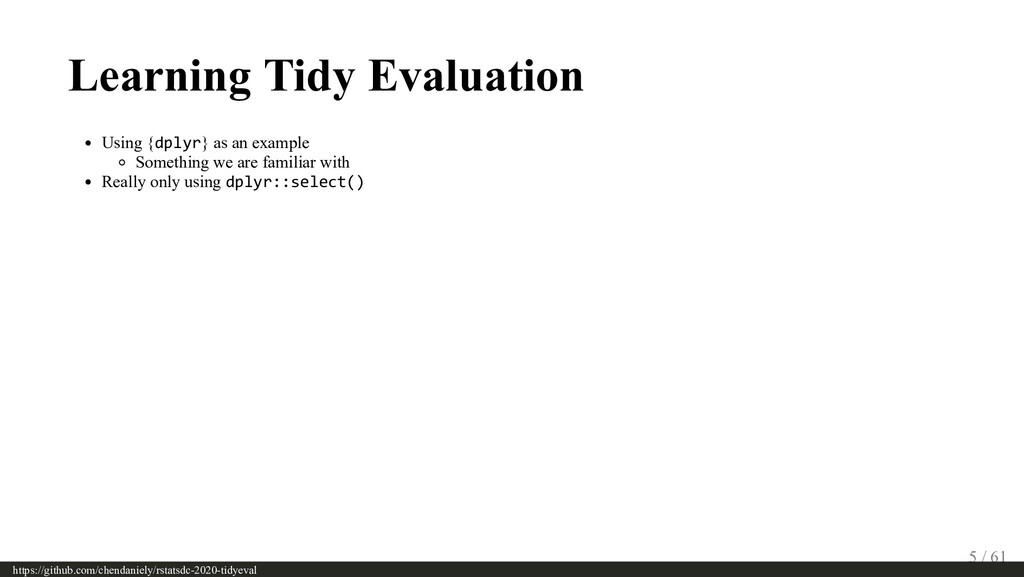
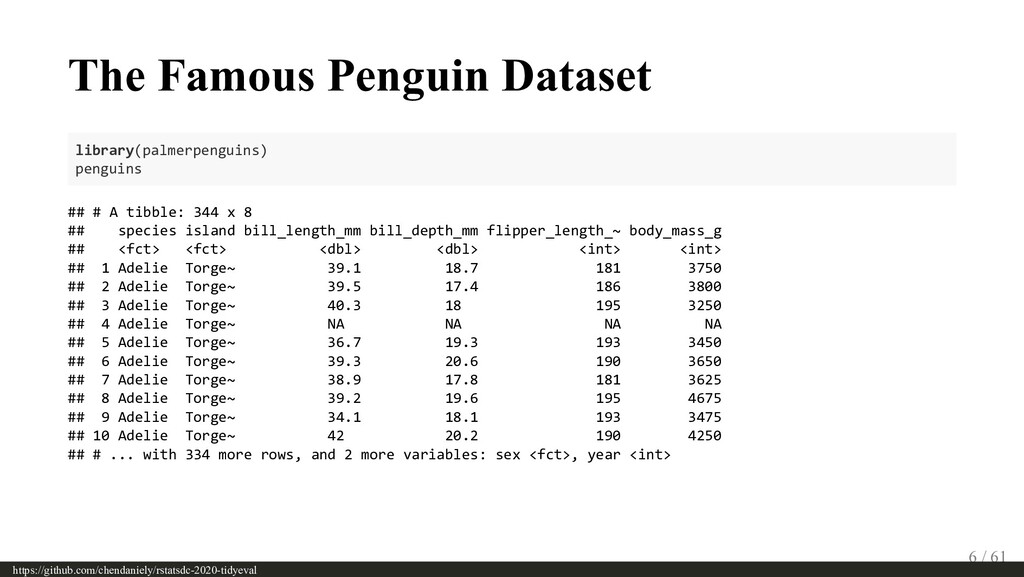
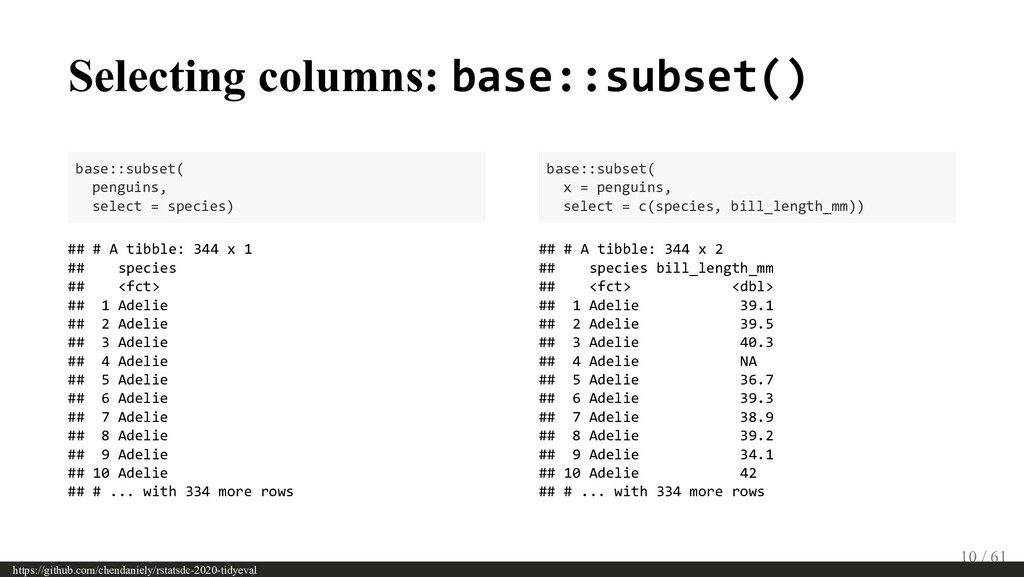
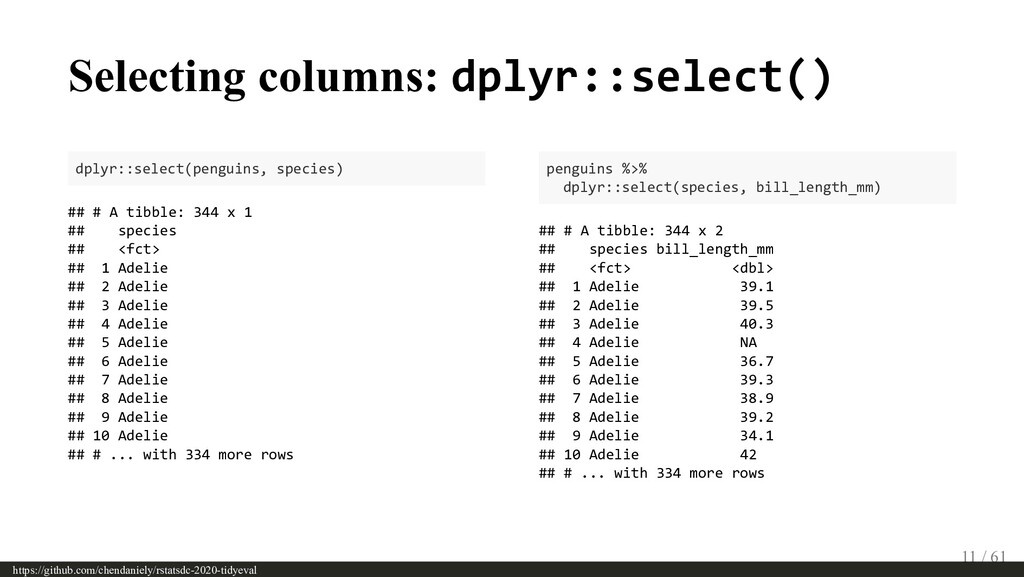
The tidyverse has grown to be a widely used set of tools with dplyr as one of its earliest members. One can leverage people’s familiarity with dplyr as the motivating example for going through the more complicated topics around tidy evaluation. By re-implementing the behaviours of some dplyr functions (e.g., select, filter, etc) one can see how rlang’s tools for quoting (e.g., quo, enquo) and unquoting (e.g. !! and !!! ) play a role in writing tidyverse functions. The audience may have already heard of “passing the dots”, but this talk will take off one of the training wheels to see how users can use the tools to create their own functions by replicating some of the behaviours of the ones that many folks know and are familiar with.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![head(penguins[, "species"]) # for tibble ## # A tibble: 6](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_7.jpg){kind=link}
![Selecting columns: $, drop=TRUE penguins$species penguins[, "species", drop = TRUE]](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![penguins[, 1, drop = FALSE] ## # A tibble: 344](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Direct string column penguins[, "species"] ## # A tibble: 344](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_16.jpg){kind=link}
![Selecting columns: Variables need to exist penguins[, species] ## Error](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_17.jpg){kind=link}
![as.name("species") ## species quote(species) ## species penguins[, as.name("species")] ## #](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_18.jpg){kind=link}
![Selecting: tibble specific (data.frame) iris[, as.name("Species")] ## Error in .subset(x,](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_19.jpg){kind=link}
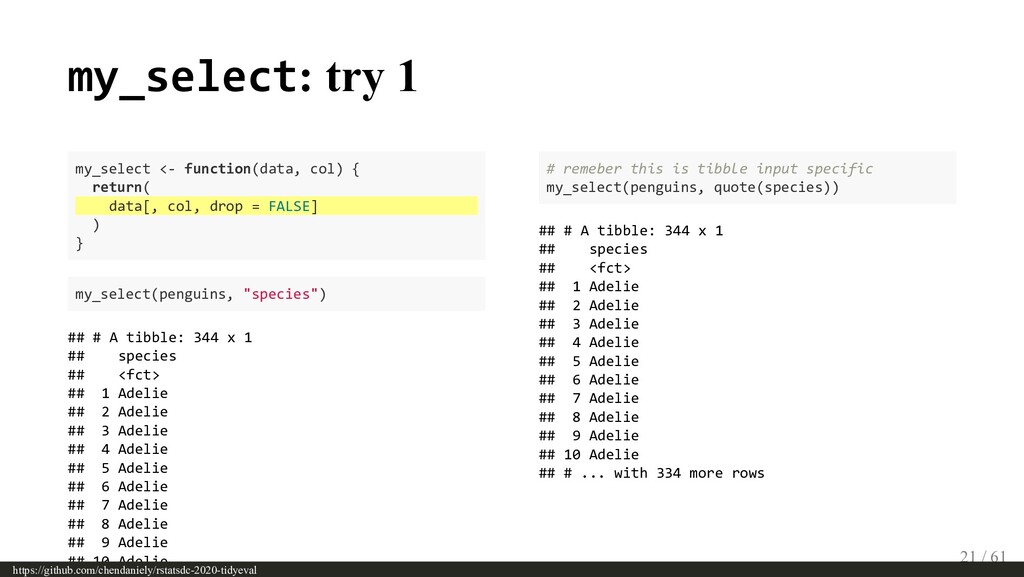{kind=link}
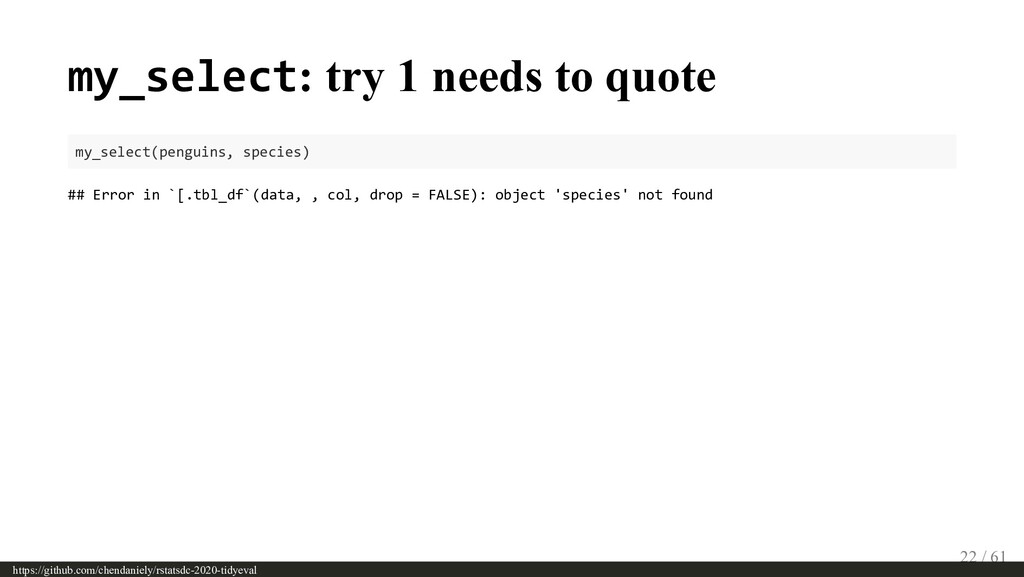{kind=link}
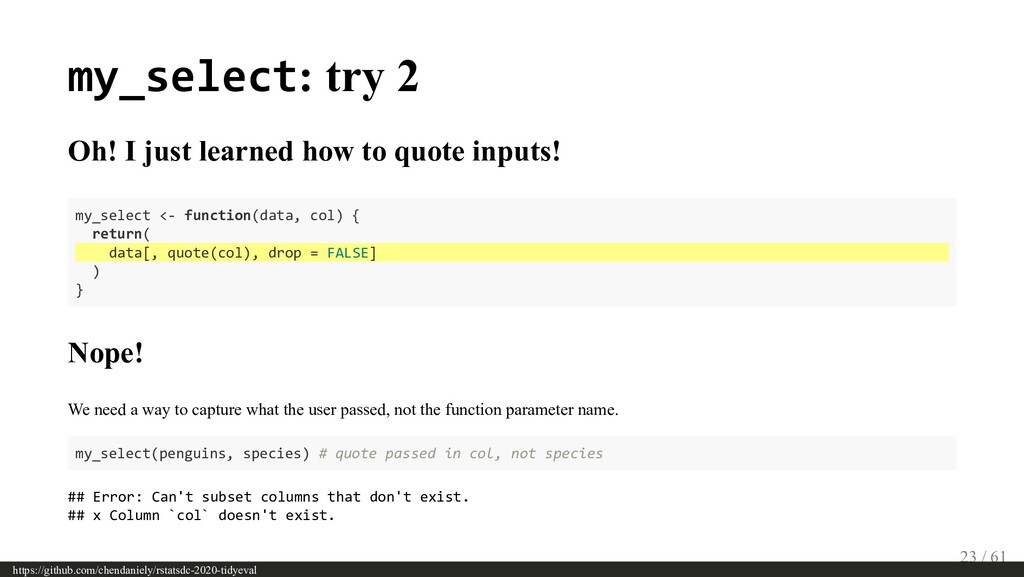{kind=link}
{kind=link}
{kind=link}
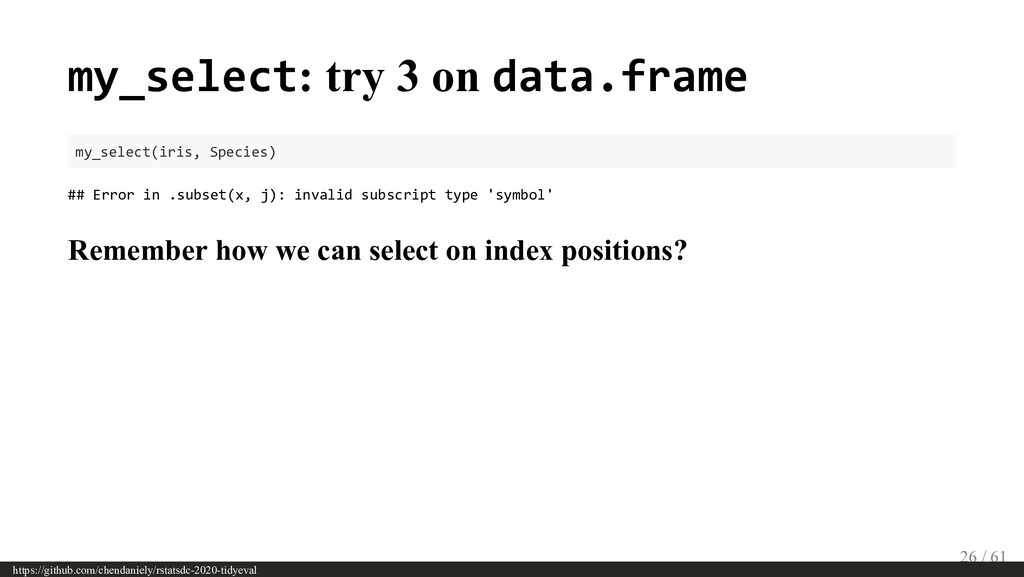{kind=link}
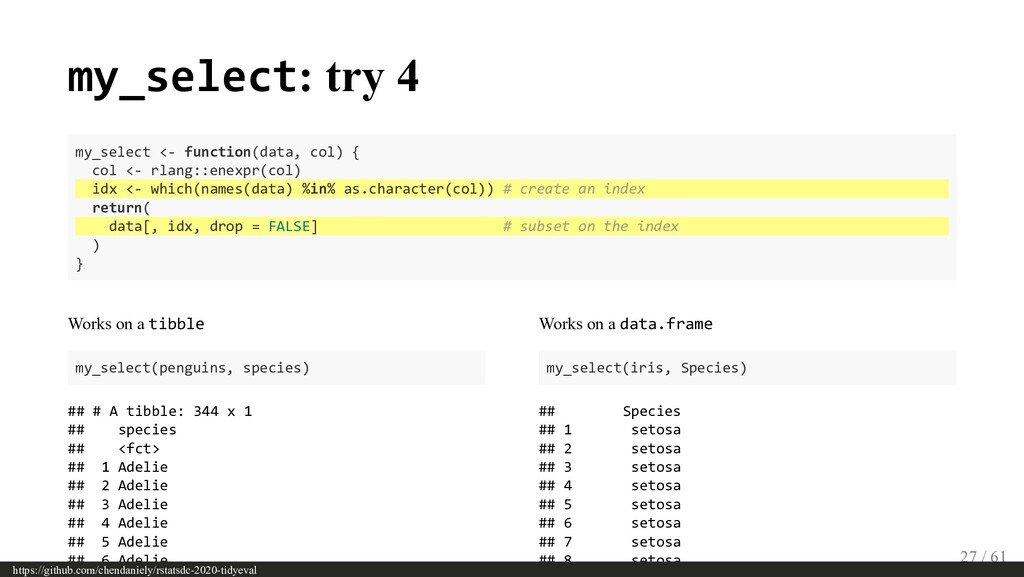{kind=link}
{kind=link}
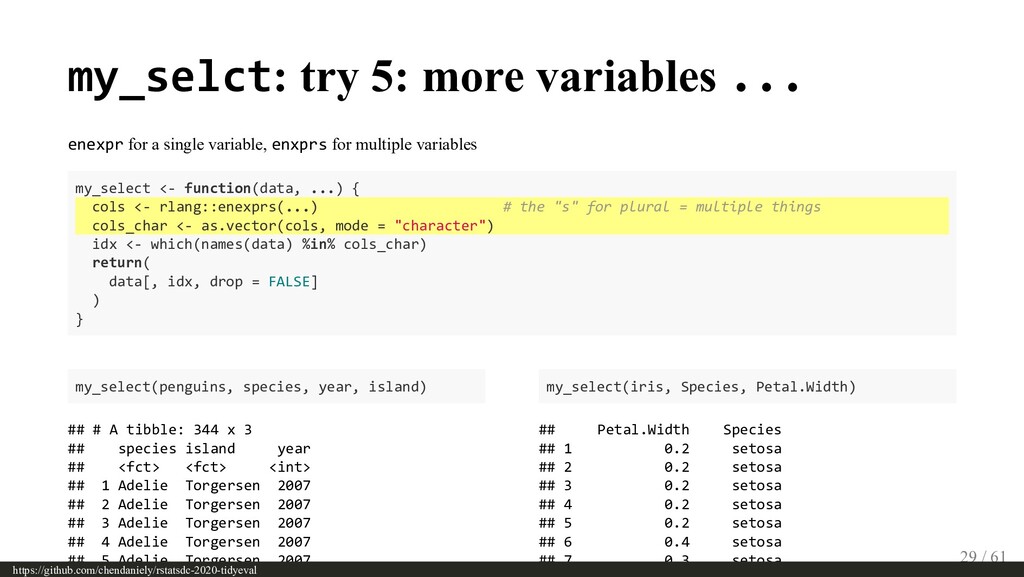{kind=link}
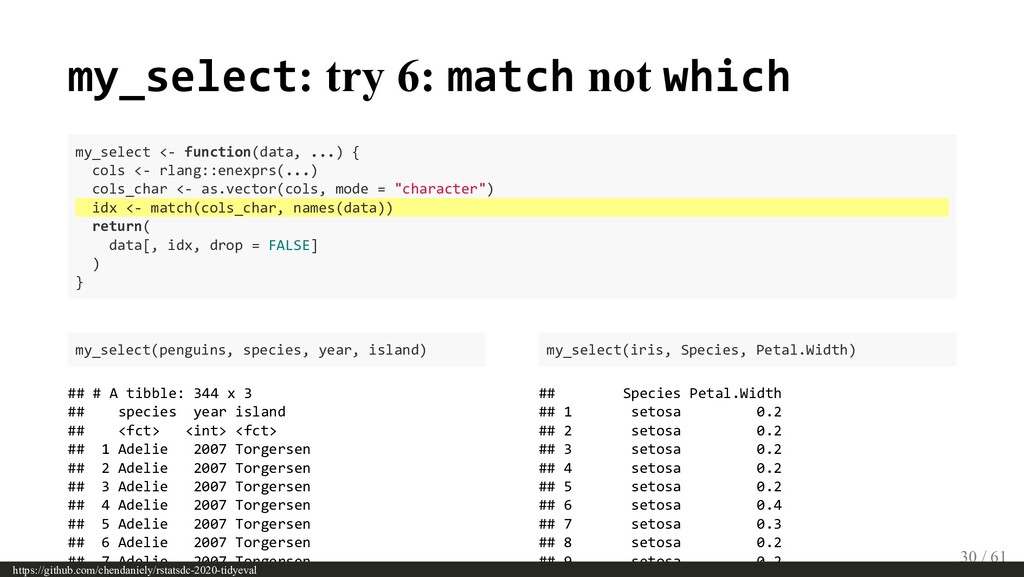{kind=link}
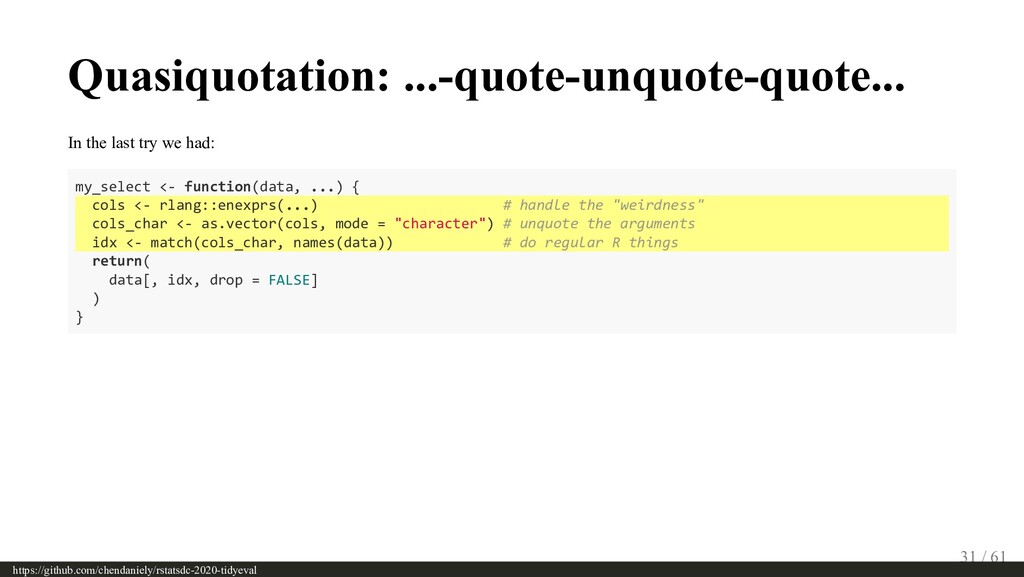{kind=link}
![penguins[, c(col_name, "island", "year")] ## # A tibble: 344 x](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_31.jpg){kind=link}
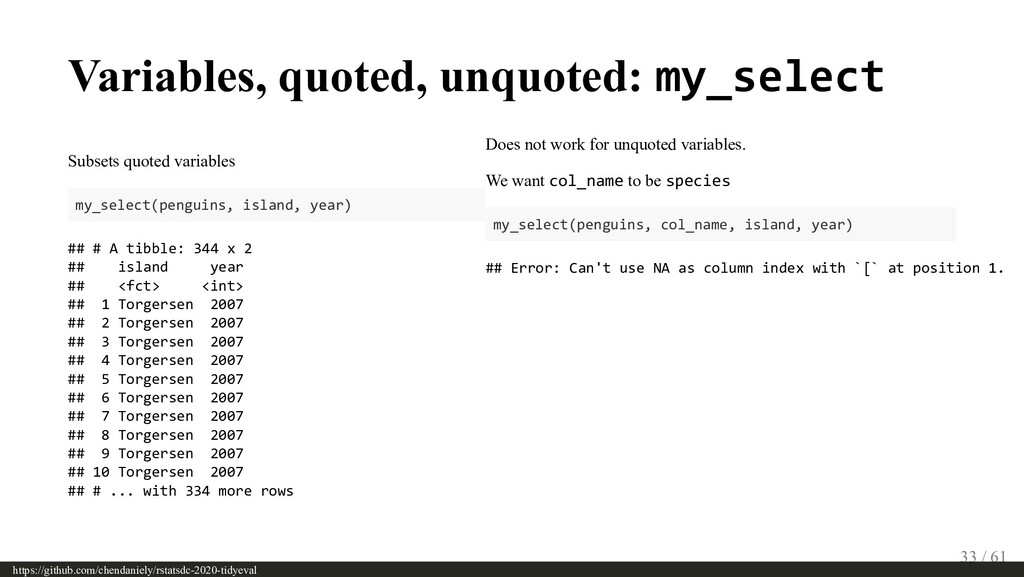{kind=link}
{kind=link}
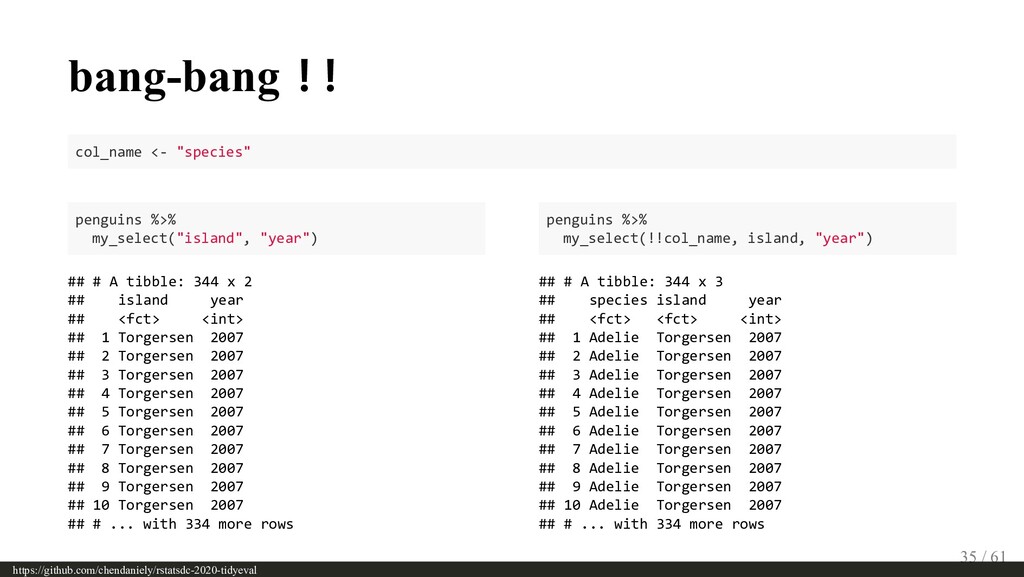{kind=link}
{kind=link}
{kind=link}
![cols <- exprs(species, island, year) cols ## [[1]] ## species](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
![Closure?! df[1] ## Error in df[1]: object of type 'closure'](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_40.jpg){kind=link}
![e <- new.env() e$x <- 3 e$x ## [1] 3](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_41.jpg){kind=link}
{kind=link}
![form <- ~ 3 + x form[[1]] ## `~` form[[2]]](https://files.speakerdeck.com/presentations/e2d66f1bdd0d450fa169ec5fc3776479/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
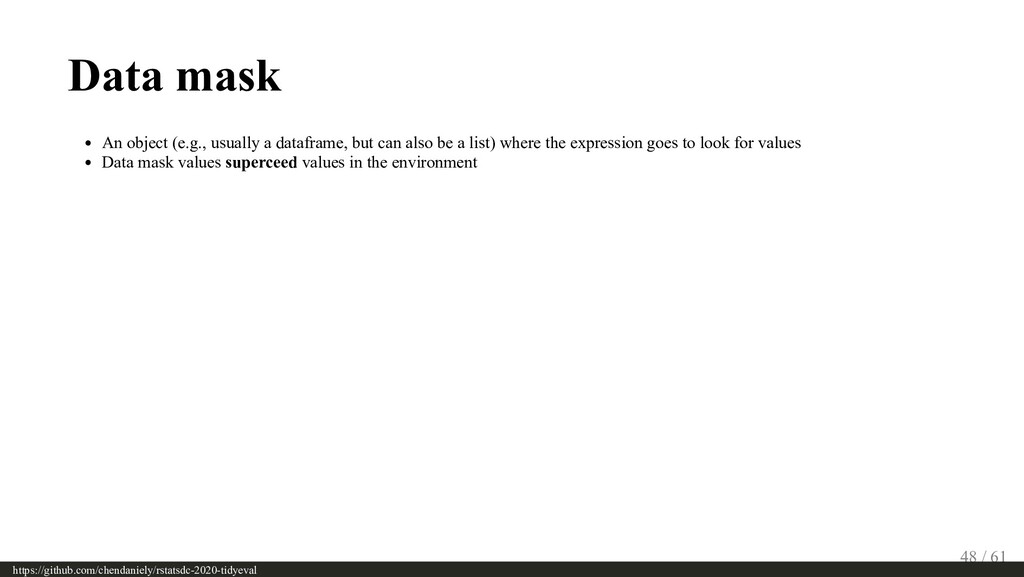{kind=link}
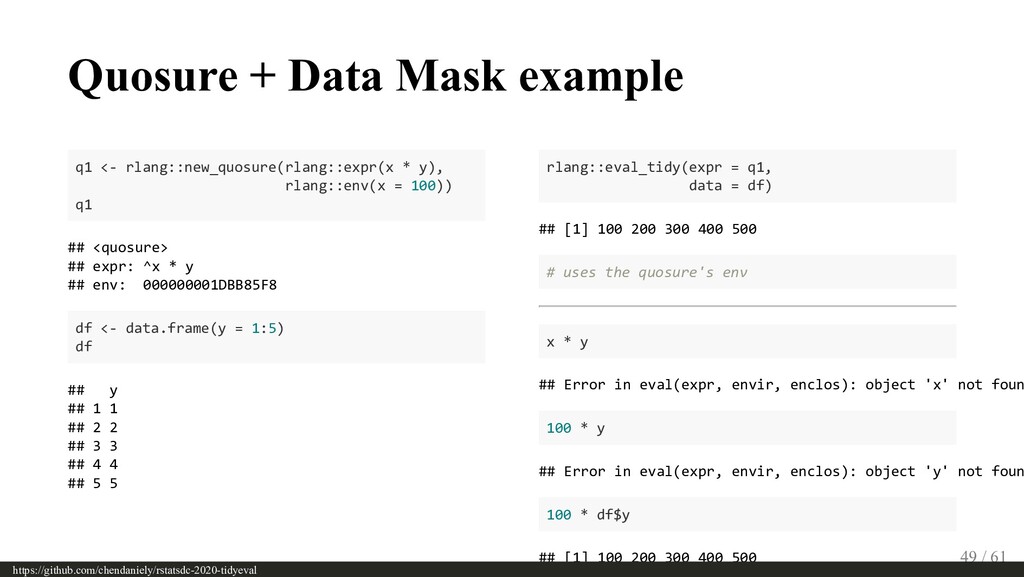{kind=link}
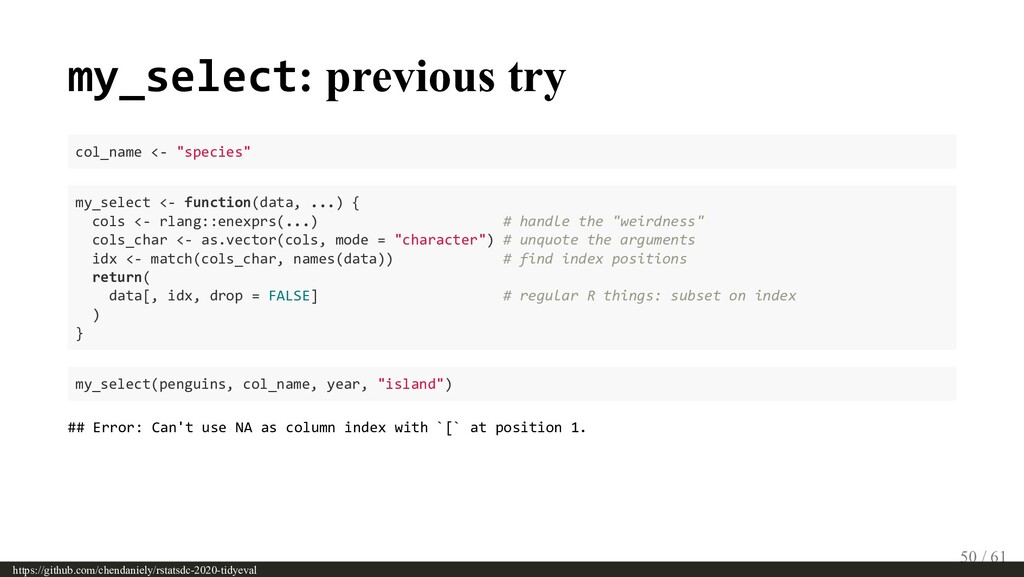{kind=link}
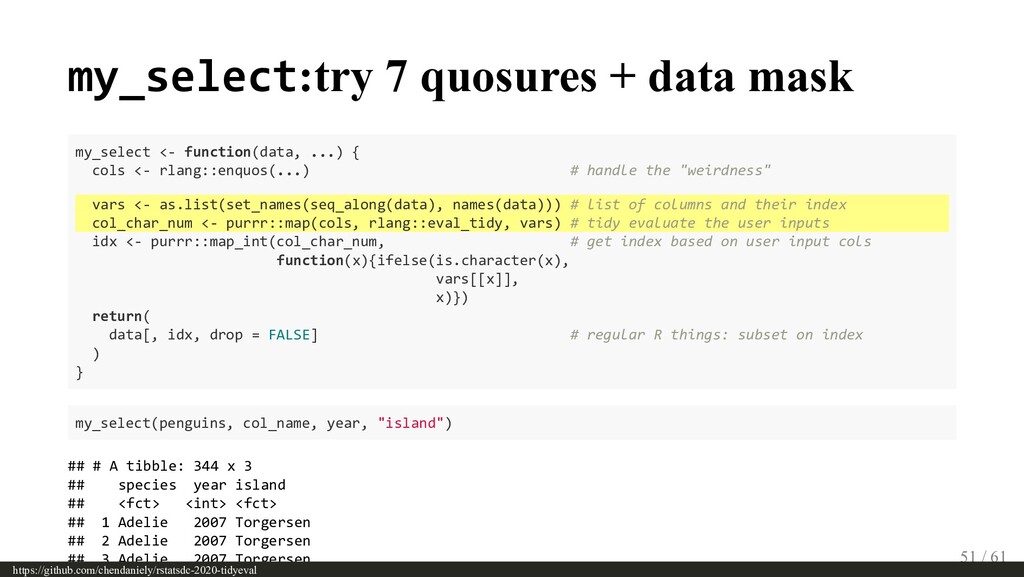{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}