Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【AIコミュニティLT】私用Databricksで 自宅の温湿度データ可視化してみた
Search
福永 敦史
June 29, 2025
55
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【AIコミュニティLT】私用Databricksで 自宅の温湿度データ可視化してみた
福永 敦史
June 29, 2025
Featured
See All Featured
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
How STYLIGHT went responsive
nonsquared
100
6.2k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
Producing Creativity
orderedlist
PRO
348
40k
Agile that works and the tools we love
rasmusluckow
331
22k
Practical Orchestrator
shlominoach
191
11k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Facilitating Awesome Meetings
lara
57
7k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Become a Pro
speakerdeck
PRO
31
6k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
Transcript
Databricksを使って 解決したいビジネス課題
How What Why
How What Why 目的 IT技術
疲れてませんか?
純粋に技術を楽しめていますか?
How What Why IT技術 目的 が好き!!
Databricksを使って 解決したいビジネス課題
Databricksを使って 解決したいビジネス課題 私用Databricksで 自宅の温湿度データ可視化してみた!!
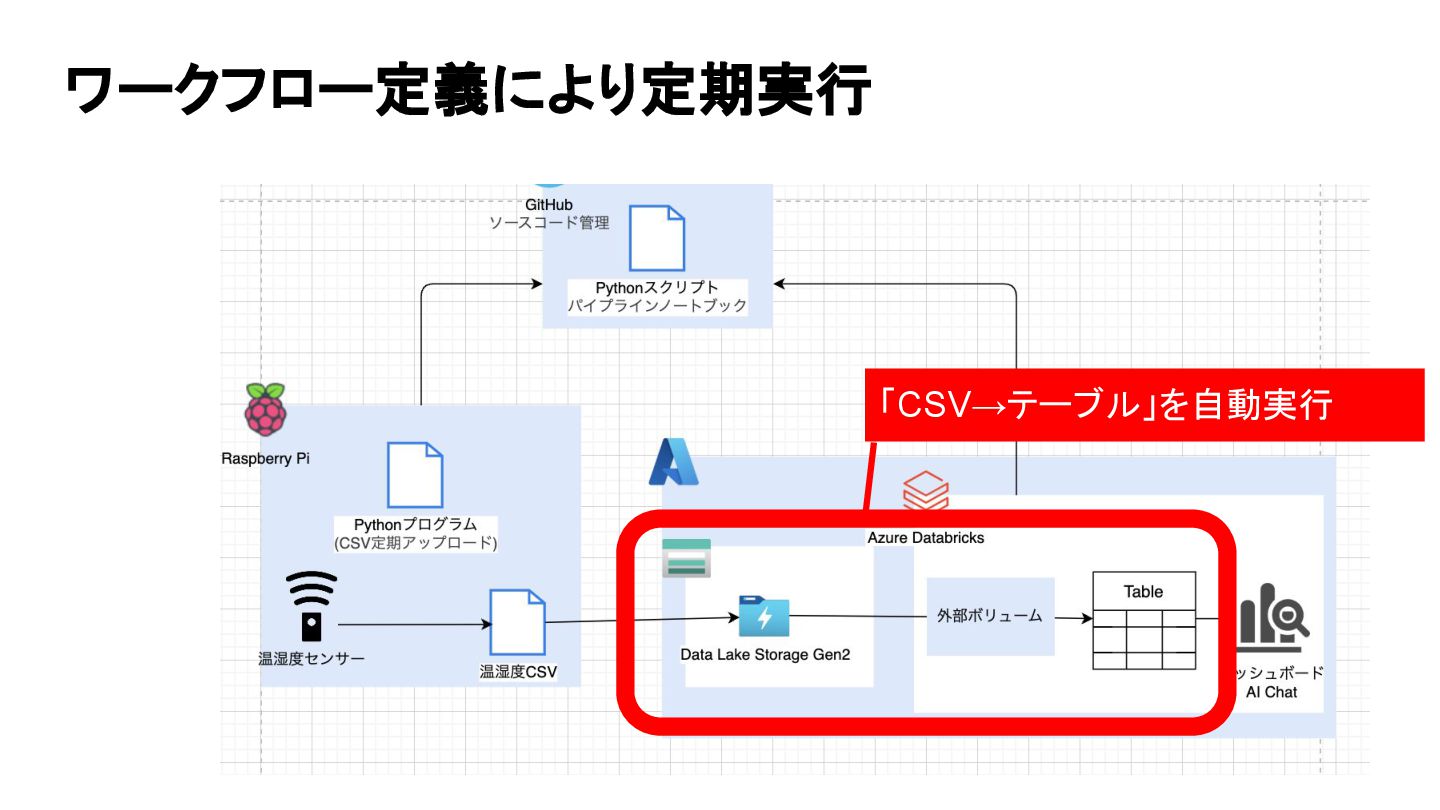
開発手法・アーキテクチャ リポジトリ: https://github.com/balle-mech/raspi-temp-humidity-pipeline
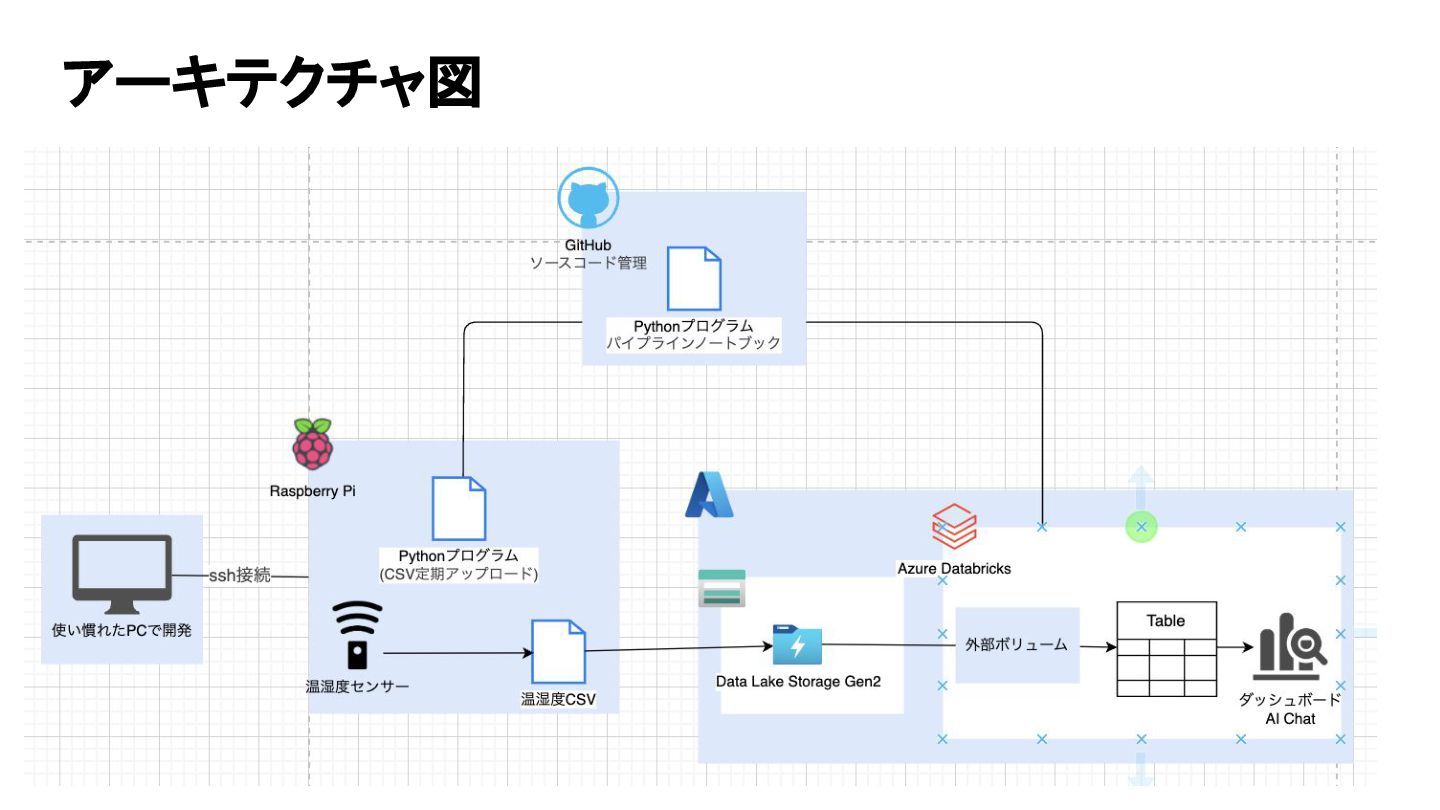
アーキテクチャ図
センサー各種 温湿度センサー Raspberry Pi5
========= CSVファイル ============= タイムスタンプ、温度(℃)、湿度(%) 2025-04-08 16:53:04,20,46 2025-04-08 16:55:04,20,46 ============================== ・カラムの説明 タイムスタンプ:計測時間 温度
(℃):温度 湿度(%):湿度 取得する温湿度データ
・5分に一度計測しCSVファイルに書き込む ・週一回CSVファイルをAzureのBlobストレージにアップロード 計測間隔
解決策として使用したLinuxコマンド nohup python3 /${ファイルパス}/measure_upload.py > output.log 2>&1 & nohup ・「no
hang up(ハングアップしない)」の略 ・シェルを終了してもプログラムが実行し続けられるようにするためのコマンド ・&:コマンドをバックグラウンドで実行するための記号 ・2>&1:標準エラー出力を標準出力にマージ 参考:https://qiita.com/digger/items/7a35b632995d6b54bf59 , https://note.com/ym202110/n/ndaf6ea2b0ce7 課題:SSH接続を切ると計測が終了してしまう
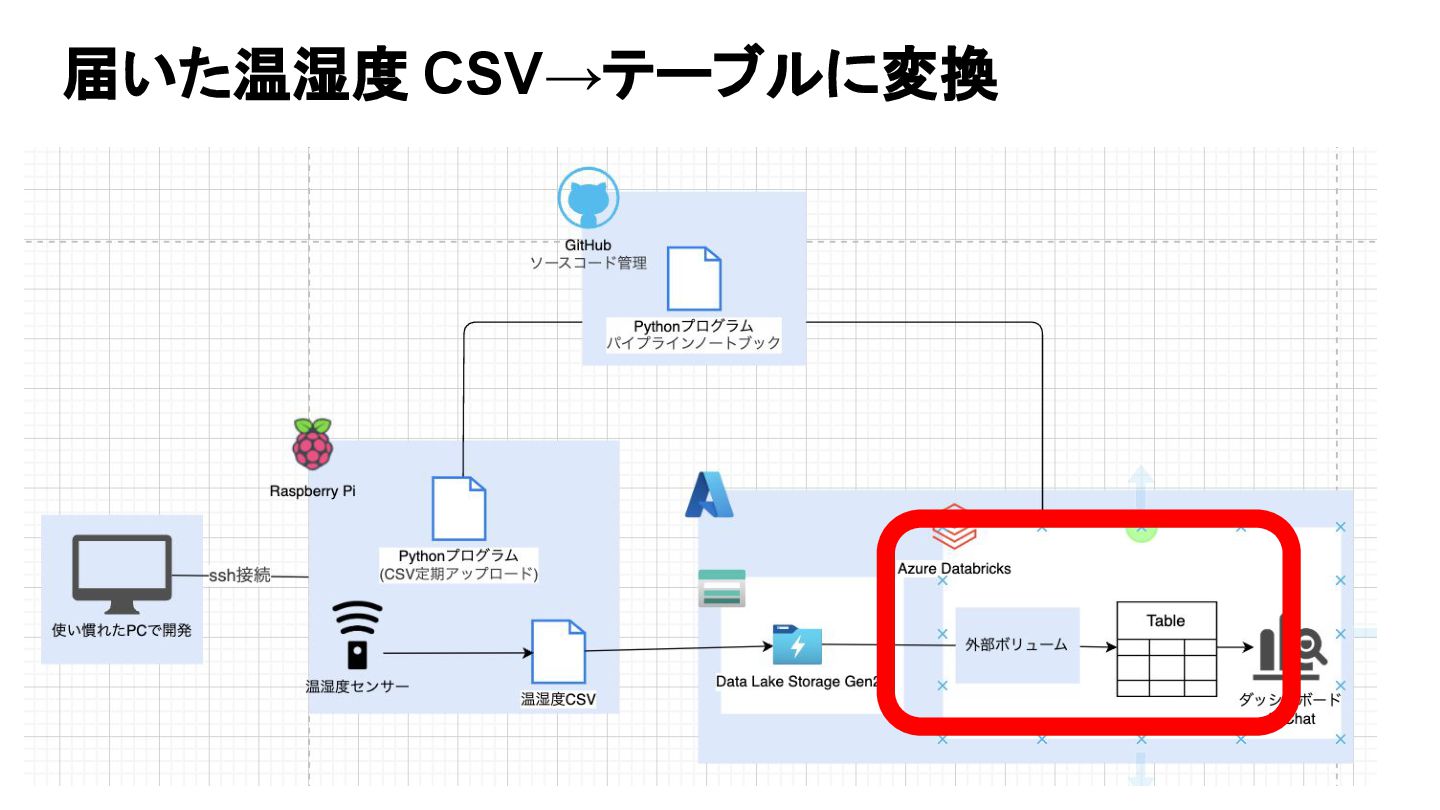
届いた温湿度 CSV→テーブルに変換
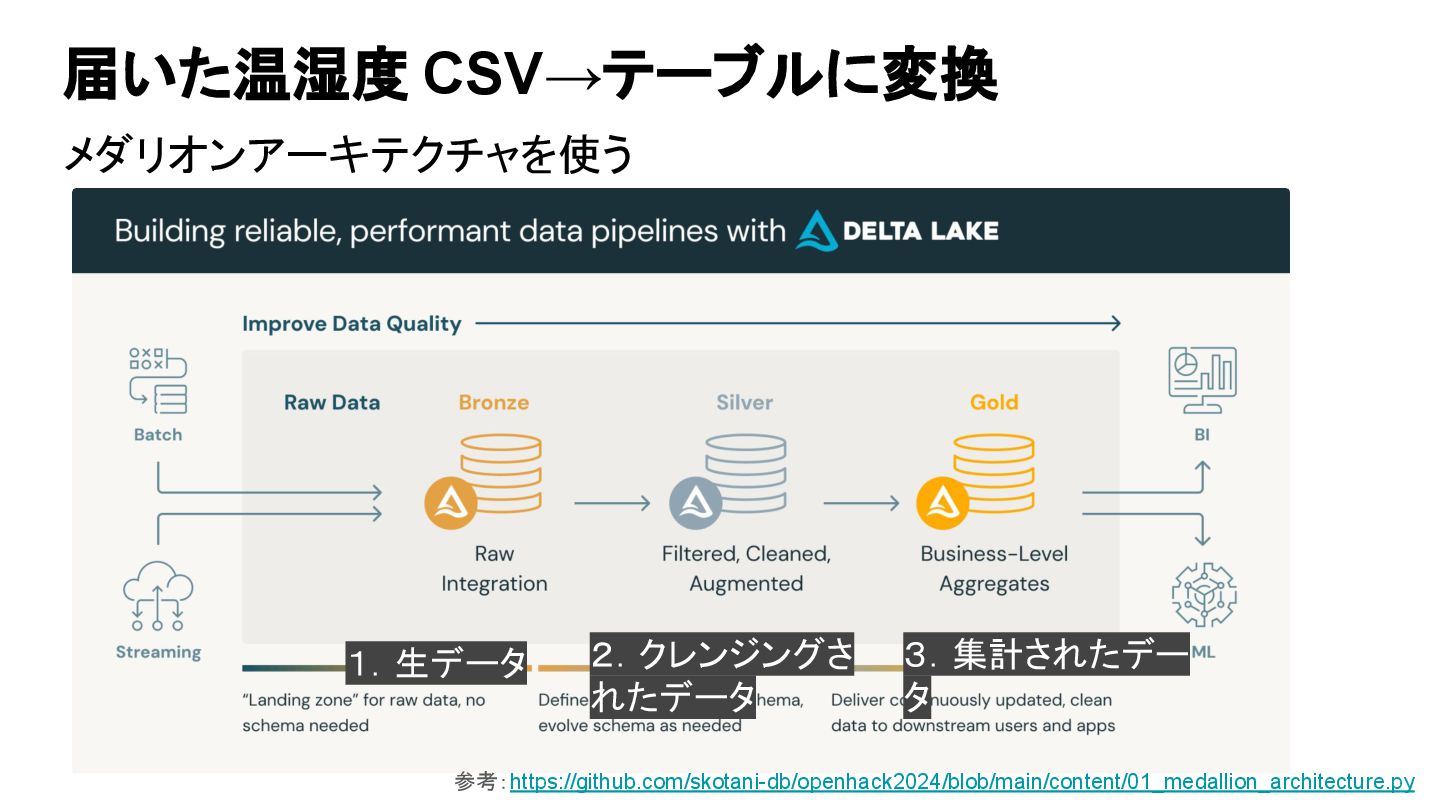
届いた温湿度 CSV→テーブルに変換 メダリオンアーキテクチャを使う 1.生データ 2.クレンジングさ れたデータ 3.集計されたデー タ 参考:https://github.com/skotani-db/openhack2024/blob/main/content/01_medallion_architecture.py
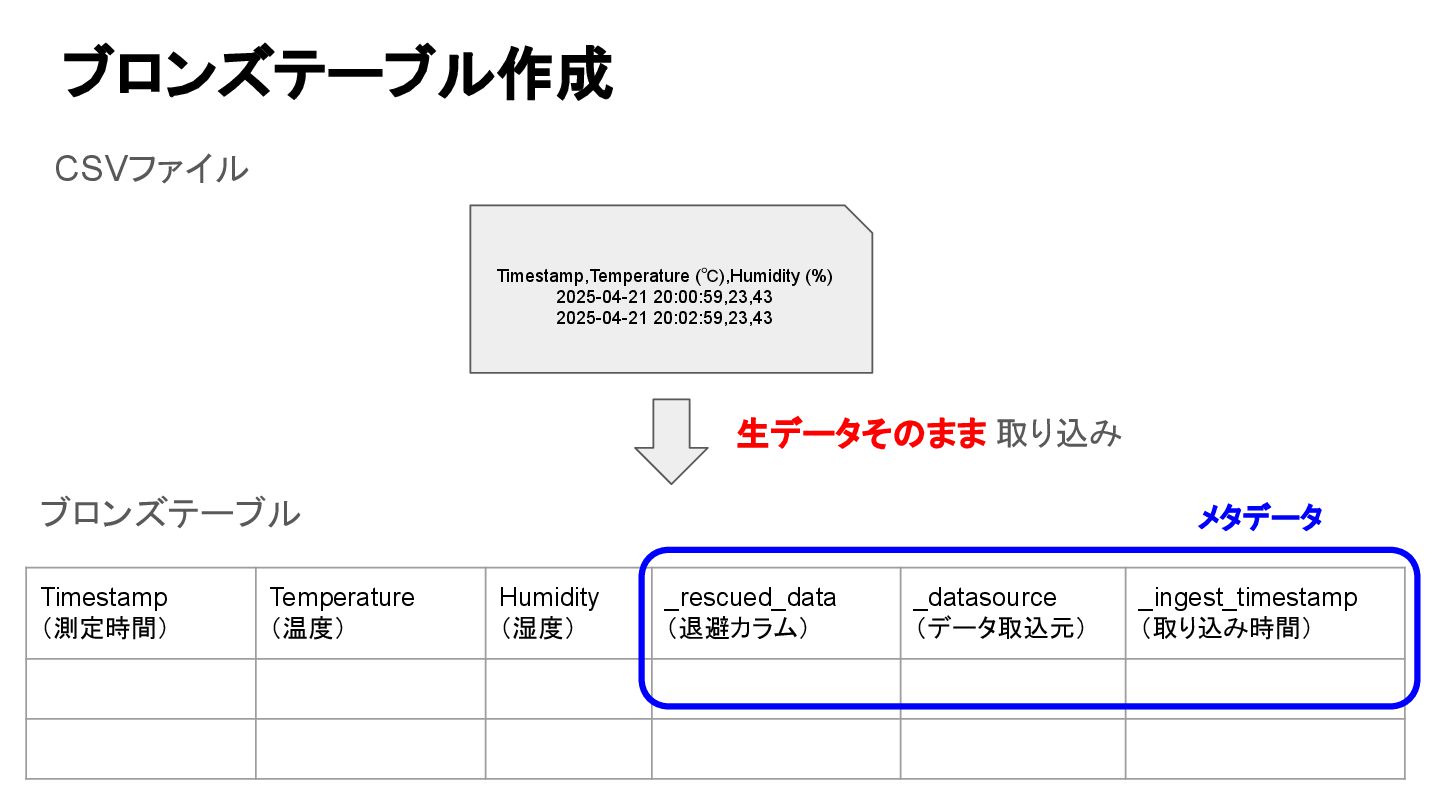
Timestamp (測定時間) Temperature (温度) Humidity (湿度) _rescued_data (退避カラム) _datasource (データ取込元)
_ingest_timestamp (取り込み時間) このような空のテーブルを作成 メタデータ ブロンズテーブル作成
Timestamp (測定時間) Temperature (温度) Humidity (湿度) _rescued_data (退避カラム) _datasource (データ取込元)
_ingest_timestamp (取り込み時間) ブロンズテーブル Timestamp,Temperature (℃),Humidity (%) 2025-04-21 20:00:59,23,43 2025-04-21 20:02:59,23,43 CSVファイル 生データそのまま 取り込み メタデータ ブロンズテーブル作成
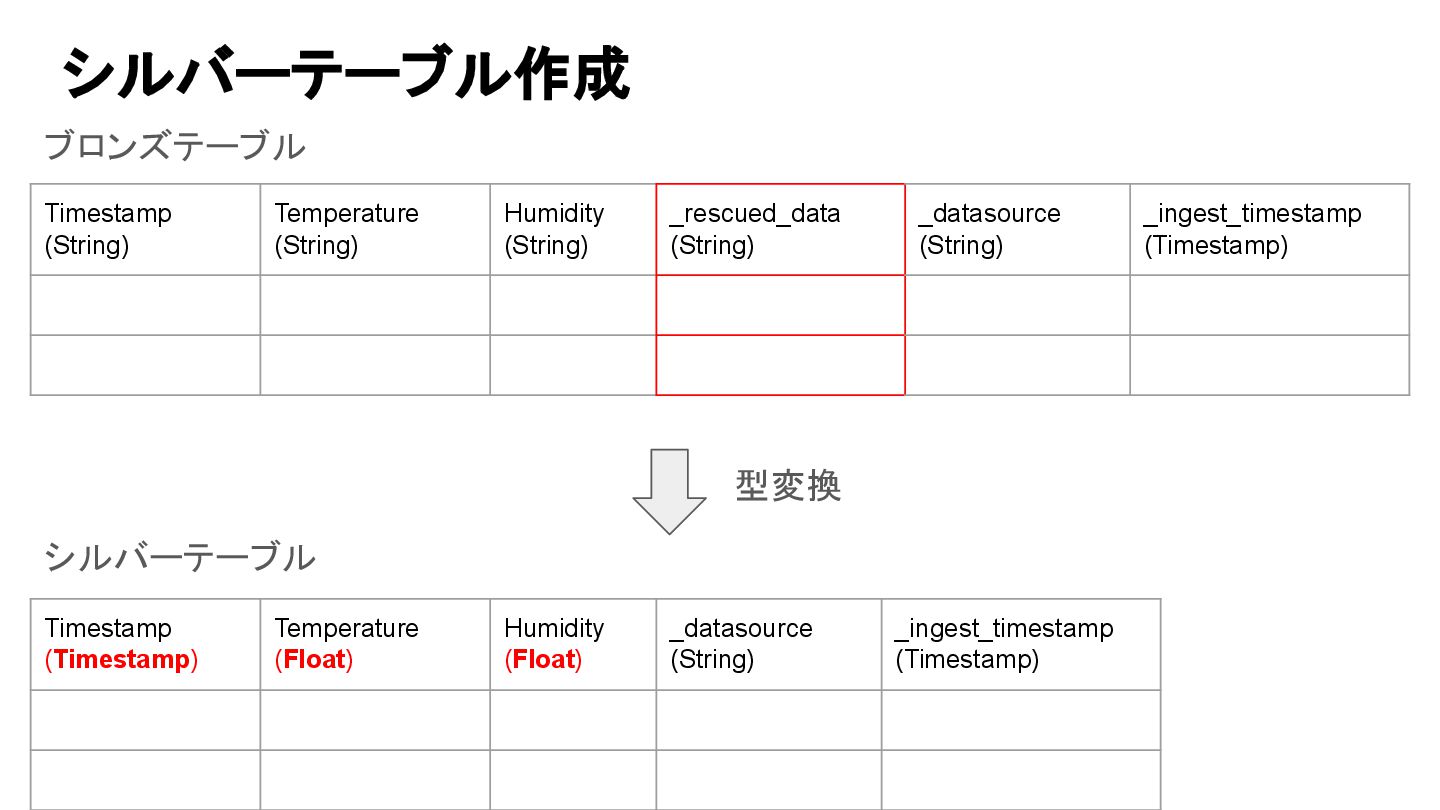
Timestamp (String) Temperature (String) Humidity (String) _rescued_data (String) _datasource (String)
_ingest_timestamp (Timestamp) 型変換 Timestamp (Timestamp) Temperature (Float) Humidity (Float) _datasource (String) _ingest_timestamp (Timestamp) シルバーテーブル ブロンズテーブル シルバーテーブル作成
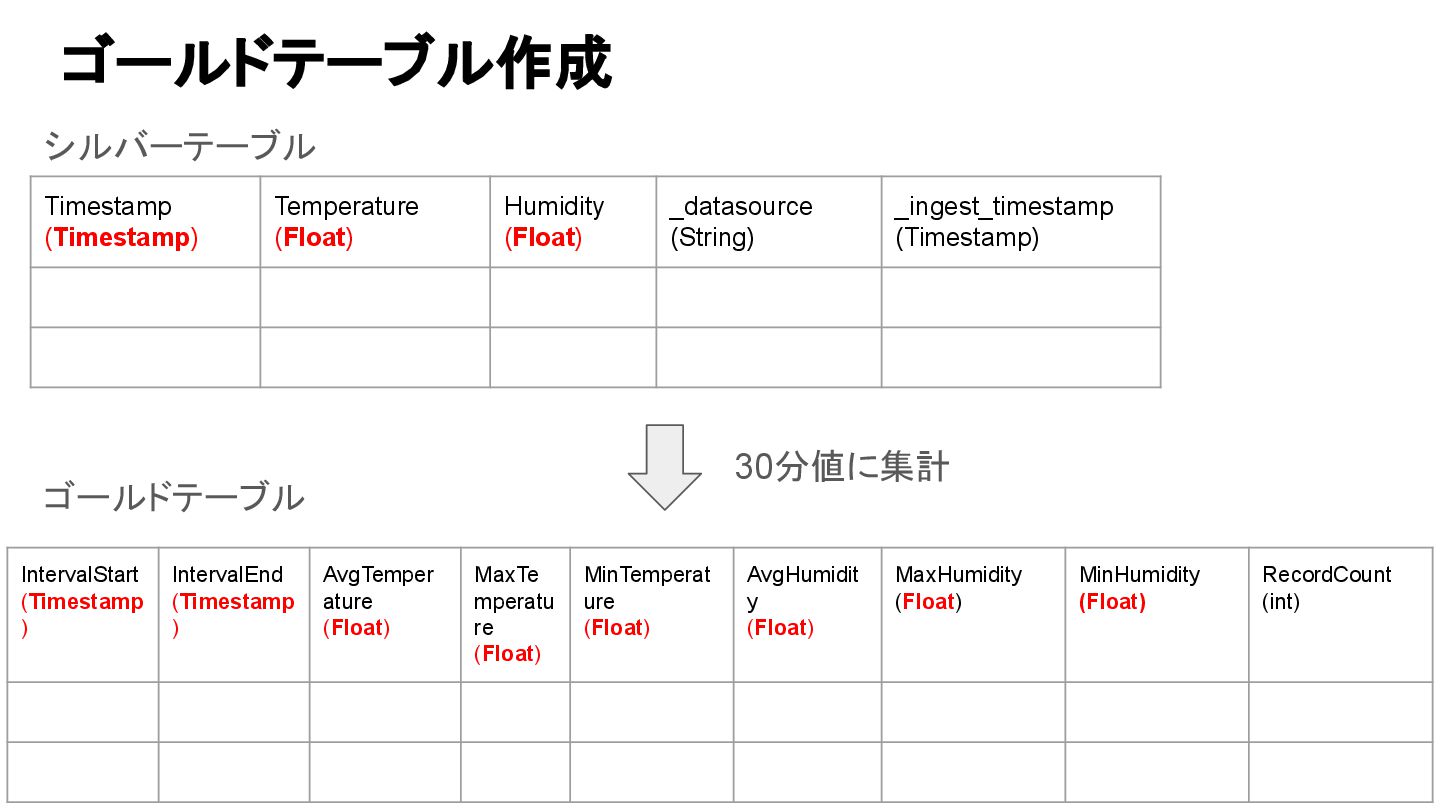
30分値に集計 IntervalStart (Timestamp ) IntervalEnd (Timestamp ) AvgTemper ature (Float)
MaxTe mperatu re (Float) MinTemperat ure (Float) AvgHumidit y (Float) MaxHumidity (Float) MinHumidity (Float) RecordCount (int) ゴールドテーブル シルバーテーブル ゴールドテーブル作成 Timestamp (Timestamp) Temperature (Float) Humidity (Float) _datasource (String) _ingest_timestamp (Timestamp)
ワークフロー定義により定期実行 「CSV→テーブル」を自動実行
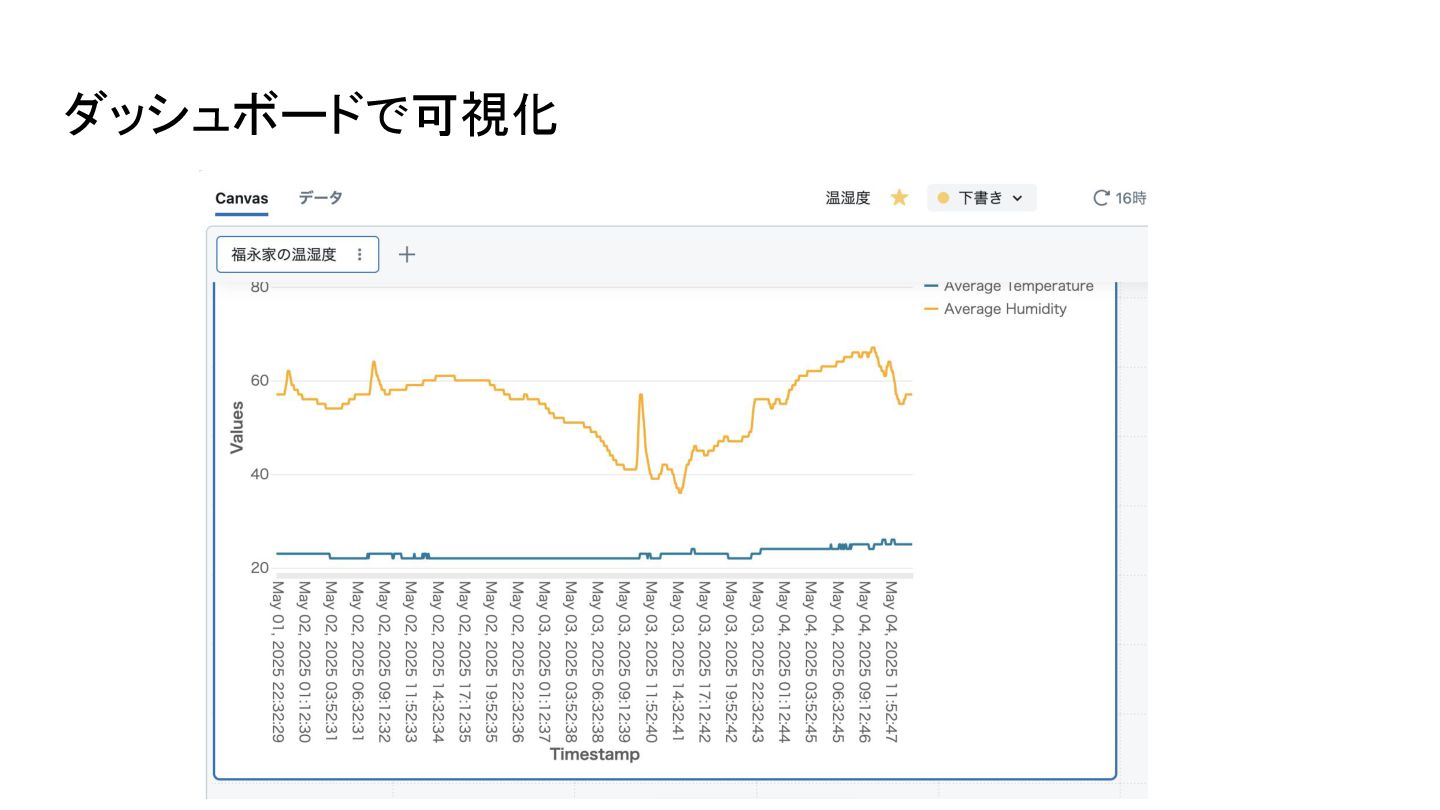
ダッシュボードで可視化
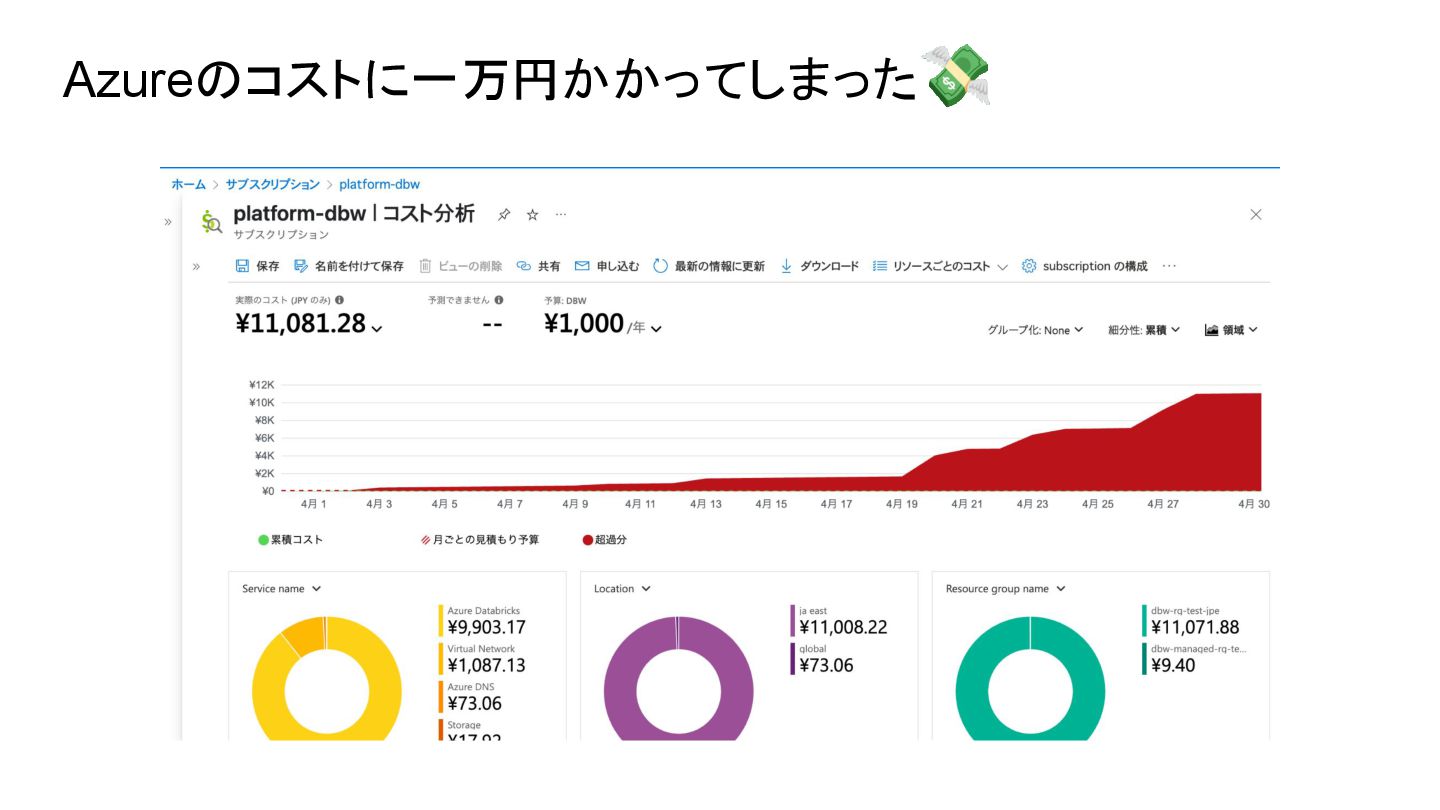
テーブル化できて、めでたしめでたし
テーブル化できて、めでたしめでたし 大問題発生
Azureのコストに一万円かかってしまった💸
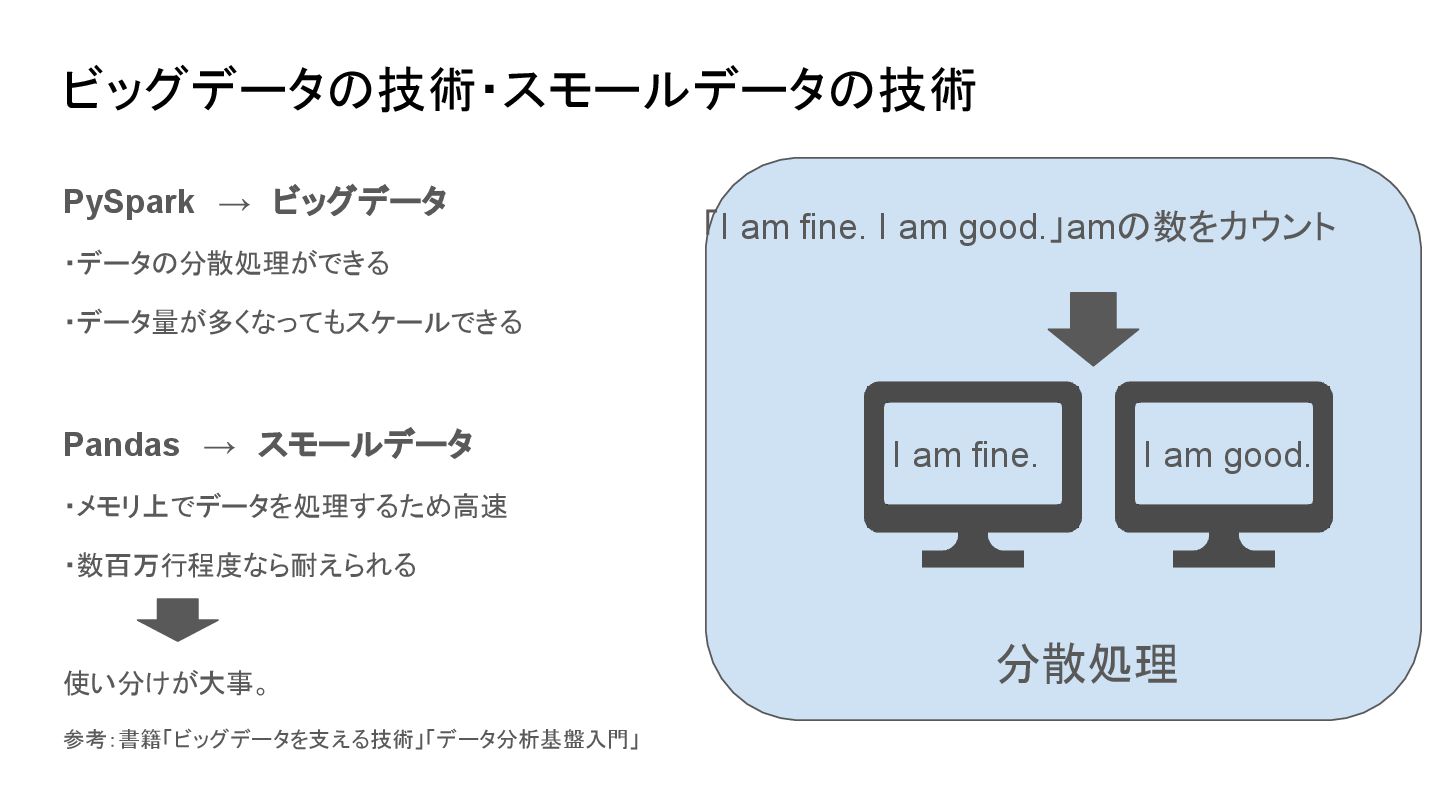
ビッグデータの技術・スモールデータの技術 PySpark → ビッグデータ ・データの分散処理ができる ・データ量が多くなってもスケールできる Pandas → スモールデータ ・メモリ上でデータを処理するため高速 ・数百万行程度なら耐えられる 使い分けが大事。 参考:書籍「ビッグデータを支える技術」「データ分析基盤入門」 「I
am fine. I am good.」amの数をカウント I am fine. I am good. 分散処理
伝えたかったこと ・技術の楽しさ ・データ加工の話 ・やっぱりWhat・Whyは大事 今後の展望 オープンデータとの統合
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}