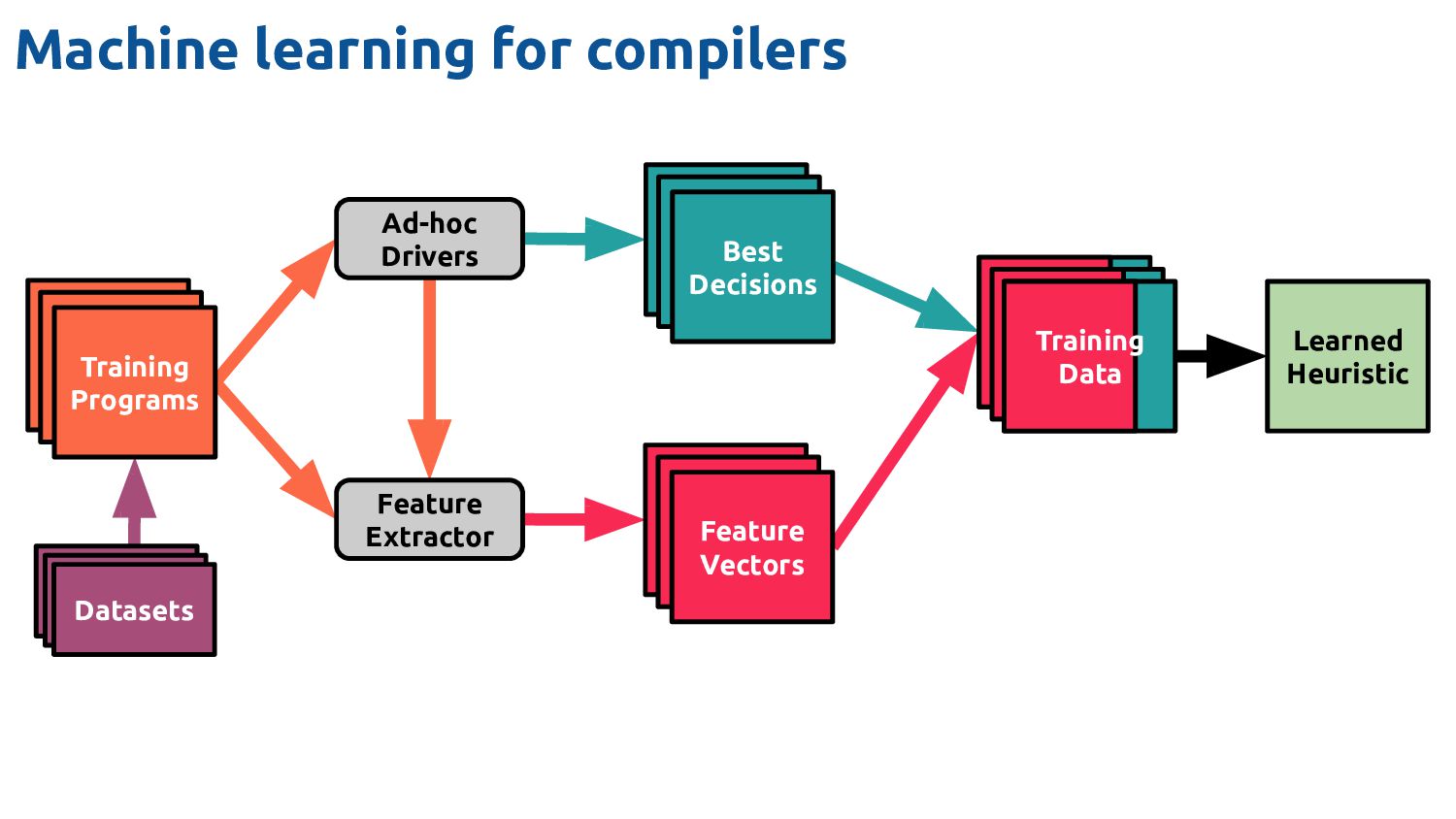
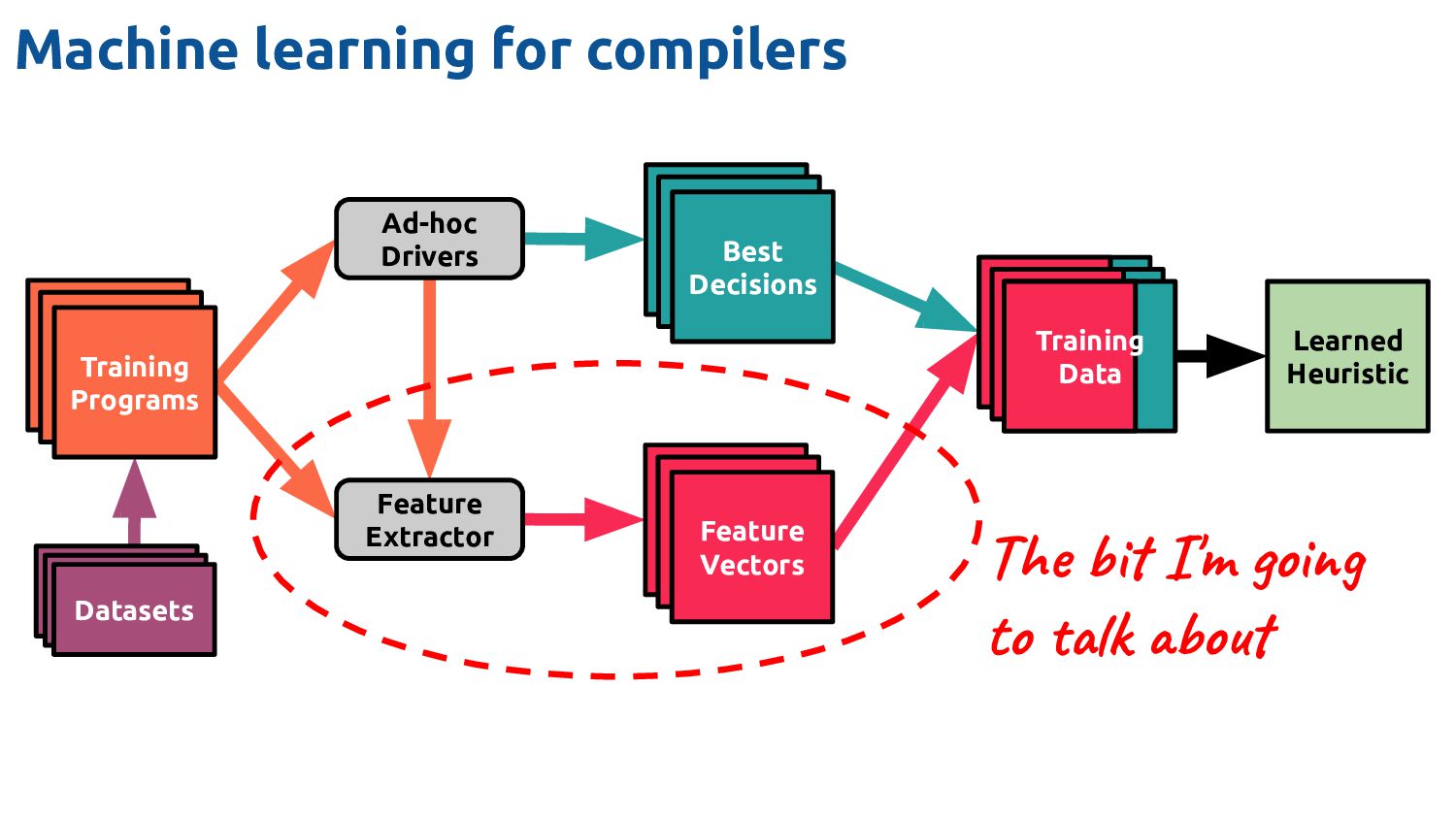
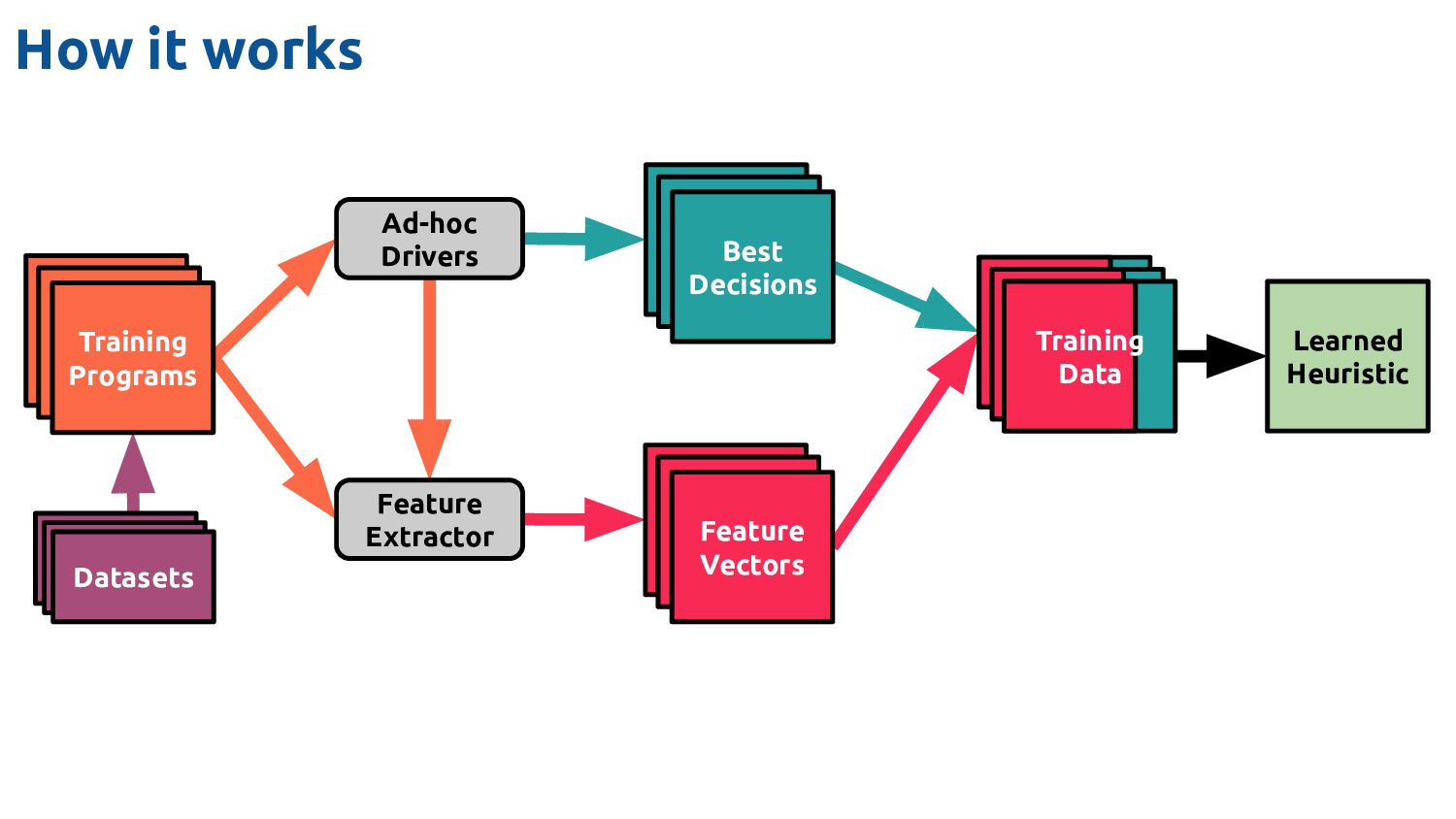
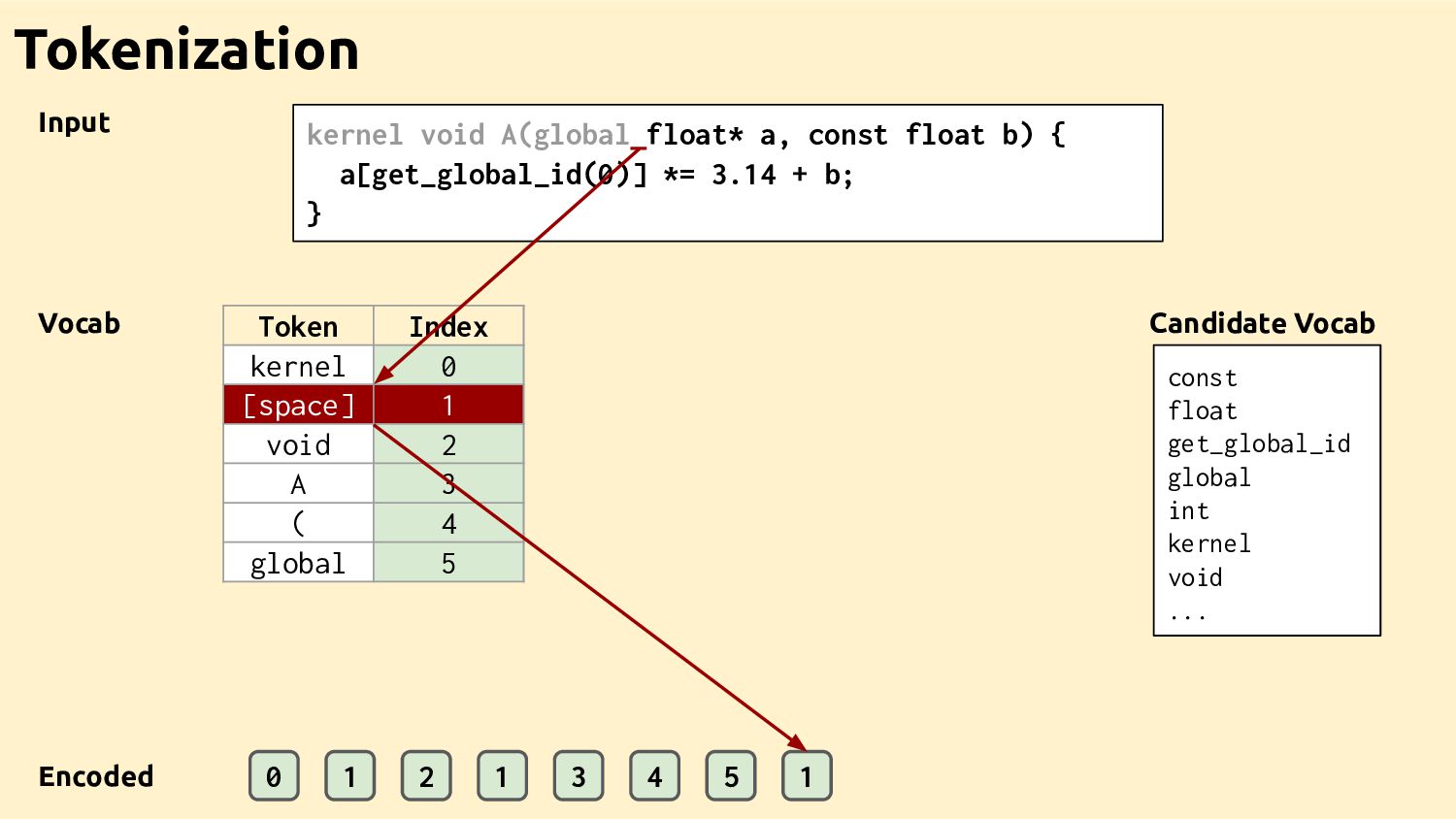
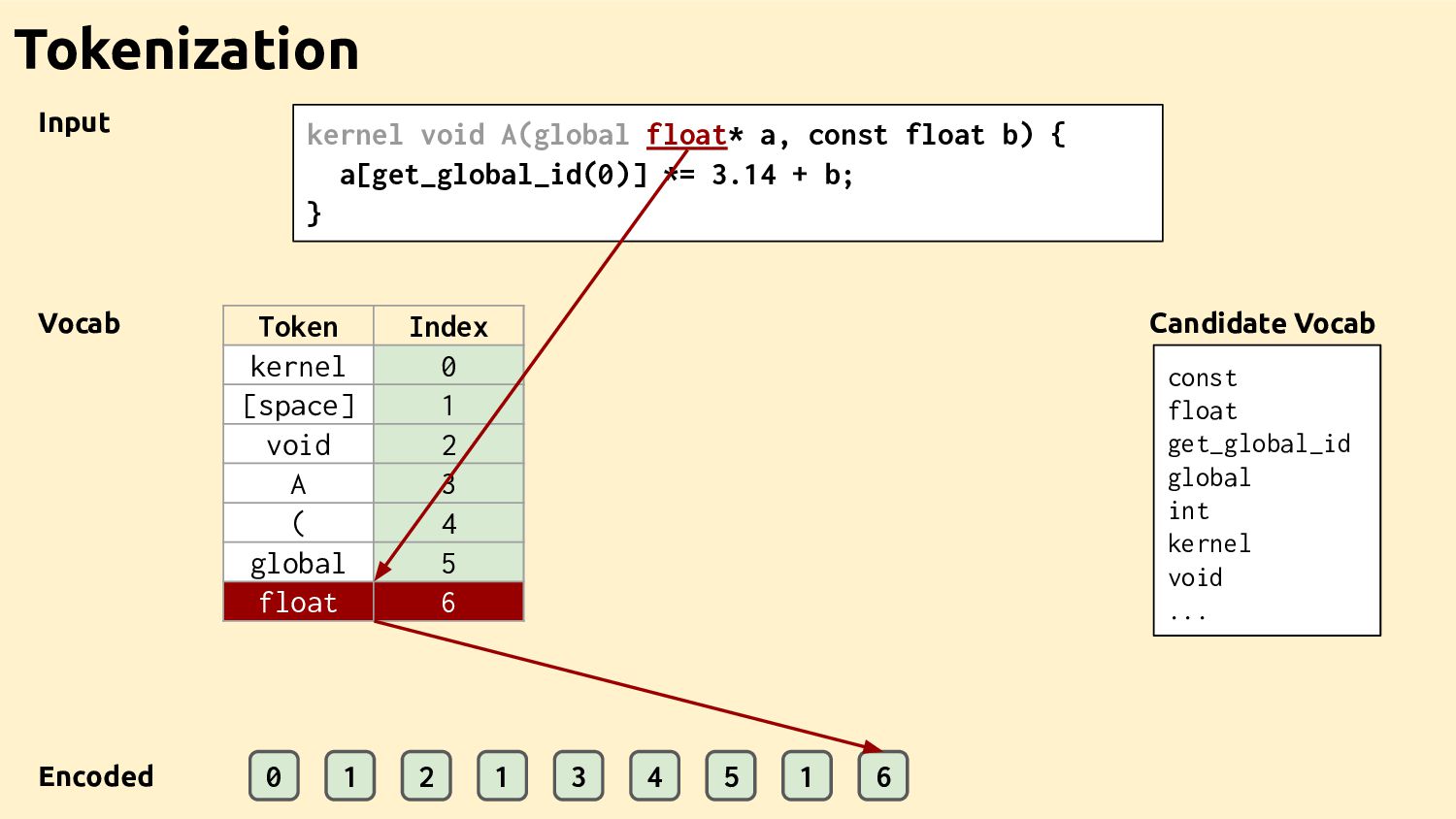
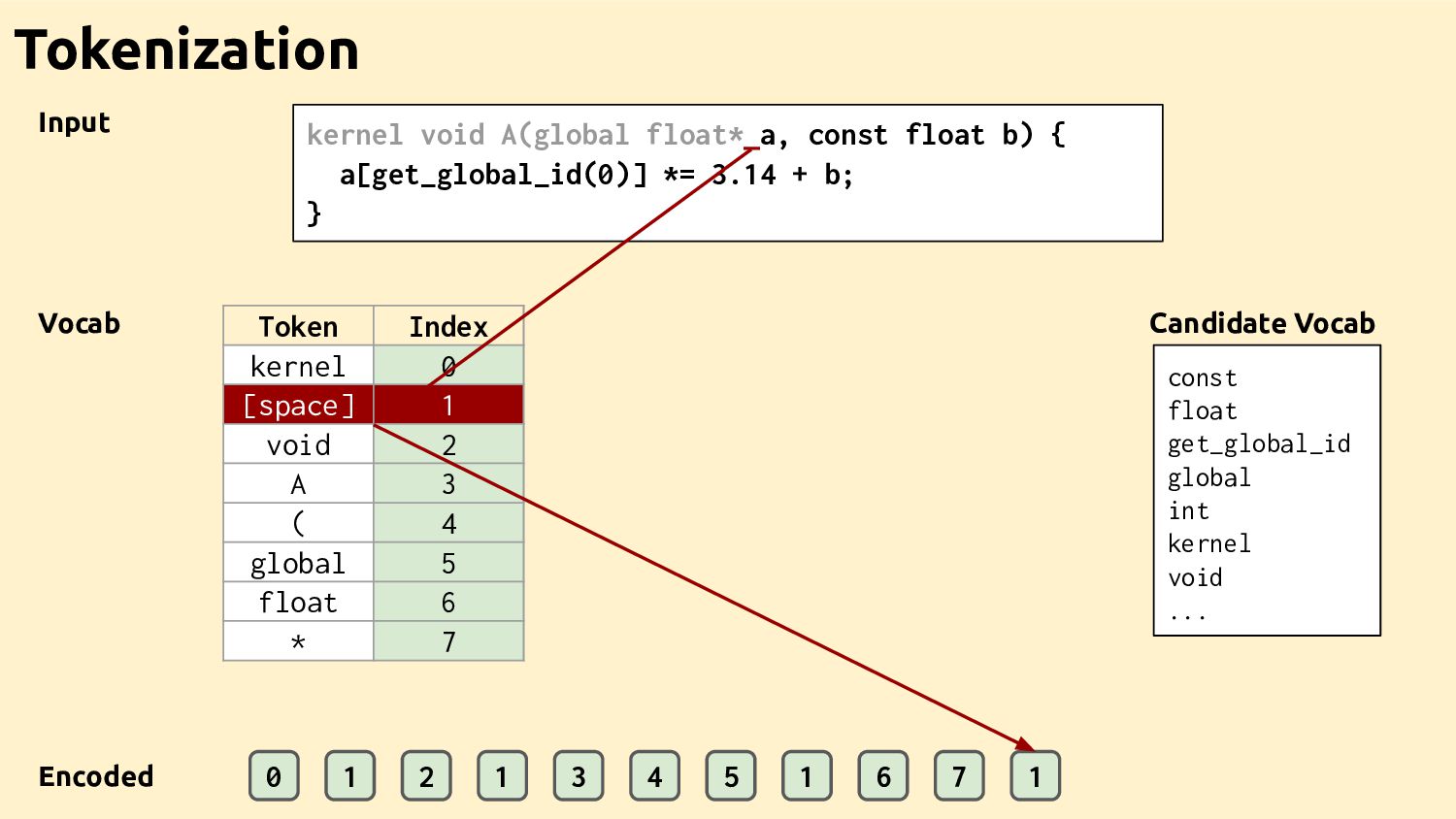
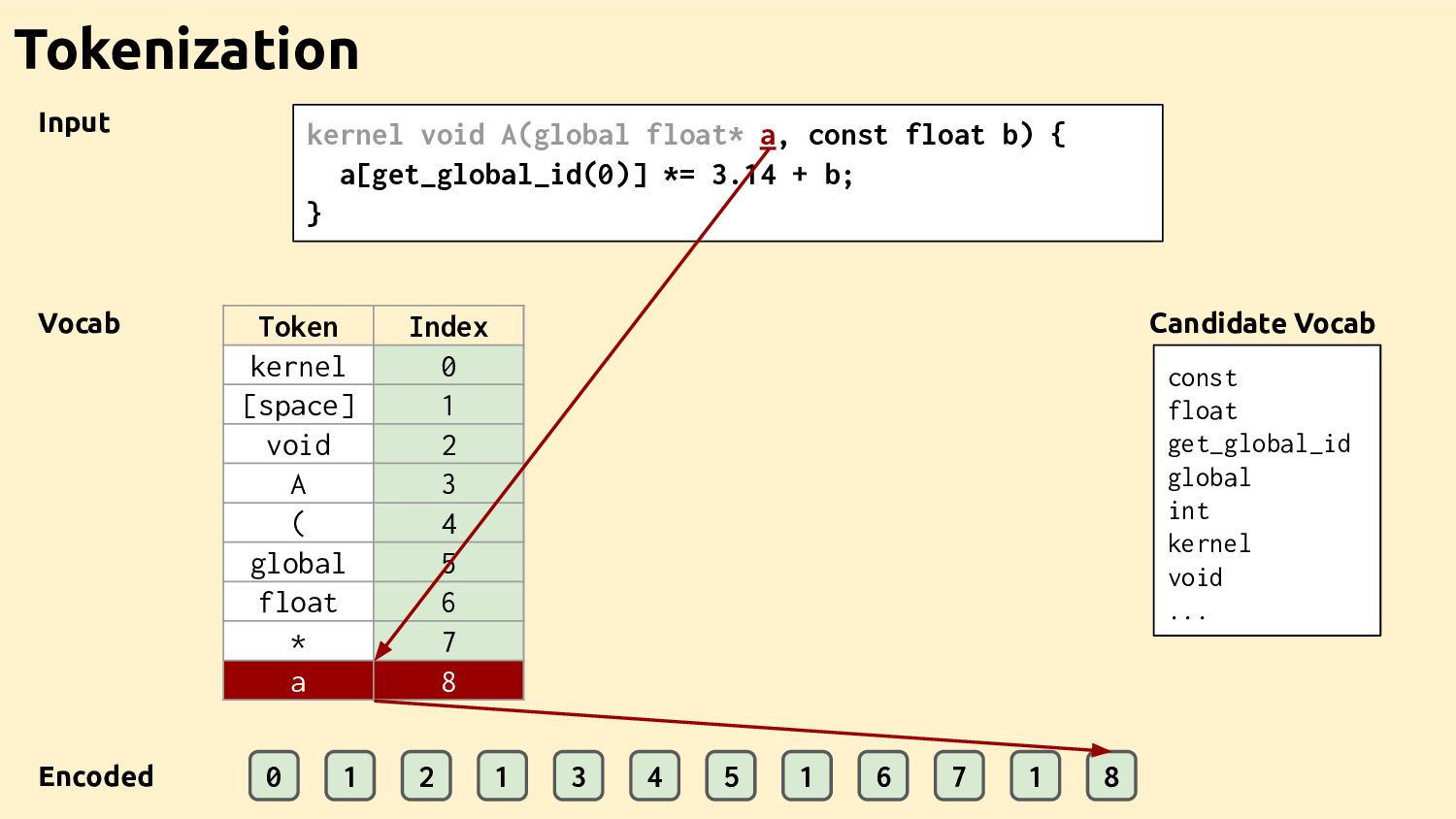
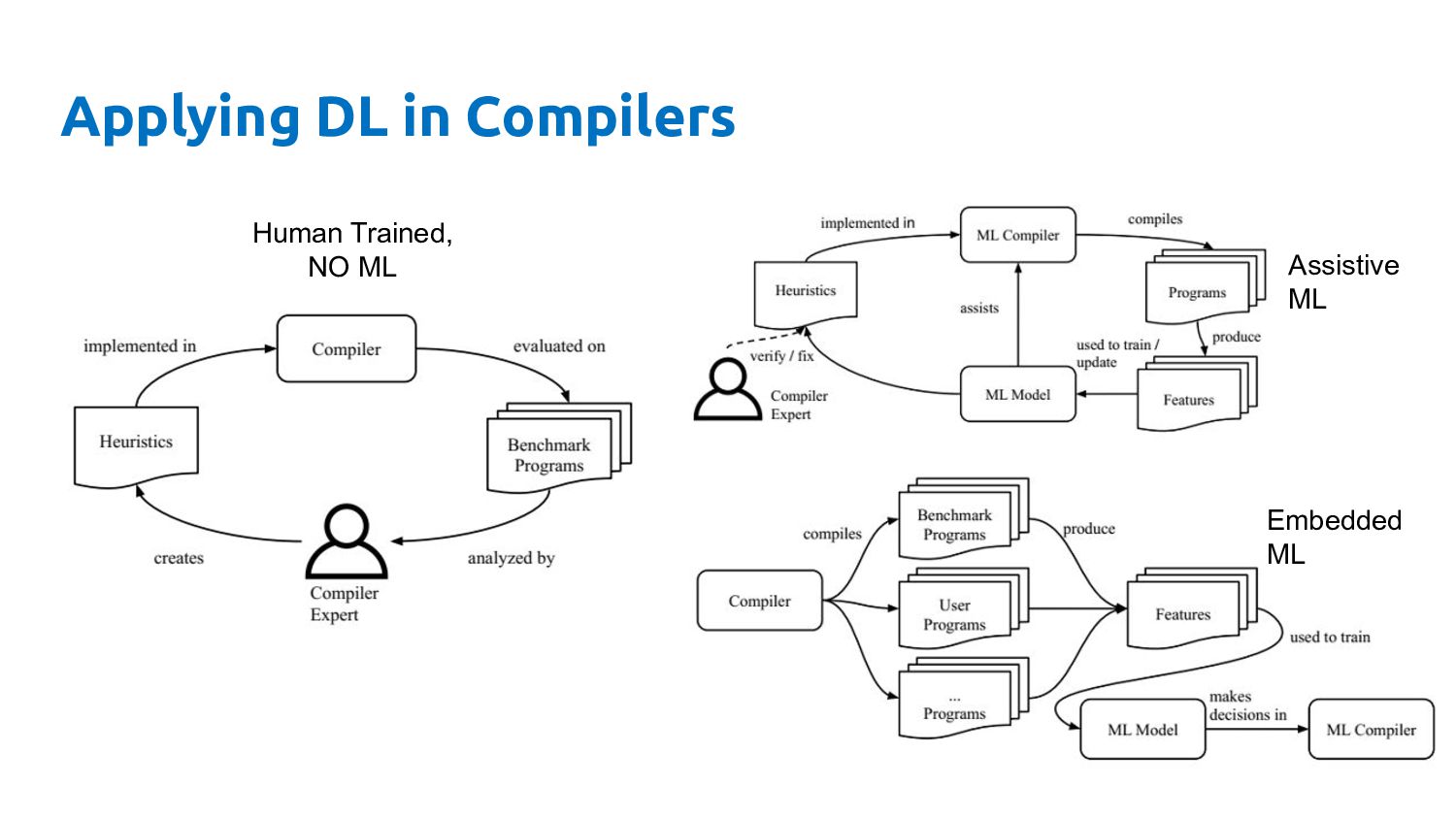
Datasets Feature Vectors Feature Vectors Best Decisions Feature Vectors Feature Vectors Feature Vectors Ad-hoc Drivers Training Data Feature Extractor Learned Heuristic Machine learning for compilers The bit I'm going to talk about
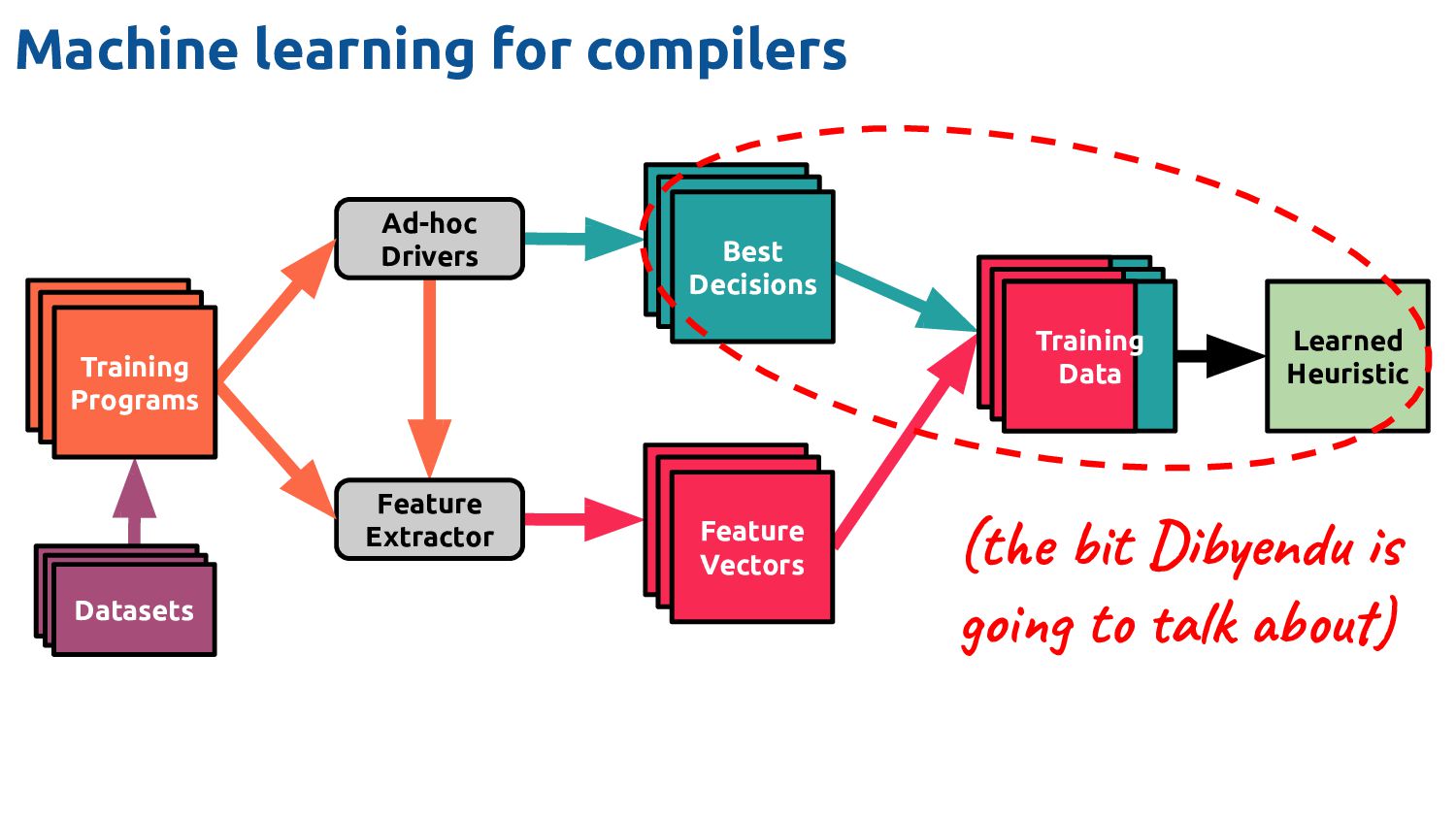
Feature Vectors Ad-hoc Drivers Training Data Feature Extractor Learned Heuristic Machine learning for compilers (the bit Dibyendu is going to talk about) Feature Vectors Feature Vectors Training Programs Feature Vectors Feature Vectors Datasets
Learning Approach (2022) Cummins et. al. End-to-end Deep Learning of Optimization Heuristics (2017) Cummins et. al. ProGraML: A Graph-based Program Representation for Data Flow Analysis and Compiler Optimizations (2021) Three approaches to program representation 1. Handcrafted features 2. Language Modeling 3. Graph Reasoning
Learning Approach (2022) Cummins et. al. End-to-end Deep Learning of Optimization Heuristics (2017) Cummins et. al. ProGraML: A Graph-based Program Representation for Data Flow Analysis and Compiler Optimizations (2021) Three approaches to program representation 1. Handcrafted features 2. Language Modeling 3. Graph Reasoning
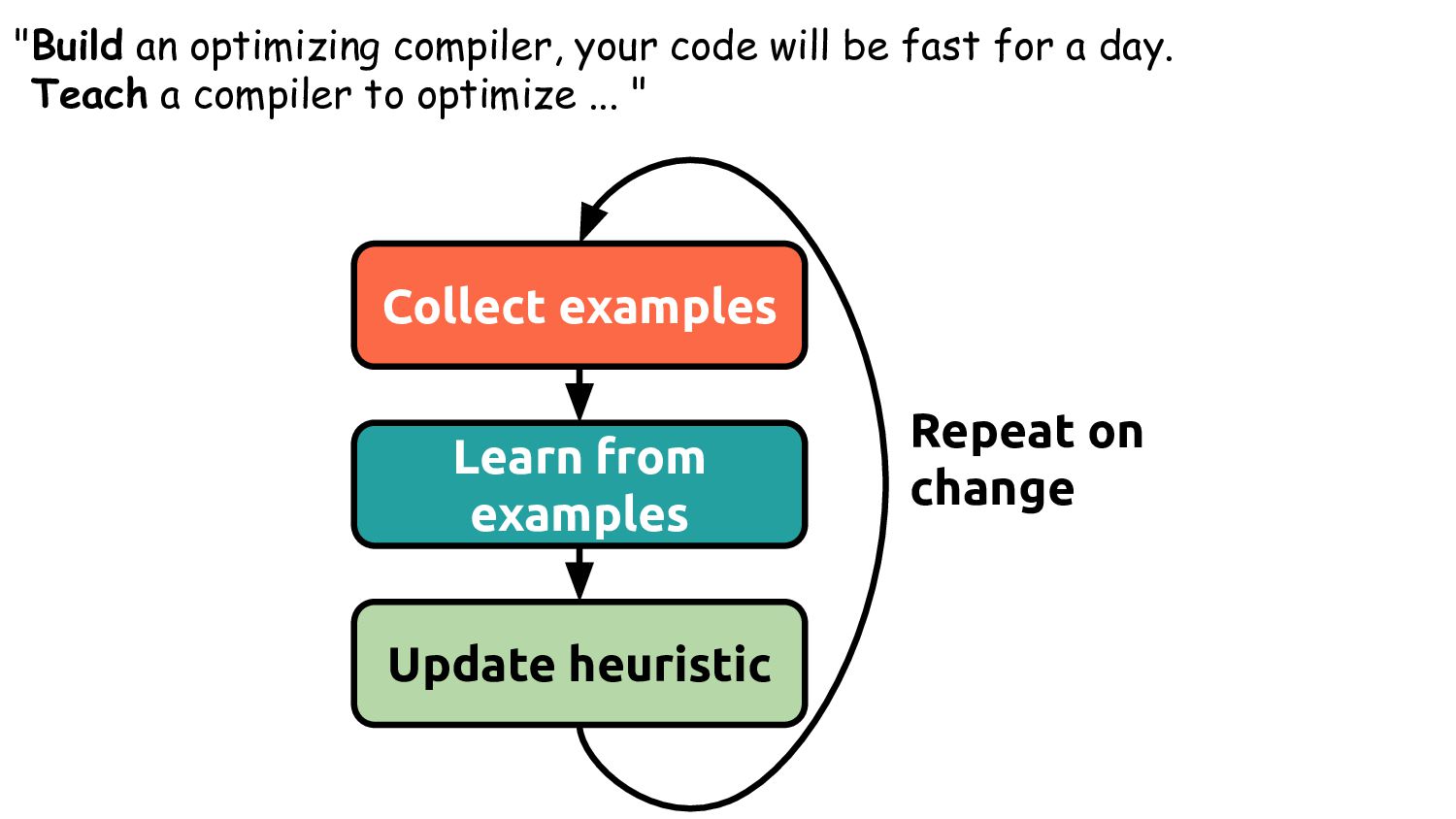
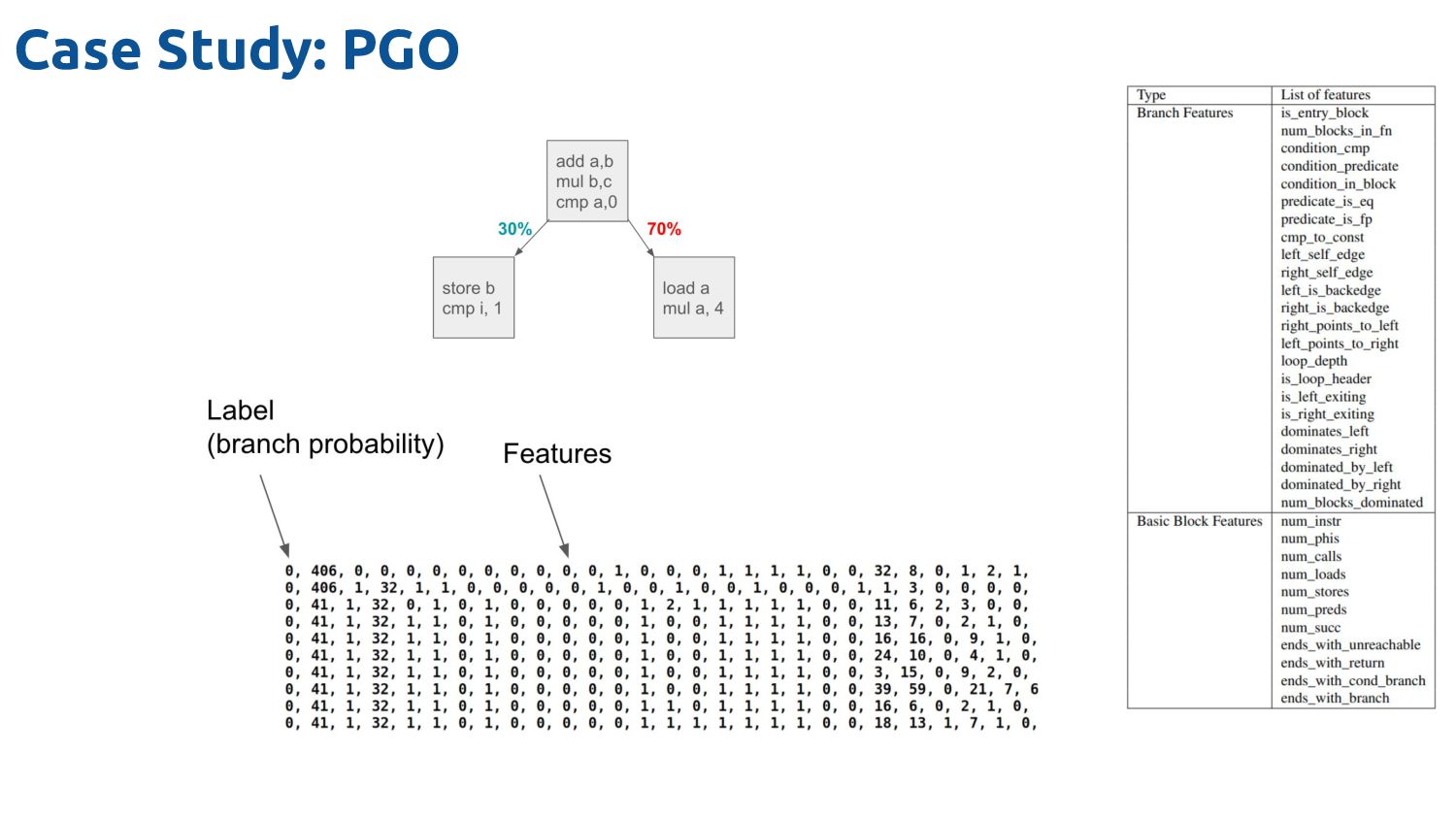
steps • LLVM has a set of hard coded rules that predict things • Developed by dozens of engineers, using thousands of lines of code, over a decade Case Study: PGO
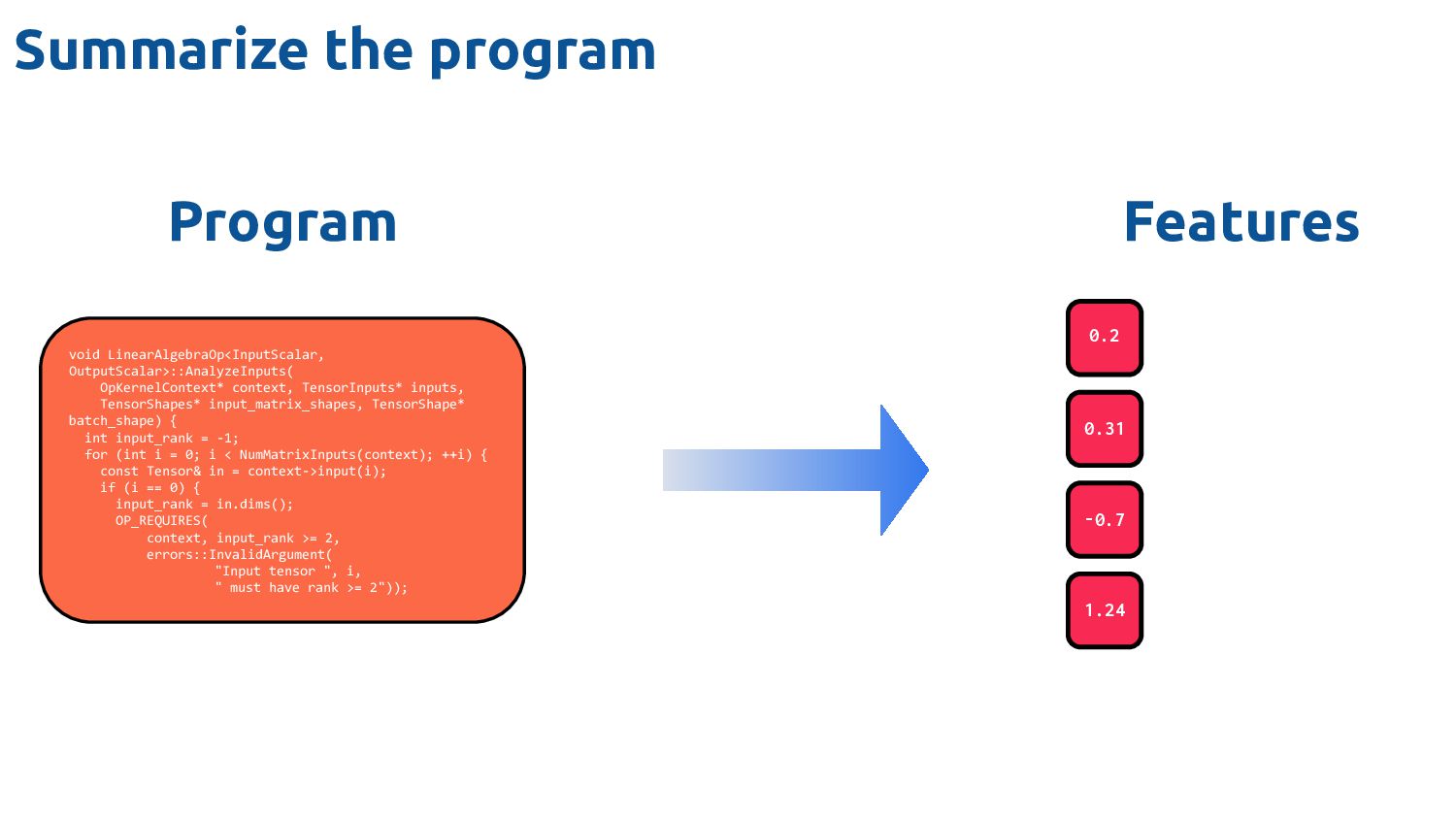
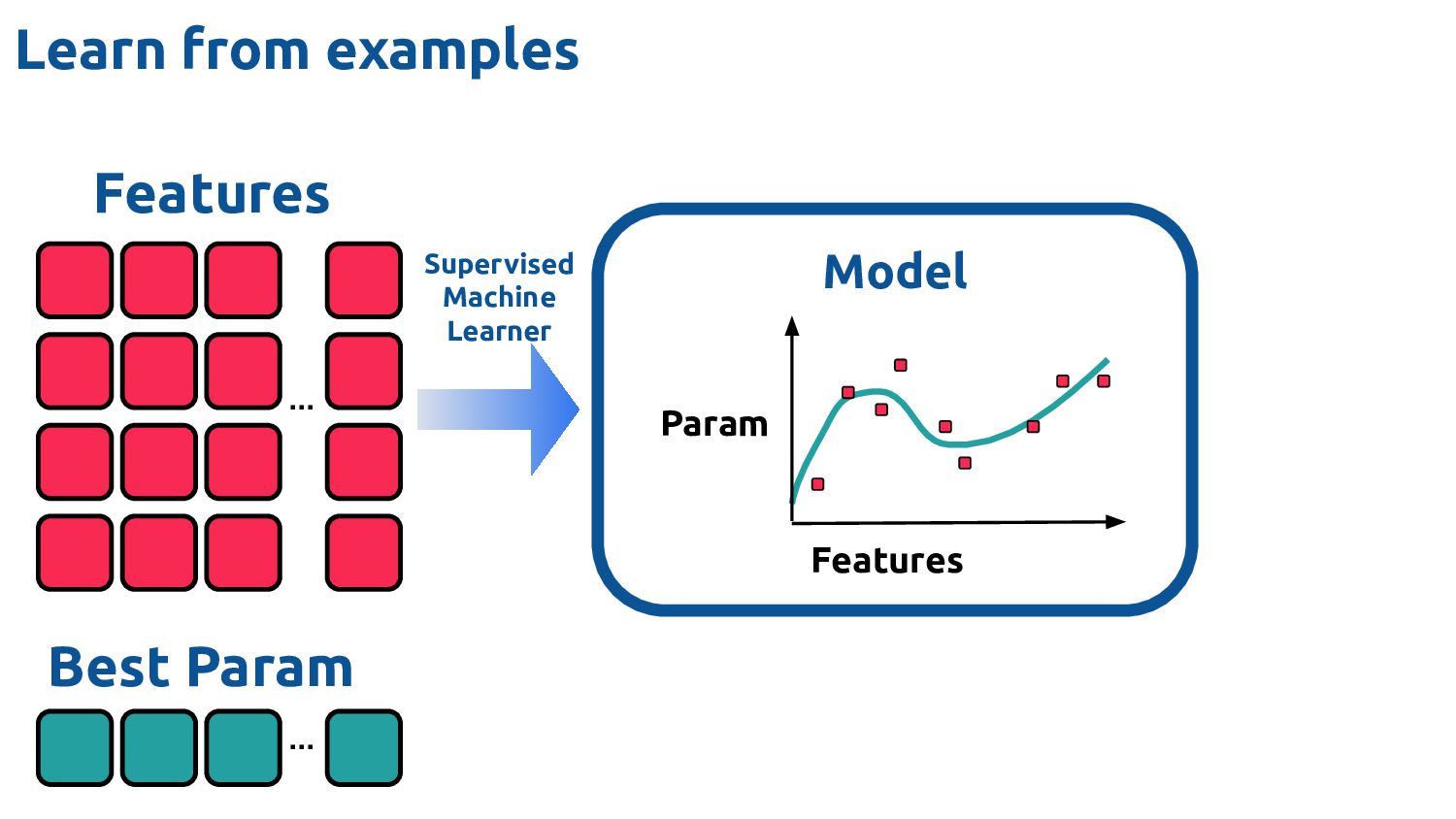
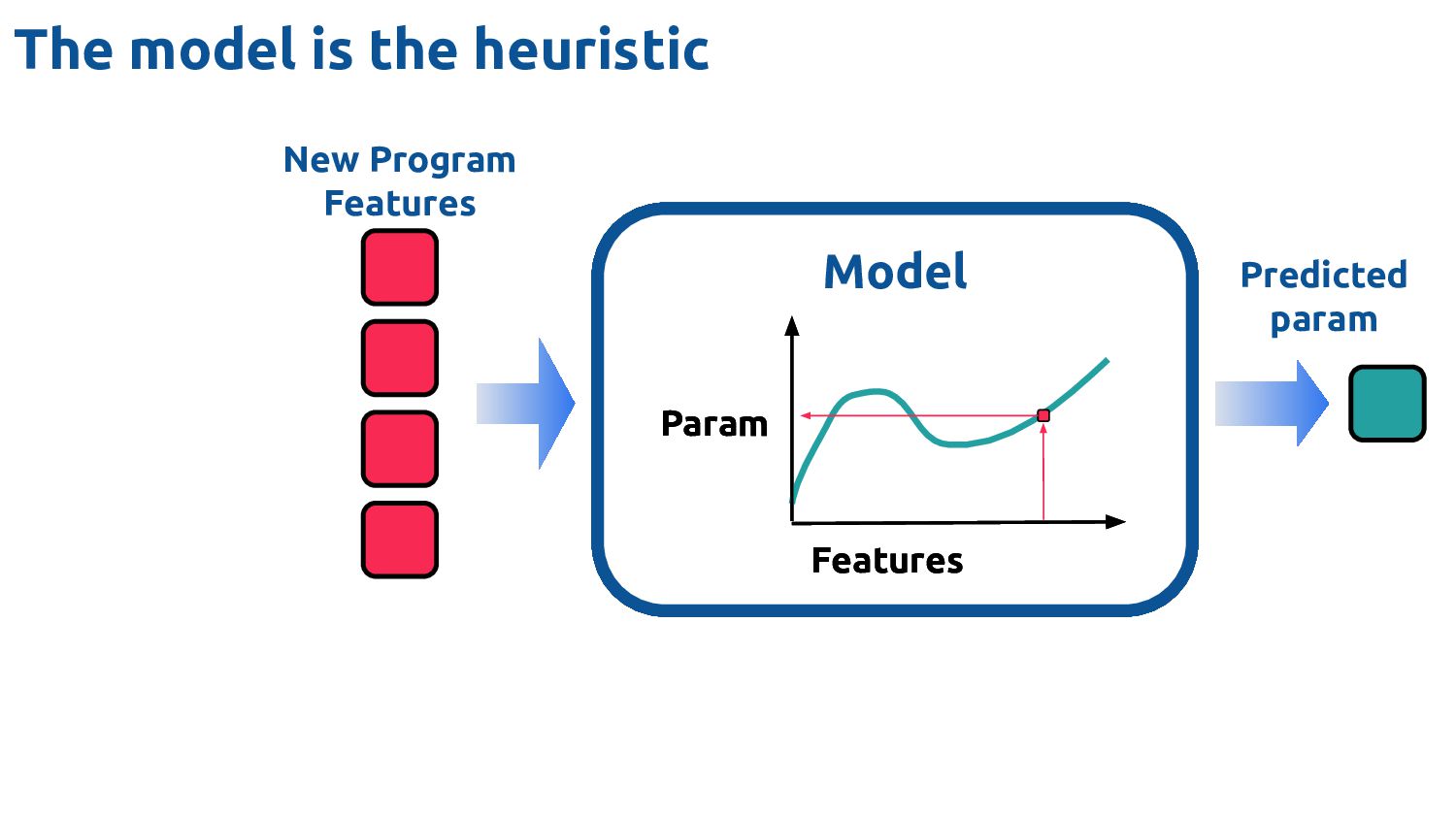
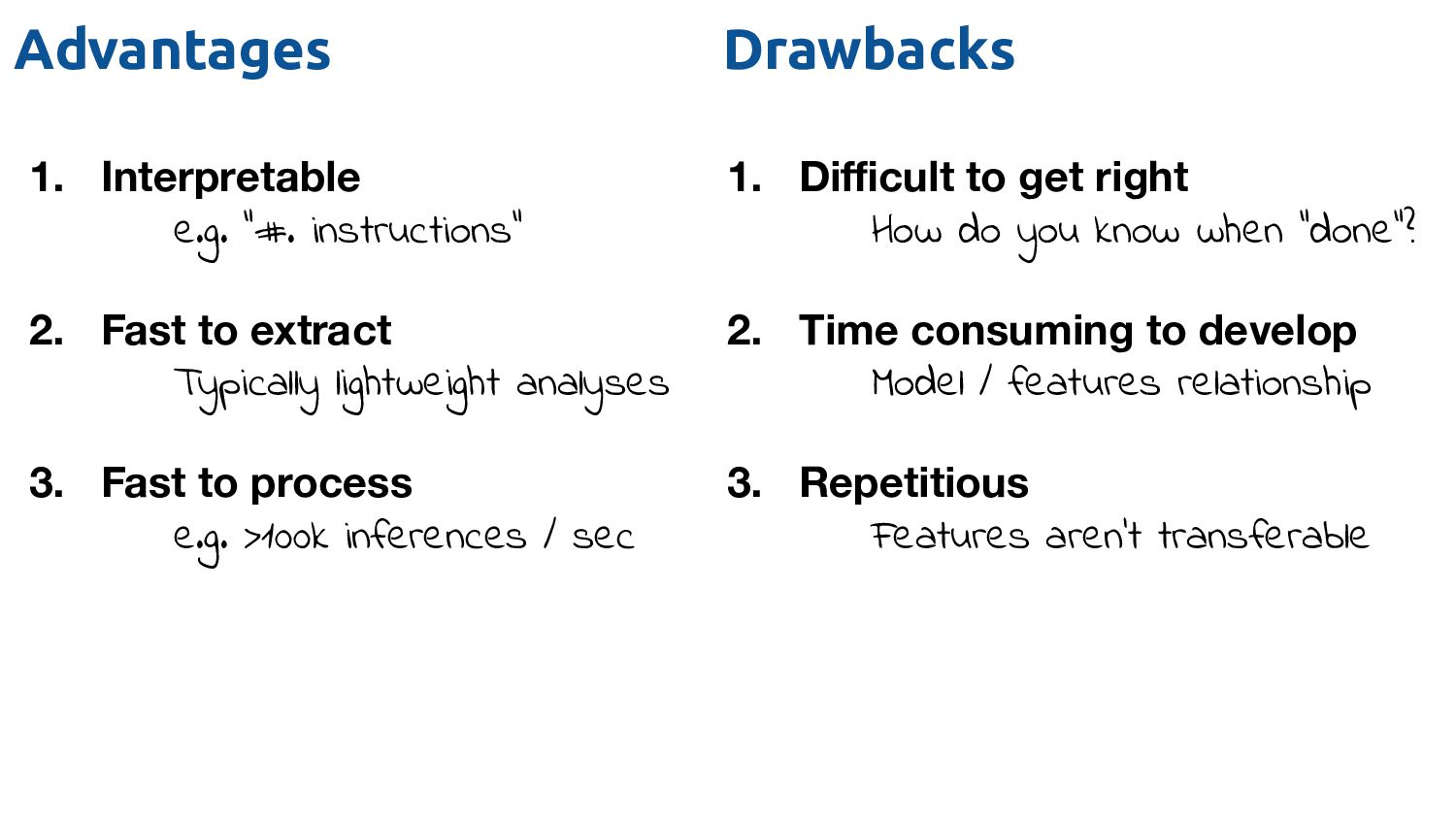
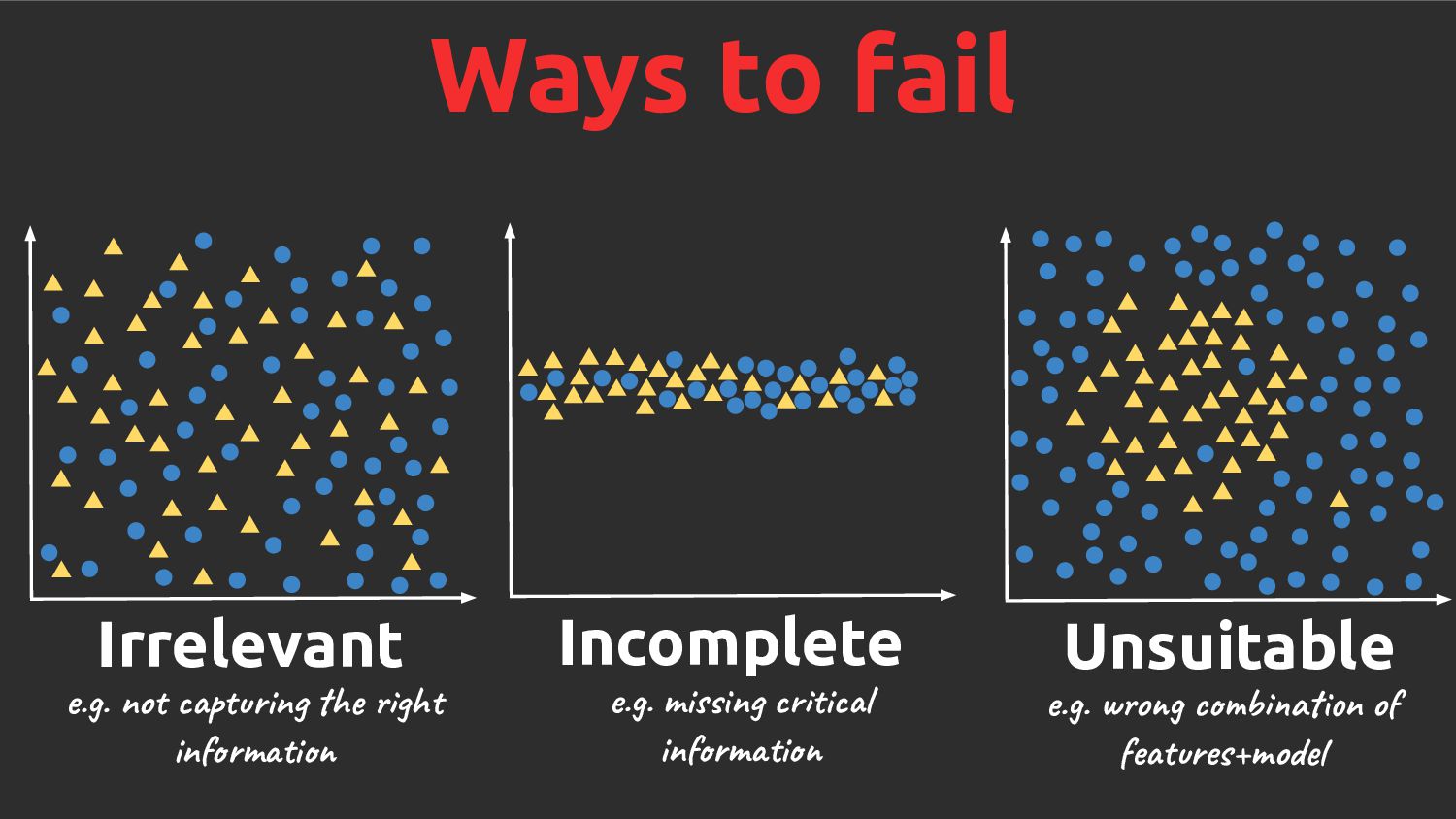
extract Typically lightweight analyses 3. Fast to process e.g. >100k inferences / sec 1. Difficult to get right How do you know when "done"? 2. Time consuming to develop Model / features relationship 3. Repetitious Features aren't transferable
Learning Approach (2022) Cummins et. al. End-to-end Deep Learning of Optimization Heuristics (2017) Cummins et. al. ProGraML: A Graph-based Program Representation for Data Flow Analysis and Compiler Optimizations (2021) Three approaches to program representation 1. Handcrafted features 2. Language Modeling 3. Graph Reasoning
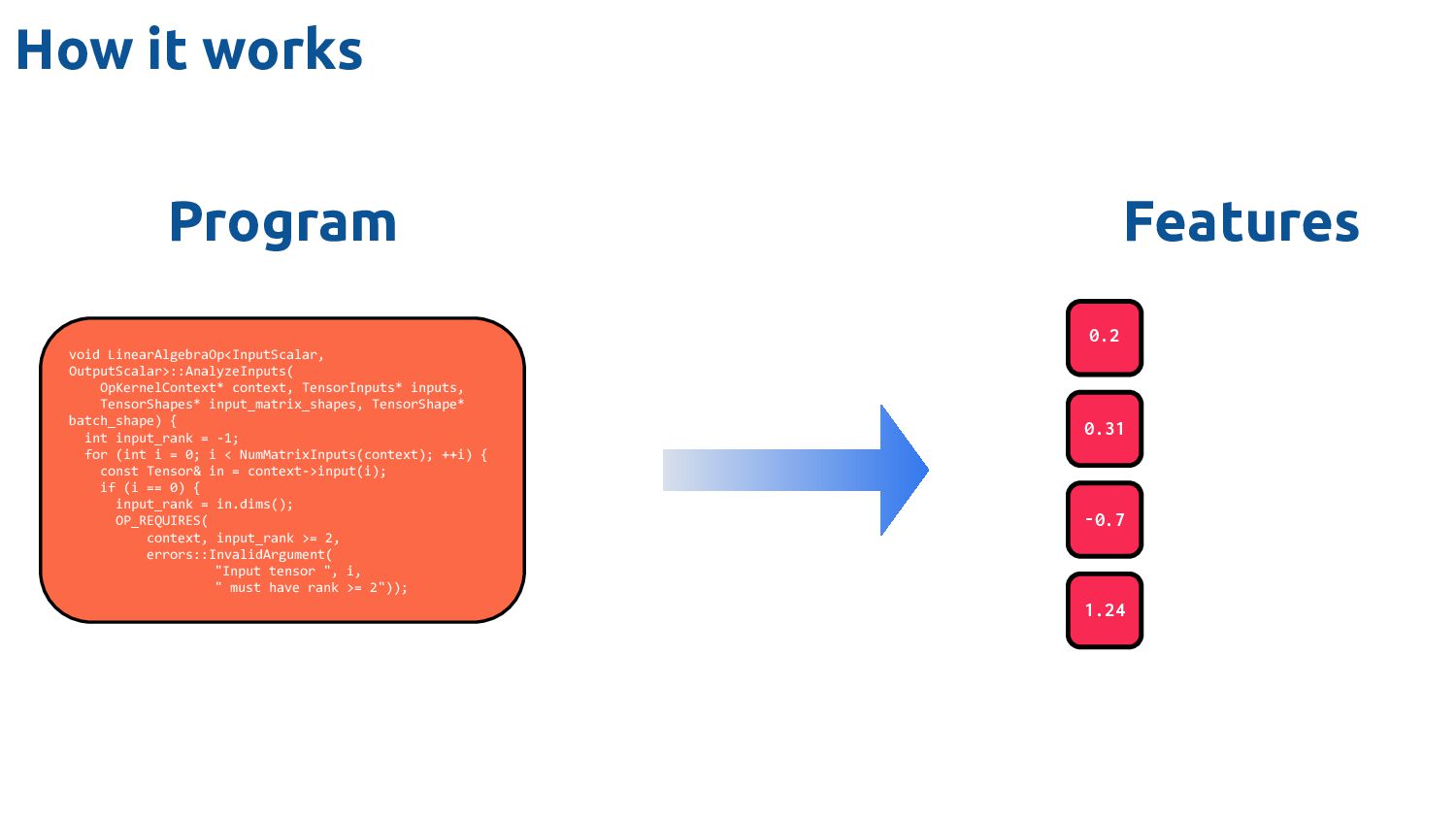
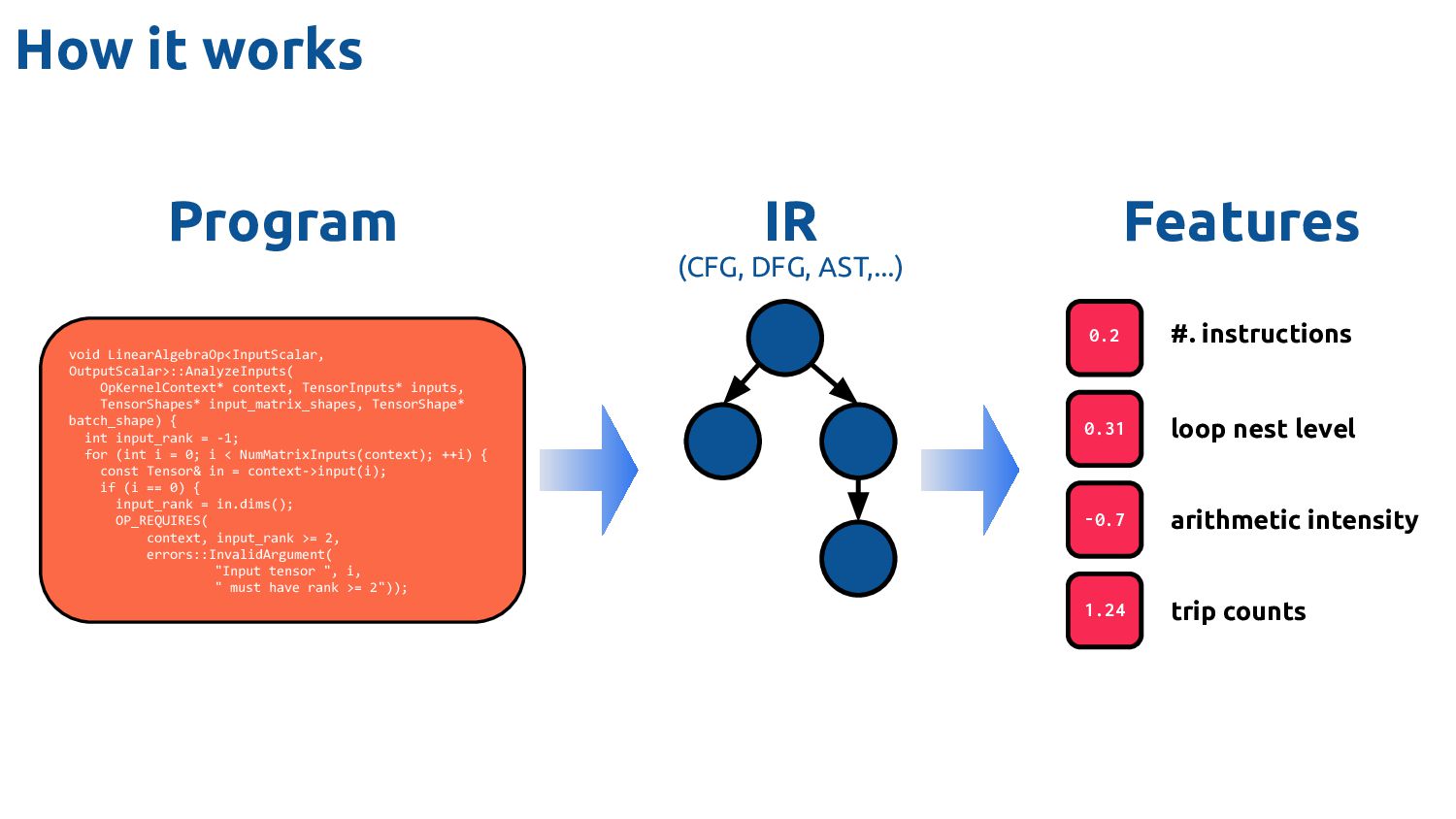
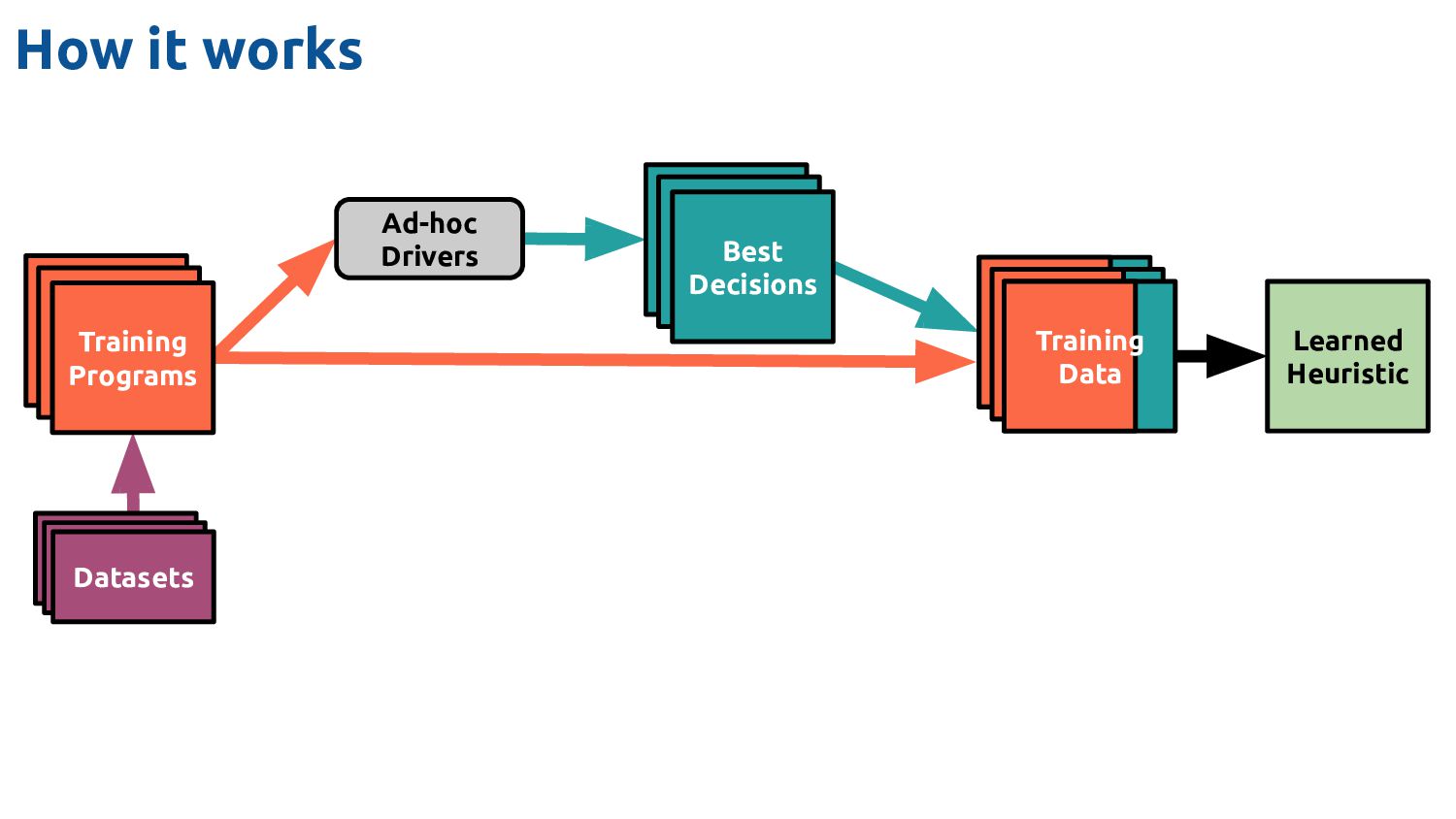
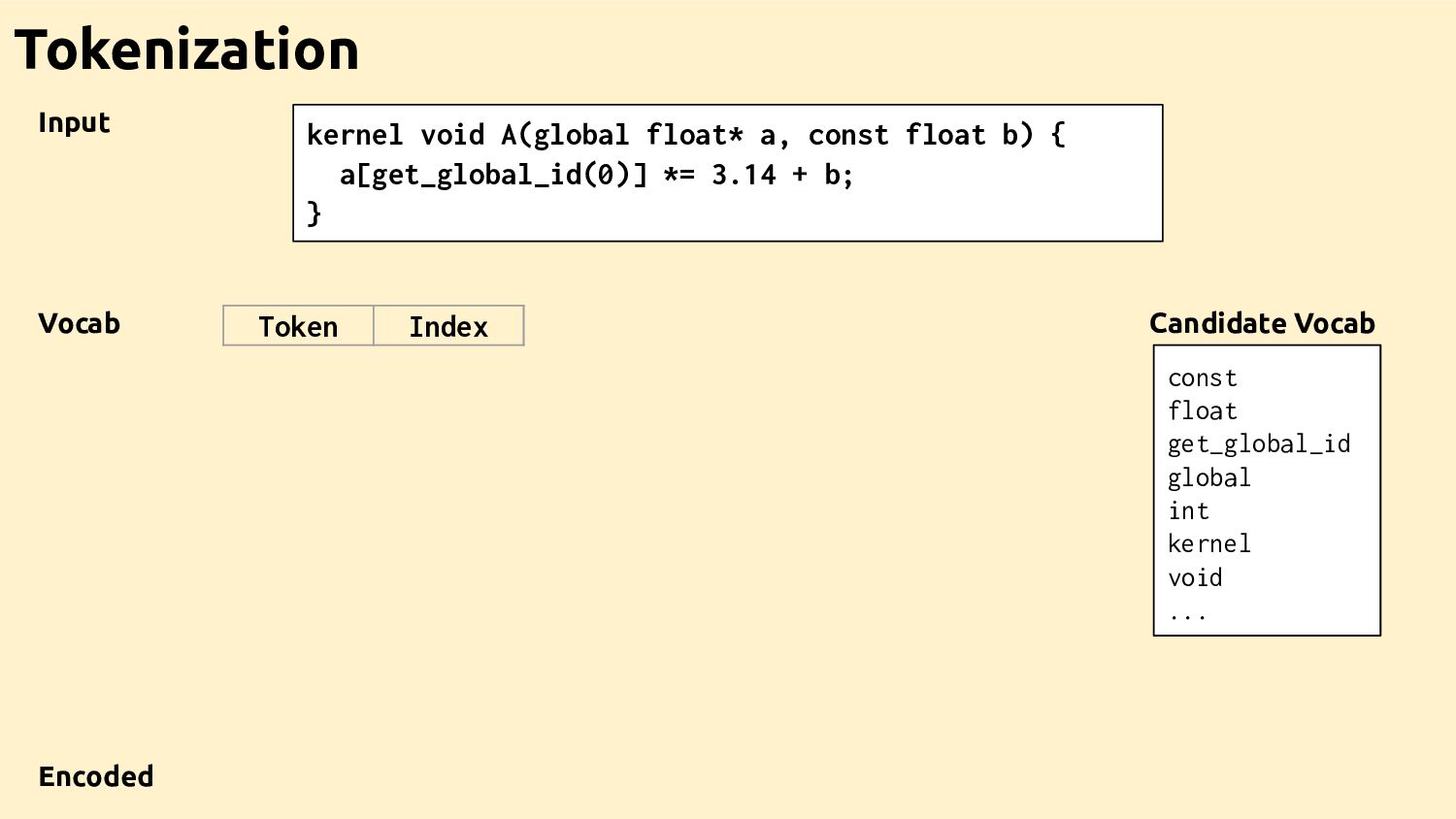
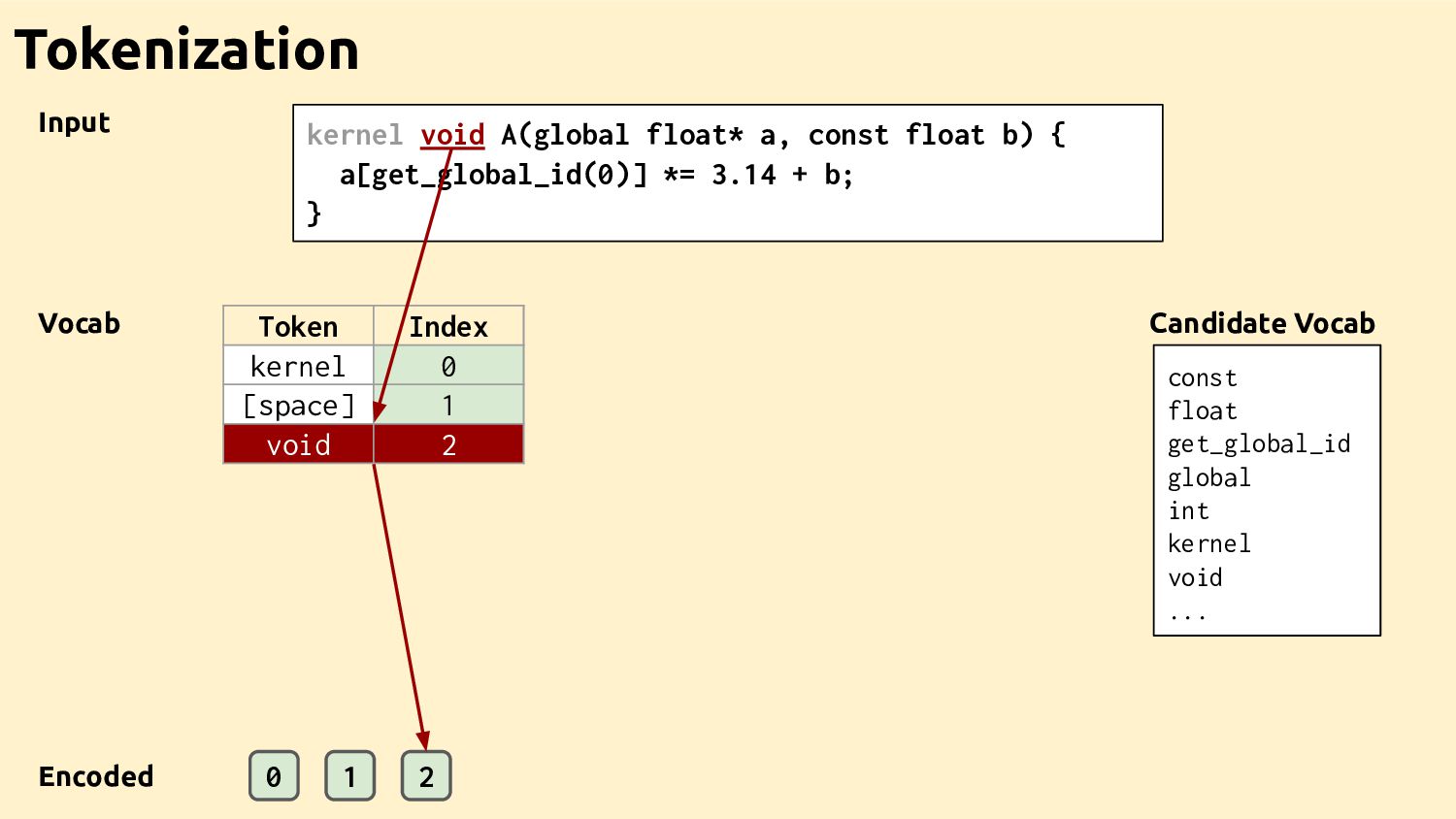
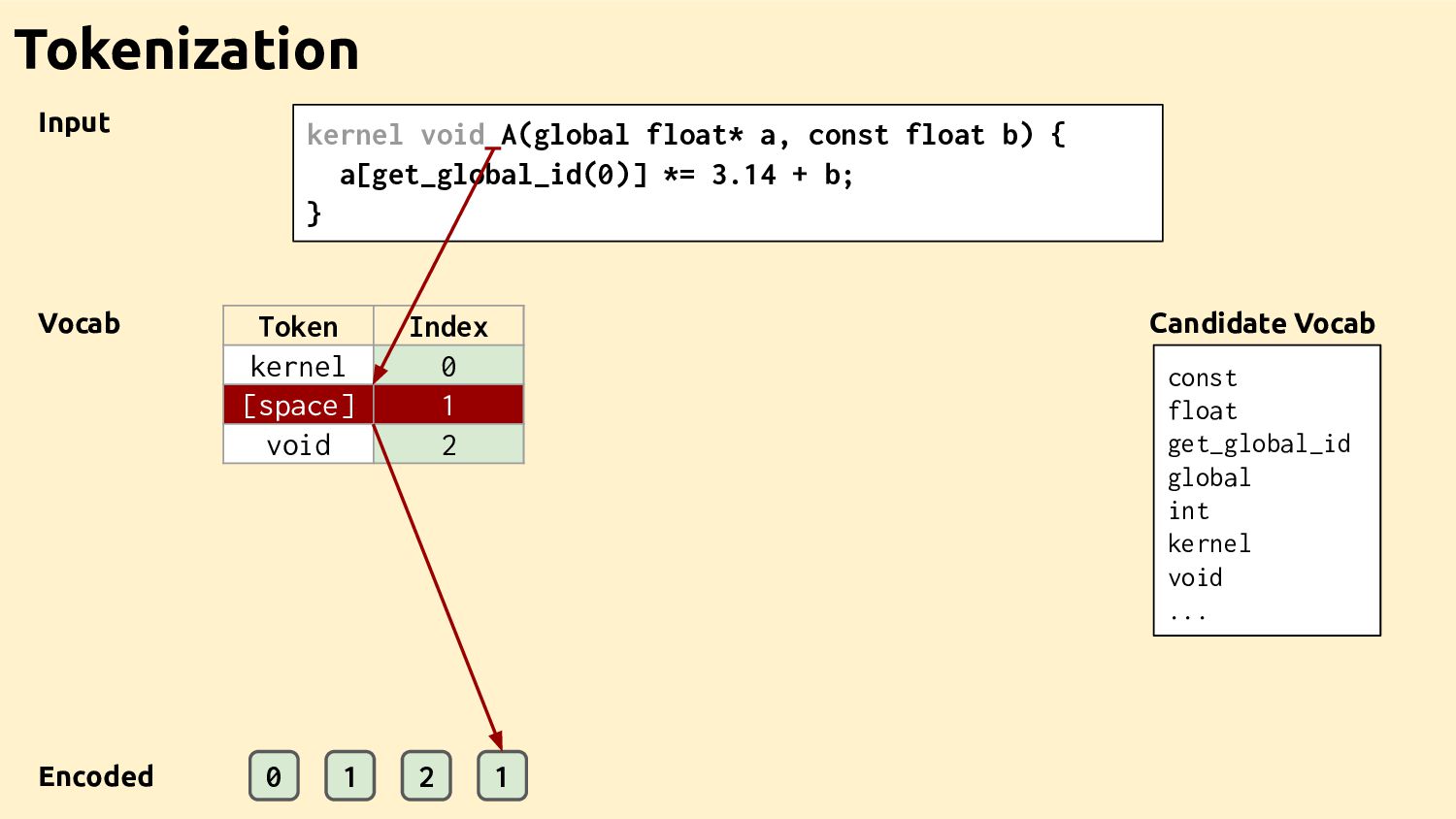
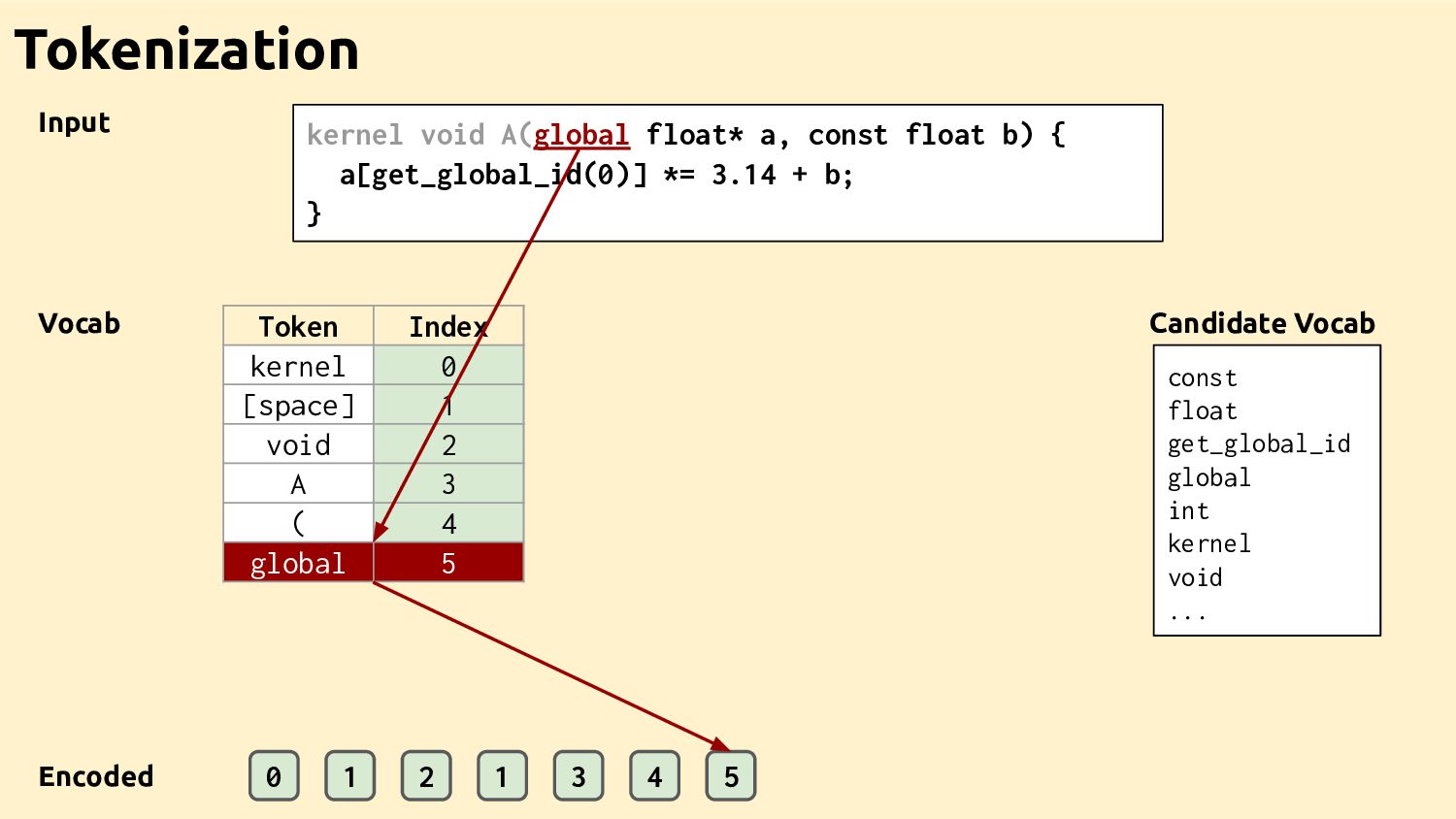
Feature Vectors Feature Vectors Feature Vectors Training Programs Feature Vectors Feature Vectors Datasets Ad-hoc Drivers Training Data Feature Extractor Learned Heuristic How it works
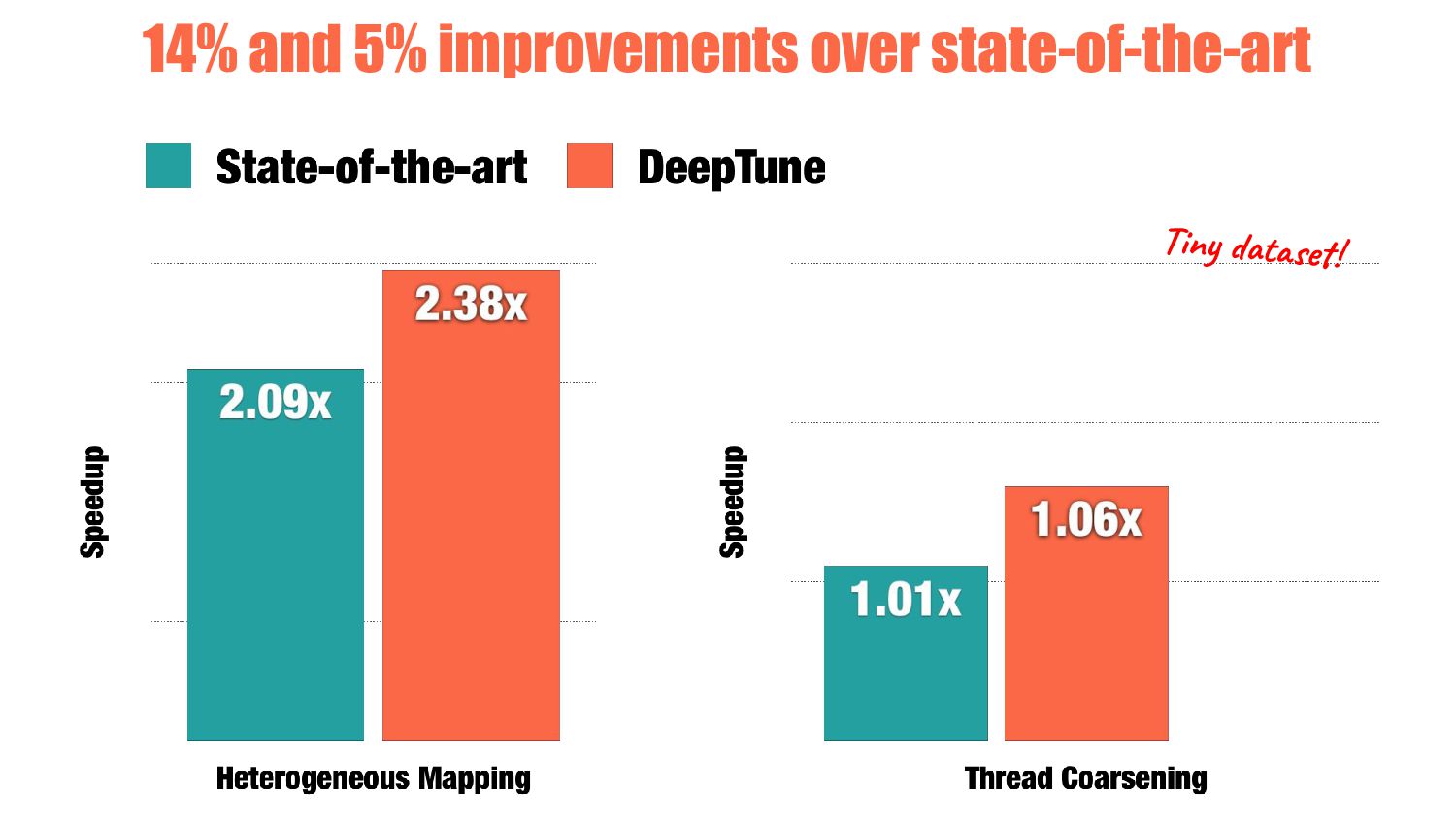
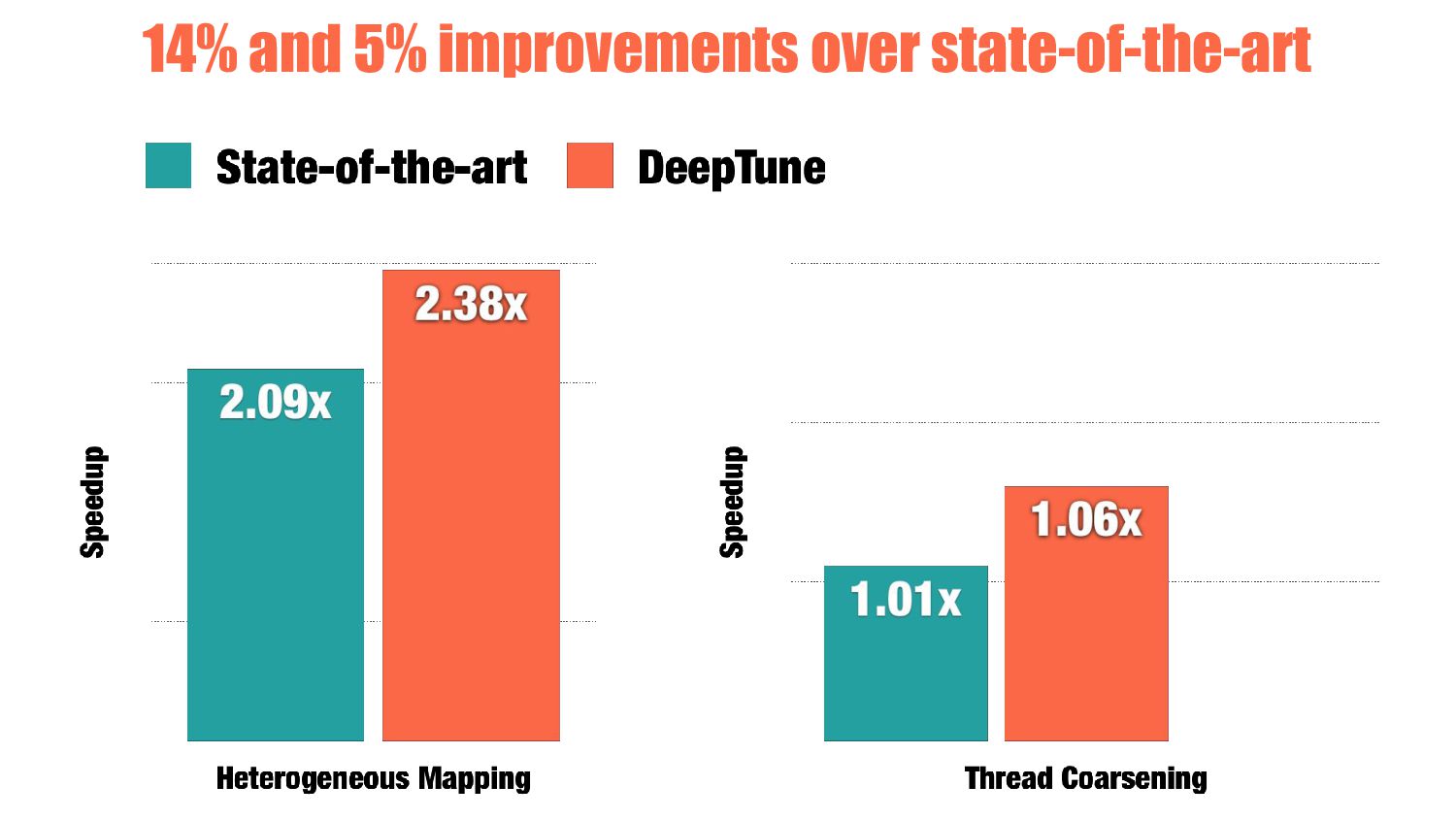
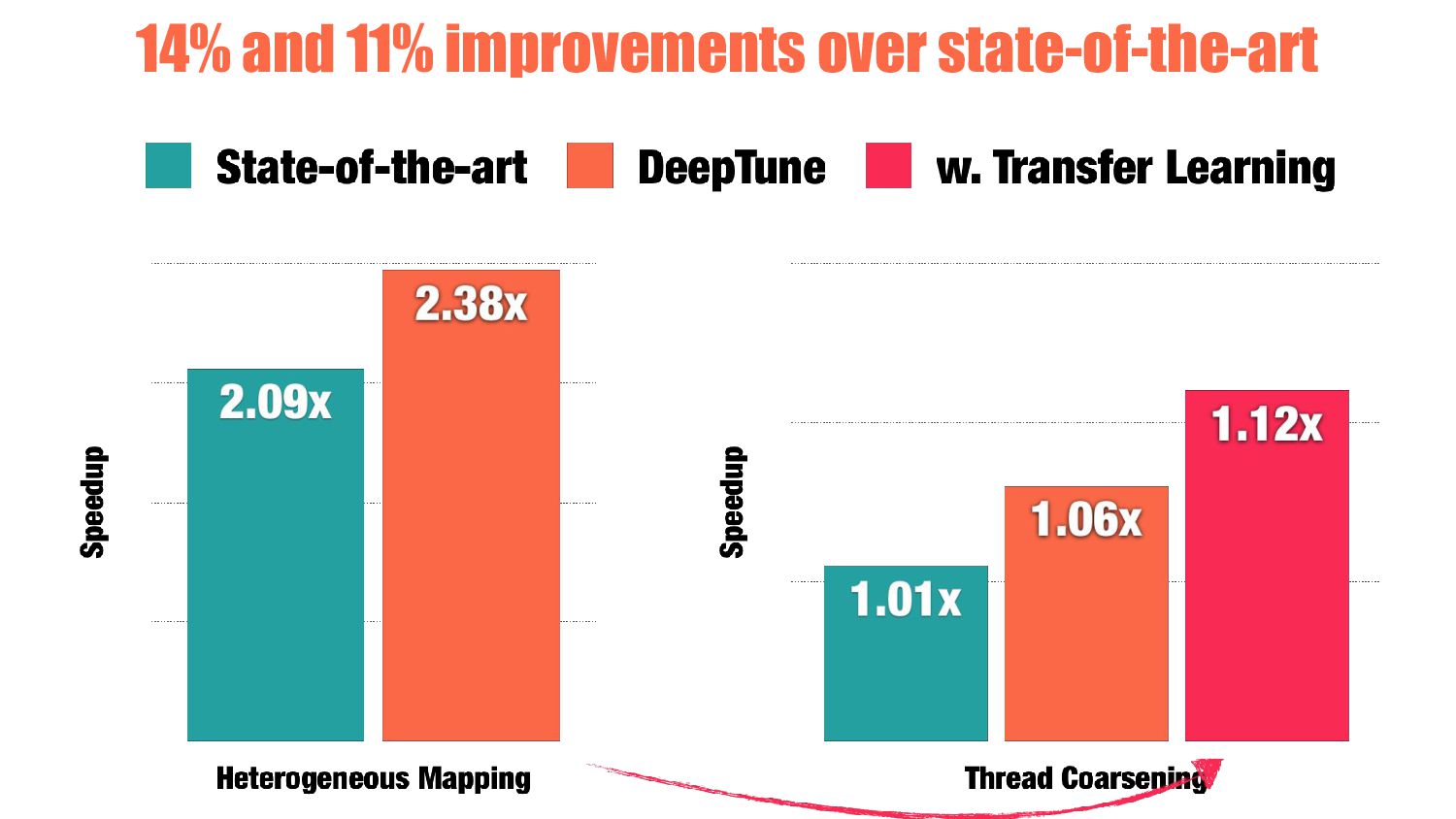
classification One-of-six classification Neural Networks Decision Tree Cascading {CPU, GPU} {1, 2, 4, 8, 16, 32} Features 7 Principle Components of 34 raw features Combinations of values from ad-hoc LLVM analysis CGO’13 PACT’14 2x papers!
Learning Approach (2022) Cummins et. al. End-to-end Deep Learning of Optimization Heuristics (2017) Cummins et. al. ProGraML: A Graph-based Program Representation for Data Flow Analysis and Compiler Optimizations (2021) Three approaches to program representation 1. Handcrafted features 2. Language Modeling 3. Graph Reasoning
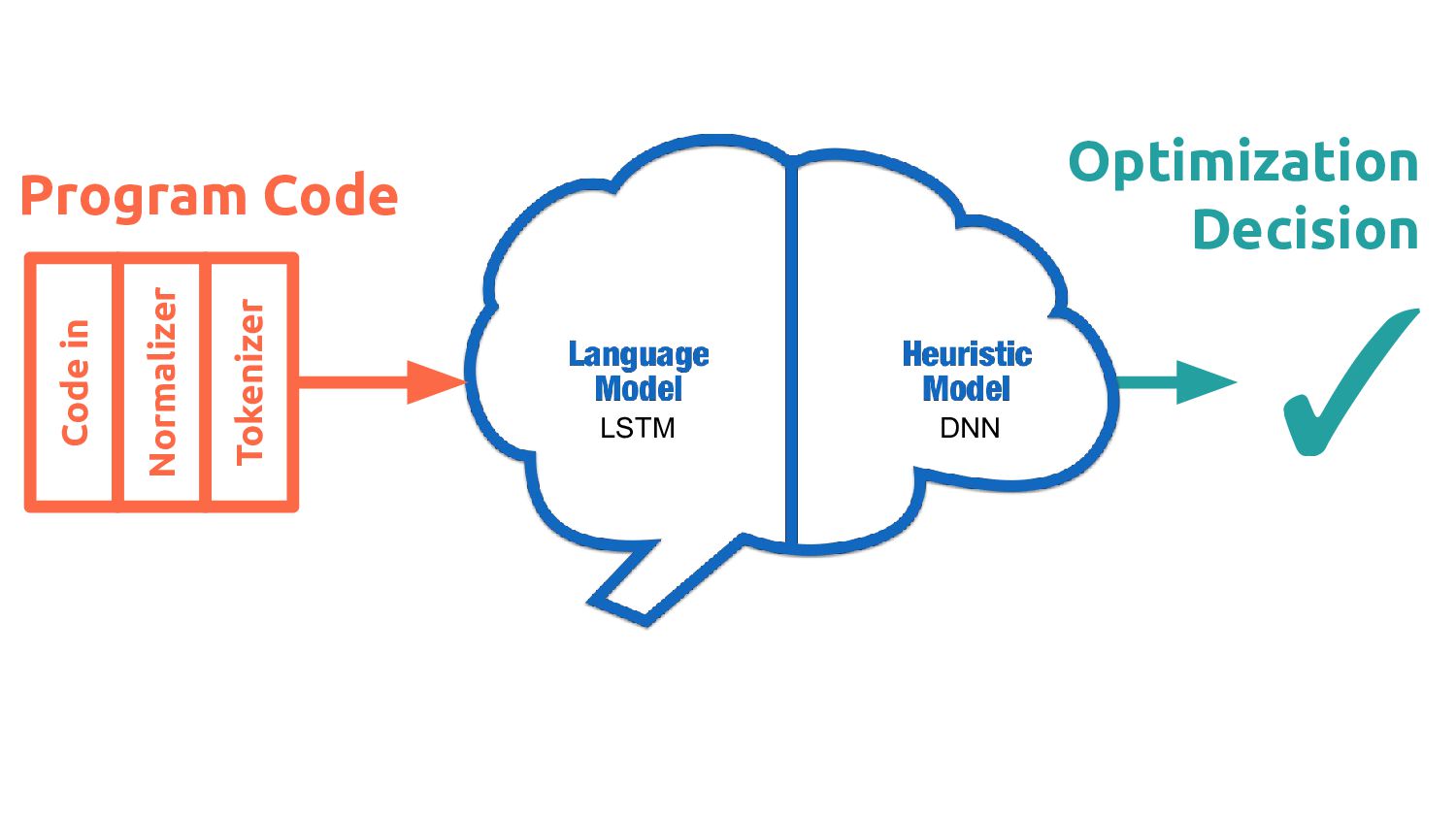
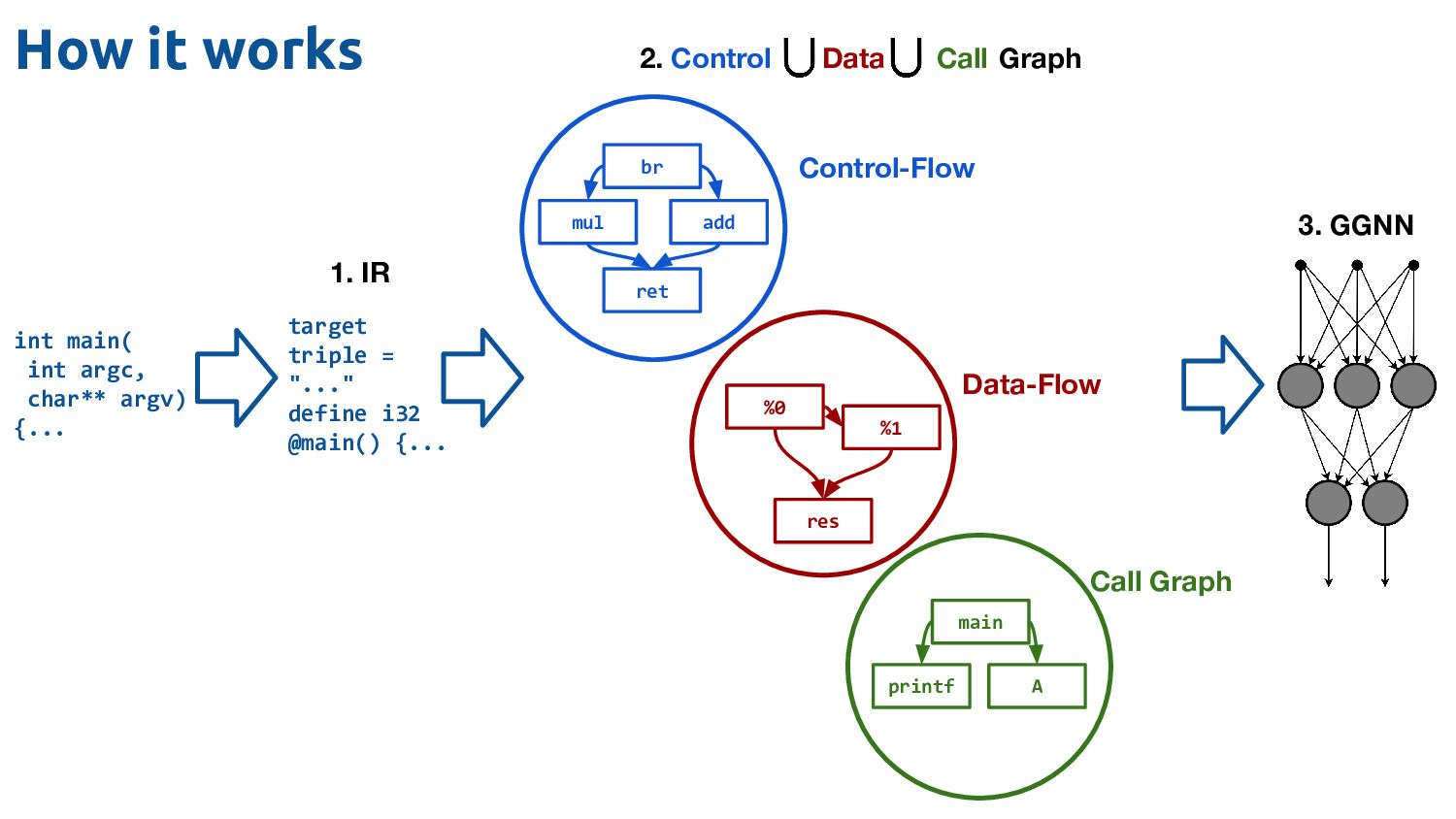
"..." define i32 @main() {... 1. IR 3. GGNN %0 res %1 main printf A br ret add mul Control-Flow Data-Flow Call Graph Control Data Call 2. Graph How it works
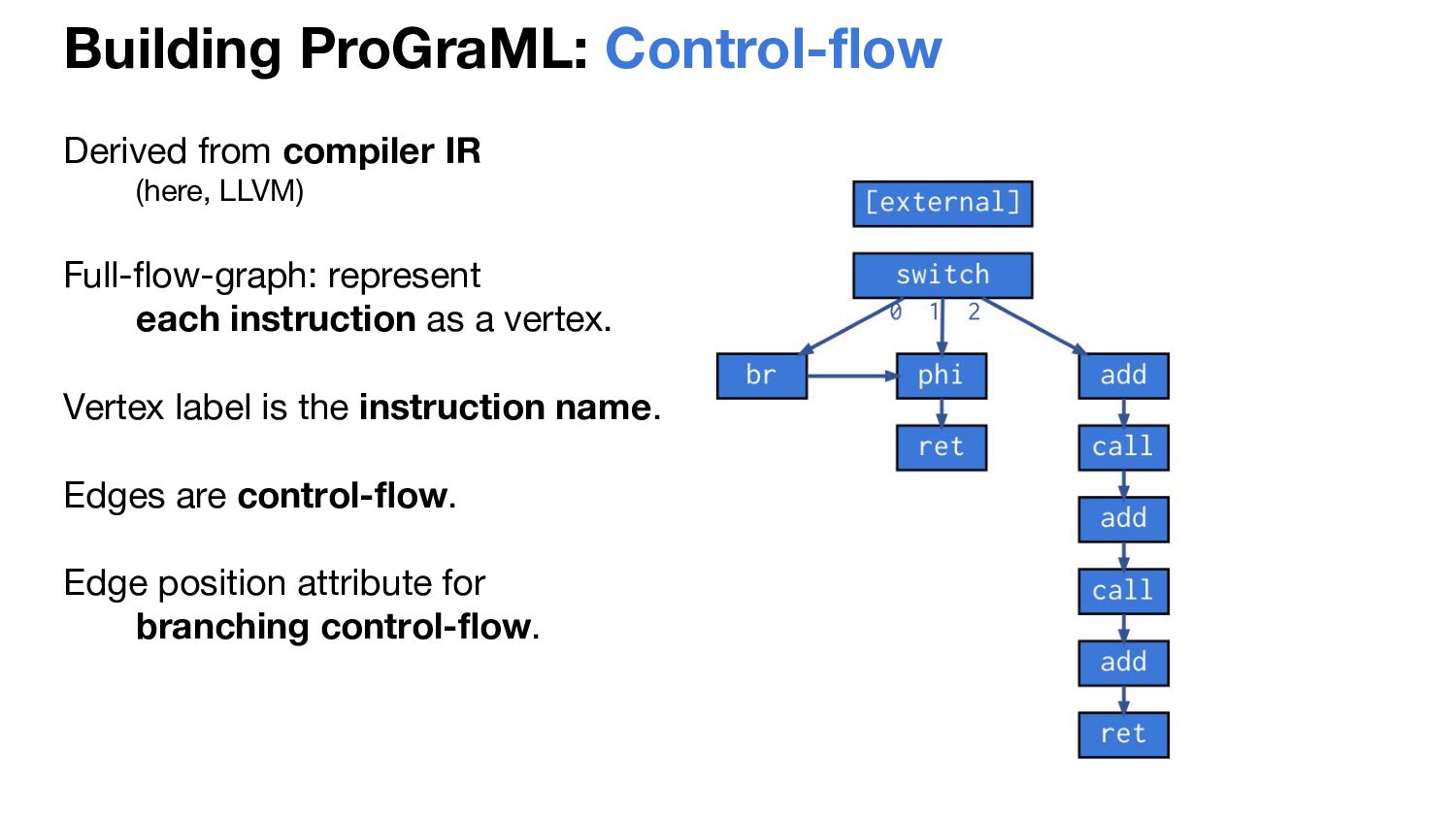
represent each instruction as a vertex. Vertex label is the instruction name. Edges are control-flow. Edge position attribute for branching control-flow.
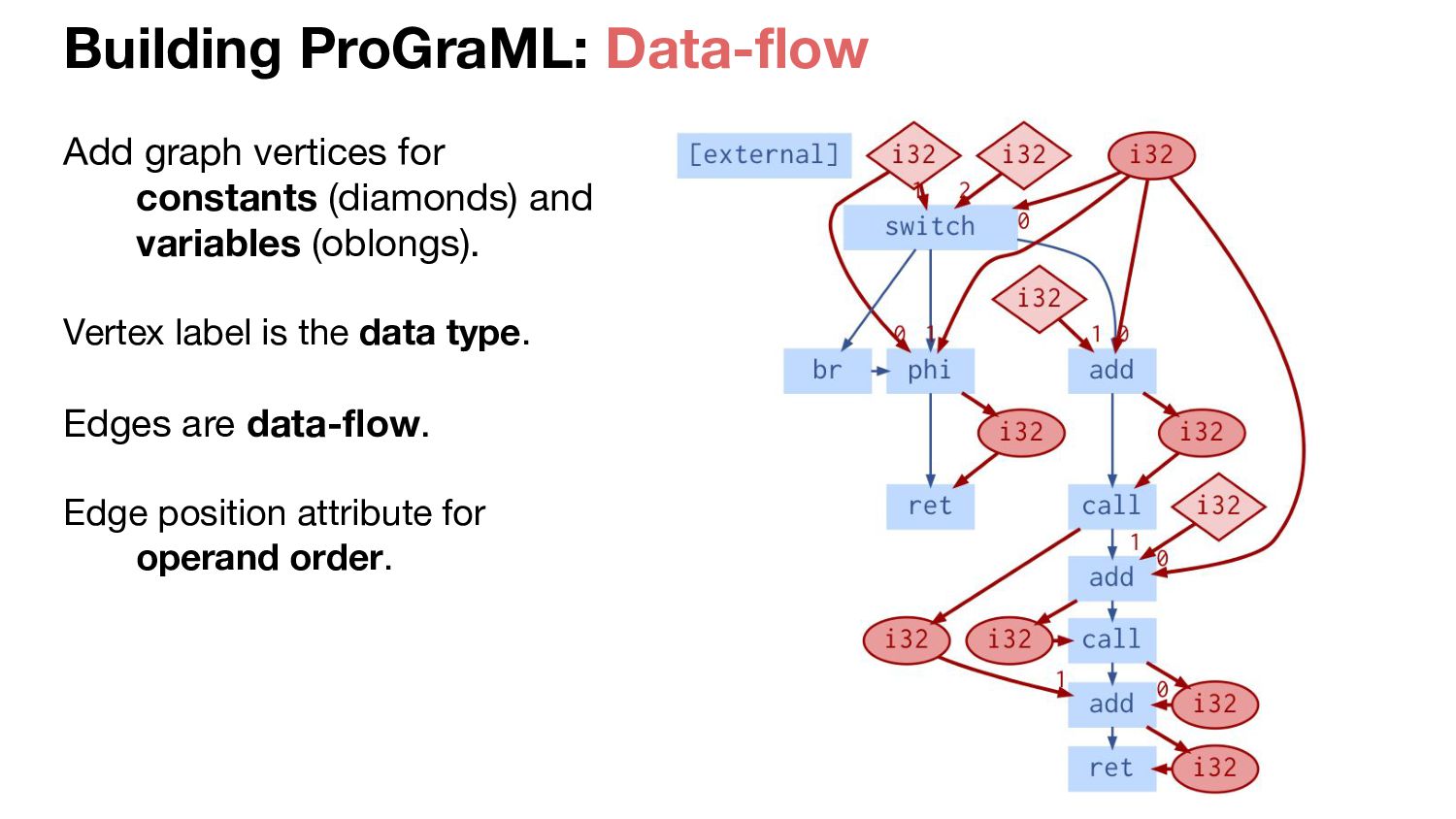
keys Derive vocab from set of unique vertex labels on training graphs. Separate type/instruction nodes leads to compact vocab, excellent coverage on unseen programs compared to prior approaches: inst2vec: combined instruction+operands CDFG: uses only instructions for vocab, ignores data br add i32 0 1 2 i32 <id> = a<id> <int8>
and operand order 6 typed weight matrices for {forwards,backwards} {control,data,call} edge types Message Passing Readout Head per-vertex prediction after T message-passing steps
Dependencies 0.236 0.993 Live-out Variables - 1.000 Global Common Subexpressions 0.214 0.930 Learning compiler analyses F1 Scores Dataset: 250k LLVM graphs covering 6 program languages
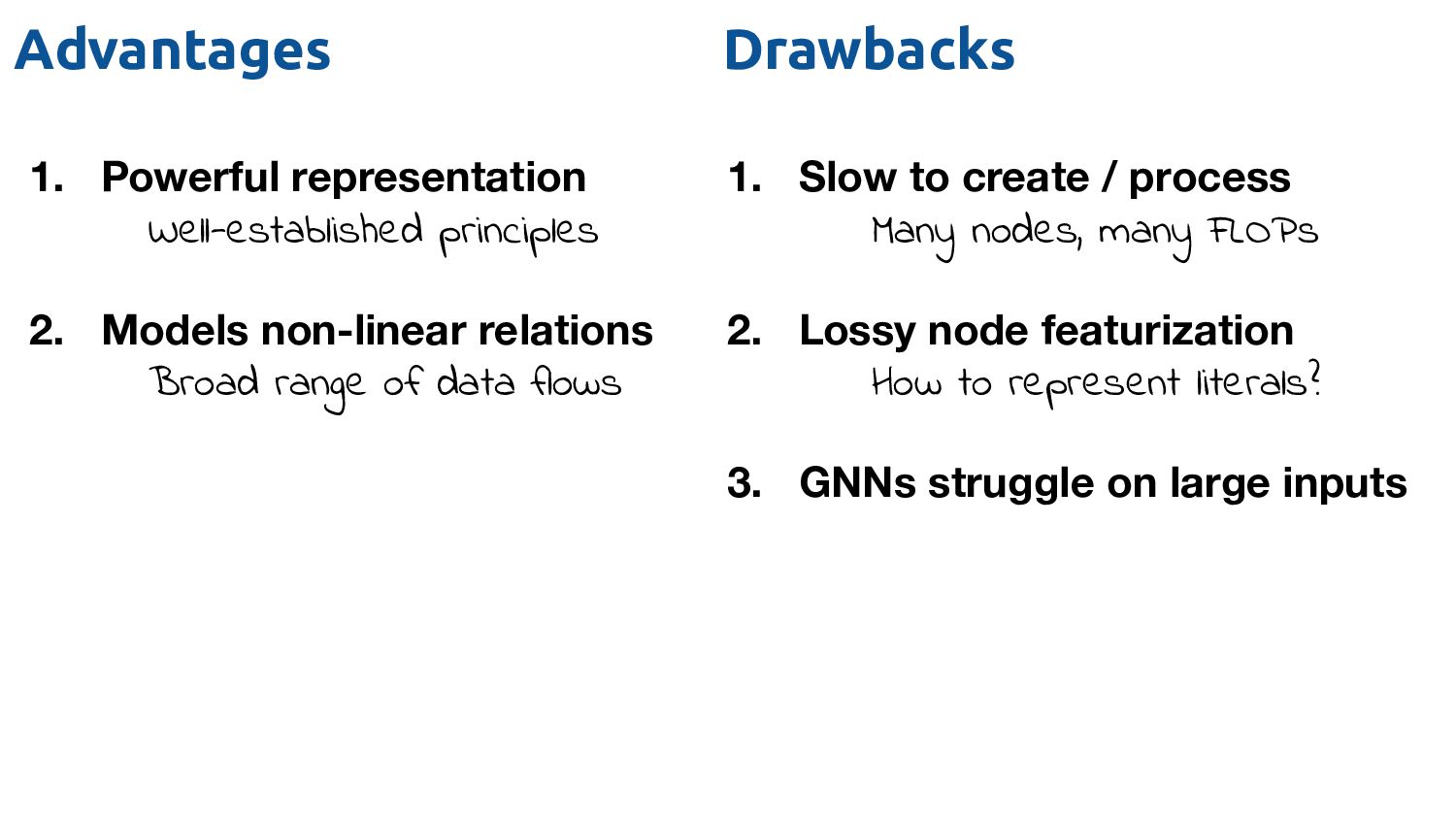
relations Broad range of data flows 1. Slow to create / process Many nodes, many FLOPs 2. Lossy node featurization How to represent literals? 3. GNNs struggle on large inputs
in applying ML to various problems • Even from last decade: ◦ Sameer Kulkarni, John Cavazos, Christian Wimmer, Douglas Simon. Automatic construction of inlining heuristics using machine learning. CGO 2013 ◦ H. Leather, E. Bonilla, M. O’Boyle. Automatic feature generation for machine learning based optimizing compilers. CGO 2009 (Unroll factor learning) • Not much of this has made it to production compilers • Adopting ML/DL in production compilers is not easy! • Many challenges in adopting ML/DL driven optimizations!
challenges is that the existing compilers, LLVM included, were never designed for machine learning integration. • And so there’s a lot of work that could be done to integrate machine learning techniques … into our compiler frameworks. • But because the abstractions were wrong, it’s really hard to do that outside of a one-off research paper…”
a human-manageable set of benchmarks and regression cases. Heuristics are human-written code that needs to be maintained ◦ Limits the number of program features and combinations involved ◦ But using more features and feature combinations -> better opt. decisions Human heuristics more comprehensible in theory, can grow complex over time DL easily scales to large training examples ◦ Generalization to real world diverse programs likely to be better DL scales well with the addition of features ◦ Avoids need of retraining models often in production compilers ◦ Can also discover automatically profitable feature combinations DL models not comprehensible/explainable
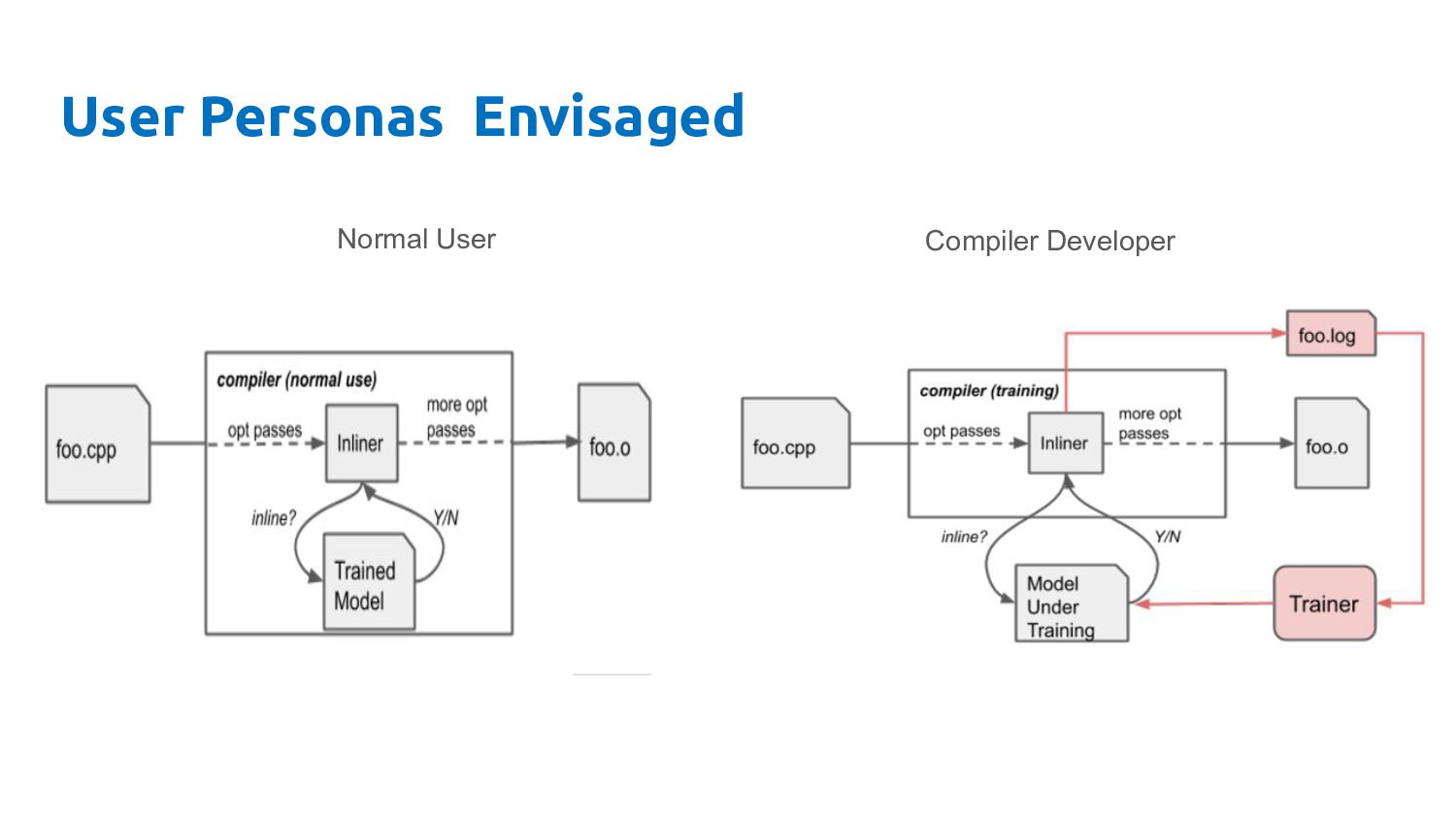
production use of compiler should remain unchanged • Separate deployment of compiler from training of ML models/policies • Minimize compile time overheads to acceptable levels ◦ ML model embedded in compiler and deployed in inference mode • Can cater to different user personas ◦ Normal User (uses compiler to compile his application) ◦ Compiler engineer who is developing/maintaining the compiler
to replacement by learnt models/policies • What are the challenges in adopting this in production compiler? • Let us look at a case study ◦ MLGO: a Machine Learning Guided Compiler Optimizations Framework (Troffin et al.2020).
of inlining-for-size in LLVM compiler • Size instead of performance ◦ Modelling performance rewards are noisy, costly • Inlining heuristics are complex! • Supervised learning not viable ◦ there are no optimal labels for the task ◦ no simple way of saying an inline decision is optimal • Need to explore different strategies, learn from these experiences • Reinforcement Learning (RL) & Evolution Strategies (ES) more suitable
correctness and performance of the generated code should not be impacted • Timeliness of build • compilation determinism (incremental build support) • No added cost/complexity to build and release pipelines MLGO Design Goals • No visible changes to normal user • Separating Correctness & Policy • Only support ML driven heuristics • not code changes • Minimal impact on compile time • No online training • Should not need frequent retraining • Generalize across code bases
optimizations in compiler • Wants to apply ML to improve compiler passes • Improve ML driven opts • Fix regressions & ship blockers MLGO Design Goals • Support efficient retraining • ML models/policy visible to user • Can lead to additional dependencies • Build/release pipelines can be changed • Improve policy by adding missing features/regressions to retraining data • Flexibility to support alternate training algorithms
Dataset created, new ML model trained iteratively to replace existing human heuristics. ◦ User Persona – Compiler Engineer • Policy Deployment ◦ Model incorporated into compiler in inference mode and deployed in release compiler ◦ User persona – Application Developer • Policy Improvement ◦ Retraining Model to improve performance. User Persona : Compiler Engineer • Policy Maintenance ◦ Bug Fixing ML model. User Persona: Compiler Engineer
Call Graph of a module in a bottom up order • The inlined callee’s call sites added to worklist for iterative processing • Inlining pass includes a number of decisions ◦ The order of traversal ◦ Clean ups done and their timing ◦ Decision to inline a callsite or not • MLGO focusses on the decision to inline a callsite or not based on size
callee post inlining • Compare the computed cost with a threshold • Threshold based on call site hotness and inline keyword • Bonuses/threshold modifications based on ◦ Callee characteristics like single BB, number of SIMD instructions etc • Inlining may be deferred, if it may be profitable to inline caller first • Interplay of a number of program characteristics ◦ Local to the callsite ◦ Global ◦ Source level directives, optimization options etc
inlining policy with 2 different algorithms 1. Reinforcement Learning based 2. Evolution Strategies (ES) based • To handle cold start issue for RL Policy, use behavioral cloning • Behavioral Cloning mimics the standard LLVM Inliner heuristics
the environment ◦ based on current state and learnt policy, performs actions • The action leads to a reward ◦ Also changes the current state of the environment • Reward feedback tunes the policy for further steps • In our case, compiler is the agent and Policy is the learnt model for heuristics • Action is inline/not inline & State is the current state of the call graph • We will talk about reward later!
Process ◦ Sequential Decision Making • MDP represented by the tuple < S, A, P, R > ◦ state space S ◦ action space A, ◦ state transition distribution P(𝑠′|𝑠, 𝑎), ◦ reward function R(𝑠, 𝑎). • The agent’s decisions governed by policy 𝜋 = 𝑃𝑟 (𝑎|𝑠) ◦ maps observed state 𝑠 to a distribution over actions. ◦ 𝜋 is a neural network and we call it policy network. • Goal is to find the optimal policy 𝜋∗ to maximize total reward
current call graph State and call site being visited ◦ Not practical ◦ Approximated using a set of features • Action A = {0.1} 0-> no inline. 1-> inline • Deterministic state transition based on action and Call Graph updated • Reward R – native size reduction after action A ◦ If inlined: R = S(caller_before) – S(caller_after) + [S(callee) if callee deleted, 0 if not deleted] ◦ Not inlined: R = 0 ◦ Compute total native size with/without inlining and subtract
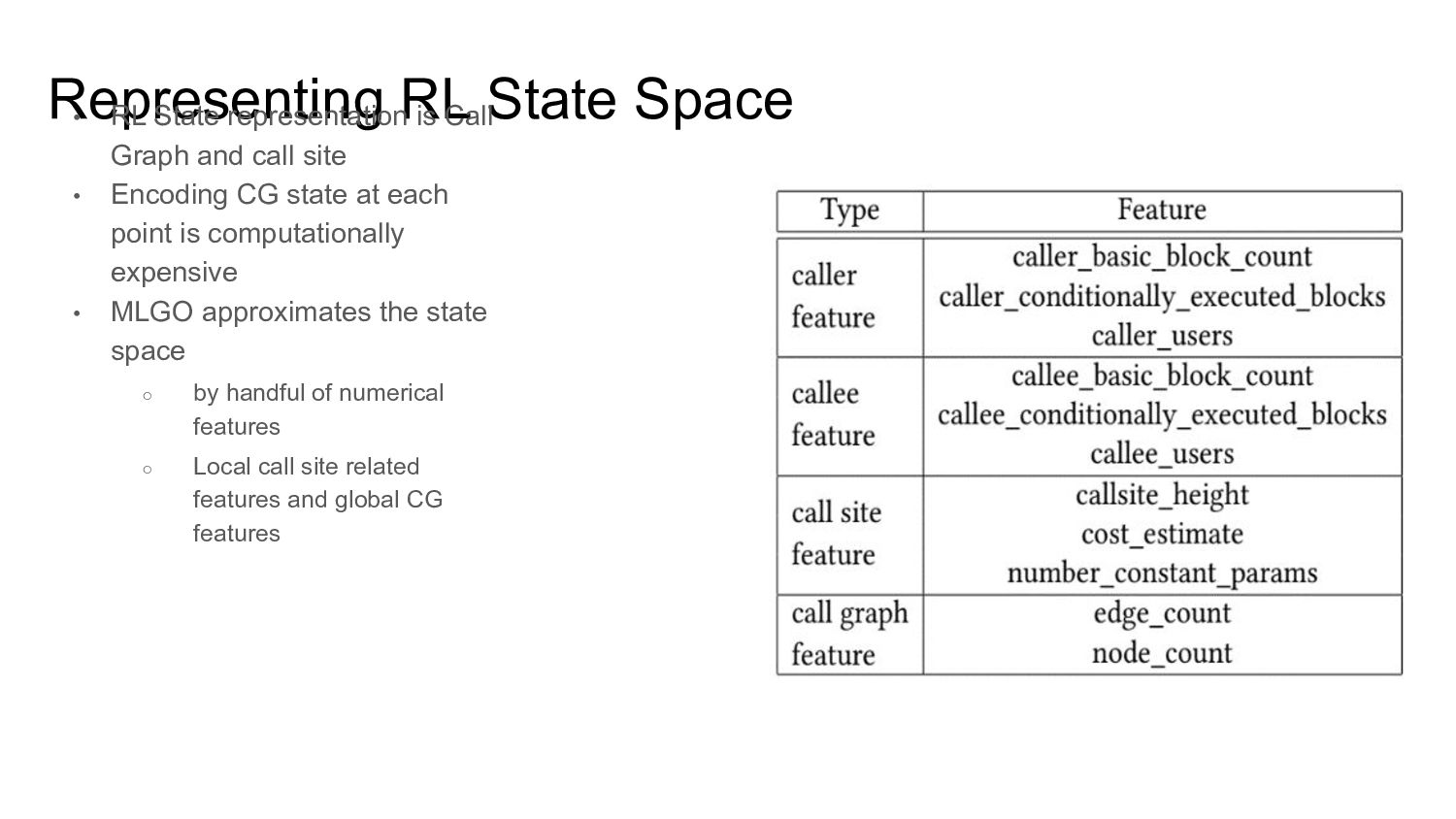
Graph and call site • Encoding CG state at each point is computationally expensive • MLGO approximates the state space ◦ by handful of numerical features ◦ Local call site related features and global CG features
representation computationally unviable • Can impact compile time significantly • MLGO trades off state representation fidelity to mitigate this ◦ Falls back to handful of numeric features • This reduces information available to the RL model ◦ impacts the policy trained in MLGO • MLGO also does not use IR code embedding of callee.. ◦ To reduce memory/compute costs • Opportunity: Develop computationally viable & high fidelity ◦ State space representation ◦ IR embedding representations (both task agnostic/task specific)
size during inlining pass • MLGO opts to use total reward instead of partial rewards ◦ Evaluate native size with and without inlining and subtract • This requires more compute and can impact model quality • Inlining for performance would make this even more complicated! Opportunity: Develop scalable reward formulations without impacting model quality
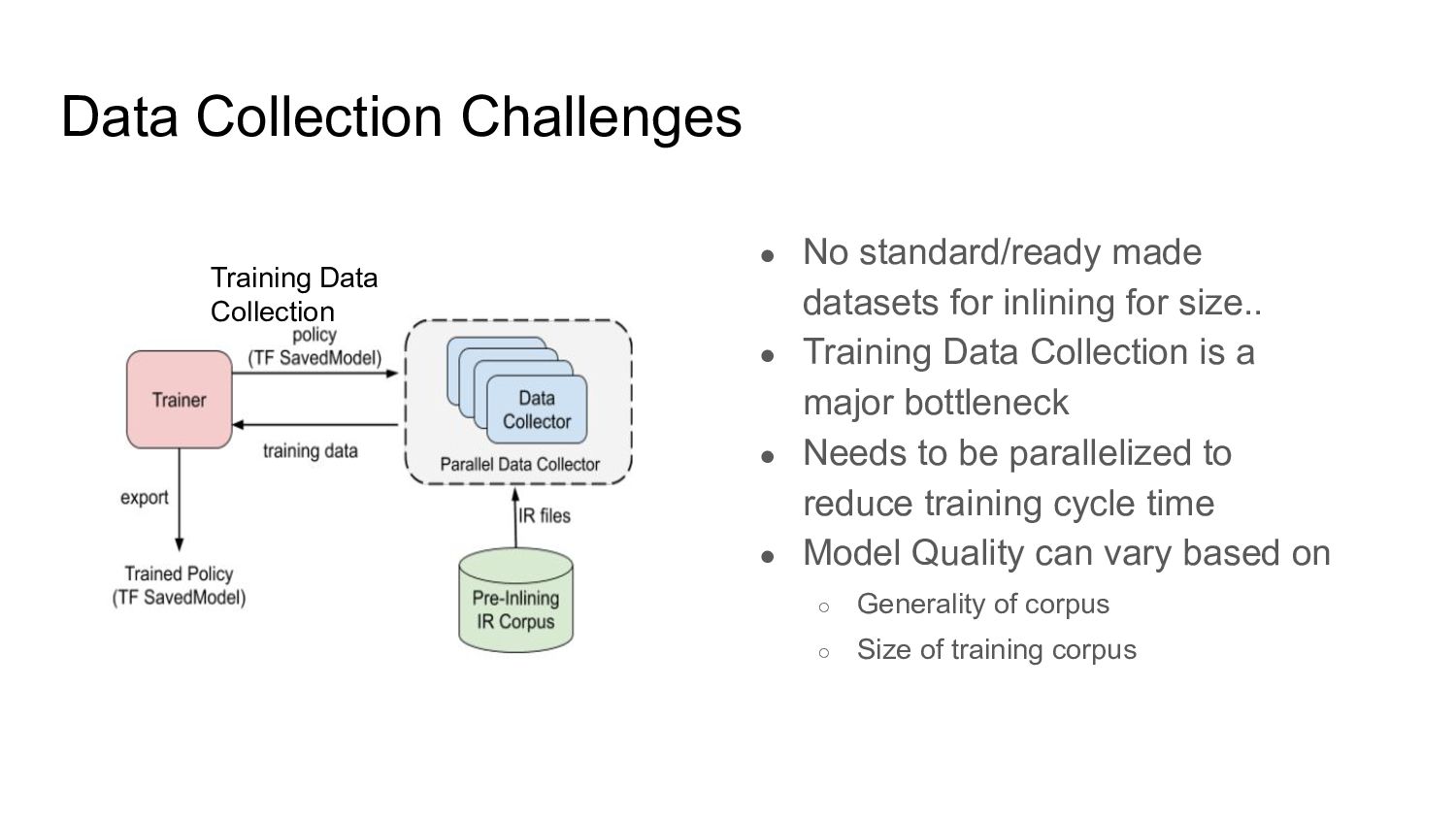
for size.. • Training Data Collection is a major bottleneck • Needs to be parallelized to reduce training cycle time • Model Quality can vary based on ◦ Generality of corpus ◦ Size of training corpus Training Data Collection
Long cycle time and requires compiler engineer expertise • Identify missing features based on regressions ◦ Black box nature of DL algorithms makes it difficult • Incorporate regression test cases from field and retraining ◦ Requires model updates in production compiler • Explore alternative learning algorithms ◦ Longer dev time and compiler release updates needed ◦ Trade off between simpler (better interpretable) algorithms vs performance
• DL model policies blackbox in nature, hamper debugging • For Ship blockers, fall back to ◦ Earlier working policy/model ◦ Manual heuristics • Fix would require model retraining ◦ Trained with newer training data ◦ Adding/dropping features • Selective application of manual heuristics to buggy code + DL model driven inlining for rest of code base
model/policy quality and compute costs • Timeliness of compiles is non-negotiable for normal user • Explainability of DL models/policies is desirable for troubleshooting
speed optimizations? ◦ Handling noisy rewards like speedup/runtime ◦ Task Specific proxy reward formulations ◦ Scalable and compute efficient • How do we design richer & efficient state representations? ◦ Encode CG State into a compact representation ◦ With minimal impact on compile time ◦ Learning these representations from pre-trained models? ◦ Exploring IR code embedding techniques for callee analysis
datasets typical ❑ Large datasets like AnghaBench available only at source code level 2. Lack of Pretrained IR models ❑ Transfer learning not yet possible 3. Non-availability of generalized contextual IR embeddings Research Directions 1. Automatically Synthesizing benchmarks and datasets for various compiler tasks 2. Pre-trained LMs at different points of optimization pipeline ❑ Middle end and at codegen level 3. Techniques for IR embeddings that can generalize across code bases and different compiler tasks
increasingly complex • Correctness & performance of applications depends on the compiler • Increasingly difficult to write compiler optimizations which generalize across software • Can ML/DL assist human in developing better compiler optimizations?
problems that are hard to solve manually/algorithmically • Typical characteristics include ◦ Large search space ◦ Approximate solutions preferred ◦ Availability of large code bases/samples that can be mined ◦ Probabilistic nature of ML does not impact correctness • Compiler Problems that fit these characteristics well ◦ Heuristics, Phase Ordering decisions, Cost Modelling
increasingly complex ➔ Increasingly difficult to write compiler optimizations which generalize across software ➔ But correctness & performance of applications depends on the compiler ➔ Where can we target ML to ease & improve compiler optimization?
modelled with two phases ◆ Analysis & Transformation ➔ Analysis Phase (Correctness, Cost/Benefit, Feasibility) ◆ May be driven by heuristics, No code change involved ➔ Transformation Phase (Implementing the Decision) ◆ The big concern is correctness ➔ Complex Optimizations - Inlining, Scheduling, Register allocation ◆ NP Hard Problems ◆ Decision making approximated by complex and multifactorial heuristics
ML to problems that are hard to solve manually/algorithmically ➔ Preferable characteristics include ◆ Large search space ◆ Approximate solutions preferred ◆ Availability of large code bases/samples that can be mined ◆ Probabilistic nature of ML does not impact correctness ➔ Three areas: Optimization heuristics, Phase Ordering, Cost Modelling
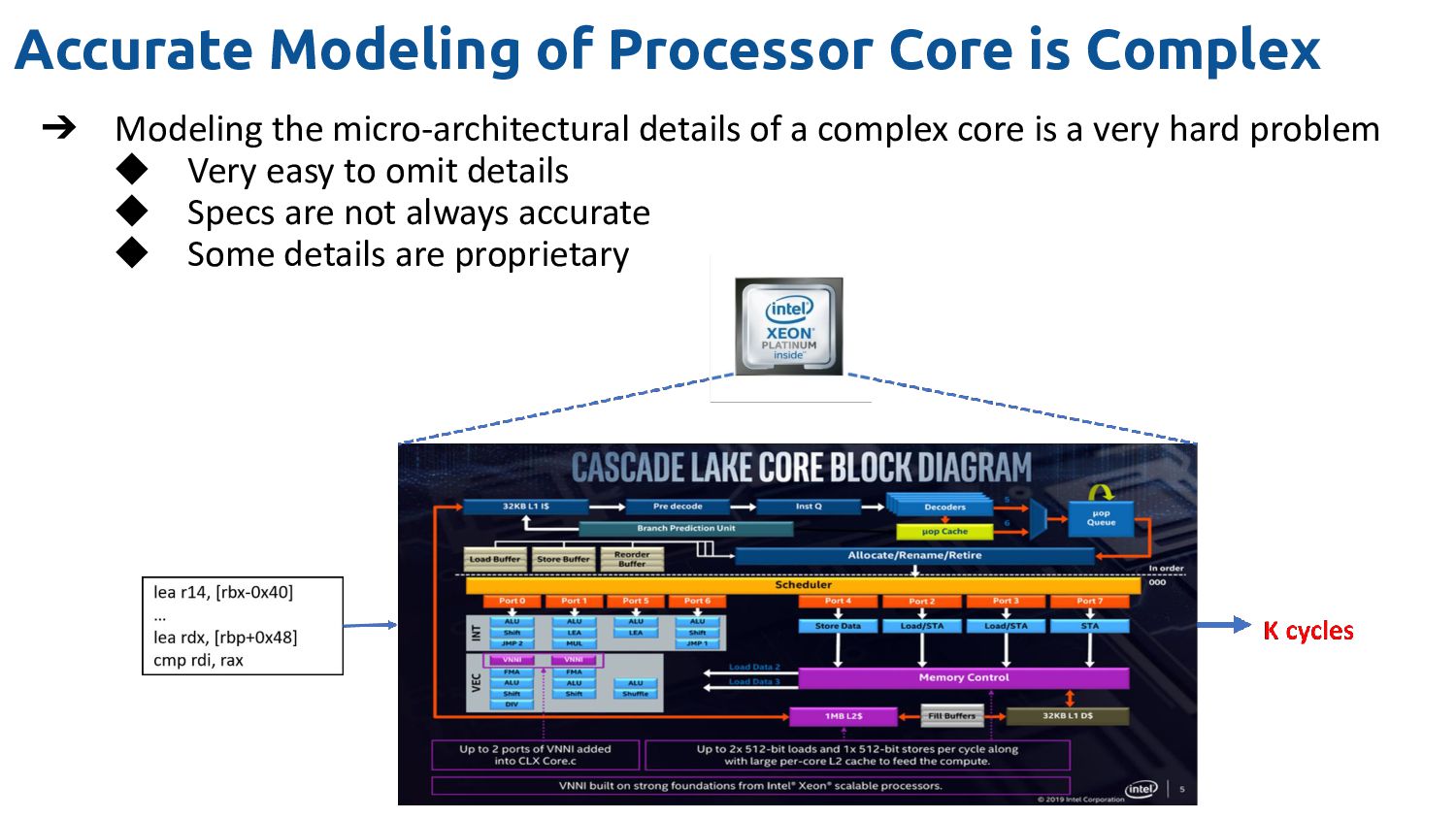
micro-architectural details of a complex core is a very hard problem ◆ Very easy to omit details ◆ Specs are not always accurate ◆ Some details are proprietary
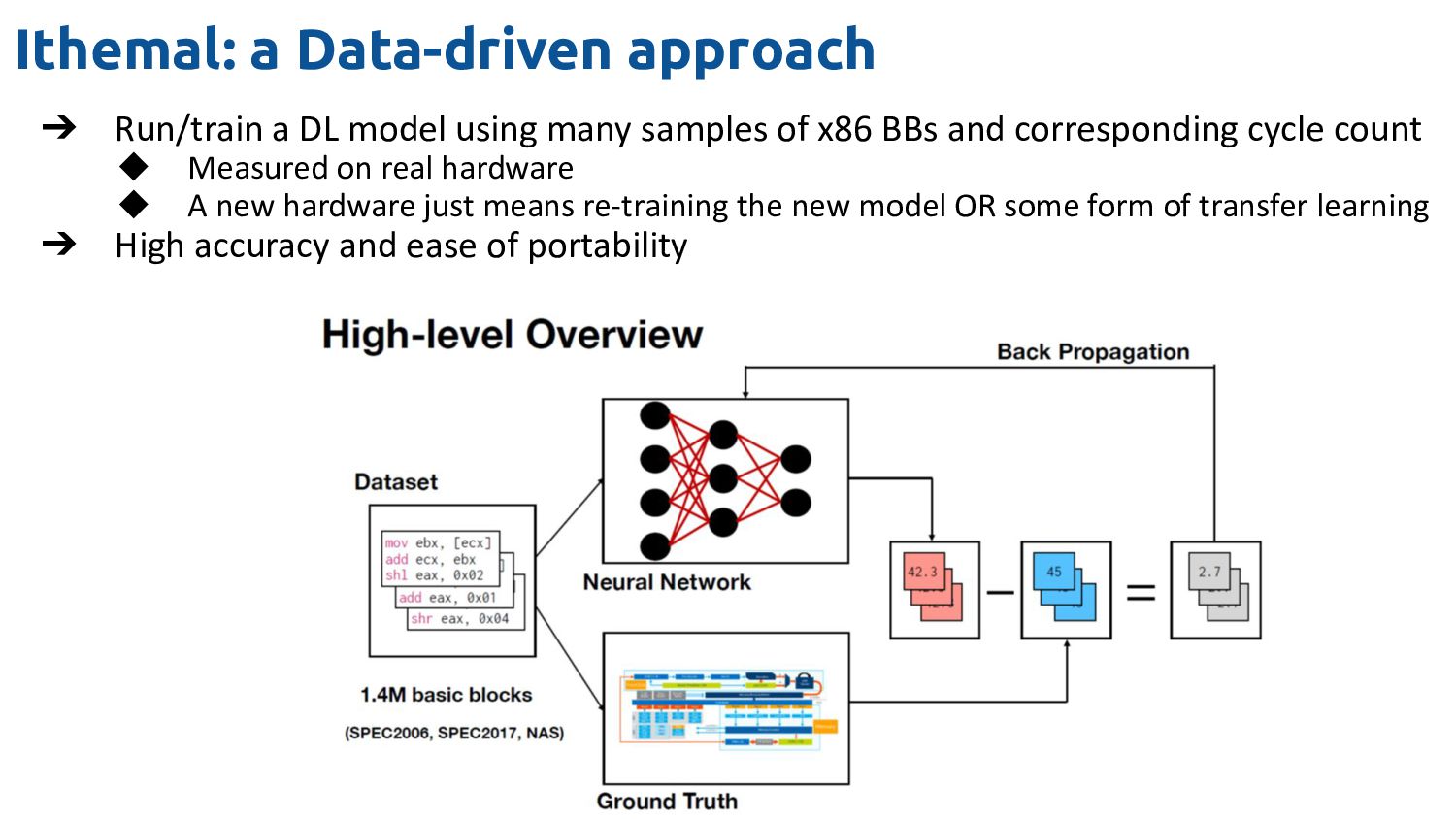
many samples of x86 BBs and corresponding cycle count ◆ Measured on real hardware ◆ A new hardware just means re-training the new model OR some form of transfer learning ➔ High accuracy and ease of portability
in a BB as input ◆ 2-layers ◆ Layer-1 for the sequence of operands of each instruction ◆ Layer-2 for the sequence of instructions ➔ Regression model ◆ Throughput predictor
important problem in code generation ➔ The number of registers available may be < number of variables ➔ Create *interference graph* which models registers which need to be *live* at the same time
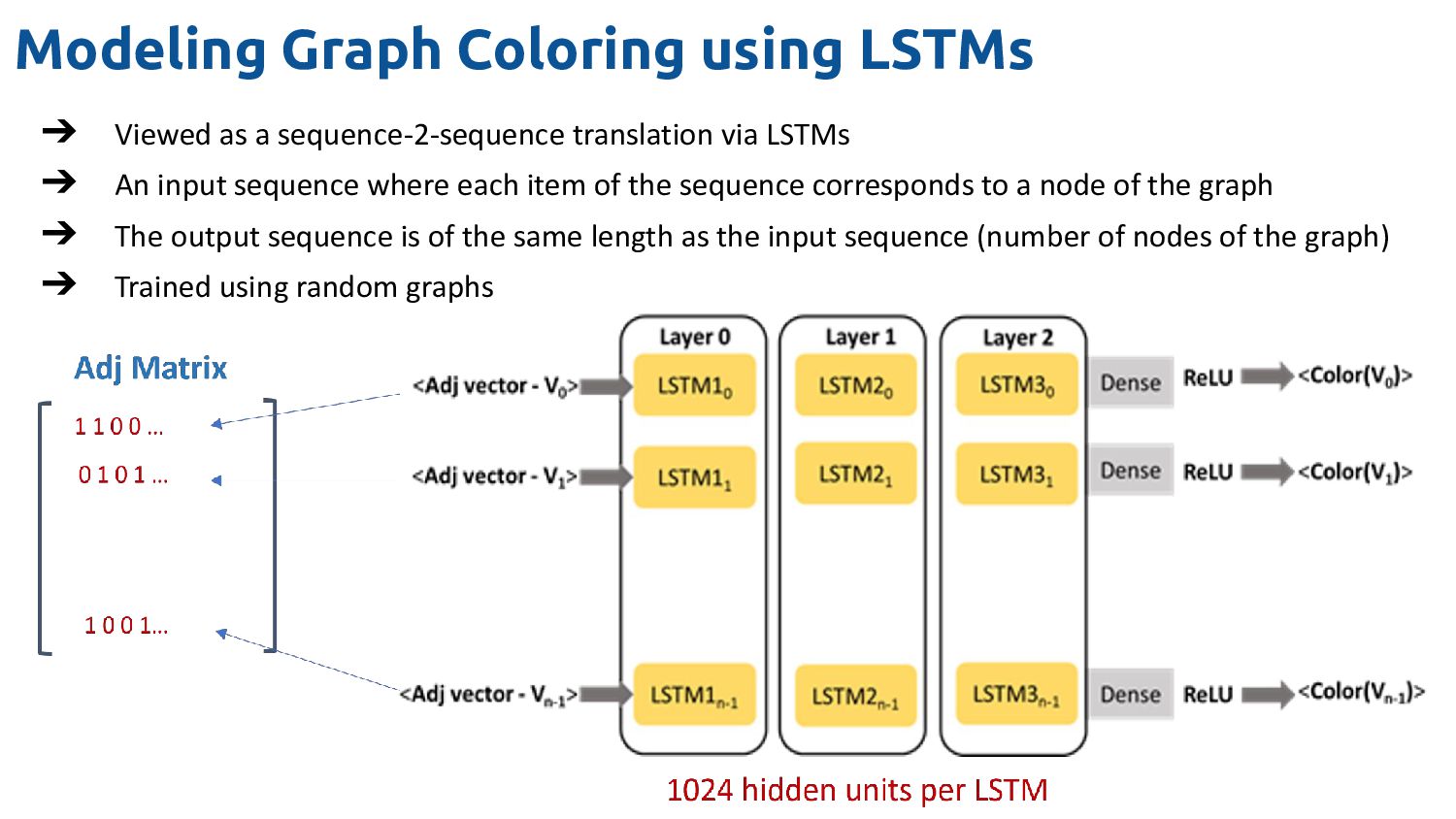
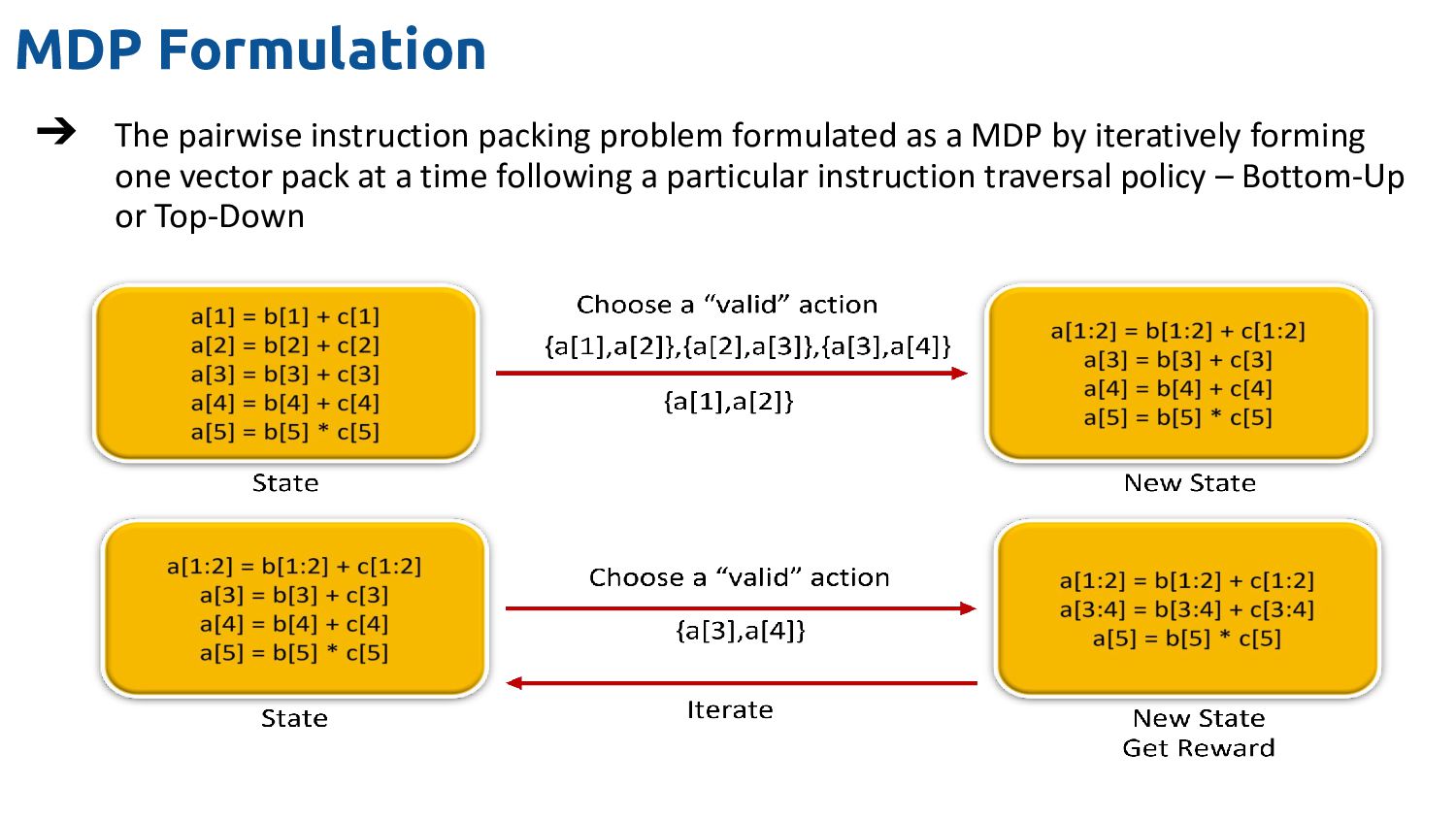
translation via LSTMs ➔ An input sequence where each item of the sequence corresponds to a node of the graph ➔ The output sequence is of the same length as the input sequence (number of nodes of the graph) ➔ Trained using random graphs
that two adjacent nodes cannot have some color ➔ *Invalid* edges may appear during inference ➔ Rectify these edges using a post-inference color-correct pass
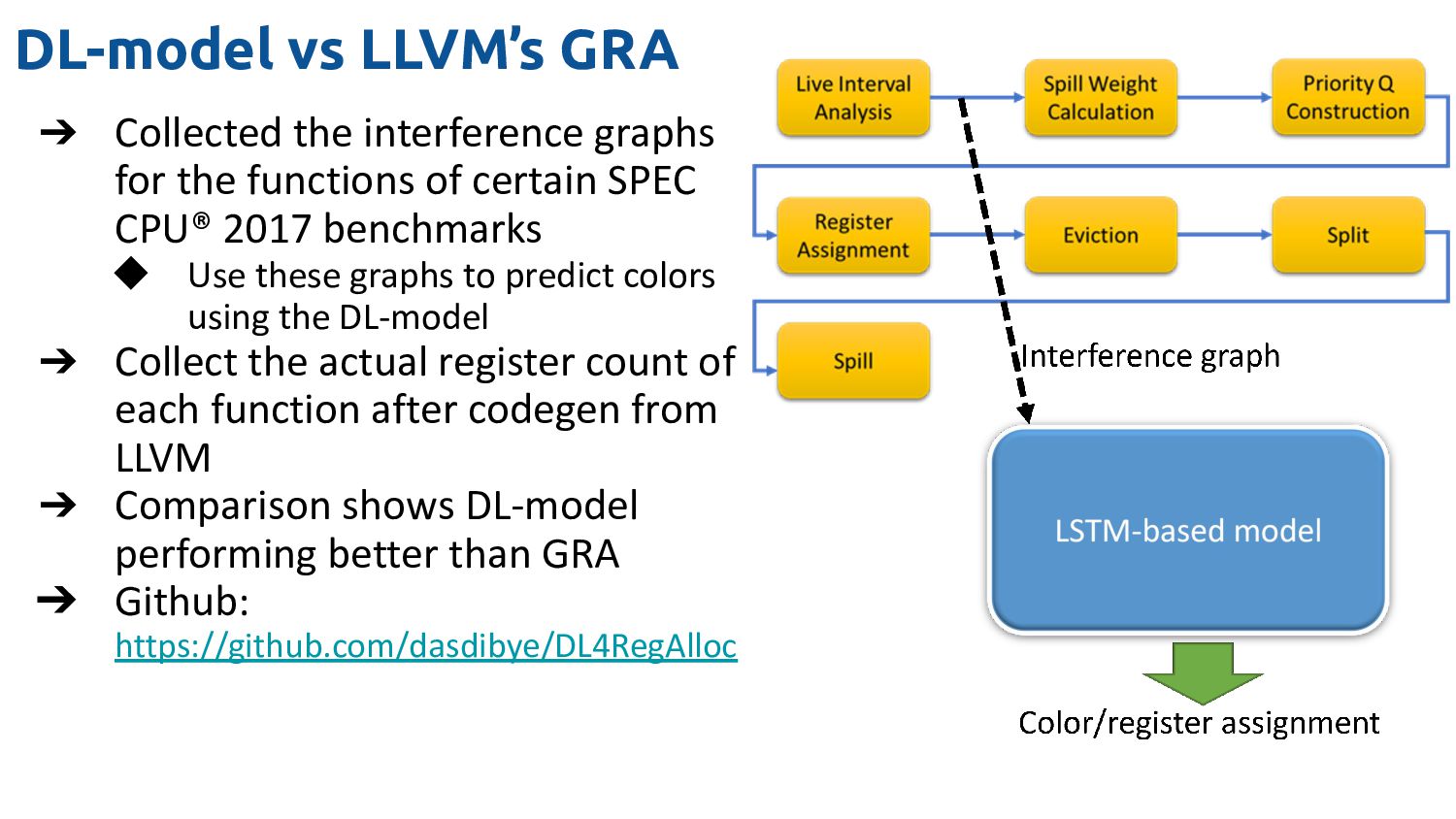
the functions of certain SPEC CPU® 2017 benchmarks ◆ Use these graphs to predict colors using the DL-model ➔ Collect the actual register count of each function after codegen from LLVM ➔ Comparison shows DL-model performing better than GRA ➔ Github: https://github.com/dasdibye/DL4RegAlloc
(Superword-Level Parallelism) using ML ◆ SLP is a superset of Loop Vectorization whereby stratight-line code can also be vectorized ➔ Naïve ML strategies may lead to correctness issues as only isomorphic statements can be vectorized
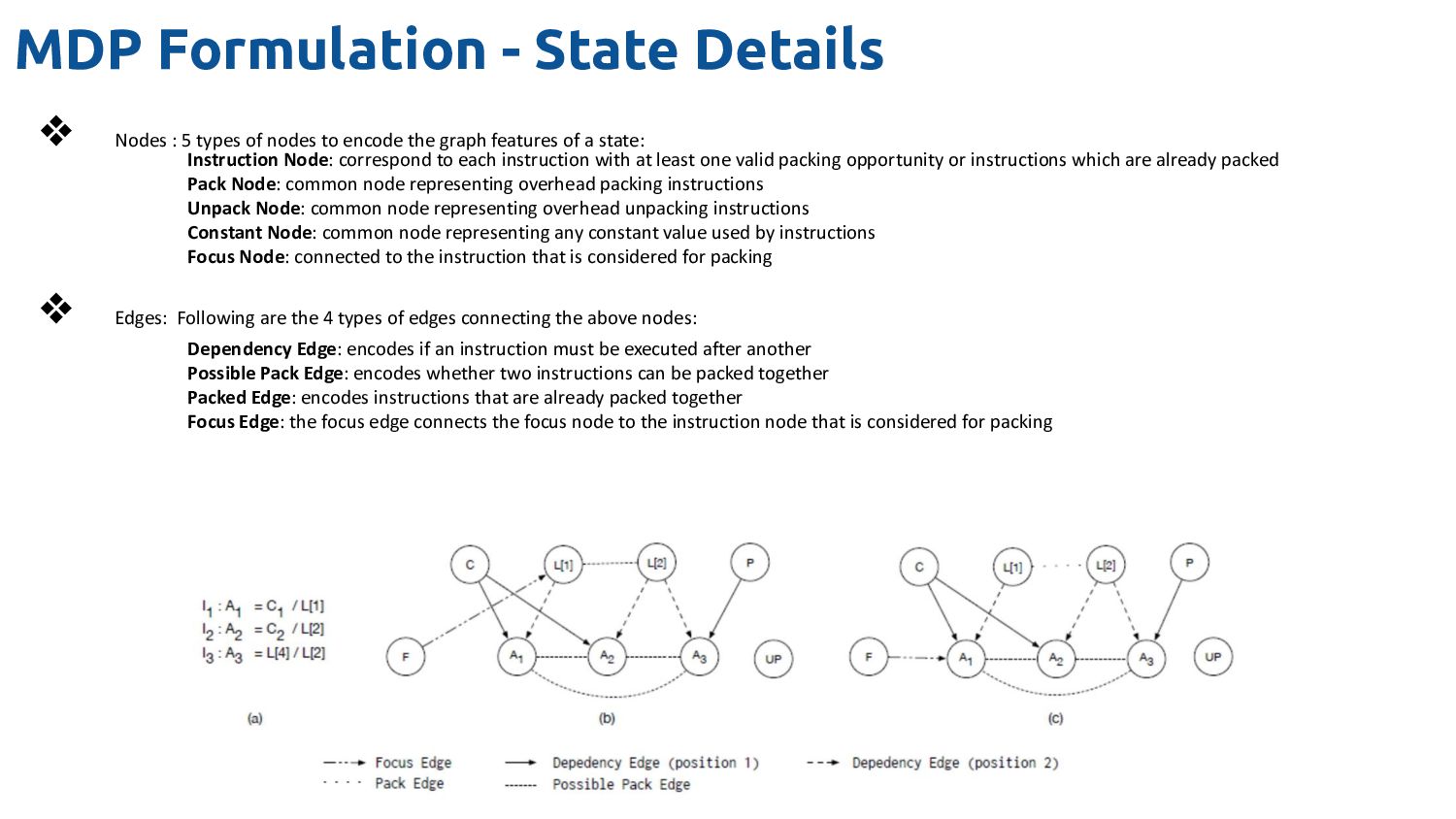
of nodes to encode the graph features of a state: Instruction Node: correspond to each instruction with at least one valid packing opportunity or instructions which are already packed Pack Node: common node representing overhead packing instructions Unpack Node: common node representing overhead unpacking instructions Constant Node: common node representing any constant value used by instructions Focus Node: connected to the instruction that is considered for packing ❖ Edges: Following are the 4 types of edges connecting the above nodes: Dependency Edge: encodes if an instruction must be executed after another Possible Pack Edge: encodes whether two instructions can be packed together Packed Edge: encodes instructions that are already packed together Focus Edge: the focus edge connects the focus node to the instruction node that is considered for packing
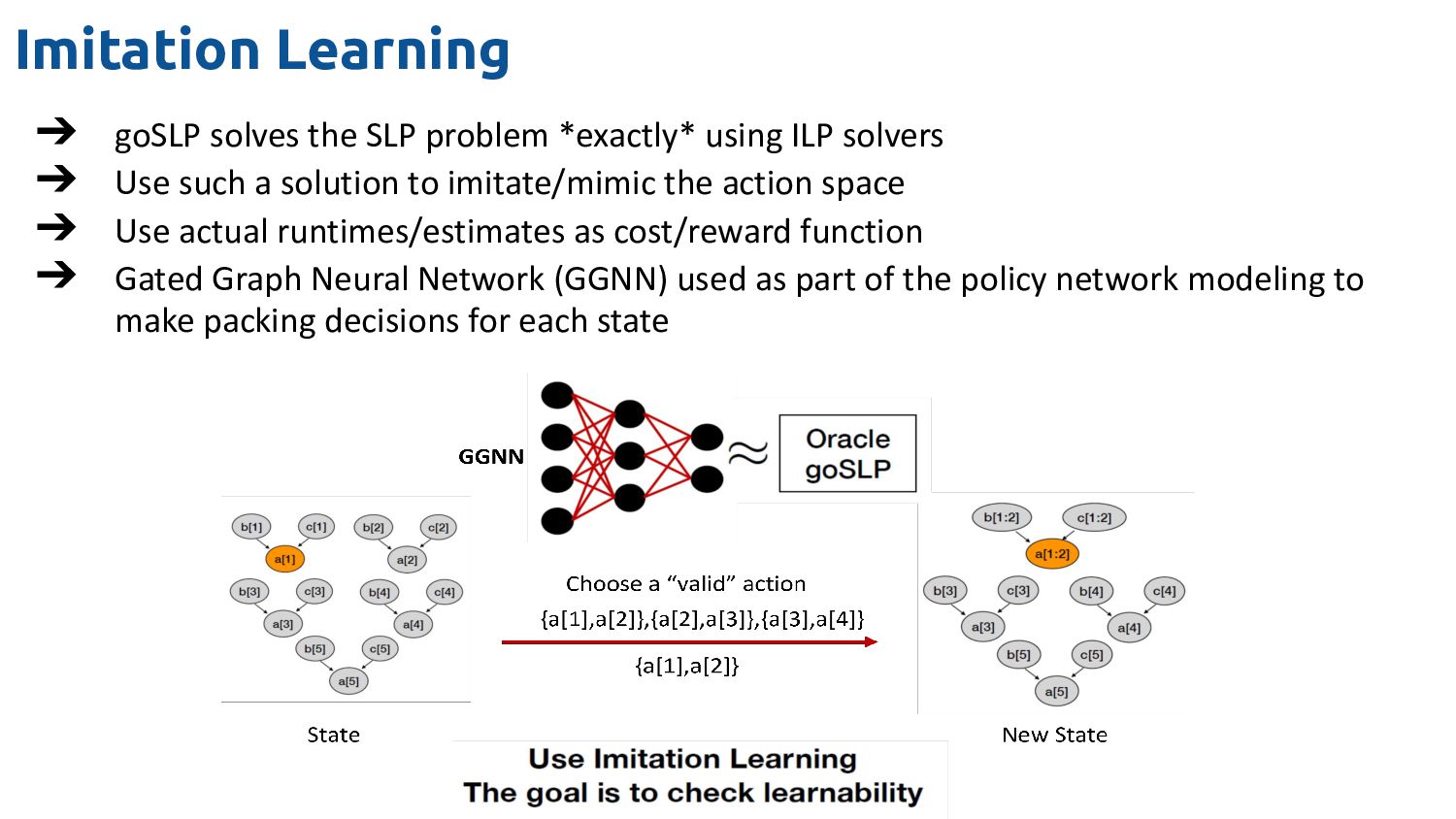
ILP solvers ➔ Use such a solution to imitate/mimic the action space ➔ Use actual runtimes/estimates as cost/reward function ➔ Gated Graph Neural Network (GGNN) used as part of the policy network modeling to make packing decisions for each state
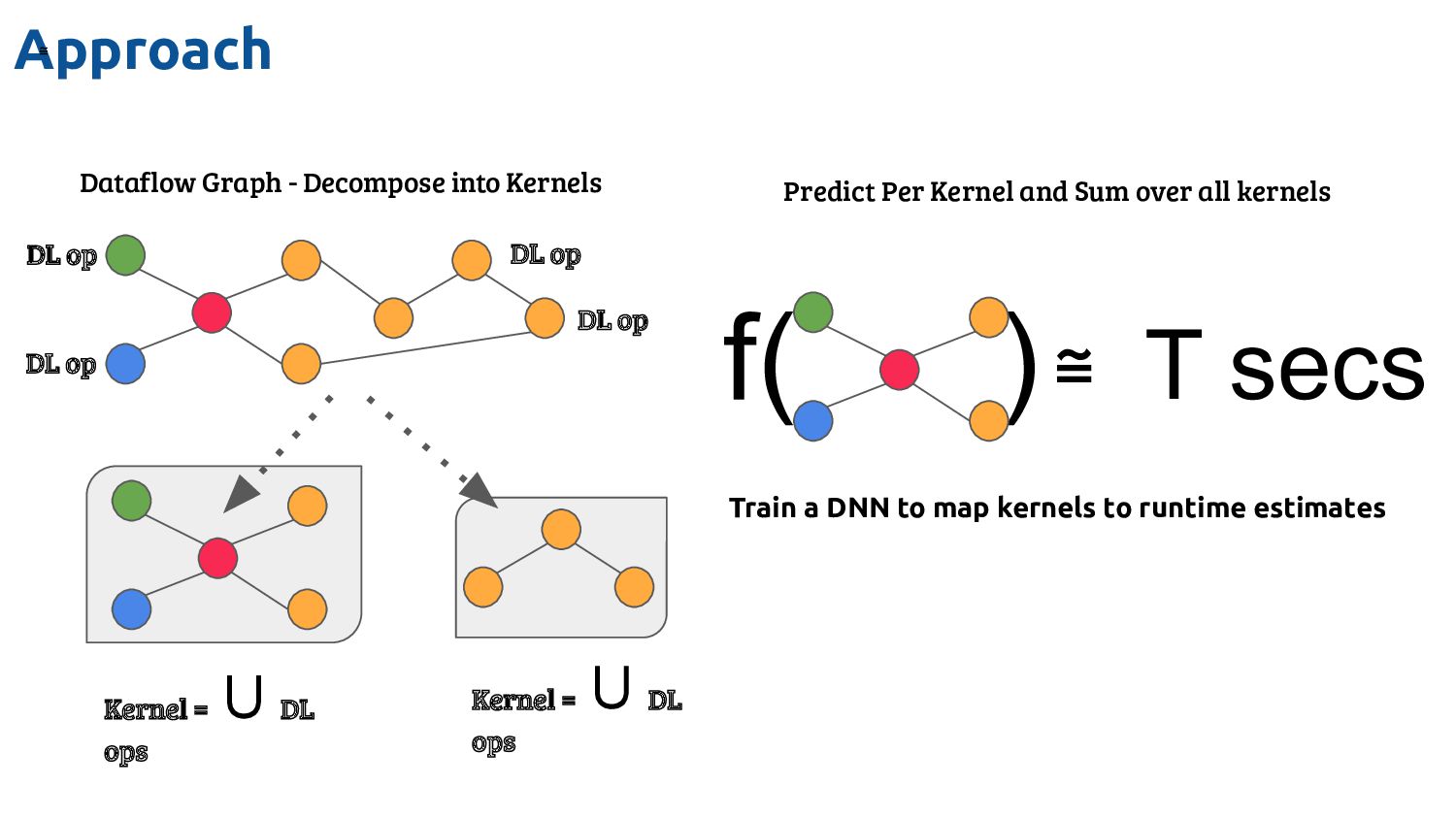
with the underlying processor architecture as well as the optimization decisions that are made during compilation ➔ Developing an accurate analytical model of program performance on a modern processor is challenging and can take months of engineering effort ➔ Developers of analytical models are often unaware of detailed features of the processor or effects from all compiler passes ➔ Learn a performance model for XLA graphs on the TPU
the optimal tile size among many for a kernel ◆ Query the valid tile sizes and obtain the relative performance among them • A kernel may have up to 500K valid tile sizes • For training, up to 25M samples were used ➔ Operator Fusion ◆ Used a random search strategy for fusion on the entire computation graph ◆ For training, up to 50K fusion configurations ◆ More than 200M samples
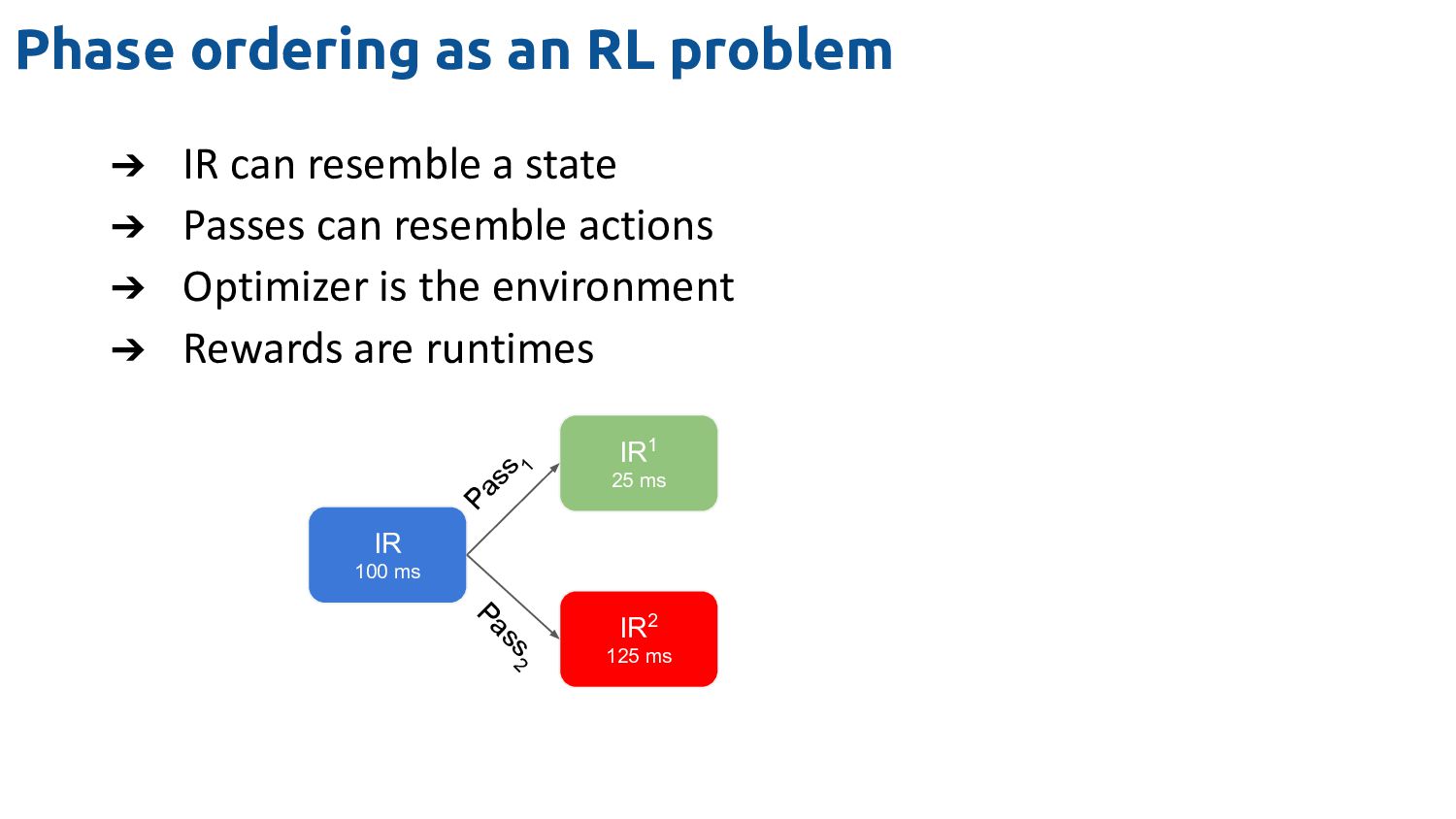
modern compiler ◆ 50+ passes in LLVM pass infrastructure depending on the optimization level ◆ Each pass may have several tunable parameters ➔ Phase-ordering problem extremely hard to solve ◆ Current order is rigid but enumerating possibilities creates a huge search space ◆ We may need to trade off between compile time and performance
,A t ,w) = R(S t ,A t ) + γ.max a∊A Q(S t+1 ,a,w) ➔ Where R = ln (T(S t )/T(S t+1 )), T(x) is runtime of IR x Start input_ir.ll Action Reward 1 -2.3 2 +1.5 3 +0.3 4 -0.9 Action Reward 2 +1.5 Value > 0 ? Record LLVM Opt Action History Agent Prediction Max End True
(Neural Code Comprehension) vector embedding ( Ben-Nun et al. ) ➔ Action history is one-hot encoded ➔ A state is an agglomeration of the encoded IR and action history ➔ The actions are divided into 3 levels of abstraction : H, M, L ◆ H denotes a group of passes together while M,L denotes individual passes ◆ H creates smaller search space than M,L IR Action History State NCC 1-hot State Vector Embedding
for compiler passes ➔ A big challenge is to ensure correctness ➔ Proposed work consists of NLP-like techniques and RL ➔ No consensus yet on standardized program representations and CFG/DFG ➔ Open questions: ◆ Can we generate *semantically correct* transformed code using a DL model ? • Would the optimizations of the future be a mix of DL models + Fast correction algorithms ? • Get most of it right using a DL model and then apply a quick and simple correction pass ◆ Can these models be really portable – across compilers and across hardware ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}