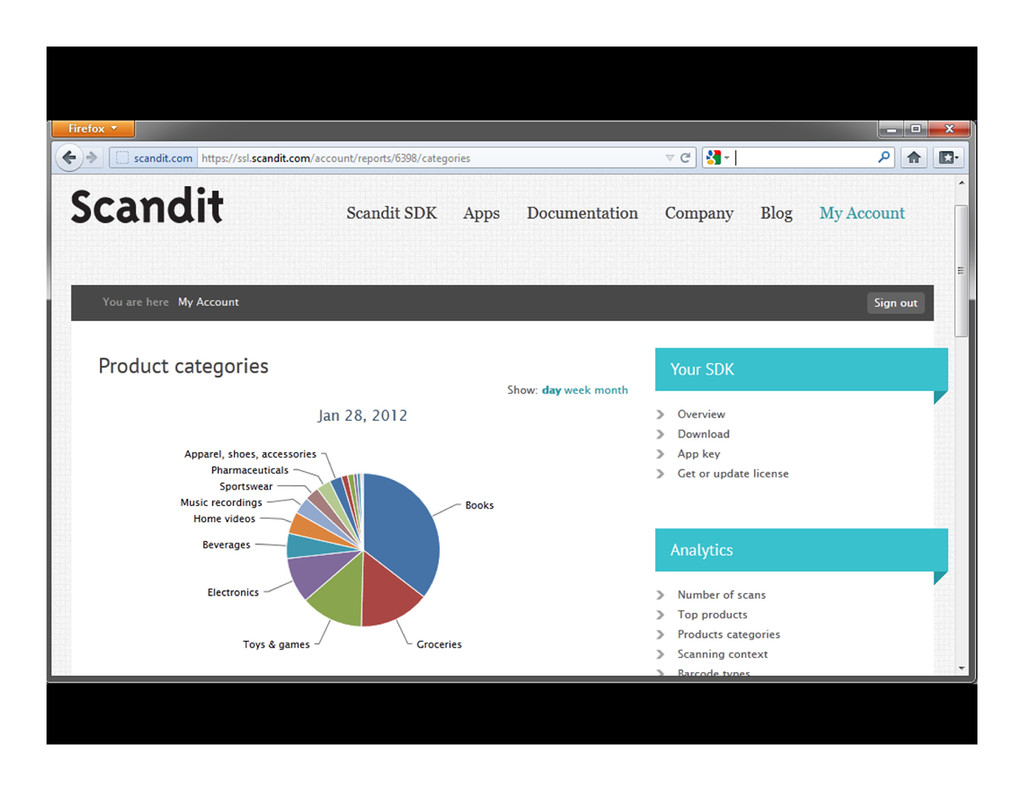
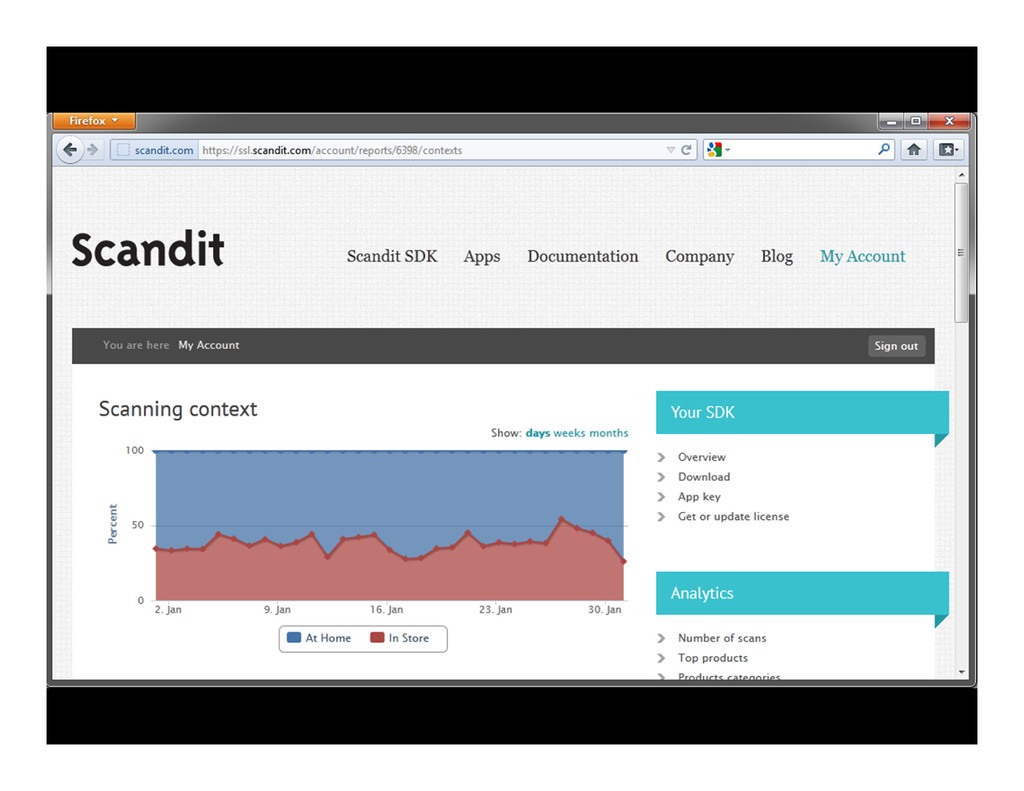
App-specific real-time usage statistics Insights into consumer behavior: What do users scan? Product categories? Groceries, electronics, books, cosmetics, …? Where do users scan? At home? Or while in a retail store? Top products and brands Identify new opportunities: Customer engagement Product interest Cross-selling and up-selling
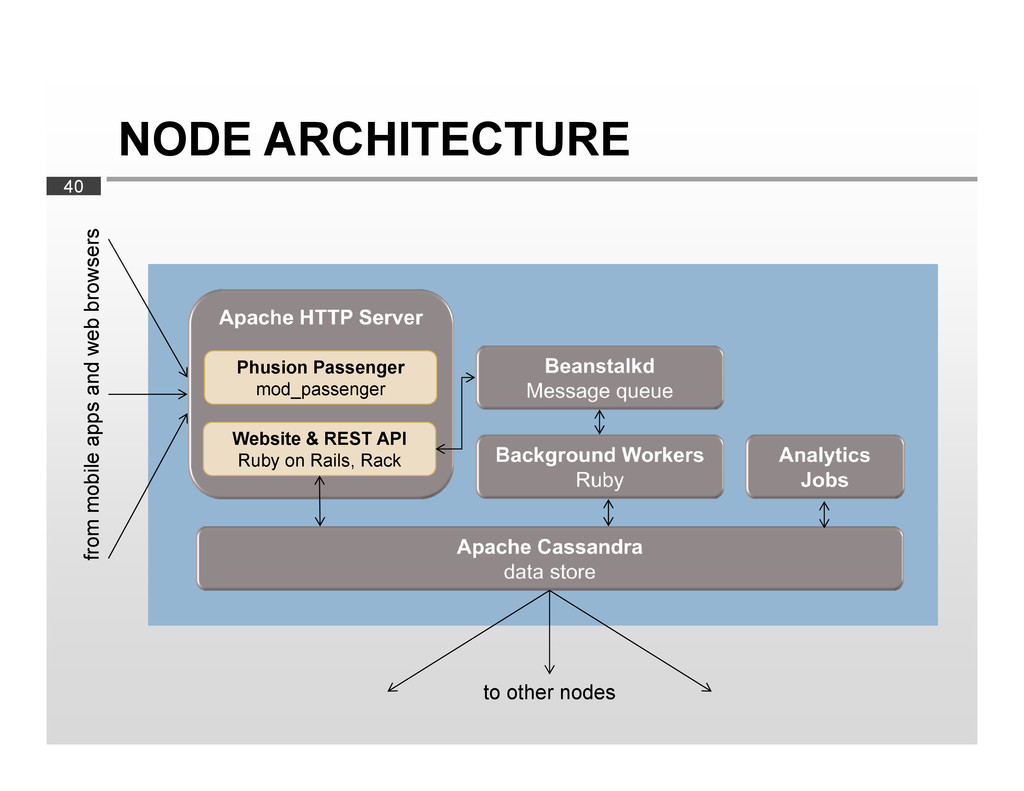
products Many different data sources Curation of product data (filtering, etc.) Analysis of scans Accept and store high volumes of scans Generate statistics over extended time periods Correlate with product data Provide reports to developers
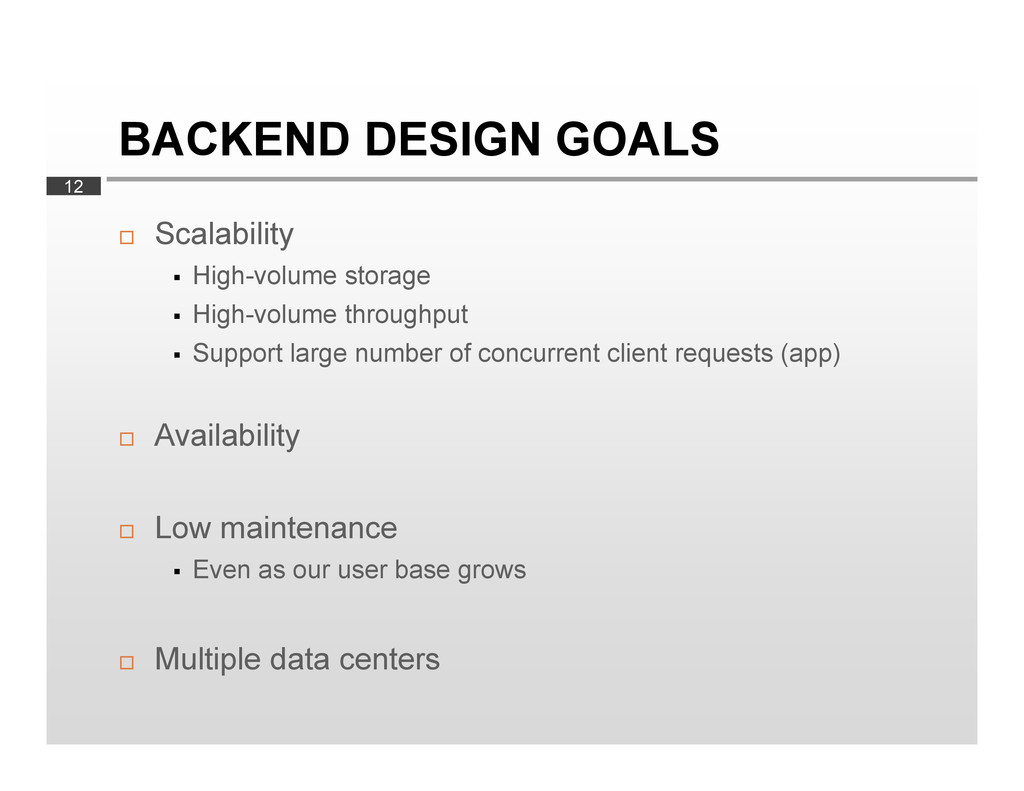
High-volume throughput Support large number of concurrent client requests (app) Availability Low maintenance Even as our user base grows Multiple data centers
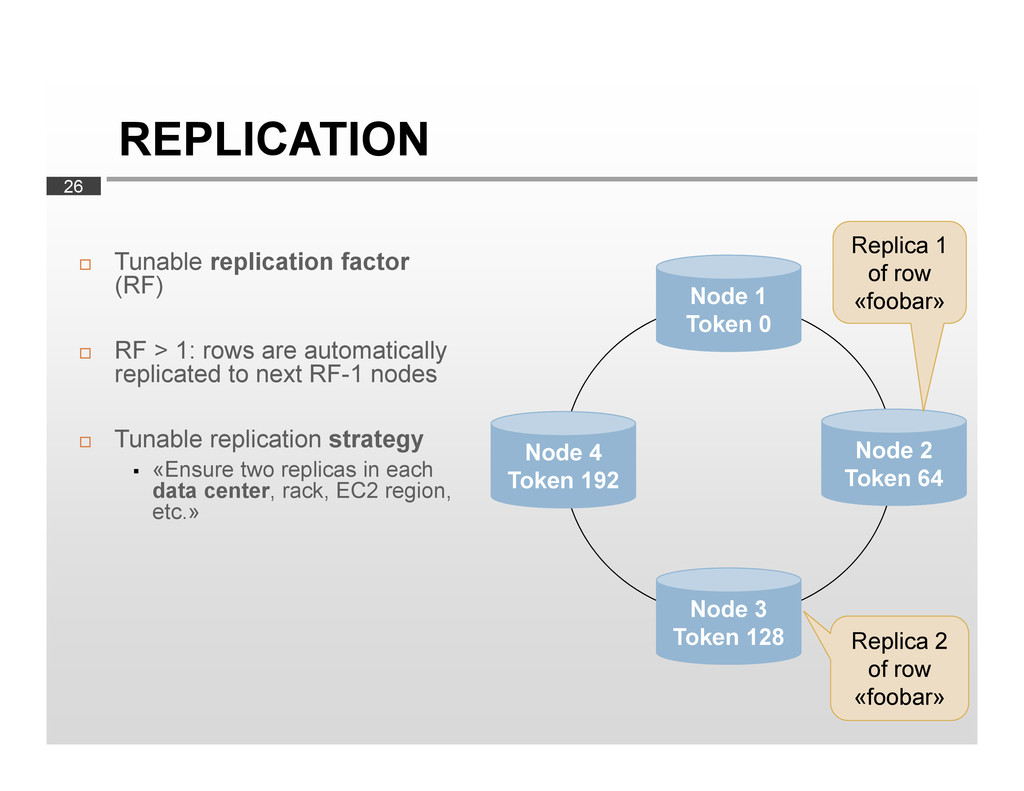
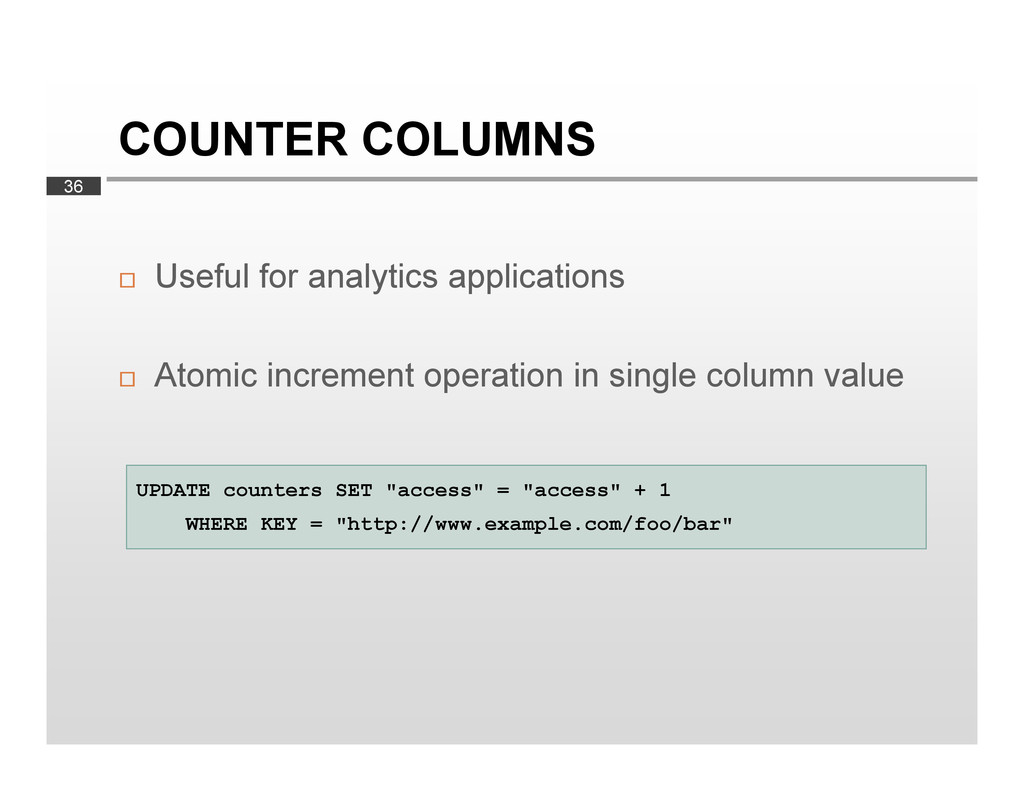
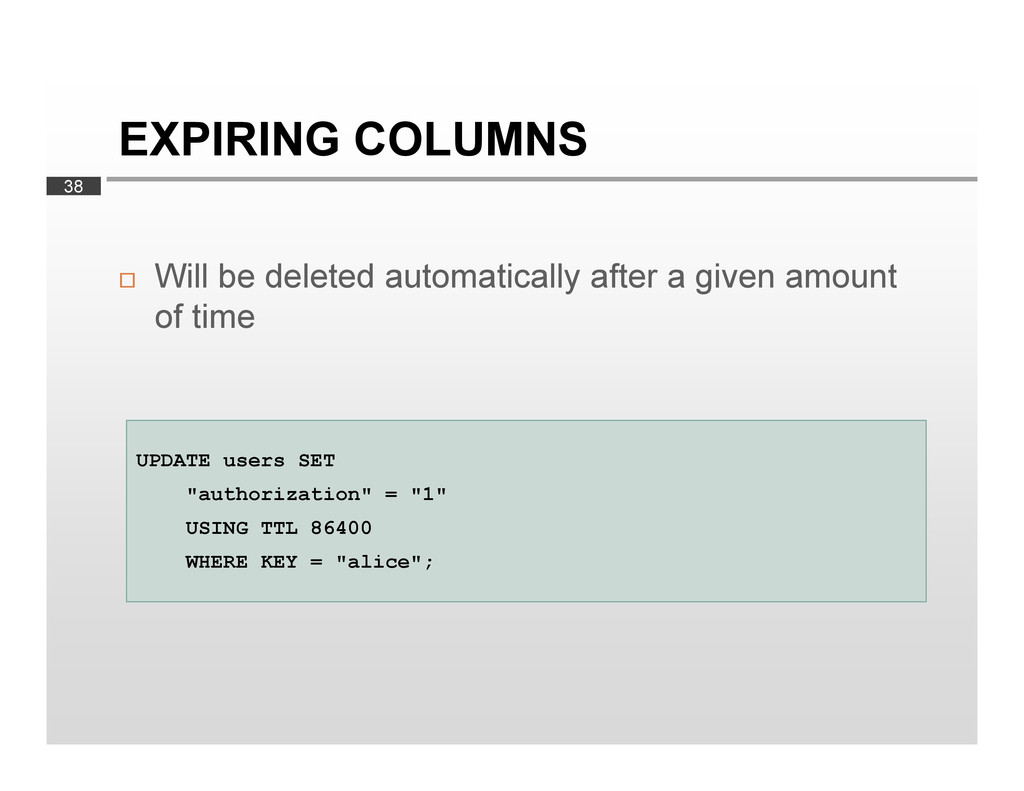
data is much larger than RAM Performs well in write-heavy environment Proven scalability Without downtime Tunable replication Data model YMMV…
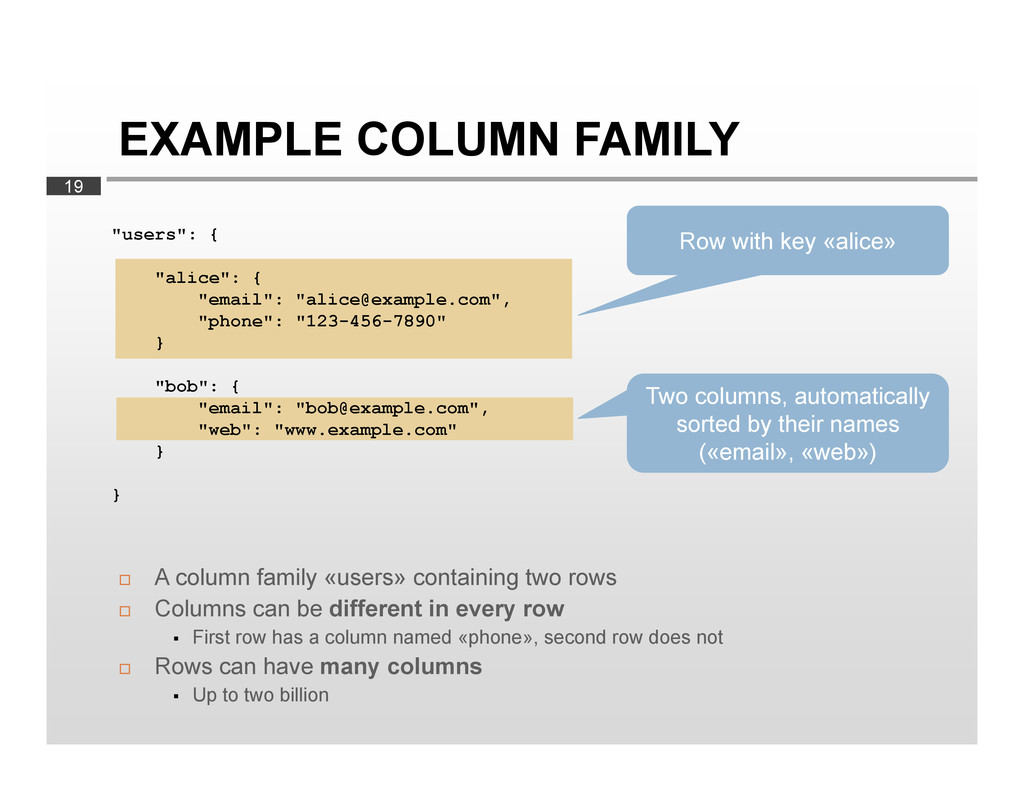
pair Row: Has exactly one key Contains any number of columns Columns are always automatically sorted by their name Column family: A collection of any number of rows (!) Has a name «Like a table»
two rows Columns can be different in every row First row has a column named «phone», second row does not Rows can have many columns Up to two billion "users": { "alice": { "email": "[email protected]", "phone": "123-456-7890" } "bob": { "email": "[email protected]", "web": "www.example.com" } } Row with key «alice» Two columns, automatically sorted by their names («email», «web»)
Data type can be defined for: Keys The values of all columns with a given name The column names in a CF By default, data type BLOB is used Data Types BLOB (default) ASCII text UTF8 text Timestamp Boolean UUID Integer (arbitrary length) Float Double Decimal
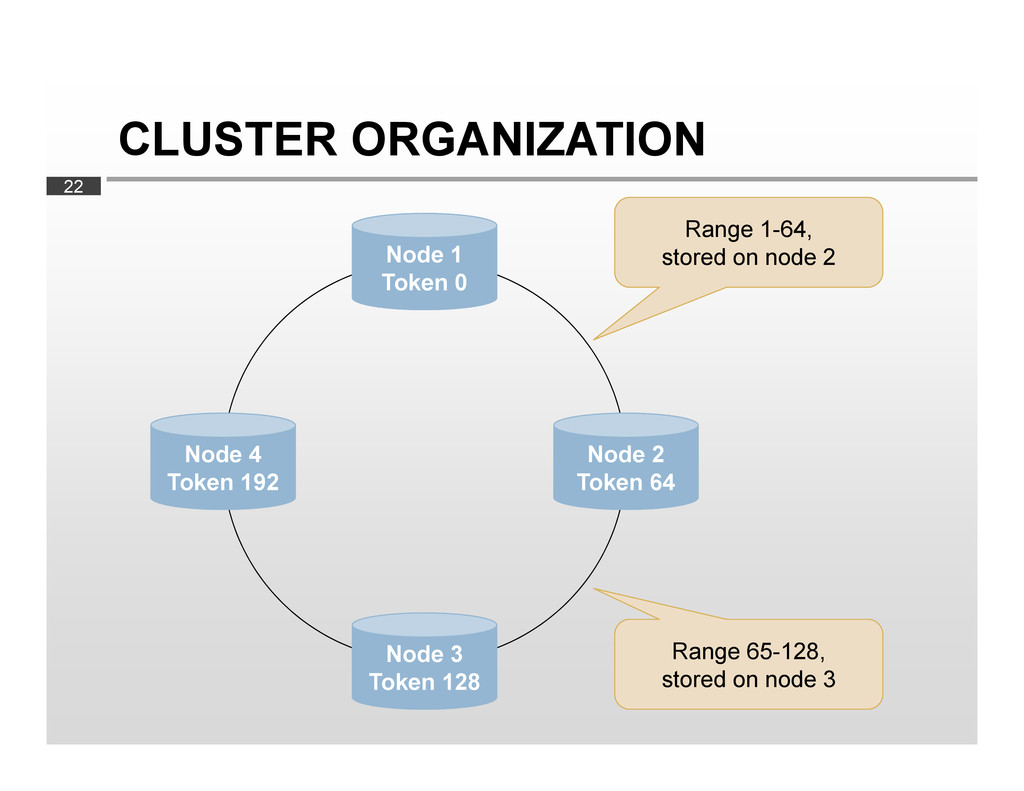
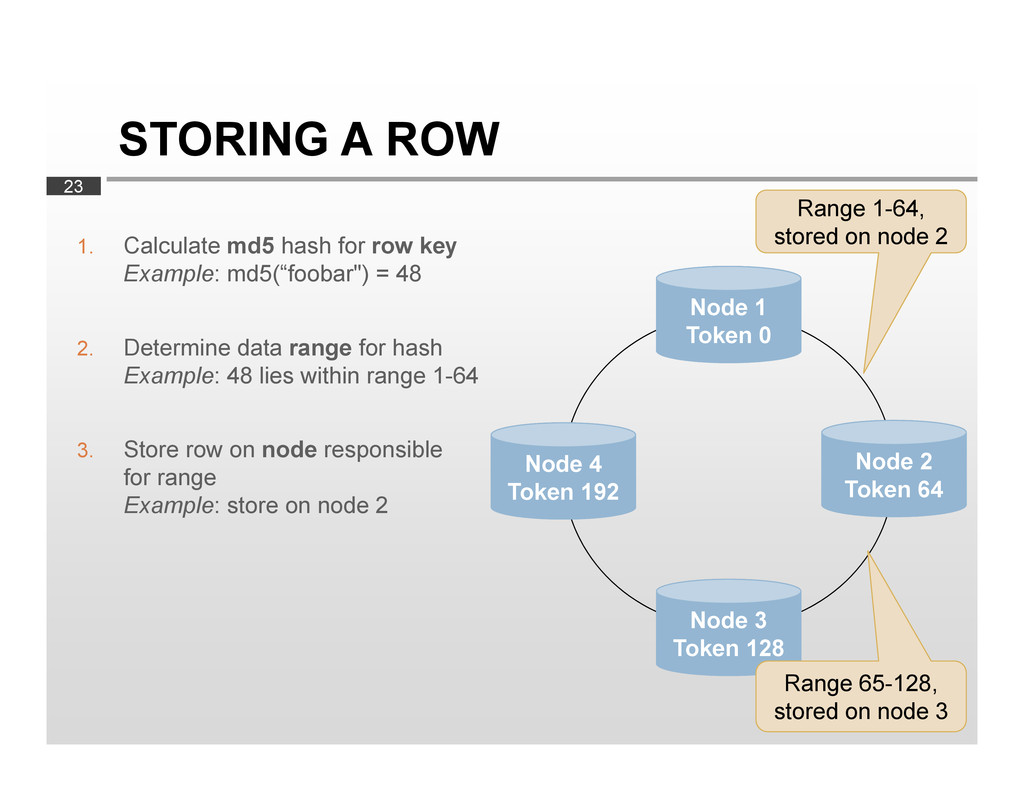
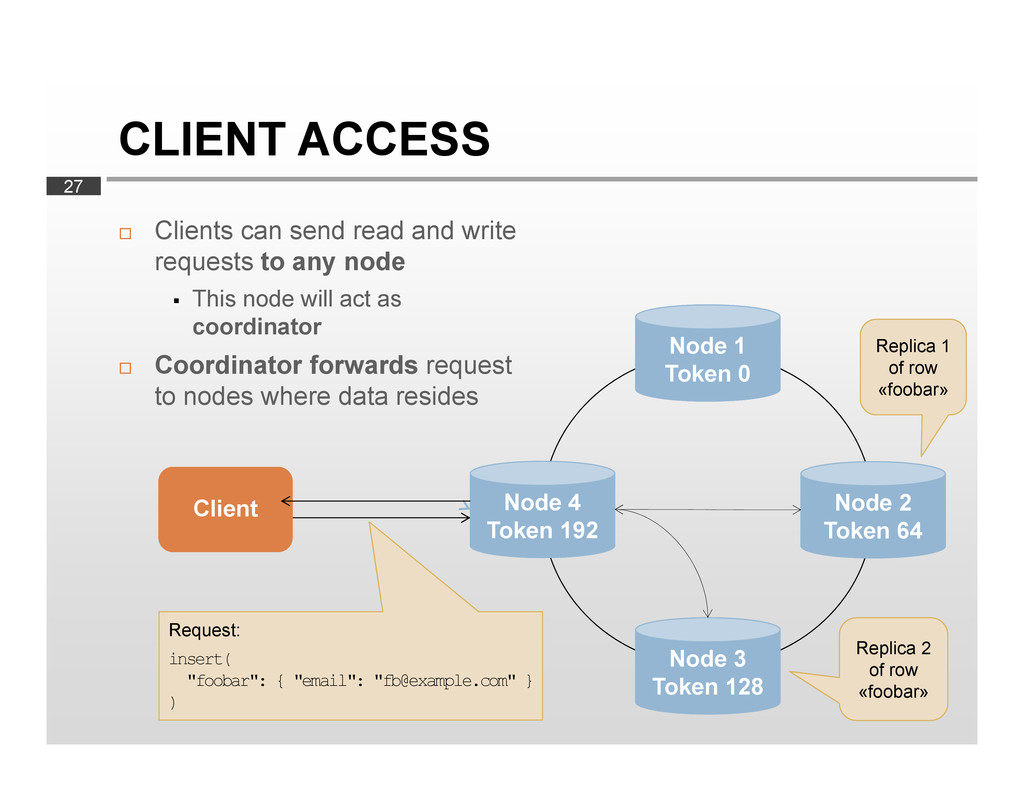
key Example: md5(“foobar") = 48 2. Determine data range for hash Example: 48 lies within range 1-64 3. Store row on node responsible for range Example: store on node 2 Node 3 Token 128 Node 2 Token 64 Node 4 Token 192 Node 1 Token 0 Range 1-64, stored on node 2 Range 65-128, stored on node 3
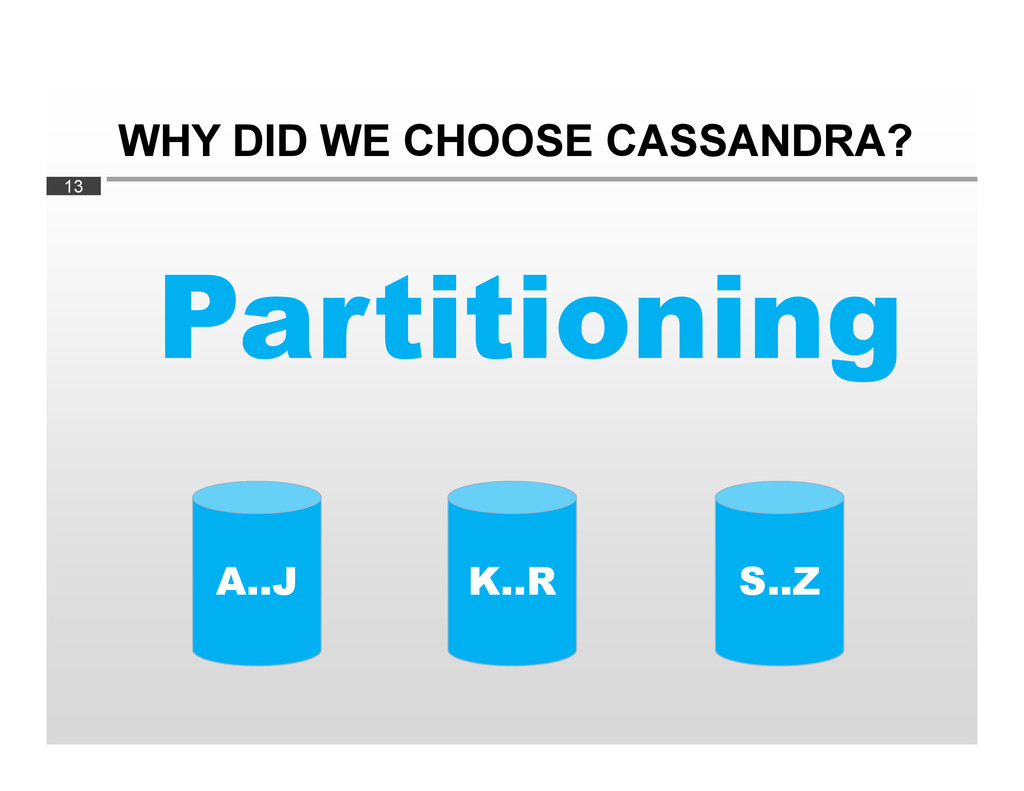
equally between nodes No hotspots Scaling out? Easy Divide data ranges by adding more nodes Cluster rebalances itself automatically Range queries not possible You can’t retrieve «all rows from A-C» Rows are not stored in their «natural» order Rows are stored in order of their md5 hashes
Partitioner» (OPP) OPP determines node based on a row’s key instead of its hash Don’t use it… Manually balancing a cluster is hard Hotspots Balancing cluster for one column family creates hotspot for another Option 2: Use columns instead of rows Columns are always sorted Rows can store millions of columns
all requests, clients can set a consistency level (CL) For writes: CL defines how many replicas must be written before «success» is returned to client For reads: CL defines how many replicas must respond before result is returned to client Consistency levels: ONE QUORUM ALL Data center-aware levels (e.g., LOCAL_QUORUM)
Two existing replica for row «foobar» Client overwrites existing columns in «foobar» Replica 2 is down What happens: Column is updated in replica 1, but not replica 2 (even with CL=ALL !) Timestamps to the rescue Every column has a timestamp Timestamps are supplied by clients Upon read, column with latest timestamp wins →Use NTP
can… Get all rows Get a single row by specifying its key Get a number of rows by specifying their keys Get a range of rows Only with OPP, strongly discouraged At a column level, you can… Get all columns Get a single column by specifying its name Get a number of columns by specifying their names Get a range of columns by specifying the name of the first and last column Again: no ranges of rows
(single) columns Secondary indices only support equality predicate (=) in queries Each node maintains index for data it owns Request must be forwarded to all nodes Sometimes better to manually maintain your own index CREATE INDEX email_key ON users (email); SELECT * FROM users WHERE "email" = "[email protected]"
fast Language bindings don’t have the same quality Out of sync, bugs Data model is a mental twist Design-time decisions sometimes hard to change Know your queries… Rudimentary access control No support for geospatial data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![32 "users": { "alice": { "email": "[email protected]", "phone": "123-456-7890" }](https://files.speakerdeck.com/presentations/4feca9d4bf92280022005b82/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}