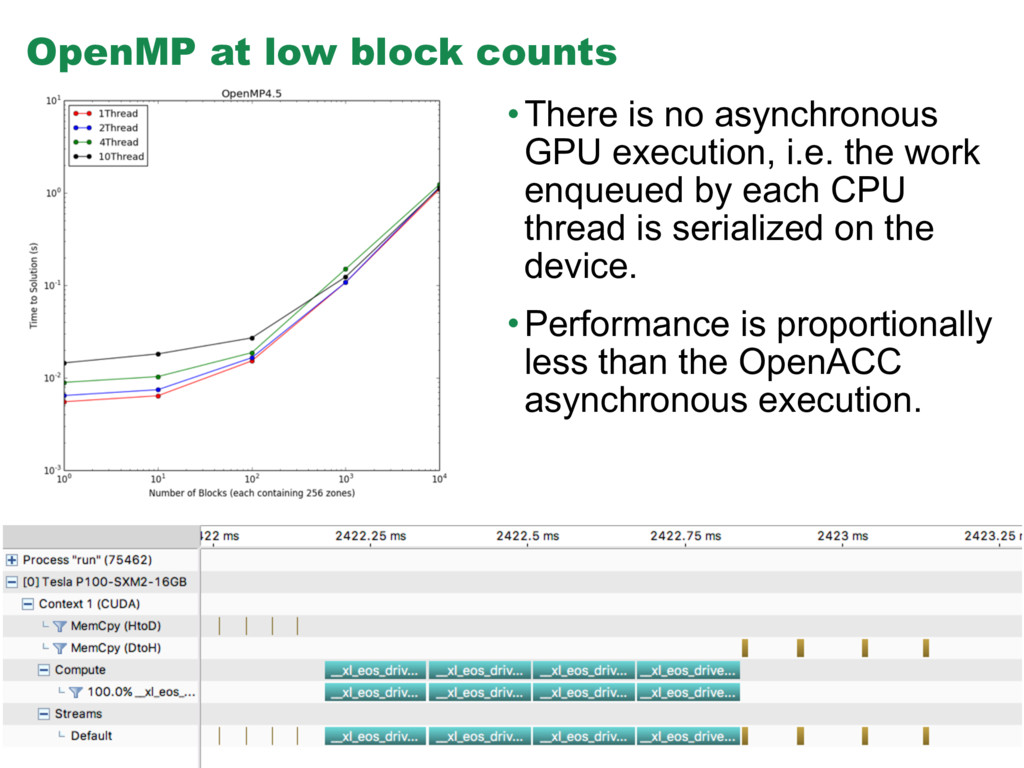
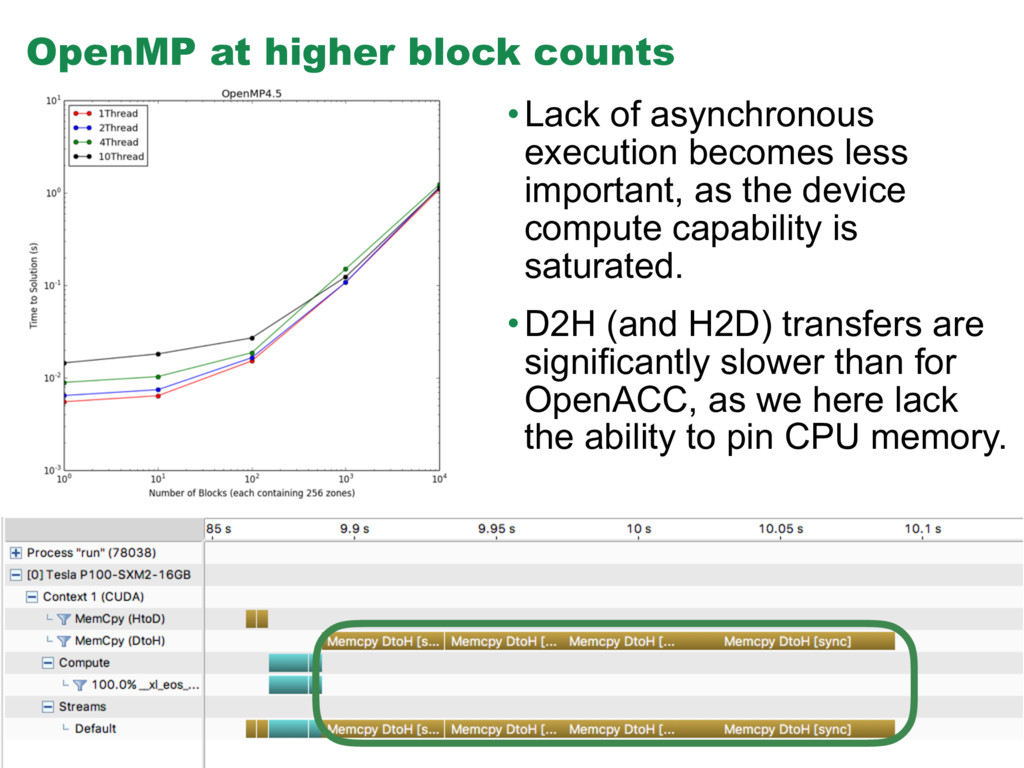
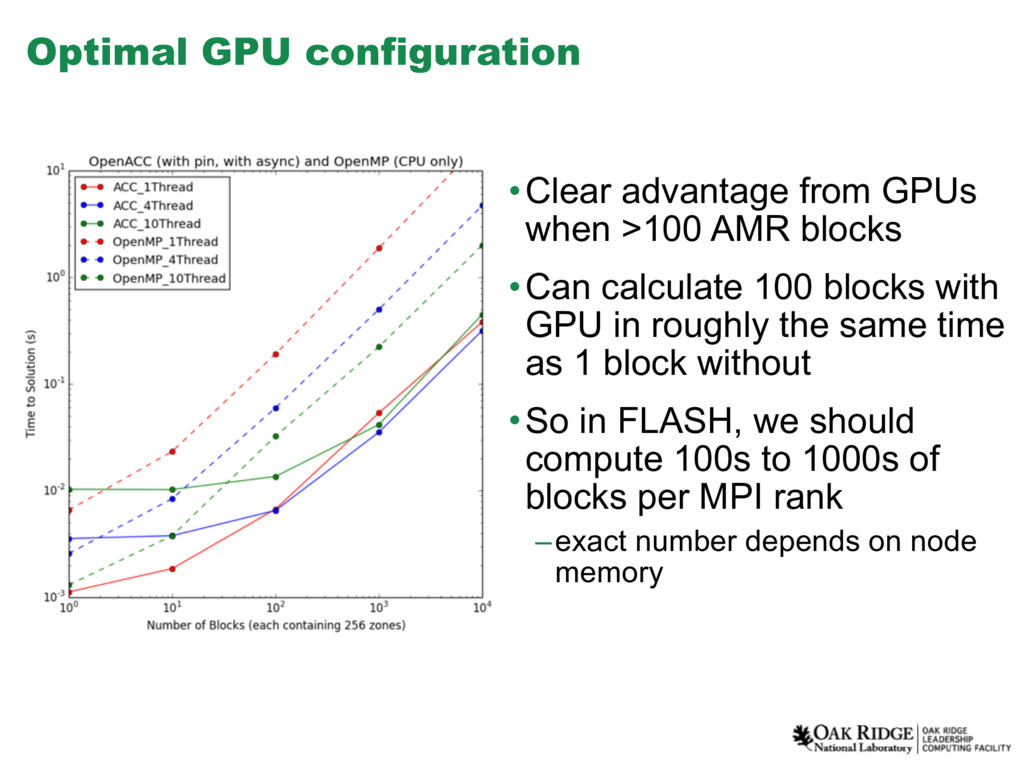
portability, so despite the current lower performance, we plan to use the OpenMP 4.5 implementation in FLASH production. • Primary factors affecting current OpenMP performance are the serialization of kernels on the device and high data transfer times associated with having to use pageable memory when using OpenMP 4.5. These are technical problems that are certainly surmountable. • In general, we find that the best balance between CPU threads and block number occurs at and above 2-4 CPU threads and roughly 1,000 blocks. We can retire all 1,000 of these EOS evaluations in a time less than 10x the fastest 100-block calculation for both OpenACC and OpenMP. • This mode is congruent with our planned production use of FLASH on the OLCF Summit machine, where we will place 3 MPI ranks on each CPU socket, each bound to one of the three available, closely coupled GPUs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
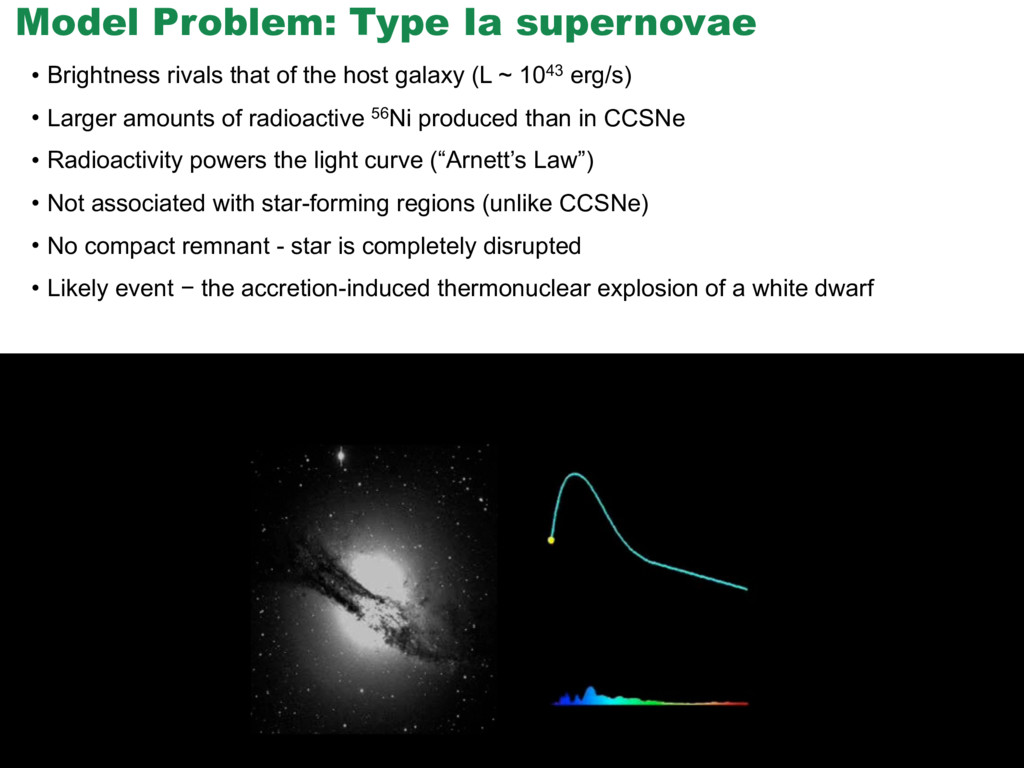{kind=link}
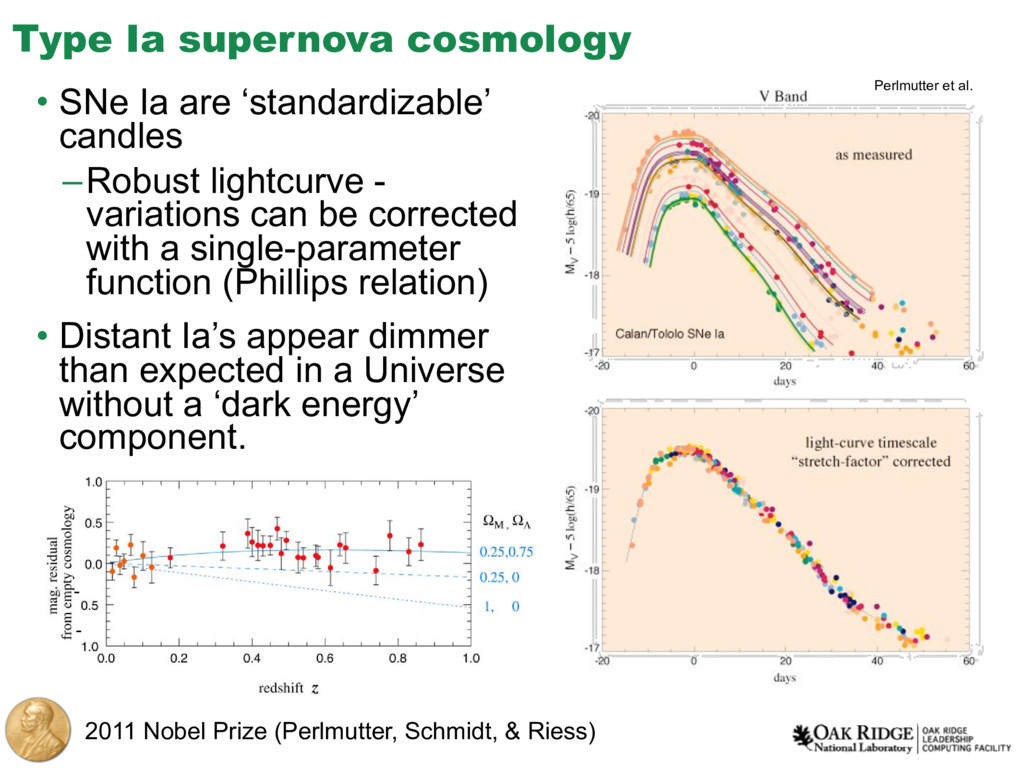{kind=link}
{kind=link}
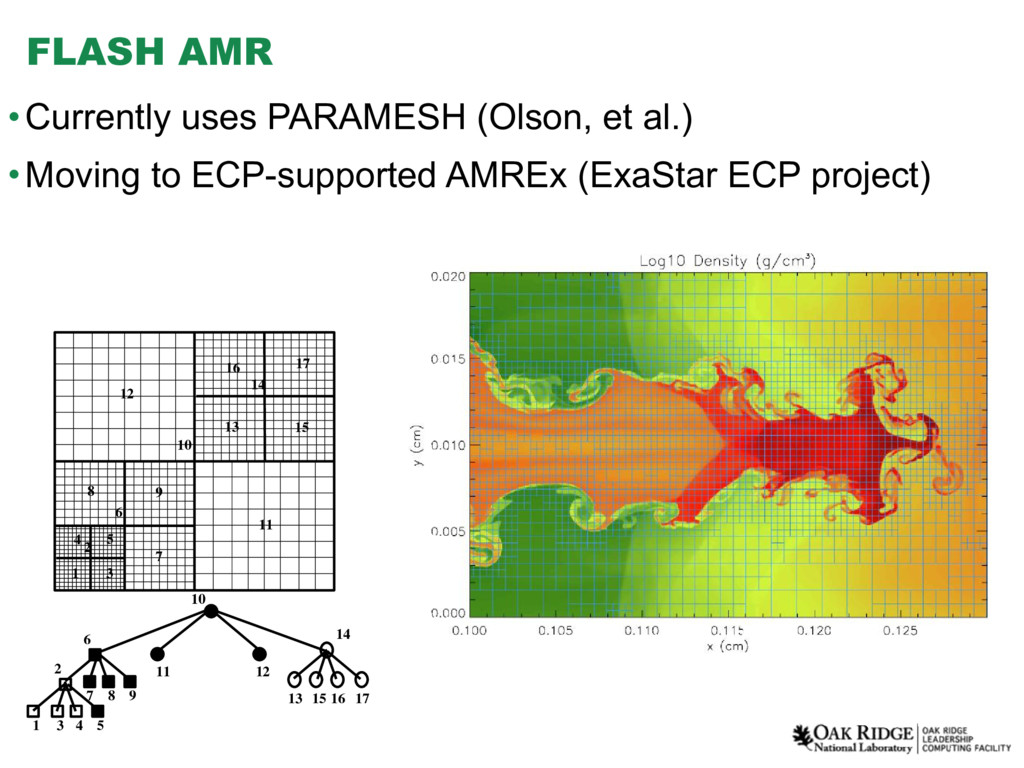{kind=link}
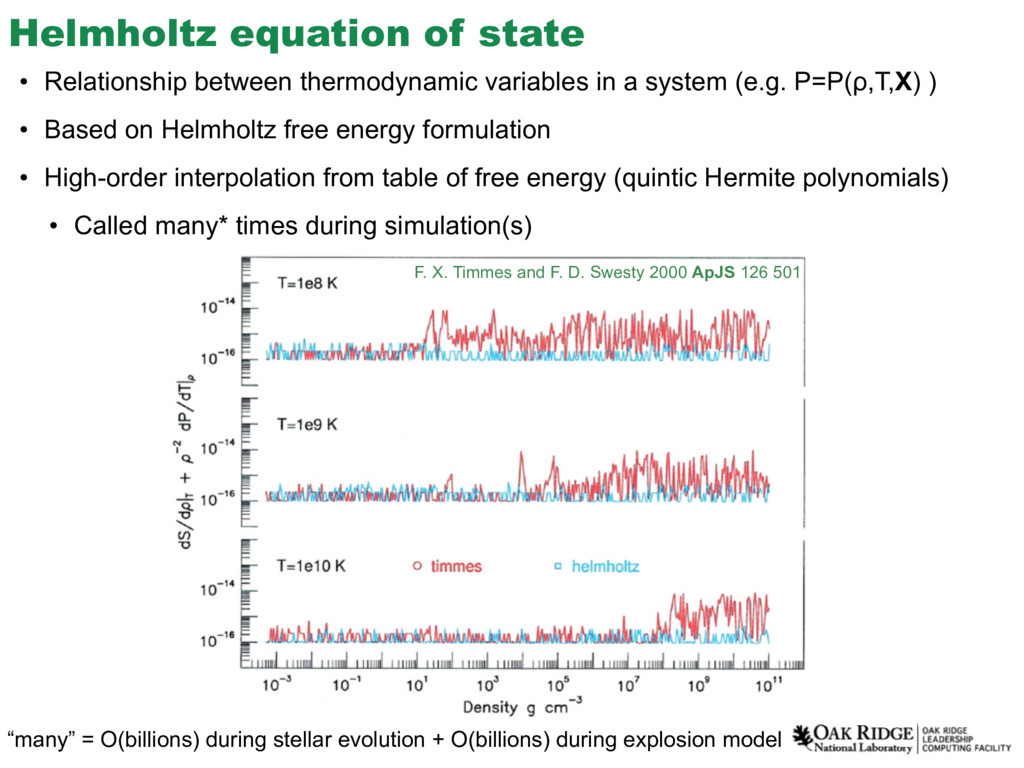{kind=link}
{kind=link}
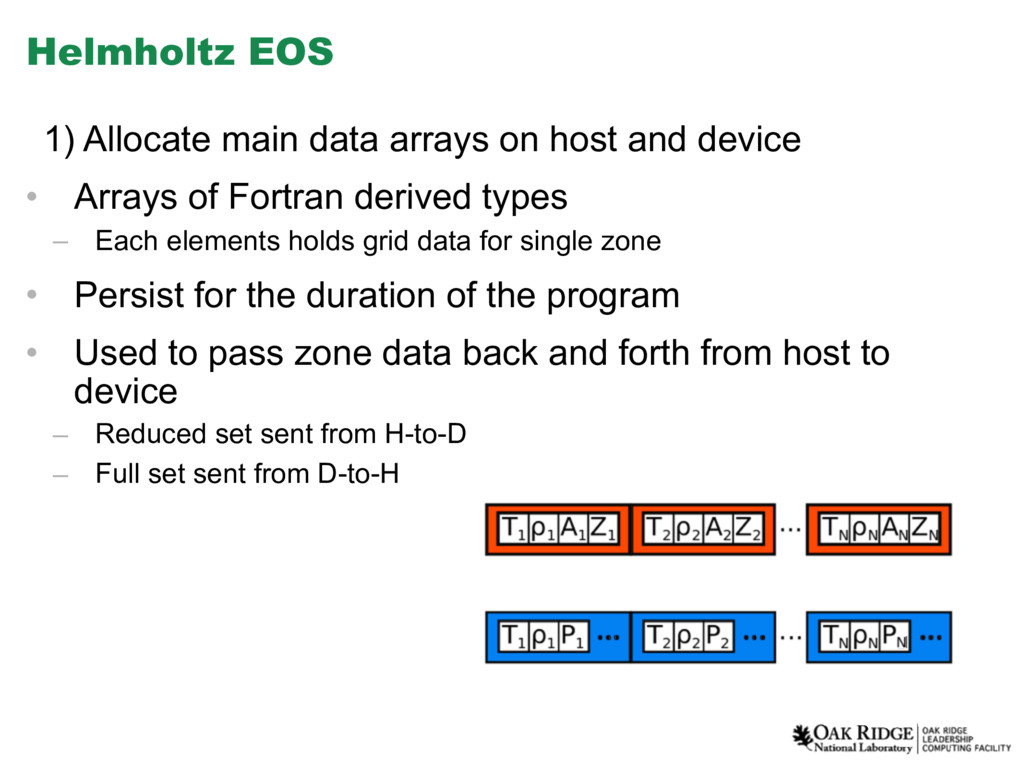{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
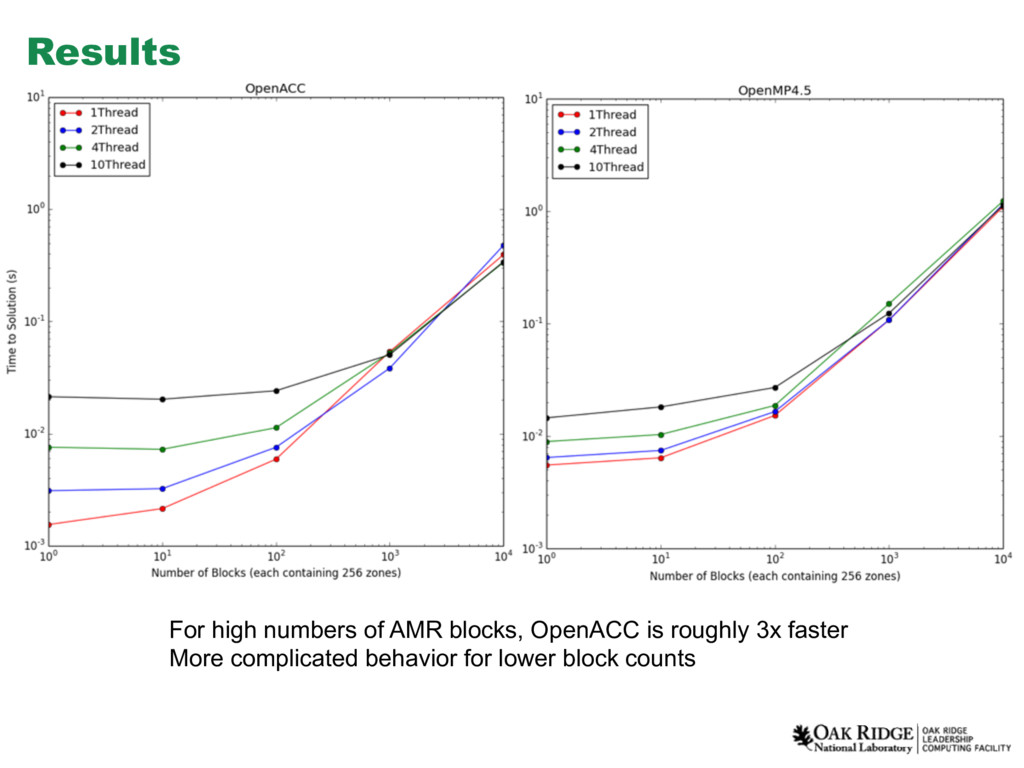{kind=link}
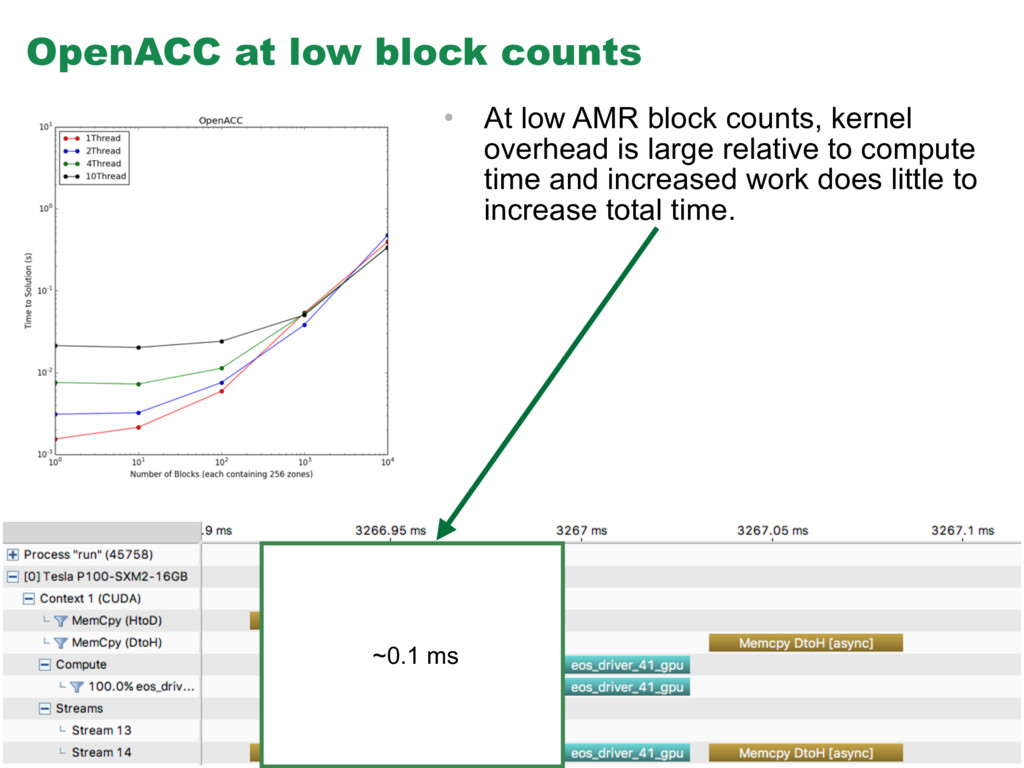{kind=link}
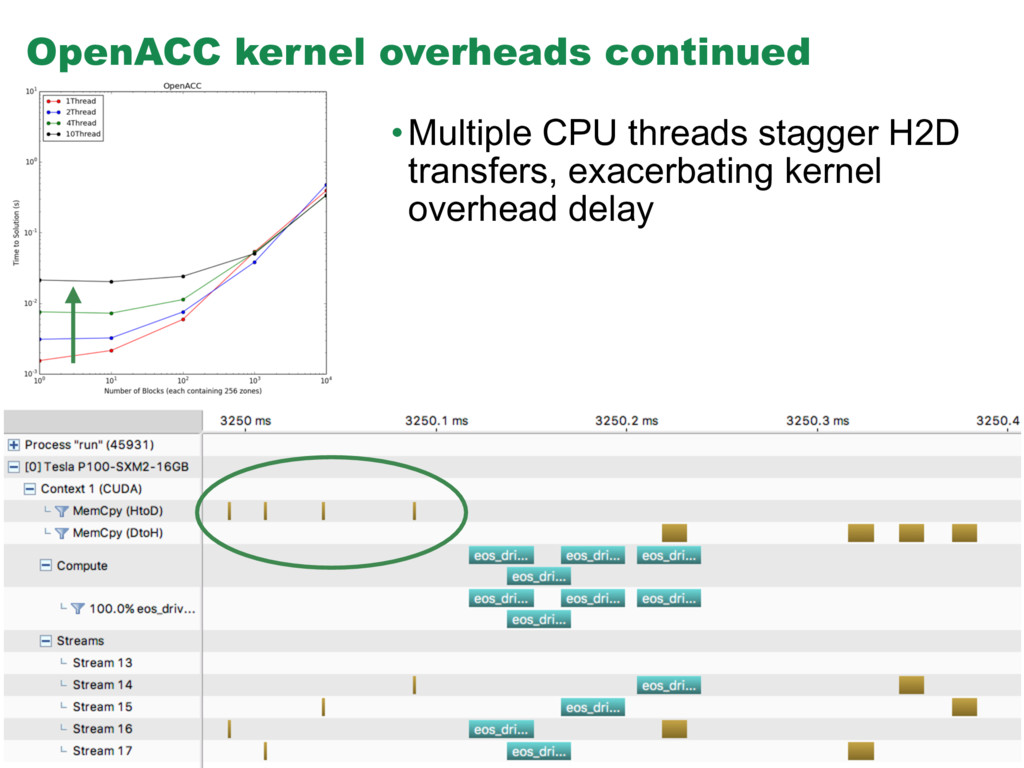{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}