Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Botify @ Data Tuesday
Search
Botify
February 26, 2014
Programming
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Botify @ Data Tuesday
#fr
Botify
February 26, 2014
More Decks by Botify
See All by Botify
Git history rewriting
botify
3
84
Yet another JS/CSS workflow
botify
2
730
Fixing the process
botify
2
190
Amazon Redshift : it's all about data compression
botify
3
3.6k
Other Decks in Programming
See All in Programming
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
480
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
610
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
300
スマートグラスで並列バイブコーディング
hyshu
0
290
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
110
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
160
symfony/aiとlaravel/boost
77web
0
120
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
140
1B+ /day規模のログを管理する技術
broadleaf
0
130
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
580
その問い、本当に正しいですか?AI時代のエンジニアに必要な哲学と認知科学 / ai-philosophy-cognitive-science
minodriven
14
6.8k
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
110
Featured
See All Featured
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Building Adaptive Systems
keathley
44
3.1k
4 Signs Your Business is Dying
shpigford
187
22k
Everyday Curiosity
cassininazir
0
250
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
The Cost Of JavaScript in 2023
addyosmani
55
10k
Believing is Seeing
oripsolob
1
170
First, design no harm
axbom
PRO
2
1.2k
Transcript
What do you really know about your website ? @botify
/ www.botify.com
Je suis Thomas Grange (@mpelmann) Cofondateur de Botify
Mon site (aspiré par Botify)
Mon site aspiré par un moteur de recherche (Google par
exemple)
Vu par Botify Vu par le moteur Le meilleur des
cas
Problème
Le moteur ne voit pas du tout la même chose
!
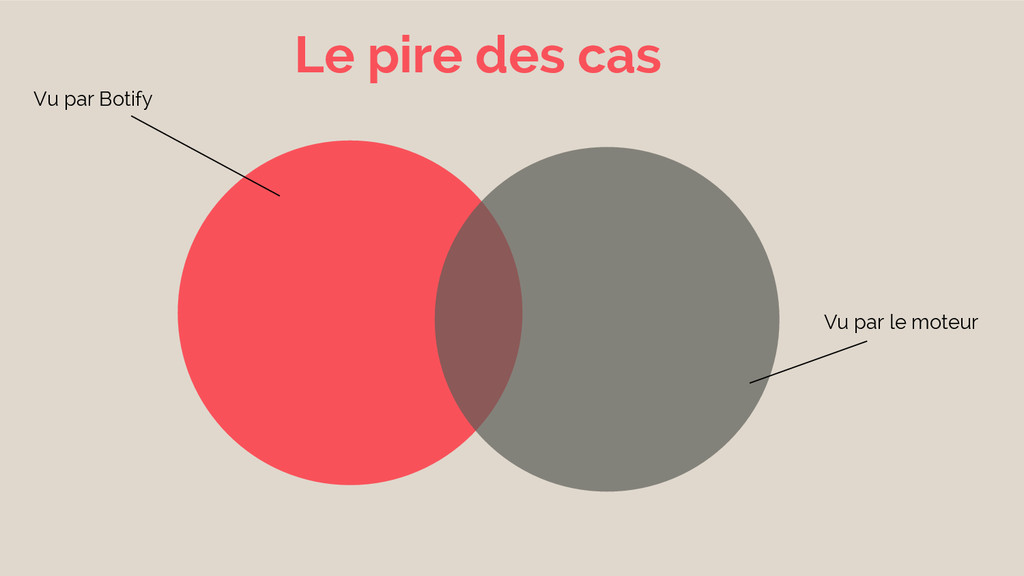
Vu par Botify Vu par le moteur Le pire des
cas
Si Google ne peut pas voir mon produit ? Personne
ne pourra le rechercher ?
Si Google ne peut pas voir mon produit ? Personne
ne pourra l’acheter ?
Question simple : “Combien de pages avez-vous sur votre site
?”
Tous nos clients se sont trompés d’un facteur 10 à
1000 !
Quels sont donc les objectifs de Botify ?
1. Obtenir les data 2. Masher les data 3. Interpréter
les résultats
Botify crawle un site entièrement Sont extraits : liens sortants,
metadonnées (title, h1, canonicals..), temps de réponses
En chiffres 1 site d’1 million de pages = 200
millions de liens 200 à 500 GB de data
Nos clients peuvent également pusher leurs logs serveurs quotidiennement
En chiffres Botify reçoit plus de 200 GB de logs
par jour
et une grande partie de l’analyse est encore effectuée en
#python (désolé, ce n’est pas un keyword big data :)
1. Obtenir les data 2. Masher les data 3. Interpréter
les résultats
Architecture (réseau de liens, profondeur des pages...)
Santé (temps de chargement, codes réponses)
Qualité sémantique (textes inédits et non dupliqués...)
Quels critères justifient qu’une page ne soit pas crawlée
Quels critères justifient qu’une page ne soit pas visitée
Quelles sont les pages qui pointent vers des pages 404
?
Quelles sont les pages dupliquées entre elles ?
Quelles sont les pages qui ne reçoivent qu’un seul lien
entrant ?
Interpréter avec le crawler + avec les logs serveurs
Sur les 3 derniers mois, comment s’est passé le rafraîchissement
de mon site par le robot Google ?
Sur les 3 derniers mois, quel est le volume de
pages crawlées par Google et Bing n’ayant ramené aucune visite
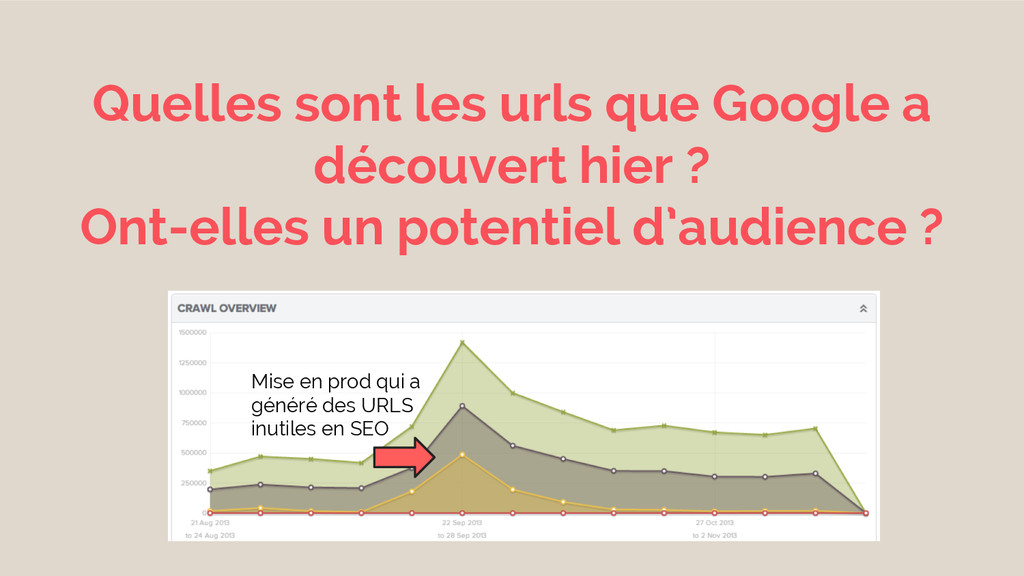
Quelles sont les urls que Google a découvert hier ?
Ont-elles un potentiel d’audience ? Mise en prod qui a généré des URLS inutiles en SEO
1. Obtenir les data 2. Masher les data 3. Interpréter
les résultats
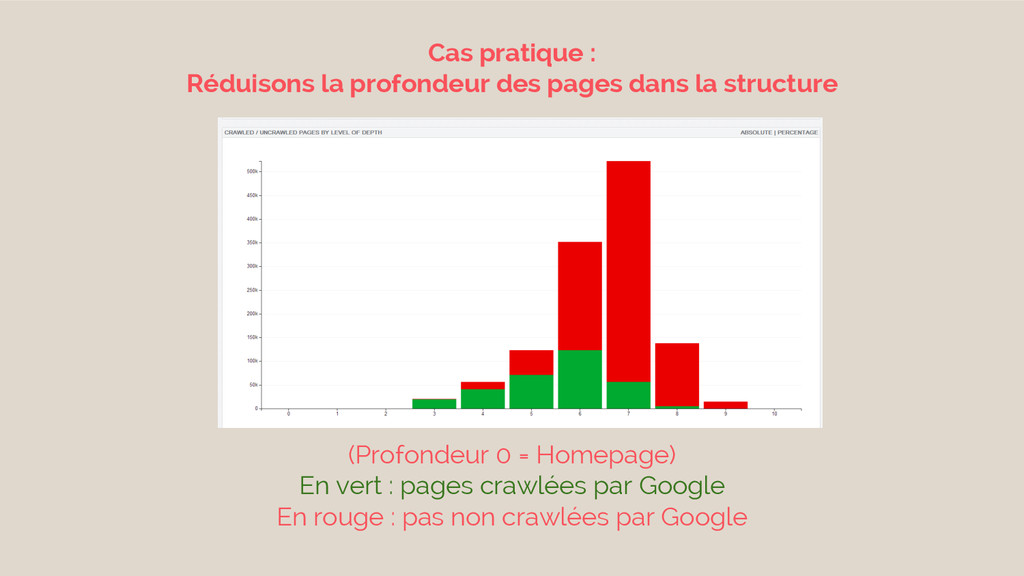
Cas pratique : Réduisons la profondeur des pages dans la
structure (Profondeur 0 = Homepage) En vert : pages crawlées par Google En rouge : pas non crawlées par Google
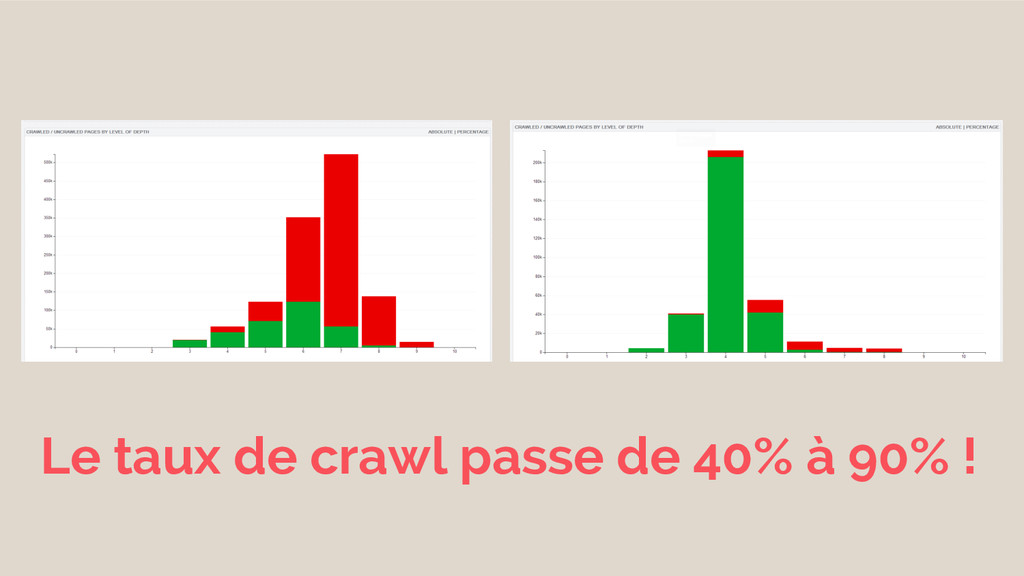
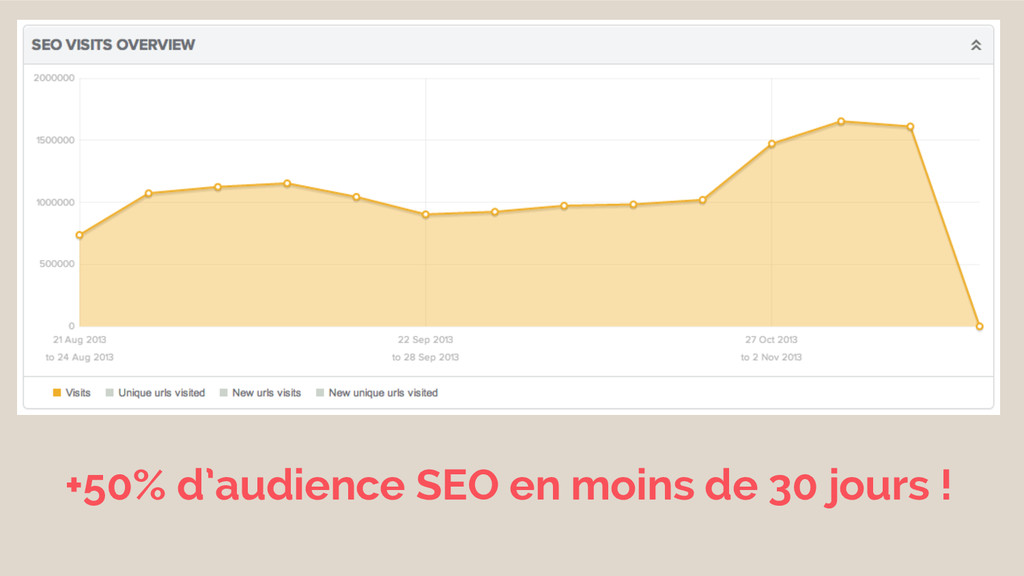
Le taux de crawl passe de 40% à 90% !
+50% d’audience SEO en moins de 30 jours !
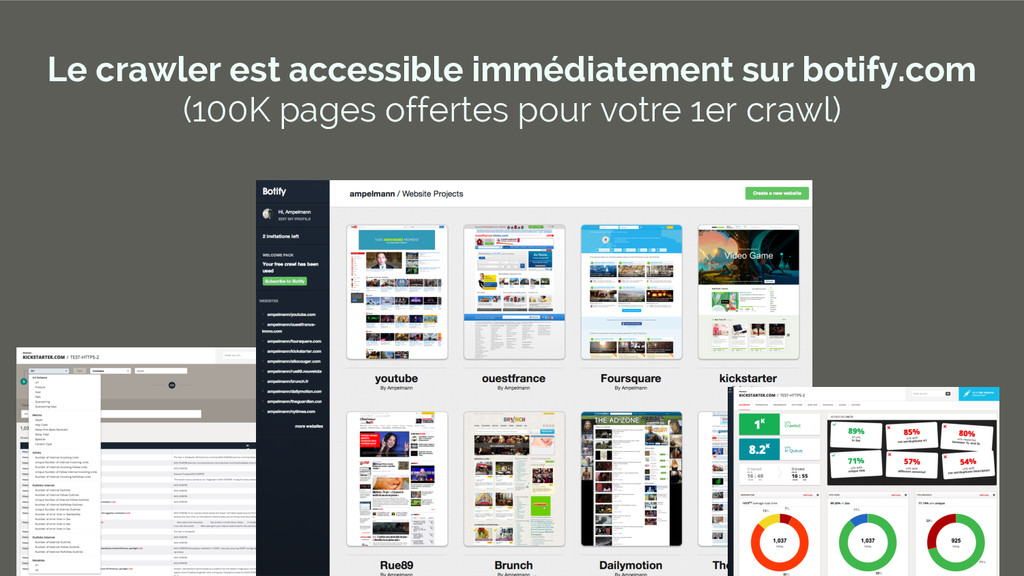
Le crawler est accessible immédiatement sur botify.com (100K pages offertes
pour votre 1er crawl)
Nous recrutons ! Un directeur de production Des devs #django
#python #go Des passionnés !
Merci !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}