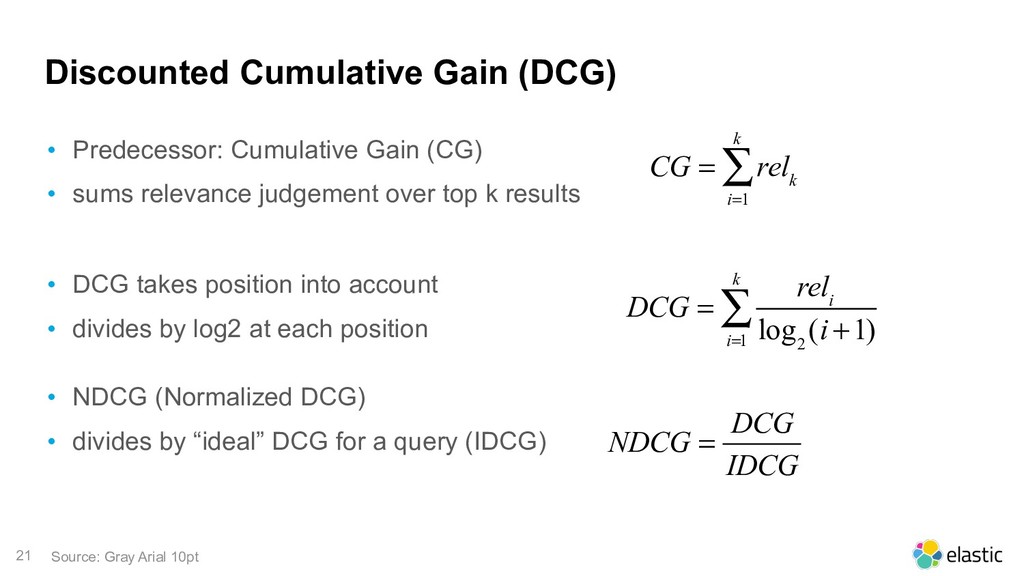
The evaluation of search ranking results is an important task for every search engineer. The new Elasticsearch Ranking Evaluation API makes it easier to measure well-known information retrieval metrics like Precision@K or NDCG. This helps to make better relevance tuning decisions and allows to evaluate and optimize query templates over a wider range of user needs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
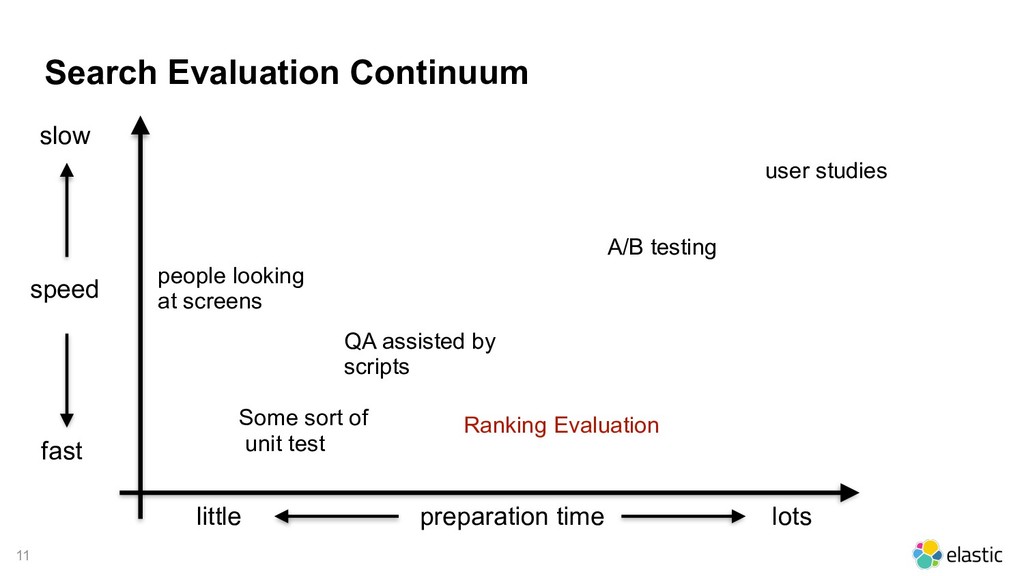{kind=link}
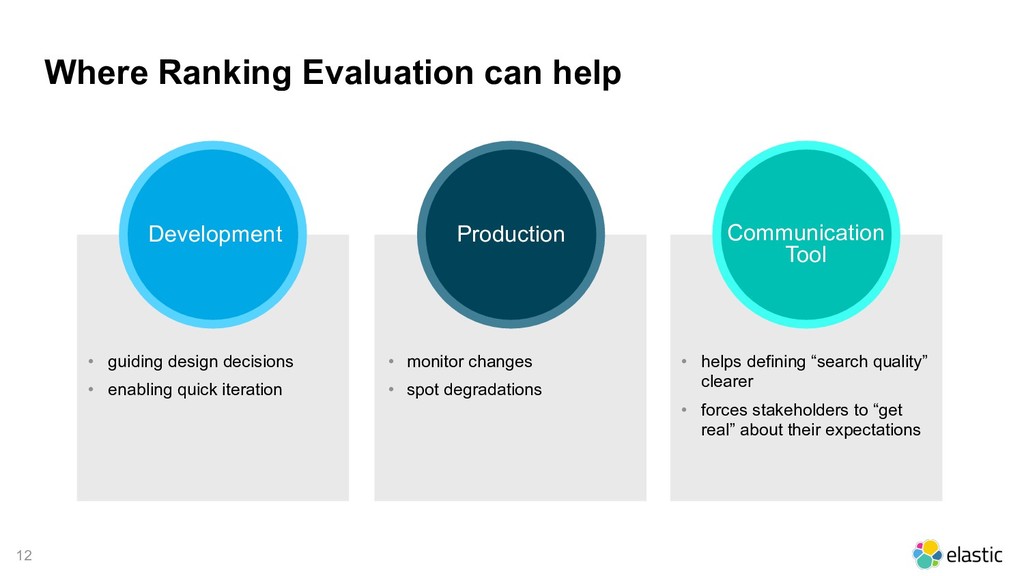{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
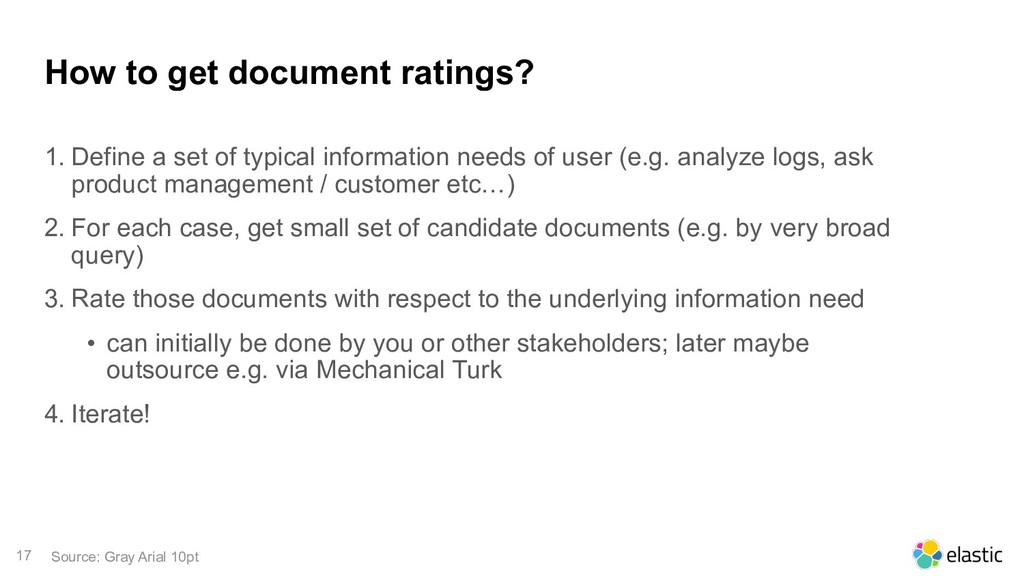{kind=link}
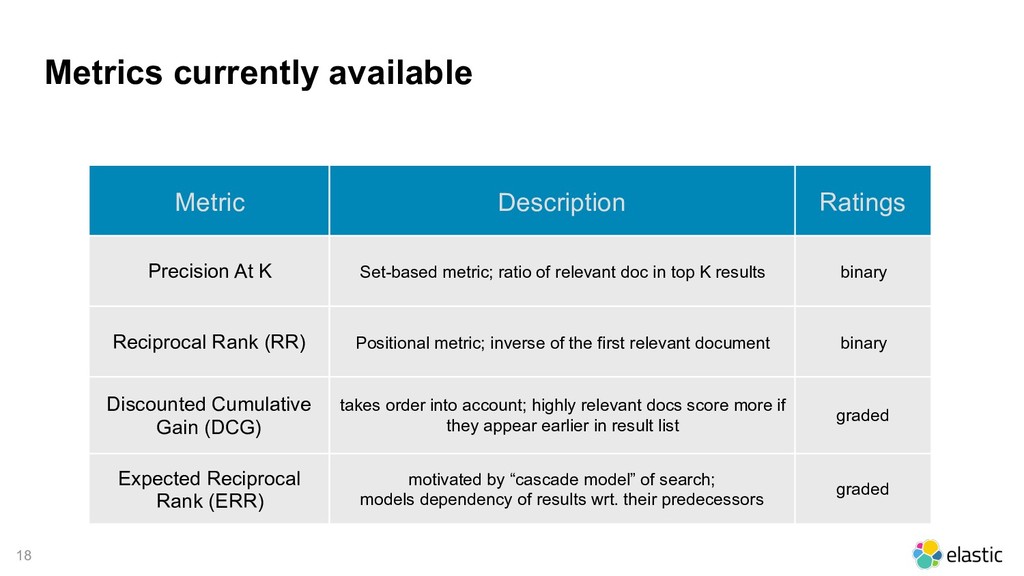{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}