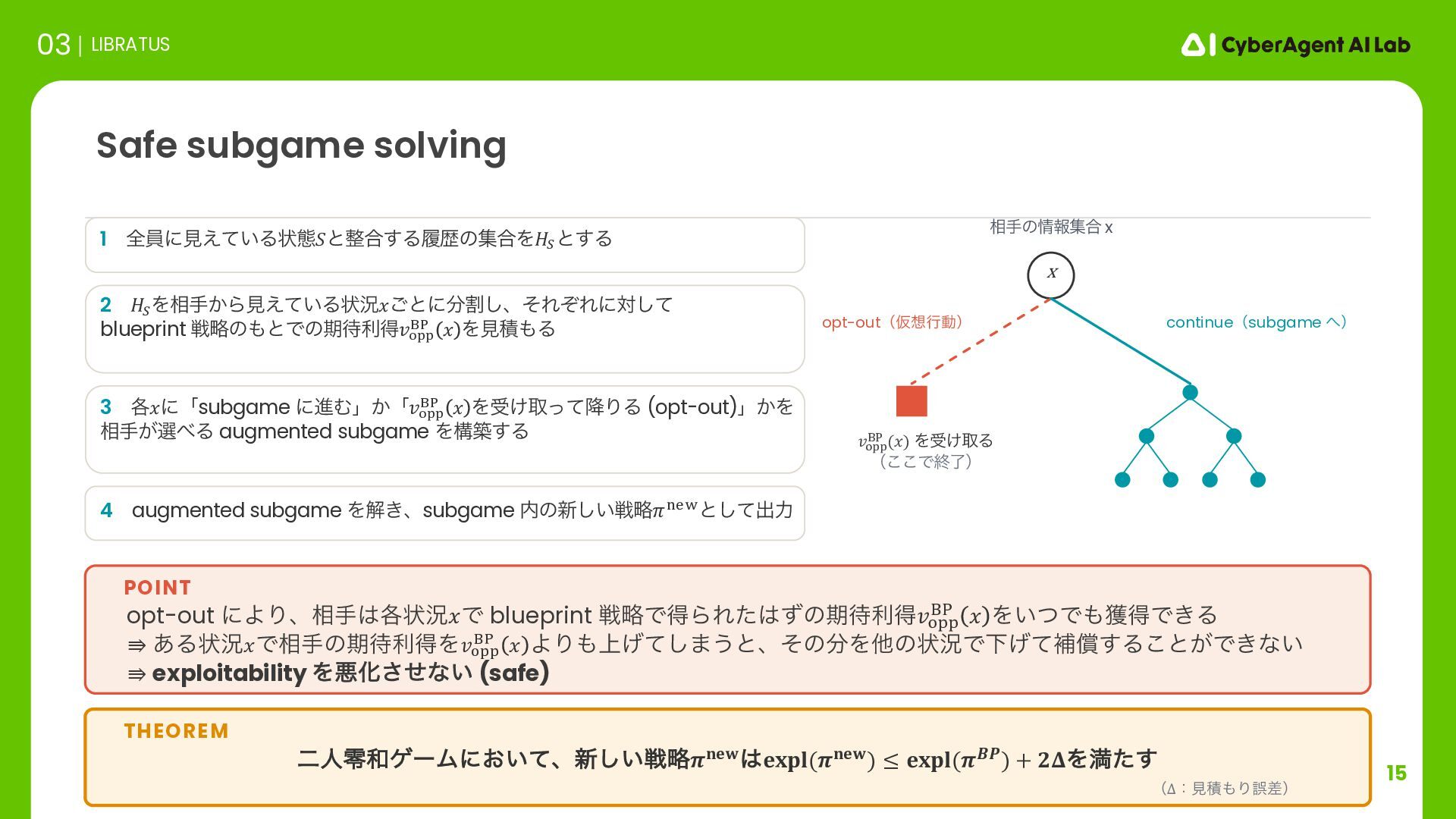
ઓུͷݶք 03 LIBRATUS ૈ͍ abstraction ͷͱͰऔΕΔߦಈ ॏཁͳہ໘Ͱɺଟ༷ͳߦಈΛऔΕΔඞཁ͕͋Δ 0.5x pot 1x pot all-in 1/3 pot 2/3 pot pot 1.5x pot 2x pot all-in ࣮ࡍʹϓϨΠͨ͠ͱ͖ʹॏཁͳہ໘ʹ౸ୡͨ͠߹ɺabstraction Λࡉ͔ͨ͘͠ઓུΛܭࢉ͠ͳ͓͍ͨ͠ʂ POINT
⇛ ϙʔΧʔܕͷ abstraction + subgame solving ͕ద༻͠ʹ͍͘ DeepNash ͱʁ 05 DEEPNASH ہॴతʹղ͖͢ͷͰͳ͘ɺશہ໘Ͱ͑Δ NN ํࡦΛ model-free self-play RL Ͱֶश POINT Perolat et al., lMastering the game of Stratego with model-free multiagent reinforcement learningz, Science 2022
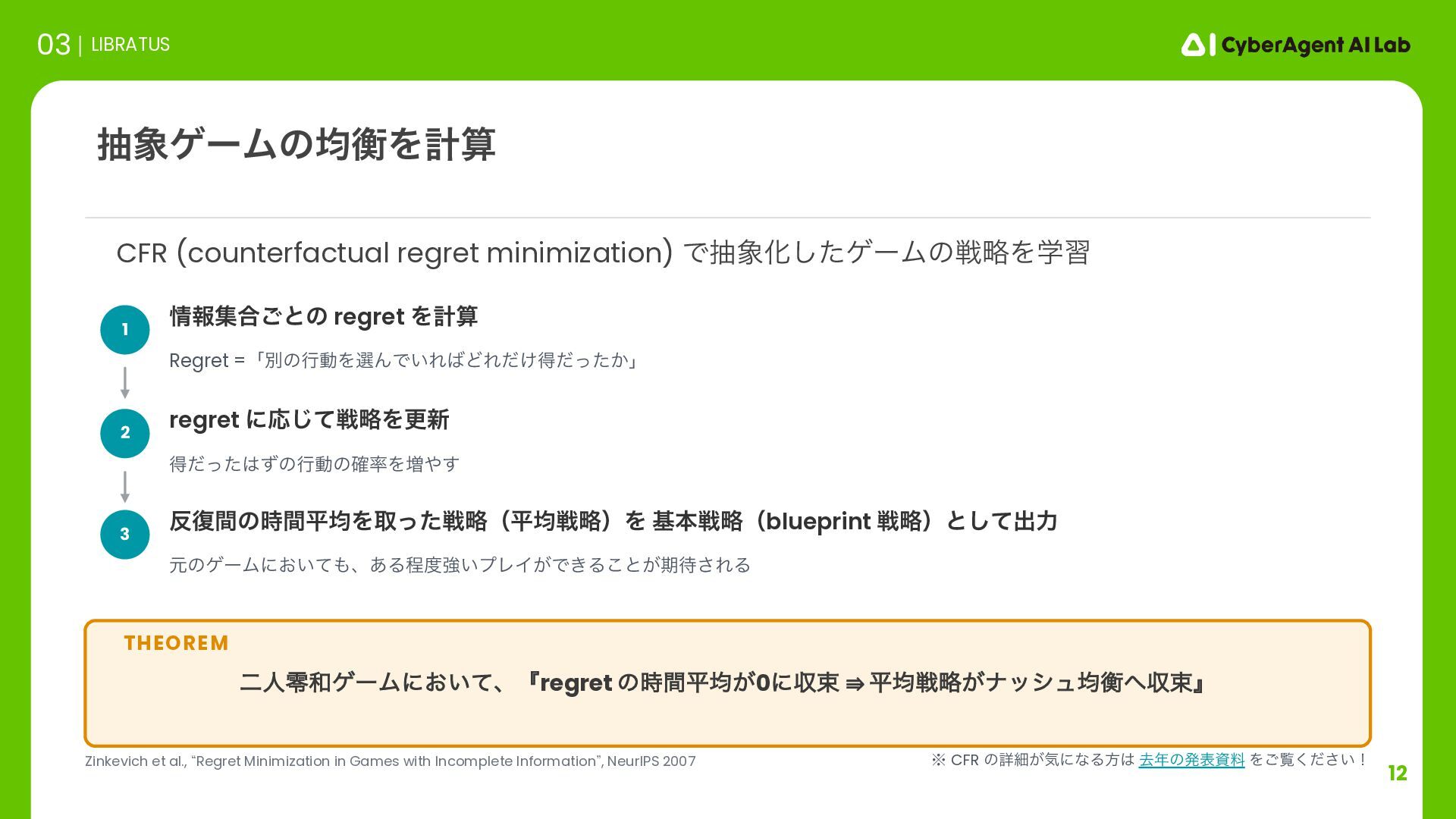
heads-up no-limit poker: Libratus beats top professionals”, Science, 2018. • N. Brown & T. Sandholm, “Safe and Nested Subgame Solving for Imperfect-Information Games”, NeurIPS 2017. • N. Burch, M. Johanson & M. Bowling, “Solving Imperfect Information Games Using Decomposition”, AAAI 2014. • M. Zinkevich, M. Johanson, M. Bowling & C. Piccione, “Regret Minimization in Games with Incomplete Information”, NeurIPS 2007. • N. Brown & T. Sandholm, “Superhuman AI for multiplayer poker”, Science, 2019. • J. Perolat et al., “Mastering the game of Stratego with model-free multiagent reinforcement learning”, Science, 2022. • J. Perolat et al., “From Poincaré Recurrence to Convergence in Imperfect Information Games: Finding Equilibrium via Regularization”, ICML 2021. • K. Abe et al., “Adaptively Perturbed Mirror Descent for Learning in Games”, ICML 2024. ࢀߟจݙ 06 REFERENCES
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}