# 概要
プロンプトはLLMを使ったサービス開発の生命線。でも、モデルを変えるたび手作業調整に消耗していませんか?
このトークのテーマは、プロンプト調整の“属人化”を打破し、モデル変更にもしなやかに追従できる新時代の自動プロンプト最適化フレームワーク“DSPy(Declarative Self-improving Python)”の紹介です。
LLMのモデルやバージョン変更の際のプロンプト調整に疲弊した結果、自動でプロンプト最適化がこれから盛り上がっていくことを感じ、本トークでは以下の内容をお伝えします。
## なぜプロンプトの自動最適化が必要か
LLMサービスの現場では、GPT-4/5やClaude、Geminiなどモデル/バージョンの切替が急速に発生
そのたび「出力結果が崩れた」「従来のプロンプトでは最適でなくなった」悩みが頻発
従来は人手による微調整(プロンプトエンジニアリング)が膨大な工数で発生
プロンプトは人手の属人的な運用から脱却し、仕様書とデータ駆動で“自動的に改善”すべき
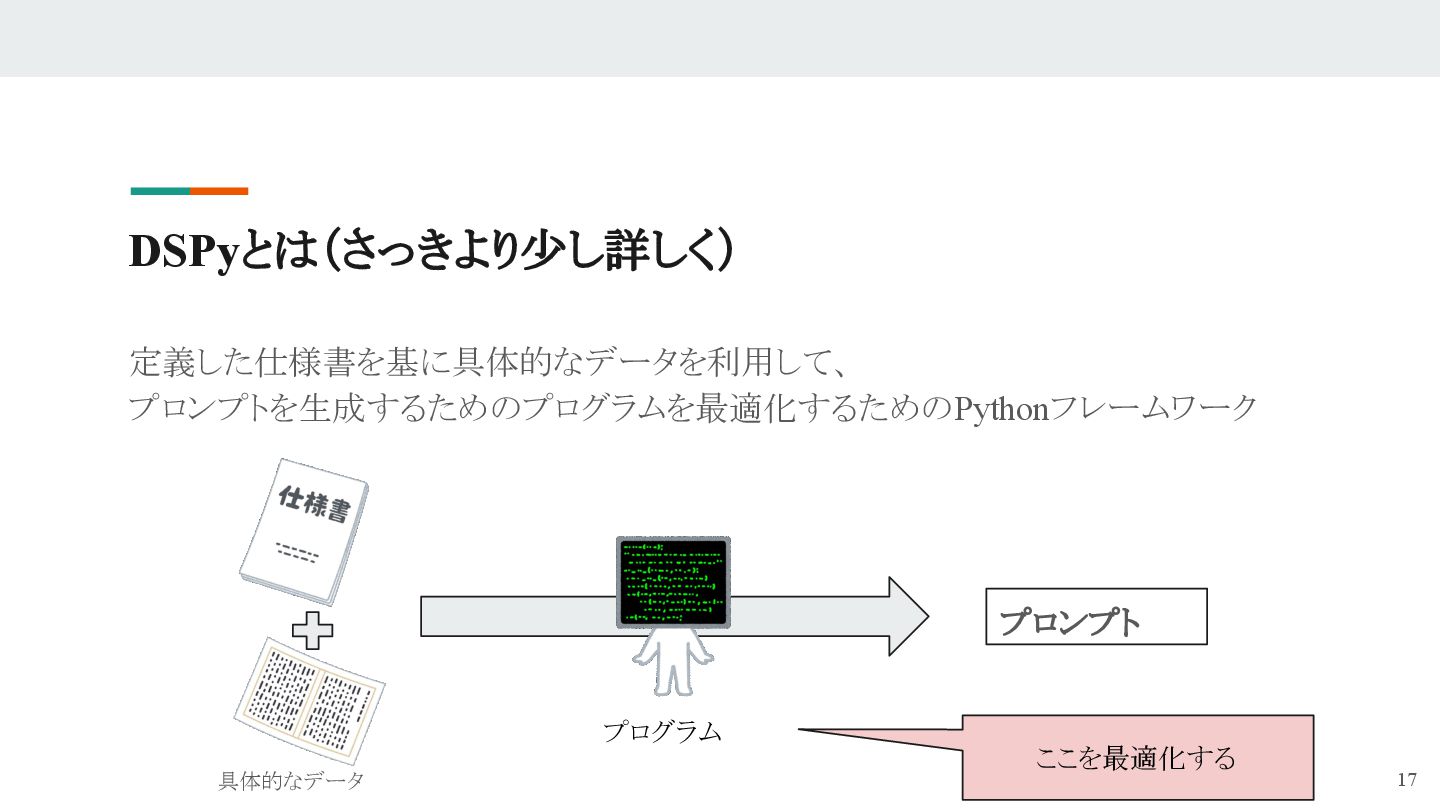
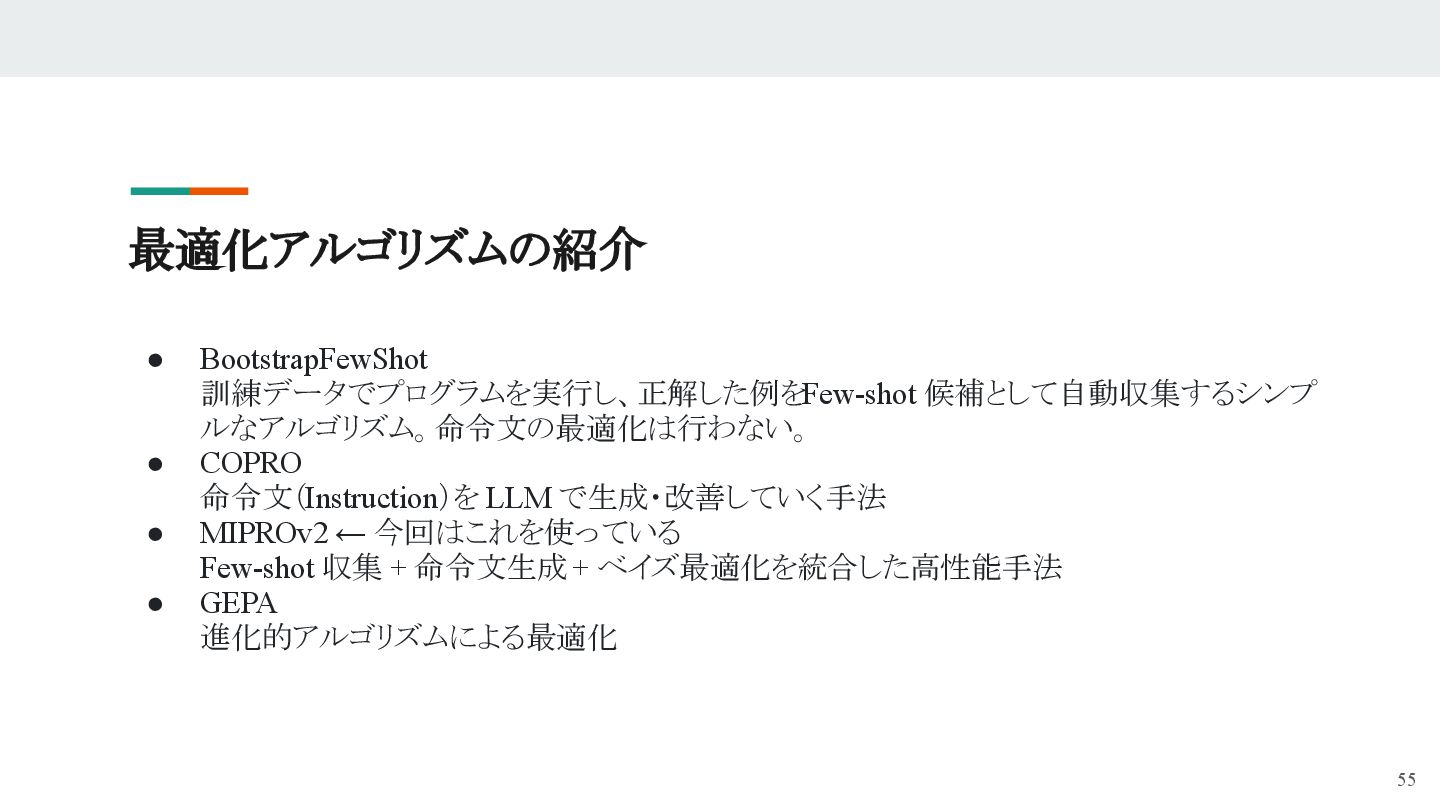
## DSPyとは
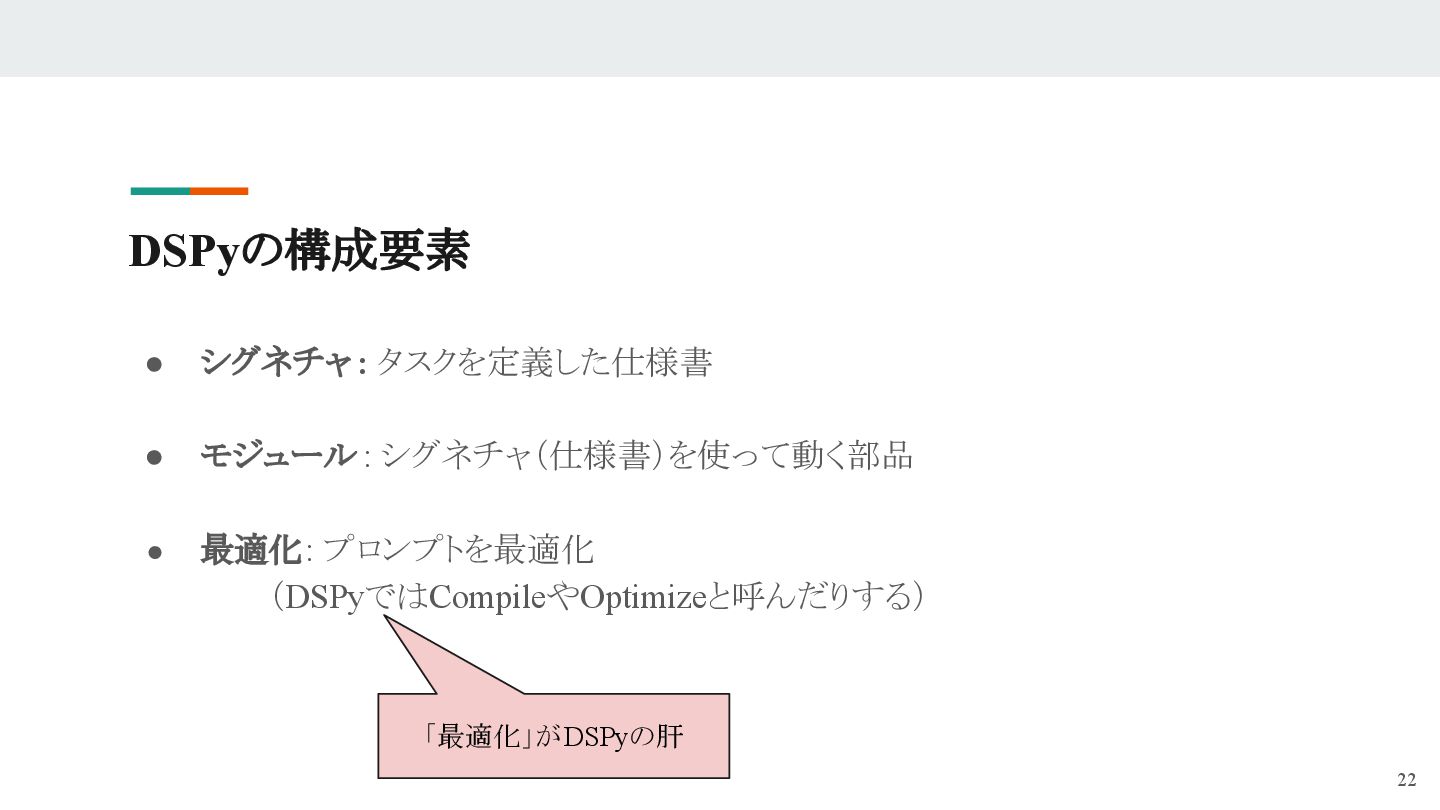
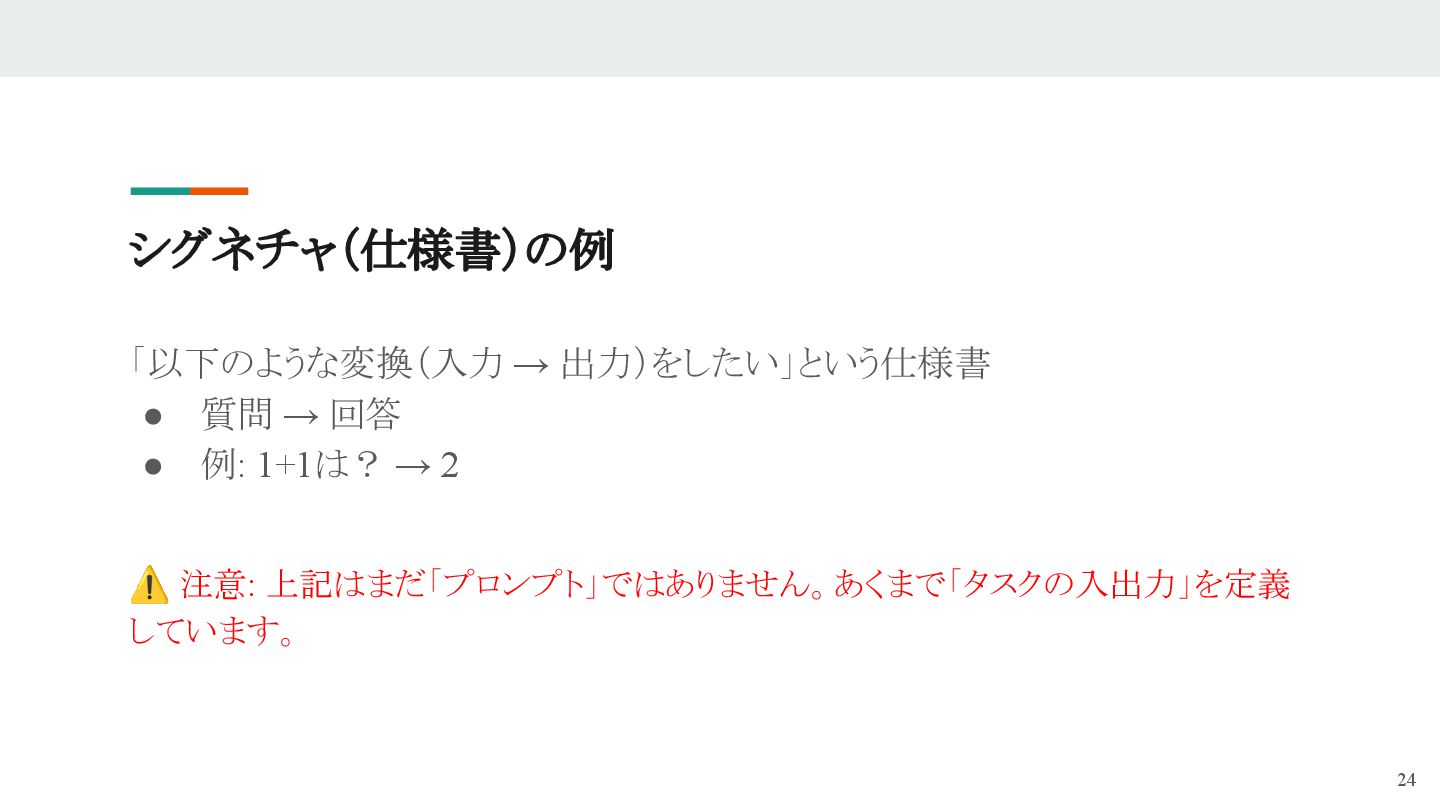
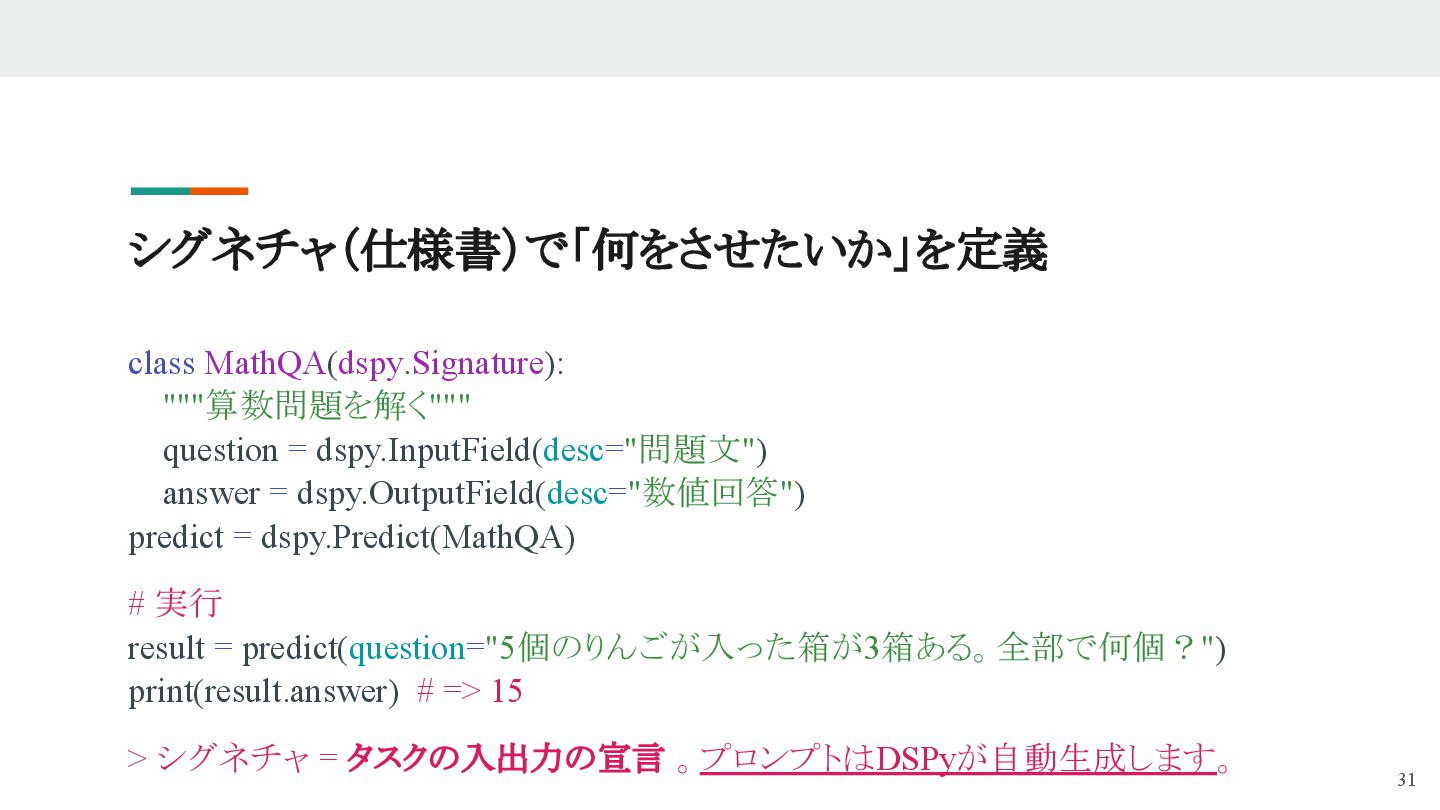
- 仕様書(シグネチャ)と具体例で“理想の変換”を定義
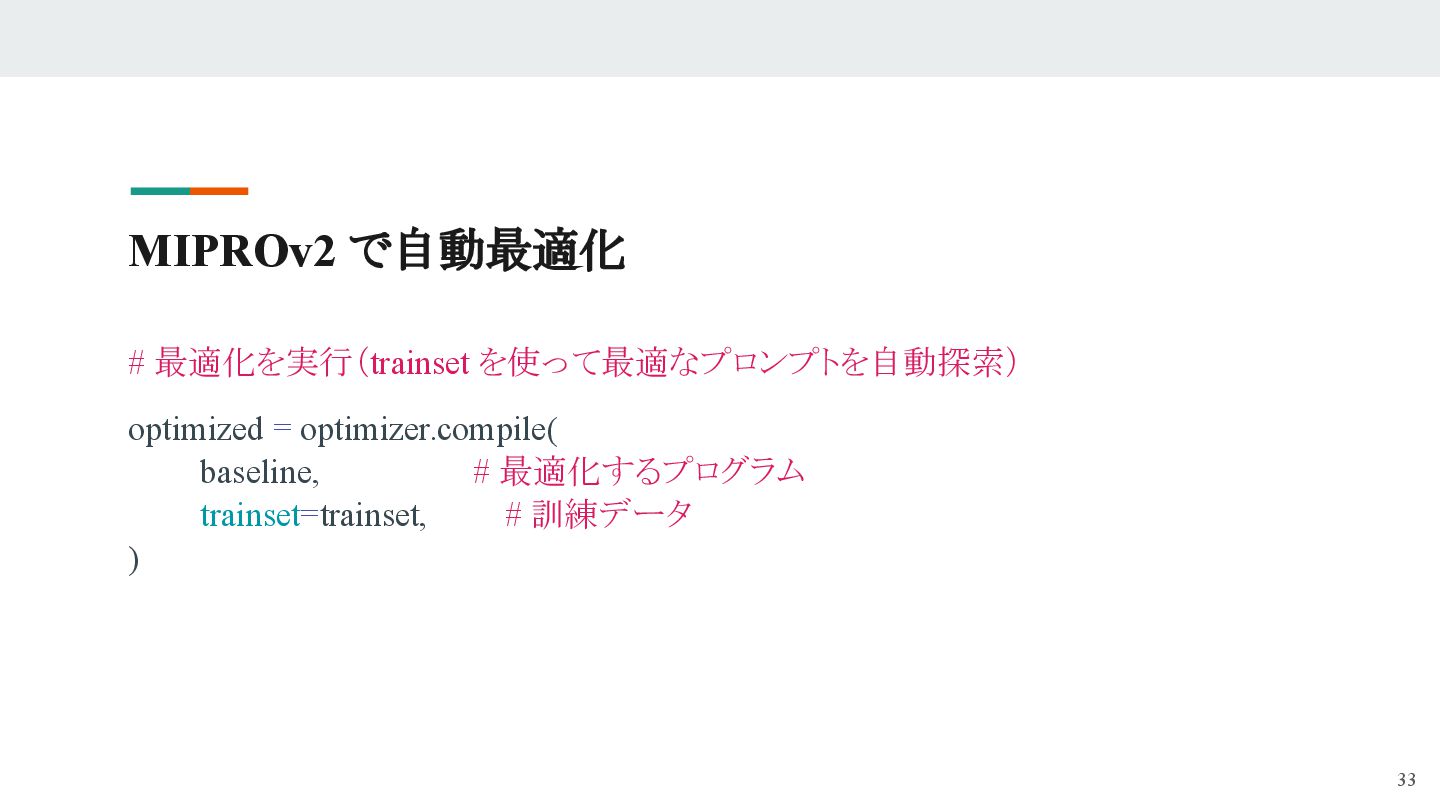
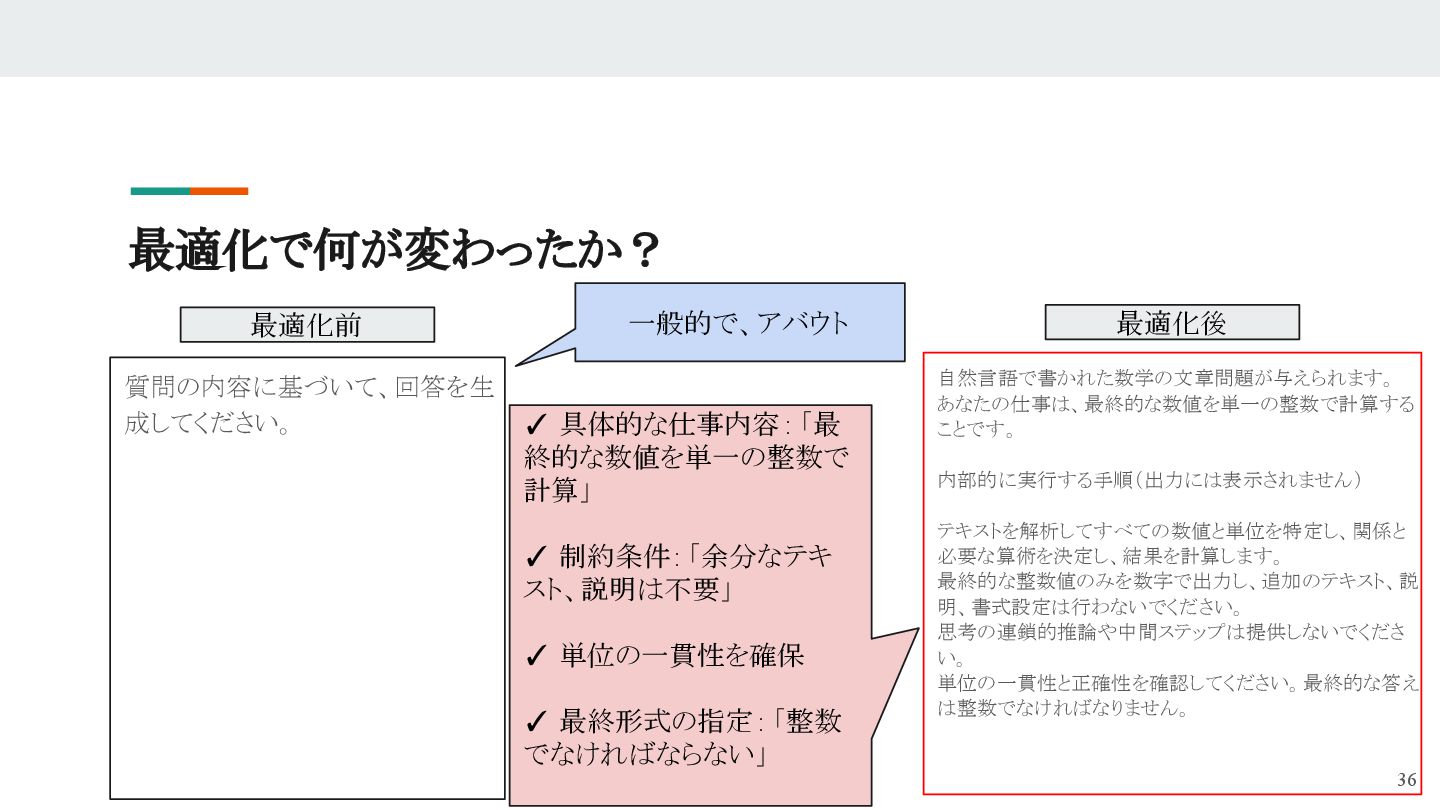
- DSPyが効率よく「最適なプロンプト」を探索し、人手不要で最適化
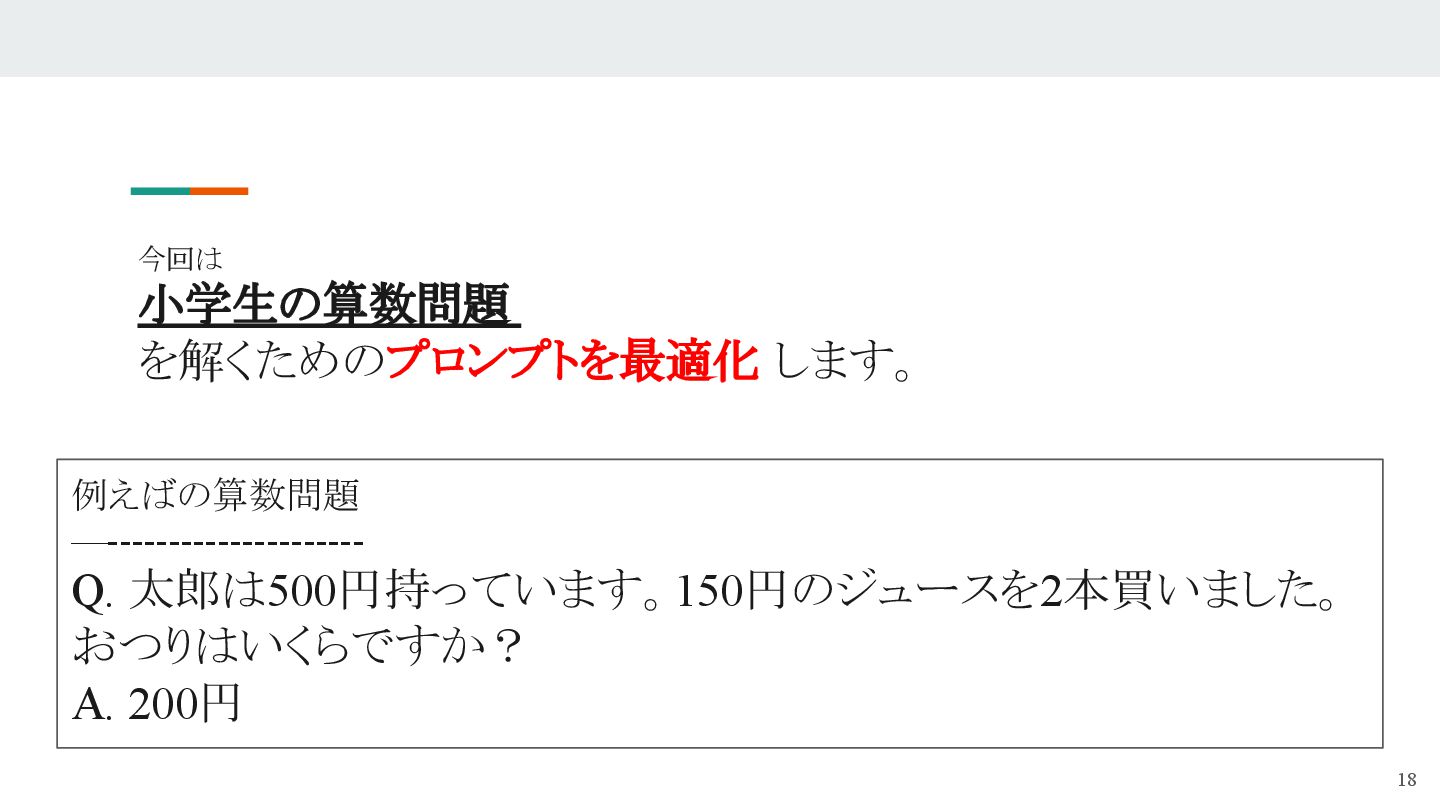
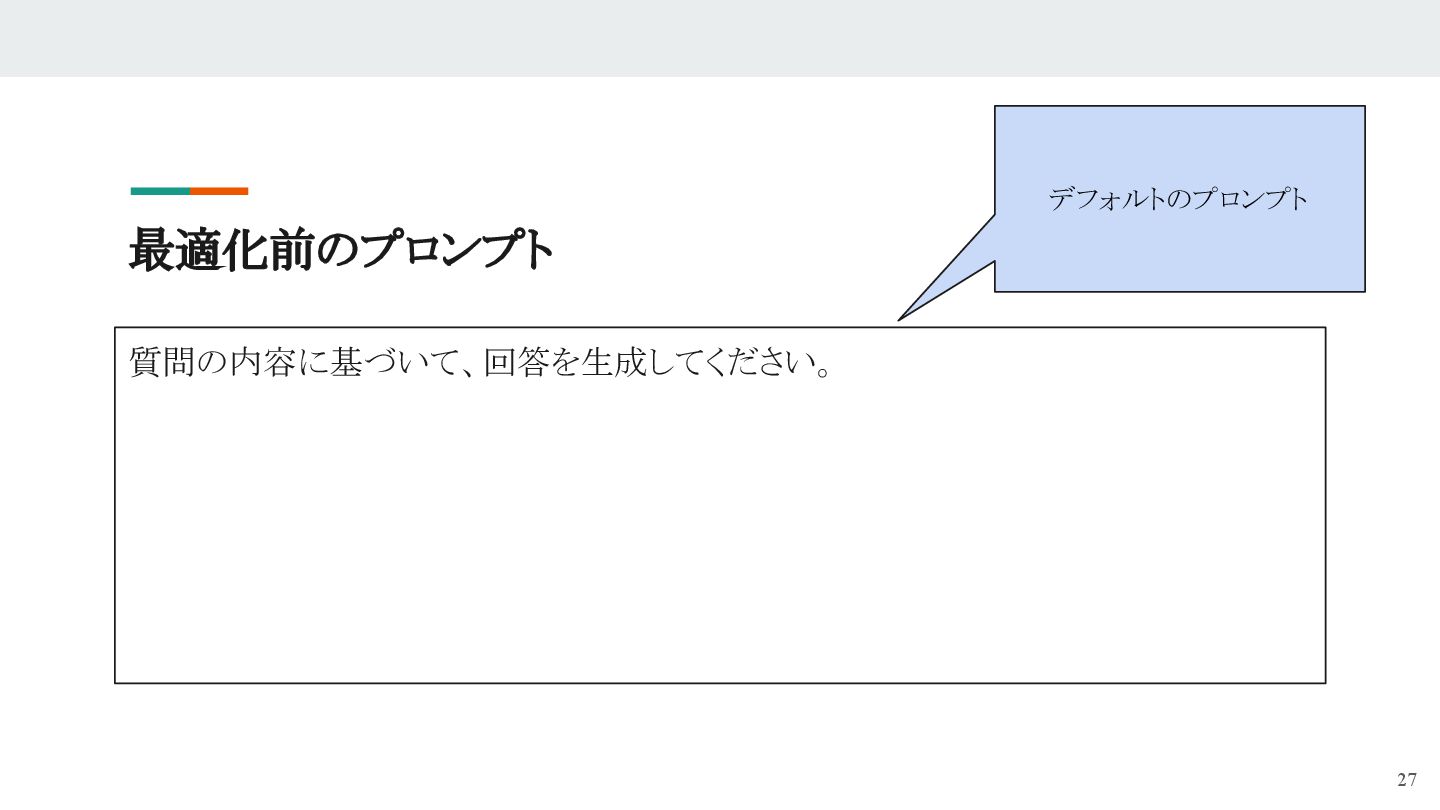
- たとえば「あるキャラクターの口調」で話すボットを作成したい場合、以前は手動でプロンプトを書き、入出力を見比べながら微調整していました。
- DSPyでは、仕様と変換例を与えることで、モデル特性を学習し、自律的に最適プロンプトを生成することができます。
## アウトライン
時間 内容
2分 自己紹介とトークの背景説明
8分 プロンプト最適化の必要性と課題の説明
10分 DSPyの技術的詳細と仕組みの解説
15分 コード例を交えた実践的な使い方の紹介
5分 まとめと今後の展望
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}