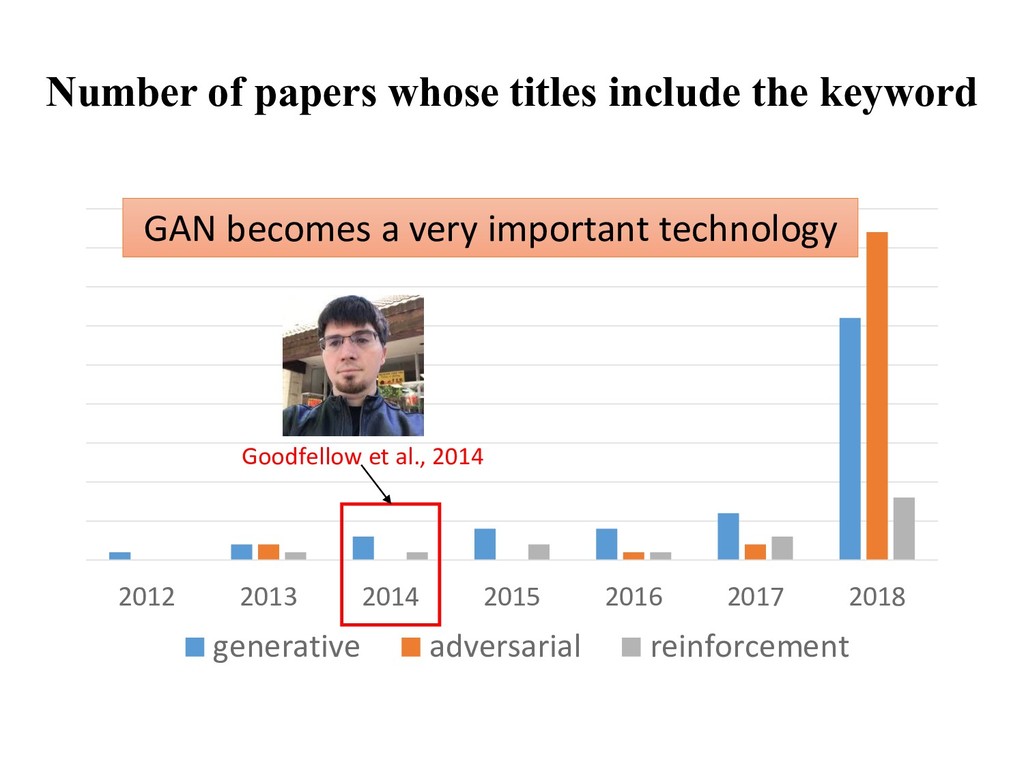
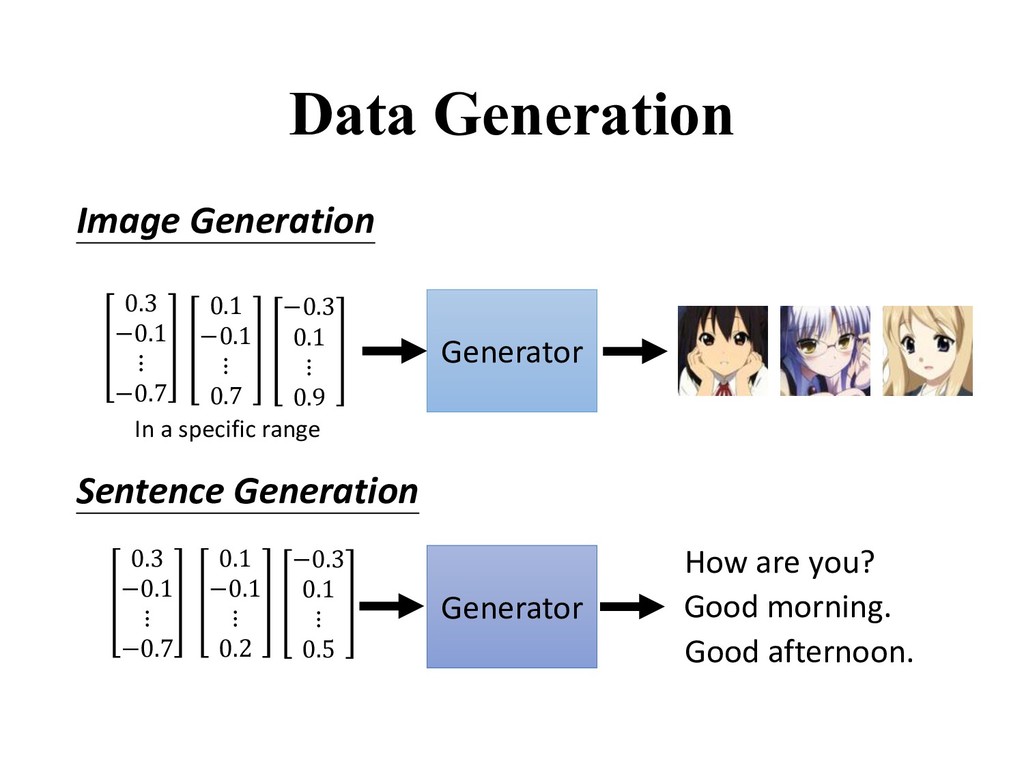
Speech synthesis: — Machine translation: Chinese English • Chinese: 我喜欢深度学习。 • English: I love deep learning. • Environment simulator — Reinforcement learning — Planning • Leverage unlabeled data
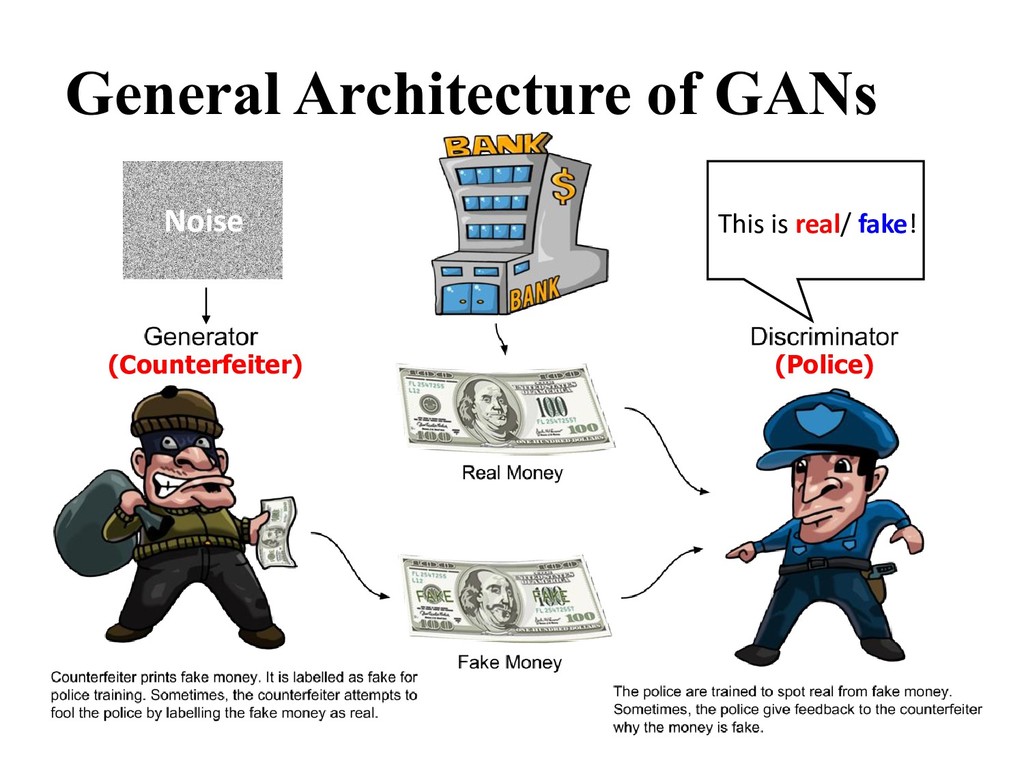
generate new samples that are as similar as data and fool the discriminator — Discriminative model D: act as a judge to distinguish the generated samples from the real one adversarial Generator Discriminator Vs
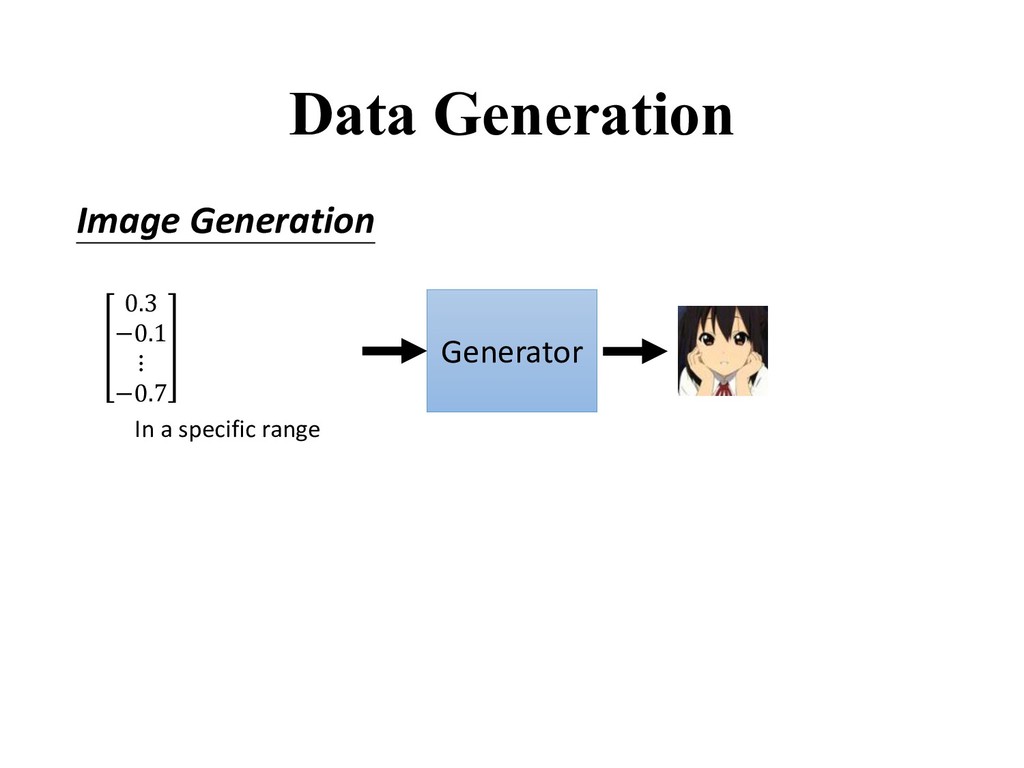
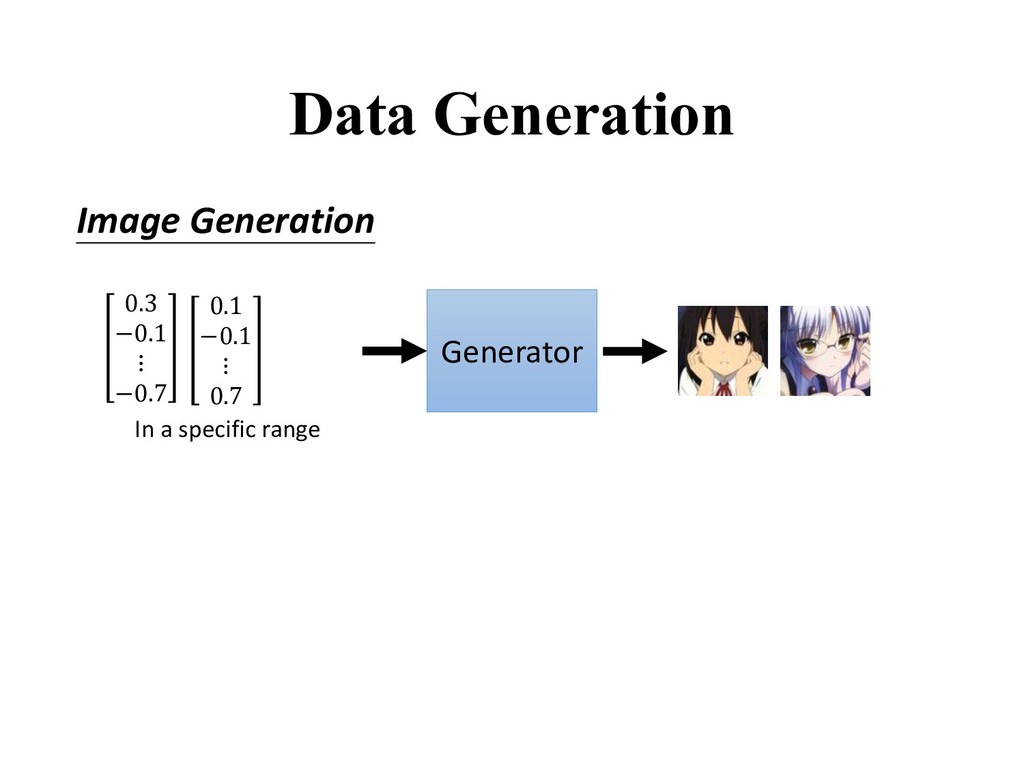
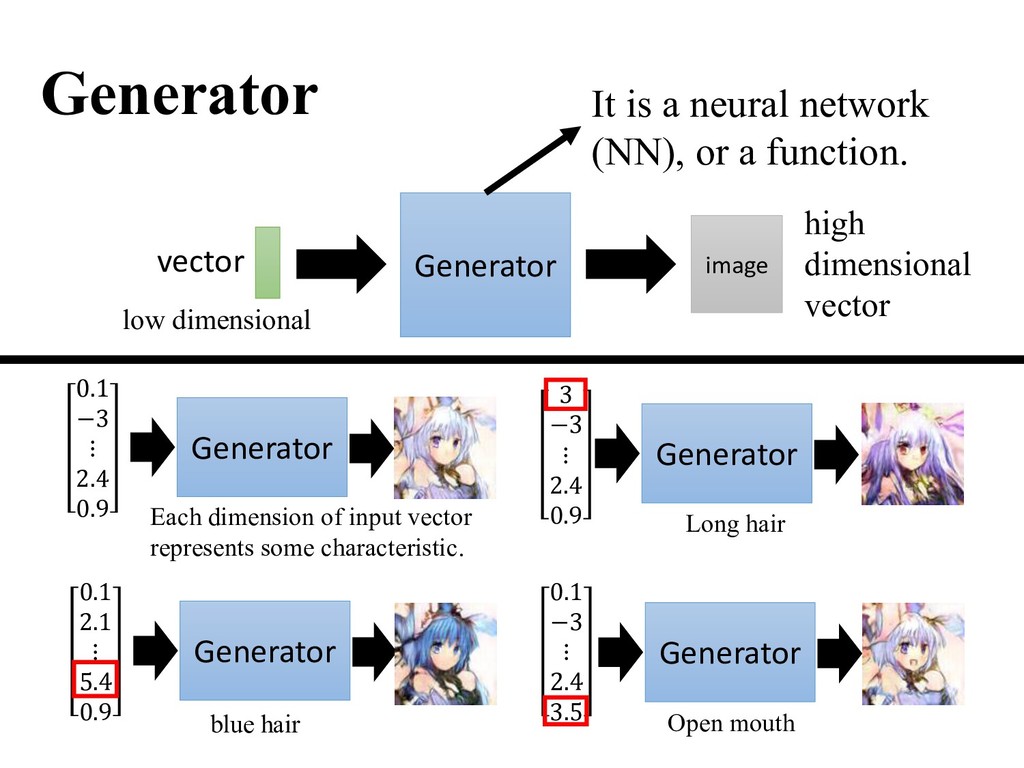
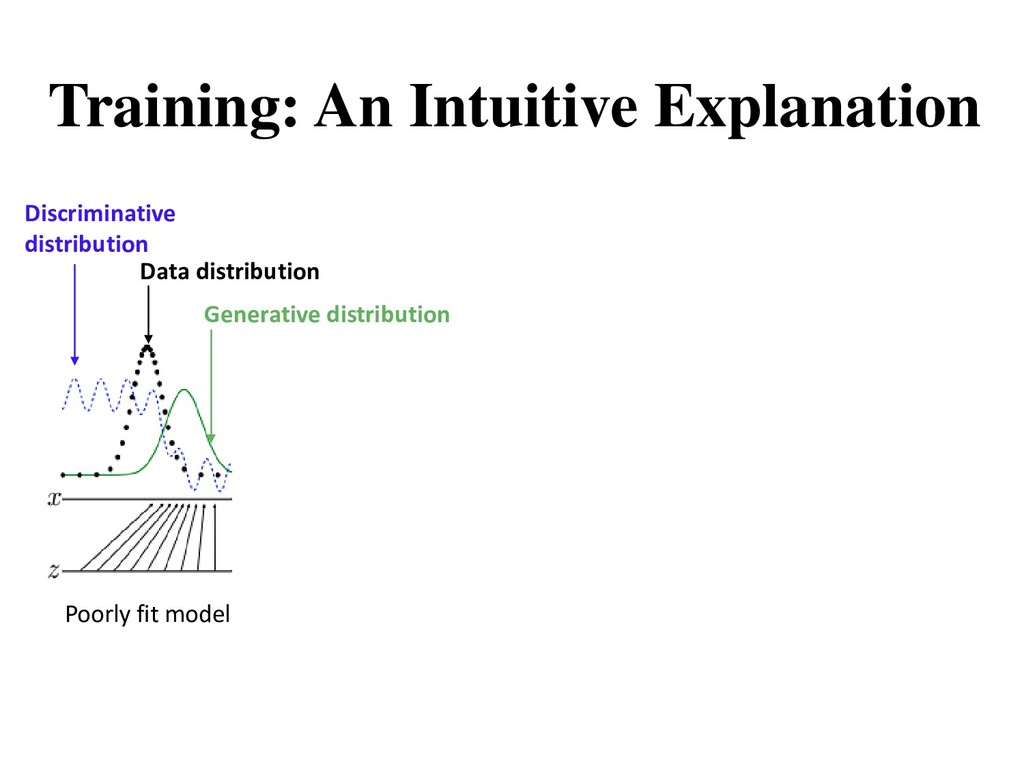
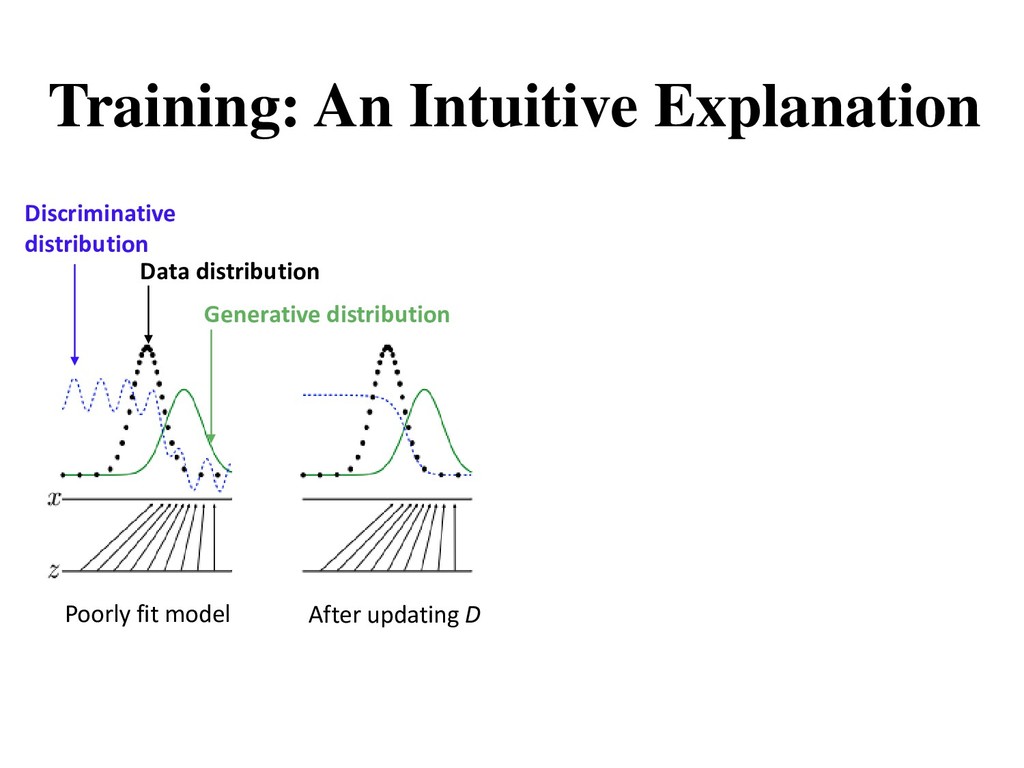
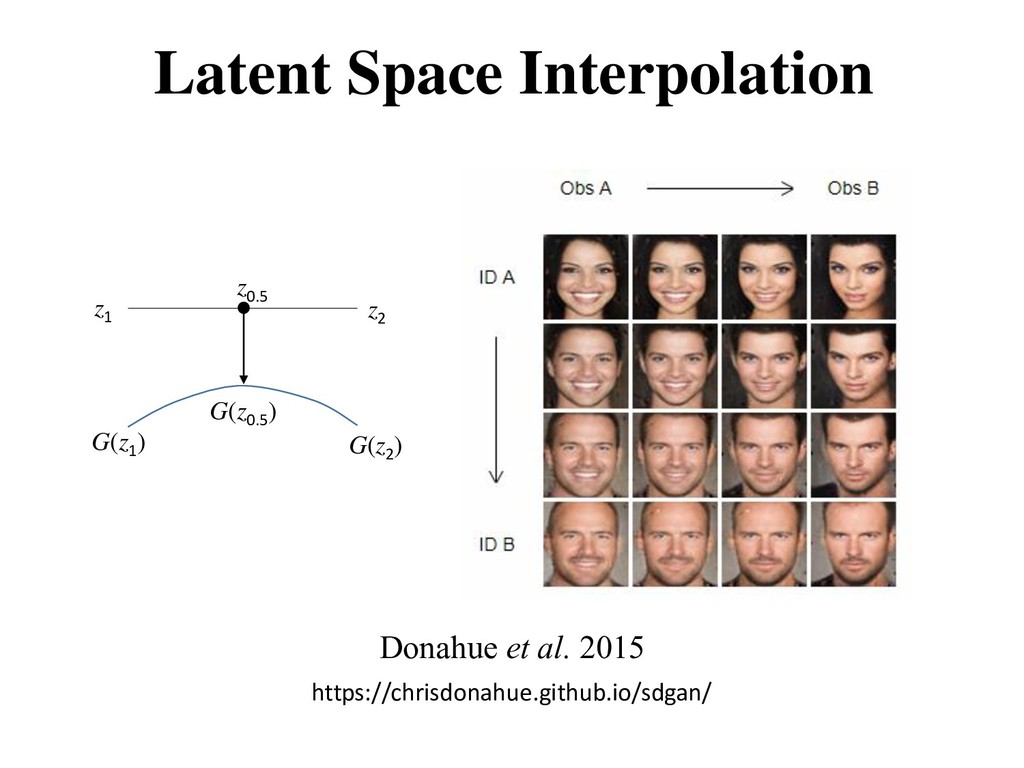
. • is a latent variable drawn from a prior distribution. • Trainable for any size of A generative model tries to learn the distribution of real data from the prior distribution ().
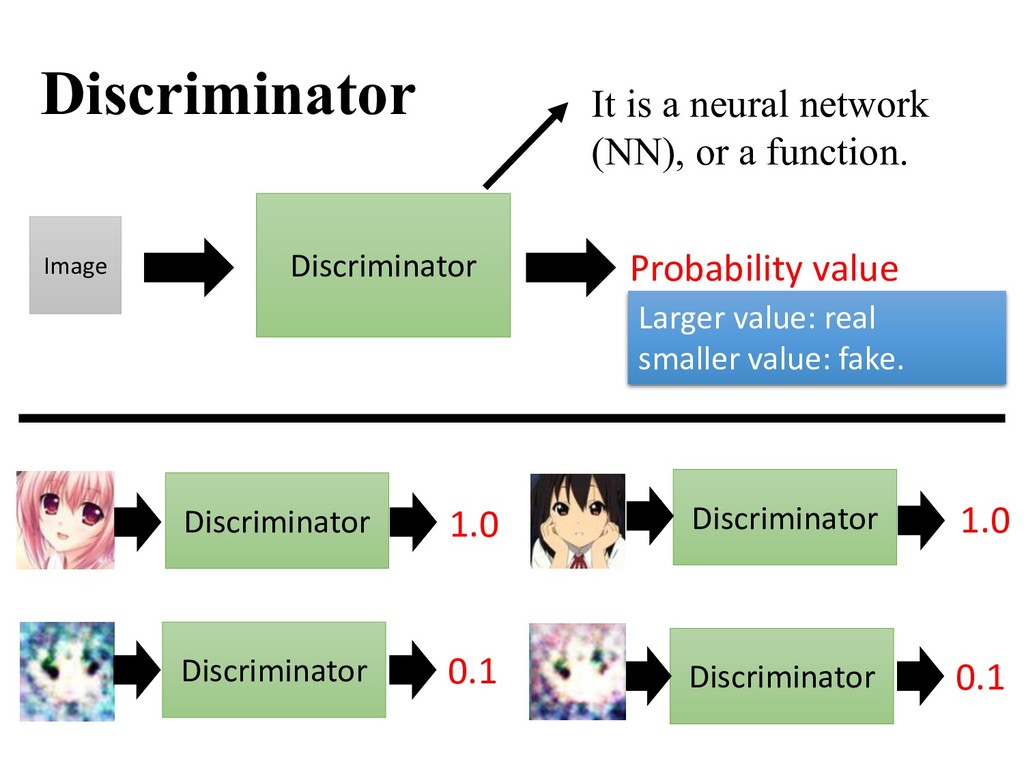
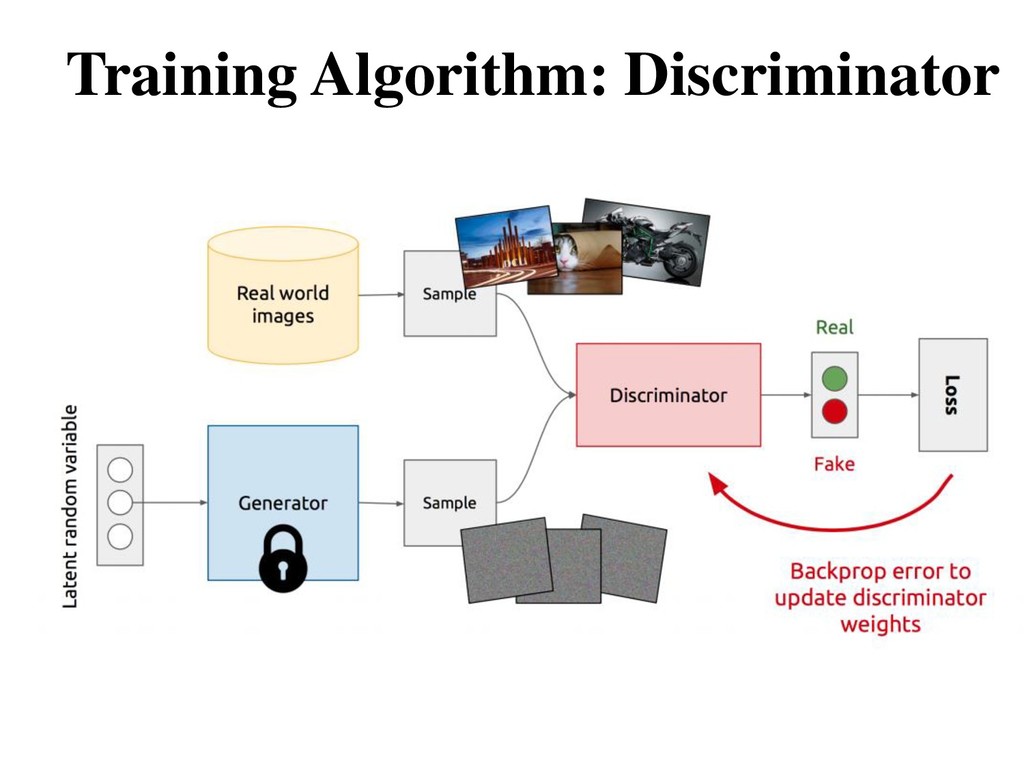
generated samples from the real data • (): estimate the probability that is a real data sample — = 1: regards as a real sample — = 0: regards as a fake sample Discriminative Model Binary classification
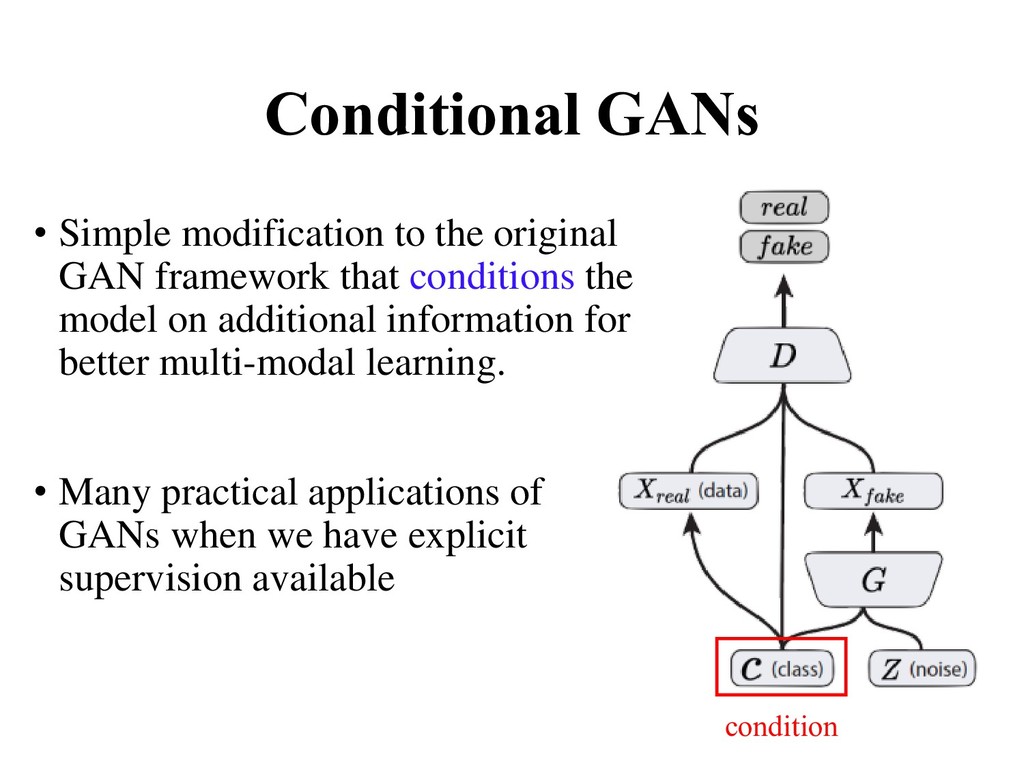
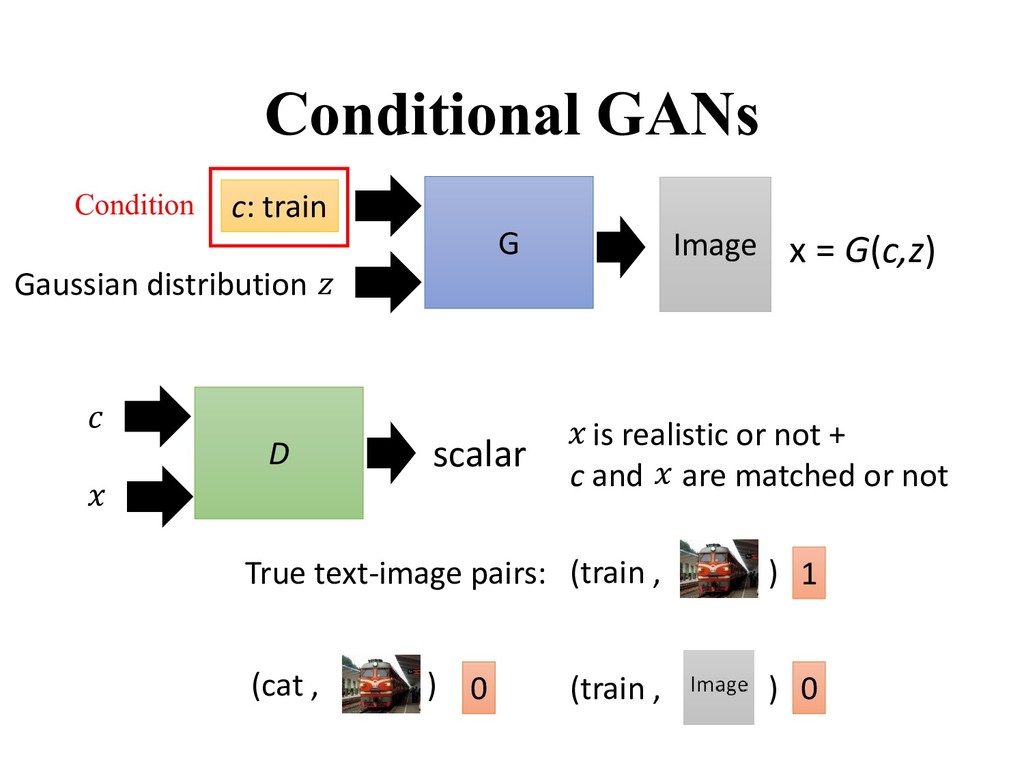
framework that conditions the model on additional information for better multi-modal learning. • Many practical applications of GANs when we have explicit supervision available
correct • Discriminator maximizes cross-entropy of real and generated data • Equilibrium is a saddle point of the discriminator loss Cross-entropy Loss
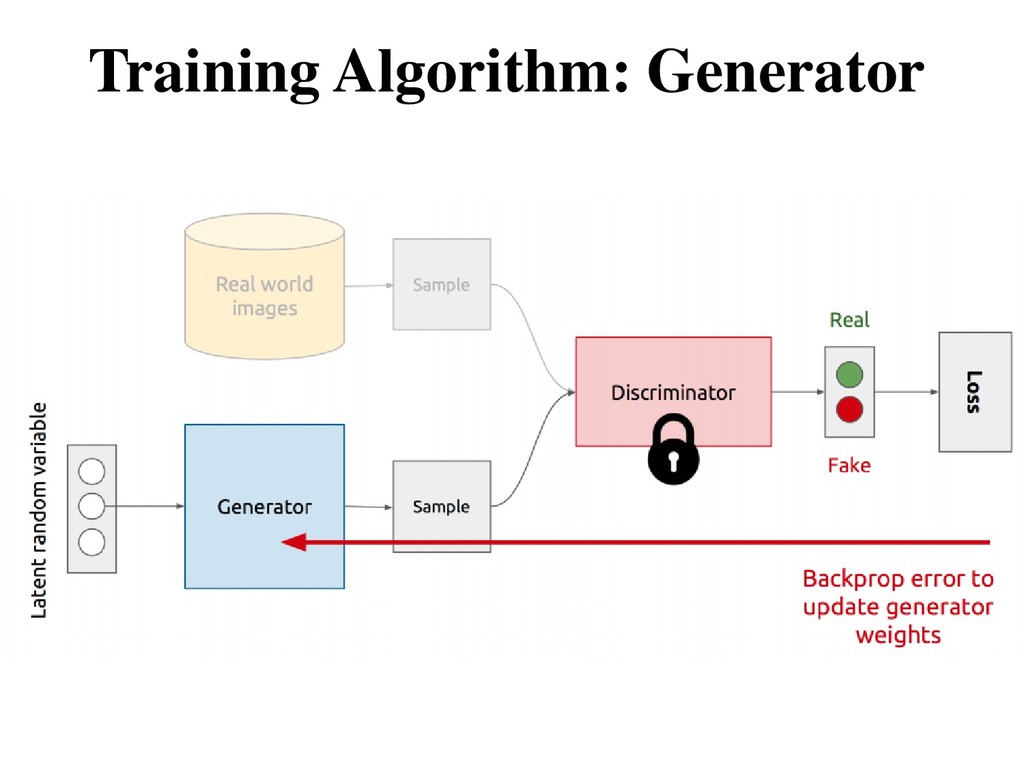
D(x) is close to 1 (real) and D(G(z)) is close to 0 (fake) • Generator aims to minimize objective such that D(G(z)) is close to 1 (discriminator is fooled into thinking generated G(z) is real)
• A mini-batch of training samples • A mini-batch of generated samples • Optional: Run steps of one player for every step of the other player - example: WGAN updates Discriminator for 5 steps and Generator for 1 step.
Generator vector 0.13 hidden layer update fix large network Generator learns to “fool” the discriminator Training Algorithm: Generator Objective of the discriminator:
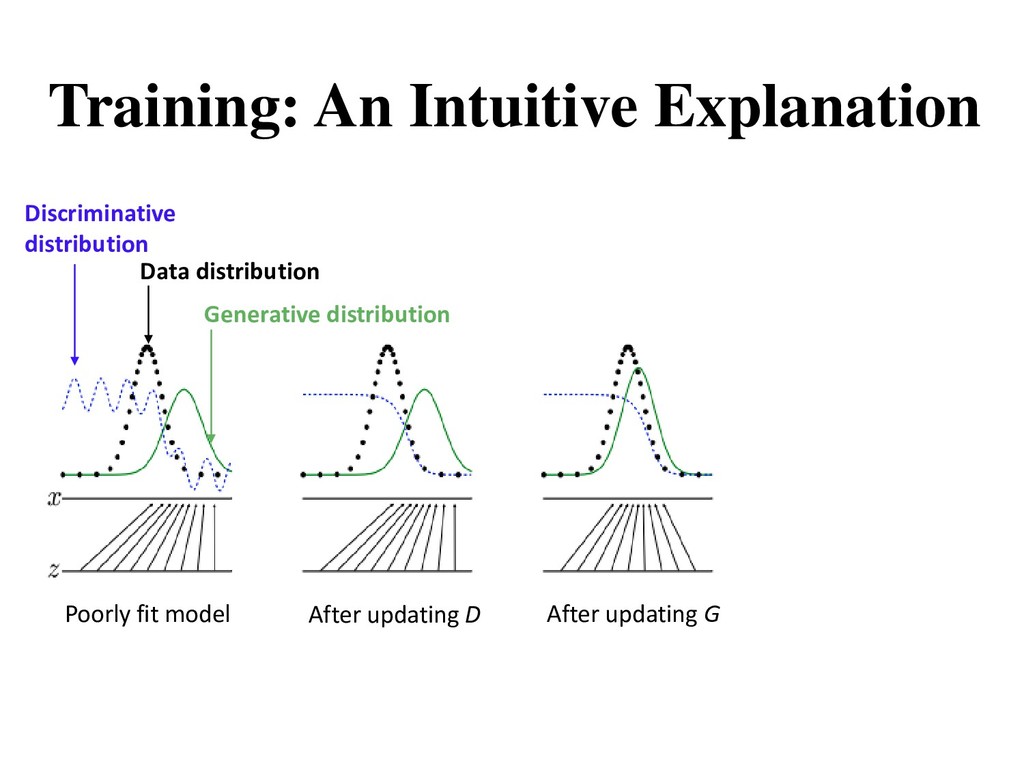
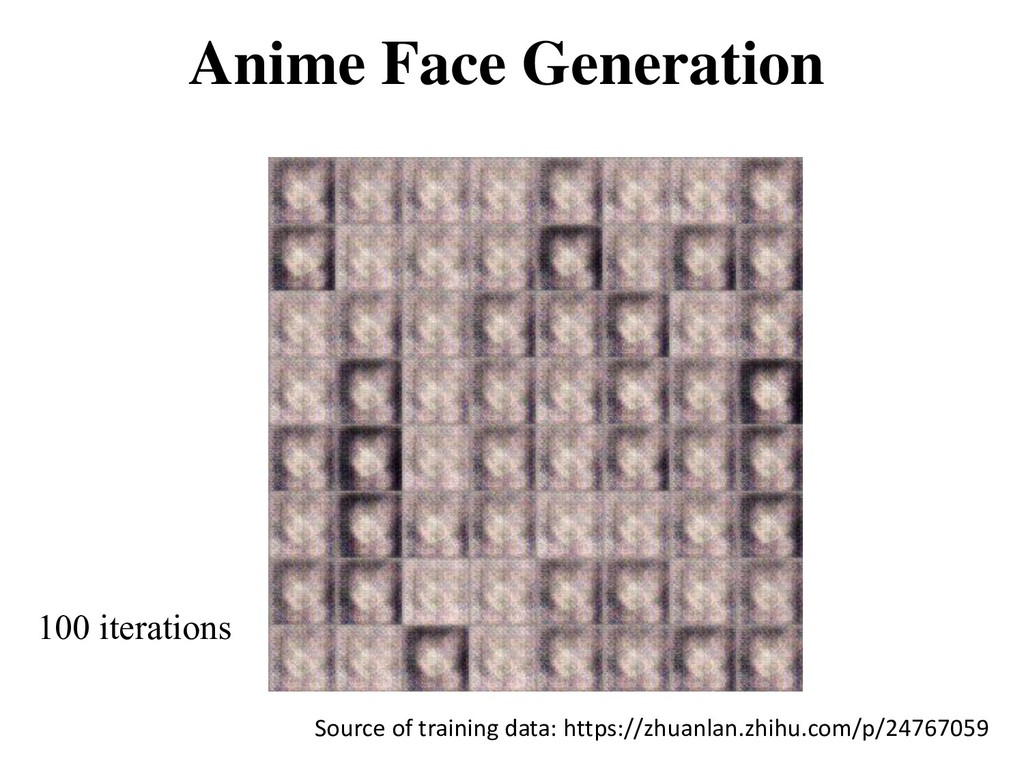
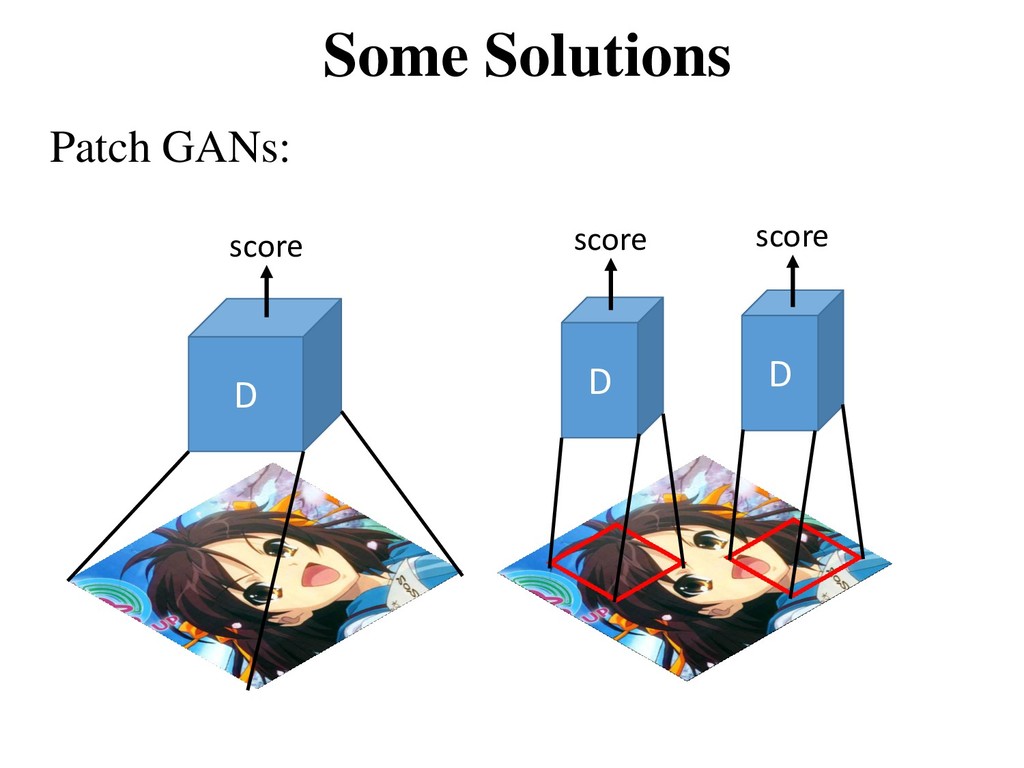
theoretically guaranteed to converge, the model often break down during the training • Oscillation: GAN can be trained for a very long time without clearly generating better samples • Training imbalance: discriminator becomes too strong too quickly and the generator ends up not learning anything • Mode collapse: almost all the samples look the same (very low diversity) • Visual problems: counting, perspective, global structure, etc.
smoothed cost (Salimans et al. 2016) : label : probability Benefits • Prevents discriminator from giving very large gradient signal to generator • Stabilize the training and prevents extrapolating to encourage extreme samples One-Sided Label Smoothing: Some Solutions
Track failures early (D loss goes to 0: failure mode) • If you have labels, use them • Add noise to inputs, decay over time Tricks for GANs . . . . . .
two stochastic neural network modules: Generator and Discriminator. • Generator tries to generate samples from random noise as input. • Discriminator tries to distinguish the samples from Generator and samples from the real data distribution. • Both players are trained adversarially to fool each other, and they become better at their respective tasks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![WeChat My website Thank you! My mail: [email protected] Questions?](https://files.speakerdeck.com/presentations/84f0931b53814eaeb0a1f3e846e48bb8/slide_78.jpg){kind=link}