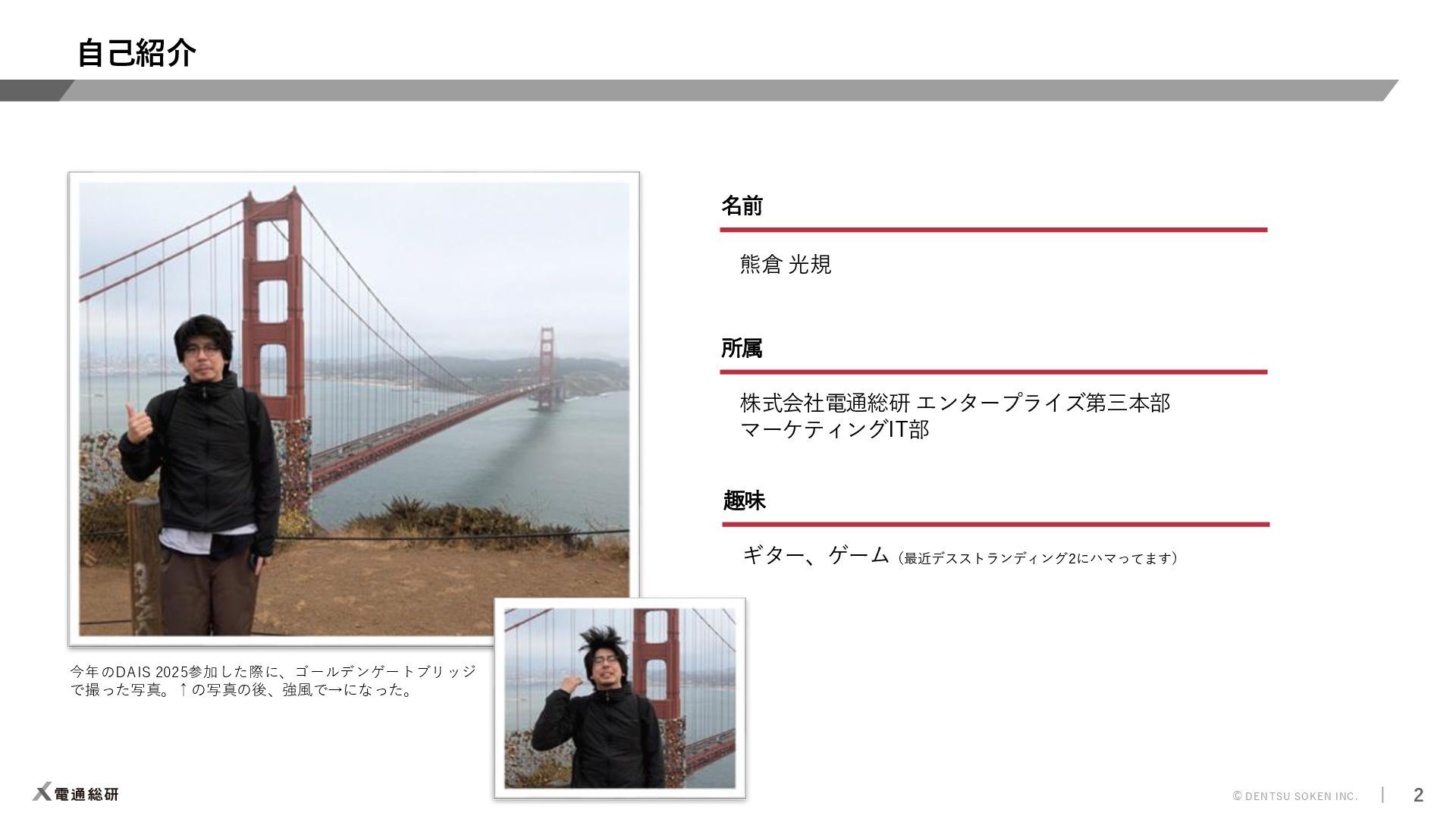
https://youtu.be/0pys27kA67U?si=bn_f8Zs3L9B5-upD&t=5483 (1:31:23ごろ) Day2 Main Keynote https://youtu.be/ul8cRLIP_Vk?si=M8lhhB9OkBNqz_IS&t=7296 (2:01:36ごろ) Day1 Main Keynote
https://youtu.be/0pys27kA67U?si=bn_f8Zs3L9B5-upD&t=5483 (1:31:23ごろ) Day2 Main Keynote https://youtu.be/ul8cRLIP_Vk?si=M8lhhB9OkBNqz_IS&t=7296 (2:01:36ごろ) Day1 Main Keynote
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
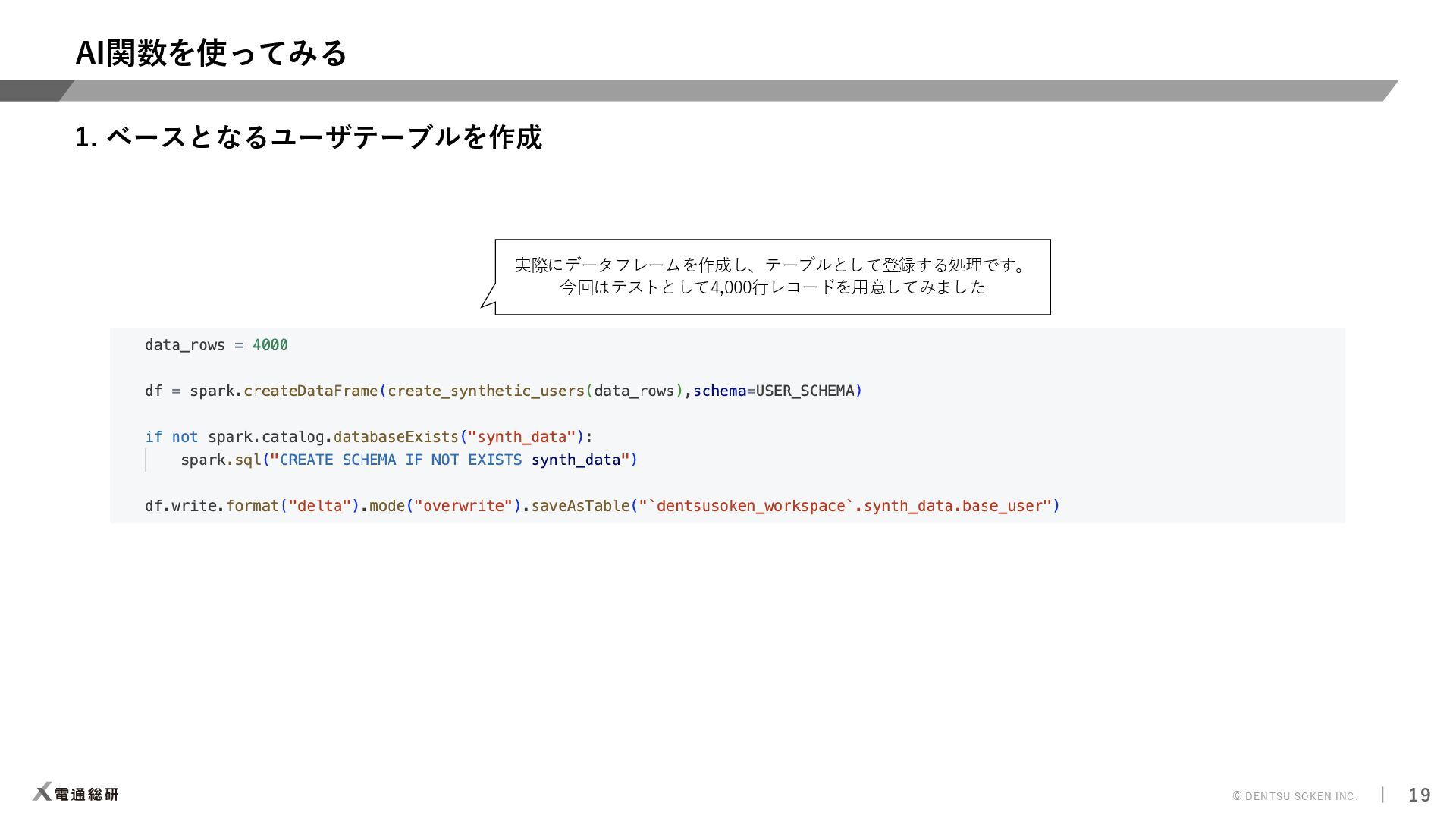{kind=link}
{kind=link}
{kind=link}
{kind=link}
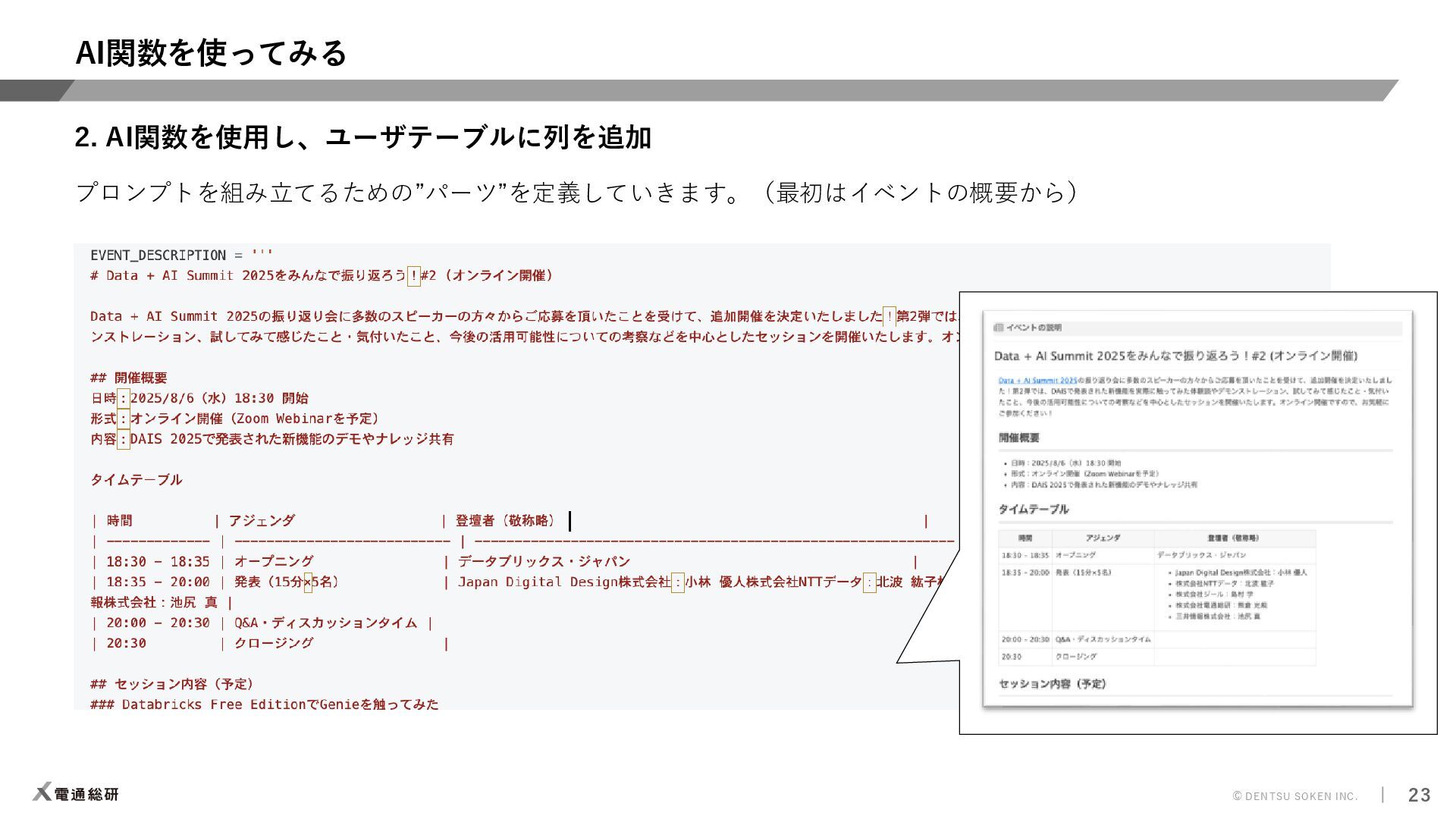{kind=link}
{kind=link}
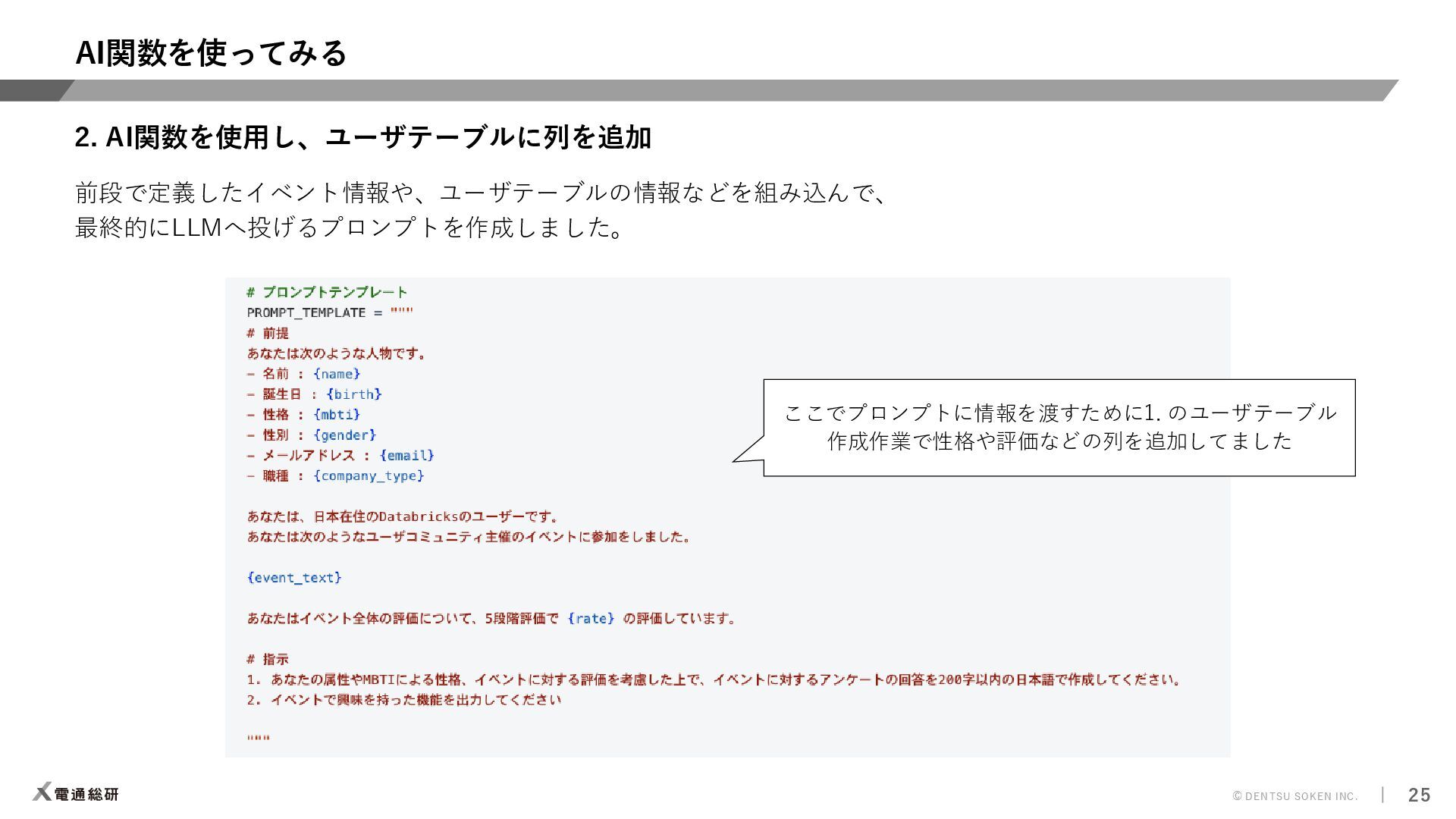{kind=link}
{kind=link}
{kind=link}
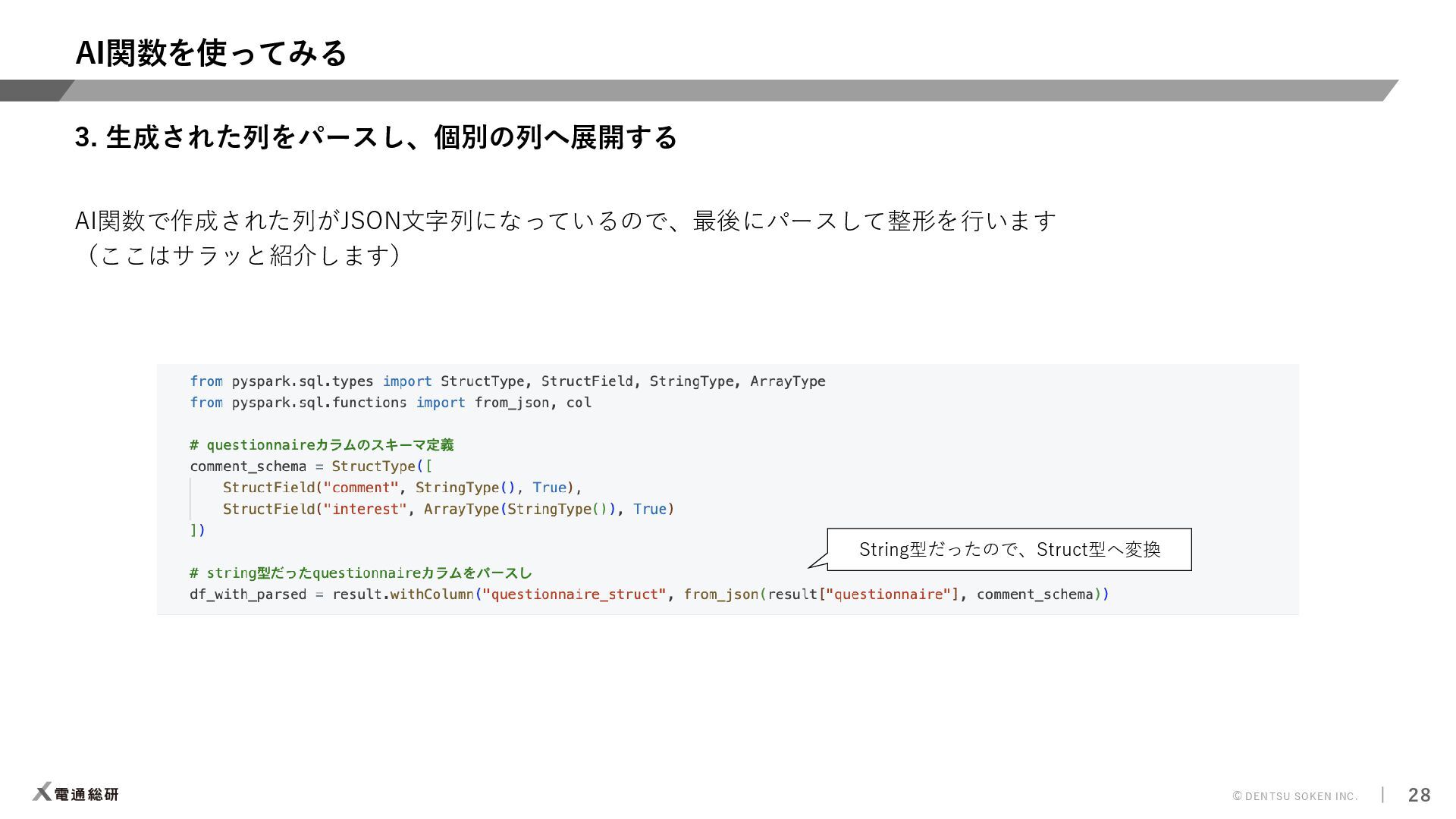{kind=link}
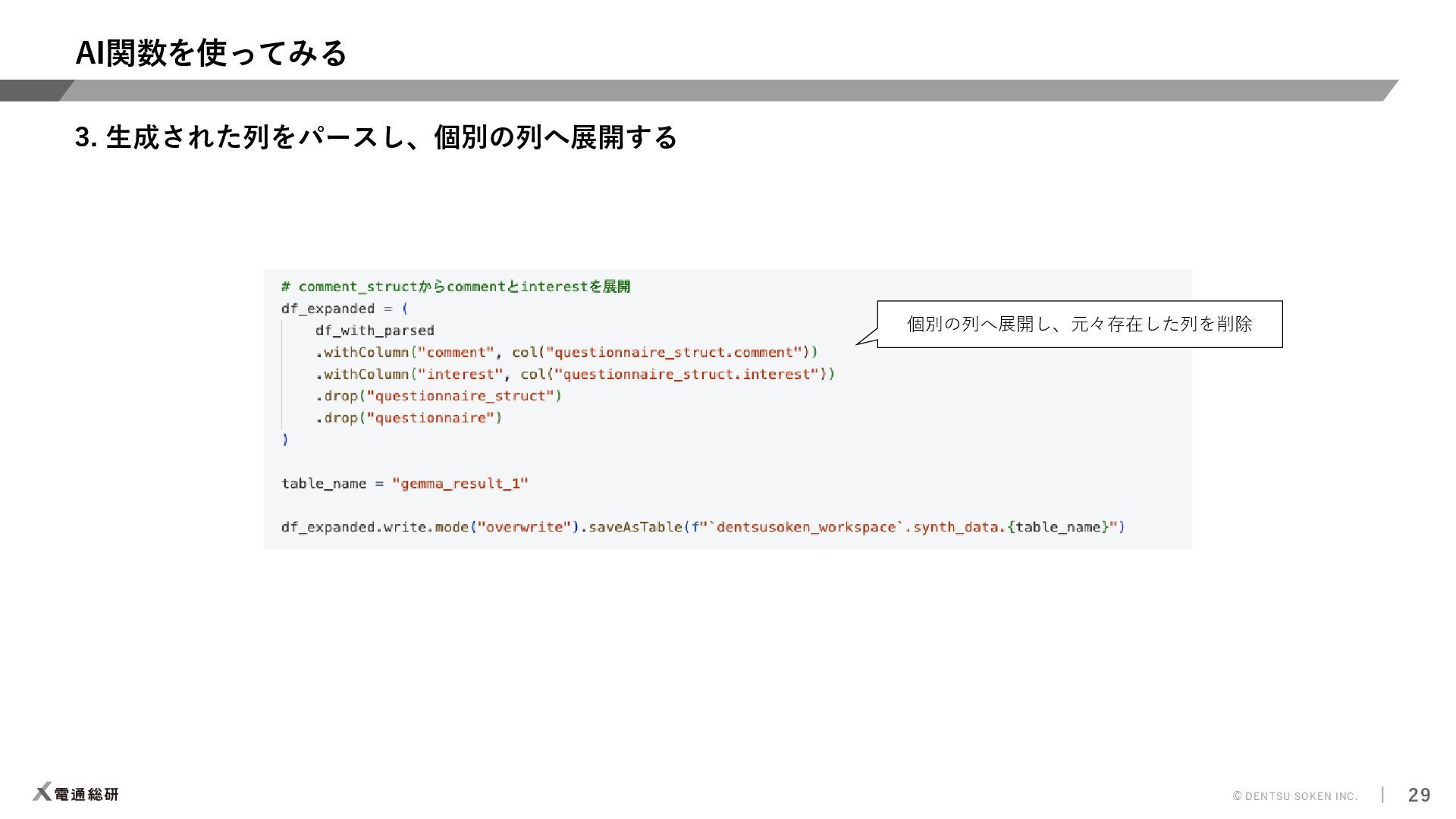{kind=link}
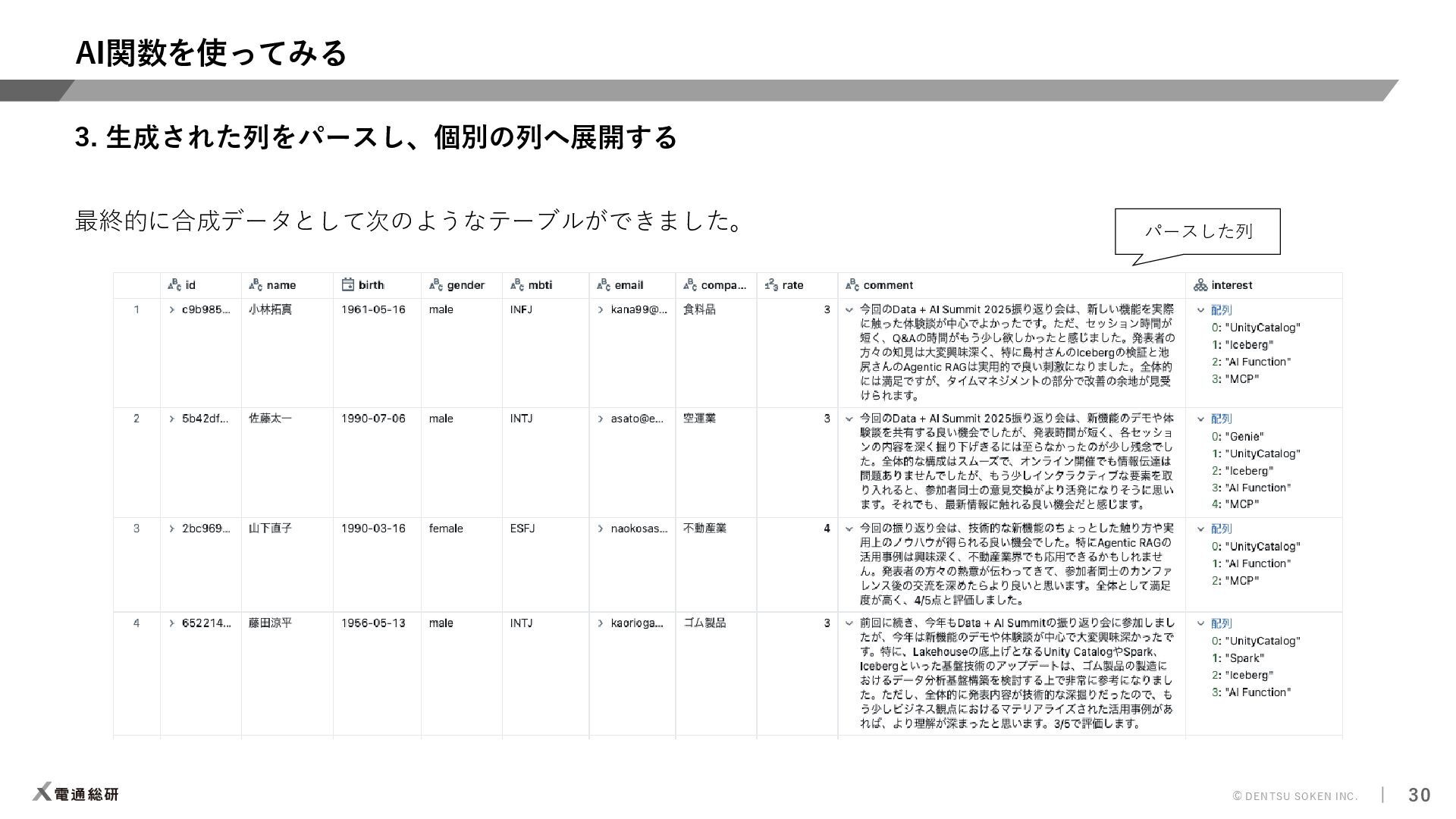{kind=link}
{kind=link}
{kind=link}
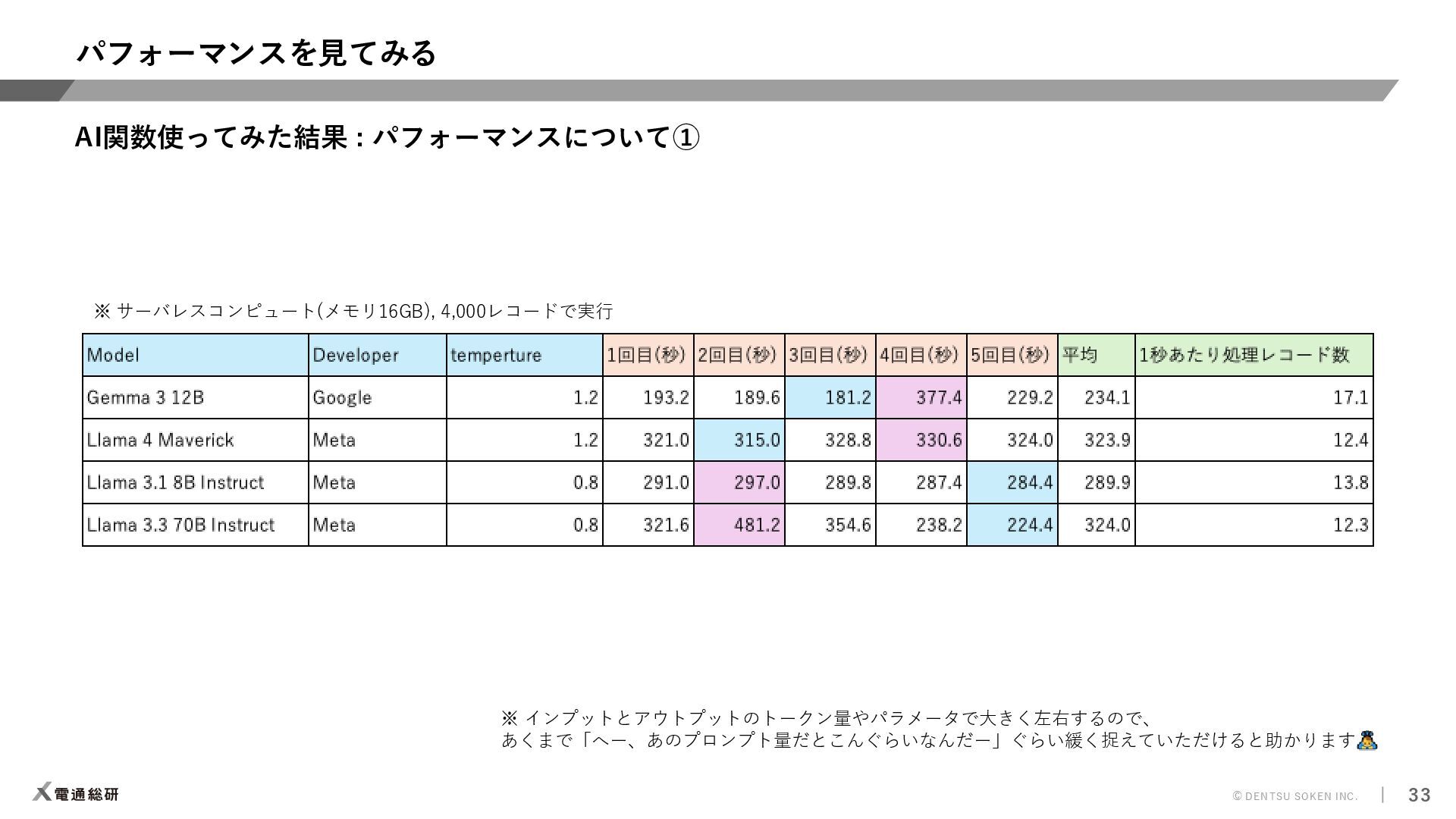{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![39 © DENTSU SOKEN INC. Appendix GPT OSS 20B[new!]で作成したテーブル(パラメータデフォルト) まだ、レスポンスの型指定に対応していないみたいで](https://files.speakerdeck.com/presentations/df074f5da71f471abea4fcbc149c8a74/slide_38.jpg){kind=link}
![40 © DENTSU SOKEN INC. Appendix GPT OSS 120B[new!]で作成したテーブル(パラメータデフォルト) まだ、レスポンスの型指定に対応していないみたいで](https://files.speakerdeck.com/presentations/df074f5da71f471abea4fcbc149c8a74/slide_39.jpg){kind=link}
{kind=link}