= prepare_model_for_kbit_training(model) peft_config = LoraConfig( lora_alpha=16, lora_dropout=0.1, r=32, bias="none", task_type=TaskType.SEQ_CLS, inference_mode=False, # target_modules=["self_attn"] target_modules=['q_proj', 'out_proj', 'k_proj', 'v_proj'], ) lora_model = get_peft_model(model, peft_config) lora_model.print_trainable_parameters() from transformers import AutoTokenizer from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer model_name= "mistralai/Mistral-7B-v0.1" tokenizer = AutoTokenizer.from_pretrained(model_name, truncation_side='left') bnb_config = transformers.BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16 ) model = AutoModelForSequenceClassification.from_pretrain ed(model_name, num_labels=5, quantization_config=bnb_config) training_args = TrainingArguments( do_train = True, do_eval=True, warmup_ratio=0.8, learning_rate=5e-6, per_device_train_batch_size=2, per_device_eval_batch_size=4, num_train_epochs=3, report_to='none', output_dir='.', ) trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_train_dataset, eval_dataset=tokenized_val_dataset, tokenizer=tokenizer, compute_metrics=compute_metrics, )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
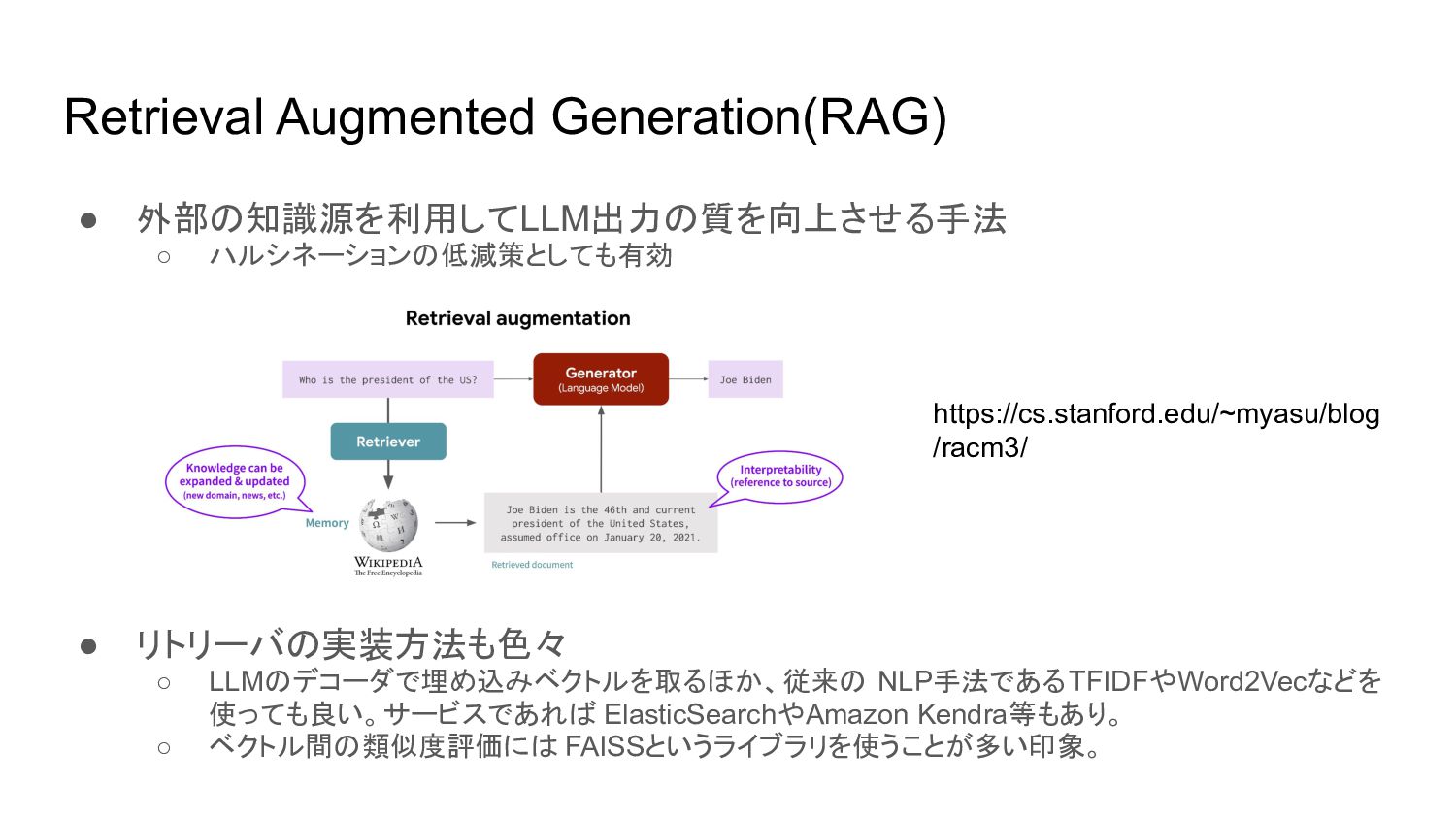{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}