Continuum Analytics, where she worked on MEMEX, a DARPA- funded project helping stop human trafficking. She has 5+ years of experience in analytics, operations research, and machine learning in a variety of industries, including energy, manufacturing, and banking. Christine holds a M.S. in Industrial Engineering from the Polytechnic University of Catalonia in Barcelona. She is an open source advocate and has spoken at many conferences, including PyData, EuroPython, SciPy and PyCon. Christine Doig Senior Data Scientist Continuum Analytics @ch_doig
SIGKDD’15 • Scale your data, not your process. Welcome to the Blaze ecosystem! , EuroPython’15 • Reproducible Multilanguage Data Science with conda, PyData Dallas’15 • Building Python Data Applications with Blaze and Bokeh, SciPy’15 • Navigating the Data Science Python Ecosystem, PyConES’15 • The State of Python for Data Science, PySS’15 • Beginner’s Guide to Machine Learning Competitions, PyTexas’15 Christine Doig Senior Data Scientist Continuum Analytics @ch_doig
Y day 1 0 1 1 happy day 2 0 1 1 happy day 3 1 0 1 sad day 4 0 0 0 happy day 5 0 0 1 sad day 6 0 1 1 sad day 7 1 1 0 sad day 8 0 1 1 happy day 9 0 0 0 happy day 10 1 0 1 sad Rainy Ice cream Traffic jam Label Y day 11 0 0 1 sad day 12 0 1 1 happy day 13 1 0 1 sad day 14 0 1 0 happy day 15 0 1 1 happy day 16 0 1 0 happy day 17 1 1 1 happy day 18 0 0 0 happy day 19 0 0 1 sad day 20 1 1 1 happy
least two random variables X, Y, ..., that are defined on a probability space, the joint probability distribution for X, Y, ... is a probability distribution that gives the probability that each of X, Y, ... falls in any particular range or discrete set of values specified for that variable.
1 1 happy day 2 0 1 1 happy day 3 1 0 1 sad day 4 0 0 0 happy Rainy Ice cream Probability 1 1 0.15 1 0 0.15 0 1 0.40 0 0 0.30 ? Count how many times we encounter each situation. Divide by total number of instances. Joint Probability Distribution
0 0.15 0 1 0.40 0 0 0.30 Pr(¬Rainy) = 0.70 Pr(Ice cream | Rainy) = 0.15 / 0.3 = 0.5 What’s the probability of not rainy? What’s the probability that if it’s raining, I’m going to eat an ice cream? Conditional probability
instance to be classified, represented by a vector representing some n features (independent variables), it assigns to this instance probabilities Naive Bayes for each of K possible outcomes or classes.
1 0 1 1 happy day 2 0 1 1 happy day 3 1 0 1 sad day 4 0 0 0 happy day 5 0 0 1 sad day 6 0 1 1 sad day 7 1 1 0 sad day 8 0 1 1 happy day 9 0 0 0 happy day 10 1 0 1 sad Pr(happy| RAINY, ICE CREAM, TRAFFIC JAM) Pr(sad| RAINY, ICE CREAM, TRAFFIC JAM) if the number of features n is large or if a feature can take on a large number of values, then basing such a model on probability tables is infeasible. PROBLEM
1 0 1 1 happy day 2 0 1 1 happy day 3 1 0 1 sad day 4 0 0 0 happy day 5 0 0 1 sad day 6 0 1 1 sad day 7 1 1 0 sad day 8 0 1 1 happy day 9 0 0 0 happy day 10 1 0 1 sad What we want to compute, but infeasible! Bayes’ theorem
Naive Bayes Algorithms occurance counts binary/boolean features The different naive Bayes classifiers differ mainly by the assumptions they make regarding the distribution of
day 1 0 2 1 happy day 2 2 3 1 happy day 3 1 0 3 sad day 4 0 3 0 happy day 5 1 2 1 sad day 6 0 1 1 sad day 7 2 4 0 sad day 8 0 1 1 happy day 9 0 2 3 happy day 10 1 0 1 sad Not wheter it rained or not, I had ice cream or not, there was a traffic jam or not. Now the data tells me how many times it rained, how many ice creams I had and in how many traffic jams I was a day! 0 1 2 3 4
day 1 0 2 1 happy day 2 2 3 1 happy day 3 1 0 3 sad day 4 0 3 0 happy day 5 1 2 1 sad day 6 0 1 1 sad day 7 2 4 0 sad day 8 0 1 1 happy day 9 0 2 3 happy day 10 1 0 1 sad Not wheter it rained or not, I had ice cream or not, there was a traffic jam or not. Now the data tells me how many times it rained, how many ice creams I had and in how many traffic jams I was a day!
binomial distribution. • the multinomial distribution gives the probability of any particular combination of numbers of successes for the various categories. • A feature vector is then a histogram, with xi counting the number of times event i was observed in a particular instance. Multinomial Distribution
the learning samples and prevents zero probabilities in further computations. - alpha = 1 is called Laplace smoothing - alpha < 1 is called Lidstone smoothing. Multinomial Naive Bayes
data are typically represented as word vector counts, although tf-idf vectors are also known to work well in practice). Rainy Ice cream Traffic jam Label Y doc 1 0 2 1 happy doc 2 2 3 1 happy doc 3 1 0 3 sad doc 4 0 3 0 happy doc 5 1 2 1 sad doc 6 0 1 1 sad day 7 2 4 0 sad doc 8 0 1 1 happy doc 9 0 2 3 happy doc 10 1 0 1 sad documents words type of document: happy or sad?
day 1 0 1 1 happy day 2 0 1 1 happy day 3 1 0 1 sad day 4 0 0 0 happy day 5 0 0 1 sad day 6 0 1 1 sad day 7 1 1 0 sad day 8 0 1 1 happy day 9 0 0 0 happy day 10 1 0 1 sad which differs from multinomial NB’s rule in that it explicitly penalizes the non- occurrence of a feature i that is an indicator for class y, where the multinomial variant would simply ignore a non-occurring feature.
is assumed to be a binary-valued (Bernoulli, boolean) variable • if handed any other kind of data, a BernoulliNB instance may binarize its input (depending on the binarize parameter). • text classification => word occurrence vectors Bernoulli Naive Bayes
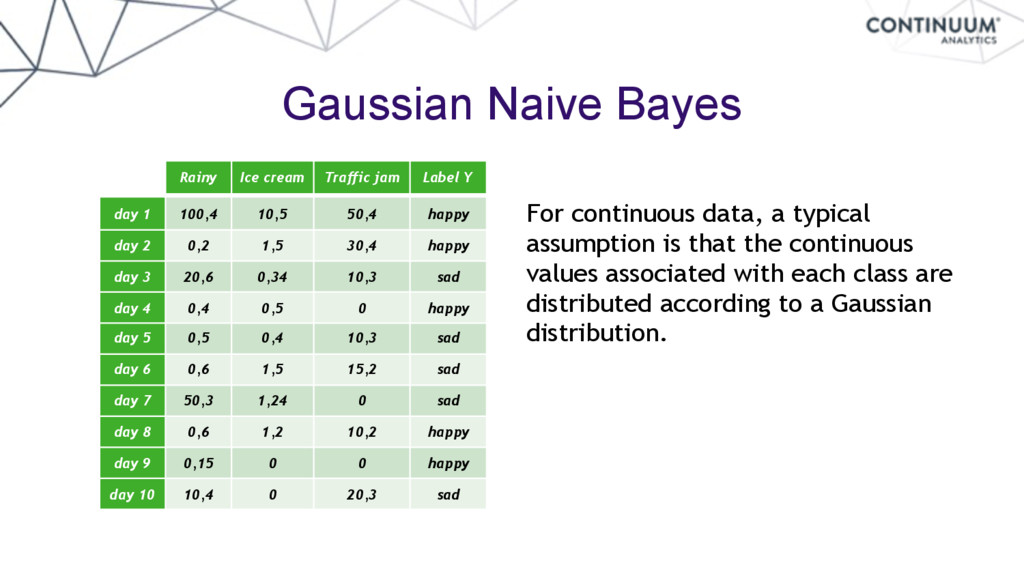
day 1 100,4 10,5 50,4 happy day 2 0,2 1,5 30,4 happy day 3 20,6 0,34 10,3 sad day 4 0,4 0,5 0 happy day 5 0,5 0,4 10,3 sad day 6 0,6 1,5 15,2 sad day 7 50,3 1,24 0 sad day 8 0,6 1,2 10,2 happy day 9 0,15 0 0 happy day 10 10,4 0 20,3 sad For continuous data, a typical assumption is that the continuous values associated with each class are distributed according to a Gaussian distribution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}