り、運⽤でカバーいただくしかないというのが現 状であり、業務の完全⾃動運転に向けた壁となっ ている 従来のSaaSの限界 業務の完全⾃動運転の実現にむけて SaaS Use Case Use Case Use Case SaaS Use Case Use Case SaaS Use Case Use Case Use Case Use Case Use Case
SaaSの限界を超えていく 業務の完全⾃動運転の実現にむけて SaaS Use Case Use Case Use Case SaaS Use Case SaaS Use Case Use Case Agent Platform Use Case Use Case Use Case Use Case Use Case
Agentic Workflowでタスクを分解して いくと多くの場合構造化データ抽出に 落ち着く • 10B以下のサイズのSLMで10k~100kの データサイズで⼀般的な構造化データ 抽出なら事後学習データとしては⼗分 な精度が出ることが多い • 定期的な学習により、新しいフォー マット‧要件にも適応可能 • テキストとしてではなくパラメータと してメモリを保持するため、複雑なプ ロンプトエンジニアリングやコンテキ ストエンジニアリングの運⽤から解放 される 識別モデルと⽣成モデルの違い [1] Small Language Models are the Future of Agentic AI [2] AI-native Memory: A Pathway from LLMs Towards AGI 1 2 1 2
{kind=link}
{kind=link}
{kind=link}
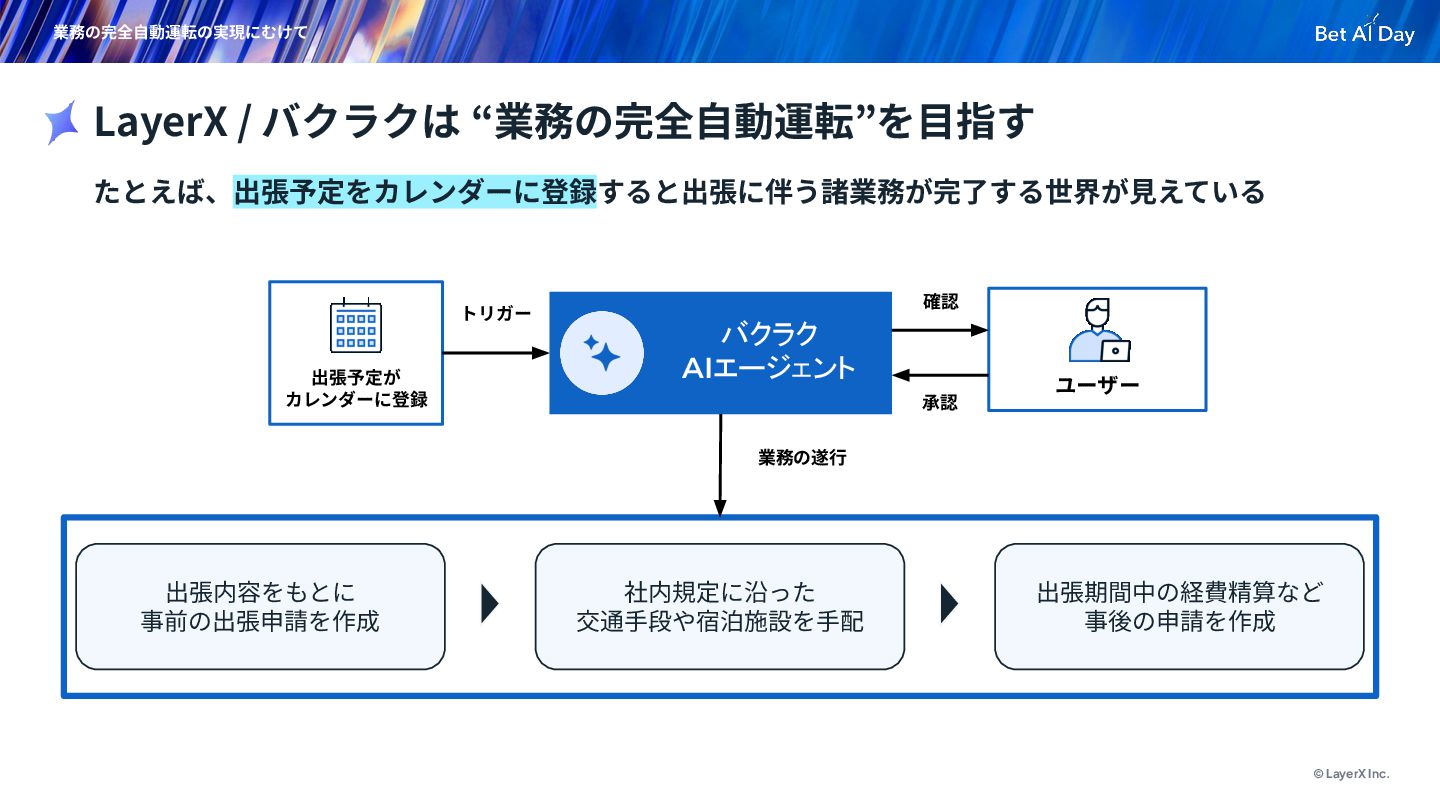{kind=link}
{kind=link}
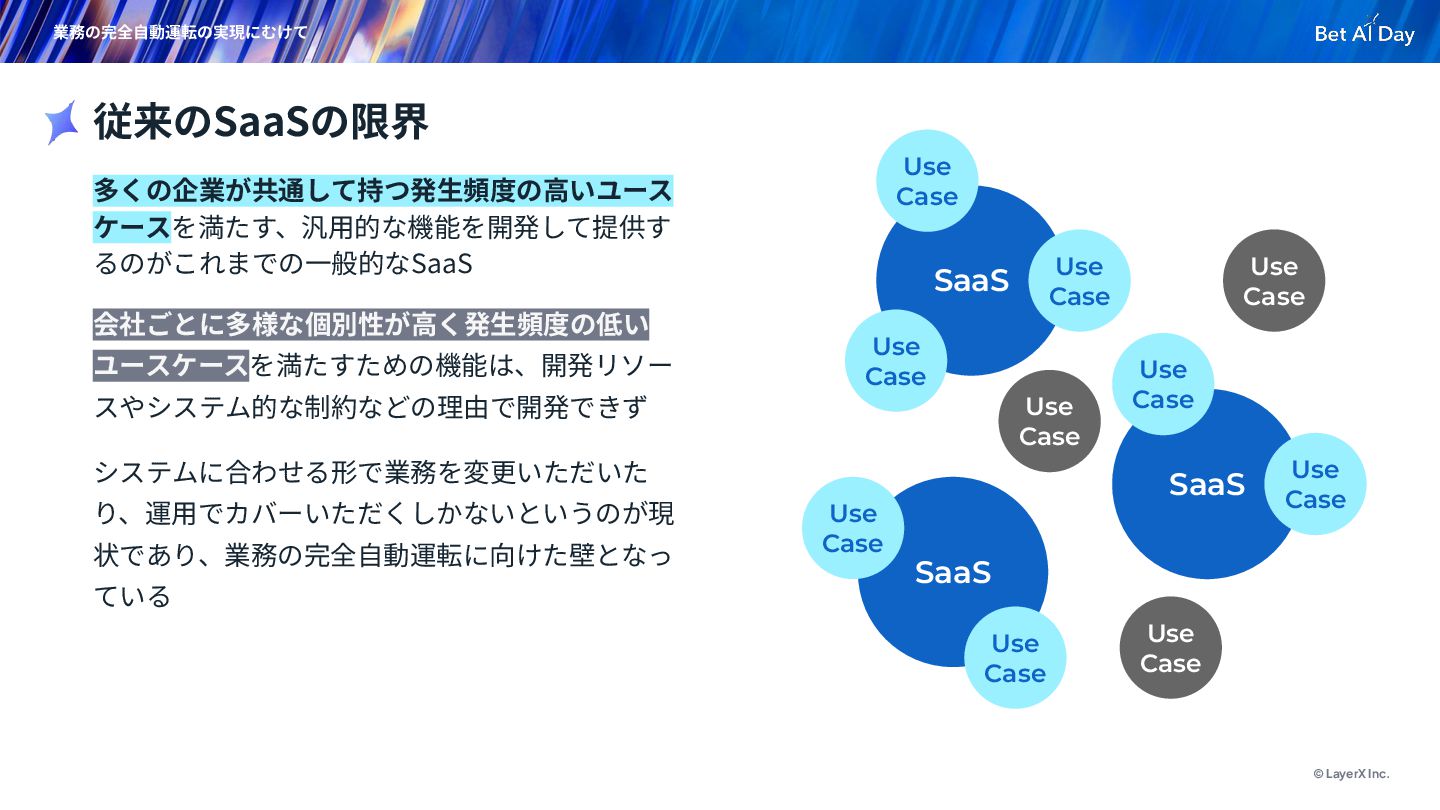{kind=link}
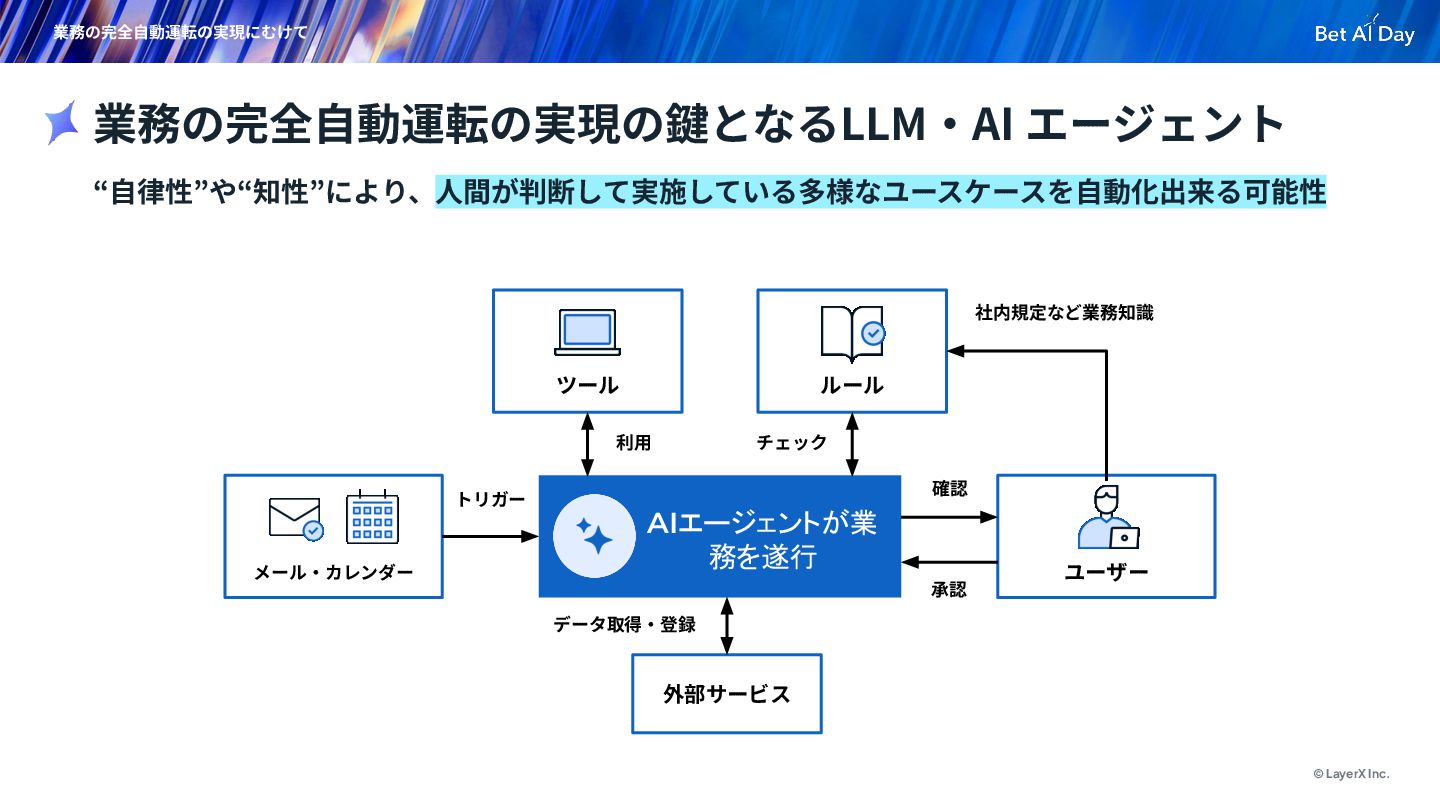{kind=link}
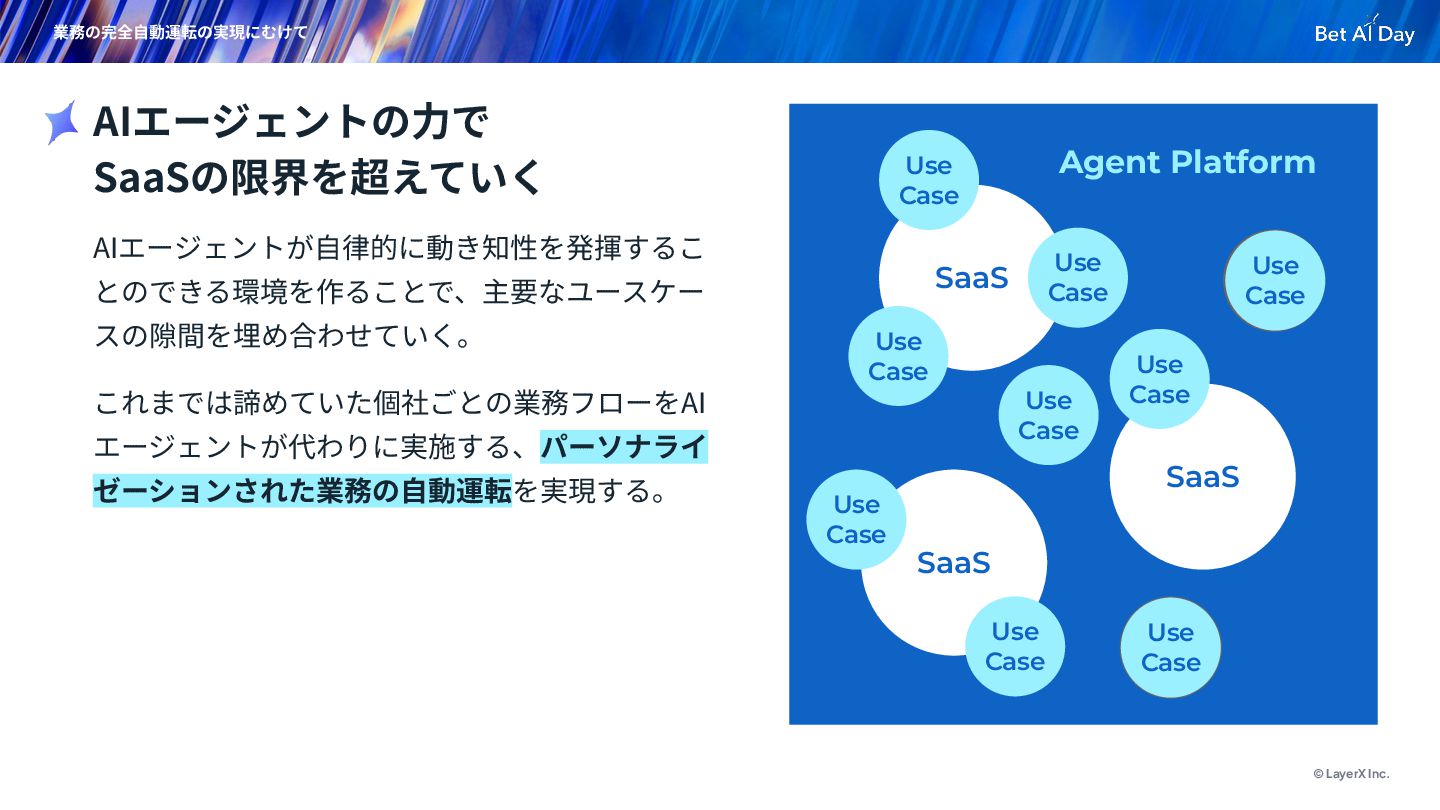{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
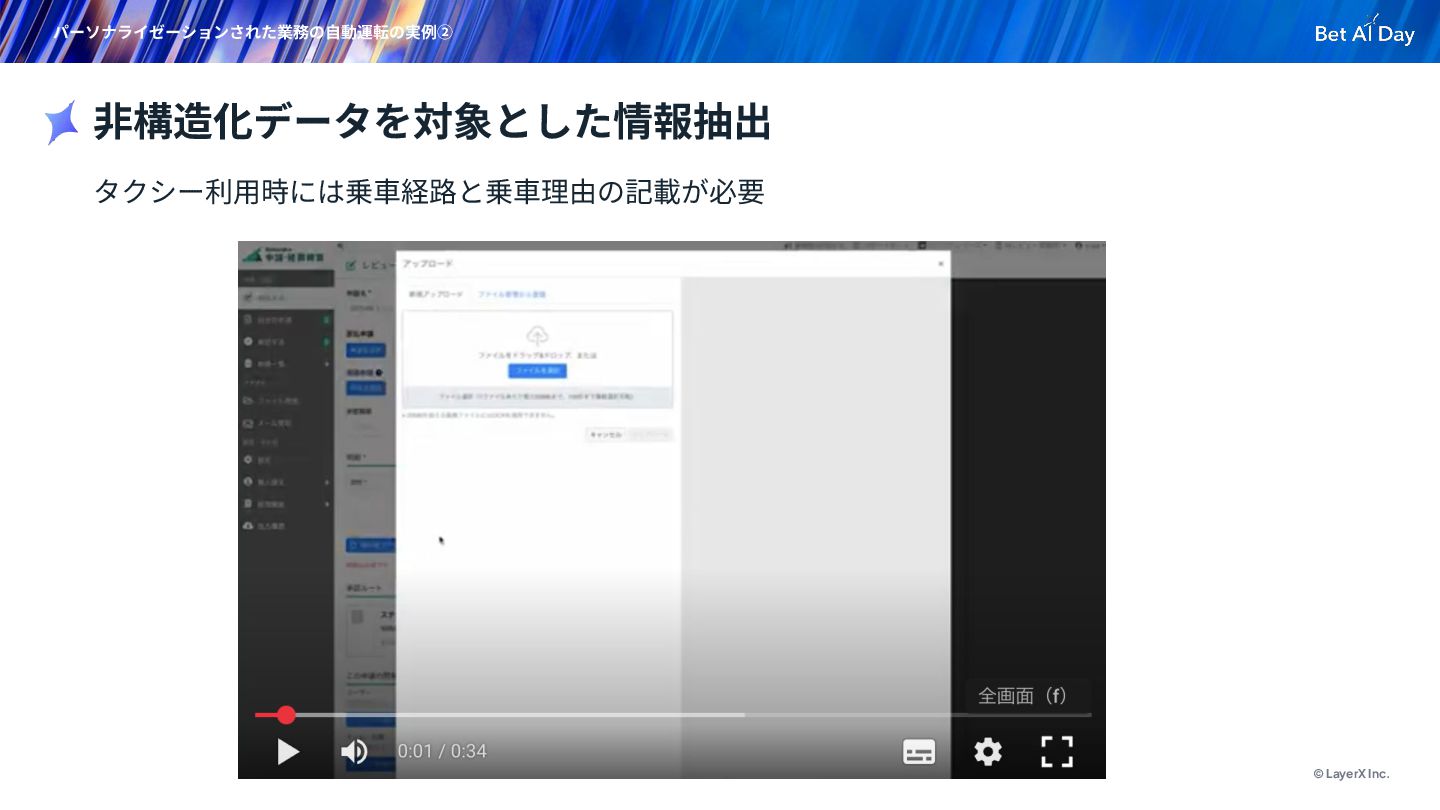{kind=link}
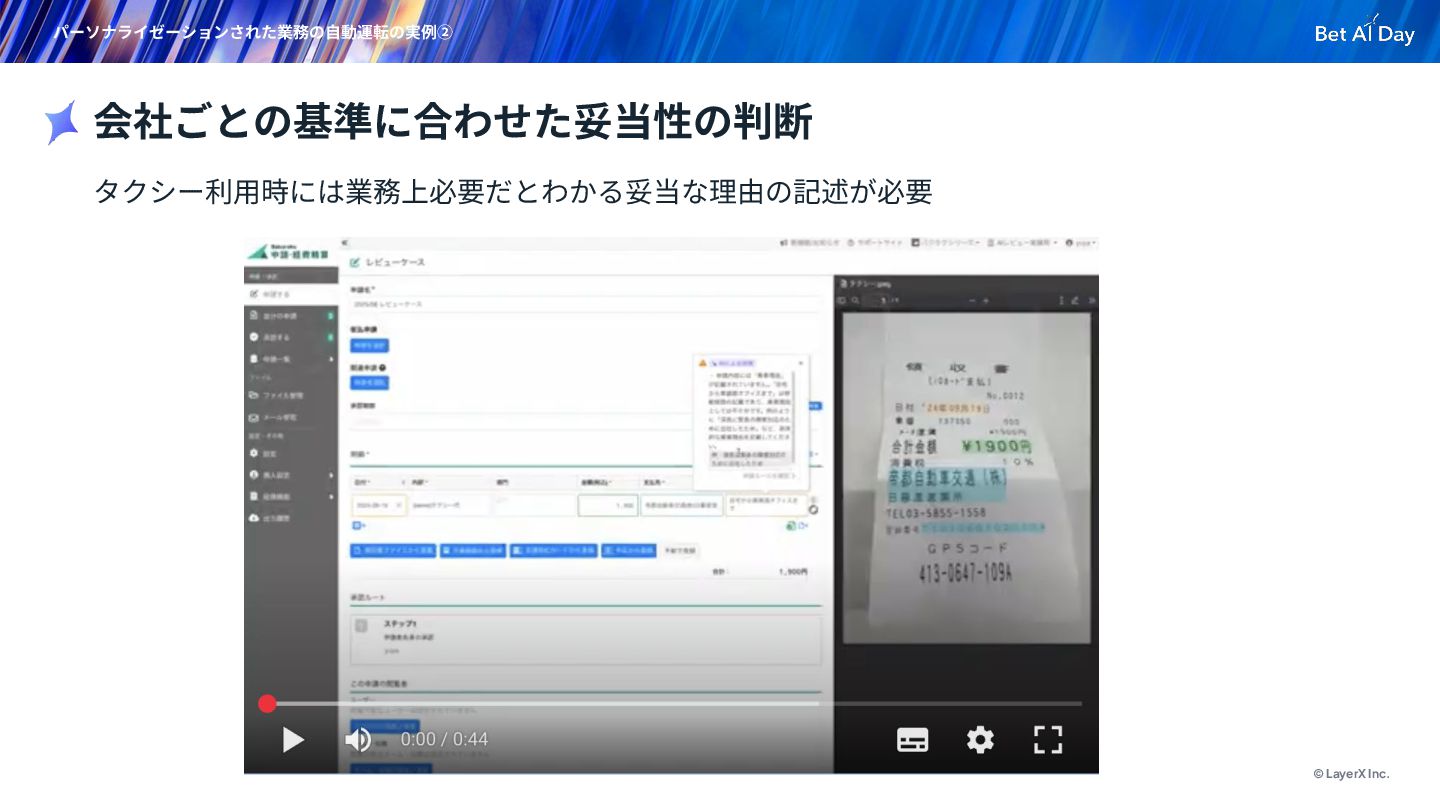{kind=link}
{kind=link}
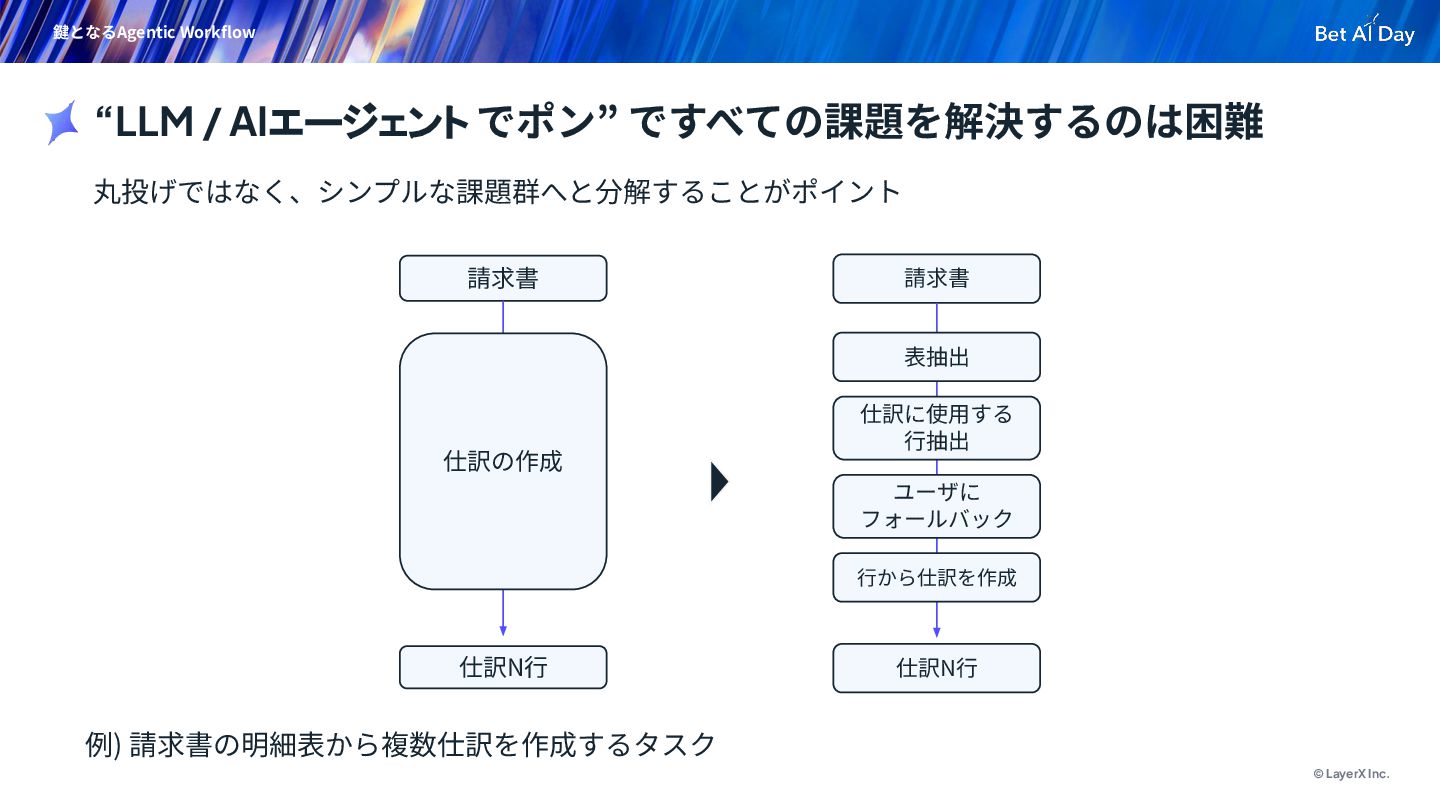{kind=link}
![© LayerX Inc. ⾃律性と決定性を兼ね揃えたAgentic Workflowが鍵となる 鍵となるAgentic Workflow 事前定義された決定的なAI Workflow、ドメイン特化した⾼性能toolなどをエージェントが利⽤可能 [1]](https://files.speakerdeck.com/presentations/02ca22e5fe61442a97b2a1ac3a249817/slide_19.jpg){kind=link}
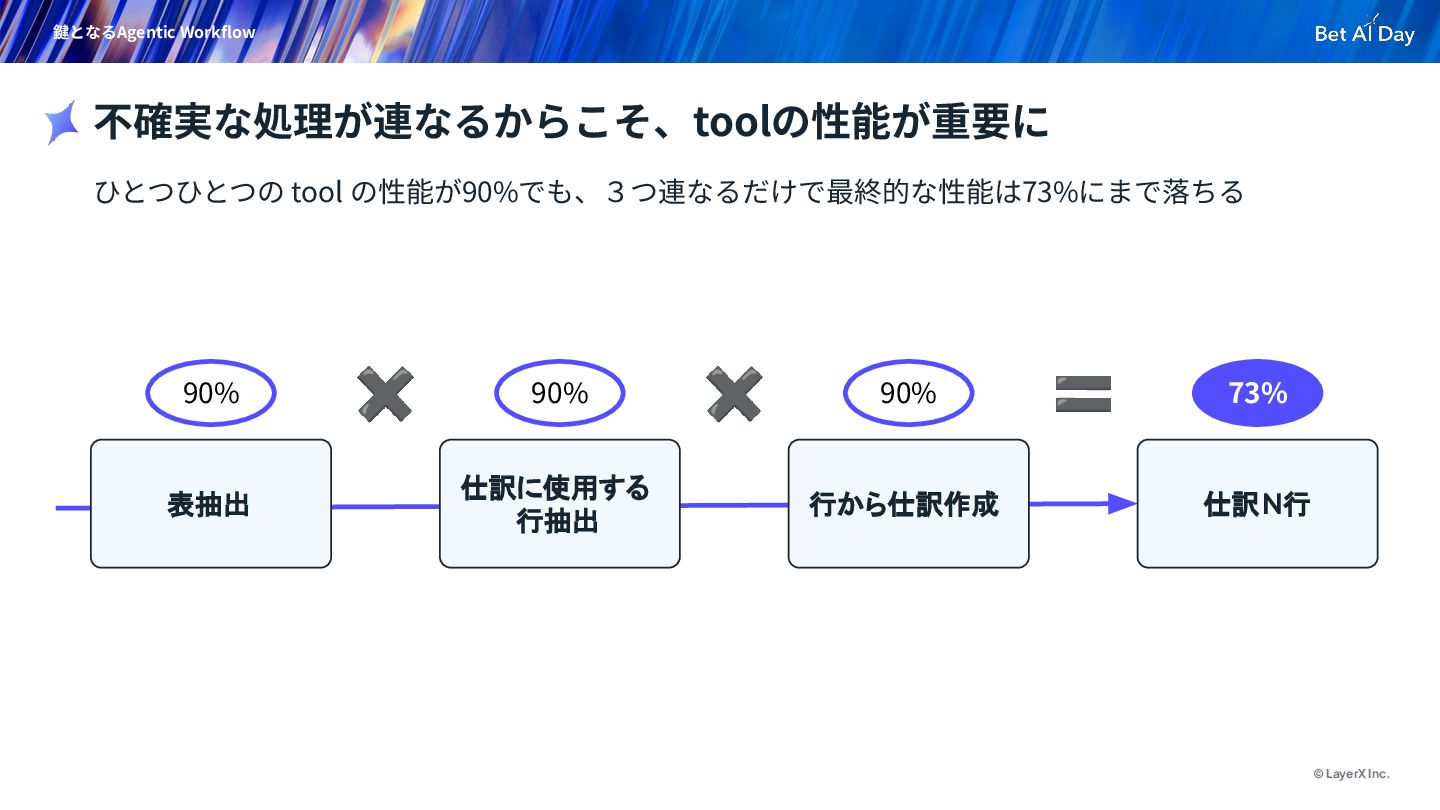{kind=link}
![© LayerX Inc. ⾃律性と決定性を兼ね揃えたAgentic Workflowが鍵となる 鍵となるAgentic Workflow [1] What's next](https://files.speakerdeck.com/presentations/02ca22e5fe61442a97b2a1ac3a249817/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
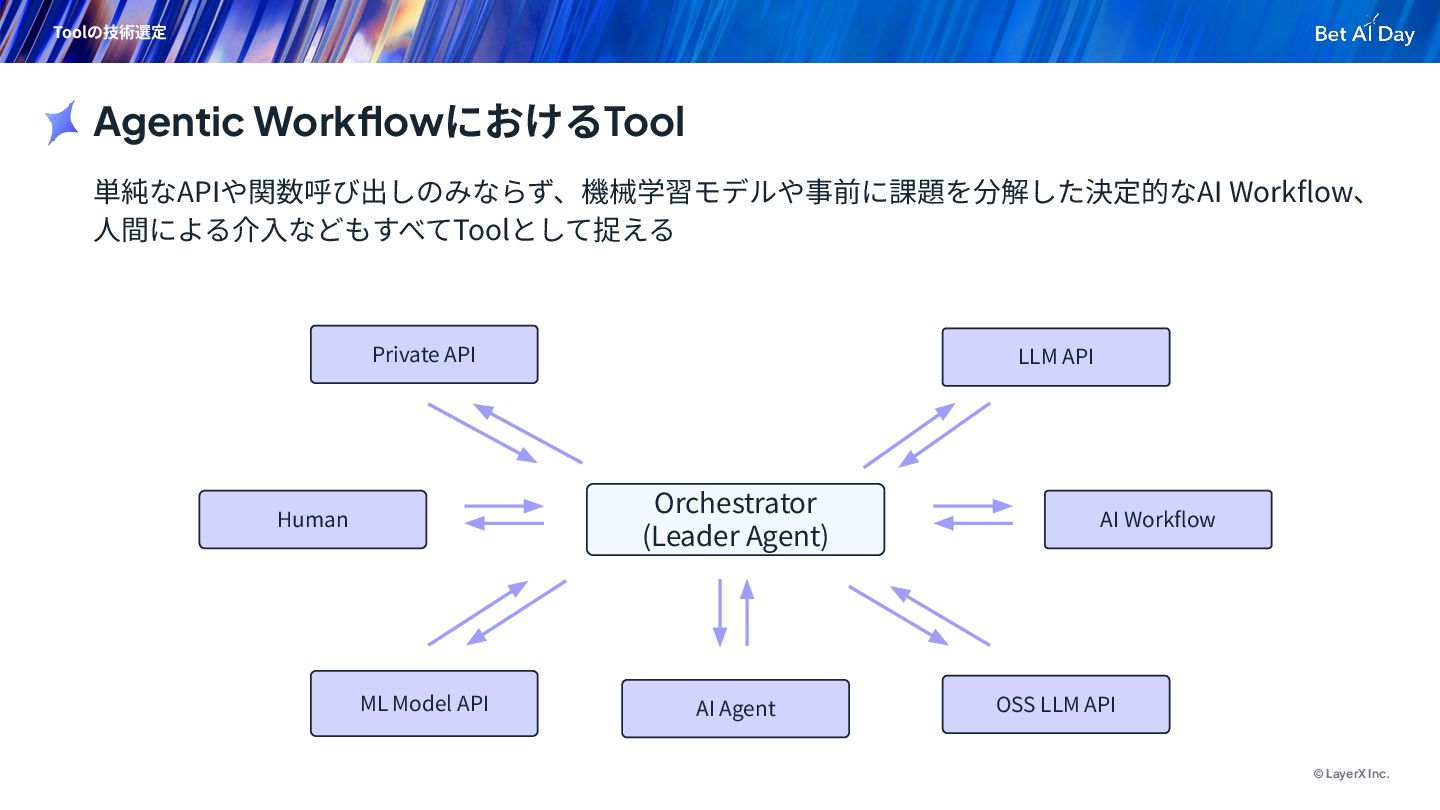{kind=link}
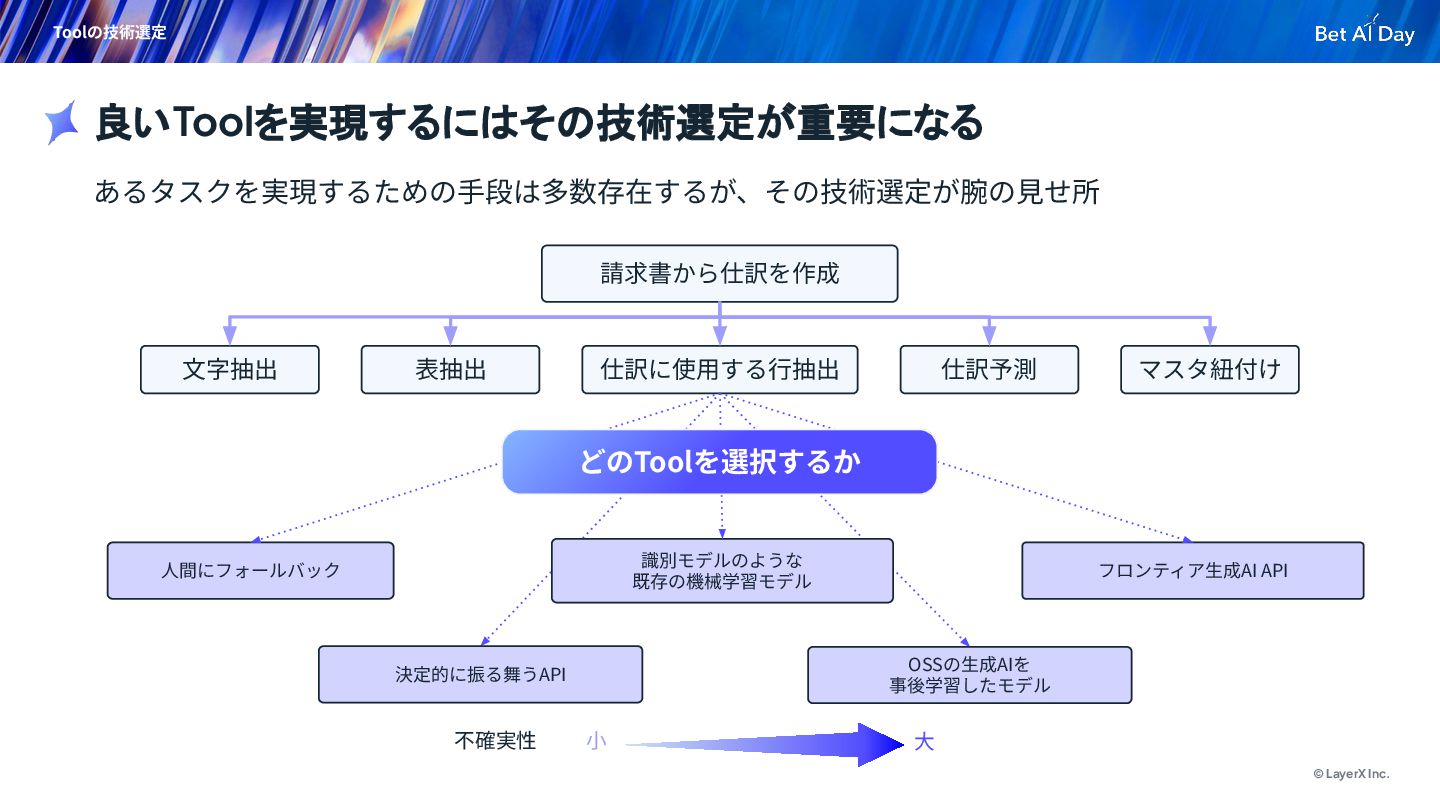{kind=link}
{kind=link}
{kind=link}
![© LayerX Inc. 追加のインフラコストはかかるが、検討する価値がある OSSのSmall Language Modelへの注⽬が⾼まる 精度[1] 扱いやすさ[2] •](https://files.speakerdeck.com/presentations/02ca22e5fe61442a97b2a1ac3a249817/slide_28.jpg){kind=link}
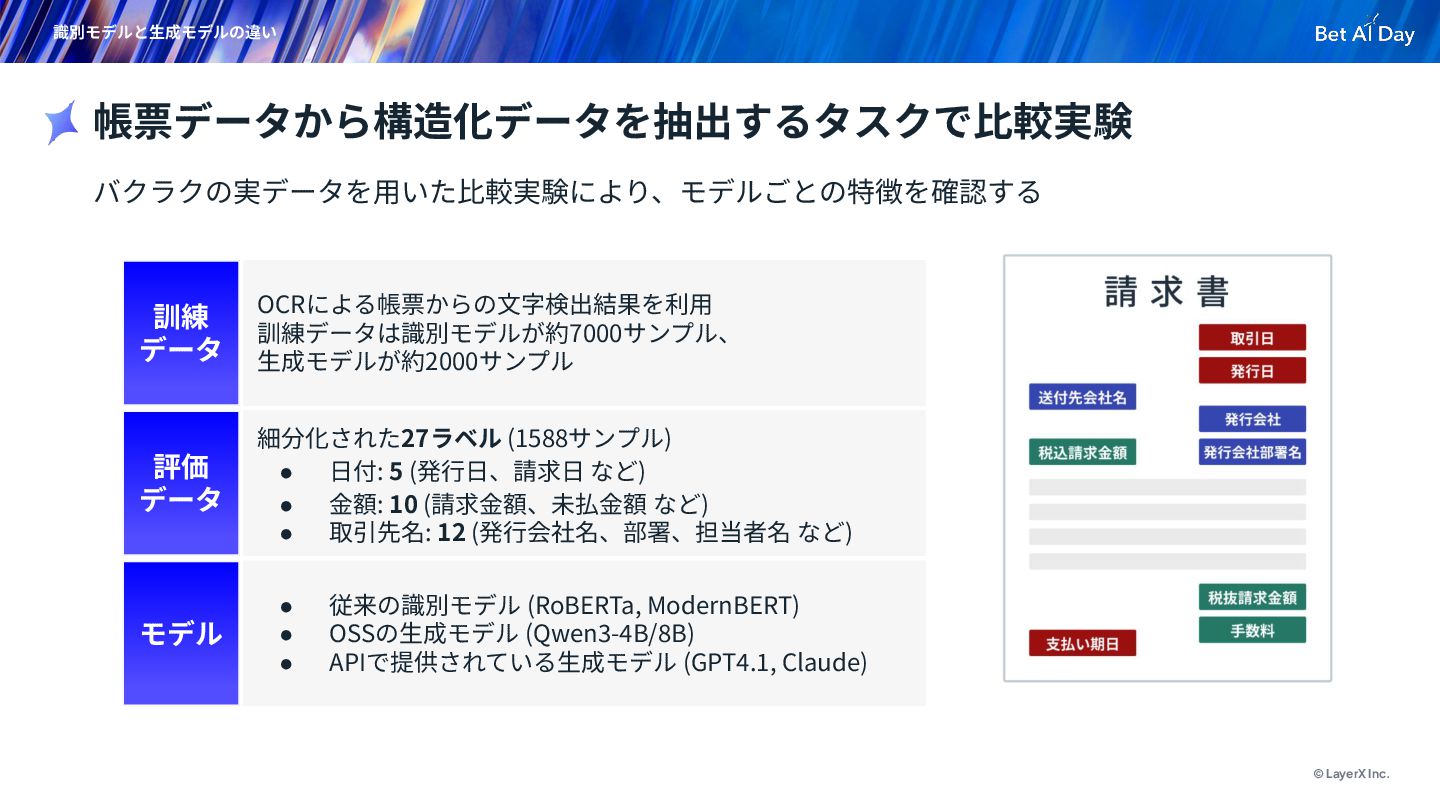{kind=link}
{kind=link}
{kind=link}
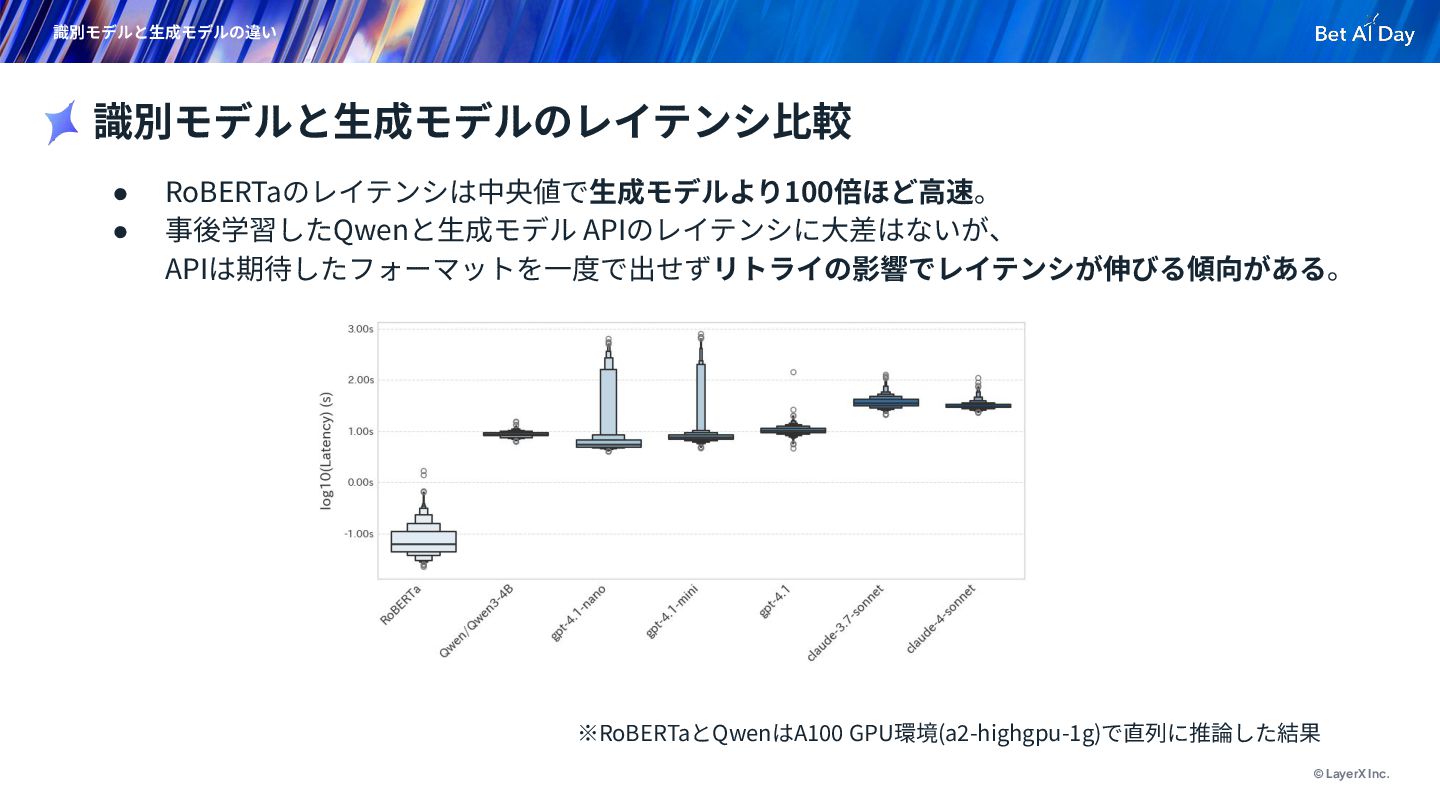{kind=link}
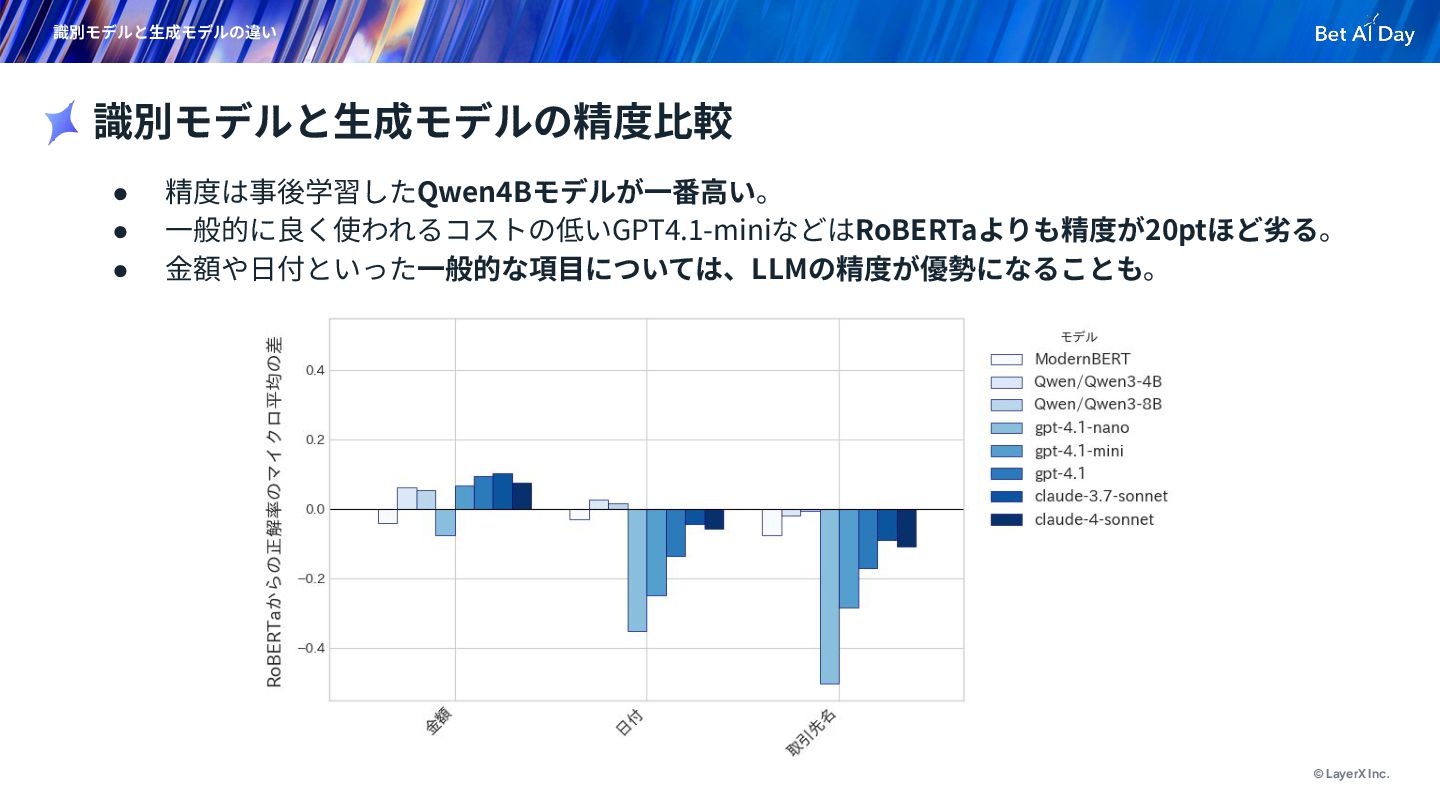{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
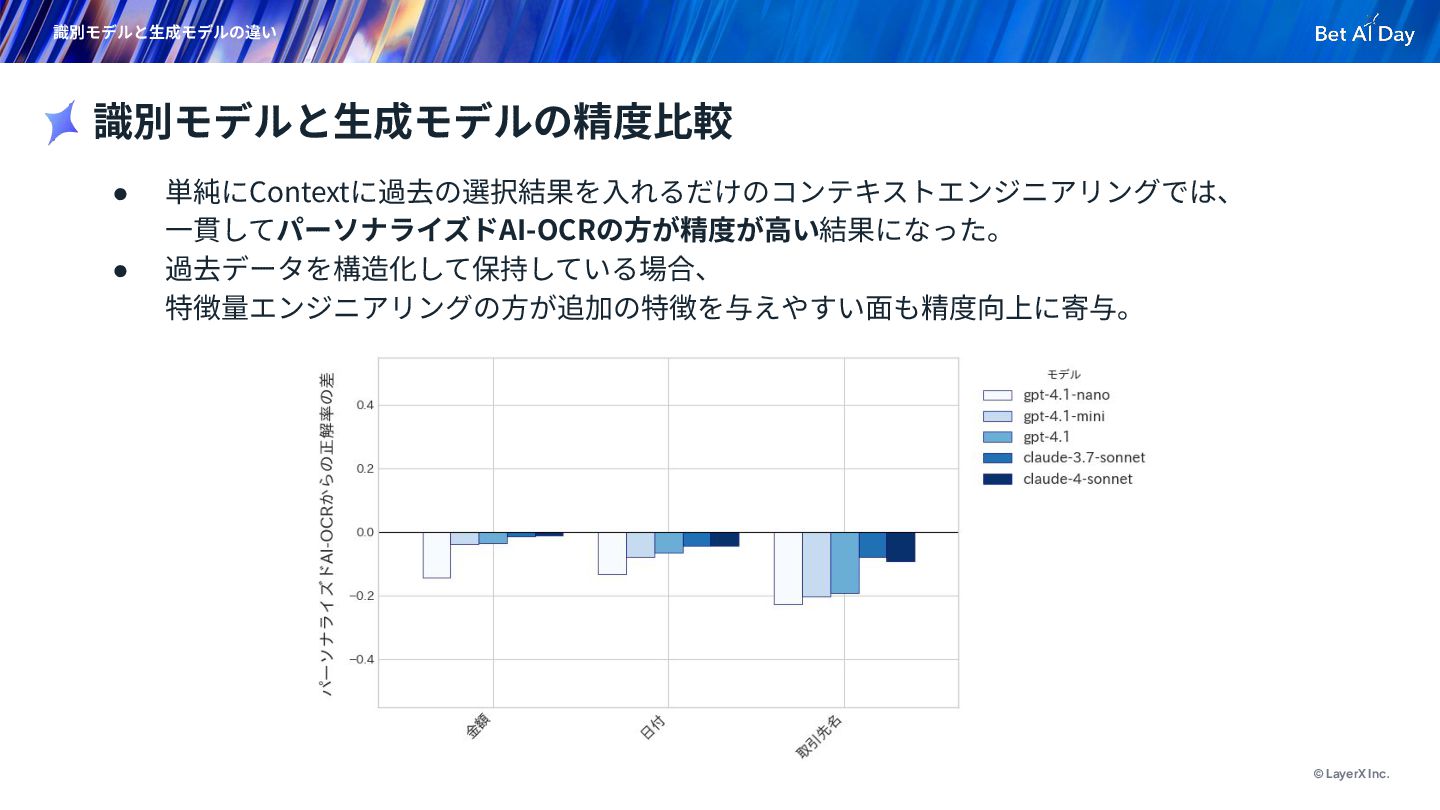{kind=link}
{kind=link}
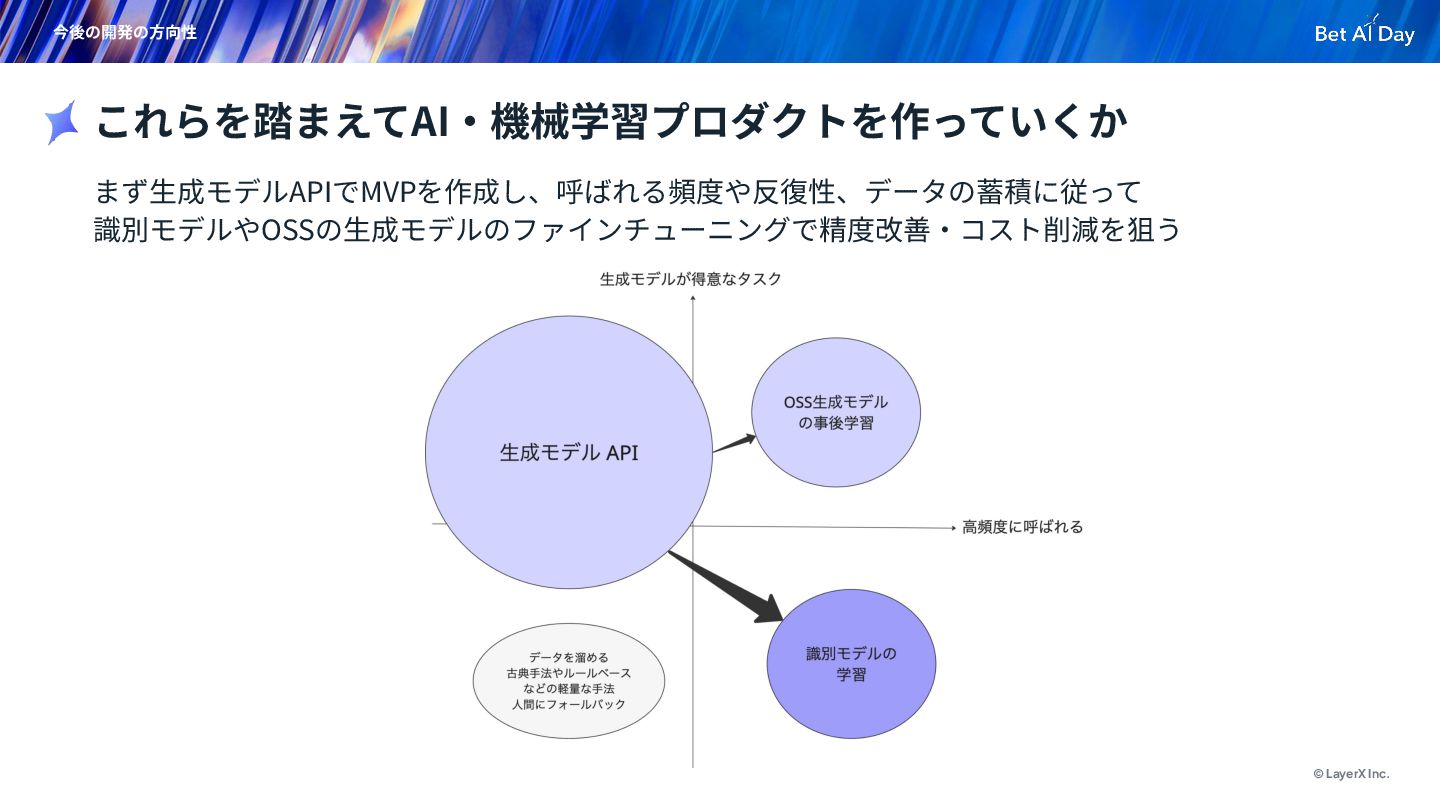{kind=link}
{kind=link}
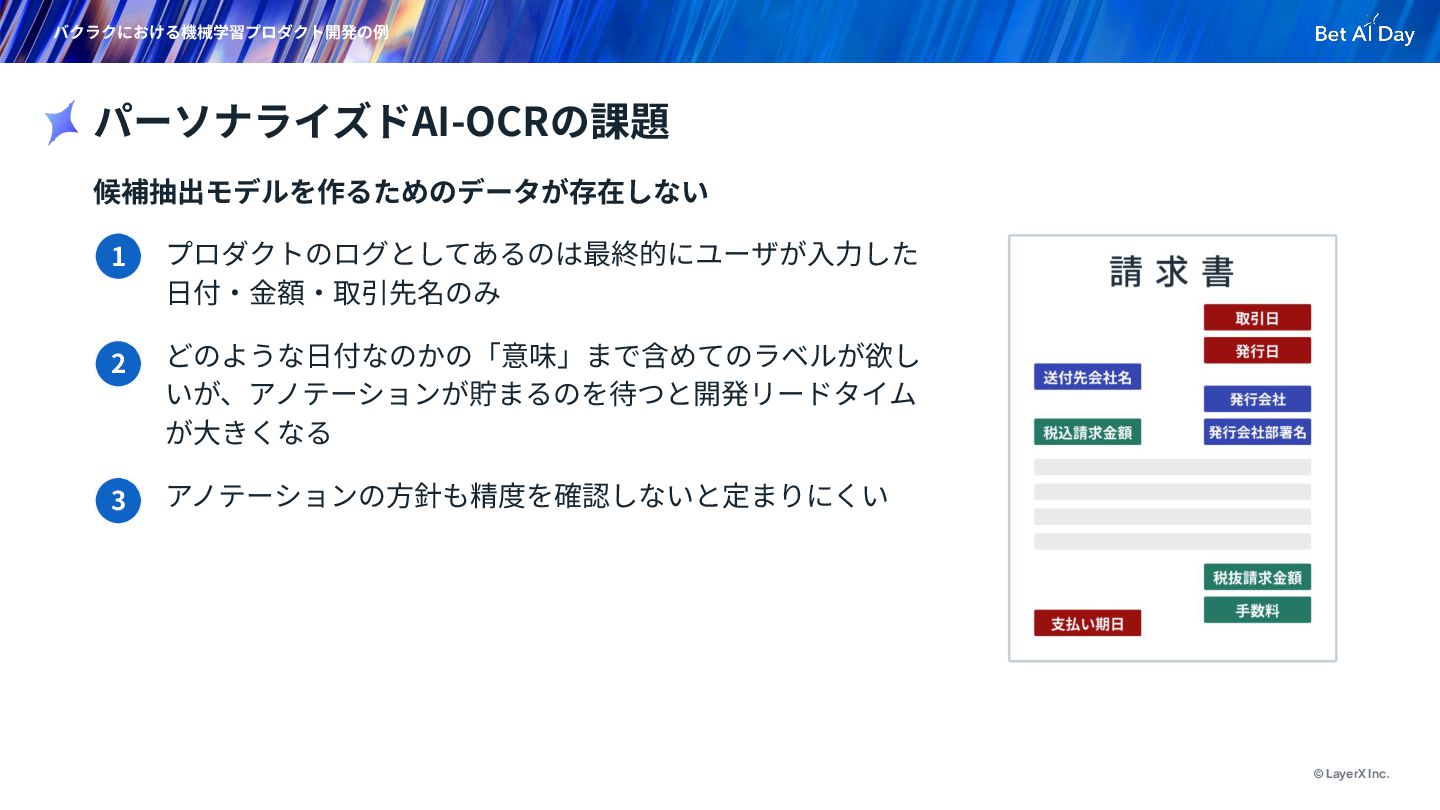{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}