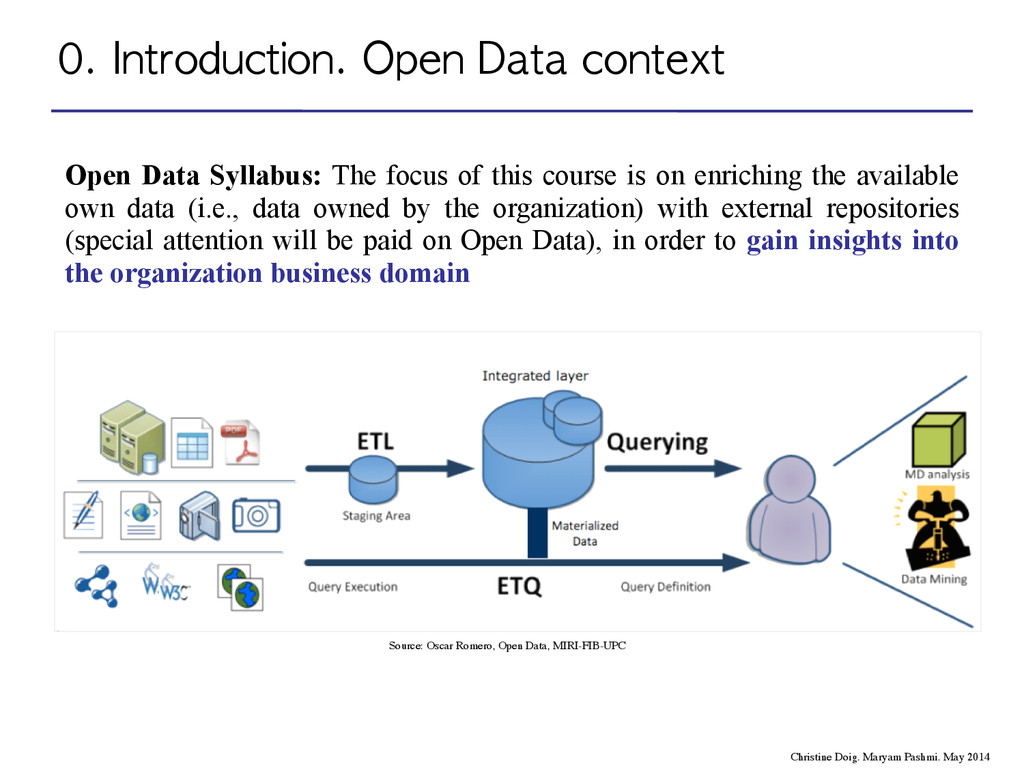
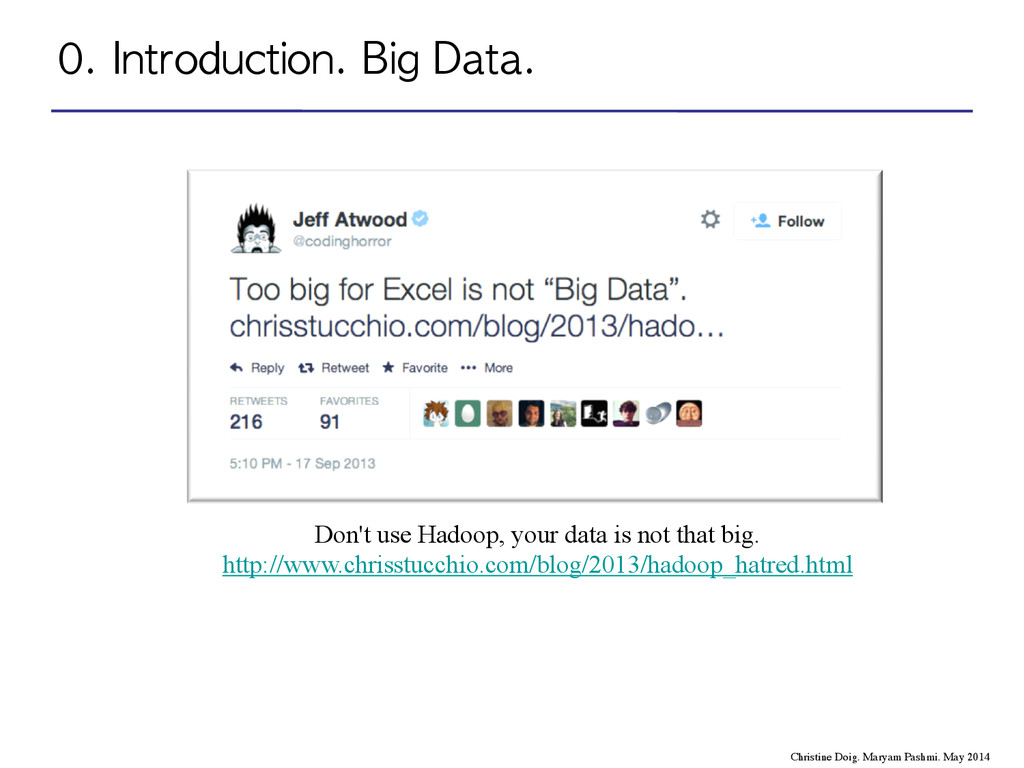
of this course is on enriching the available own data (i.e., data owned by the organization) with external repositories (special attention will be paid on Open Data), in order to gain insights into the organization business domain Source: Oscar Romero, Open Data, MIRI-FIB-UPC Christine Doig. Maryam Pashmi. May 2014
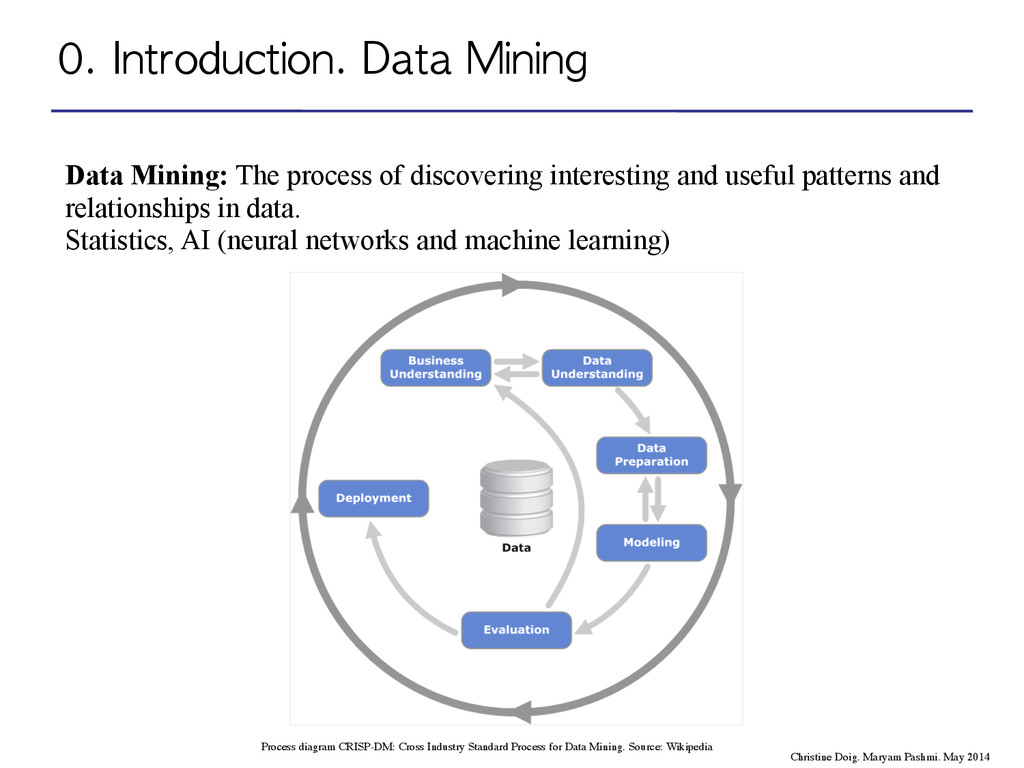
interesting and useful patterns and relationships in data. Statistics, AI (neural networks and machine learning) Source: Oscar Romero, Open Data, MIRI-FIB-UPC Process diagram CRISP-DM: Cross Industry Standard Process for Data Mining. Source: Wikipedia Christine Doig. Maryam Pashmi. May 2014
be modified by user-written code -> Giving you the pieces to build your tools. e.g. Ikea style -> Capability to build ! •Libraries: Implemented Algorithms -> Giving you a tool that you can use. You still need to know how the tool works -> Capability to use Christine Doig. Maryam Pashmi. May 2014
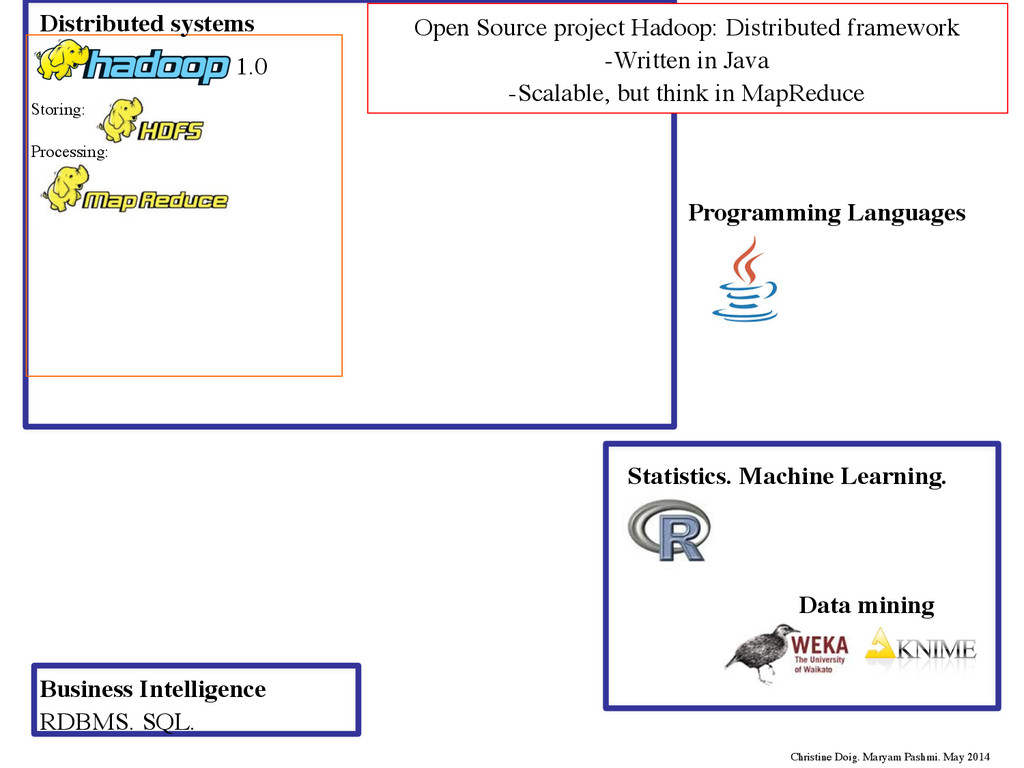
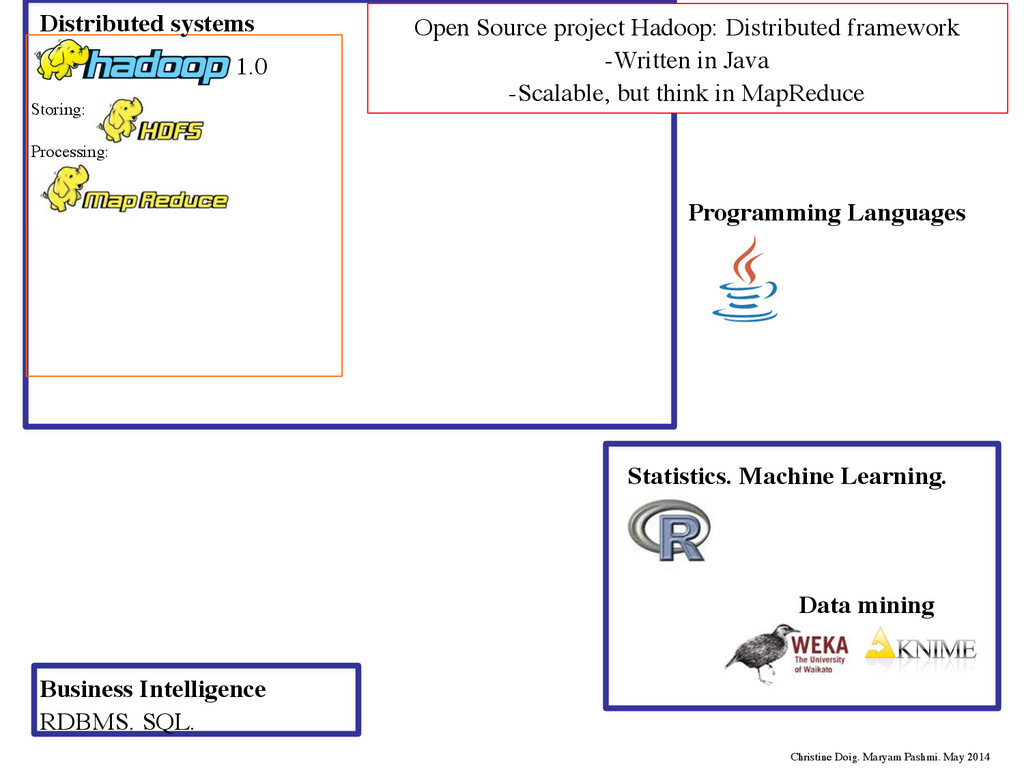
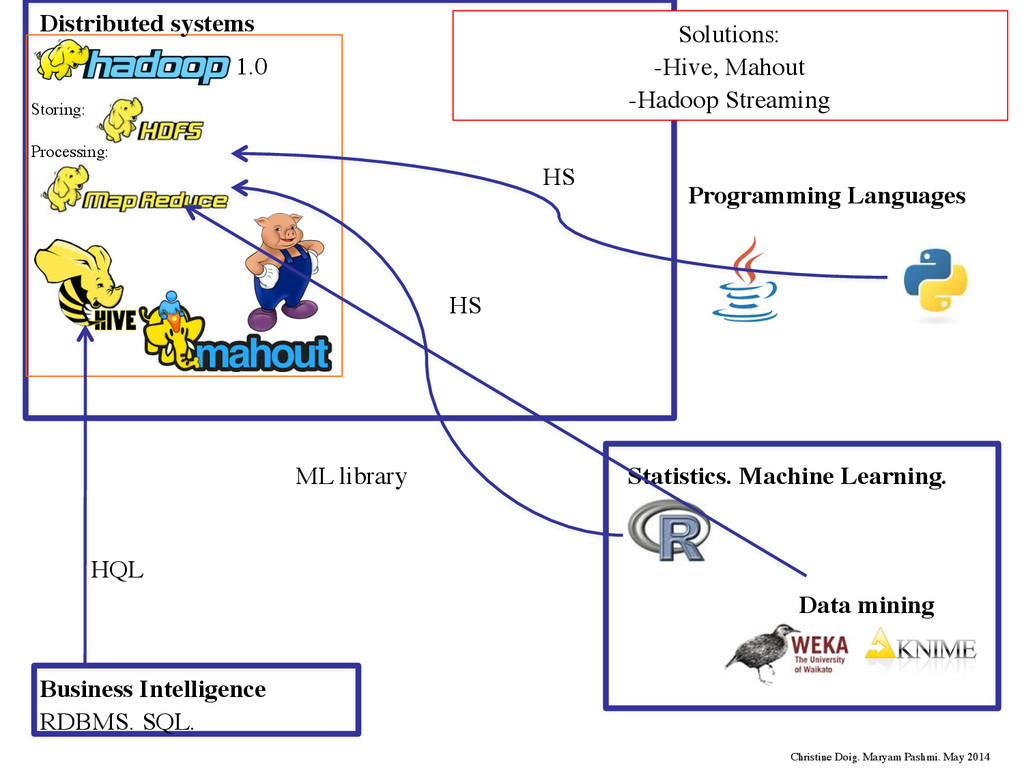
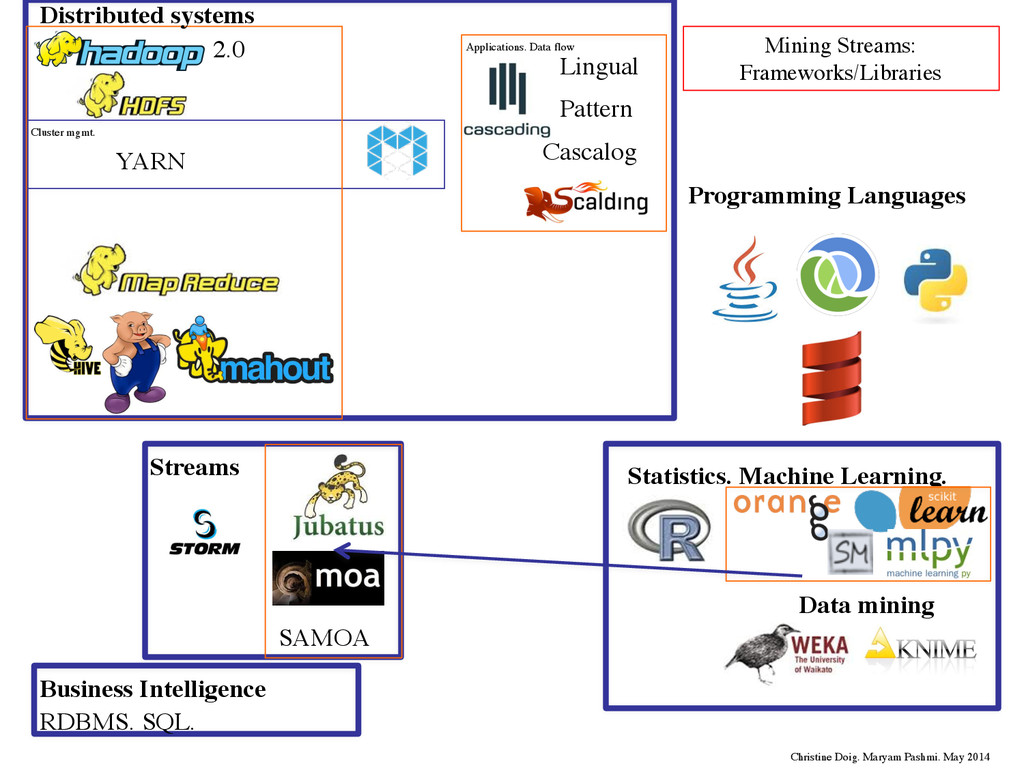
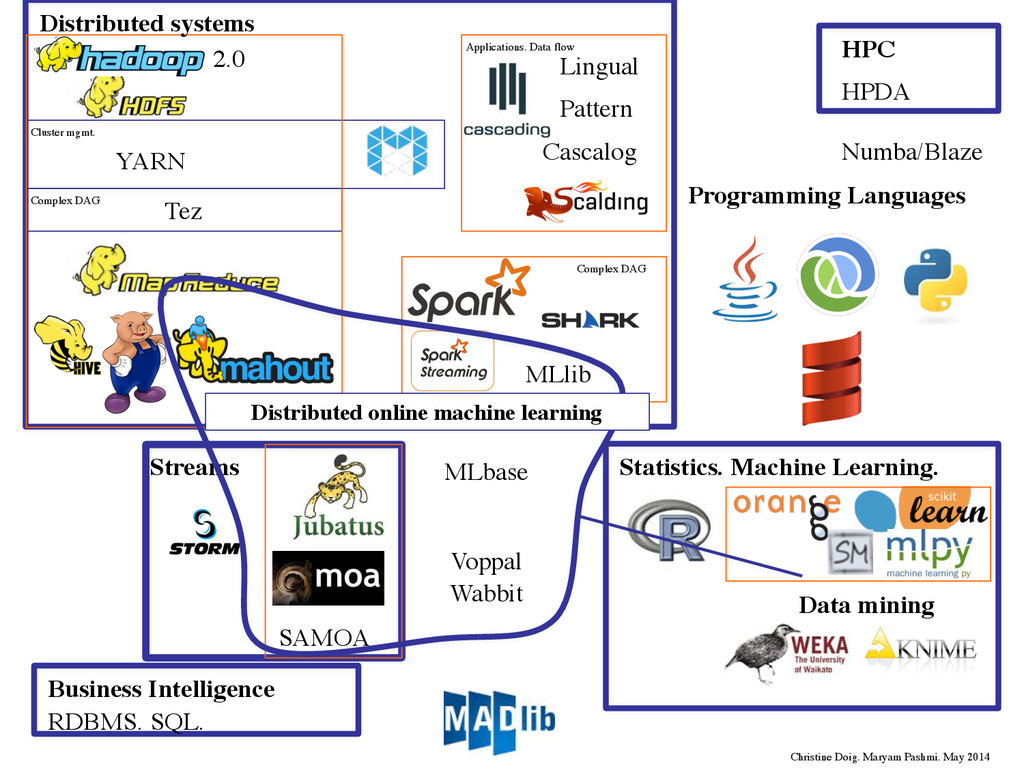
Languages 1.0 Storing: Processing: Open Source project Hadoop: Distributed framework -Written in Java -Scalable, but think in MapReduce Christine Doig. Maryam Pashmi. May 2014 Distributed systems
Languages 1.0 Storing: Processing: Open Source project Hadoop: Distributed framework -Written in Java -Scalable, but think in MapReduce Christine Doig. Maryam Pashmi. May 2014 Distributed systems Source: Doug Cutting
Languages 1.0 Storing: Processing: Open Source project Hadoop: Distributed framework -Written in Java -Scalable, but think in MapReduce Christine Doig. Maryam Pashmi. May 2014 Distributed systems
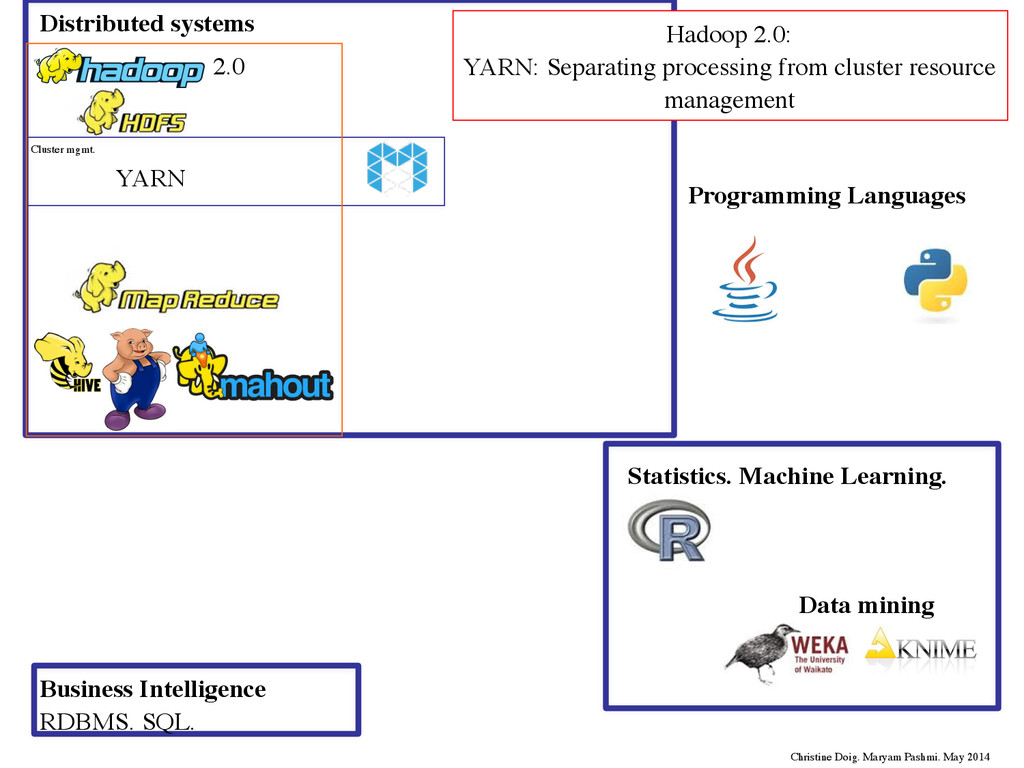
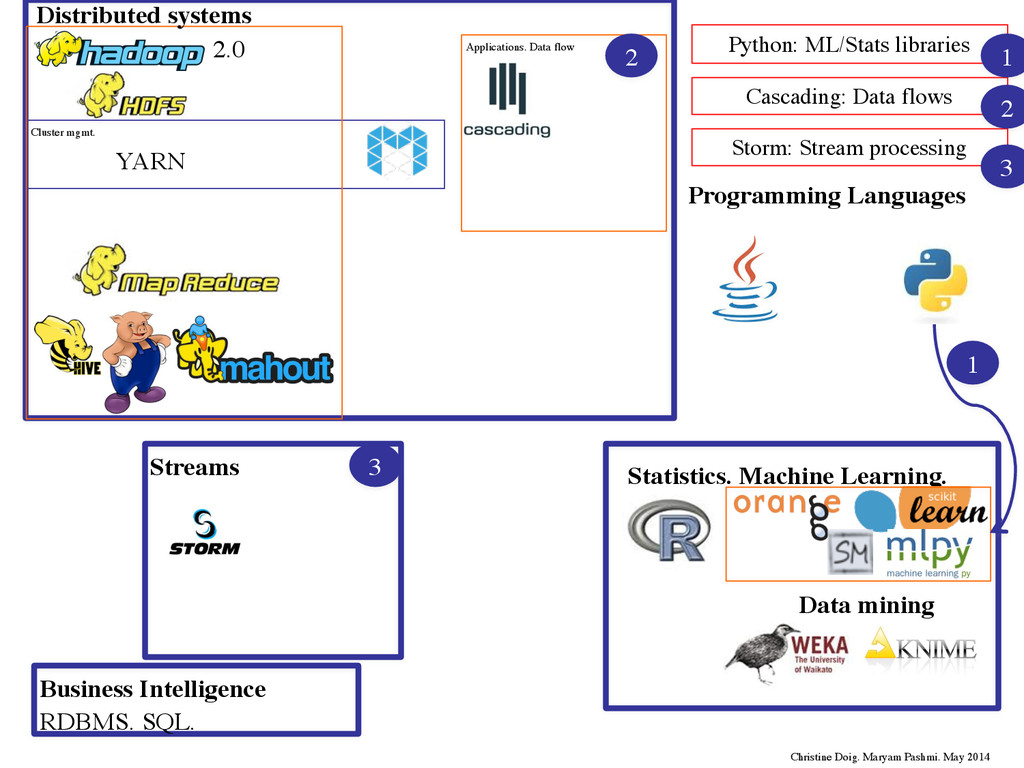
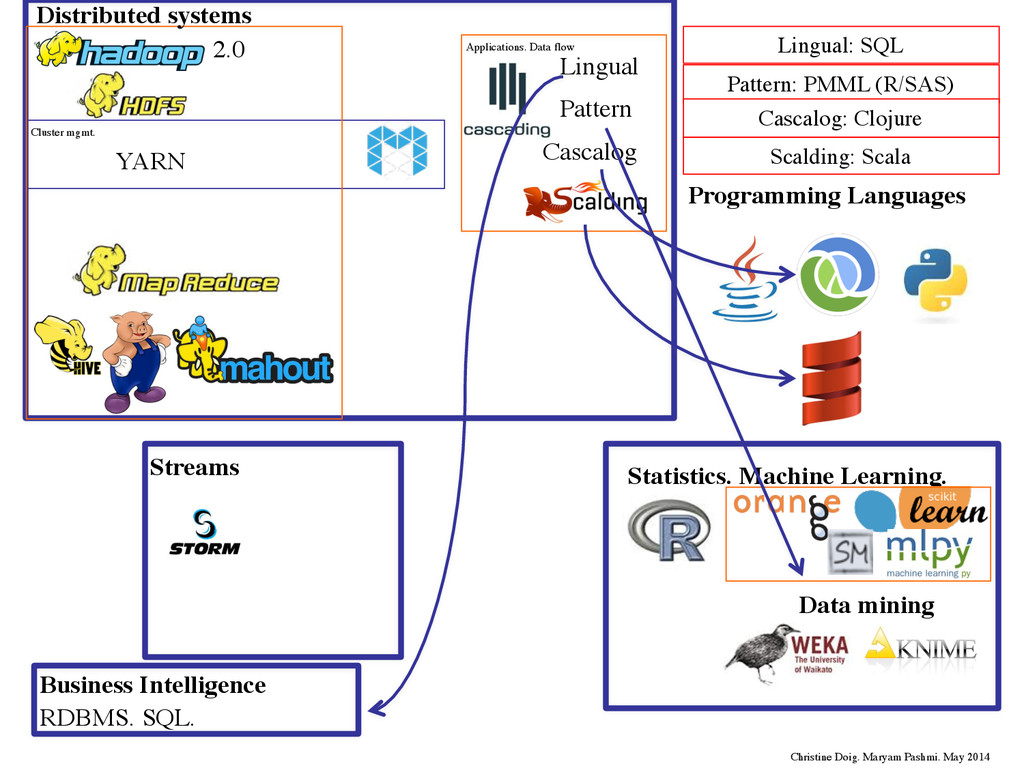
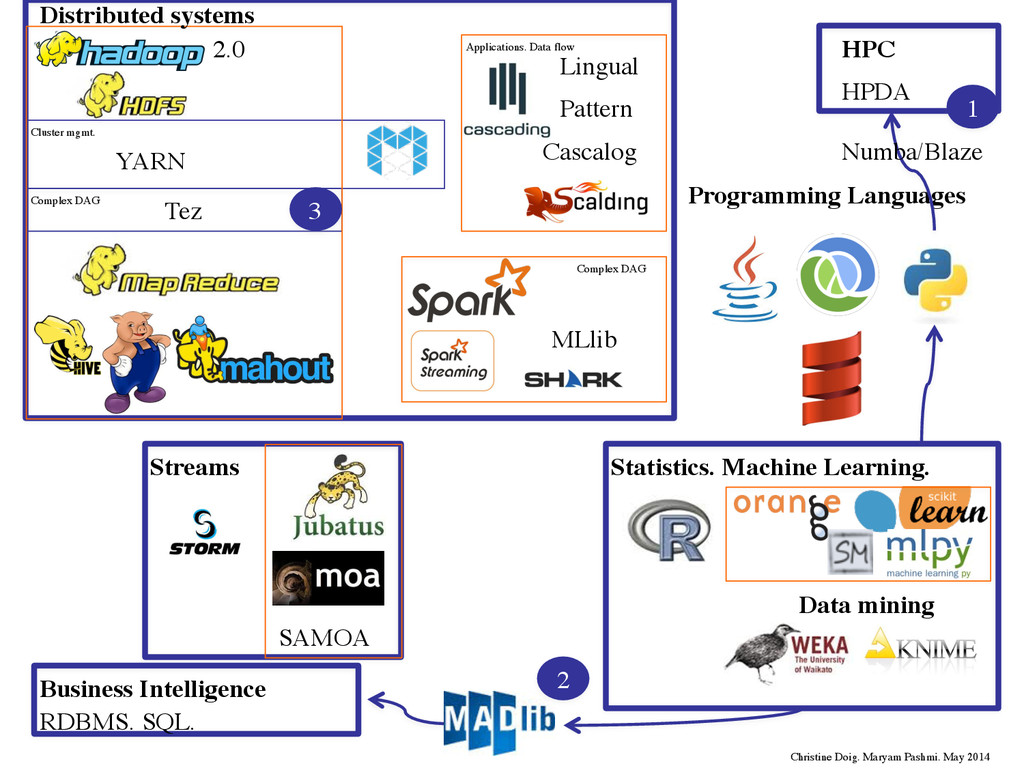
Languages HPC HPDA Streams SAMOA YARN Cluster mgmt. Tez Complex DAG 2.0 Cascalog Lingual Pattern MLlib Complex DAG Applications. Data flow Numba/Blaze Christine Doig. Maryam Pashmi. May 2014 Distributed systems 1 2 3
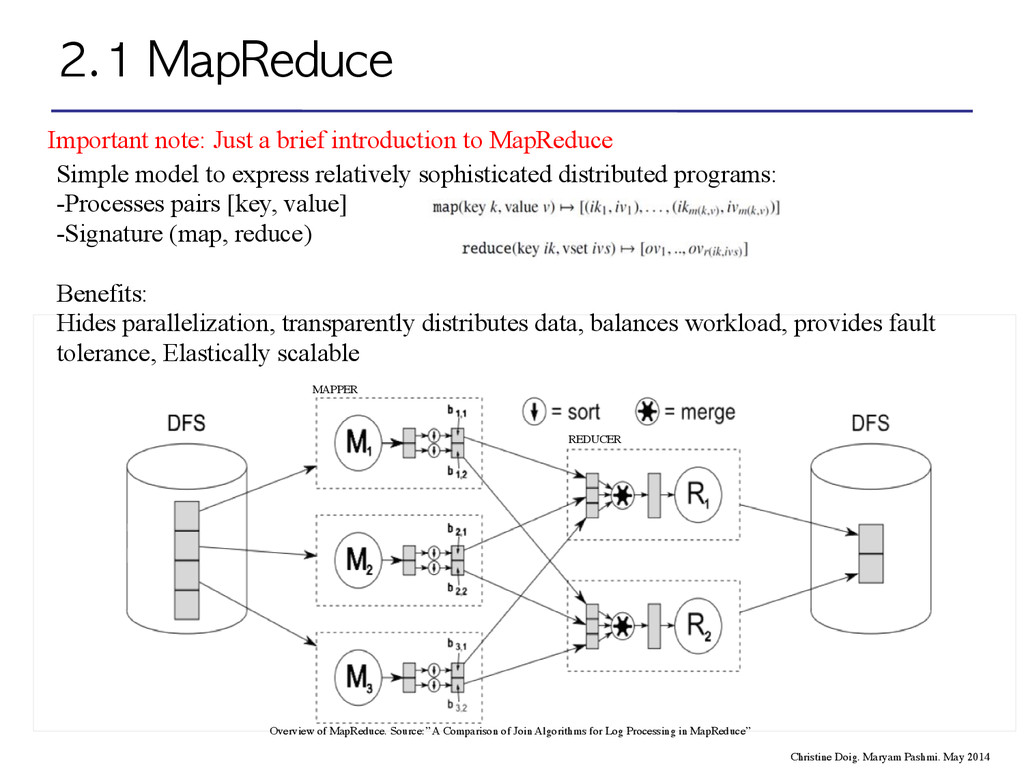
Summary What are the problems with plain MapReduce? • Fit your problem into MapReduce • Java • Optimization • Performance • Moving data around Christine Doig. Maryam Pashmi. May 2014
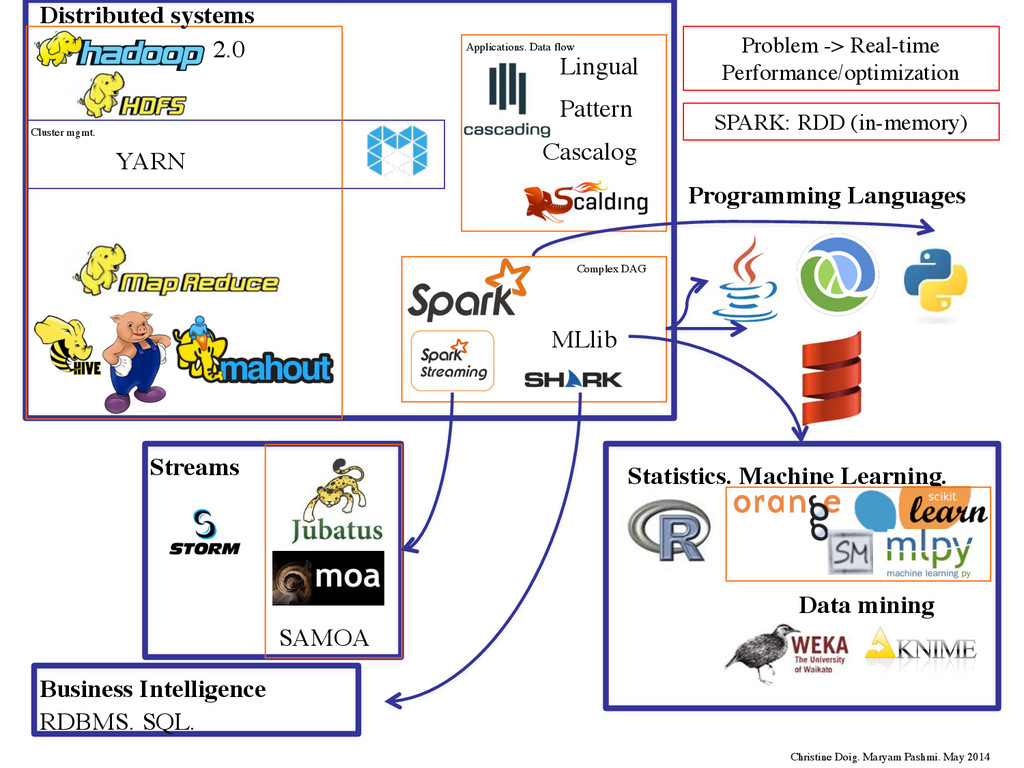
MapReduce: Building frameworks and tools on top of MapReduce: -Hive (HQL), Pig (ETL/data flow/scripts), Cascading (data flow). Building DM/ML libraries on top of MapReduce: -Mahout, Pattern •Java: -Hadoop Streaming -R (RHadoop/RSpark) & Python(PySpark) -Scala (Scalding, Spark) & Clojure (Cascalog) •Optimization: Building application framework which allows for a complex directed-acyclic- graph of tasks for processing data: -Tez/Spark •Performance: Interactivity and Iteration: Spark. Streaming and Real-time: Storm, Spark Streaming •Moving data around: Bring the algorithms to the DB: MADlib Christine Doig. Maryam Pashmi. May 2014
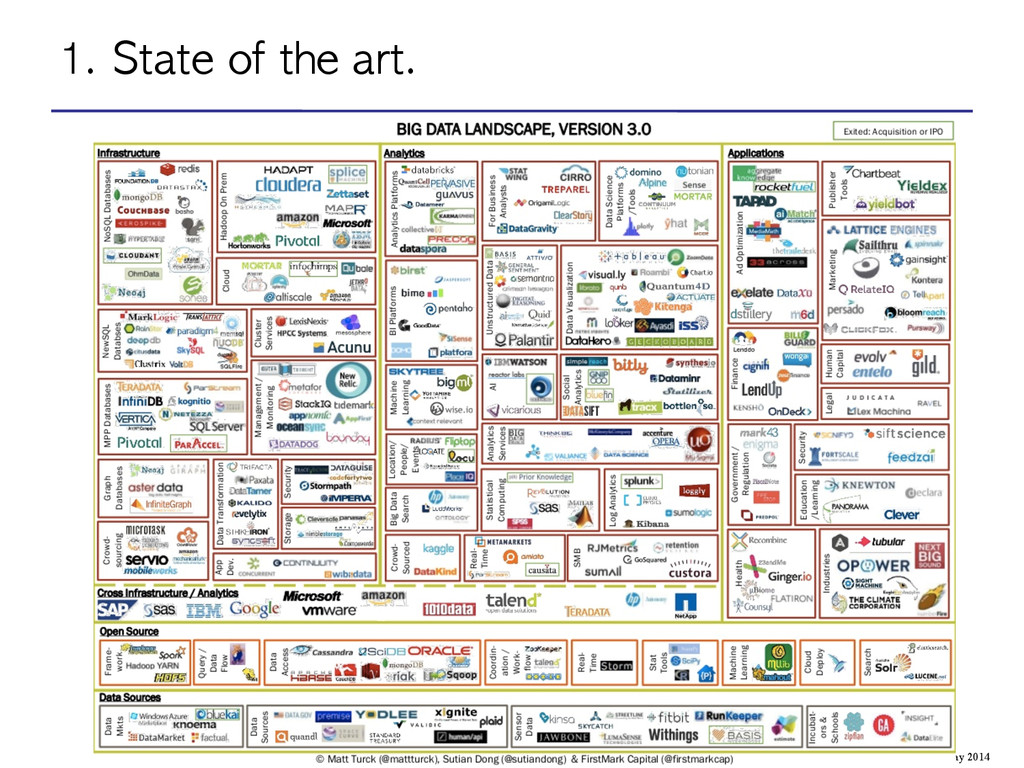
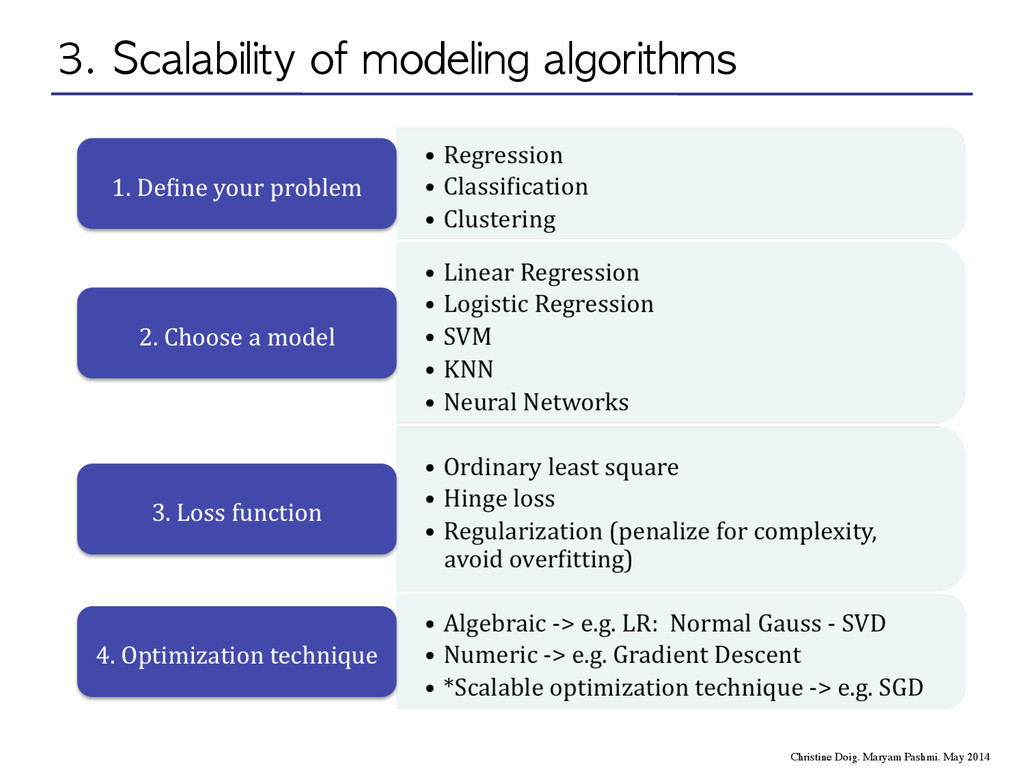
May 2014 Next Section: 2. Frameworks and Libraries -> Present each technology 3. Scalability of Modeling algorithm -> Approach comparison between libraries
machine learning libraries under the Apache Software License. •Hides the underlying MapReduce processes to the user. •Provides implemented algorithms. ! 2.1 Mahout *From April, 25th : The Mahout community decided to move its codebase onto modern data processing systems that offer a richer programming model and more efficient execution than Hadoop MapReduce. Mahout will therefore reject new MapReduce algorithm implementations from now on. We will however keep our widely used MapReduce algorithms in the codebase and maintain them. ! Why? Spark Christine Doig. Maryam Pashmi. May 2014 Source: http://mahout.apache.org/ Contains: User and Item based recommenders Matrix factorization based recommenders K-Means, Fuzzy K-Means clustering Latent Dirichlet Allocation Singular Value Decomposition Logistic regression classifier (Complementary) Naive Bayes classifier Random forest classifier
the correlation coefficient between their interactions. define which simila users we want to leverage for the recommender 2.1 Mahout - Example Christine Doig. Maryam Pashmi. May 2014
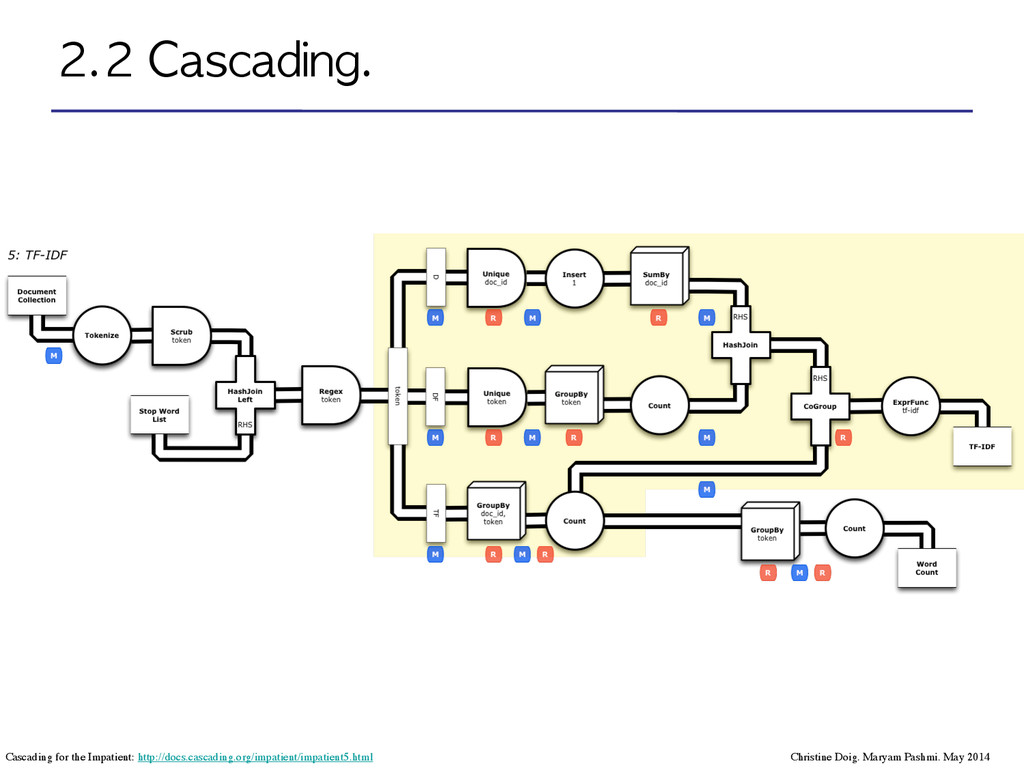
a software abstraction layer for Apache Hadoop that is intended to allow developers to write their data applications once and then deploy those applications on any big data infrastructure. ! In Cascading you define workflows, pipes of data that get routed through familiar operators such as "GroupBy", "Count", "Filter", "Merge", “Each” (map), “Every” (aggregate), “CoGroup” (MR join), “HashJoin” (Local join), etc. ! In Cascading vocabulary: "Build a Cascade from Flows which connect Taps via Pipes built into Assemblies to process Tuples” ! A workflow can be visualized as a "flow diagram”. ! ! “Scalding the Crunchy Pig for Cascading into the Hive“ http://thewit.ch/scalding_crunchy_pig
Predictive Model Markup Language •Import model descriptions from R, SAS,Weka, RapidMiner, KNIME,SQL Server, etc. •XML-based file format developed by the Data Mining Group •Implemented algorithms: Random Forest, Linear Regression, Hierarchical Clustering and K-Means Clustering, Logistic Regression. Example: Linear Regression. package cascading.pattern.pmml.iris; *Popular open source projects have been built on of top Cascading, such as Scala (Scalding) and Clojure (Cascalog), which include significant Machine Learning libraries.
Predictive Model Markup Language •Import model descriptions from R, SAS,Weka, RapidMiner, KNIME,SQL Server, etc. •XML-based file format developed by the Data Mining Group •Implemented algorithms: Random Forest, Linear Regression, Hierarchical Clustering and K-Means Clustering, Logistic Regression. Example: Linear Regression. package cascading.pattern.pmml.iris; *Popular open source projects have been built on of top Cascading, such as Scala (Scalding) and Clojure (Cascalog), which include significant Machine Learning libraries.
Predictive Model Markup Language •Import model descriptions from R, SAS,Weka, RapidMiner, KNIME,SQL Server, etc. •XML-based file format developed by the Data Mining Group •Implemented algorithms: Random Forest, Linear Regression, Hierarchical Clustering and K-Means Clustering, Logistic Regression. Example: Linear Regression. package cascading.pattern.pmml.iris; *Popular open source projects have been built on of top Cascading, such as Scala (Scalding) and Clojure (Cascalog), which include significant Machine Learning libraries.
Predictive Model Markup Language •Import model descriptions from R, SAS,Weka, RapidMiner, KNIME,SQL Server, etc. •XML-based file format developed by the Data Mining Group •Implemented algorithms: Random Forest, Linear Regression, Hierarchical Clustering and K-Means Clustering, Logistic Regression. Example: Linear Regression. package cascading.pattern.pmml.iris; *Popular open source projects have been built on of top Cascading, such as Scala (Scalding) and Clojure (Cascalog), which include significant Machine Learning libraries.
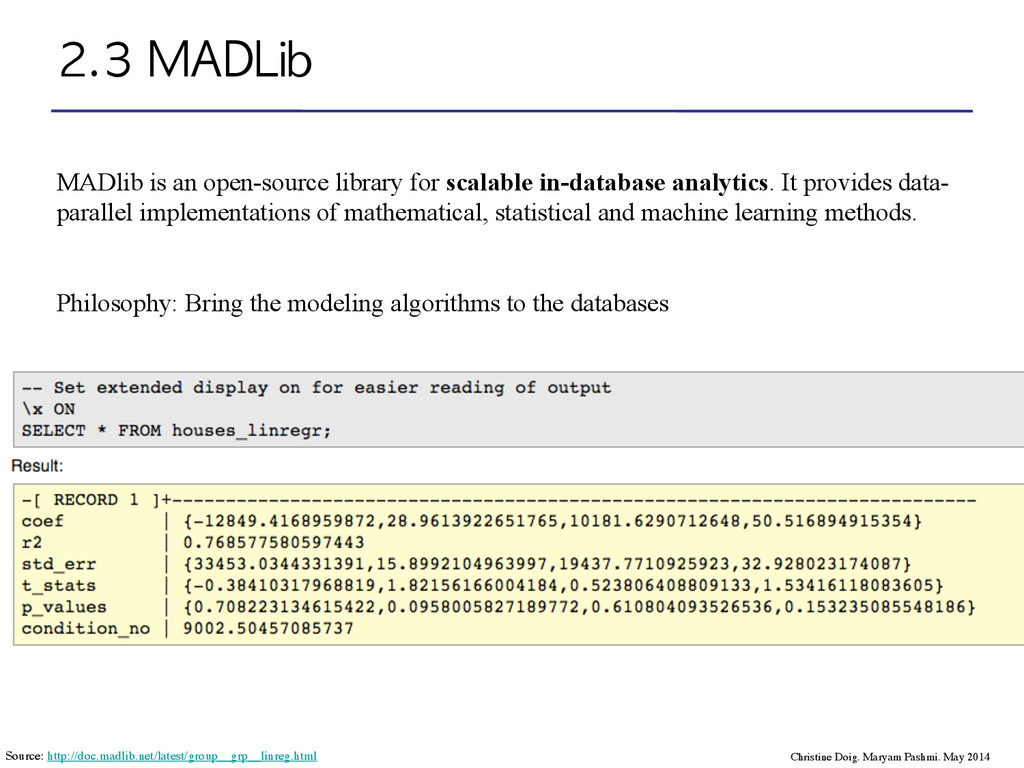
the modeling algorithms to the databases MADlib is an open-source library for scalable in-database analytics. It provides data- parallel implementations of mathematical, statistical and machine learning methods. Source: http://doc.madlib.net/latest/group__grp__linreg.html
the modeling algorithms to the databases MADlib is an open-source library for scalable in-database analytics. It provides data- parallel implementations of mathematical, statistical and machine learning methods. Source: http://doc.madlib.net/latest/group__grp__linreg.html
the modeling algorithms to the databases MADlib is an open-source library for scalable in-database analytics. It provides data- parallel implementations of mathematical, statistical and machine learning methods. Source: http://doc.madlib.net/latest/group__grp__linreg.html
the modeling algorithms to the databases MADlib is an open-source library for scalable in-database analytics. It provides data- parallel implementations of mathematical, statistical and machine learning methods. Source: http://doc.madlib.net/latest/group__grp__linreg.html
the modeling algorithms to the databases MADlib is an open-source library for scalable in-database analytics. It provides data- parallel implementations of mathematical, statistical and machine learning methods. Source: http://doc.madlib.net/latest/group__grp__linreg.html
the modeling algorithms to the databases MADlib is an open-source library for scalable in-database analytics. It provides data- parallel implementations of mathematical, statistical and machine learning methods. Source: http://doc.madlib.net/latest/group__grp__linreg.html
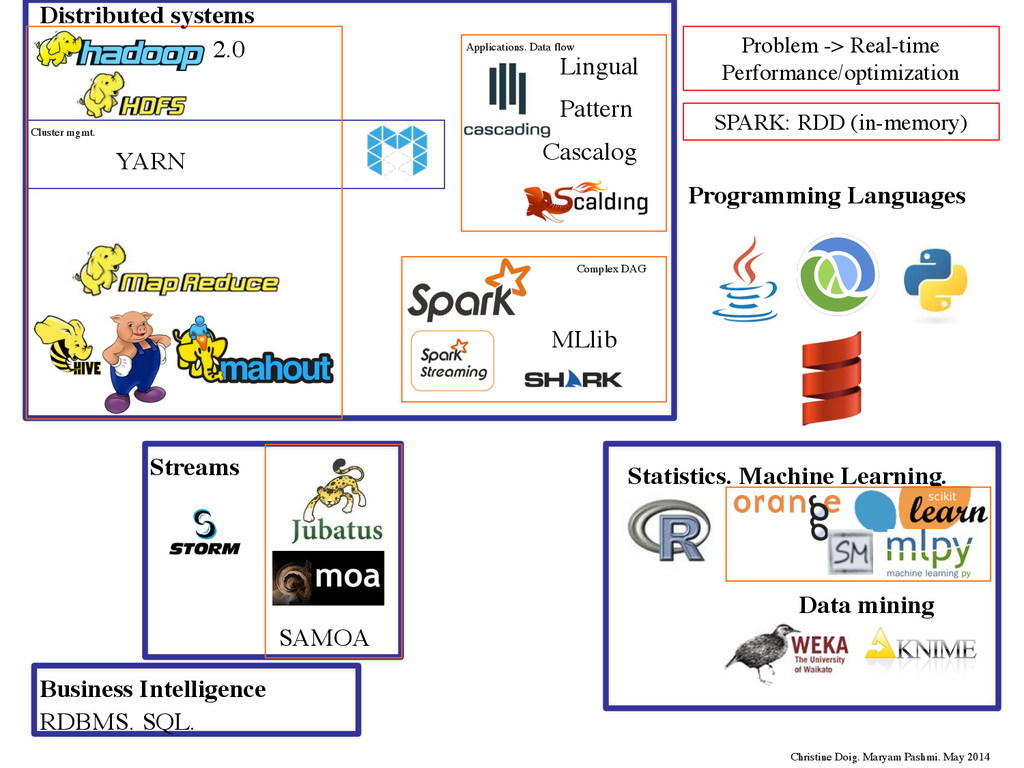
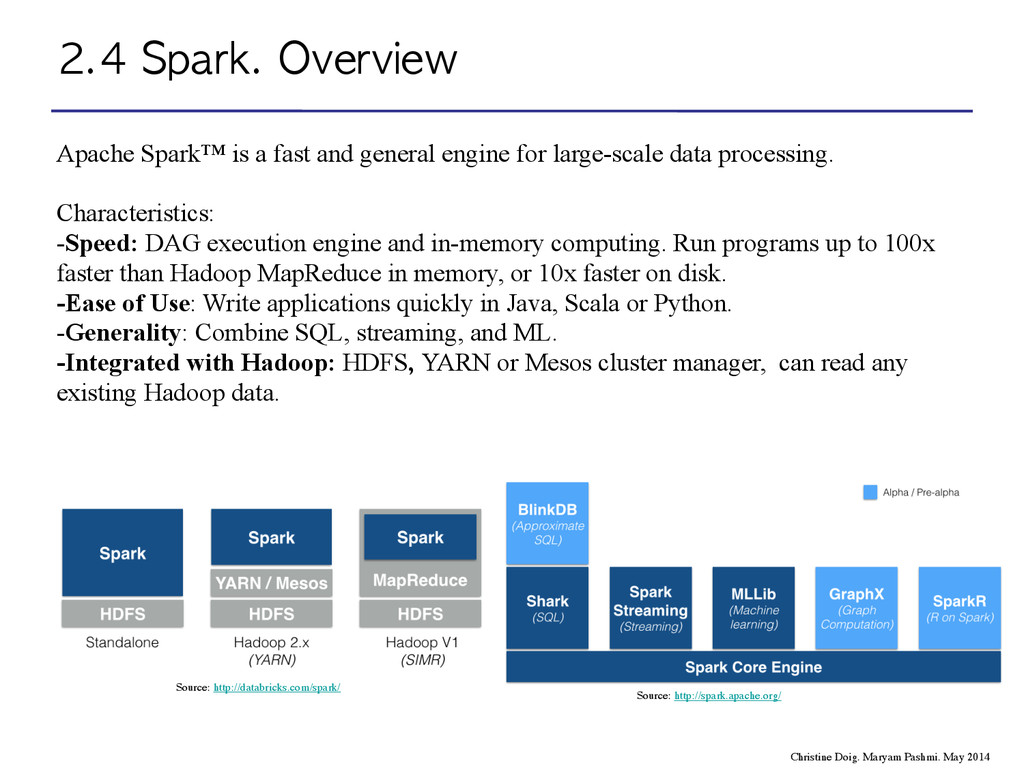
Spark™ is a fast and general engine for large-scale data processing. ! Characteristics: -Speed: DAG execution engine and in-memory computing. Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. -Ease of Use: Write applications quickly in Java, Scala or Python. -Generality: Combine SQL, streaming, and ML. -Integrated with Hadoop: HDFS, YARN or Mesos cluster manager, can read any existing Hadoop data. ! ! ! ! Source: http://databricks.com/spark/ Source: http://spark.apache.org/
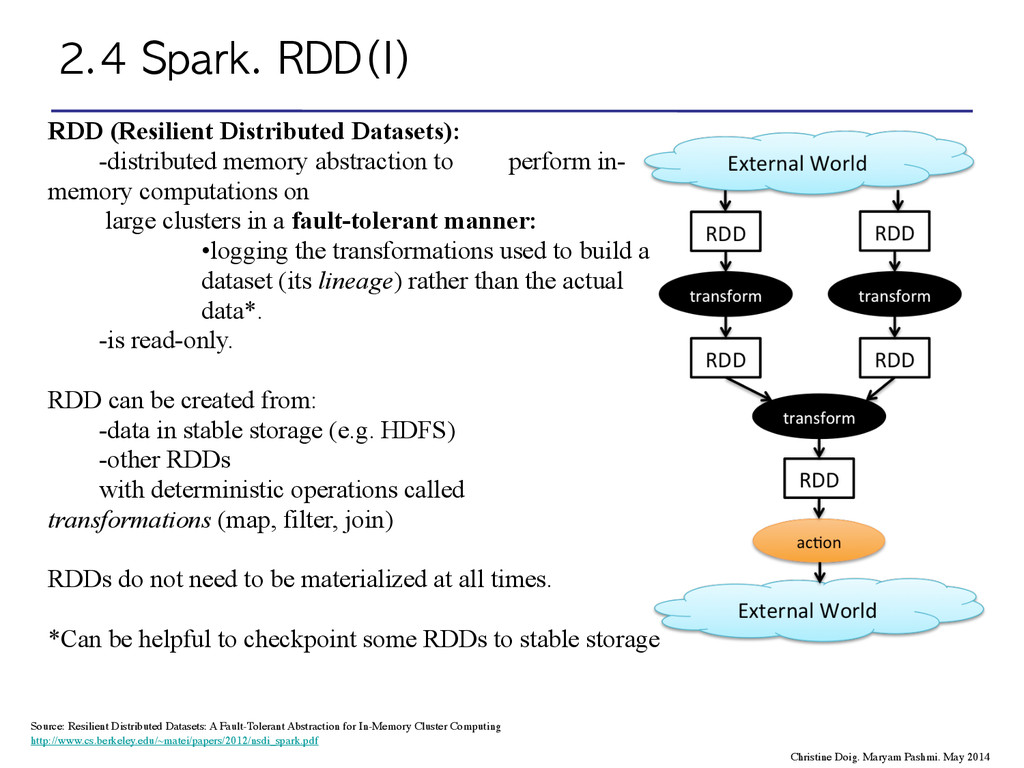
(Resilient Distributed Datasets): -distributed memory abstraction to perform in- memory computations on large clusters in a fault-tolerant manner: •logging the transformations used to build a dataset (its lineage) rather than the actual data*. -is read-only. RDD can be created from: -data in stable storage (e.g. HDFS) -other RDDs with deterministic operations called transformations (map, filter, join) ! RDDs do not need to be materialized at all times. ! *Can be helpful to checkpoint some RDDs to stable storage ! ! ! ! Source: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
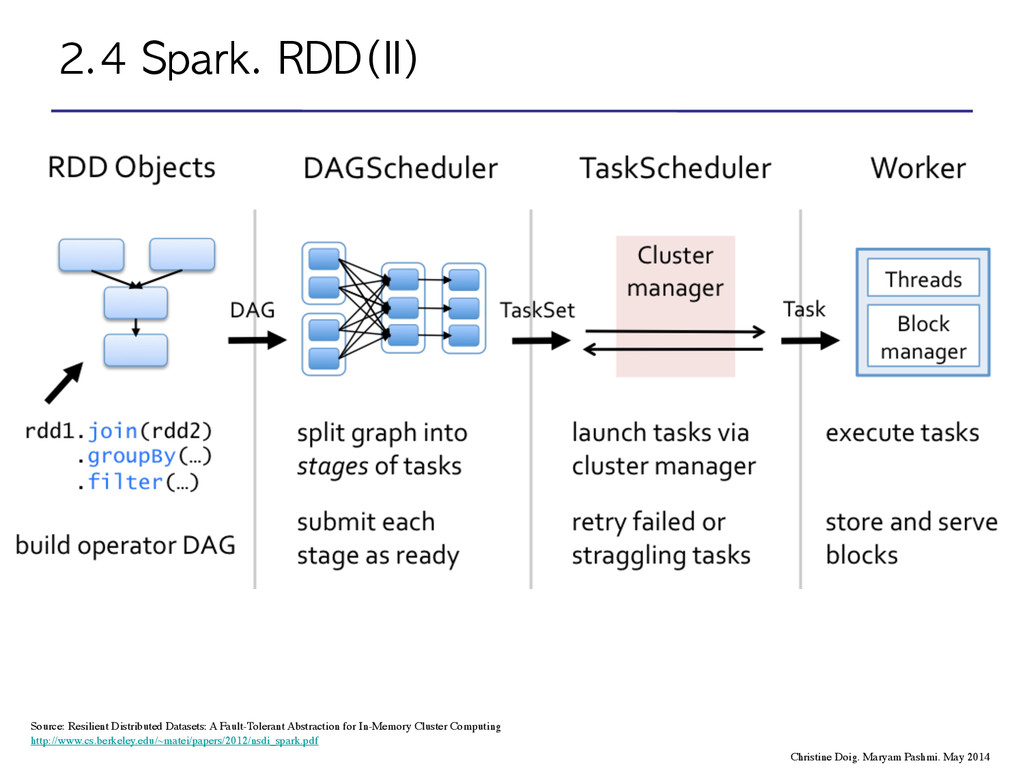
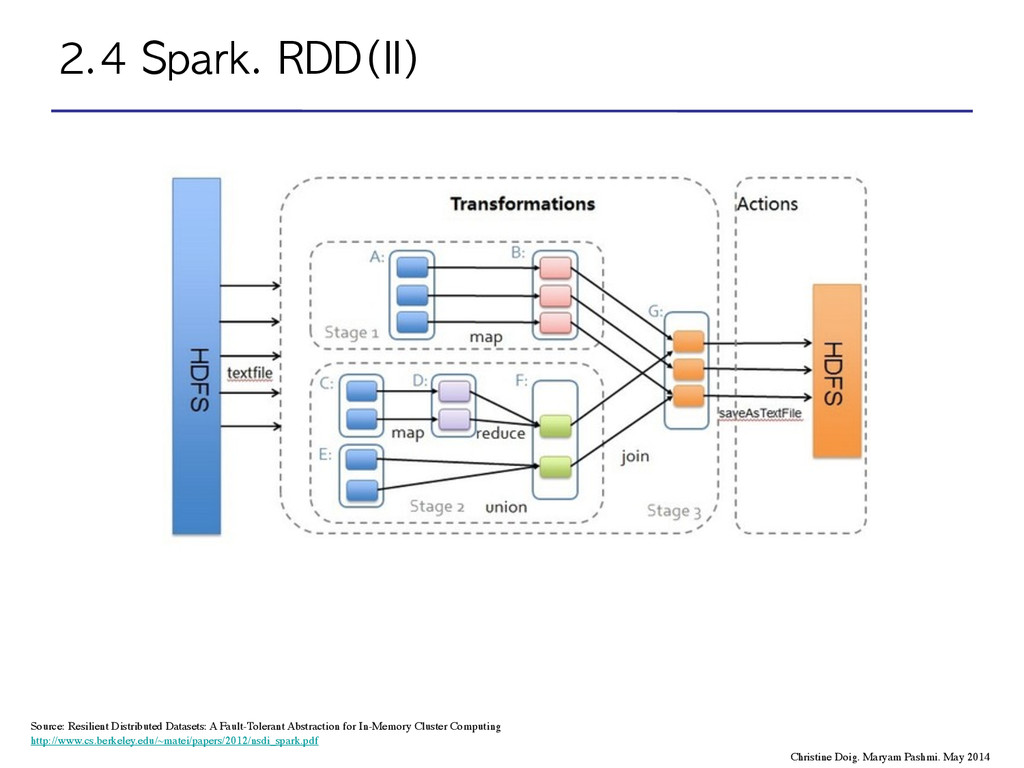
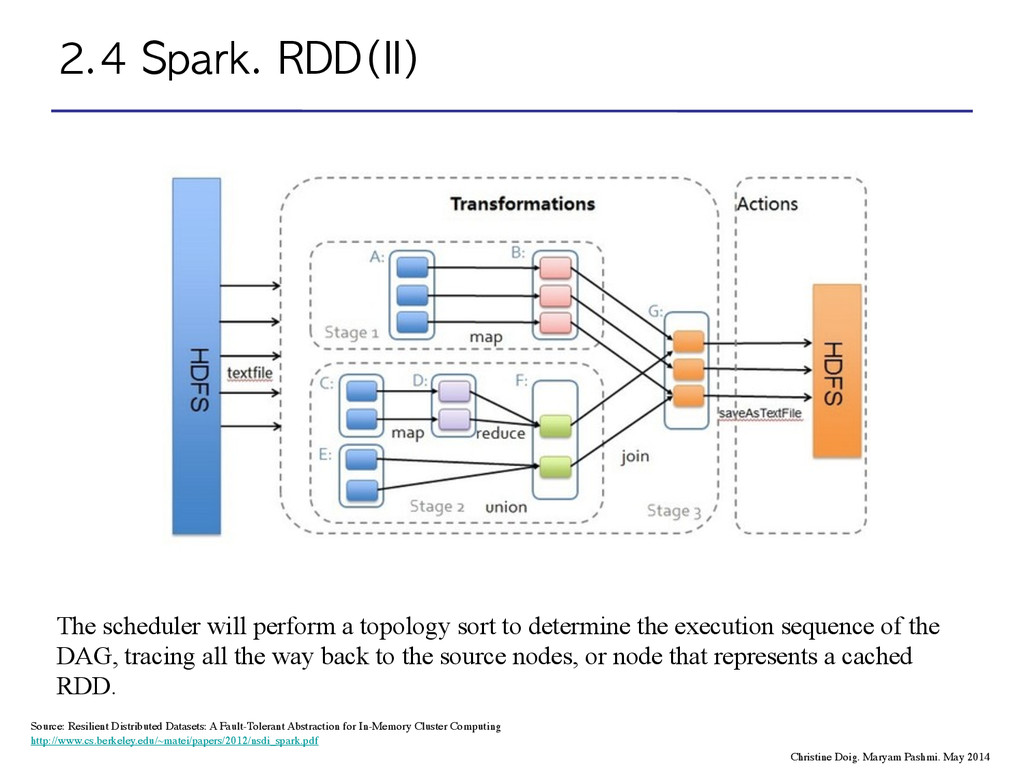
scheduler will perform a topology sort to determine the execution sequence of the DAG, tracing all the way back to the source nodes, or node that represents a cached RDD. Source: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
scheduler will perform a topology sort to determine the execution sequence of the DAG, tracing all the way back to the source nodes, or node that represents a cached RDD. Source: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
Why Spark is suitable for mining large data sets? ! -Iteration -Interactivity ! Many machine learning algorithms are iterative in nature because they run iterative optimization procedures. They can thus run much faster by keeping their data in memory. ! Spark supports two types of shared variables: •broadcast variables: cache a value in memory on all nodes. •accumulators: variables that are only “added” to, such as counters and sums. ! Users can control two other aspects of RDDs: • persistence: indicate which RDDs they will reuse and choose a storage strategy for them (e.g., in-memory storage). • partitioning: ask that an RDD’s elements be partitioned across machines based on a key in each record. Controlling how different RDD are co-partitioned (with the same keys) across machines can reduce inter-machine data shuffling within a cluster. ! !
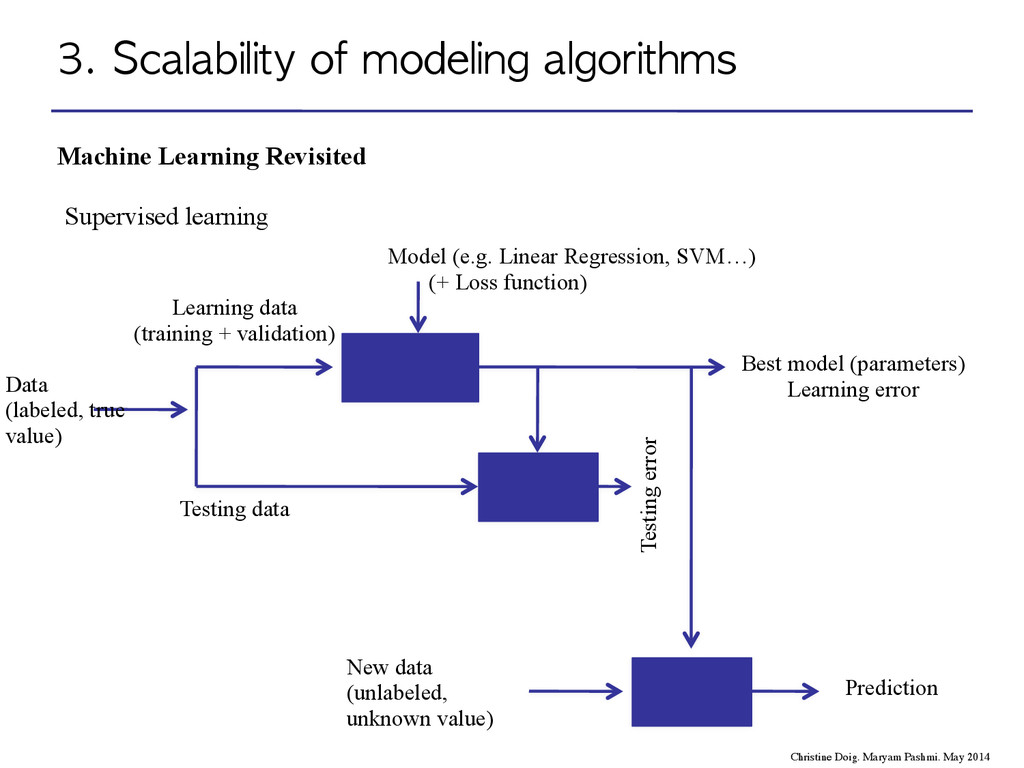
Maryam Pashmi. May 2014 Data (labeled, true value) Supervised learning Learning data (training + validation) Testing data Model (e.g. Linear Regression, SVM…) (+ Loss function) Best model (parameters) Learning error Testing error New data (unlabeled, unknown value) Prediction
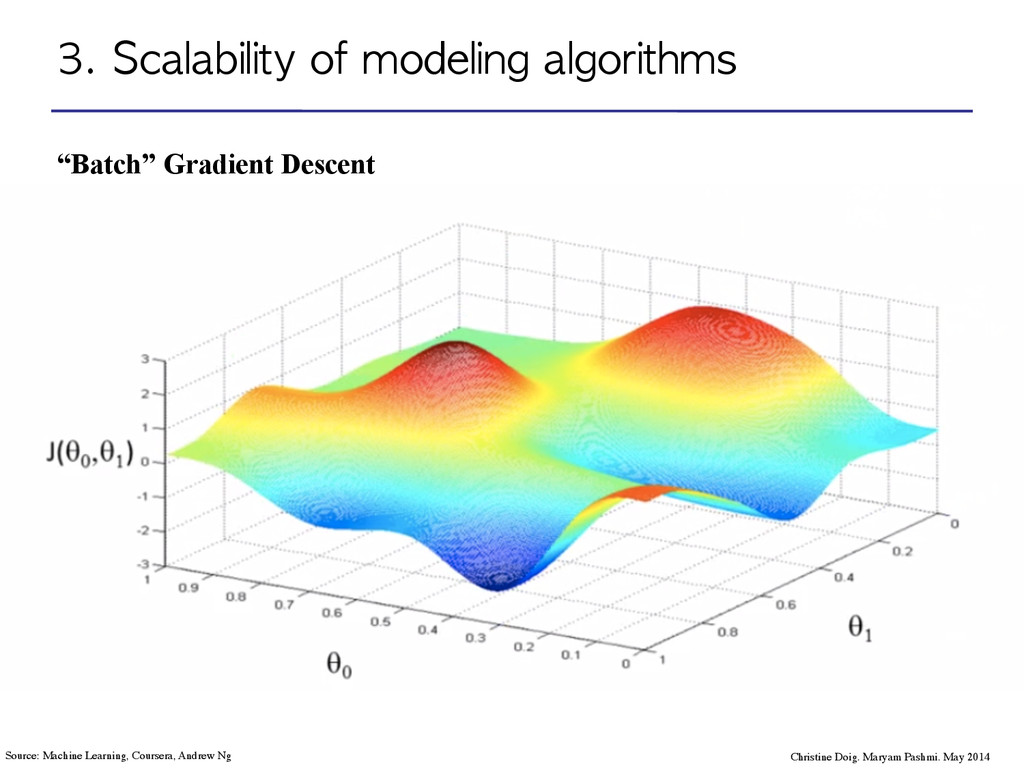
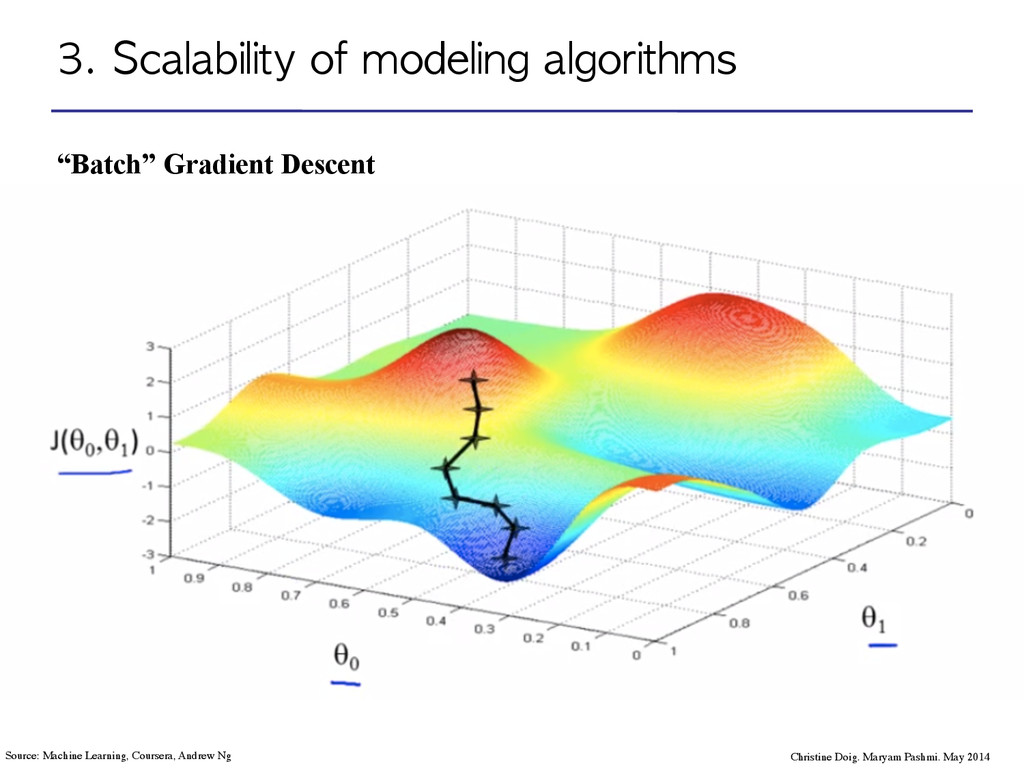
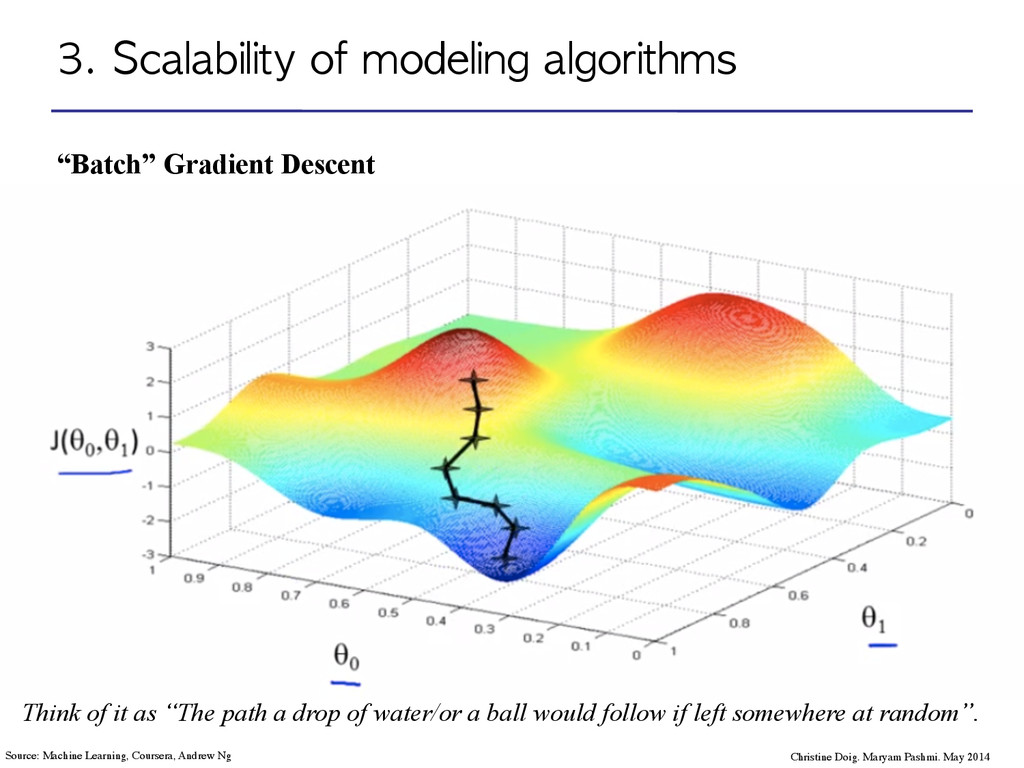
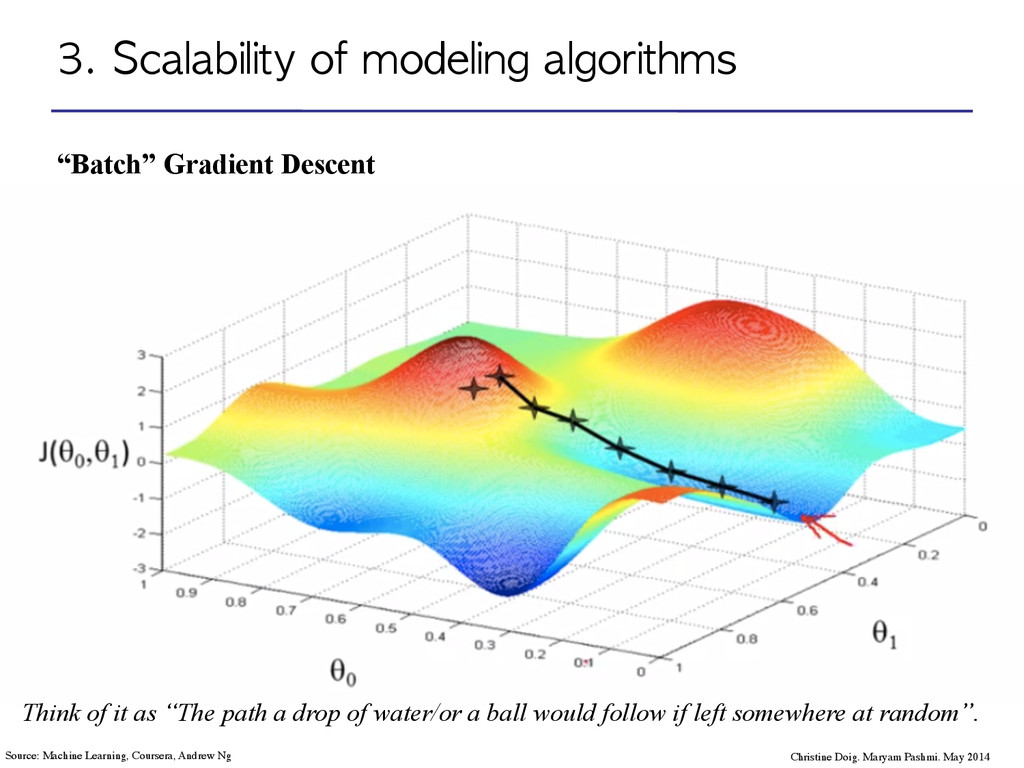
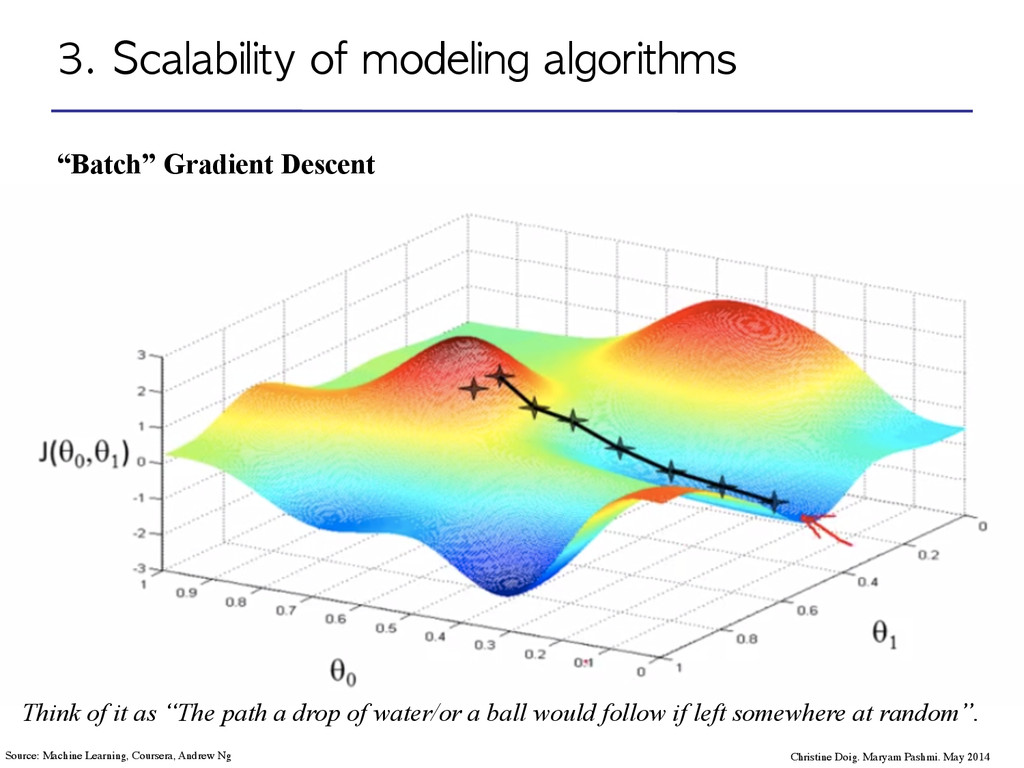
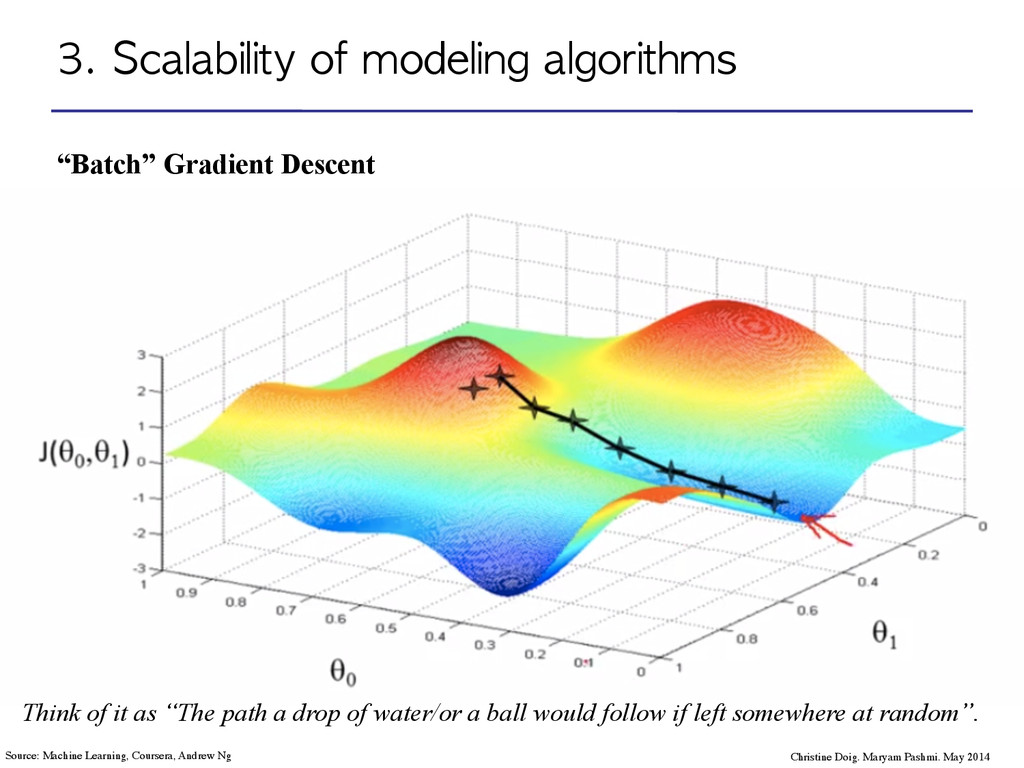
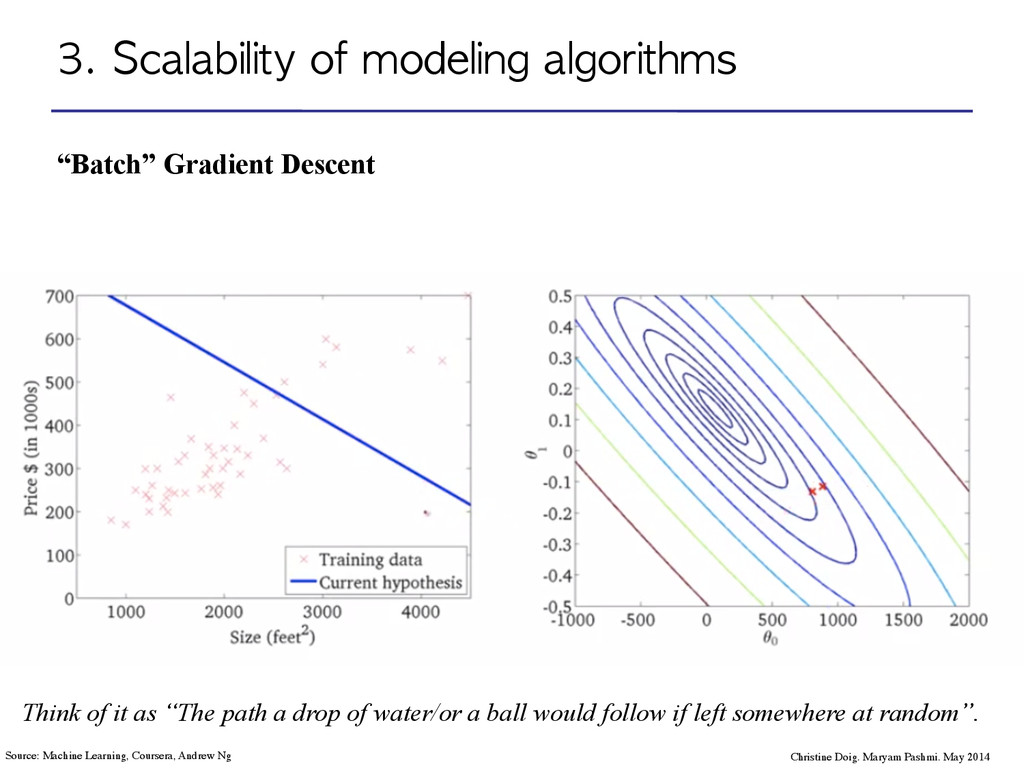
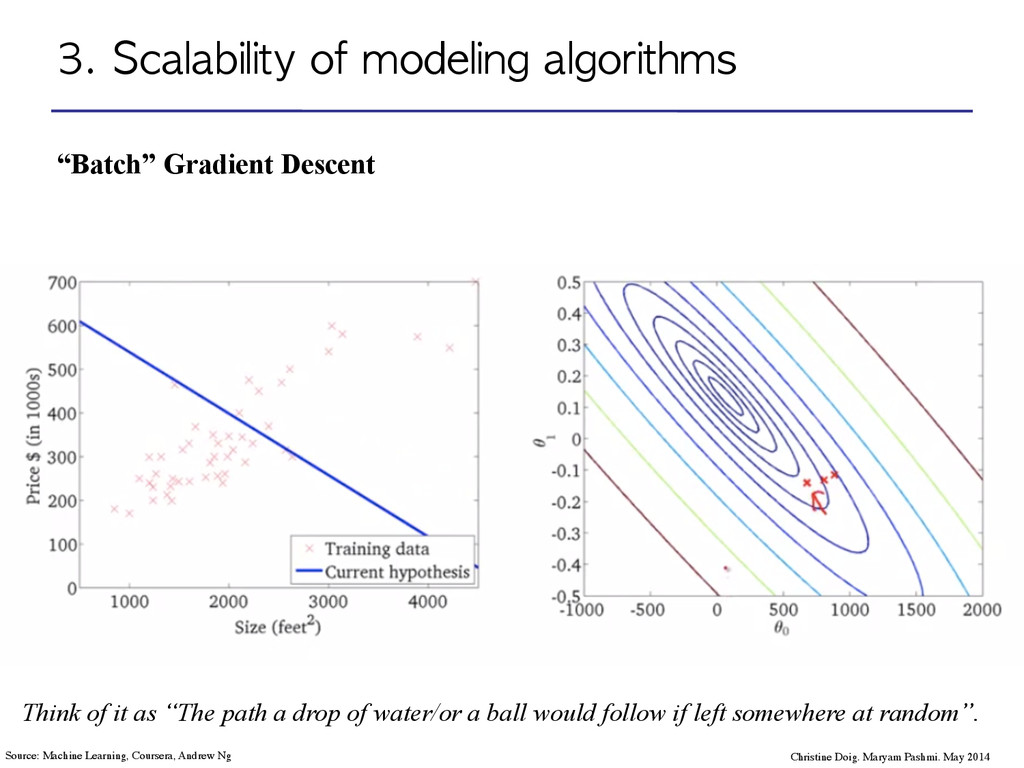
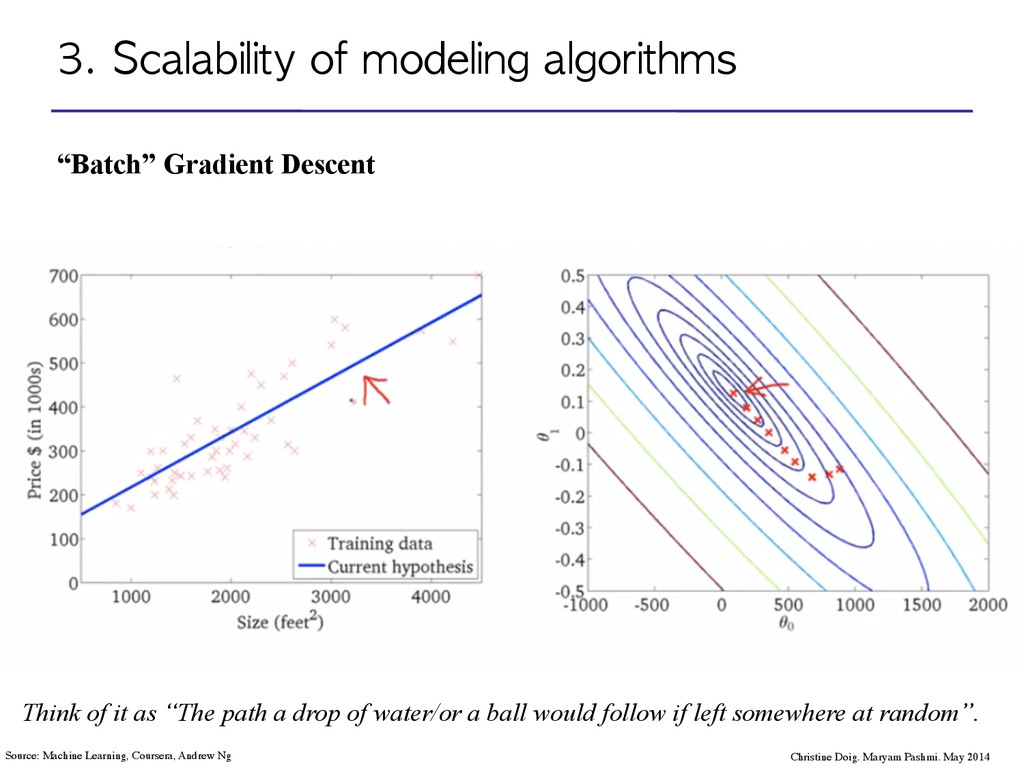
Maryam Pashmi. May 2014 Source: Machine Learning, Coursera, Andrew Ng Think of it as “The path a drop of water/or a ball would follow if left somewhere at random”.
Maryam Pashmi. May 2014 Source: Machine Learning, Coursera, Andrew Ng Think of it as “The path a drop of water/or a ball would follow if left somewhere at random”.
Maryam Pashmi. May 2014 Source: Machine Learning, Coursera, Andrew Ng Think of it as “The path a drop of water/or a ball would follow if left somewhere at random”.
Maryam Pashmi. May 2014 Source: Machine Learning, Coursera, Andrew Ng Think of it as “The path a drop of water/or a ball would follow if left somewhere at random”.
Maryam Pashmi. May 2014 Source: Machine Learning, Coursera, Andrew Ng Think of it as “The path a drop of water/or a ball would follow if left somewhere at random”.
Maryam Pashmi. May 2014 Source: Machine Learning, Coursera, Andrew Ng Think of it as “The path a drop of water/or a ball would follow if left somewhere at random”.
Maryam Pashmi. May 2014 Source: Machine Learning, Coursera, Andrew Ng Think of it as “The path a drop of water/or a ball would follow if left somewhere at random”.
Maryam Pashmi. May 2014 Source: Machine Learning, Coursera, Andrew Ng Think of it as “The path a drop of water/or a ball would follow if left somewhere at random”.
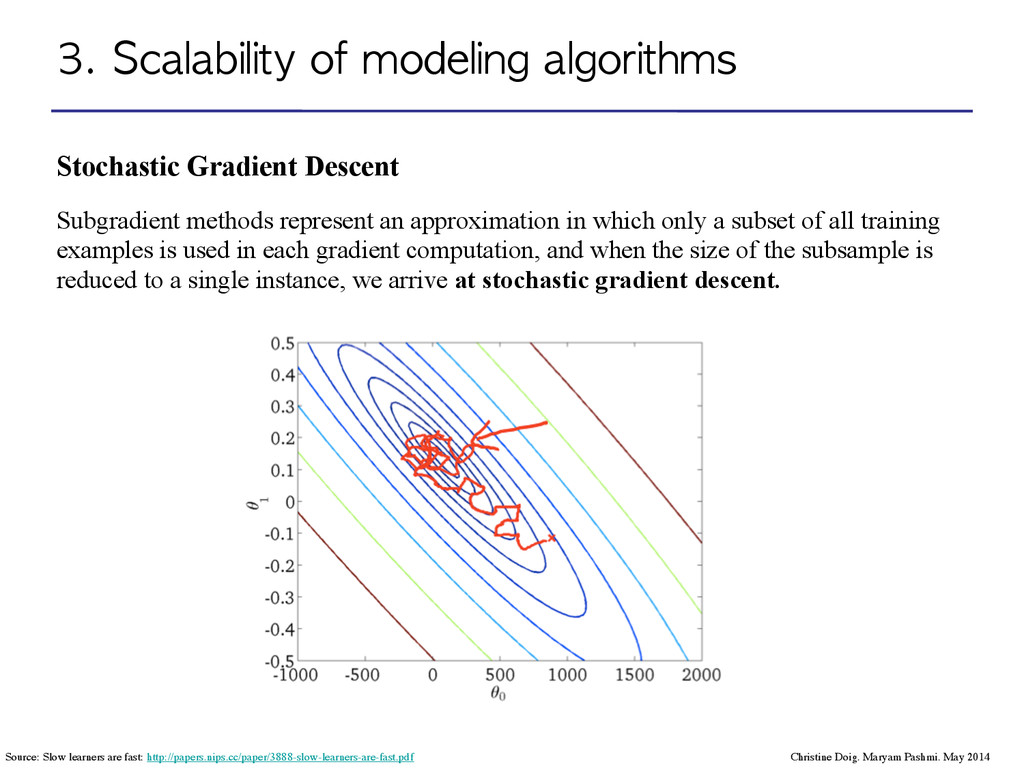
Maryam Pashmi. May 2014 Subgradient methods represent an approximation in which only a subset of all training examples is used in each gradient computation, and when the size of the subsample is reduced to a single instance, we arrive at stochastic gradient descent. Source: Slow learners are fast: http://papers.nips.cc/paper/3888-slow-learners-are-fast.pdf
Doig. Maryam Pashmi. May 2014 •“Stochastic” option: •Single machine performs stochastic gradient descent. •Several processing cores perform stochastic gradient descent independently of each other while sharing a common parameter vector which is updated asynchronously. ! •“Batch” option: linear function classes where parts of the function can be computed independently on several cores. Source: Slow learners are fast: http://papers.nips.cc/paper/3888-slow-learners-are-fast.pdf
•Mahout: Stochastic Gradient Decent ! •MLlib in Spark: Stochastic Gradient Decent ! •Voppal Wabbit: Variant of online gradient decent. Conjugate gradient (CG), mini- batch, and data-dependent learning rates, are included. ! •Jubatus: Loose model sharing. The key is to share only models rather than data between distributed servers. Iterative Parameter Mixture. •UPDATE •MIX •ANALYZE ! Christine Doig. Maryam Pashmi. May 2014 Jubatus: An Open Source Platform for Distributed Online Machine Learning. http://biglearn.org/2013/files/papers/biglearning2013_submission_24.pdf http://www.umiacs.umd.edu/~jimmylin/publications/Lin_Kolcz_SIGMOD2012.pdf
(Directed Acyclic Graph Scheduler) -Performance: Interactive results, Speed, in-memory -Building tools for different capabilities, hiding underlying processes: Importance of end users Open Source frameworks/libraries -Hadoop/MapReduce: Mining large datasets as a batch process -Cascading/Pattern: Building data applications that incorporate ML/Stats algorithms -MADLib: Bring the algorithms to the database. Familiarity SQL -Spark,/Mlbase: DAG, in-memory, optimization of model selection Scalability of modeling algorithms Different numerical optimization techniques for large datasets -Stochastic Gradient Descent -Subgradient or “mini-batch” Gradient Descent -Batch Gradient Descent Christine Doig. Maryam Pashmi. May 2014
Some online tutorials/exercises: R in Hadoop: http://hortonworks.com/hadoop-tutorial/using-rhadoop-to-predict-visitors-amount/ http://www.revolutionanalytics.com/sites/default/files/revoscalerdecisiontrees.pdf ! Tutorials for Cascading: http://www.cascading.org/documentation/tutorials/ ! Spark: A Data Science Case Study http://hortonworks.com/blog/spark-data-science-case-study/ ! Cascading Pattern to translate from R to Hadoop. Example: anti-fraud classifier used in e-commerce apps http://blog.cloudera.com/blog/2013/11/how-to-use-cascading-pattern-with-r-and-cdh/ ! Movie Recommendation with Scalding: http://blog.echen.me/2012/02/09/movie-recommendations-and-more-via-mapreduce-and- scalding/ ! Vowpal wabbit: http://zinkov.com/posts/2013-08-13-vowpal-tutorial/ !
•Python for Data Science: •IPython/IPython notebook •Numpy •Scipy •Pandas •Matplotlib •Scikit-learn •Orange •Mlpy •Numba •Blaze •Pytables ! ! Presentation at Pybcn: http://chdoig.github.io/pybcn-python4science/ ADM Paper: A Primer on Python for DM (ask me) Python vs R: http://inside-bigdata.com/2013/12/09/data- science-wars-python-vs-r/ http://www.kaggle.com/forums/t/5243/pros-and- cons-of-r-vs-python-sci-kit-learn
the following implementations by their performance (worst -> better) in mining a big data set (imagine 1TB of data). Why? ! Q2: Name three issues/problems in writing plain MapReduce in Java for DM/ ML algorithms. Why?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}