& serverless data preparation” • Business People focused • “Excell” like • See data + statistics • Just push “Run” button… • Presentation: https://www.youtube.com/watch?v=Q5GuTIgmt98
• See & “feel” data • Help before developing • Stats: outliers, skew • For Business: • Before: 1st analysis better Jiras • After: validate with stats
{kind=link}
![Make the elephant fly, once again Luangsay Sourygna [email protected]](https://files.speakerdeck.com/presentations/afffb9f2cbd84f719bbcf3bcdc007df8/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
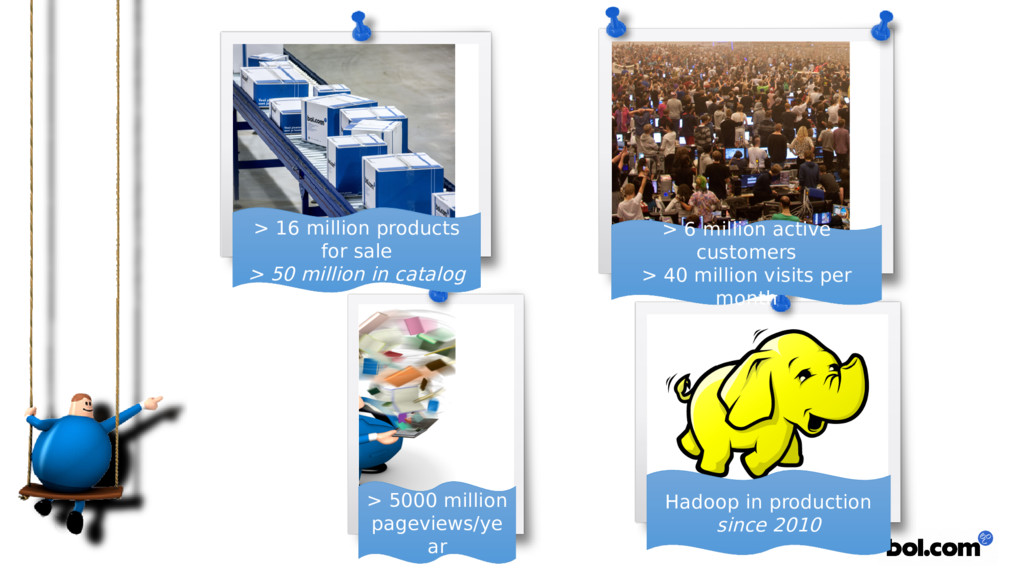{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
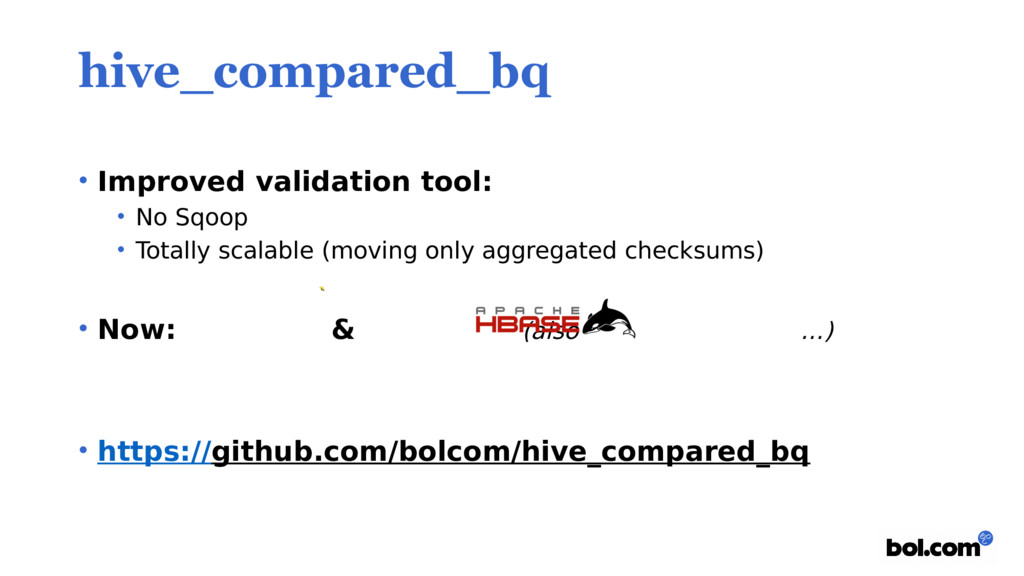{kind=link}
{kind=link}
{kind=link}
{kind=link}
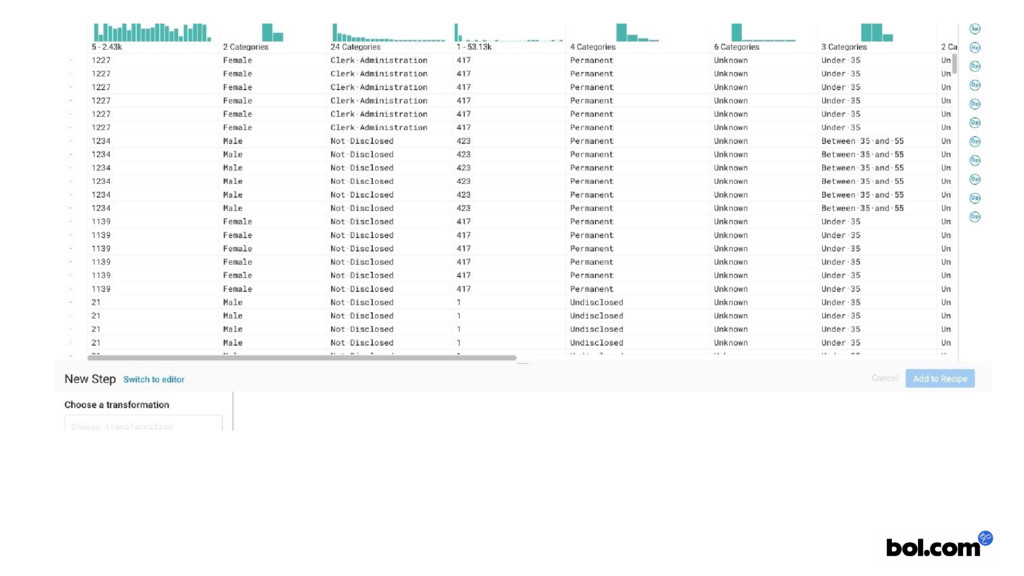{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks till next bol.com Sourygna Luangsay [email protected]](https://files.speakerdeck.com/presentations/afffb9f2cbd84f719bbcf3bcdc007df8/slide_32.jpg){kind=link}