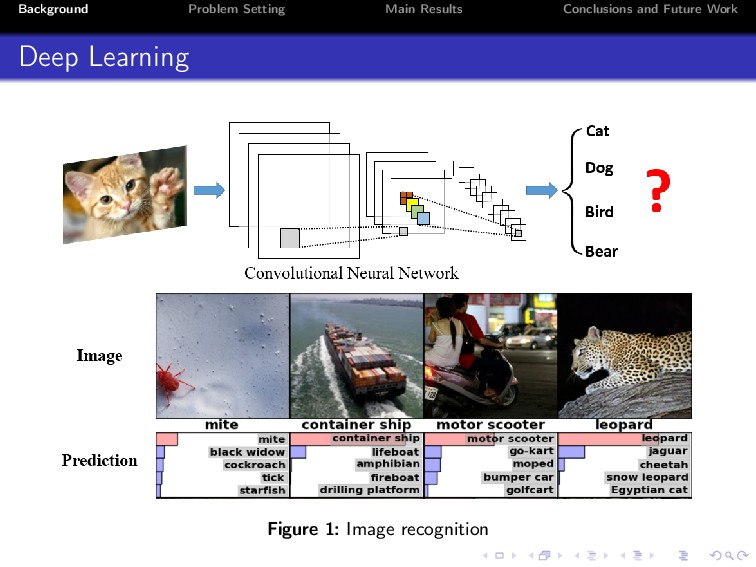
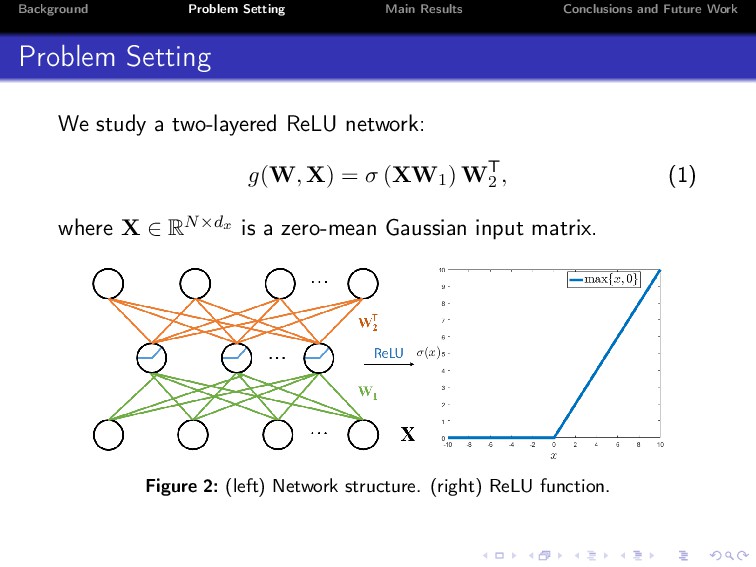
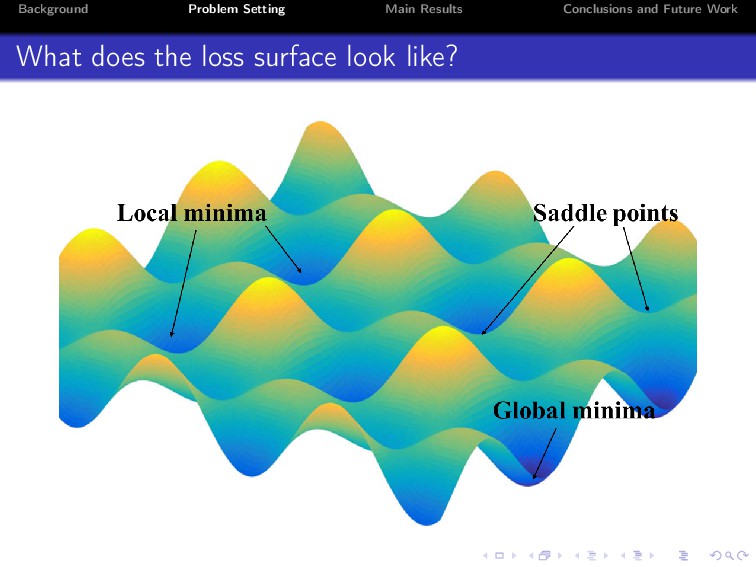
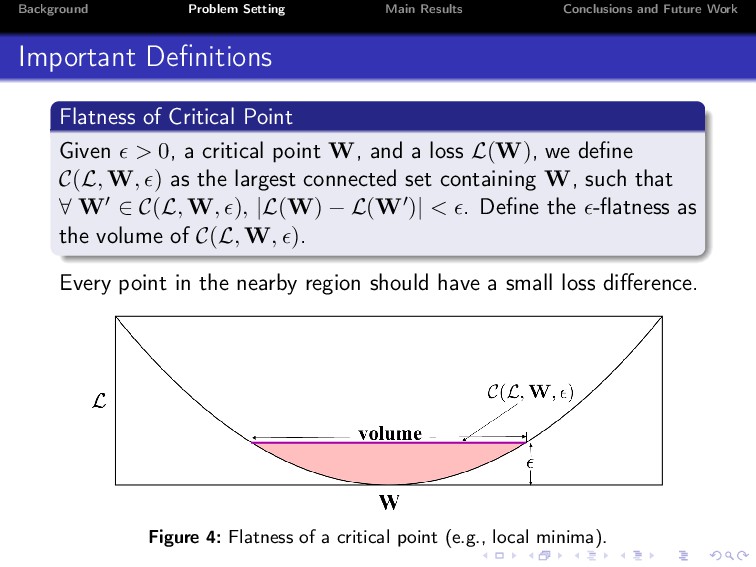
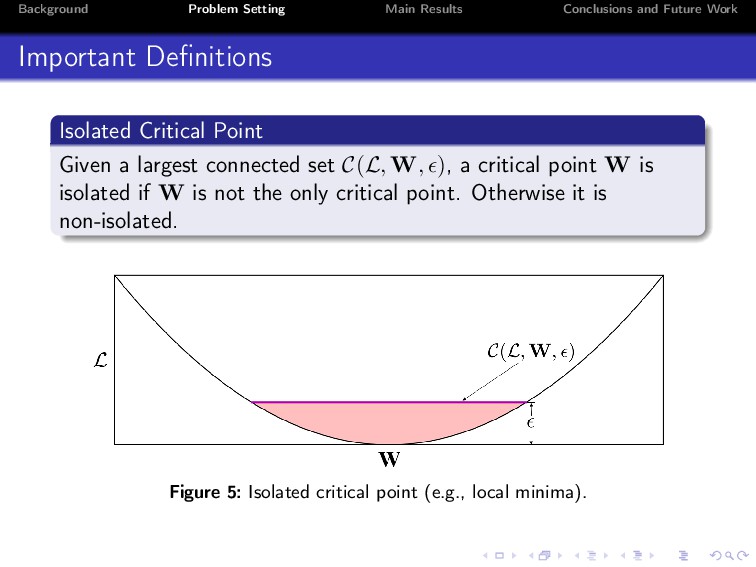
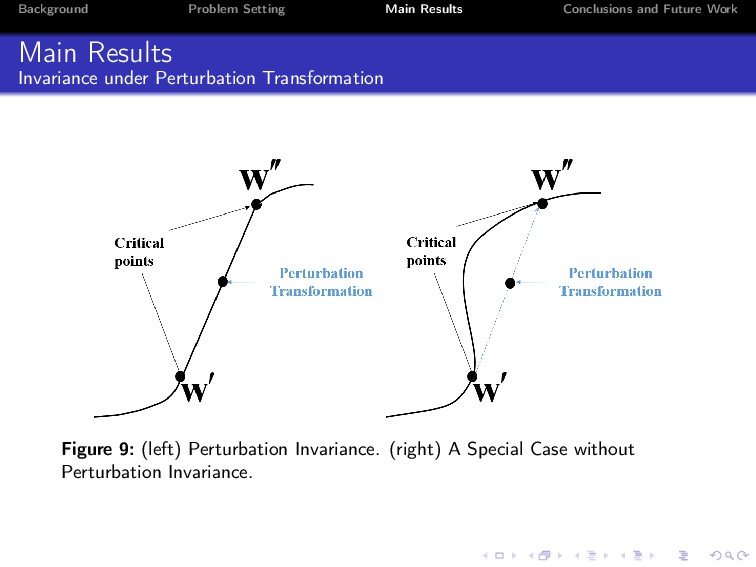
Deep learning has achieved unprecedented practical success in many applications. Despite its empirical success, however, the theoretical understanding of deep neural networks still remains a major open problem. In this paper, we explore properties of two-layered ReLU networks. For simplicity, we assume that the optimal model parameters (also called ground-truth parameters) are known. We then assume that a network receives Gaussian input and is trained by minimizing the expected squared loss between the prediction function of the network and a target function. To conduct the analysis, we propose a normal equation for critical points, and study the invariances under three kinds of transformations, namely, scale transformation, rotation transformation and perturbation transformation. We prove that these transformations can keep the loss of a critical point invariant, thus can incur at regions. Consequently, how to escape from at regions is vital in training neural networks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}