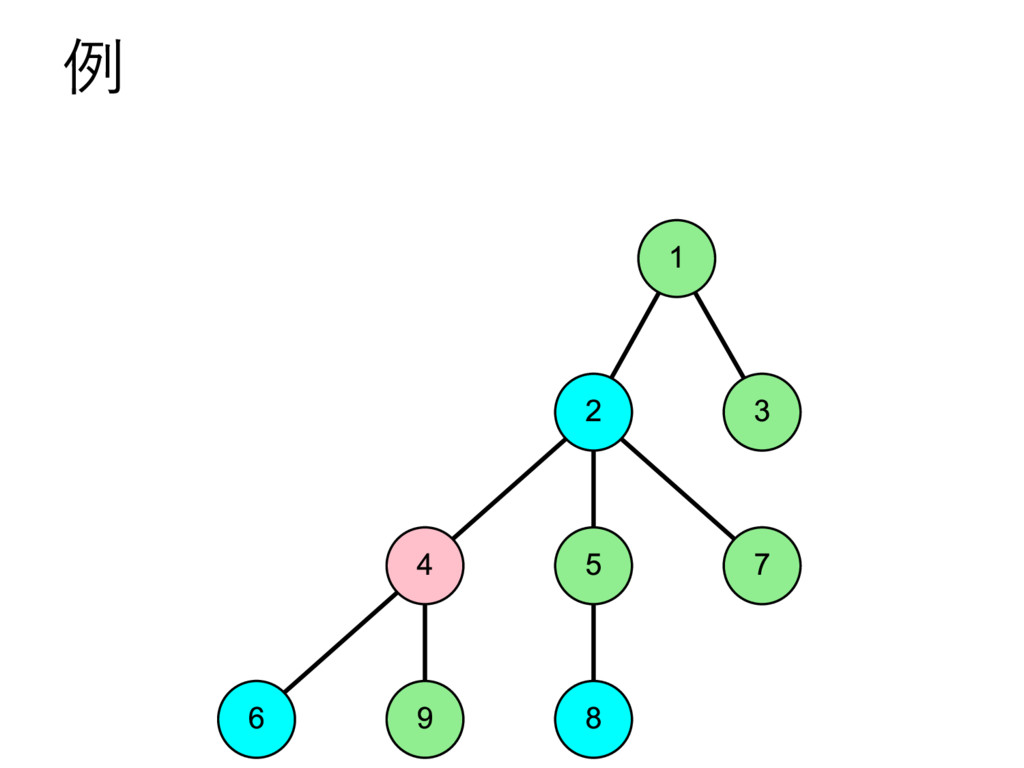
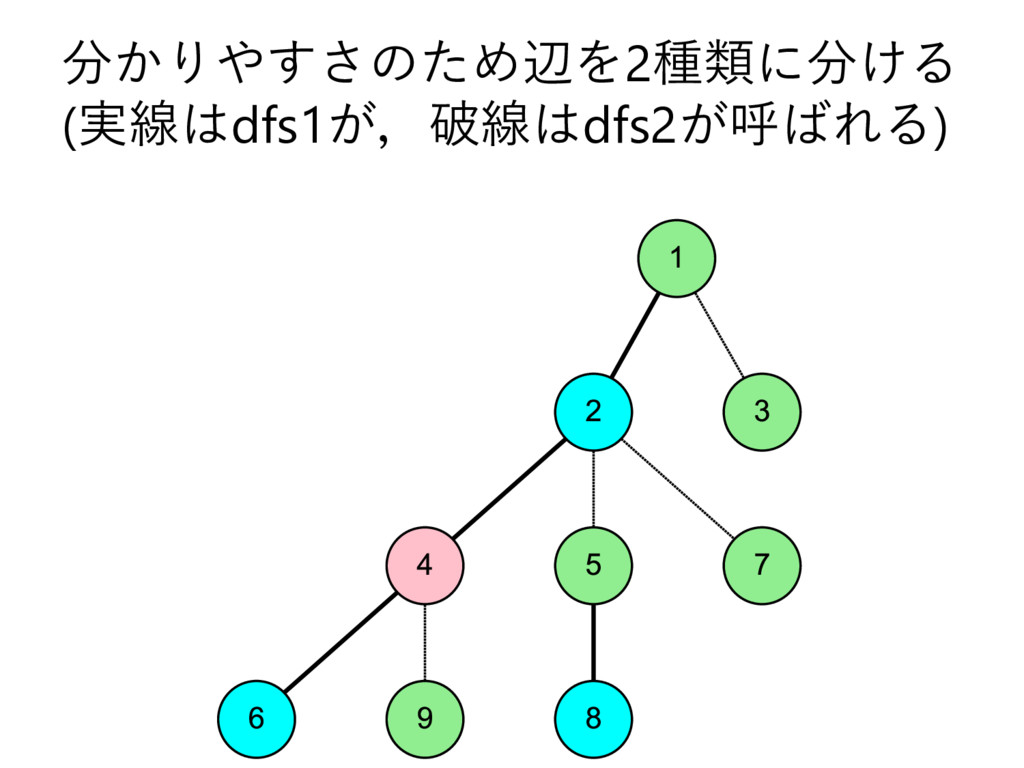
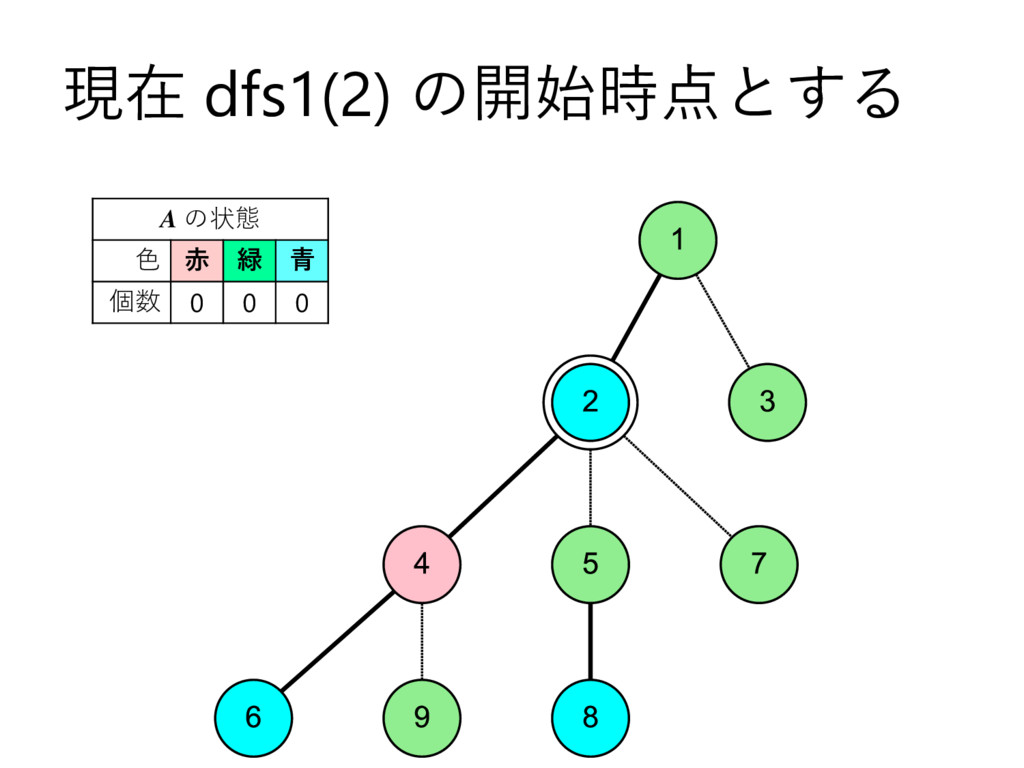
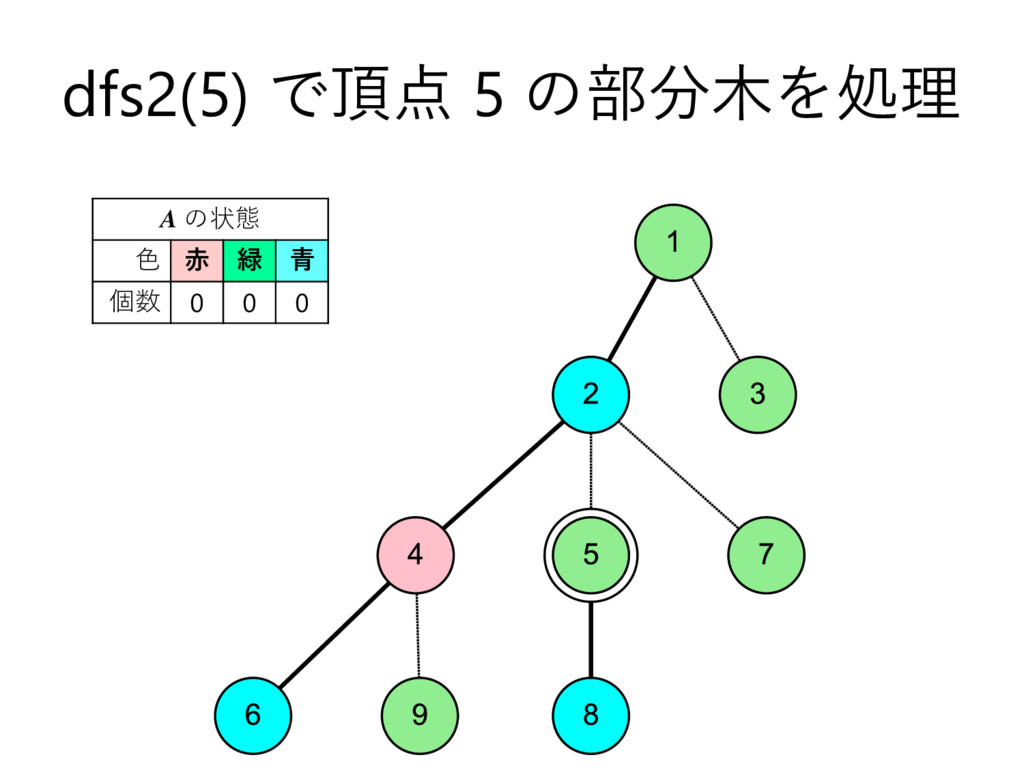
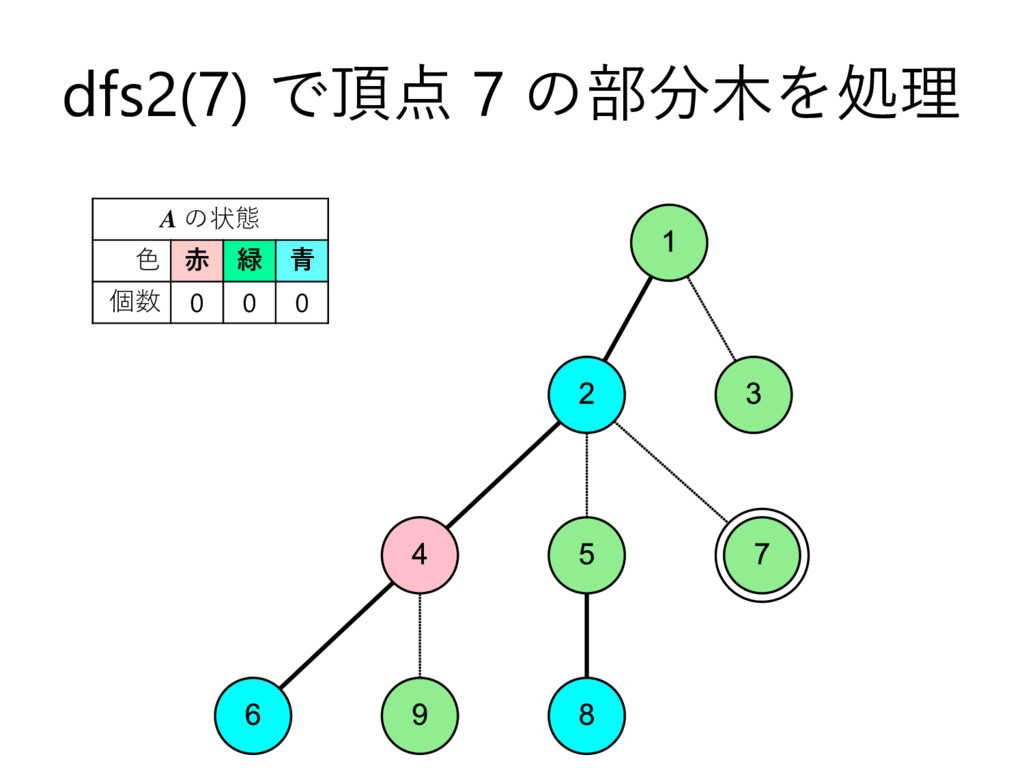
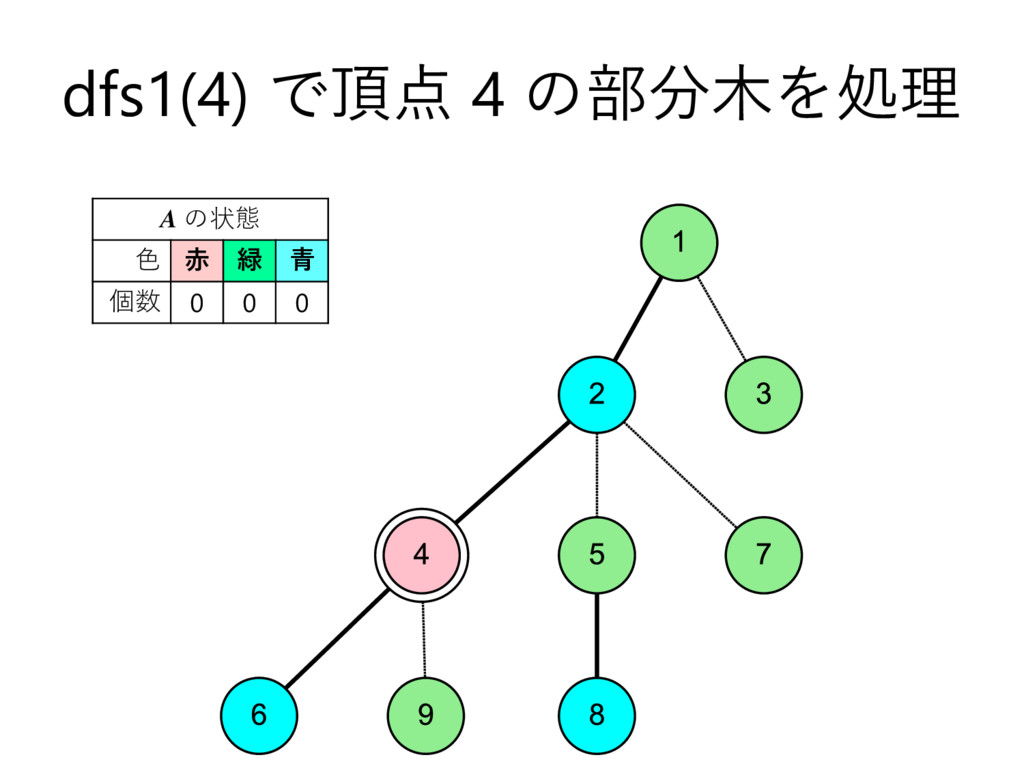
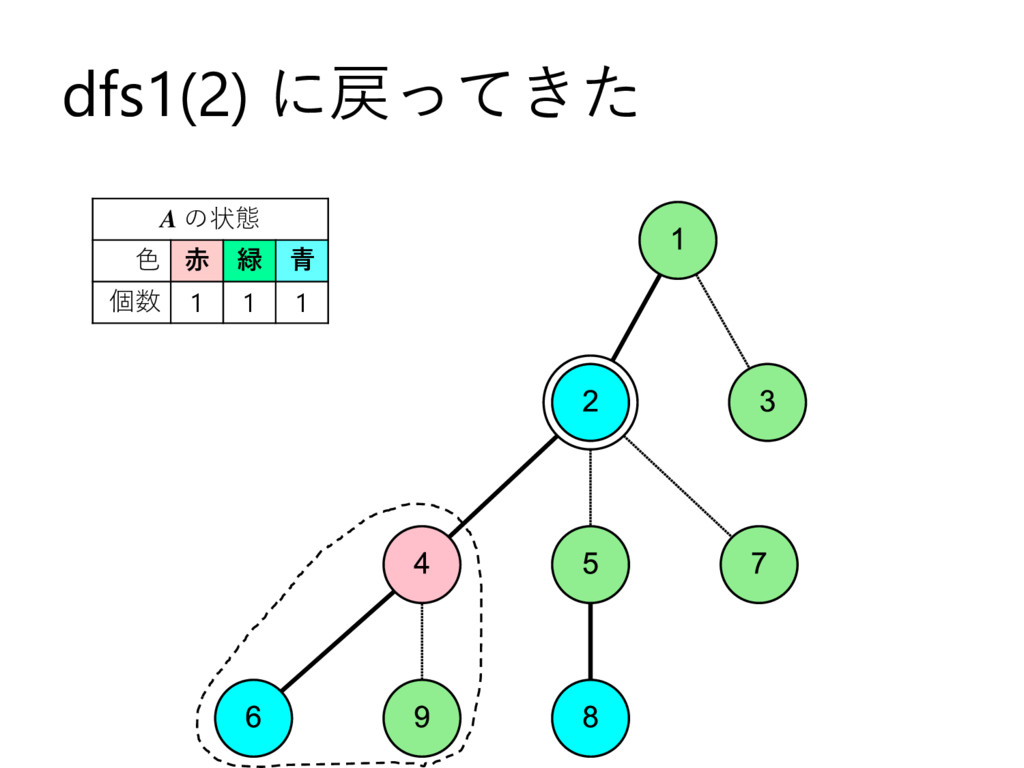
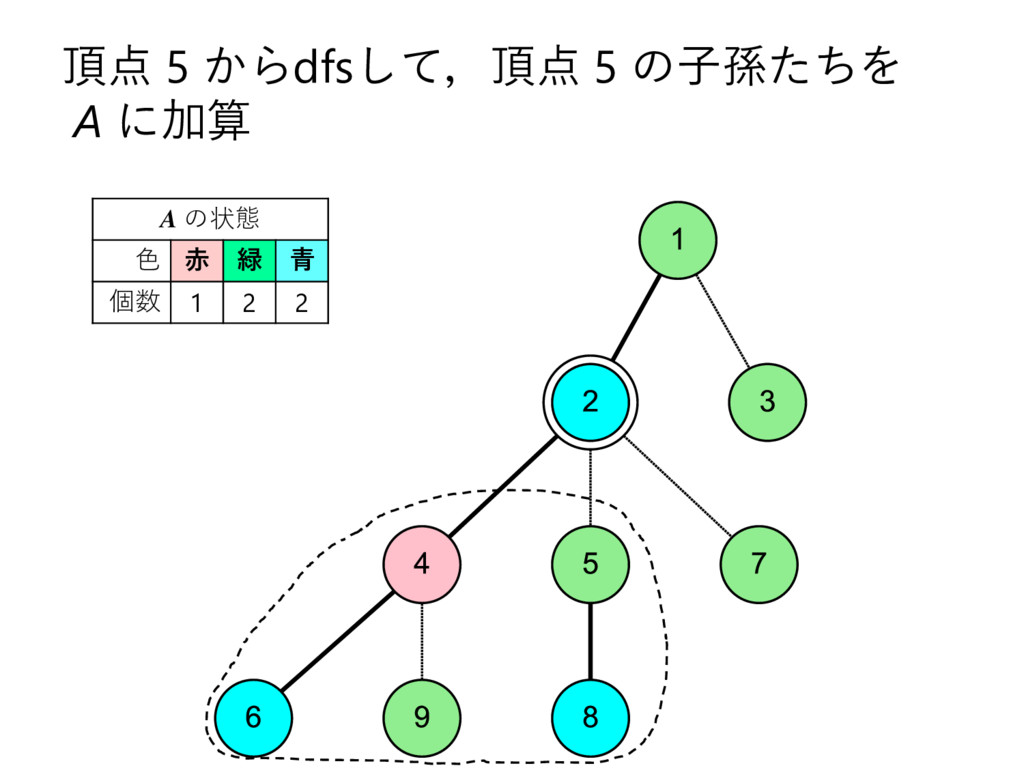
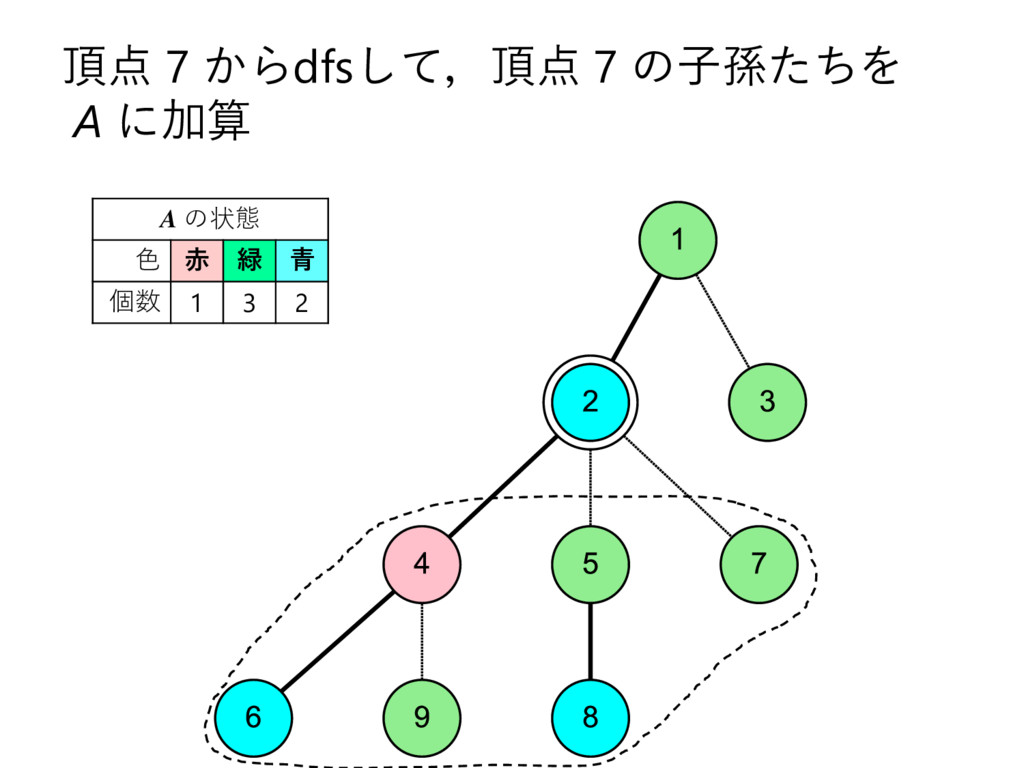
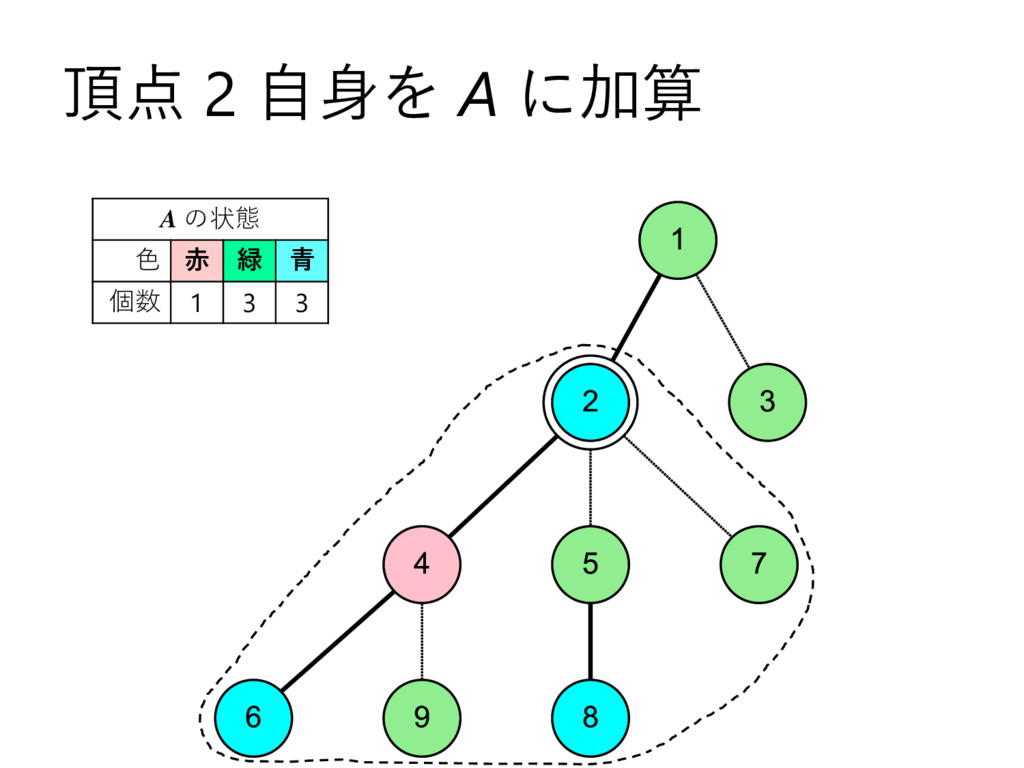
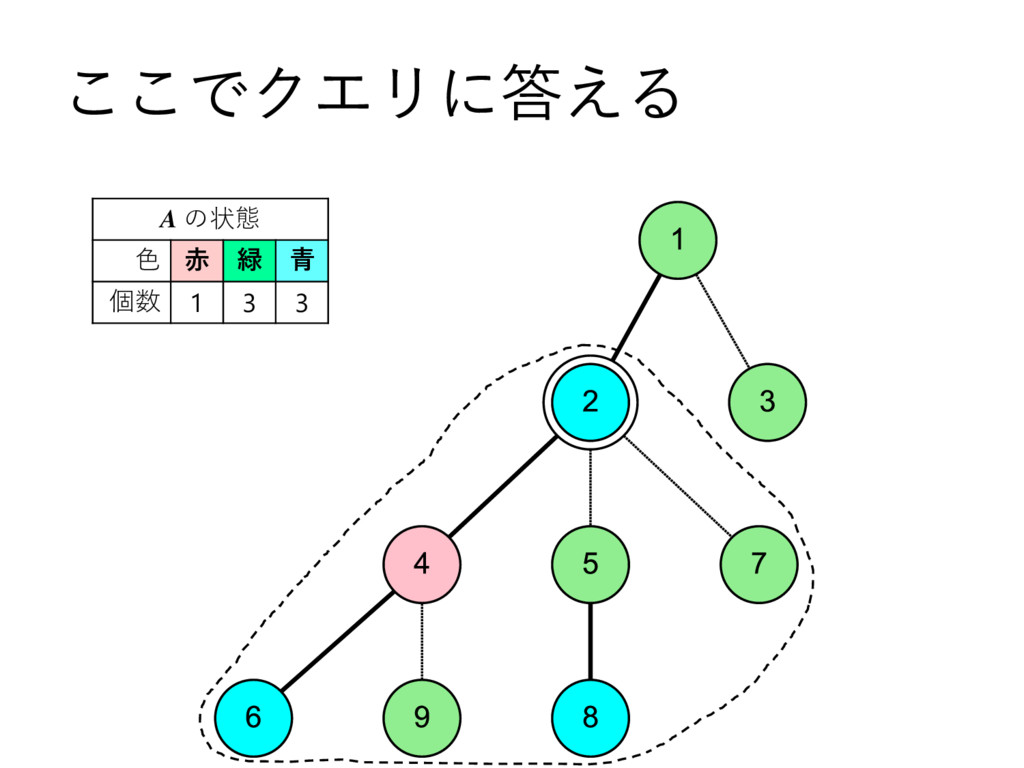
… , uk とする – 部分木のサイズの降順で並んでいる,とする • u2 , u3 , u4 , … , uk についてdfs2で処理 • u1 についてdfs1で処理して結果を受け取る – これを A とする • u2 , u3 , u4 , … , uk を根とする部分木に 含まれる頂点の色を全て調べて A に加算 • v 自身の色を A に加算 – このタイミングでクエリについて処理 • A を返す
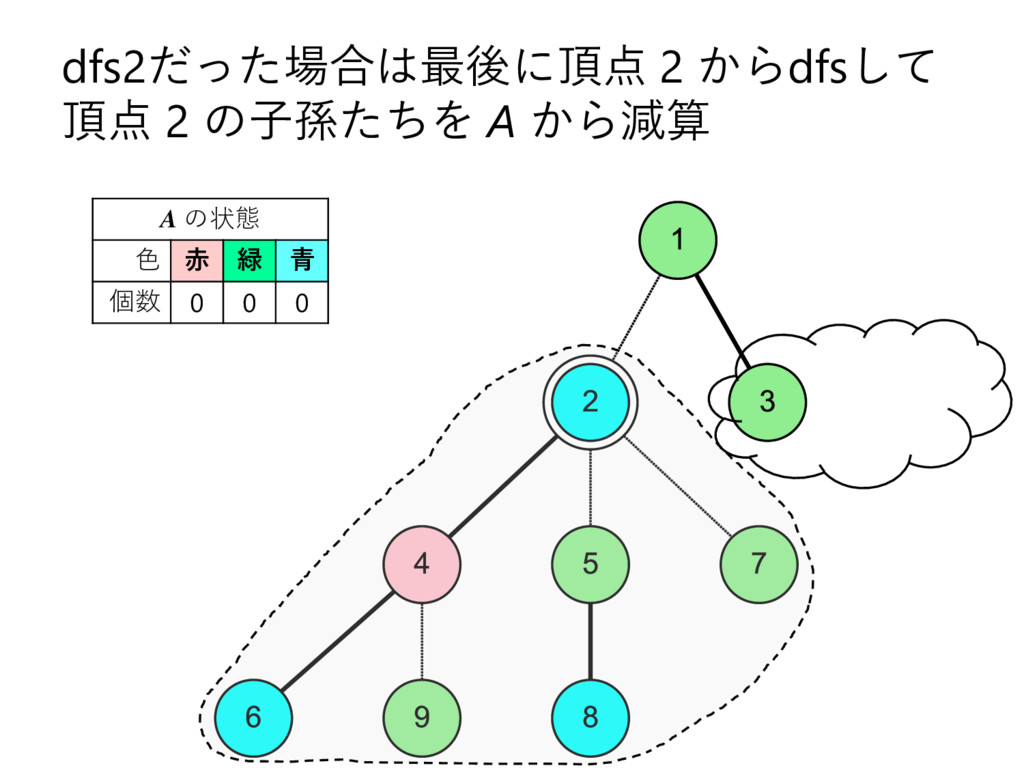
… , uk とする – 部分木のサイズの降順で並んでいる,とする • u2 , u3 , u4 , … , uk についてdfs2で処理 • u1 についてdfs1で処理して結果を受け取る – これを A とする • u2 , u3 , u4 , … , uk を根とする部分木に 含まれる頂点の色を全て調べて A に加算 • v 自身の色を A に加算 – このタイミングでクエリについて処理 • vを根とする部分木に含まれる頂点の色を 全て調べて A から減算
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}