The NoSQL phenomenon has been attracting a lot of attention in the past few years. Driven by their need to accommodate high volumes of real-time data, major internet companies have popularized the use of data storage solutions that differ from traditional RDBMS.
One example of such a solution is the Apache Cassandra distributed database management system. Originally developed by Facebook to power their inbox search, Cassandra combines a schema-flexible data model (borrowed from Google's BigTable) with a fully distributed, shared-nothing design (borrowed from Amazon's Dynamo). This allows Cassandra to offer high availability, linear scalability and high performance while relaxing some consistency guarantees.
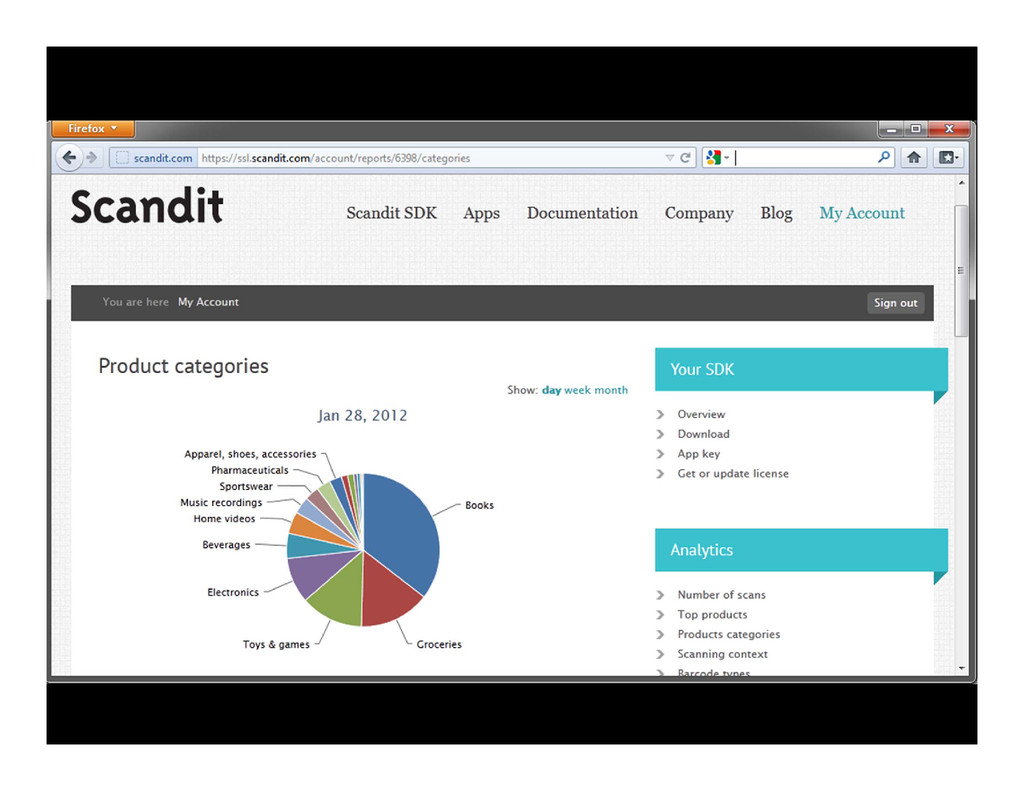
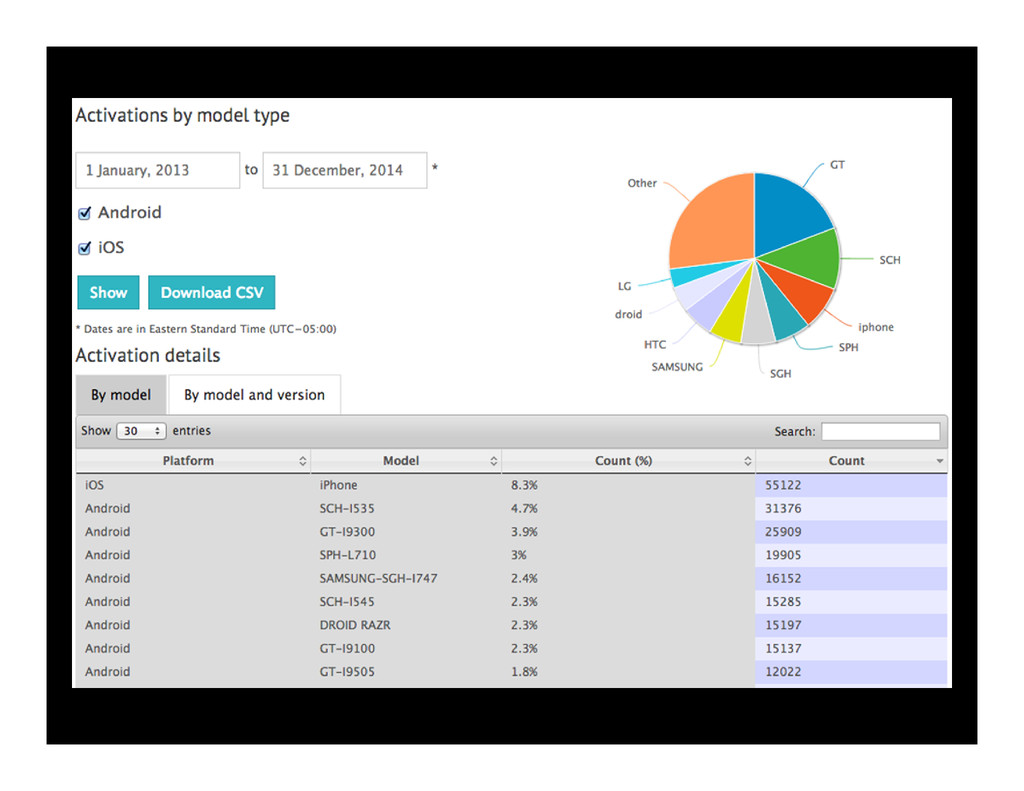
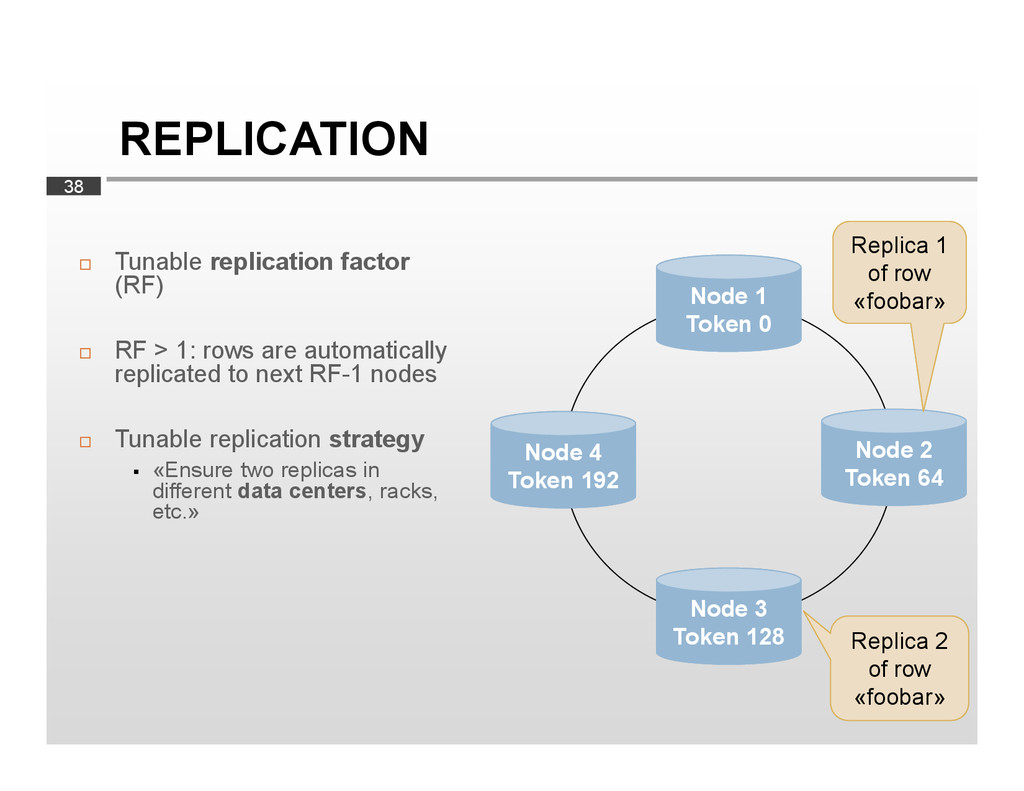
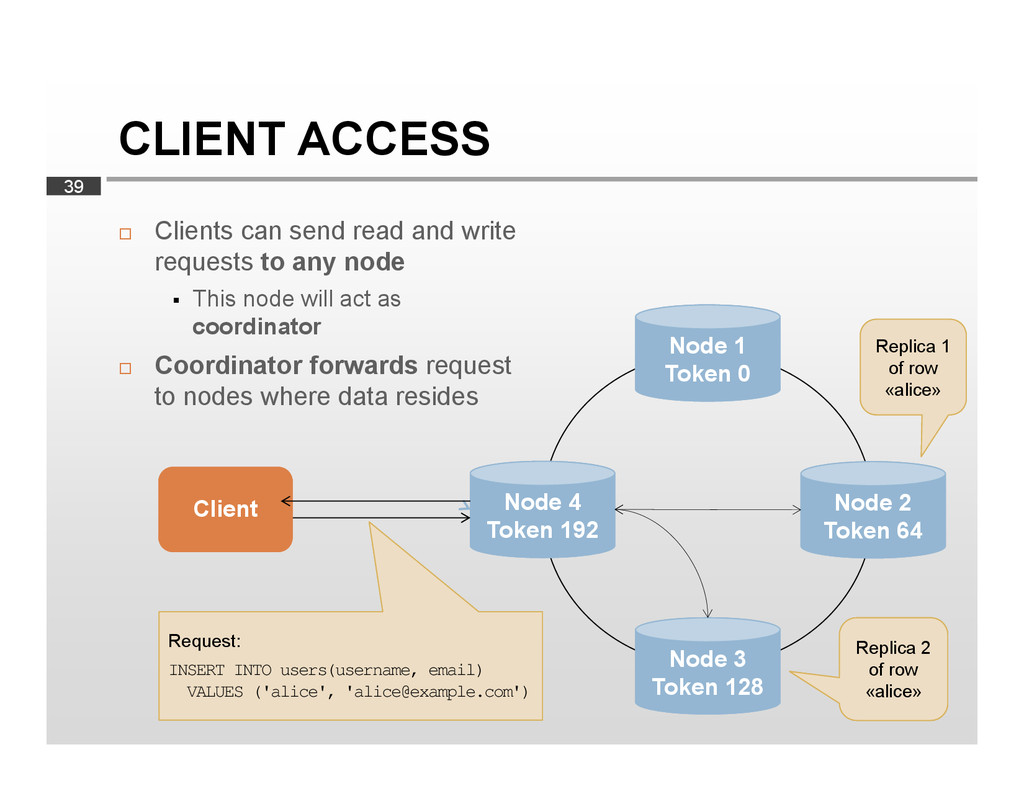
This talk will give developers and software architects an overview of the fundamentals of Apache Cassandra. We will discuss the core concepts of the system, such as its data model, its query language and its cluster architecture. We will also review data replication and consistency and look at a real-world application built upon Cassandra, as it is used at Scandit to manage millions of barcode scans.
The goal of this talk is for attendees to know the main concepts behind Cassandra and their implications. This will let them understand both the benefits and limitations of the system, and it will help them to quickly get started with their own deployment.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
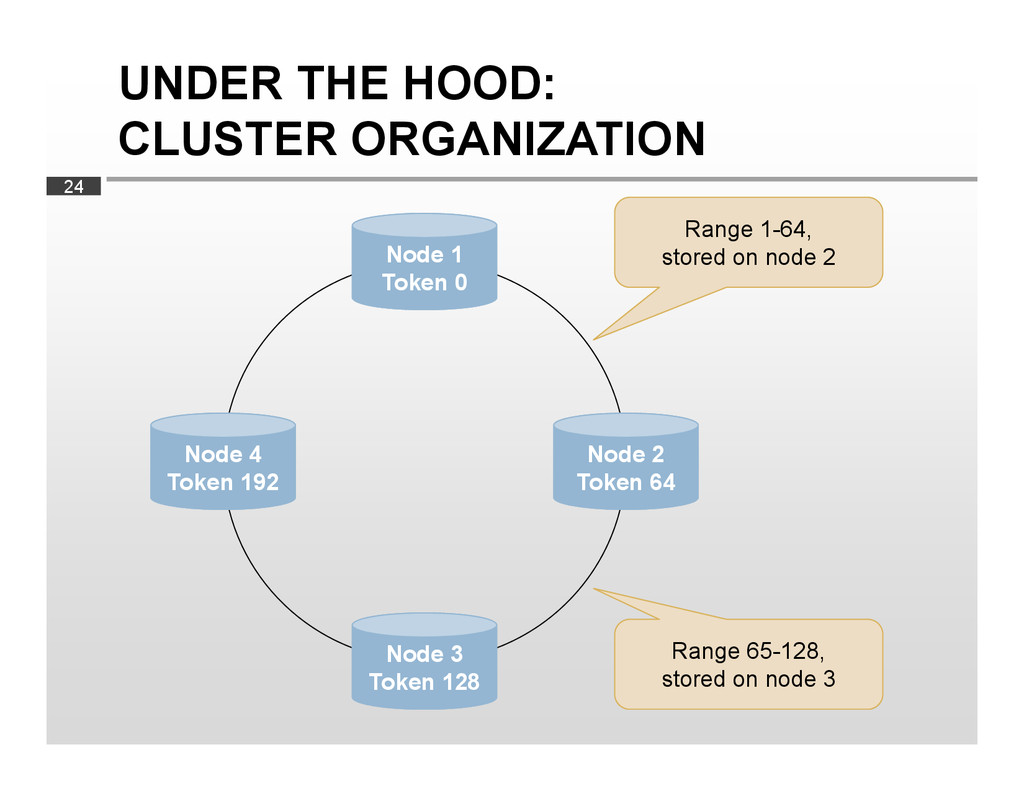{kind=link}
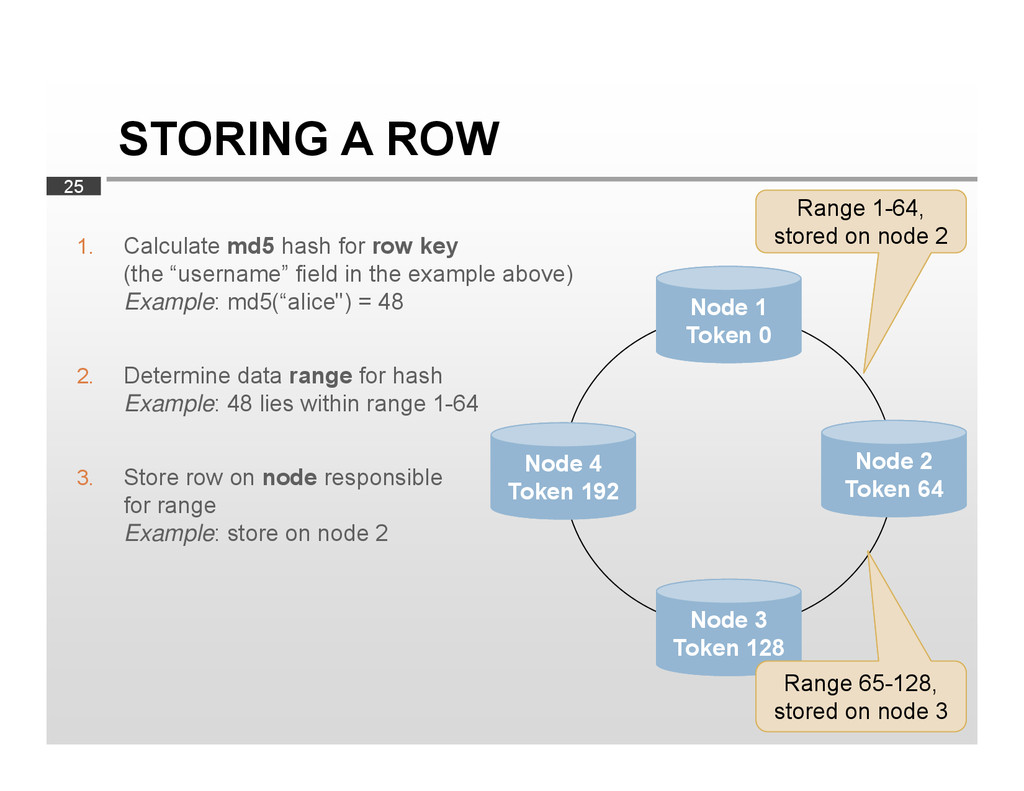{kind=link}
{kind=link}
{kind=link}
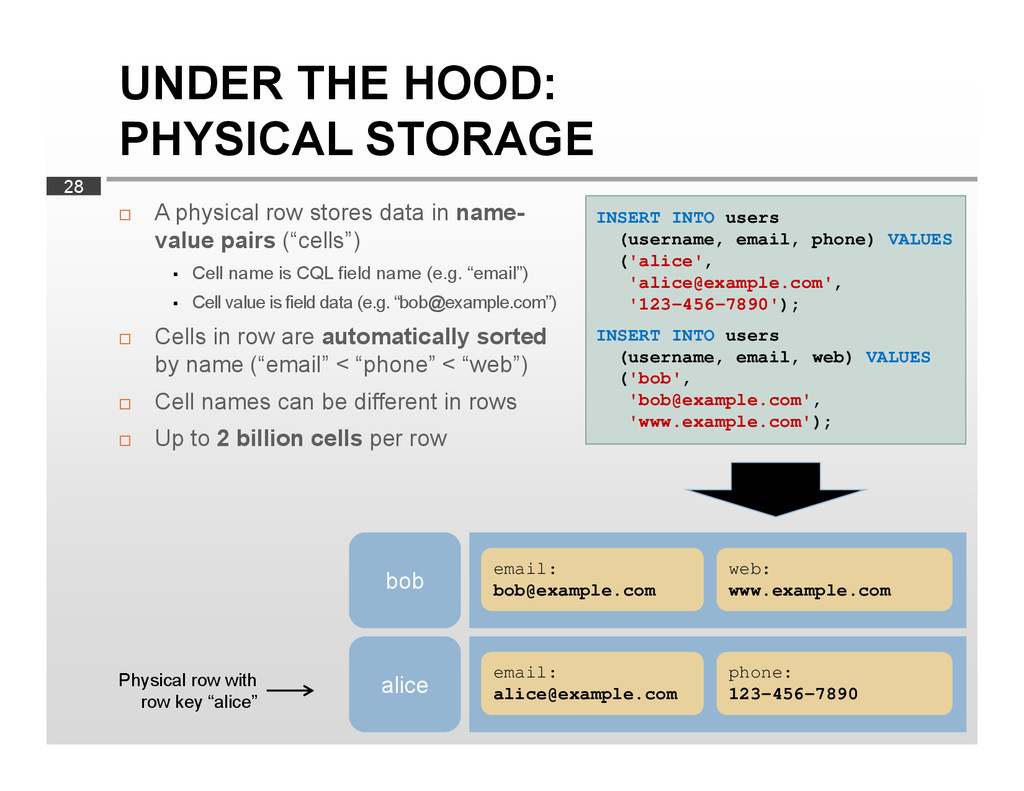{kind=link}
{kind=link}
{kind=link}
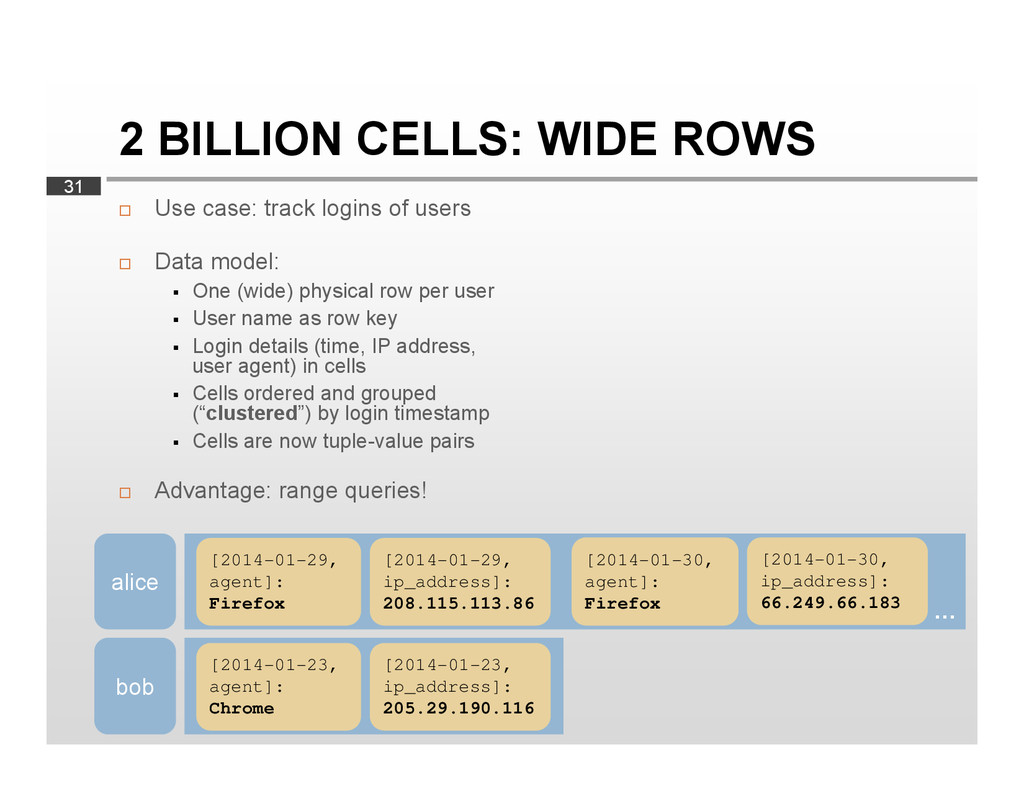{kind=link}
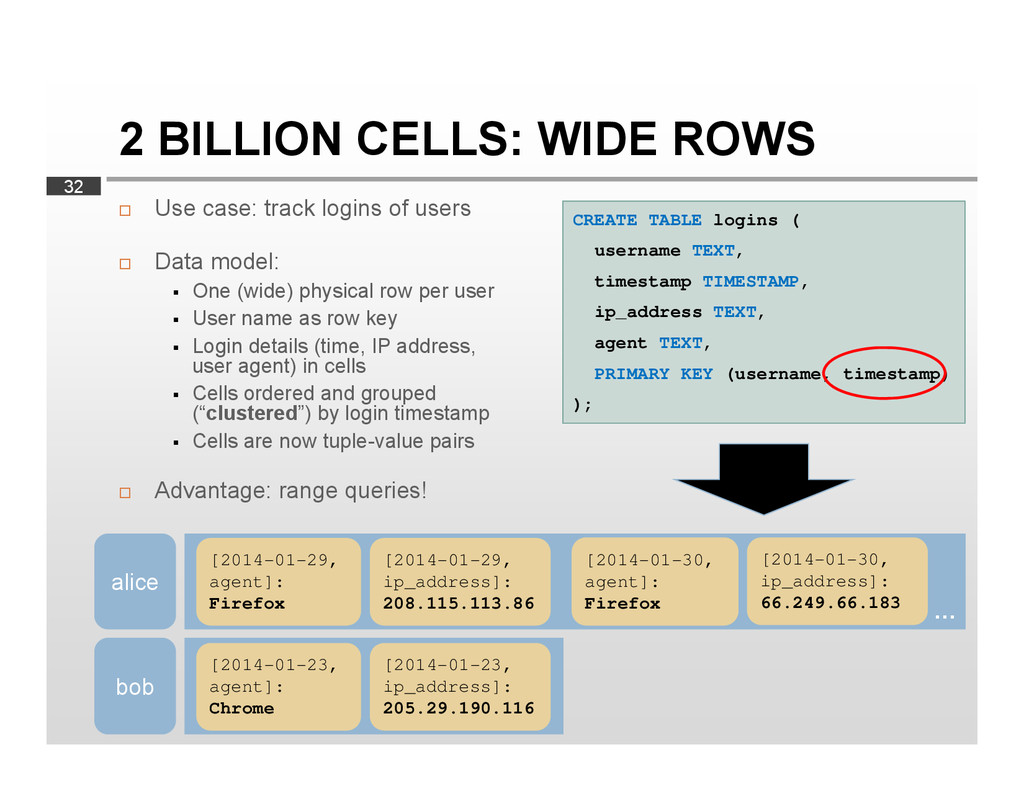{kind=link}
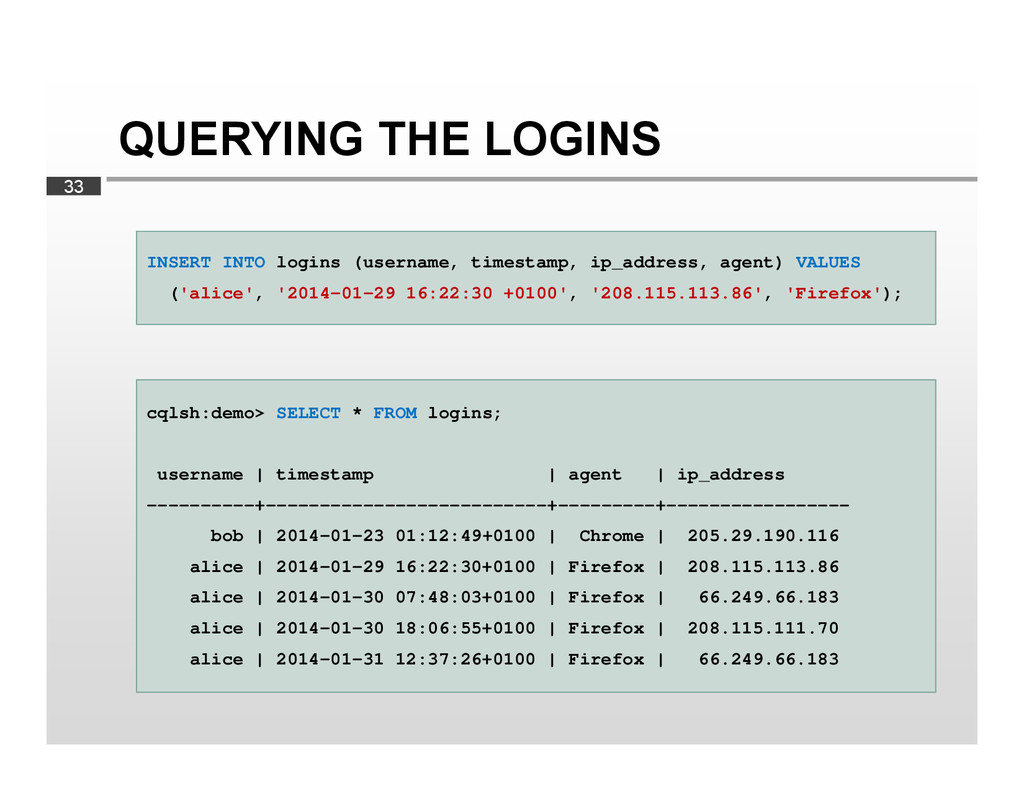{kind=link}
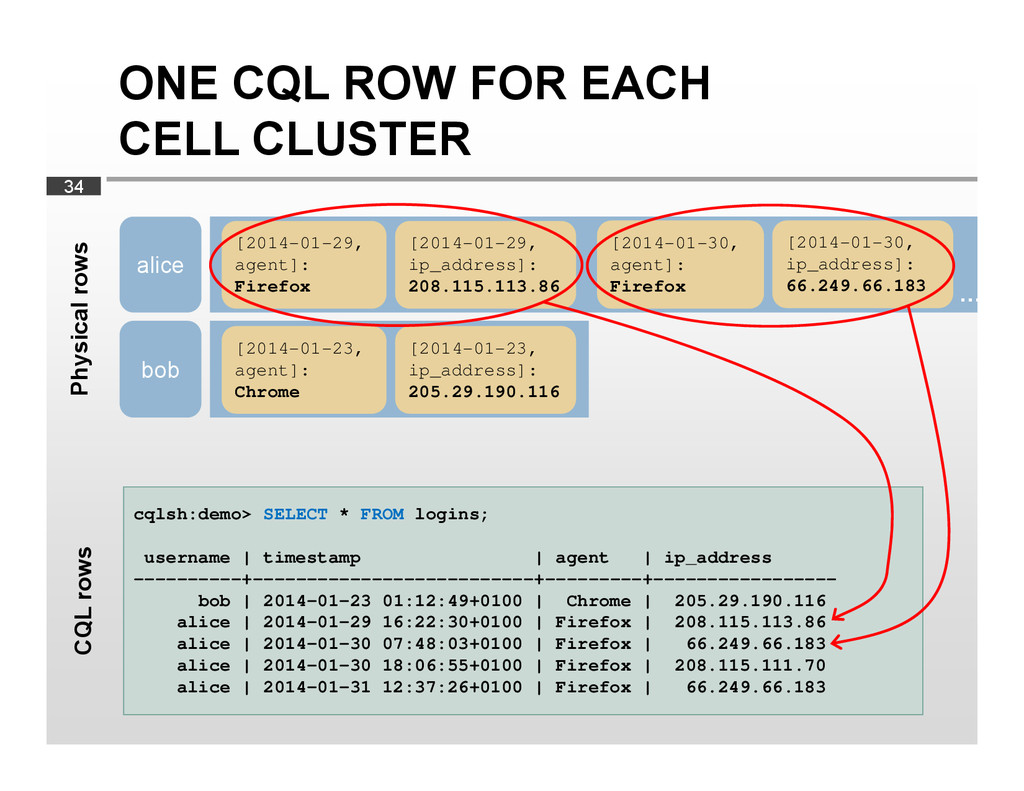{kind=link}
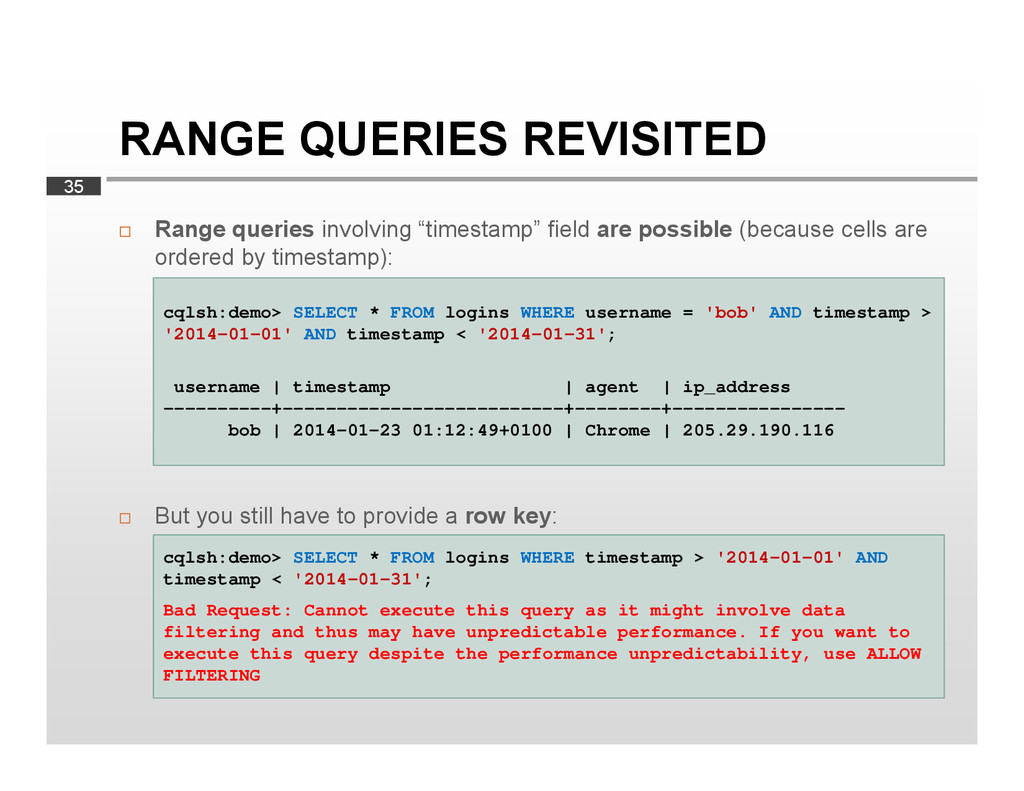{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}