is MongoDB Let's get started MongoDB What's going wrong? Document structure Basic Operations CRUD Index Explain Hint Data Model: be quiet - the answer Sharding -scaling
the way data is queried. It consists in the way data is stored. NoSQL is all about data storage. “NoSQL” should be called “SQL with alternative storage models”
any single points of failure? • Do the writes scale as well? • How much administration will the system require? • If its open source, is there a healthy community? • How much time and effort would we have to expend to deploy and integrate it? • Does it use technology which we know we can work with?
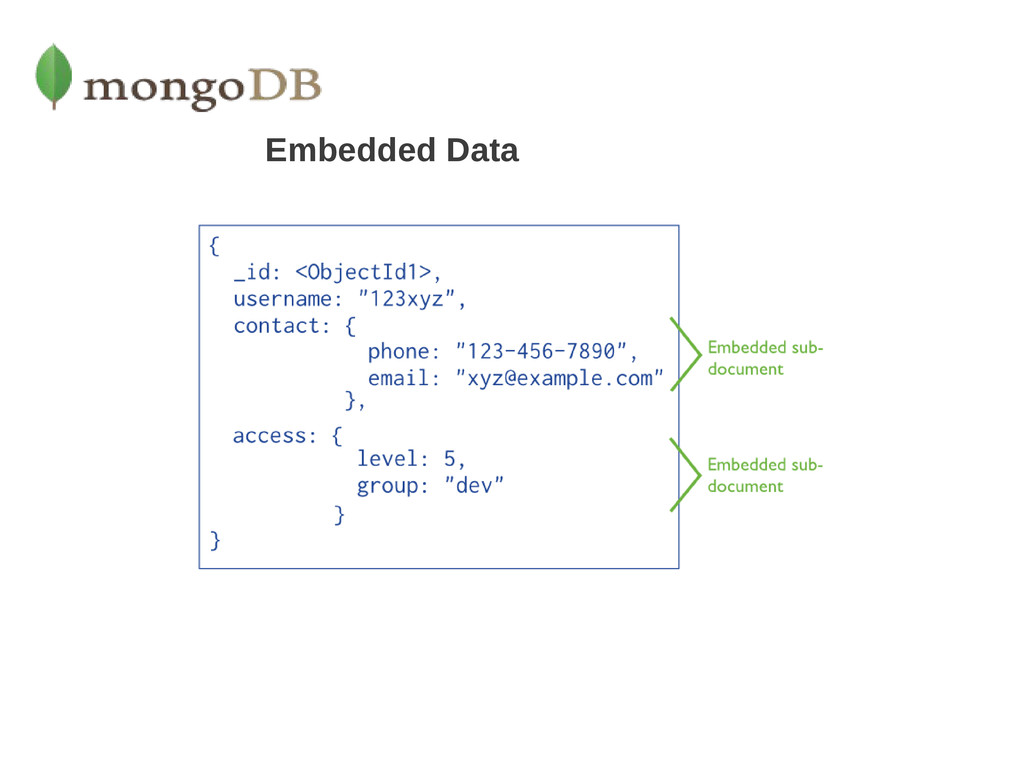
with a more flexible model: “document”. By allowing embedded documents and arrays, the document-oriented approach makes it possible to represent complex hierarchical relationships with a single record.
fields as needed becomes easier. This makes development faster as developers can quickly iterate. It is also easier to experiment. Developers can try a lot of models for the data and then choose the best one.
an incredible pace. As the amount of data that developers need to store grows, developers face a difficult decision: how should they scale their databases? Scaling a database comes down to the choice between: scaling up : getting a bigger machine. scaling out : partitioning data across more machines.
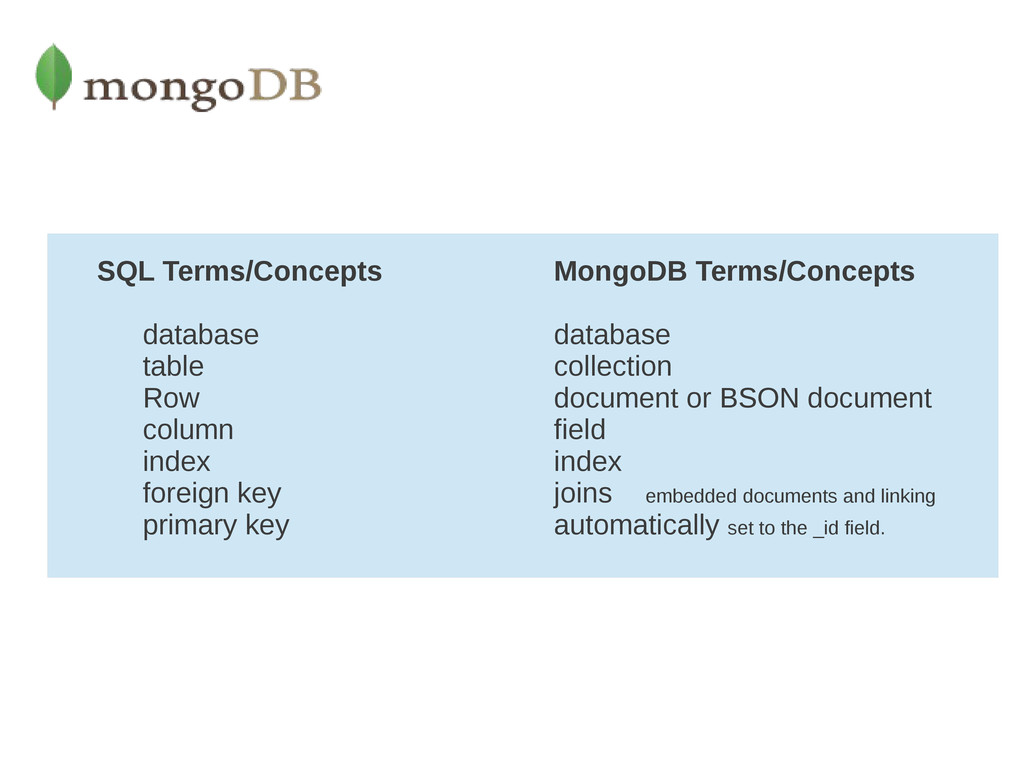
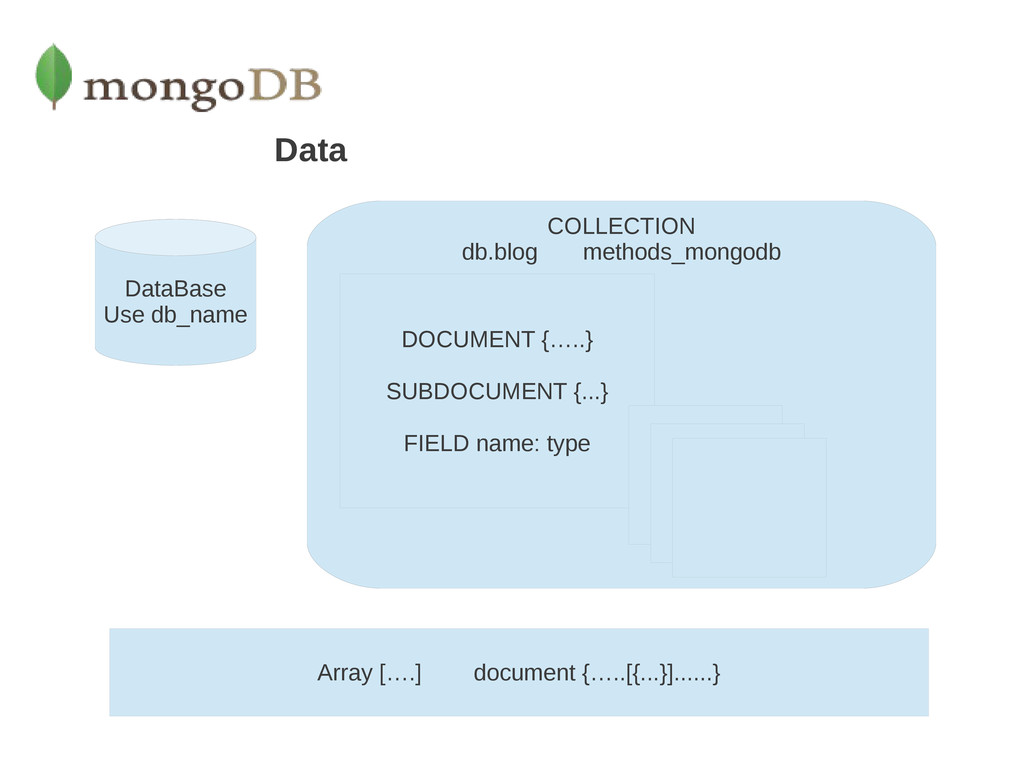
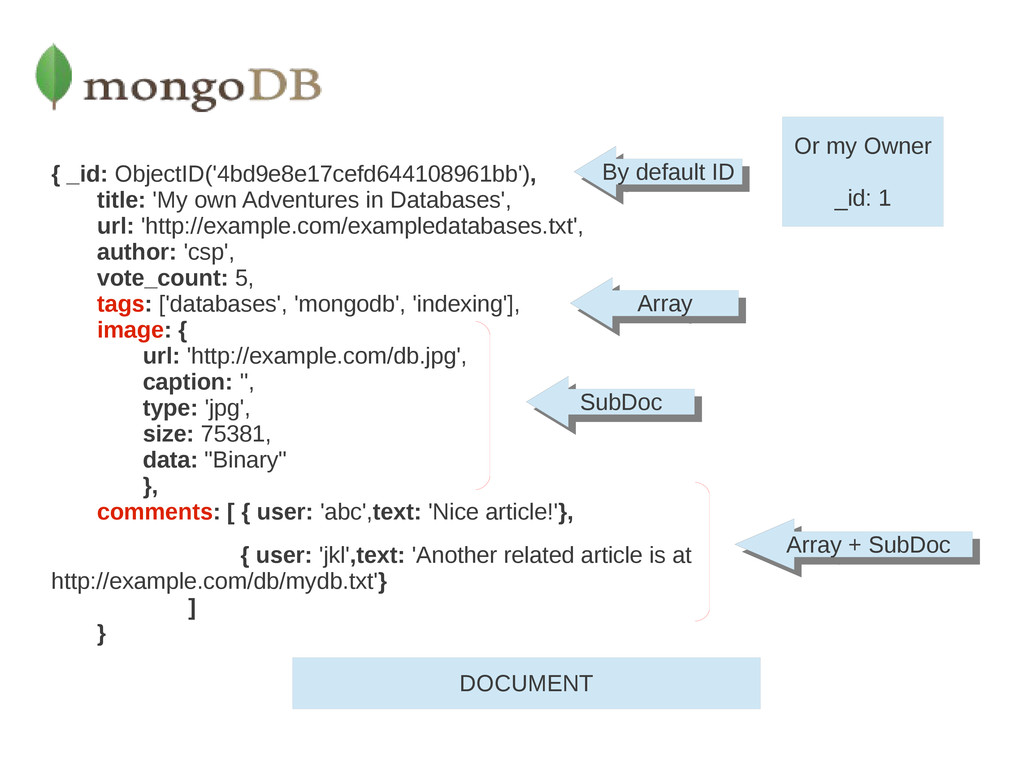
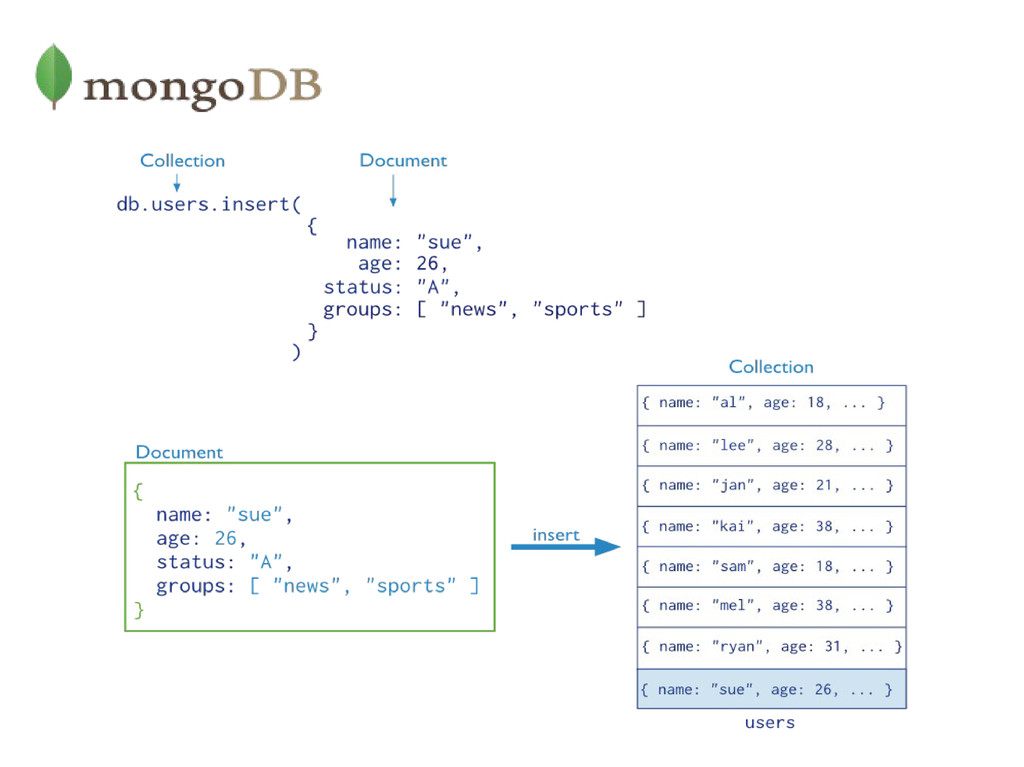
A document is the basic unit of data for MongoDB and is equivalent to a row in a Relational Database. • Collection can be thought of as a table with a dynamic schema. • A single instance of MongoDB can host multiple independent databases, each of which can have its own collections. • One document has a special key, "_id", that is unique within a collection. • Awesome JavaScript shell, which is useful for the administration and data manipulation.
set of keys with associated values. In JavaScript, for example, documents are represented as objects: {"name" : "Hello, MongoDB world!"} {"name" : "Hello, MongoDB world!", "foo" : 3} {"name" : "Hello, MongoDB world!", "foo" : 3, "fruit": ["pear","apple"]}
is allowed in a key, with a few notable exceptions: • Keys must not contain the character \0 (the null character). This character is used to signify the end of a key. • The . and $ characters have some special properties and should be used only in certain circumstances, but in general, they should be considered reserved.
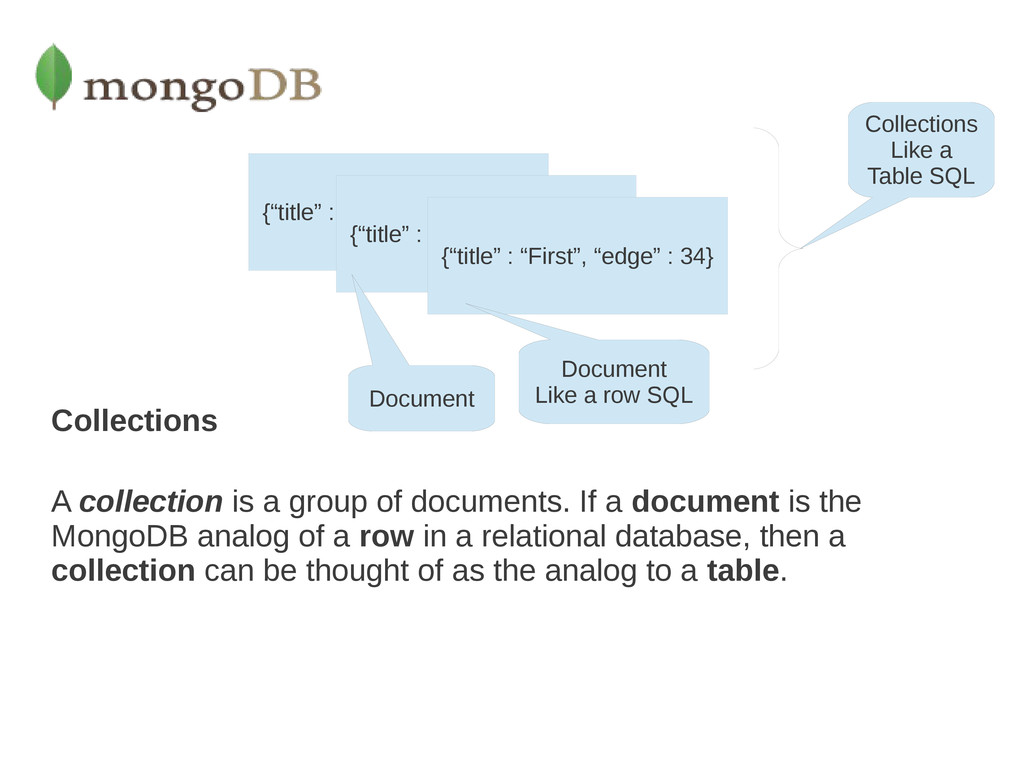
document is the MongoDB analog of a row in a relational database, then a collection can be thought of as the analog to a table. {“title” : “First”, “edge” : 34} {“title” : “First”, “edge” : 34} {“title” : “First”, “edge” : 34} Collections Like a Table SQL Document Like a row SQL Document
documents within a single collection can have any number of different “shapes.” For example, both of this documents could be stored in a single collection: {"greeting" : "Hello, mongoDB world!"} {"foo" : 23}
subcollections separated by the “.” character. For example, an a Blog application might have a collection named blog.posts and a separate collection named blog.authors.
a collection. > post = {"title" : "My first post in my blog", ... "content" : "Here's my blog post.", ... "date" : new Date()} > db.blog.insert(post) > db.blog.find() { "_id" : ObjectId("5037ee4a1084eb3ffeef7228"), "title" : "My first post in my blog", "content" : "Here's my blog post.", "date" : ISODate("2013-10-05T16:13:42.181Z") }
strict"; console.log("inserting blog entry" + title + body); // fix up the permalink to not include whitespace var permalink = title.replace( /\s/g, '_' ); permalink = permalink.replace( /\W/g, '' ); // Build a new post var post = {"title": title, "author": author, "body": body, "permalink":permalink, "tags": tags, "comments": [], "date": new Date()} // now insert the post posts.insert(post, function (err, post) { "use strict"; if (!err) { console.log("Inserted new post"); console.dir("Successfully inserted: " + JSON.stringify(post)); return callback(null, post); } return callback(err, null); }); }
query a collection. > db.blog.findOne() { "_id" : ObjectId("5037ee4a1084eb3ffeef7228"), "title" : "My first post in my blog", "content" : "Here's my blog post.", "date" : ISODate("2012-08-24T21:12:09.982Z") }
post, we can use update. update takes (at least) two parameters: the first is the criteria to find which document to update, and the second is the new document. > post.comments = [] > db.blog.update({title : "My first post in my blog"}, post) > db.blog.find() { "_id" : ObjectId("5037ee4a1084eb3ffeef7228"), "title" : "My first post in my blog", "content" : "Here's my blog post.", "date" : ISODate("2013-10-05T16:13:42.181Z"), "comments" : [ ] }
Called with no parameters, it removes all documents from a collection. It can also take a document specifying criteria for removal. > db.blog.remove({title : "My first post in my blog"}) > db.blog.find() { "_id" : ObjectId("5037ee4a1084eb3ffeef7228"), "title" : "My second post in my blog", "content" : "Here's my second blog post.", "date" : ISODate("2013-10-05T16:13:42.181Z"), "comments" : [ ] }
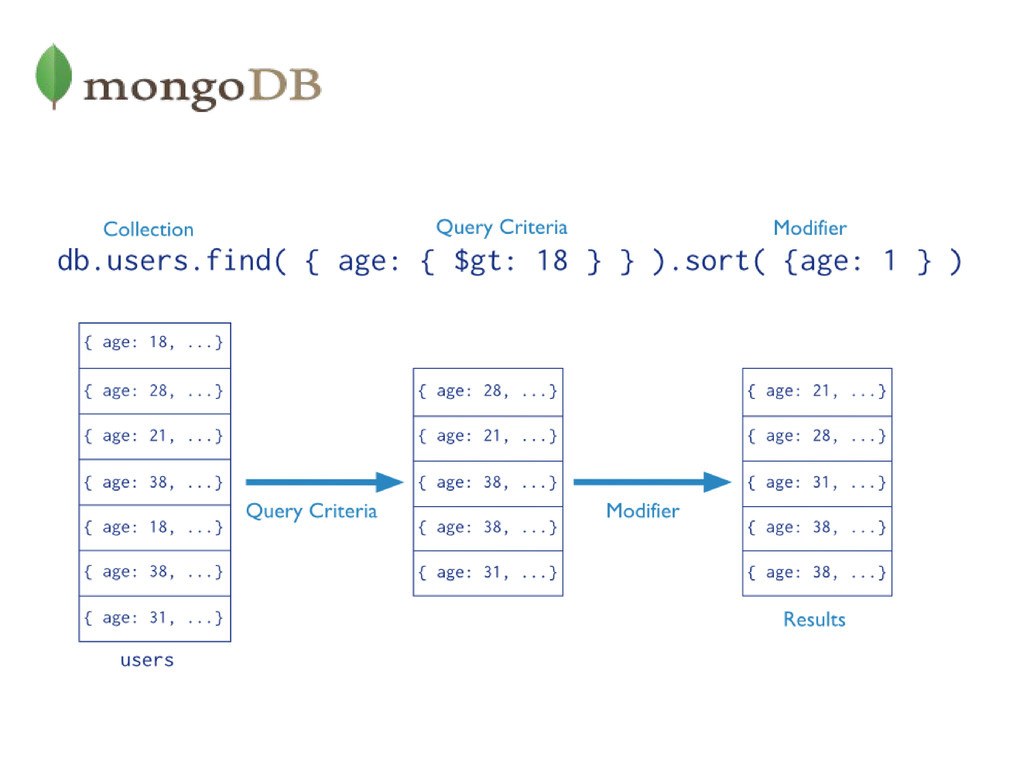
value specified in the query. $gteMatches values that are equal to or greater than the value specified in the query. $in Matches any of the values that exist in an array specified in the query. $lt Matches values that are less than the value specified in the query. $lte Matches values that are less than or equal to the value specified in the query. $ne Matches all values that are not equal to the value specified in the query. $ninMatches values that do not exist in an array specified to the query. Comparison Name Description $or Joins query clauses with a logical OR returns all documents that match the conditions of either clause. $and Joins query clauses with a logical AND returns all documents that match the conditions of both clauses. $not Inverts the effect of a query expression and returns documents that do not match the query expression. $nor Joins query clauses with a logical NOR returns all documents that fail to match both clauses. Logical
"n" : 1, "nscannedObjects" : 1000000, "nscanned" : 1000000, "nscannedObjectsAllPlans" : 1000000, "nscannedAllPlans" : 1000000, "scanAndOrder" : false, "indexOnly" : false, "nYields" : 1, "nChunkSkips" : 0, "millis" : 392, "indexBounds" : { }, "server" : "desarrollo:27017" } Others means: The query could be returned 5 documents - n scanned 9 documents from the index - nscanned and then read 5 full documents from the collection - nscannedObjects Others means: The query could be returned 5 documents - n scanned 9 documents from the index - nscanned and then read 5 full documents from the collection - nscannedObjects
executes the query. Some of relevant fields are: cursor: A result of BasicCursor indicates a non-indexed query. If we had used an indexed query, the cursor would have a type of BtreeCursor. nscanned and nscannedObjects: The difference between these two similar fields is distinct but important. The total number of documents scanned by the query is represented by nscannedObjects. The number of documents and indexes is represented by nscanned. Depending on the query, it's possible for nscanned to be greater than nscannedObjects. n: The number of matching objects. millis: Query execution duration.
i wonder: “Why do we need separate collections at all?” with no need for separate schemas for different kinds of documents, why should we use more than one collection?
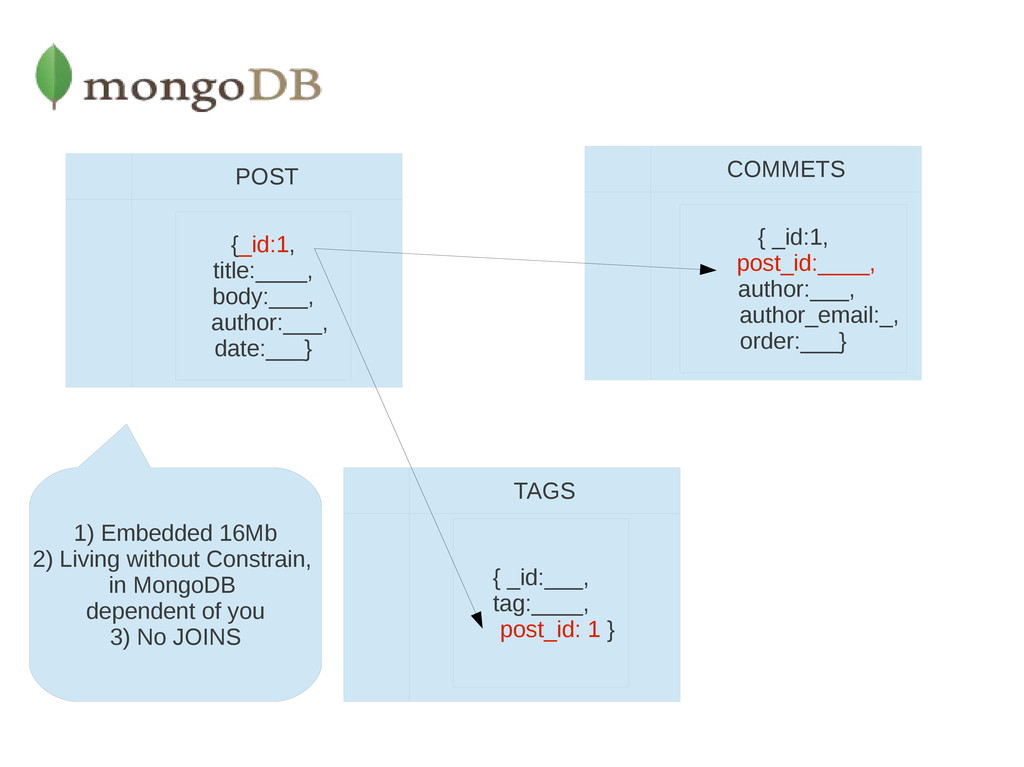
post_id:____, author:___, author_email:_, order:___} { _id:___, tag:____, post_id: 1 } 1) Embedded 16Mb 2) Living without Constrain, in MongoDB dependent of you 3) No JOINS
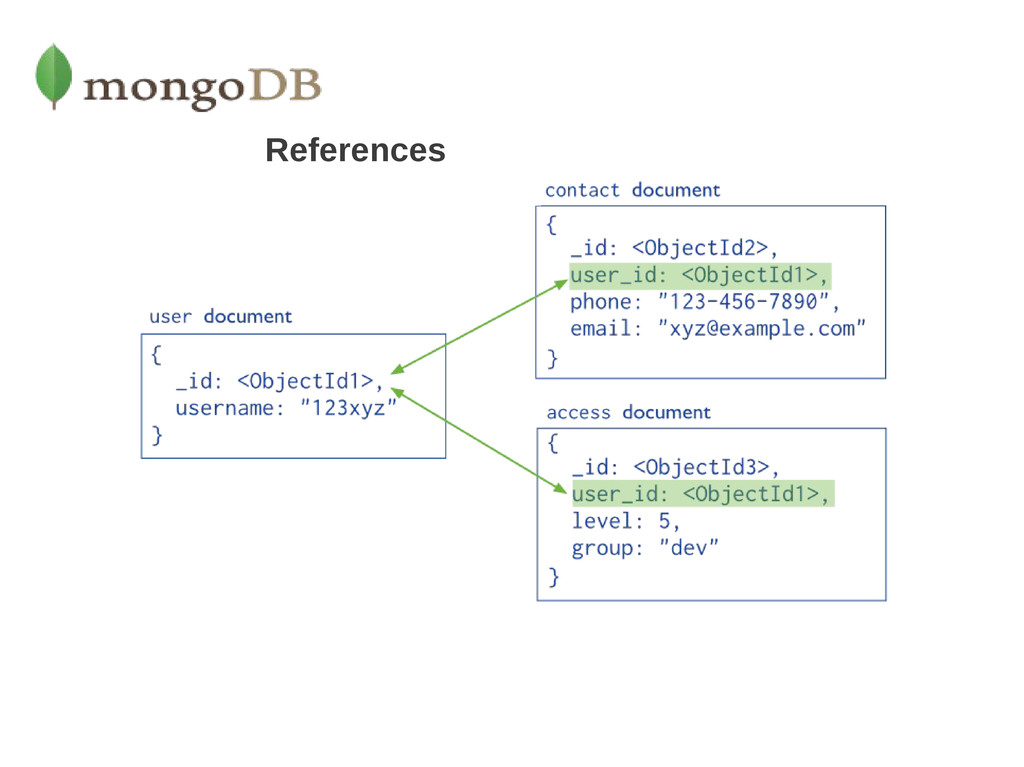
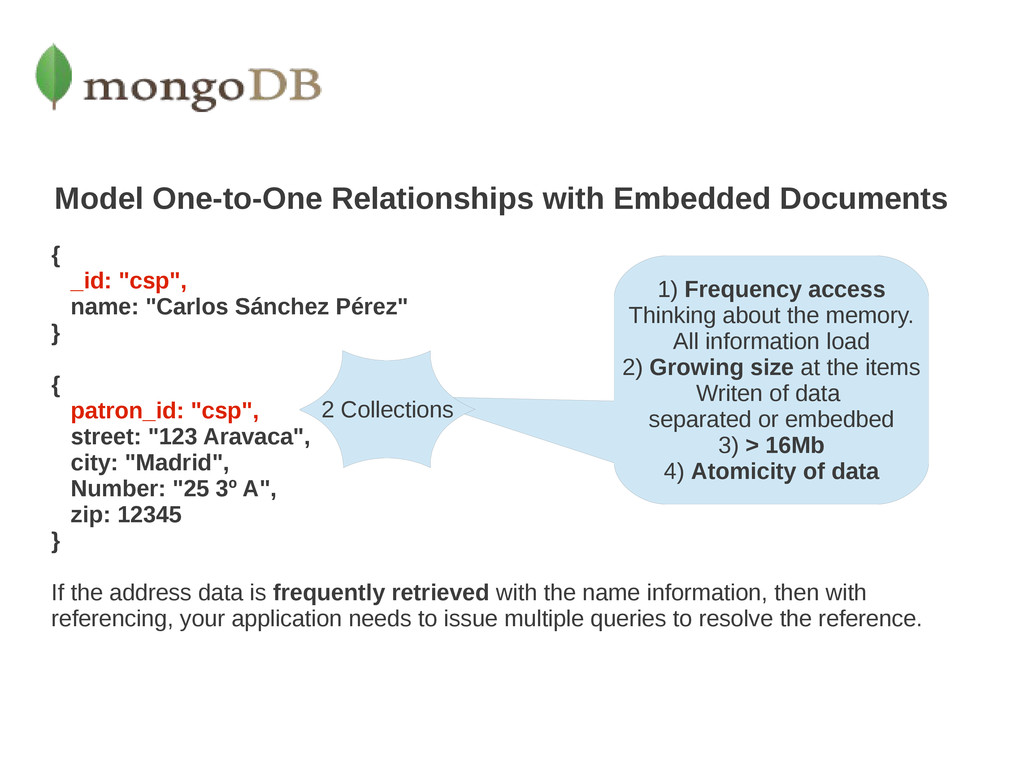
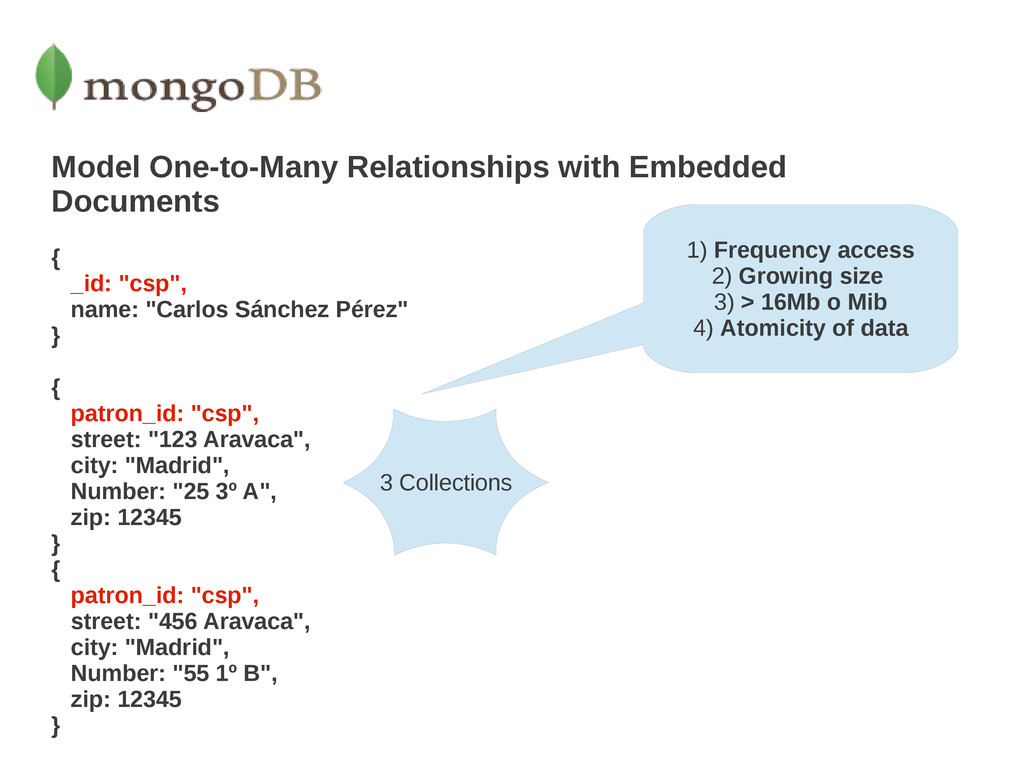
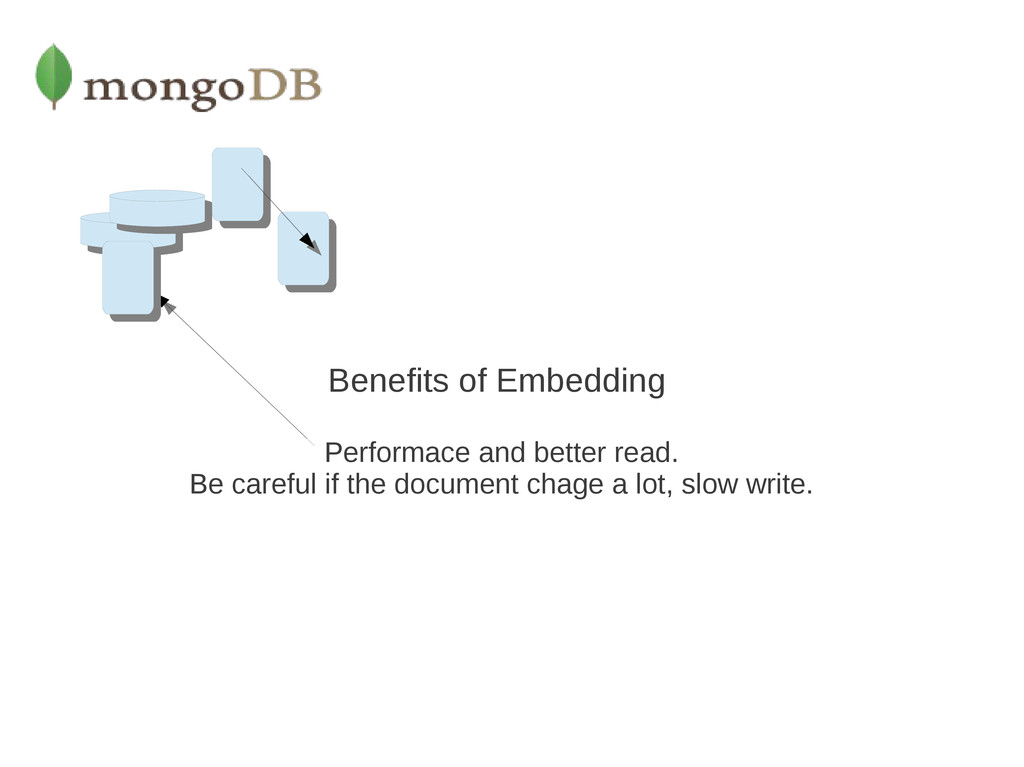
"Carlos Sánchez Pérez" } { patron_id: "csp", street: "123 Aravaca", city: "Madrid", Number: "25 3º A", zip: 12345 } If the address data is frequently retrieved with the name information, then with referencing, your application needs to issue multiple queries to resolve the reference. 1) Frequency access Thinking about the memory. All information load 2) Growing size at the items Writen of data separated or embedbed 3) > 16Mb 4) Atomicity of data 2 Collections
name: "Carlos Sánchez Pérez" City: “MD”, …................. } City { _id: "MD", Name: ….. …................. } If you are thinking in Embedded: it not a good solution in this case Why? Redundance information If you are thinking in Embedded: it not a good solution in this case Why? Redundance information
first tirle”, author : “Carlos Sánchez Pérez” , date : “19/08/2013″, comments : [ {name: "Antonio López", comment : "my comment" }, { .... } ], tags : ["tag1","tag2","tag3"] } autor { _id : “Carlos Sánchez Pérez “, password; “”,…….. } Embedded it a good solution in this case One-to-few Embedded it a good solution in this case One-to-few BLOG BLOG
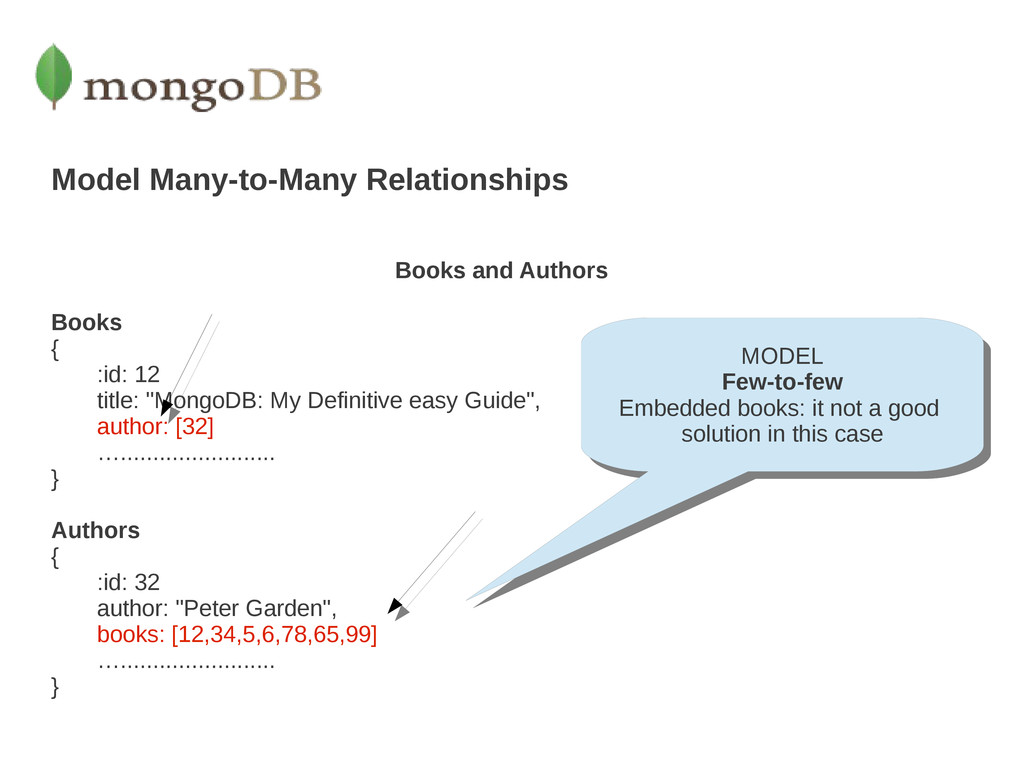
title: "MongoDB: My Definitive easy Guide", author: [32] …........................ } Authors { :id: 32 author: "Peter Garden", books: [12,34,5,6,78,65,99] …........................ } MODEL Few-to-few Embedded books: it not a good solution in this case MODEL Few-to-few Embedded books: it not a good solution in this case
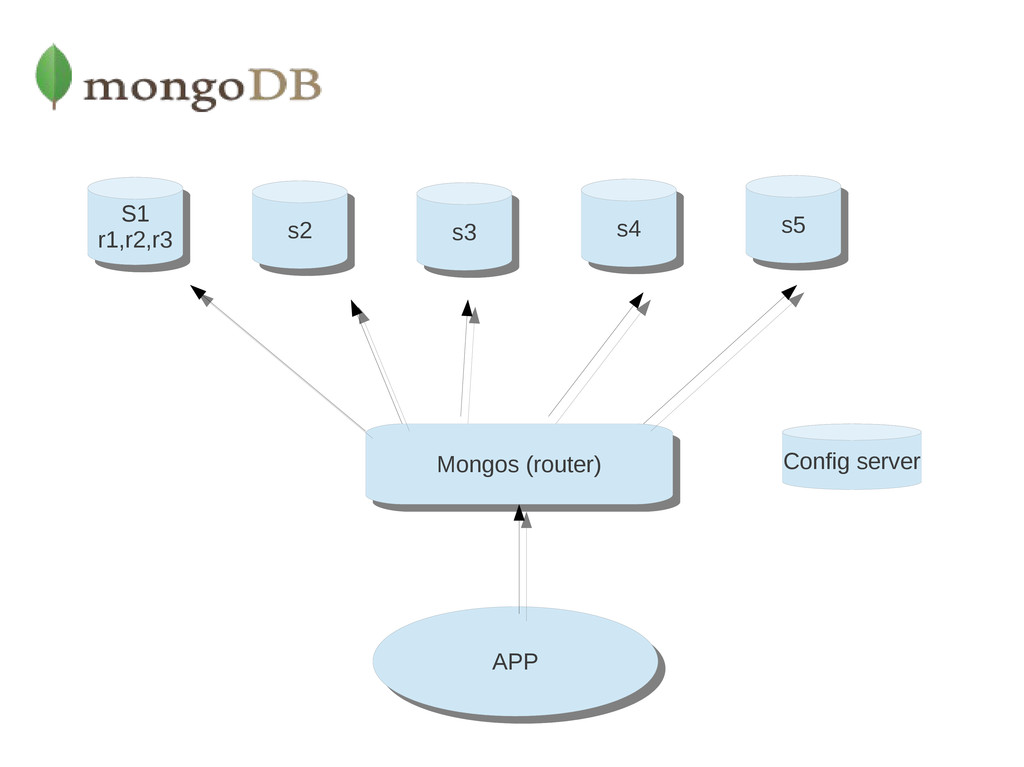
increase capacity. Scaling by adding capacity has limitations: high performance systems with large numbers of CPUs and large amount of RAM are disproportionately more expensive than smaller systems. Additionally, cloud-based providers may only allow users to provision smaller instances. As a result there is a practical maximum capability for vertical scaling. Sharding, or horizontal scaling, by contrast, divides the data set and distributes the data over multiple servers, or shards. Each shard is an independent database, and collectively, the shards make up a single logical database.
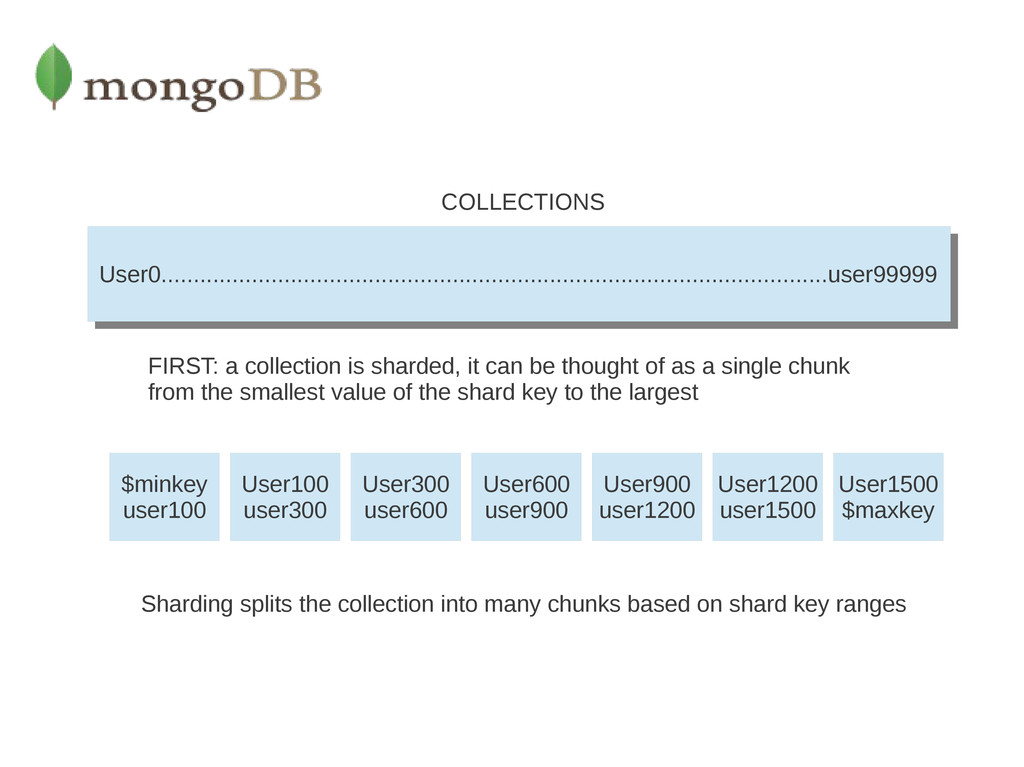
be thought of as a single chunk from the smallest value of the shard key to the largest Sharding splits the collection into many chunks based on shard key ranges $minkey user100 User100 user300 User300 user600 User600 user900 User900 user1200 User1200 user1500 User1500 $maxkey
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}