Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Claude Code と OpenAI o3 で メタデータ情報を作る
Search
laket
July 31, 2025
Programming
180
0
Share
Claude Code と OpenAI o3 で メタデータ情報を作る
BigQueryテーブルのdescriptionをLLMを用いて生成しました。
Coding Agentを使ったメタ情報生成の難しさやおもしろい点を共有します。
laket
July 31, 2025
Other Decks in Programming
See All in Programming
CursorとClaudeCodeとCodexとOpenCodeを実際に比較してみた
terisuke
1
480
AI-DLC Deep Dive
yuukiyo
9
4.6k
アーキテクチャモダナイゼーションとは何か
nwiizo
19
5.3k
Surviving Black Friday: 329 billion requests with Falcon!
ioquatix
0
710
AWSコミュニティ活動は顧客のクラウド推進に効くのか / Do AWS community activities help customers adopt the cloud?
seike460
PRO
0
150
10年分の技術的負債、完済へ ― Claude Code主導のAI駆動開発でスポーツブルを丸ごとリプレイスした話
takuya_houshima
0
2.6k
ハーネスエンジニアリングとは?
kinopeee
12
5.9k
実用!Hono RPC2026
yodaka
2
250
🦞OpenClaw works with AWS
licux
1
180
Vibe하게 만드는 Flutter GenUI App With ADK , 박제창, BWAI Incheon 2026
itsmedreamwalker
0
550
UIの境界線をデザインする | React Tokyo #15 メイントーク
sasagar
2
370
AI時代のPhpStorm最新事情 #phpcon_odawara
yusuke
0
190
Featured
See All Featured
Faster Mobile Websites
deanohume
310
31k
Building the Perfect Custom Keyboard
takai
2
730
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Context Engineering - Making Every Token Count
addyosmani
9
840
Art, The Web, and Tiny UX
lynnandtonic
304
21k
Docker and Python
trallard
47
3.8k
Tell your own story through comics
letsgokoyo
1
900
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
520
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
210
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Unsuck your backbone
ammeep
672
58k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
150
Transcript
© GO Inc. Claude Code と OpenAI o3 で メタデータ情報を作る
2025-07-31 老木 智章
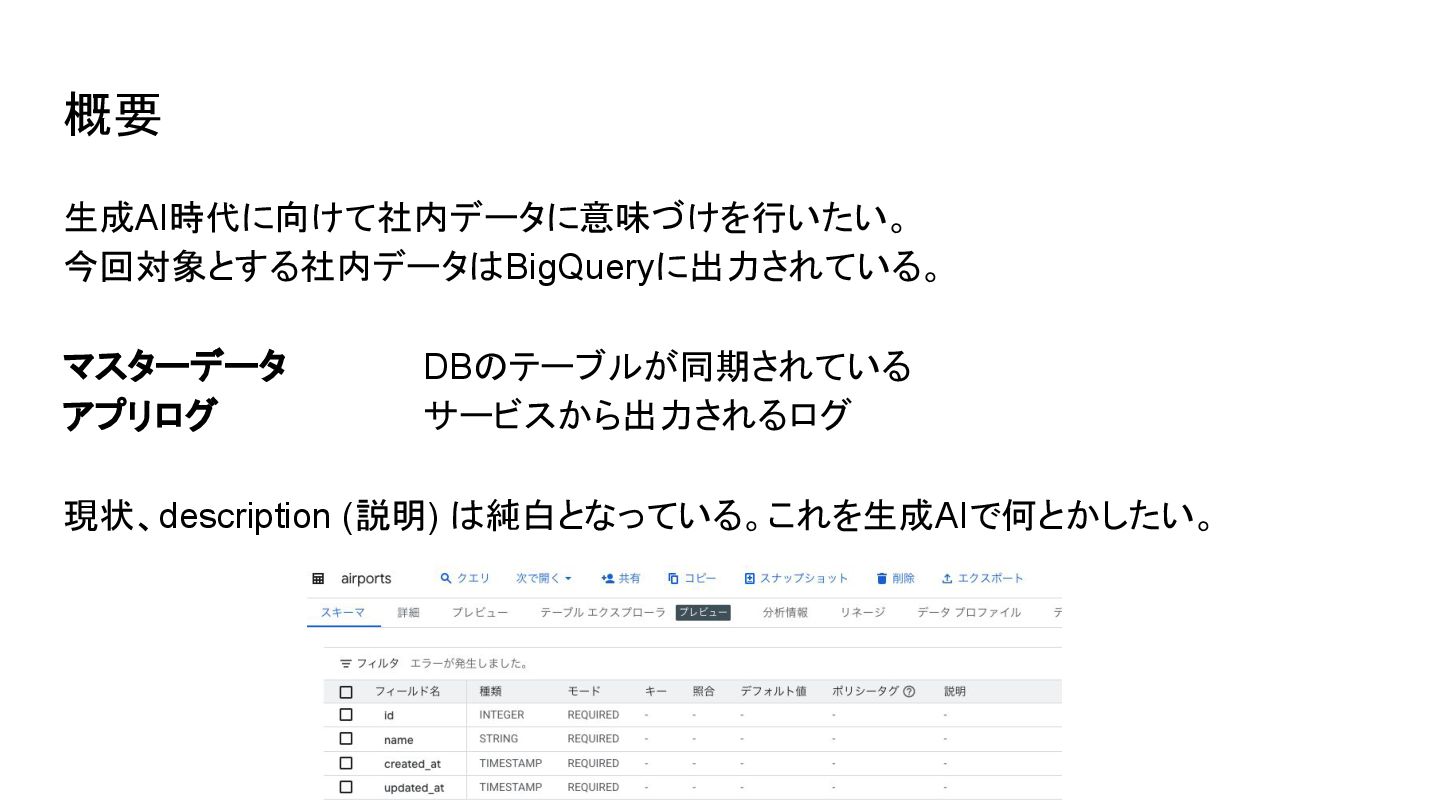
概要 生成AI時代に向けて社内データに意味づけを行いたい。 今回対象とする社内データはBigQueryに出力されている。 マスターデータ DBのテーブルが同期されている アプリログ サービスから出力されるログ 現状、description (説明) は純白となっている。これを生成AIで何とかしたい。
目次 • メタデータの生成戦略 • Open AI o3 でのマスターデータのメタデータ生成 • Claude
Code でのアプリログのメタデータ生成 • Claude Code エンジニアリング失敗集
発表者 Background 名前 老木 智章 職種 データアナリスト ブームの変遷 • BigQuery
のクエリ最適化 • ちょっと前まで streamlit が熱かった • 最近は Claude Code が熱い 最近の業績 • 調律の魔物撃破 (ナイトレイン) • Slay the Spire プレイ時間が990時間に到達
メタデータの生成戦略 テーブルの各列の意味はさまざまな情報源から推測できる。 • そのテーブルを利用した SQL • そのテーブルを分析している jupyter notebook •
データを生成しているソースコード ◦ マスターデータであれば、 DBを扱っているソースコード ◦ アプリログであればログを生成しているソースコード 今回は、情報の網羅性が高いソースコードからの生成を試みた。 (SQLからの生成であれば、不人気テーブルはSQLが少なく精度が下がりそう)
© GO Inc. Open AI o3での マスターデータのメタデータ生成
問い合わせ型のLLMでメタデータを作る まずは、簡単なマスターデータに対するメタデータ生成を行う。 Golang で書かれたサービスが利用しているテーブル群が、 BigQuery にエクスポートされており、分析で利用されている。 この分析での課題として、 • description がないため列の意味がわからない
• 格納されている値の意味がわからない (status = 2 とは?) があった。 サービスのソースコードから、このマスターデータのメタデータを生成する。
生成したメタデータ 生成したメタデータは対人間比で • 記載が丁寧。文章が長い • 格納された値の意味を記載可能 というメリットがあった。 正確性も高く、非常にうまくいっている。 なお、[ai]タグをつけて AI
による生成と明記して、 利用者に注意を促している。 { "table_name": "ways", "description": "[ai]道路情報を格納しています ", "source_file": "ways.go", "columns": [ { "name": "way_type", "description": "[ai]道の大分類を表す, "enums": { "0": "狭路", "1": "交差点" } … 出力イメージ
LLM に与えるソースコード 今回のサービスはテーブルに対応したモデルクラスと、 そのモデルクラスへの操作をまとめた.goファイルがある。 この go ファイルをルールベースで探してきて LLM の入力に用いた。 ルール例
• テーブル名と対応するファイル名 ( ways というテーブルなら way.go) • 対応する構造体定義が含まれるファイル ( type Way) • 単語の区切りの複数形を単数系にする (ways_histories => type WayHistory) ほとんどのケースで、テーブルに対応する.goファイルを発見できた。
ソースコードに含まれる内容 ソースコードにはテーブルに対応する構造体や、 列に格納される列挙型の定義が含まれている。 これにより格納されている値の意味が抽出できる。 const ( WayTypeNone WayType = iota
// empty WayTypeNarrow // 狭路 WayTypeCross // 交差点 // waysテーブルに対応するモデルクラス type Way struct { WayID uint WayType WayType // 道路種別
プロンプト例 OpenAIのo3-miniにプロンプトを投げている。 プロンプトは Claude Code が生成したものを少しだけ修正して利用。 以下のGoコードを解析して、{table_name}テーブルの情報を抽出してください。 ```go {見つけたソースコード} ```
{テーブルのスキーマ情報} 以下の情報を抽出してください: 1. テーブル全体の説明(table_description): テーブルの目的や役割を日本語で説明 2. 各列の情報(columns): 構造体のフィールド名とjsonタグを参考に、各列の意味を日本語で推測 "role": "system", あなたはGoコードを解析してデータベーステーブルの列情報を抽出する専門家です。
structured output o3-miniに、JSONのスキーマを指定して、型通りに返すことを強制している。 Claude Codeが勧めてきたが、本当に必要なのかは未検証。
細かいエンジニアリング メタデータ生成プログラムは、仕様書を作り Claude Code で生成させている。 おおむね、うまく動作しているが微調整は加えている。 主要な変更 • テーブルスキーマを入力に含めた。当初は構造体定義から列名を抽出できると考 えていたが、動作しないケースがあったため外部から与えた。
• 英語で出すなと追加で念押しした (無視されたので)
パフォーマンス Azure OpenAI Service の o3-mini を利用した。 1テーブルのメタデータを生成するのに20-30秒。 1テーブルの出力に必要な費用は$0.02 程度。
(入力トークン5000, 出力トークン4000) ただし、時たま API がなかなかレスポンスを返さないことがあった。 参考: o3-miniの価格表
まとめ マスターデータのメタデータ生成 高速に高品質のメタデータが生成できて満足している。 人手では困難であった細かい補足情報も付与できている。 発展系としては、 • モデルクラス以外のソースコードも読ませる • 他の補足情報も出力させる (関連ページへのリンクなど) が考えられる。
が、現状動作に満足しているため、あまり課題感がない。
© GO Inc. Claude Code での アプリログのメタデータ生成
アプリログのメタデータ生成の難しさ マスターデータは関連ソースコードが明確だった。 一方、アプリログは • 複数の経路から同じテーブルに出力される • 出力されるフィールドの明確な定義がない (モデルクラスがない) • 出力される列挙型が定数化されていない
(文字列が直接かかれている) といった特徴がある。関連処理・ソースコードの抽出がはるかに難しい。 アプリログ出力までのステップ 1. column_value = func_column(hoge) # 出力フィールドがどこかの関数で計算される 2. payload[“message”] = column_value # 辞書にフィールドが格納される 3. publishLog(“output_table1”, payload) # output_table1 に辞書が出力される 1-3の処理が複数の場所で行われ、同じテーブルに出ることがある。 (iOSログインとandroidログインなど)
アプリログのメタデータ生成戦略 (RAG 戦略) 生成 AI にどのようなソースを渡すかは、さまざまな戦略が考えられる。 関連しそうなソースコードを大量に渡す 簡単なルールで数十ファイルぐらいひっぱってきてLLMに渡す。 関連ソースコード抽出ルールを作り込む ドメイン知識を使い、grepを駆使して関連ソースコードを抽出する。
ベクトル検索エンジンにソースコードをいれて検索する 近い領域のソースコードをひっぱってきてLLMに渡す。(grepに負けそう) Coding Agent に関連ソースコードを探索させる Claude Code はコーディング時に関連するソースコードを都度探索している。 同様にメタデータ生成に必要となるソースコードを探索してもらう。
非対話モードの Claude Code Claude Code の標準的な使い方は、コンソールで人間と対話しながら作業する。 しかし、アプリログのテーブルは大量にあるので、人間なしにメタデータを生成したい。 そこで、Claude Code SDK
を使って、pythonから Claude Codeを呼び出した。 ※ なお、Claude Code SDK の実態はclaudeコマンドをsubprocessで呼び出している (2025/07/17 現在) for await (const message of query({ prompt: "foo.pyについての俳句を書いて ", options: { maxTurns: 3, }, })) { messages.push(message); }
対話モードでの初期検証 非対話モードの前に対話モードでメタデータを生成できるか検証。 => まあいけそう ついでに、Claude Codeに「効率のいい調査方法を記述して」と依頼。 => 特定のテーブルに特化した調査方法を出してきていまいち Claude
Codeの提案した調査方法を大幅に修正して、 非対話モードで生成してみることにした。
初期のCLAUDE.md (省略版) ログのdescriptionを生成します。 ログを出力しているソースコードを解析し、フィールドの意味を明らかにします。 # ログの仕組み ログのテーブル名は、 xxx.goに定数で定義されています。以下は定義例です。 … このイベント名を用いて、
PublishLog関数を用いて複数箇所からログが出力されています。 ``` handler.PublishLog(r, log) ``` このlogに値を格納している処理を見つけ出し、値の意味を調べます。 # 効率的な調査手順 ## 1. ログ出力箇所の特定 イベントIDでgrepして、PublishLog関数の呼び出し箇所を特定する …
非対話モードでの動作の様子 --dangerously-skip-permissionsのように、独り言を言いながら作業を進めている。 "AssistantMessage": "テーブル`xxx`の分析を開始します。まず、ログ出力関数を確認します ”, "AssistantMessage": { "name": "Grep", "input":
{ "pattern": "make_request", "path": "xxxx.go", }, "UserMessage": { "type": "tool_result", "content": "49:\tmake_request = …""
戦いの目次 非対話モードでの検証を開始したが、満足のいく性能が出なかった。 • 初期の非対話モードの失敗 • 失敗の原因を探る • 失敗のパターン • 細かいエンジニアリング
初期の非対話モードの失敗 非対話モードで検証のために、何度も同じテーブルの解析を行うと課題が明らかになっ た。とにかく結果がばらつく。 1. 同じテーブルを処理しても料金が $0.4 - $2.4 でばらつく 2.
当然実行時間もばらつく 3. 処理結果のクオリティが大きくばらつく a. enumsが出力されないことが多い b. 料金が高いとうまくいくわけではない "columns": [ { "name": "way_type", "description": "[ai]道の大分類を表す, "enums": { "0": "狭路", "1": "交差点" } …
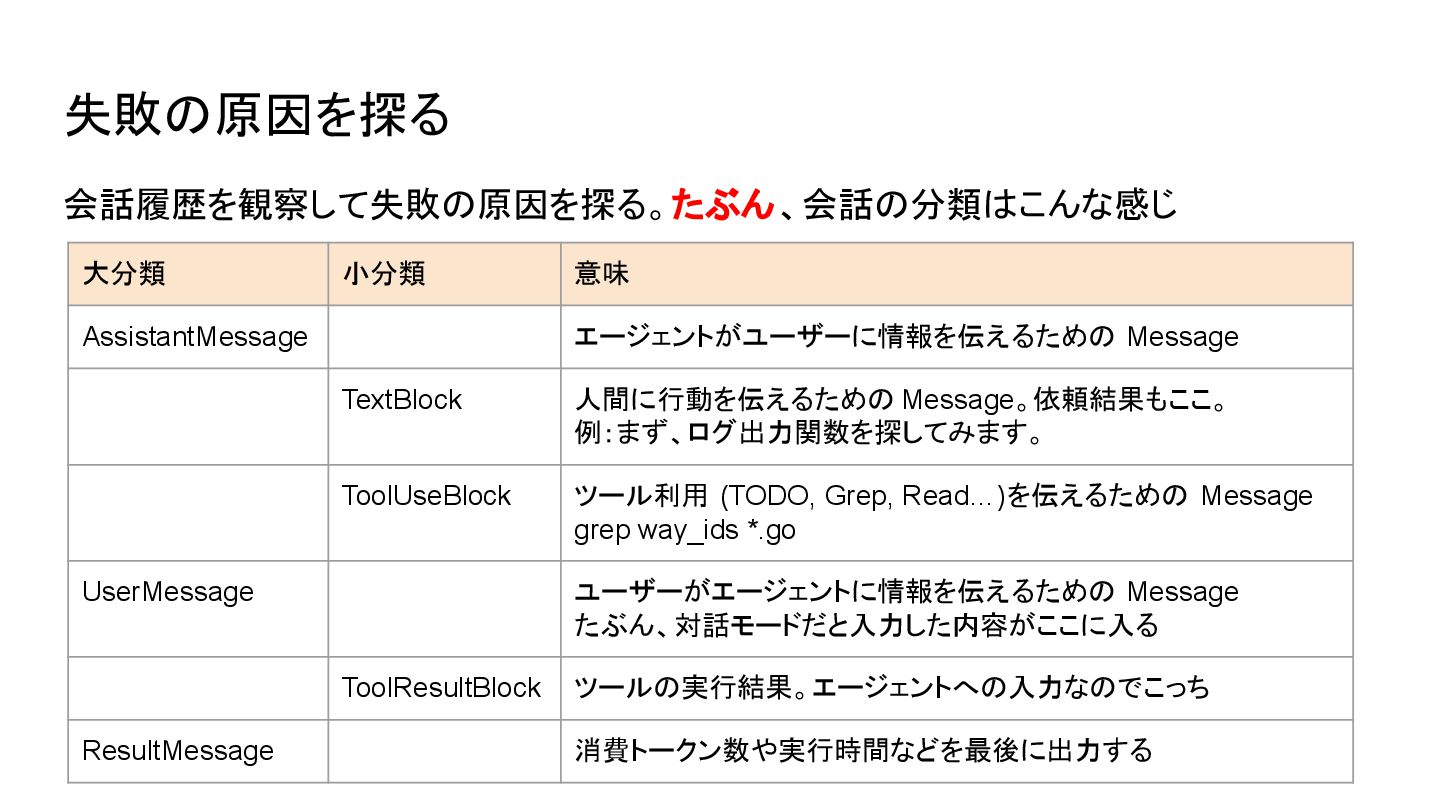
失敗の原因を探る 会話履歴を観察して失敗の原因を探る。たぶん、会話の分類はこんな感じ 大分類 小分類 意味 AssistantMessage エージェントがユーザーに情報を伝えるための Message TextBlock 人間に行動を伝えるための
Message。依頼結果もここ。 例:まず、ログ出力関数を探してみます。 ToolUseBlock ツール利用 (TODO, Grep, Read…)を伝えるための Message grep way_ids *.go UserMessage ユーザーがエージェントに情報を伝えるための Message たぶん、対話モードだと入力した内容がここに入る ToolResultBlock ツールの実行結果。エージェントへの入力なのでこっち ResultMessage 消費トークン数や実行時間などを最後に出力する
会話履歴から明らかになった失敗のパターン 指示のケアレスミス • 指示が間違っており、存在しないパスを探している • 権限設定が間違っており、ツールが使えていない タスクに Claude Code が適応できていない
• メタデータ生成に不要な詳細を把握しようとしている • 不必要に広い範囲を読もうとしている • Grepの使い方がおかしい
指示のケアレスミス (影響:小) 例えば、CLAUDE.mdに、api/handler.go を読めと書いてあったのだが、 実際は、src/api/handler.go で Claude Code が困惑していた。 他のパスを試したりして気合いで見つけていた。
また、ripgrep を使うように指示していたが、実行権限が足りずに断念していた。 Grep等を代わりに使って気合いでなんとかしていた。 指示が間違っていても Claude Code が根性でなんとか結果を出してしまう ため、詳細確認まではミスに気づけなかった。
不要な詳細を把握しようとしている (影響:中) 時折、Claude Code が不要な詳細を調査していた。 プロンプトではメタデータ生成対象の列を明示的に指定していたが、 同じテーブルに含まれる生成対象でない列の詳細を確認しようとしていた。 (例:テーブルにデータを追加した時刻) そこで生成対象でない列は調査しないように明確に指示を出した。 十分に賢ければ不要な指示だが、Claude
Code がその域に達していなかった。 テーブルの各列は、全テーブルに共通の列と、各テーブルに固有の列に分けられます。 各テーブルに固有の列は、 golangソースコード上ではxxxという変数に格納されます。 descriptionを生成したいのは、固有の列のみです。
不必要に広い範囲を読もうとしている (影響:大) 人間が今回のタスクに挑む場合、各ファイルの必要箇所を順番に読んでいく。 1. PublishLog(payload) payloadが出力されるのか 2. payload["reason"] = reason
reasonというフィールドがあるのか 3. reason = “something” reasonにはsomethingが入るのか 一方、Claude Code は、payloadが含まれるファイルを頭から読んでいた。 "ToolUseBlock(id='toolu_xxx', name='Read', input={'file_path': 'log.go'})" これを指示で抑止したところ、コストが低下し、出力の品質が向上した 。 ファイルを読み込む際は、必要な場所だけ読むことを心がけてください。 Readする場合は、**必ず**offsetやlimitを使って、読む範囲を限定してください。
コンテキストエンジニアリング Claude Code は入力として、 • プロンプト • ツールから得られた情報 (ファイル読み込み等含む) •
同一セッションでのこれまでの自身の出力 を受け取っている。この入力を質のいいものにしていきましょうね、というのがコンテキス トエンジニアリングと呼ばれる(と理解している)。 「不必要に広い範囲を読もうとしている」では、コンテキストに雑多な情報が乗ってしまっ ていたのが、出力品質を下げていたと思われる。
Grep の使い方がおかしい (影響: 大) Readの範囲指定でファイルの行数を超える行を指定してエラーが出ていた。 Warning: the file exists but
the contents are empty. これは、Grep の直後のReadで頻発していた。Grep して見つかった行の周辺を読む時 に、適当な範囲を指定する蛮行を繰り返していた 。アホすぎる。 Grepで必ず行番号を出力するように指示すると解消した。 Grepは、**常に**-nを使って、行番号を表示して利用してください。 Grepは特定のファイルを検索すると きはglobではなく、pathを利用してください。
総評と結果 $0.4 - $2.4 でばらついていたコストが $0.2 - $0.4 程度のばらつきとなり、 出力品質の安定性も大きく向上した。
改修するたびに3回以上実行して観察しているが、ばらつきが大きいため微妙な改善の 場合は、効果に確信が持てないのが難しい。 (試行回数を増やしたかったが、従量課金で心に負荷がかかって無理だった) Claude Code の賢さには日々驚かされているが、現段階では 人間が明らかに嵌まらな い穴に嵌っている。特に非対話モードではその欠点が顕著になる 。 不要な処理はコスト向上だけでなく出力品質の低下も招いており、簡単に修正できる点 は修正できる価値がある。
生成したメタデータ マスターデータのメタデータと同様に • 記載が丁寧。文章が長い • 格納された値の意味を記載可能 というメリットがあった。 さらにソースコードのコメントから、関連ページへの URLを抽出している。 自動生成のためdescription以外のさまざまな情報
を付与できる可能性がある。 "name": "request_type", "description": "[ai]リクエストの種別", "enums": { "0": "高速配車", "1": "路線からの配車", … }, "urls": { "リクエスト種別詳細": "https://atlassian.net/tekitou/pages/38" } }, 出力イメージ
パフォーマンス 1テーブルの処理に2-7分かかる。コストは、$0.1 - $1.0 程度かかる。 コストがかかるテーブルは、 • 列数が多い • 関連するファイルが多い
• イレギュラーな処理の流れでログを出力している といった特徴があった。 イレギュラーな処理の流れでは、Claude Code に教えたログ出力方法と、異なる手段で ログを出力していたが、気合いでメタデータを生成 しており、 Coding Agent を使うメリットが感じられた。
まとめ アプリログのメタデータ生成 多くのテーブルに対して情報量が多いメタデータを自動的に生成できた。 非対話モードを利用する際は、一度ログを見てみるのは有用である。 たとえ動作しているように見えても、意図せぬ動作をしており、出力品質を落としている 可能性がある。 Claude Code の出力のぶれは大きいため、ある試みが一度うまくいったからといって、 その試みが正しかったとは限らない。(本稿の実験も不十分である) 繰り返しの実験とともに、ある程度は原理にもとずく判断をすべきだろう。
© GO Inc. Claude Code エンジニアリング失敗集
Claude Code のコスト構造 上述の最適化後の Claude Code のコストは典型的には以下のようになっている。 キャッシュ付入力トークン 42152 x
$3.75 (per 100M) = $0.158 キャッシュからの入力 1474714 x $0.3 (per 100M) = $0.442 出力トークン 14253 x $15 (per 100M) = $0.214 キャッシュ付入力トークンには、プロンプトの他に、ツールで読み取ったファイルの内容 なども含まれる。 APIはステートレスであり、各呼び出しでセッション中のこれまでの会話履歴をすべて送 信している。それが、「キャッシュからの入力」を押し上げている。 上記の例では、キャッシュ付入力トークンとキャッシュからの入力の比から、同じ内容が 平均35回程度送られているのがわかる。 参考:プロンプトキャッシング
試行錯誤集 コスト構造を踏まえてさまざまな試行錯誤を実施した。 • TODOを出力させない ◦ 都度、TODOを出力していたが会話ターン数が増えるため切った ◦ 3回計測で20%程度コストが低下したが、この程度だと効果ありか確信はもてない • 逆にTODOのステップを細かくさせる
◦ 一列の調査ごとにTODOの1タスクとした ◦ 会話のターン数が増えてコストが増加したためやめた • 単一セッションで複数テーブルを処理する • 子エージェントに各列の調査を実施させる お馴染みのTODO
単一セッションで複数ファイルを処理する ここまでは、1セッションで1つのテーブルを処理していた。 しかし、テーブル間で参照ソースコードが近かったり、あるテーブル調査の知見が他の テーブルで活かせれば、単一セッションで複数テーブル解析のメリットがでてくることが 期待できる。 3つの戦略が考えられる。 1. それぞれのテーブルを独立したセッションで処理する (従来) 2.
一つのセッションで各テーブルを順番に処理する 3. 最初に複数テーブル分の指示を Claude Code に出す
単一セッションで複数ファイルを処理する (結果) セッションで最初のテーブルを処理、次にそのセッションを再開(resume)し、 再開したセッションで次のテーブルを処理、を繰り返した。 結果、キャッシュ作成料金が嵩んでしまった。 例えば、5テーブル目の処理ではキャッシュ付入力料金が3倍以上になった。 キャッシュ付入力トークン 142118 x $3.75
(per 100M) = $0.533 キャッシュからの入力 912357 x $0.3 (per 100M) = $0.274 セッション再開時に、キャッシュに会話履歴を乗せ直しているっぽい。 実装で解決できる可能性もあるが、未検証。
子エージェントに各列の調査を実施させる テーブルのメタデータ生成は、 1. テーブル共通の情報の探査 (どこで出力されているか、テーブル説明など) 2. 各列固有の情報の探査 の2段階にわかれる。 列Aの情報は列Bには不要なため、列A =>
列Bと同一セッション内で処理すると、列Bの 処理時に列Aに関する会話が何度もAPIに送信されてしまう。 => 列Bのみを行うセッションを用意すれば、余計な情報は送らなくなるため、コストは下 がるし、品質も上がるのでは?
子エージェントに各列の調査を実施させる (結果) びっくりするほどコストが上昇したため辞めた。 おそらく、単一エージェントではある列の調査の過程で、ついでに他の列も調査できてい た効果がなくなってしまうためと思われる。 # field_Aの調査をしている過程で、自然と field_Bの調査もできる payload[“field_A”] =
valueA payload[“field_B”] = valueB 複数テーブルは1セッションでまとめて調査すると効率が悪く、 複数列は1セッションでまとめて調査した方が効率が良い、という結果。 おそらく、列をうまくグルーピングすると、効率のいいセッションの切り方が出てくると思う が、労力をかけるほどの価値はなさそう。
その他の考えられる発展 調査効率を向上させる • GrepではなくMCPを使って、関係のあるコードの取得を行う ◦ Grepでは名前が被る余計なものをひっかけてきて、たまに判断を誤っている ◦ MCPでLSPサーバーと連携して参照箇所を正確にとりたい ◦ gopls
の MCPサーバーが時々クラッシュするため、 serenaを試すか・・・? メタデータの品質を向上させる • 列のとりうる値のリストを外部から与える ◦ スキーマを与えたように enumsも外部から与える ◦ 精度は間違いなく向上する • 関連する設計ドキュメントを与える ◦ 人間のコメントをヒントとして与えたのと同様の改善 ◦ 社内用語との紐付けが改善する可能性が高い "name": "way_type", "enums": { "0": "狭路", "1": "交差点" ….
まとめ Claude Code エンジニアリング 失敗集 Claude Code を使うにも色々と工夫の余地があって楽しい。 動作ログを見ると Claude
Code の気持ちになれるため、 Claude Code のログを見やすい形で管理するのが重要と考えている。 Claude Code は定額プランで使うべきだと思うが、 従量課金で使うと動作効率に意識が集中して、細かい効率にアプローチできた。 細かい効率にアプローチしたくないので定額プランで使うべきだと思う。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![生成したメタデータ 生成したメタデータは対人間比で • 記載が丁寧。文章が長い • 格納された値の意味を記載可能 というメリットがあった。 正確性も高く、非常にうまくいっている。 なお、[ai]タグをつけて AI](https://files.speakerdeck.com/presentations/de79cea8953b40b6b1b776b7763e1160/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![不必要に広い範囲を読もうとしている (影響:大) 人間が今回のタスクに挑む場合、各ファイルの必要箇所を順番に読んでいく。 1. PublishLog(payload) payloadが出力されるのか 2. payload["reason"] = reason](https://files.speakerdeck.com/presentations/de79cea8953b40b6b1b776b7763e1160/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![子エージェントに各列の調査を実施させる (結果) びっくりするほどコストが上昇したため辞めた。 おそらく、単一エージェントではある列の調査の過程で、ついでに他の列も調査できてい た効果がなくなってしまうためと思われる。 # field_Aの調査をしている過程で、自然と field_Bの調査もできる payload[“field_A”] =](https://files.speakerdeck.com/presentations/de79cea8953b40b6b1b776b7763e1160/slide_41.jpg){kind=link}
{kind=link}
{kind=link}