and interested in getting your hands dirty. (yes) ★ Some intuition how Machine Algorithms work (YES!) ★ Curious about available libraries. (yes) ★ Nothing else to do before lunch?
Vision (Captcha solvers) ★ Robotics ★ Internet Search ★ Recommender Systems (Netflix prize) ★ Solving Tic-Tac-Toe ★ Constraint Satisfaction (Sudoku) ★ Nest What is Artificial Intelligence? actually, tons of stuff we take for granted.
All that other stuff if it improves automatically as it gets more experience (data). ★ Unsupervised: Clustering, Reinforcement Learning ★ Supervised: Regression, Classification ★ Data Mining
history (training data) predict an unseen variable ★ Which class does this belong to? Classification ★ What value will this be? Regression - Where I spend most of my effort
Linear and Logistic Regression ★ Naive Bayes / Bayes Nets ★ Random Forests ★ Support Vector Machines ★ Many, many more More with less data? more data? UCI Repository
Machine Learning and Data Mining is getting the data right. Receive a clients data, listen, pay attention, but assume they don’t really know what data they have and where it is - because they don’t. ★ Feature Discovery - what are the important attributes ★ Data Visualization - big hints for prediction ★ Data Cleansing How many databases do you really need? ★ Data Leakage
you will have at the time of prediction ‣ Predicting Stock Values ‣ Attributes added after the fact ★ What attributes have been picked by your algorithm? UserID? ★ Cross fold validation ★ Can we beat random? Does it make sense?
the Data on the single best attribute Repeat for each child node BigML ★ Easily interpretable ★ Scalable easily handle streaming data why might this be important?
only if you need it ★ For most of what you do, it just isn’t necessary Really, how big is a hard drive these days? ★ There are other options ★ </rant> ★ Graphlab is awesome -Ben
of the features ★ Adjust the weight with each example (either individually or by batch) ★ Simple, Fast ★ Good For Regression, not so much for Classification
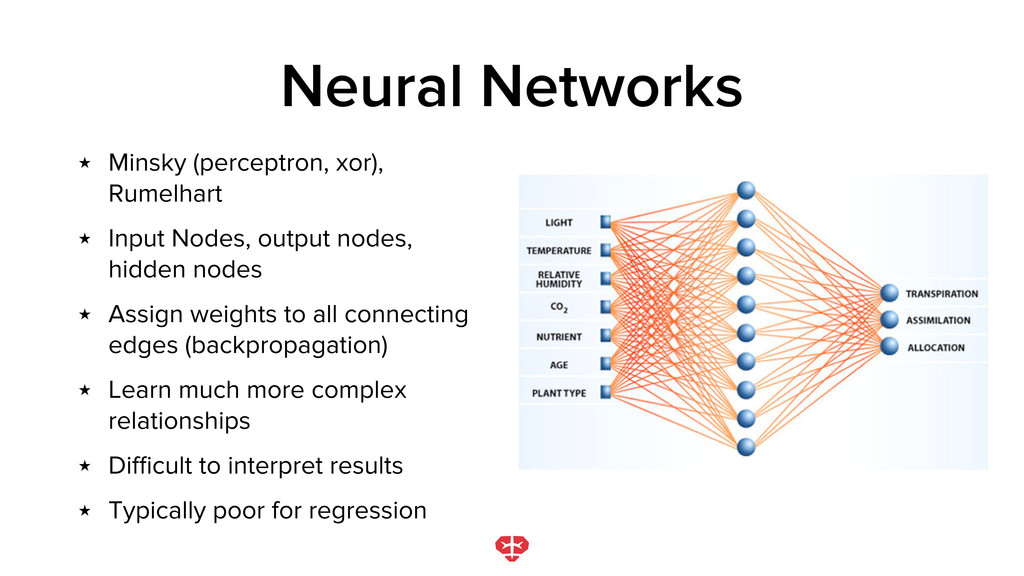
output nodes, hidden nodes ★ Assign weights to all connecting edges (backpropagation) ★ Learn much more complex relationships ★ Difficult to interpret results ★ Typically poor for regression
Do you have to? ★ Benefits If your data changes slightly over time If you aren’t sure of the structure of the data ★ Problems: Time Constraints ‣ Training time ‣ Initial Tuning Time ★ Example: LMP 500+ models, fight for your life, keep yesterday’s winners, add some extras randomly
- more than just the standard race tables Attributes? Suunto Ambit predicts recovery time. ★ Cheating at Solitaire instant recognition, faster prediction ★ NICU lots of intuition going on
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}