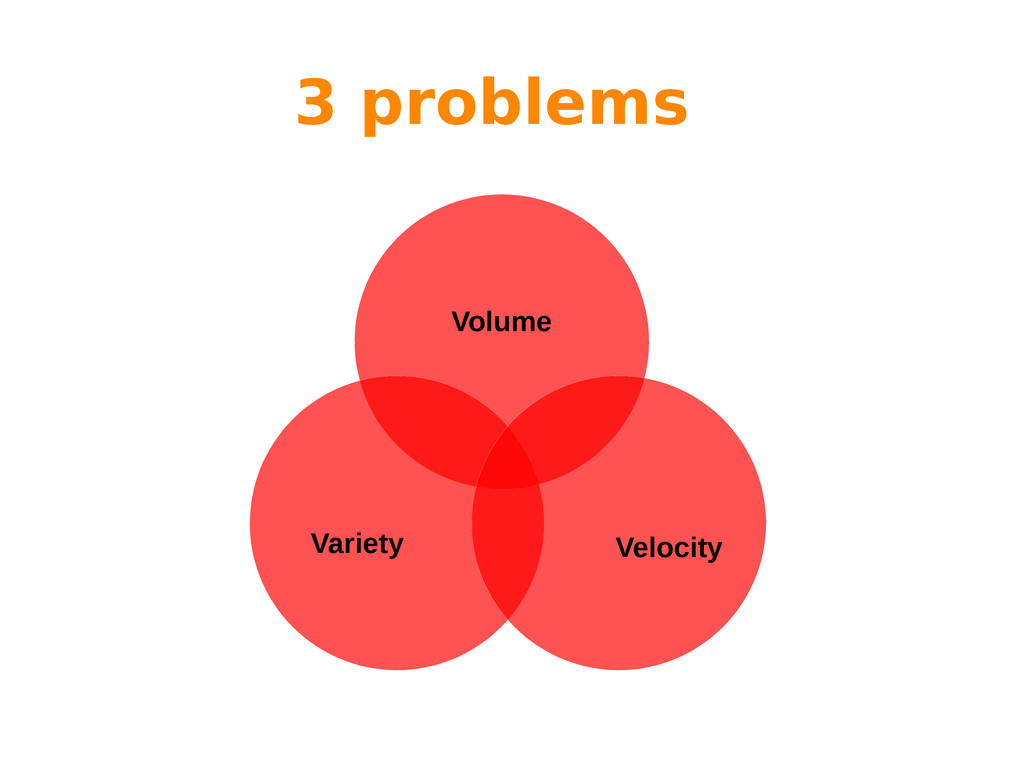
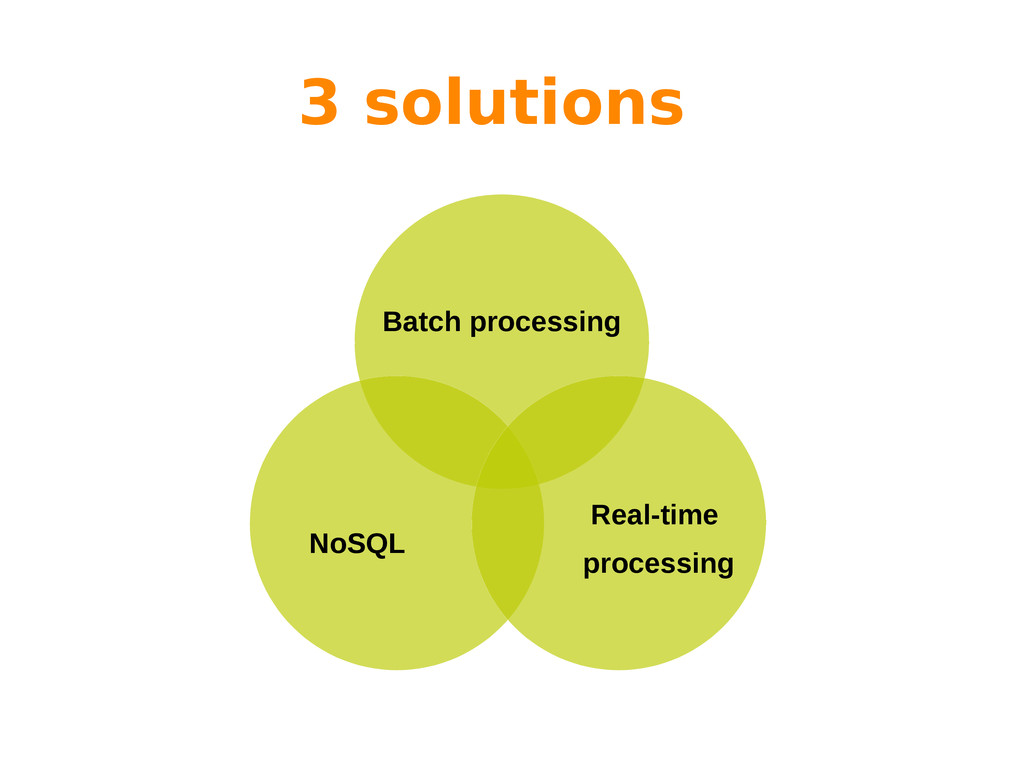
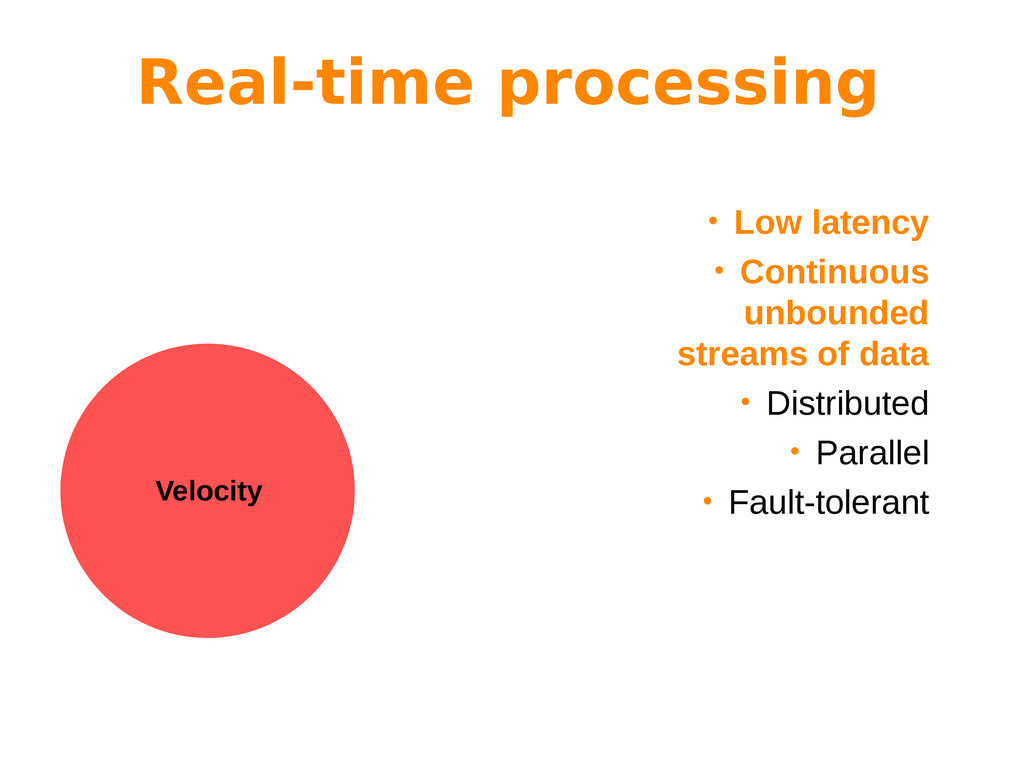
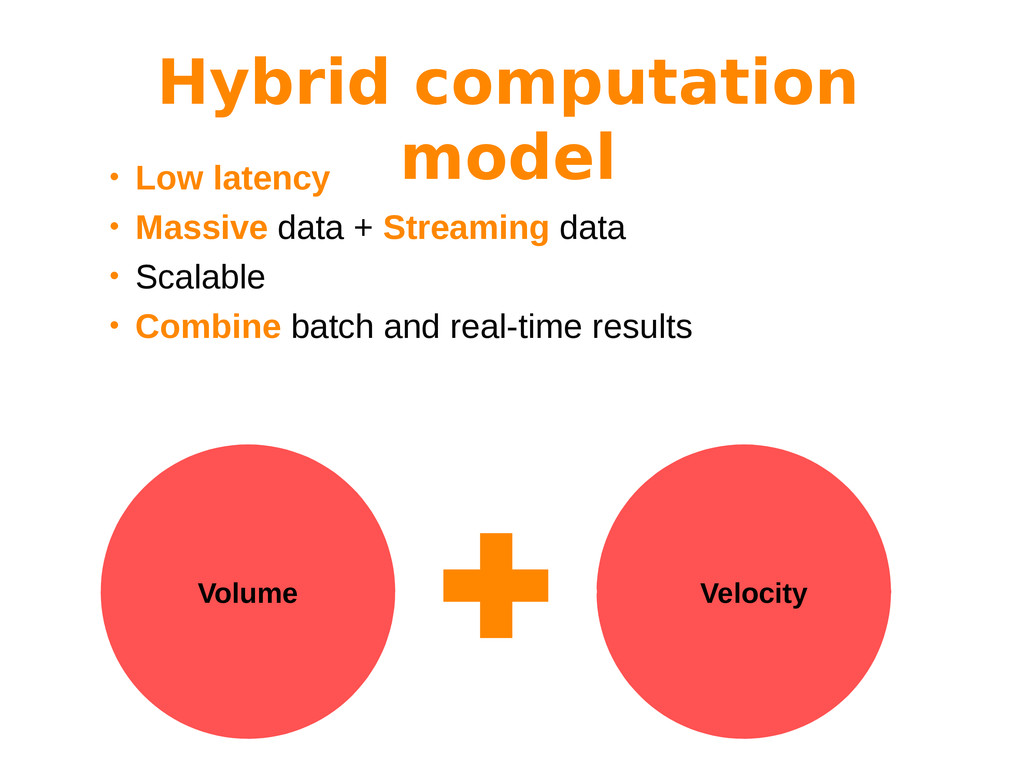
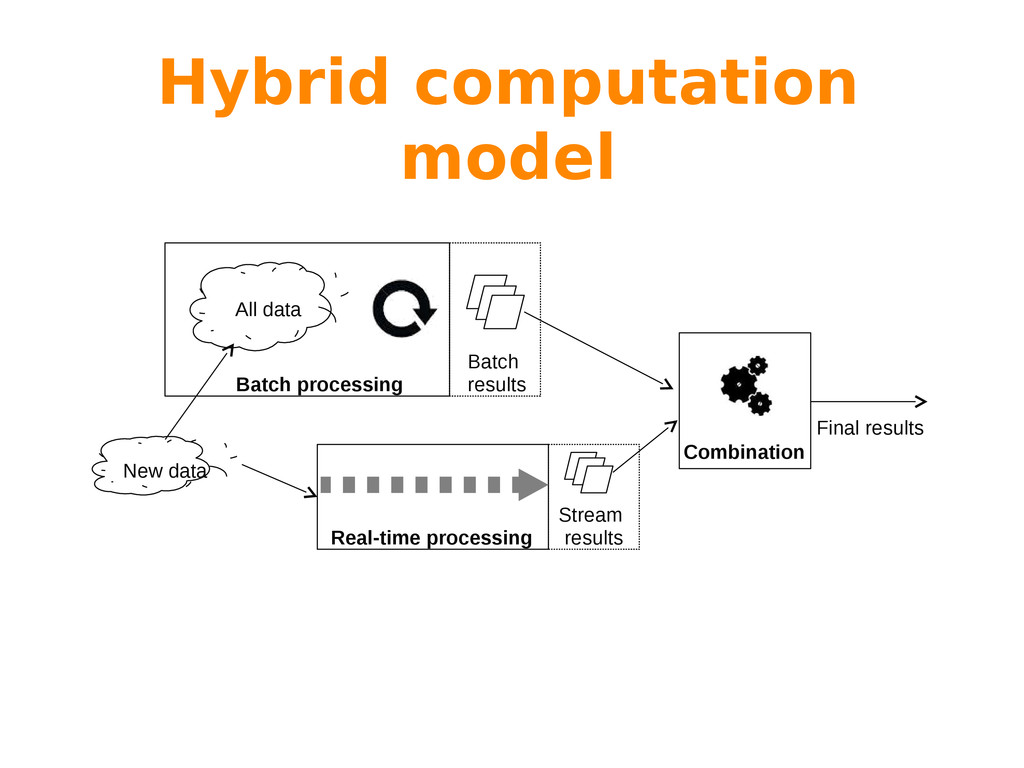
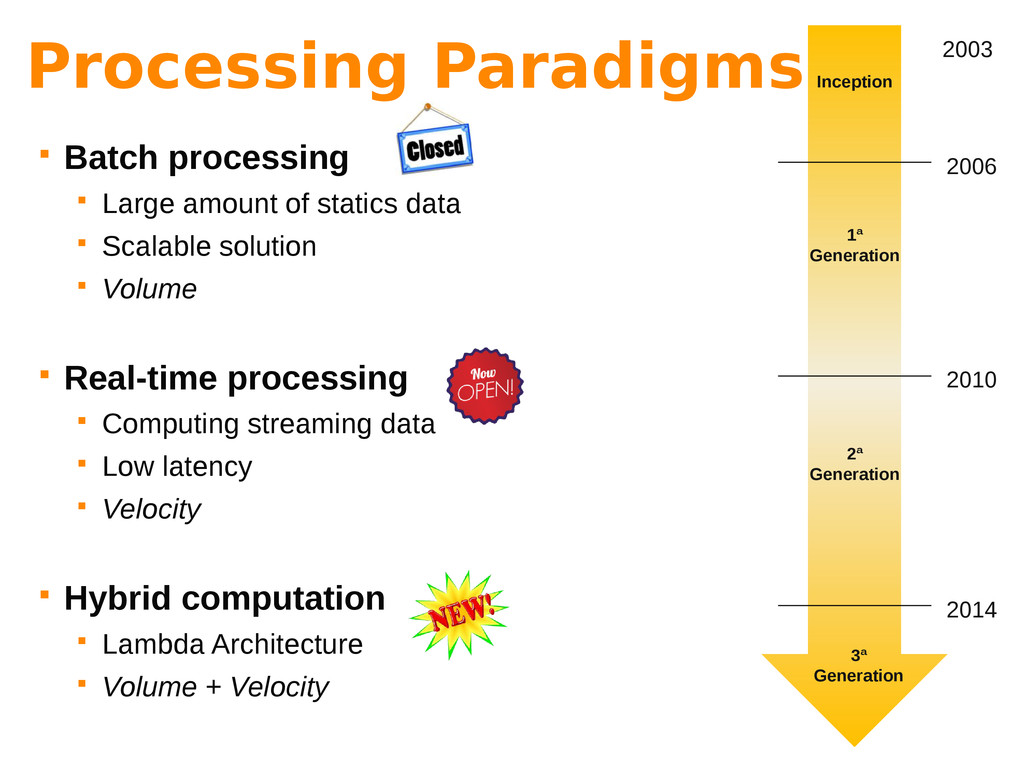
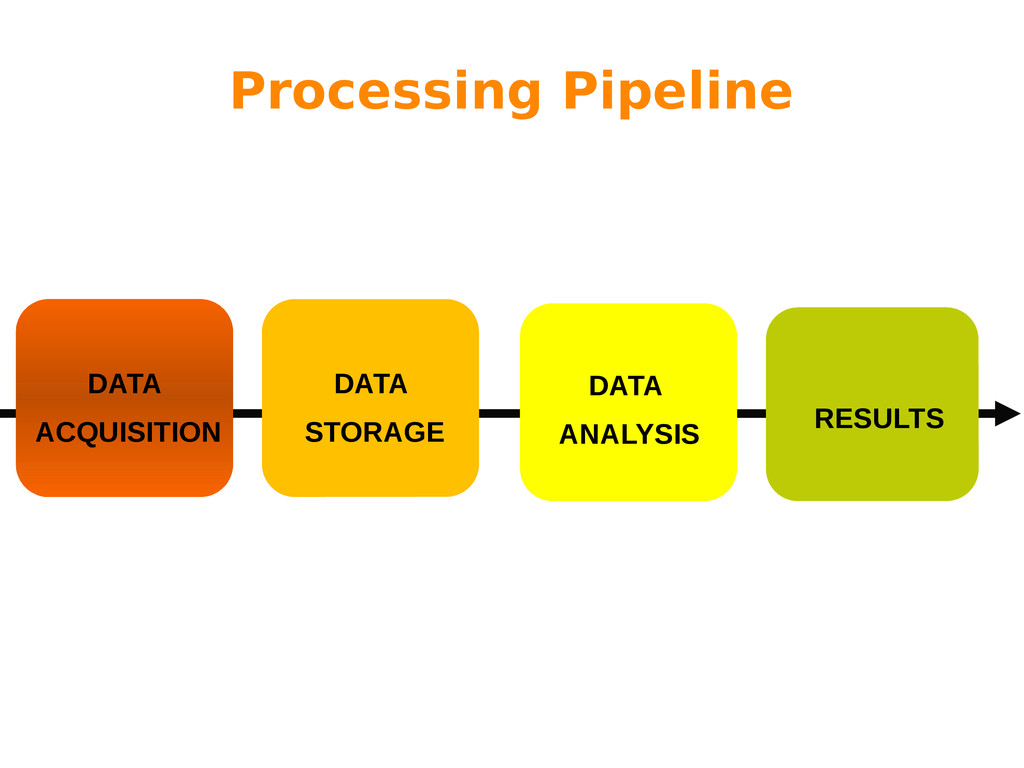
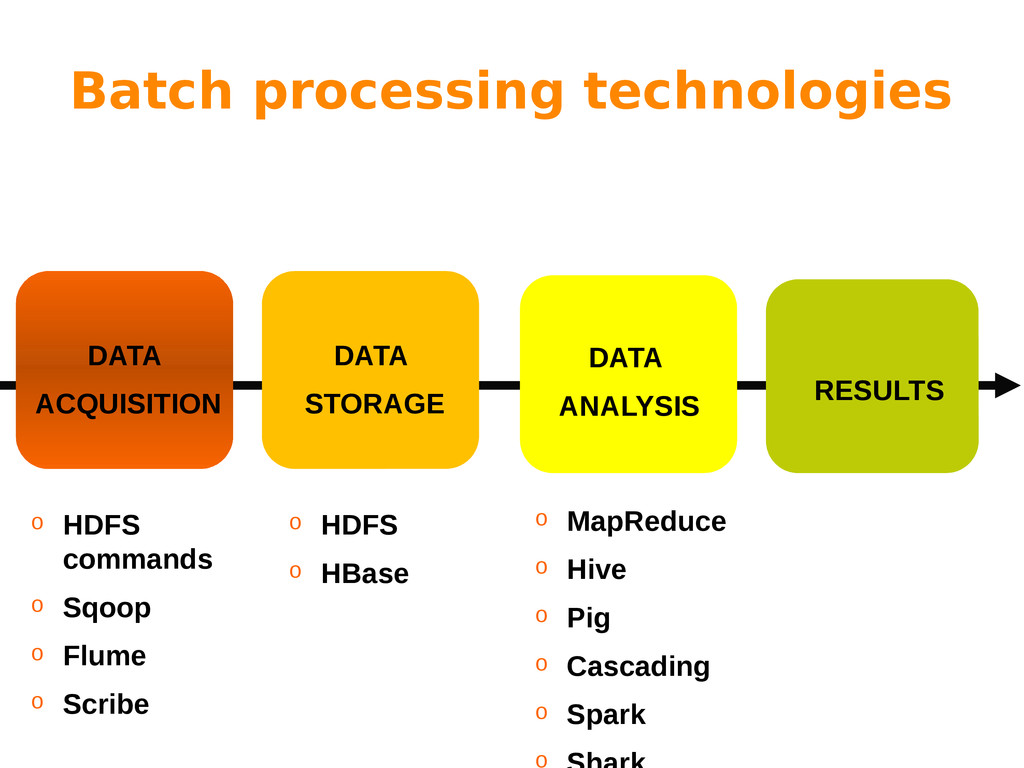
Big Data is often characterized by the 3 “Vs”: variety, volume and velocity. While variety refers to the nature of the information (multiple sources, schema-less data, etc), both volume and velocity refer to processing issues that have to be addressed by different processing paradigms.
Session presented at Big Data Spain 2013 Conference
7th Nov 2013
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/2013/conference/the-three-generations-of-big-data-processing
{kind=link}
![The three generations of Big Data processing Rubén Casado [email protected]](https://files.speakerdeck.com/presentations/b7f9bf002f7f013193f83a251344e3e5/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks for your attention! www.datadopter.com www.treelogic.com Contact us: [email protected] [email protected]](https://files.speakerdeck.com/presentations/b7f9bf002f7f013193f83a251344e3e5/slide_87.jpg){kind=link}
{kind=link}