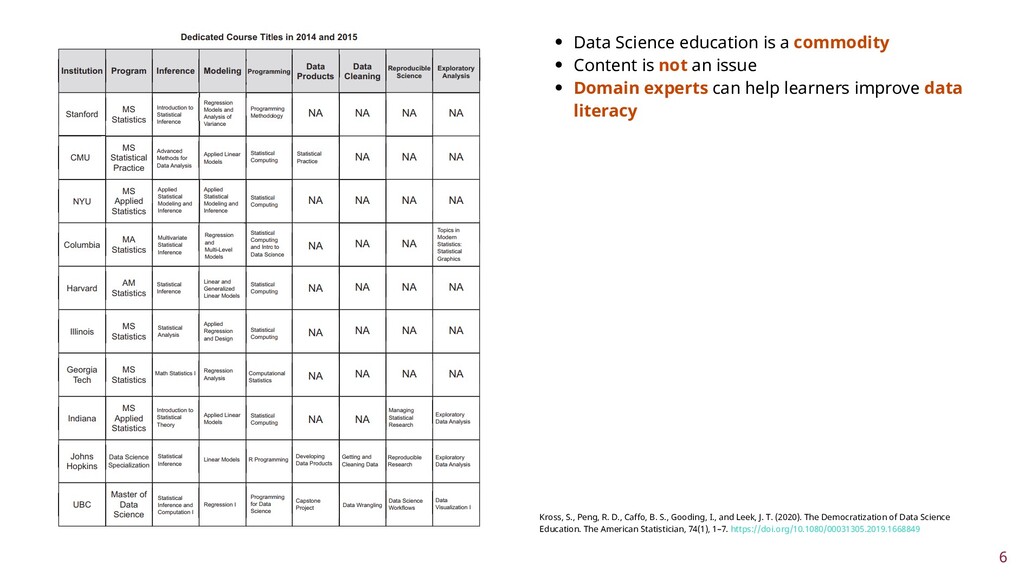
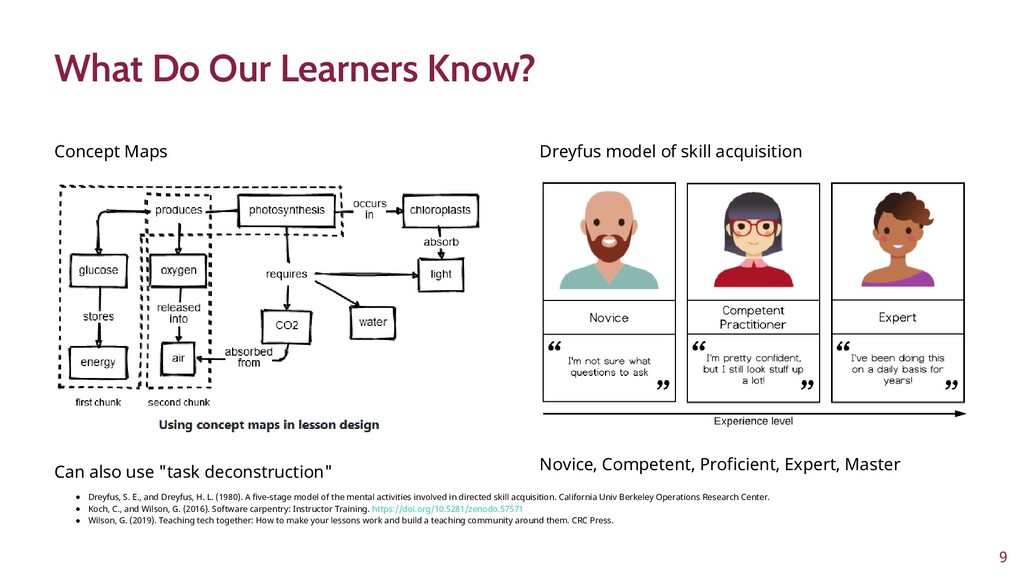
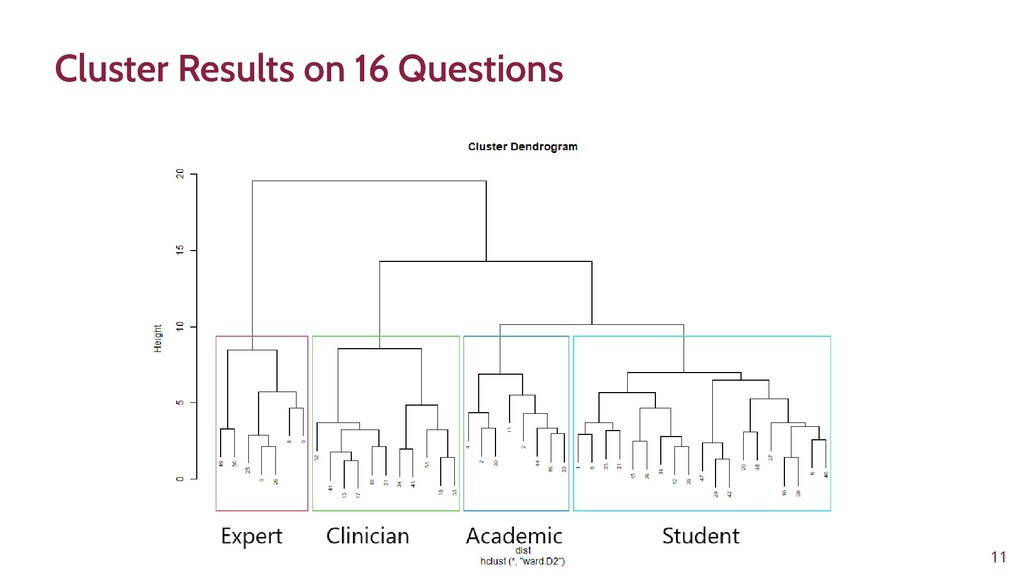
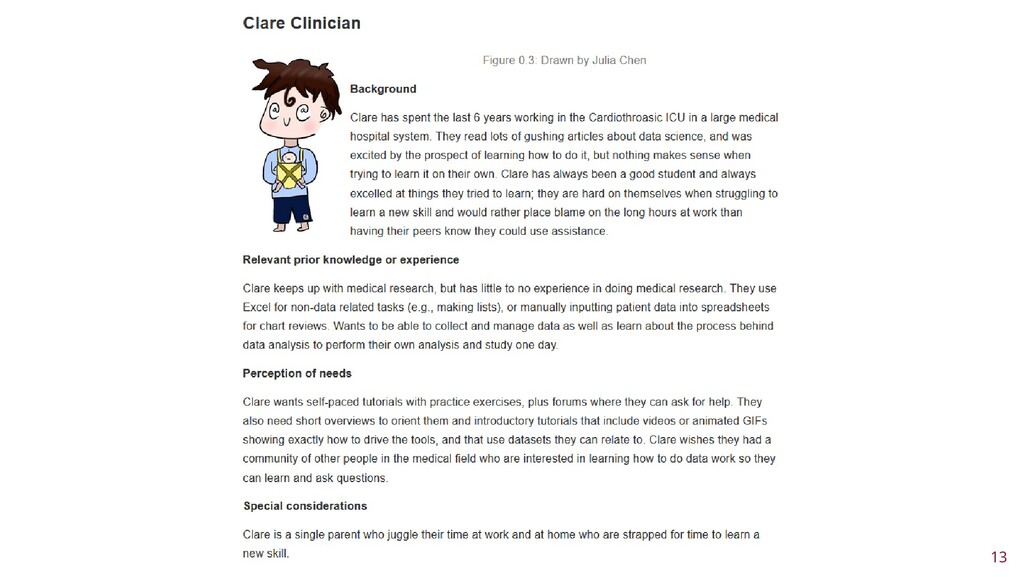
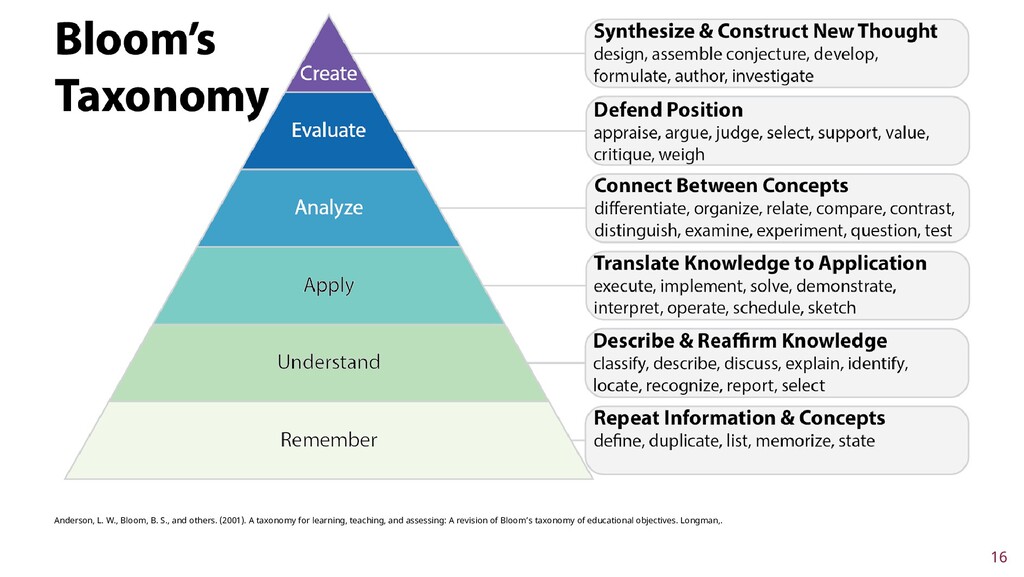
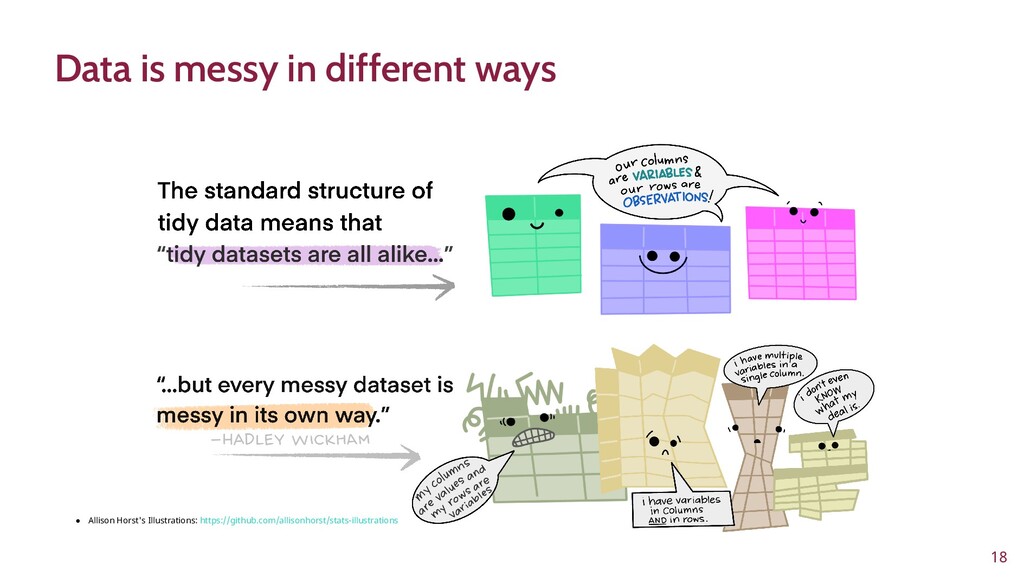
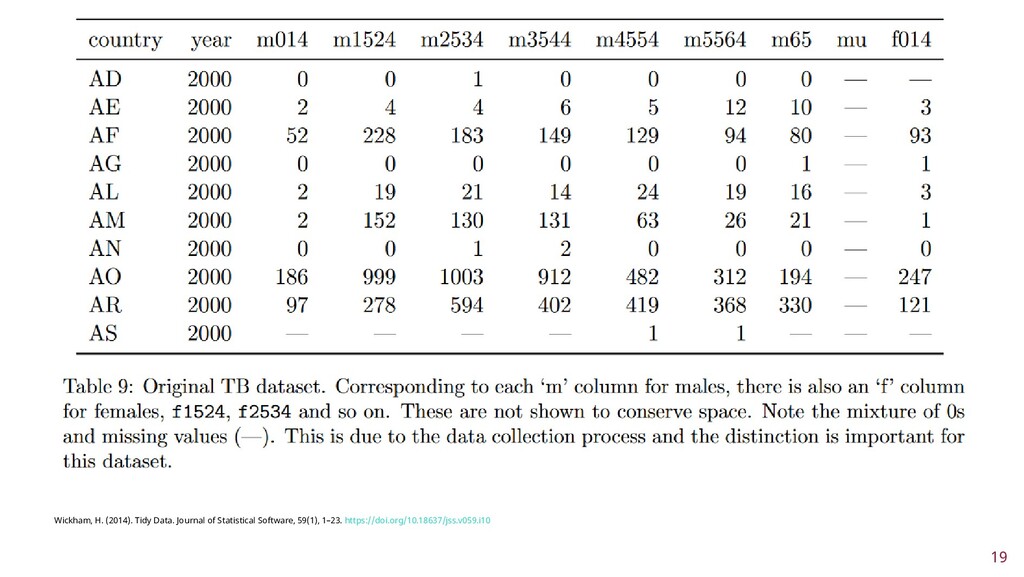
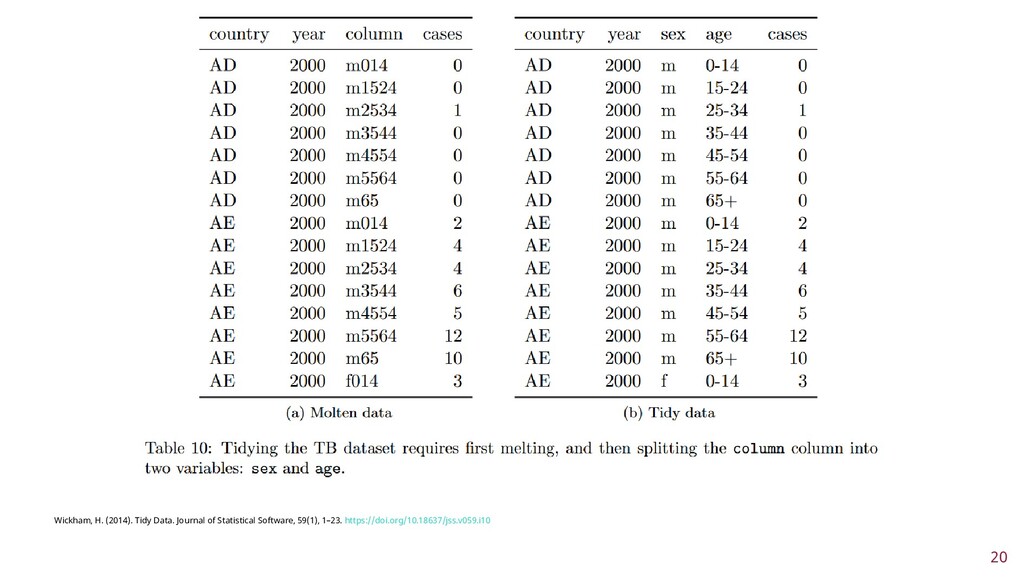
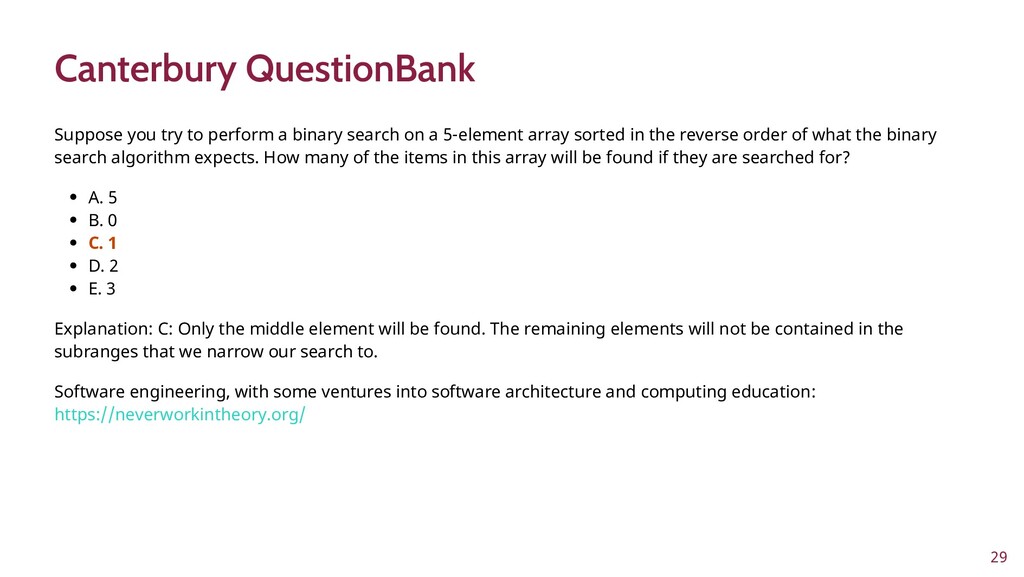
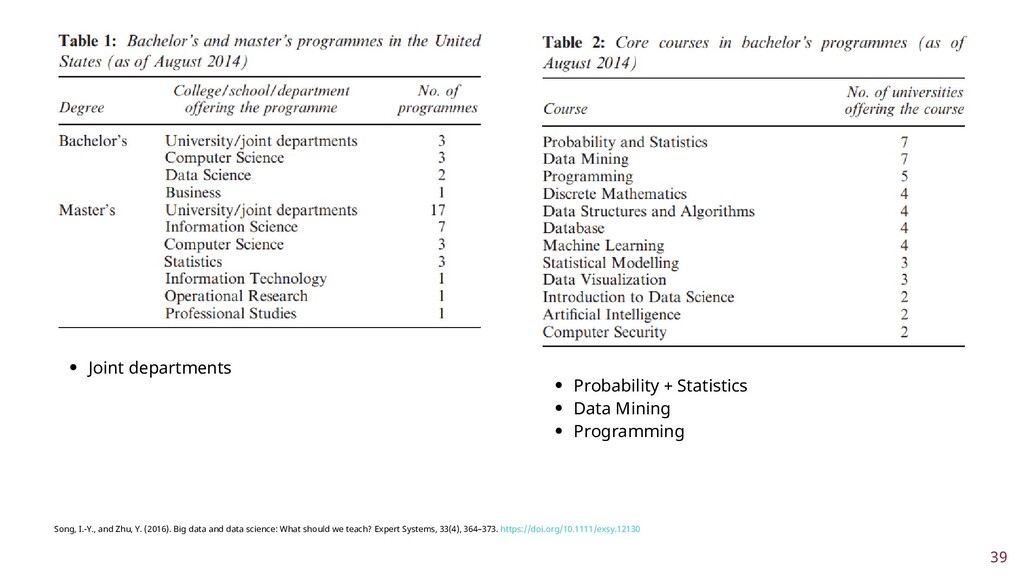
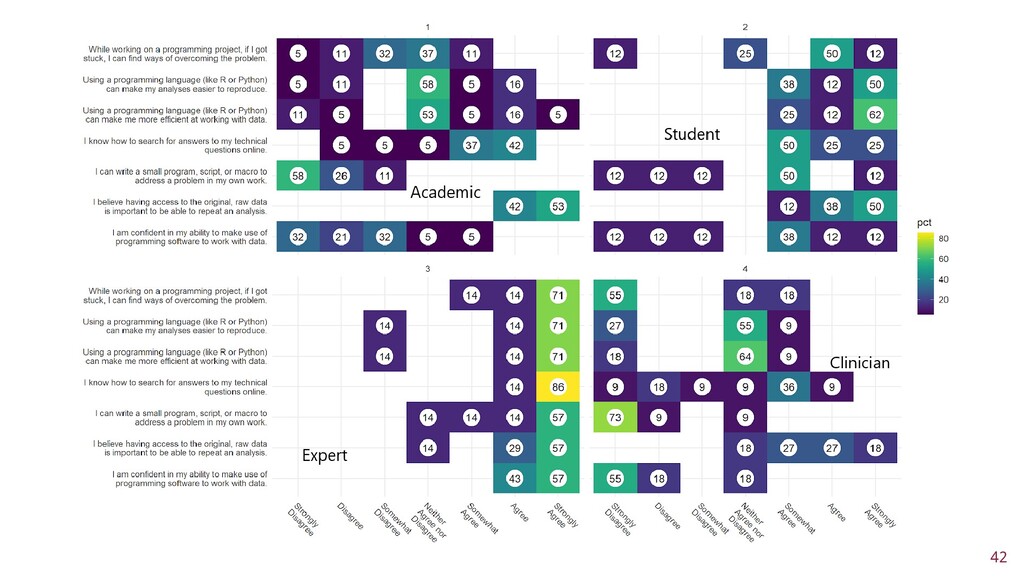
To improve learner engagement, it is necessary to have teaching and learning materials that resonate, are relevant, and are at the appropriate level for learners to motivate and support their learning in a difficult skill. A self-assessment survey was created to identify learner personas in biomedical data science and establish knowledge baseline and knowledge gaps in a population of learners. Hierarchical clustering was used to identify 4 personas: Experts, Clinicians, Academics, and Students. These personas and survey results were validated and used to create a content series on biomedical data science, which were evaluated to see if there was an improvement in learner's confidence in completing and meeting learning objectives. This work seeks to fill a technical skill gap, along with workforce development, and promote multidisciplinary collaborative teams by teaching the skills and jargon used in data science. This work also seeks to provide future educators with a roadmap of creating learner personas when creating new bodies of teaching materials relevant to data science.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}