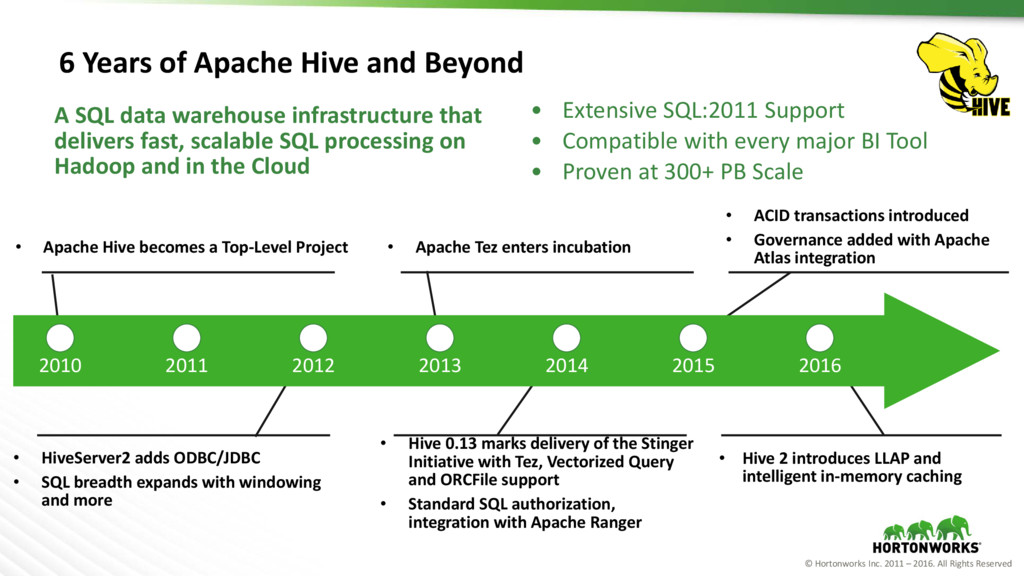
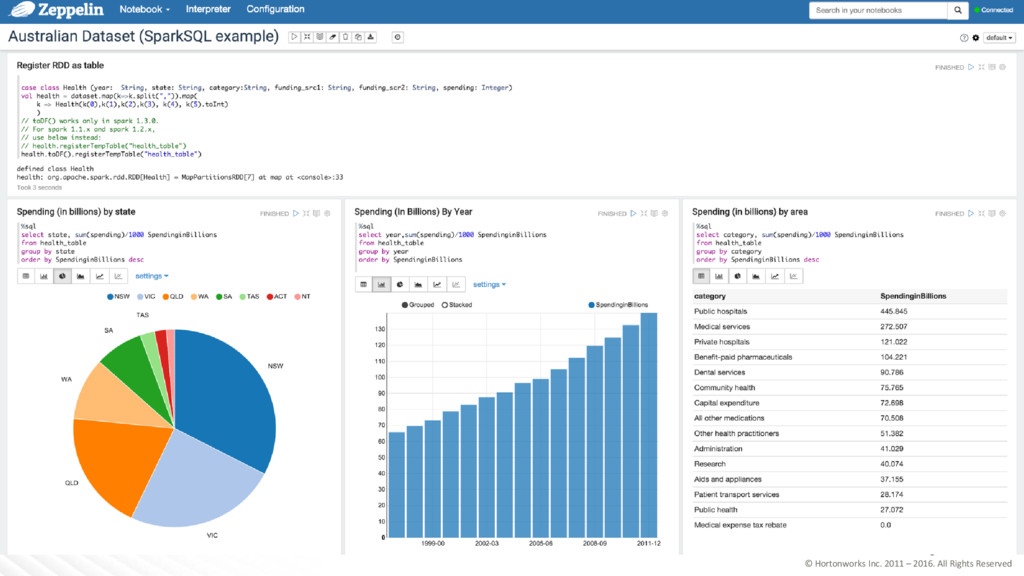
Years of Apache Hive and Beyond • Apache Hive becomes a Top-Level Project • HiveServer2 adds ODBC/JDBC • SQL breadth expands with windowing and more • Apache Tez enters incubation • Hive 0.13 marks delivery of the Stinger Initiative with Tez, Vectorized Query and ORCFile support • Standard SQL authorization, integration with Apache Ranger • ACID transactions introduced • Governance added with Apache Atlas integration • Hive 2 introduces LLAP and intelligent in-memory caching 2010 2011 2012 2013 2014 2015 2016 A SQL data warehouse infrastructure that delivers fast, scalable SQL processing on Hadoop and in the Cloud • Extensive SQL:2011 Support • Compatible with every major BI Tool • Proven at 300+ PB Scale
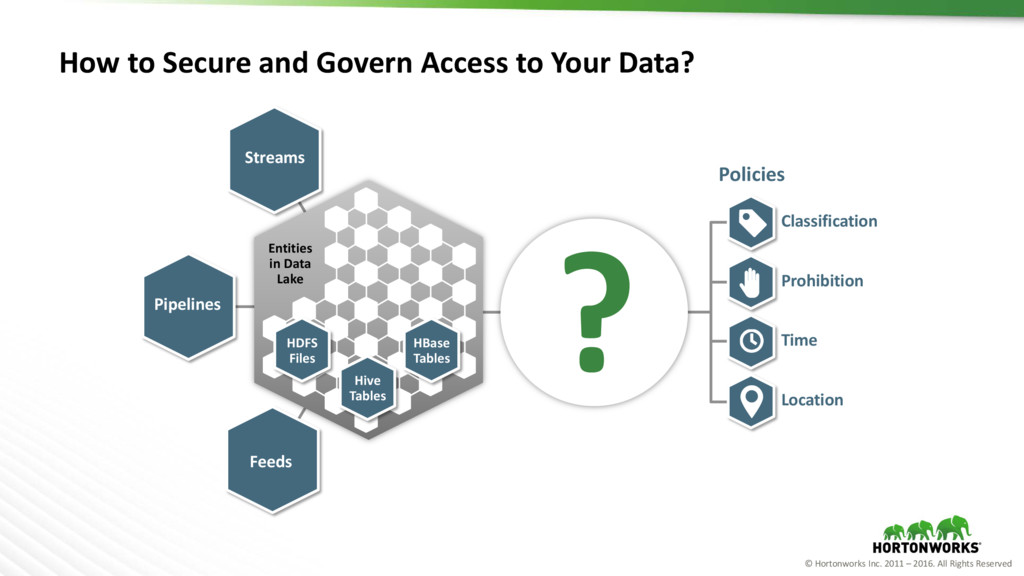
to Secure and Govern Access to Your Data? Classification Prohibition Time Location Streams Pipelines Feeds Hive Tables HDFS Files HBase Tables Entities in Data Lake Policies ?
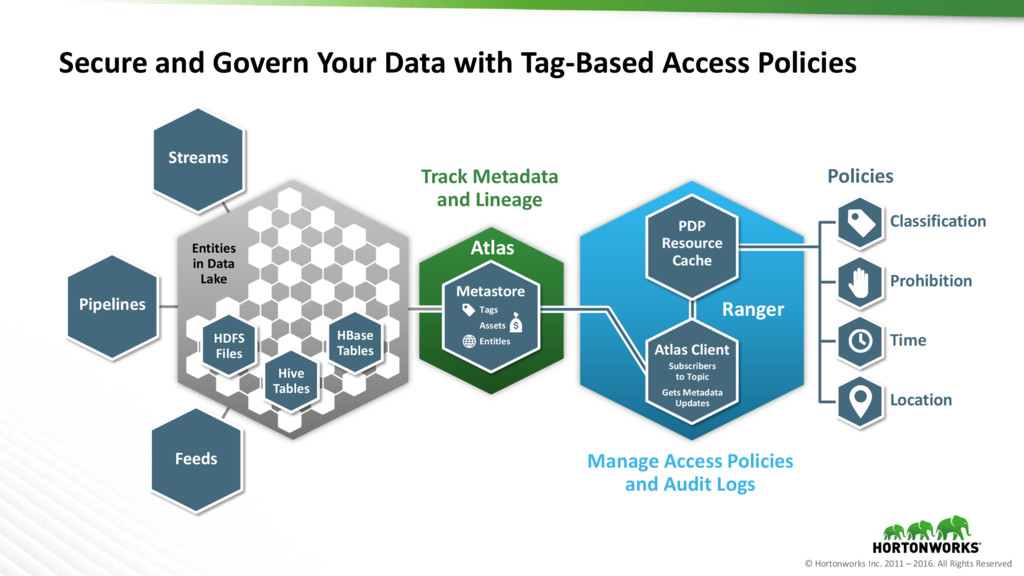
and Govern Your Data with Tag-Based Access Policies Classification Prohibition Time Location Policies PDP Resource Cache Ranger Manage Access Policies and Audit Logs Track Metadata and Lineage Atlas Client Subscribers to Topic Gets Metadata Updates Atlas Metastore Tags Assets Entitles Streams Pipelines Feeds Hive Tables HDFS Files HBase Tables Entities in Data Lake
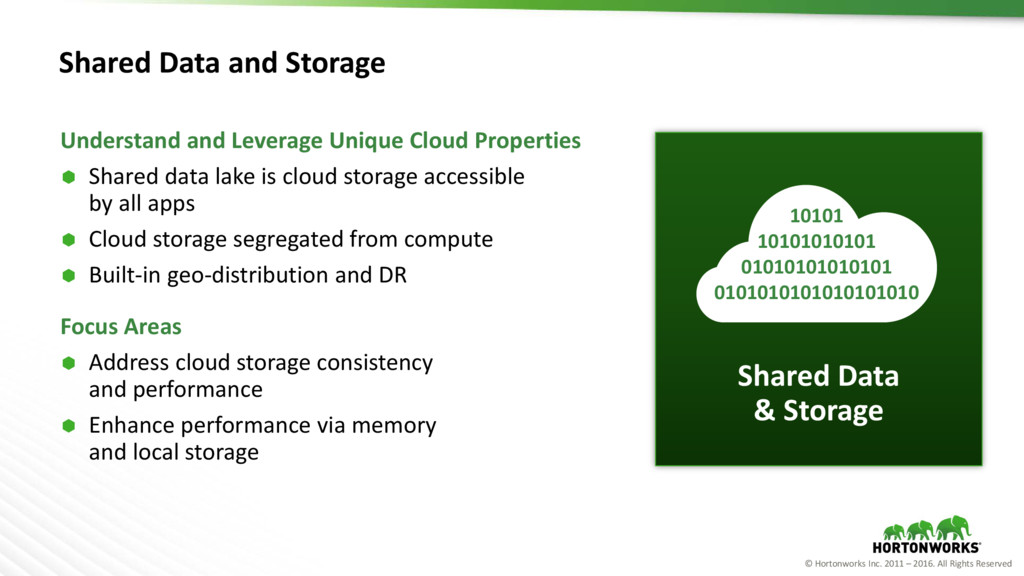
Data and Storage Understand and Leverage Unique Cloud Properties Shared data lake is cloud storage accessible by all apps Cloud storage segregated from compute Built-in geo-distribution and DR Focus Areas Address cloud storage consistency and performance Enhance performance via memory and local storage Shared Data & Storage 10101 10101010101 01010101010101 0101010101010101010
Performance via Caching Tabular Data: LLAP Read + Write-thru Cache Shared across jobs / apps and across engines Cache only the needed columns Spills to SSD when memory is full (anti-caching) Read & Write-through cache Security: Column-level and row-level HDFS Caching for Non-tabular Data Cache data from cloud storage as needed Write-through cache Workloads Cloud Storage LLAP R/W Tables HDFS Files Cache
Data Requires Shared Metadata, Security, and Governance Shared Metadata Across All Workloads Metadata considerations – Tabular data metastore – Lineage and provenance metadata – Pipeline and job management metadata – Add upon ingest – Update as processing modifies data Access / tag-based policies and audit logs Centrally stored to facilitate use across clusters – Ex. backed by Cloud RDS (or shared DB) Classification Prohibition Time Location Streams Pipelines Feeds Tables Files Objects Shared Metadata Policies
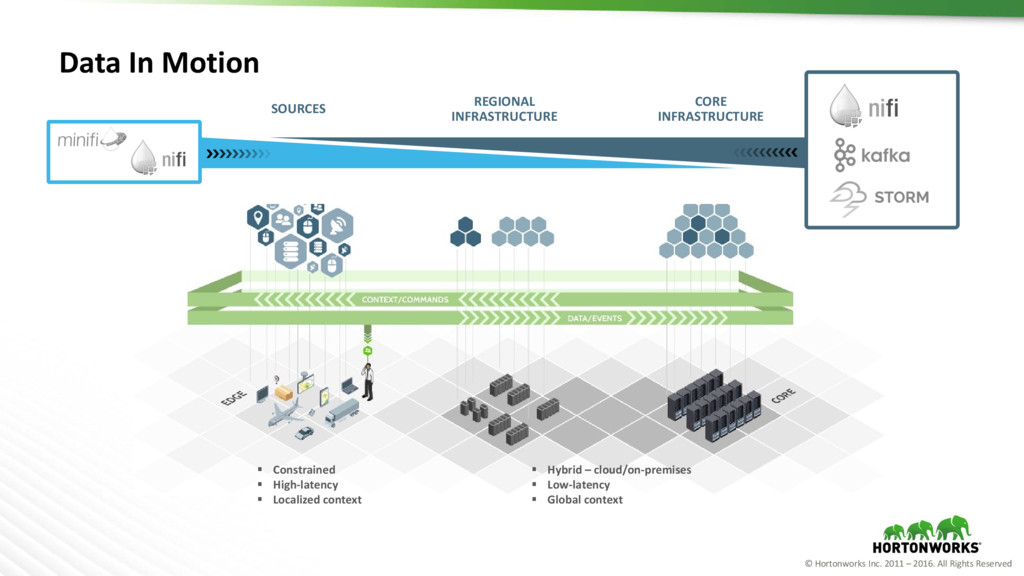
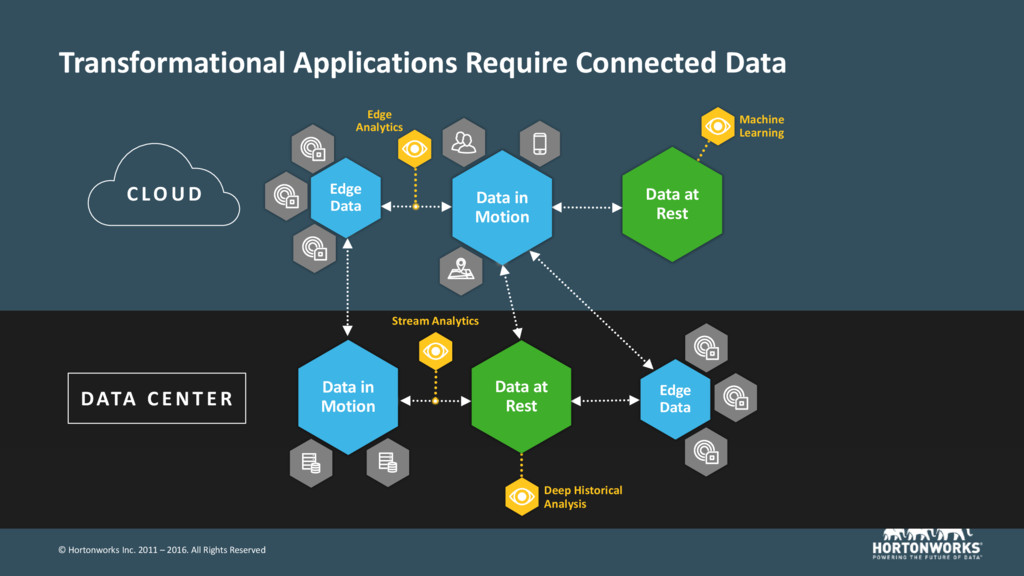
in Motion Data at Rest Deep Historical Analysis DATA C E N TE R Stream Analytics Edge Data Data in Motion Machine Learning C LOU D Edge Data Edge Analytics Data at Rest Transformational Applications Require Connected Data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
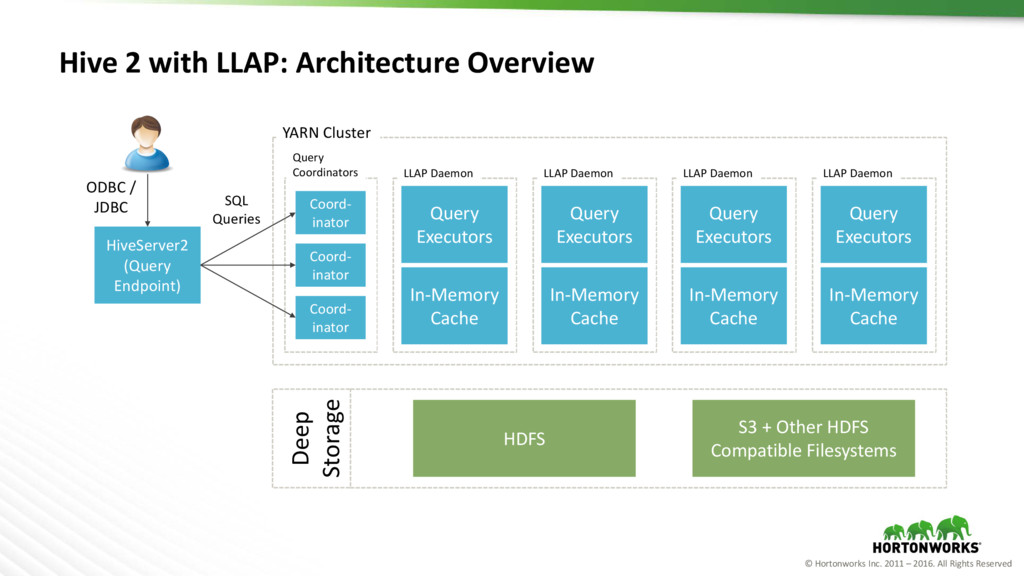{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}