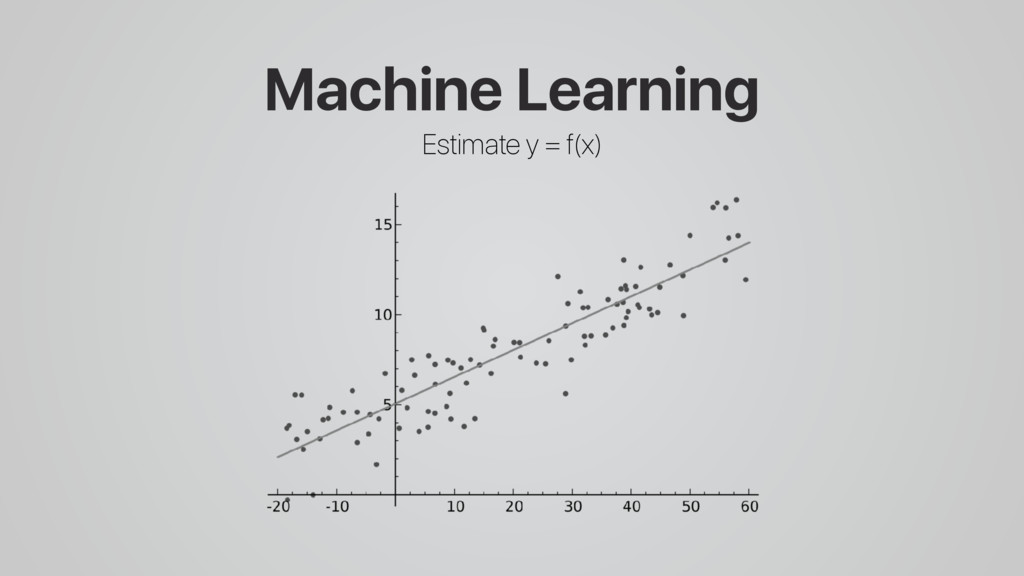
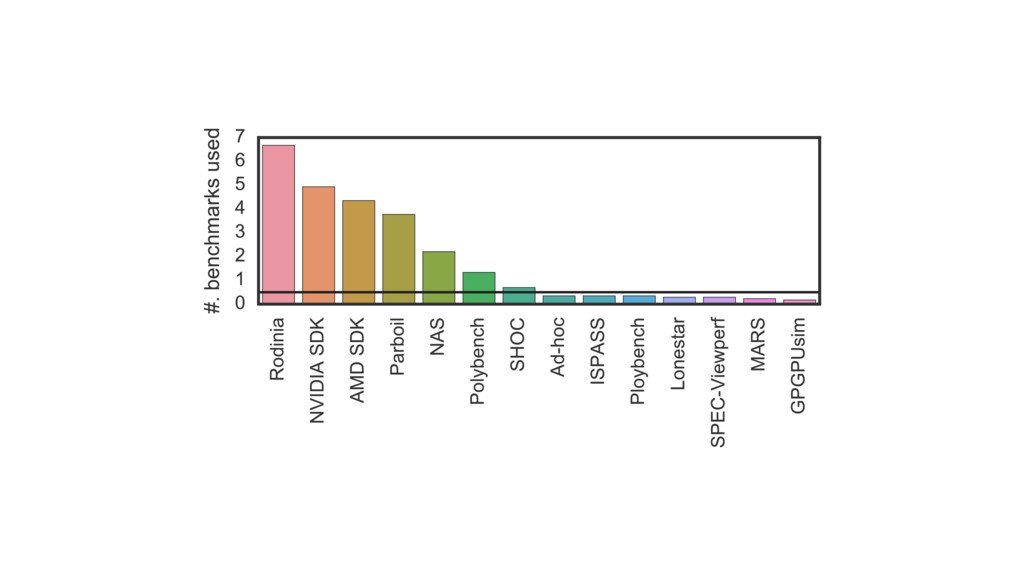
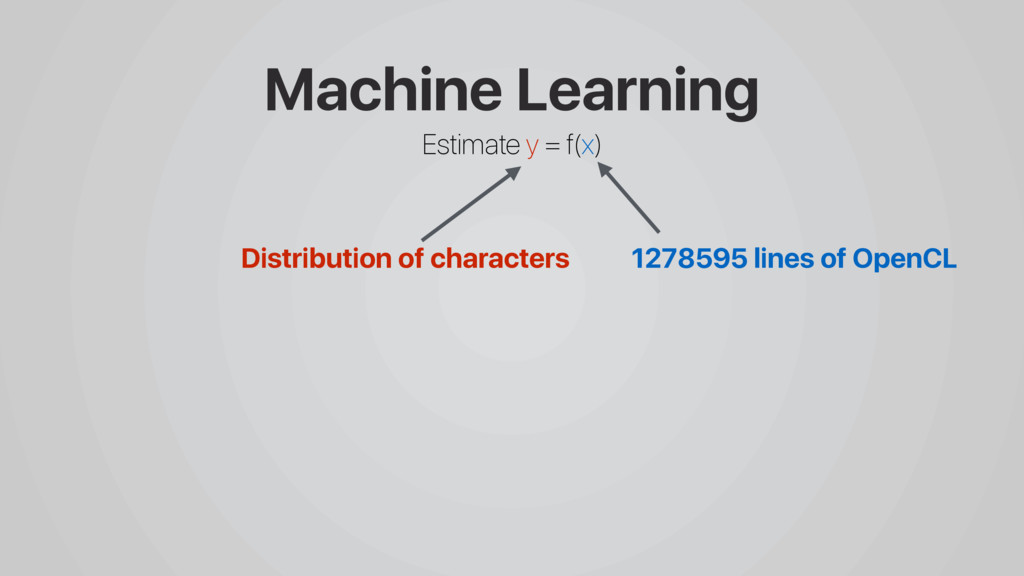
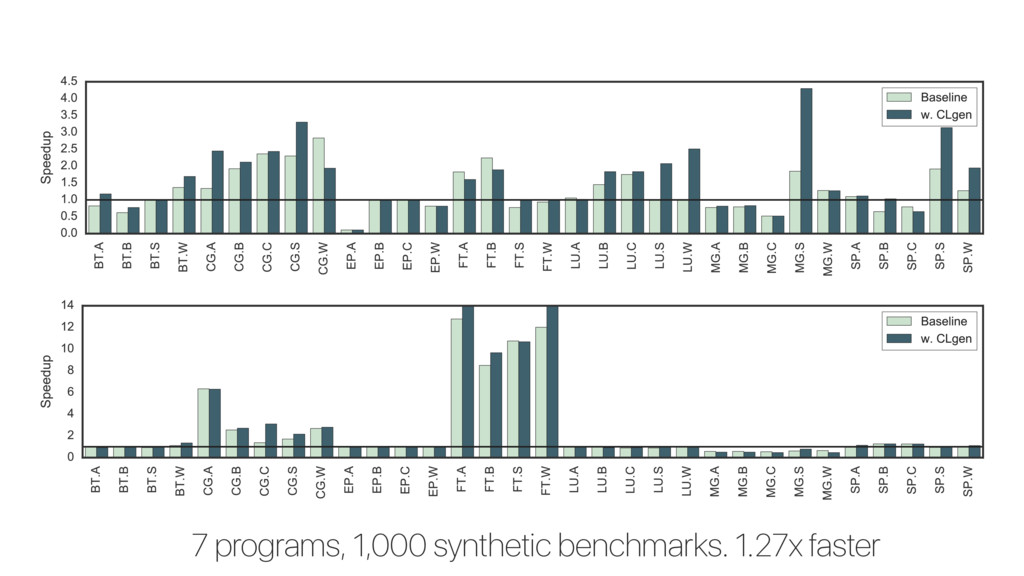
Predictive modeling using machine learning is an effective method for building compiler heuristics, but there is a shortage of benchmarks. Typical machine learning experiments outside of the compilation field train over thousands or millions of examples. In machine learning for compilers, however, there are typically only a few dozen common benchmarks available. This limits the quality of learned models, as they have very sparse training data for what are often high-dimensional feature spaces.
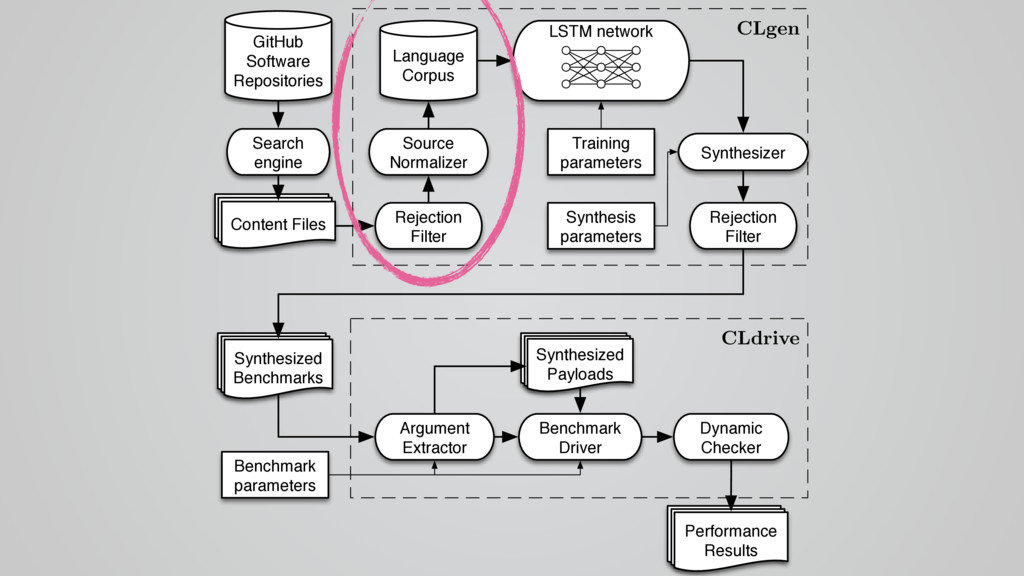
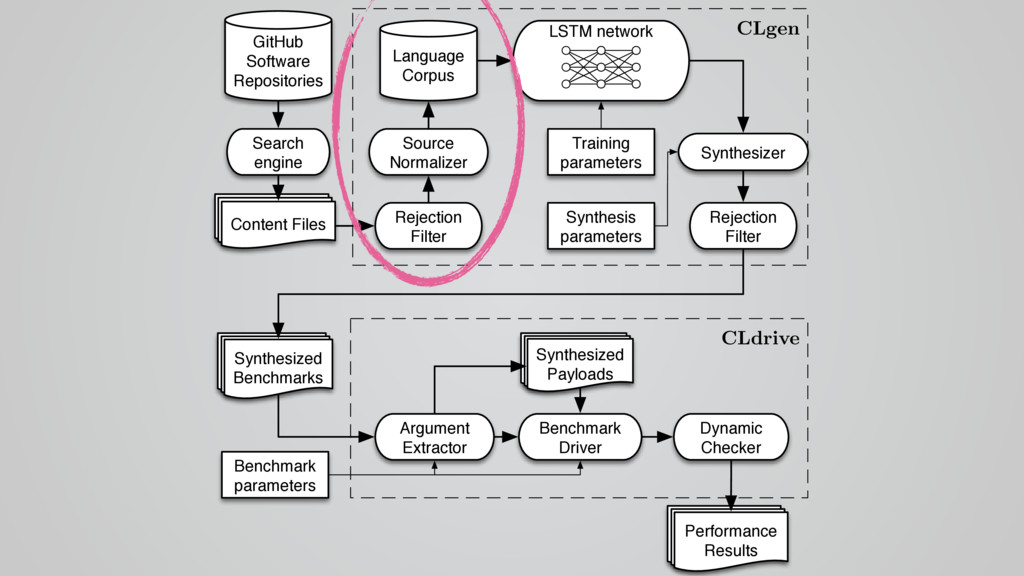
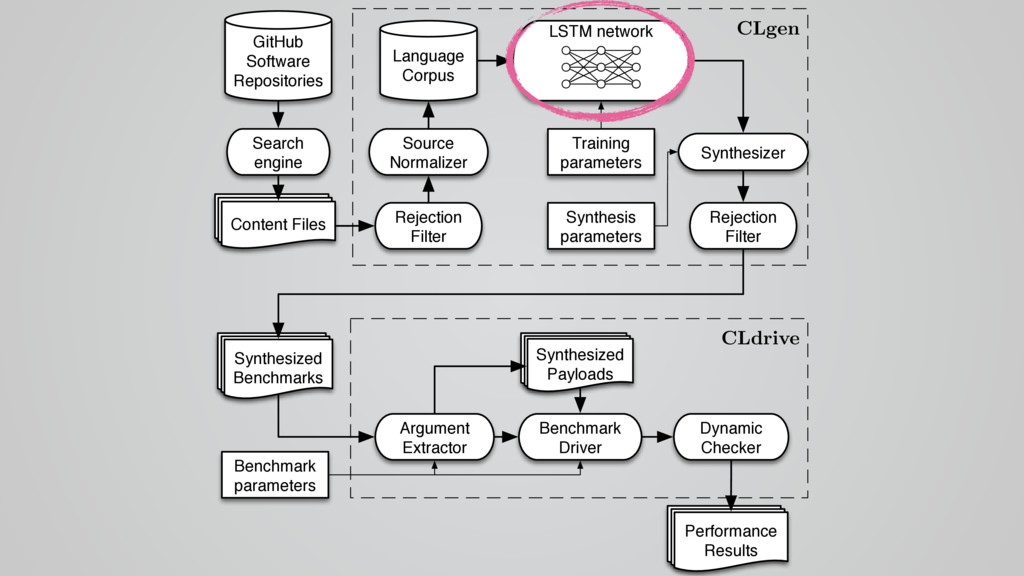
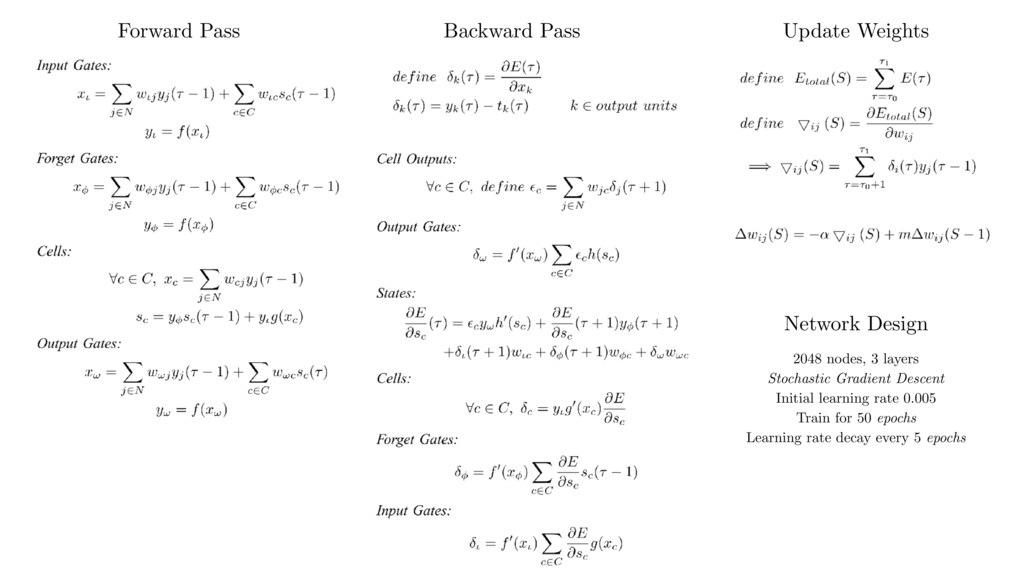
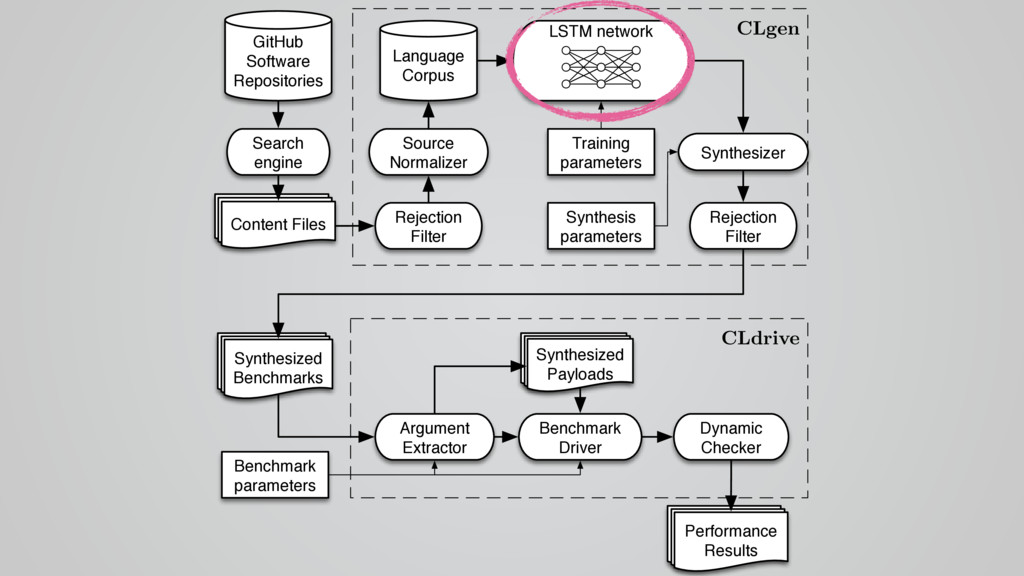
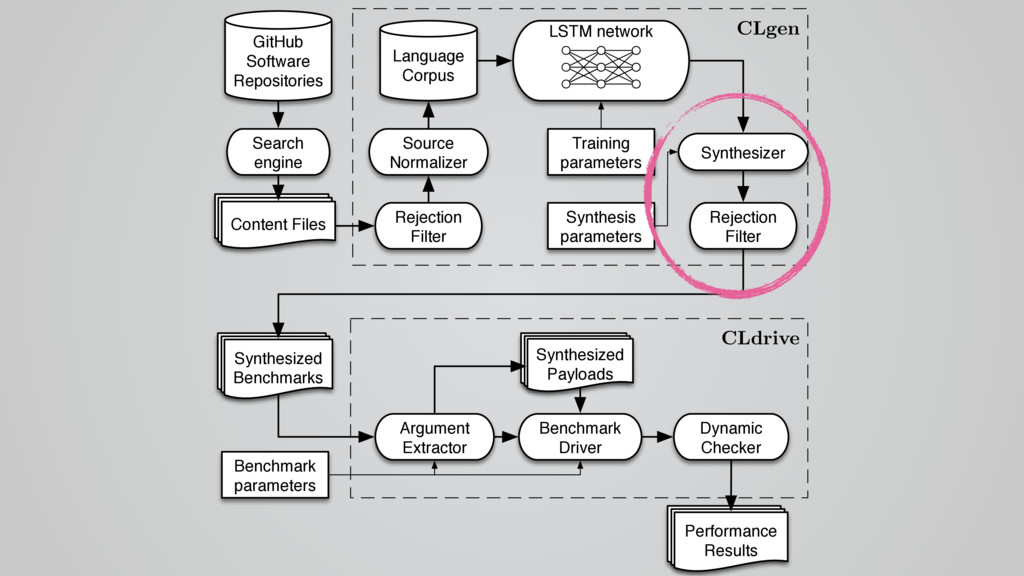
In this talk I present CLgen, a tool for generating benchmarks for predictive modeling.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![/* Copyright (C) 2004 Joe Bloggs <[email protected]> */ // //](https://files.speakerdeck.com/presentations/90738f1cf7aa4b04a53849861a665b5b/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
![/* Copyright (C) 2004 Joe Bloggs <[email protected]> */ // //](https://files.speakerdeck.com/presentations/90738f1cf7aa4b04a53849861a665b5b/slide_28.jpg){kind=link}
![/* Copyright (C) 2004 Joe Bloggs <[email protected]> */ // //](https://files.speakerdeck.com/presentations/90738f1cf7aa4b04a53849861a665b5b/slide_29.jpg){kind=link}
![/* Copyright (C) 2004 Joe Bloggs <[email protected]> */ // //](https://files.speakerdeck.com/presentations/90738f1cf7aa4b04a53849861a665b5b/slide_30.jpg){kind=link}
![/* Copyright (C) 2004 Joe Bloggs <[email protected]> */ // //](https://files.speakerdeck.com/presentations/90738f1cf7aa4b04a53849861a665b5b/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
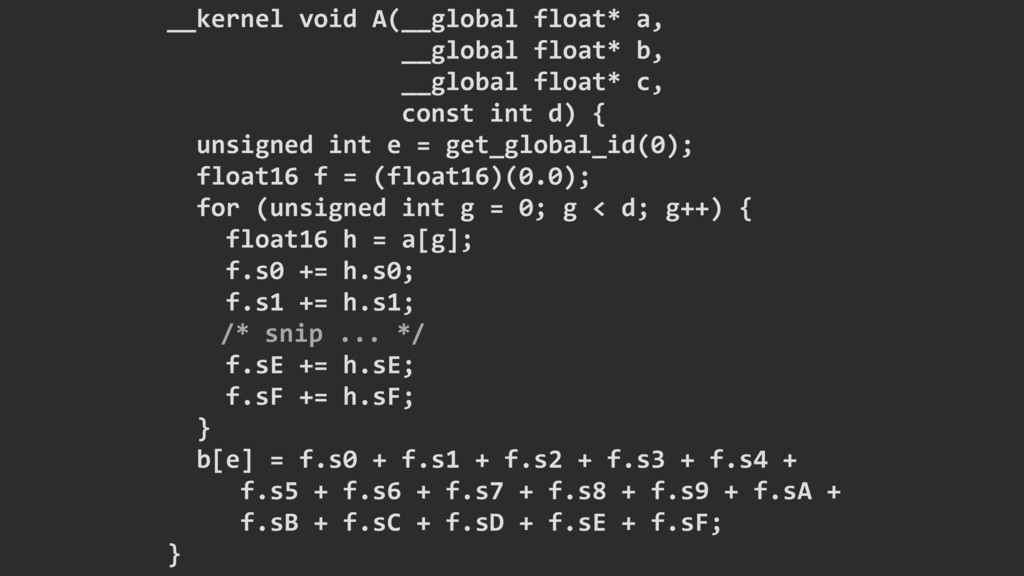{kind=link}
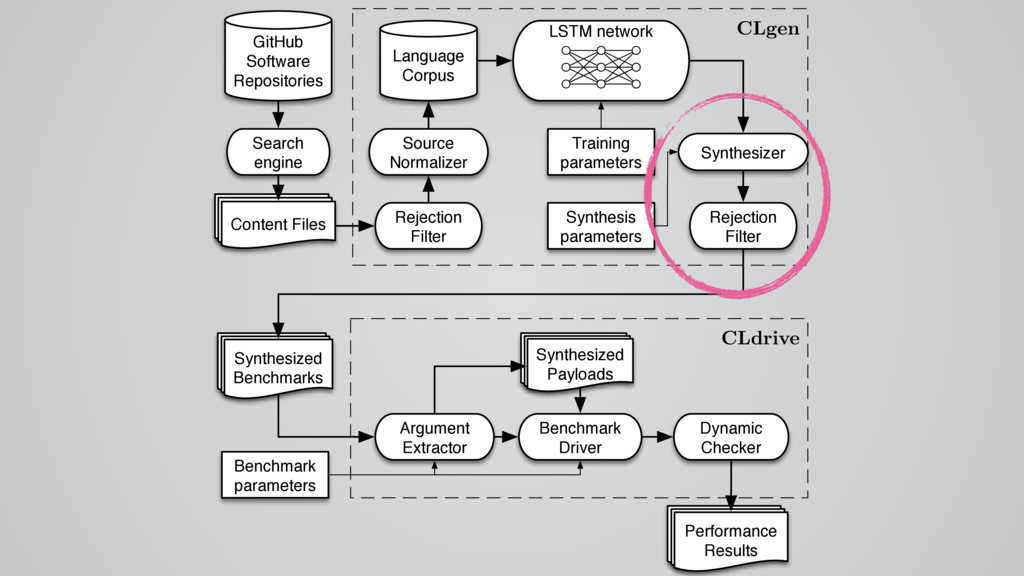{kind=link}
{kind=link}
{kind=link}
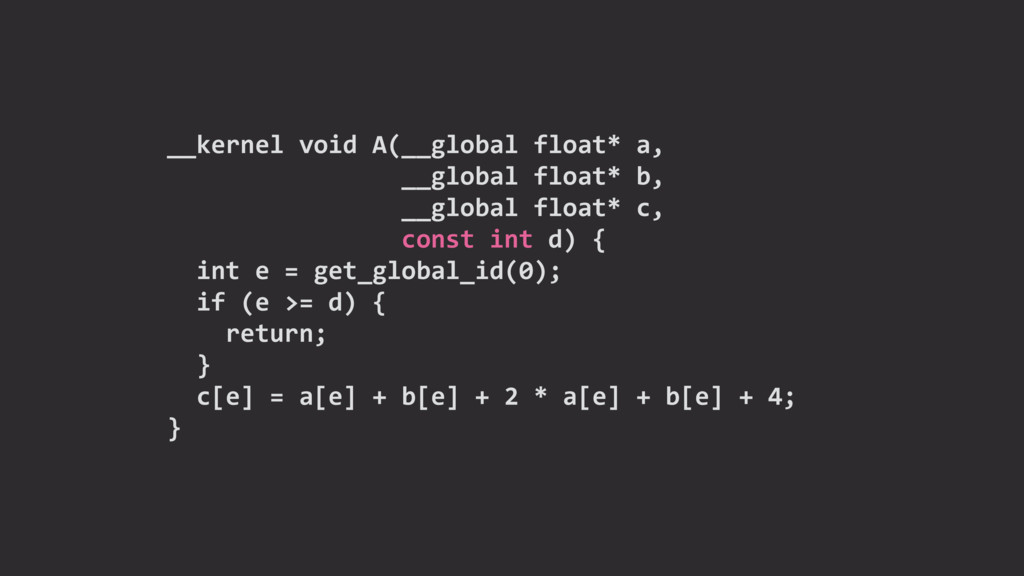{kind=link}
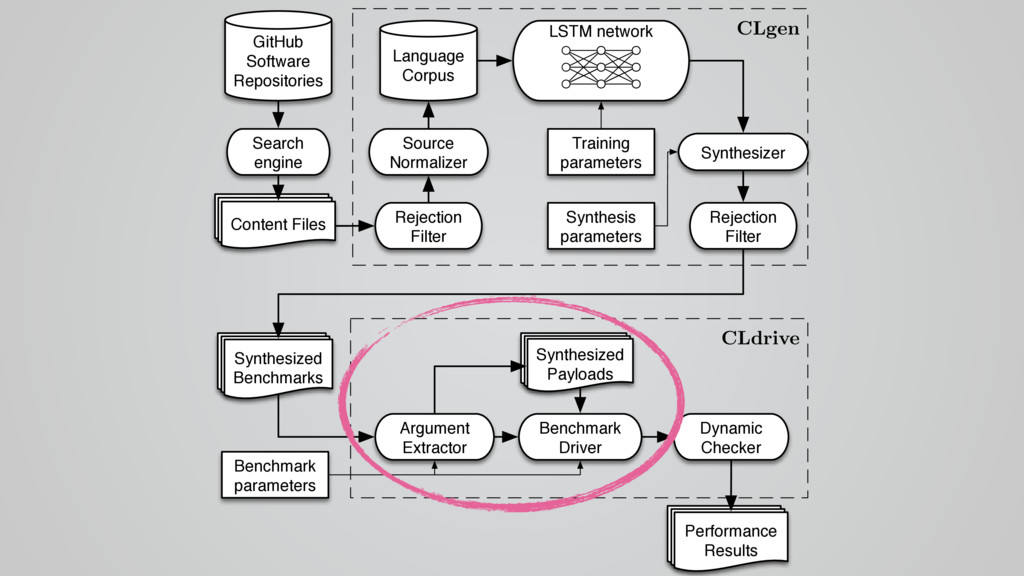{kind=link}
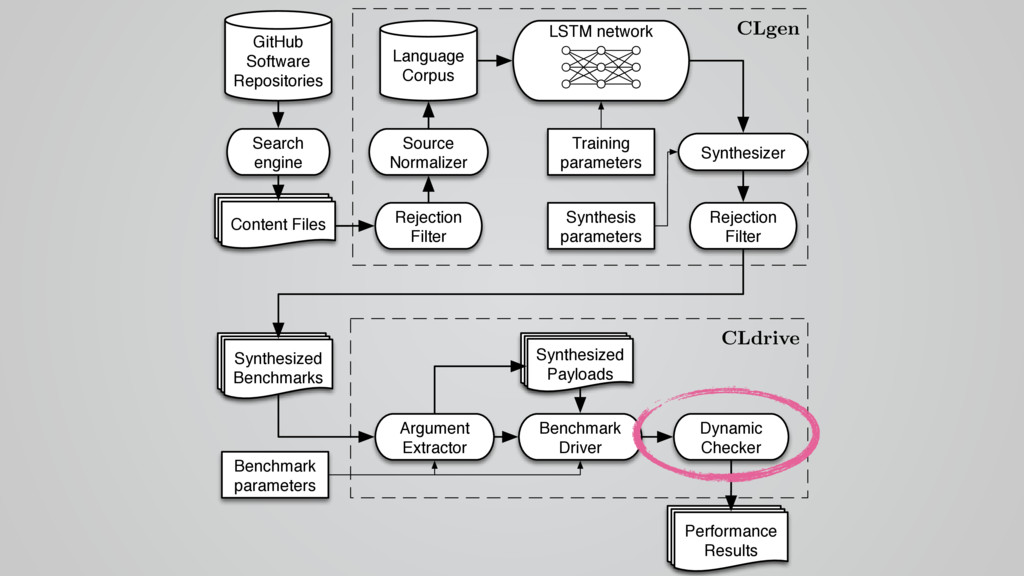{kind=link}
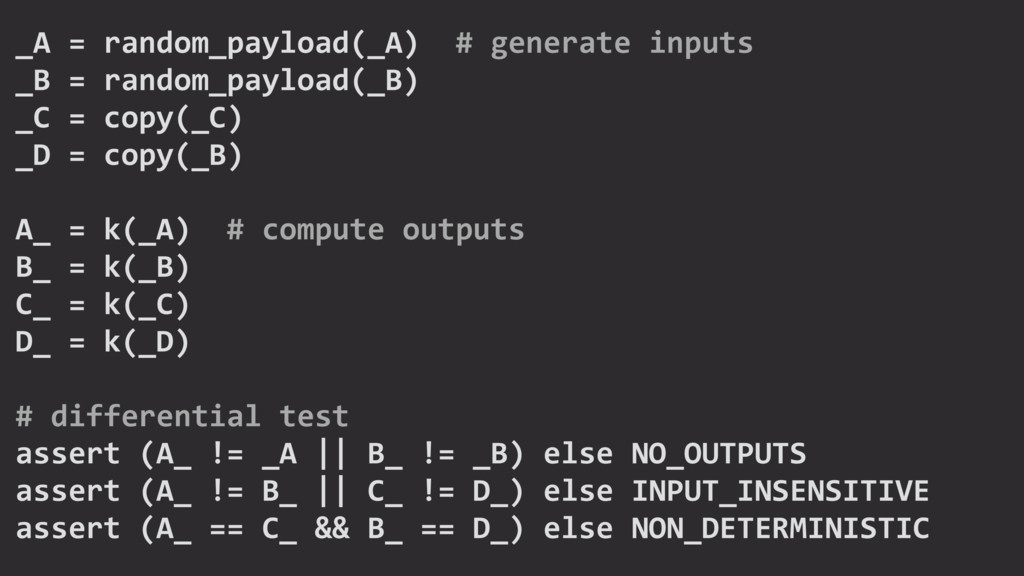{kind=link}
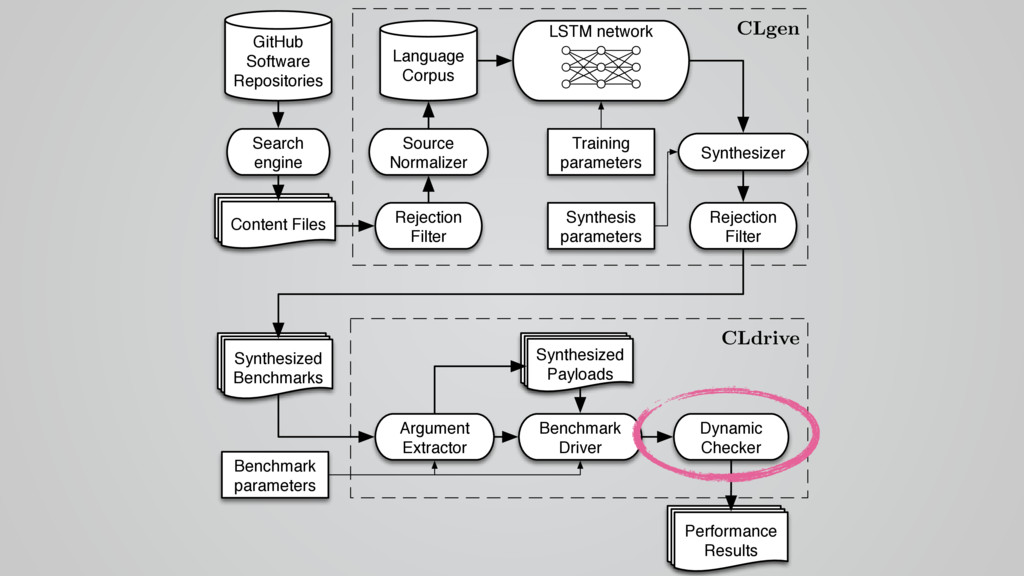{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}