Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Play Scala on AWS, C10K and DevOps
Search
arai-yusuke
April 23, 2016
Technology
1.5k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Play Scala on AWS, C10K and DevOps
arai-yusuke
April 23, 2016
More Decks by arai-yusuke
See All by arai-yusuke
Serverless Scala
cmaraiyusuke
0
2.2k
Scala: Mobile Backend on AWS
cmaraiyusuke
1
870
Other Decks in Technology
See All in Technology
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
240
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
160
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
240
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
180
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
270
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.7k
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
800
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
350
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
440
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.5k
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.2k
AI時代の闇と光
tatsuya1970
0
100
Featured
See All Featured
A better future with KSS
kneath
240
18k
The Invisible Side of Design
smashingmag
301
52k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
220
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
950
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
The Pragmatic Product Professional
lauravandoore
37
7.4k
A Tale of Four Properties
chriscoyier
163
24k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Transcript
PLAY SCALA ON AWS C10K とDevOps Yusuke A. / Classmethod,
Inc.
WHOAMI Yusuke Arai Server App Programmer / AWS Architect http://dev.classmethod.jp/author/arai-yusuke/
クラスメソッドでは、iOS / Android ネイティブアプリの 受託開発を行っています。 バックエンドにはAWS を用います。
C10K インフラ設計に問題がなくてもクライアントが1 万超 えだしたらサー バー パンクします問題 Web 2.0 のころから既に問題提起されている Netty
(Java), Node.js, Play (Java, Scala) などのアプリケ ー ションフレー ムワー クがこの問題に挑戦してきた 文脈によって意味が微妙に異なるタイプのワー ド
スマホアプリとC10K スマホアプリの開発では、 バックエンドAPI サー バー が C10K 問題としっかり向き合う必要があります。
スマホ 日本国内のスマホ普及率は49.7%(2015/8 日経BP) 5000 万人以上がスマホを通じてネットにアクセス 日本で( ひいては世界で) もっとも普及ている「 イン ター
ネットにつながったデバイス」 1 日の平均的なスマホ利用時間は2 時間くらい 10 代、20 代にフォー カスすると5 時間くらい(!) 女子高生にフォー カスすると7 時間くらい(!?)
スマホアプリの受託開発 B to B to C スマホ普及率の上昇に比例して、KPI 目標数値も上昇 してきている 初年度インストー
ル数目標は100 万のオー ダー 目標達成時には100,000 MAU 以上が容易に想定される MAU = Monthly Active User( 月間アクティブユー ザー)
10 万以上のMAU が想定される時点で、 すでにC10K 問題と 向き合うべきアプリケー ションです。 くわえて、 スマホアプリ開発には特筆すべき点がもう一 つあります。
スマホアプリの特性 スマホアプリと《 モバイルプッシュ通知》 は切り離せま せん。 B2B2C における顧客は「 エンドユー ザー と円滑に
コミュニケー ションをとる方法」 を求めています。 彼らにとって、 その問題のソリュー ションのひとつがス マホアプリであり、 その機能の中でも《 プッシュ通知》 はとても魅力的なコミュニケー ション方法だからです。
プッシュ通知のリター ン プッシュ通知にはリター ンがあります。 エンドユー ザー が通知に反応してアプリを開いた結果、 バックエンドの API やCDN
へのアクセスが発生します。 100 万件のプッシュ通知を発行した場合、10% のアクテ ィブユー ザー が一斉に反応すると瞬間的に10 万のアクセ スがバックエンドに集中します。
先ほどの100 万件の例で言えば、15 分毎に1 万ユー ザー ず つ配信する負荷分散があり得ます。 この場合は延べ1 日 以上の配信時間がかかります。
ここまで極端な例でなくとも、 数時間単位で配信に時間 がかかることは、 顧客にとって受容しがたい場合がほと んどです。
C10K 問題と向き合う 現在のClassmethod スマホアプリ開発チー ムは モバイルバックエンドAPI サー バー は、 C10K
問題に対応するのが当然。 という考え方です。
C10K のソリュー ション AWS 2 Tier チー ム全員がAWS のエキスパー トである前提。
アプ リが複雑化する。iOS / Android で全く同じビジネス ロジックを書く必要がある。 AWS Lambda + Amazon API Gateway プロダクション適用はまだ厳しい。 本当にリソー ス 間のトランザクションが不要かの精査が難しい。 C10K に答えられるアプリケー ションの構築 ✔
開発チー ムはPlay Framework 2 の採用を決めました。 しかし、『 ただ採用するだけ』 では何も解決しません。
PLAY とC10K Play Framework 2.4 を使って 1,000 RPS のアプリを開発したお話をします。 RPS
= Request Per Minute( リクエスト毎秒)
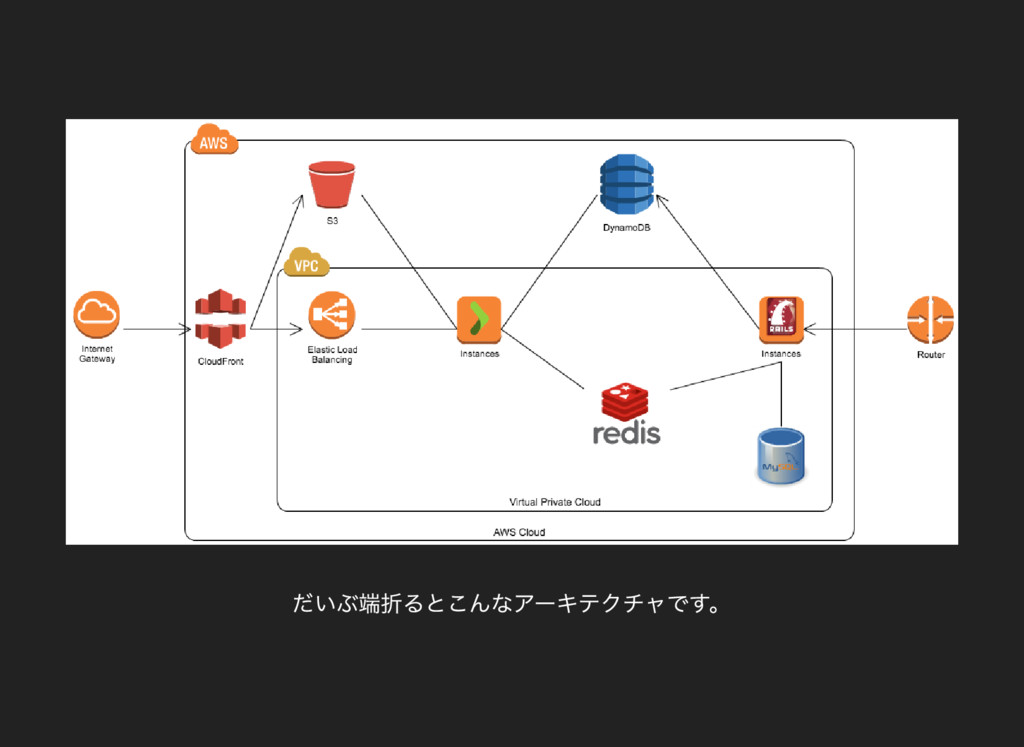
アプリケー ションの概要 飲食系大手企業のB2C モバイルアプリ 予想される初年度インストー ル数は100 万のオー ダー プッシュ通知の一斉配信あり 試算ではAPI
サー バー 全体で 1,000 RPS の性能要求 バックエンドにはPlay を採用 ✔
だいぶ端折るとこんなアー キテクチャです。
最終的な目標は、 負荷試験ツー ルを用いて 1,000 RPS の 性能をAWS 環境ににデプロイされたアプリケー ションで 確認することでした。
開発チー ムは当初より Play を正しく使えばこの要求は達成できる というスタンスでした。
結論から言えば、 この時の認識は甘かったです。 Play アプリが実際に1,000 RPS を捌くためには、 正しく使 ったうえで超えなければならない壁がありました。
PLAY を正しく使う … ために、 以下の点に配慮して開発を進めました。 同期的なI/O の禁止 I/O のタイプ毎にExecutionContext ※を分ける
Request-Response 形式以外の処理はAkka Actor に切り分 ける。 ※ ExecutionContext は、 平たく言えばスレッドプー ルです。Scala のFuture と密接に関係します。
壁1 Play のアプリログ出力がボトルネックになる 最終的にログ出力用のActor を実装した 事前に行っていた" やわめ" の負荷試験では発覚しな い、 高RPS
ならではの問題だった
壁2 スレッドプー ルの数が多くなり、 最適な設定値を探す のに苦労した ExecutionContext を細かく分割したのは高RPS に対処 する上でとても有効だったが、 副作用として設定が
複雑になった 基本的には、I/O 処理委譲先のスルー プットを考慮 してスレッド数を決めていく 低IOPS だけど集中する予定ならスレッド数多め 高IOPS ならスレッド数低め
壁3 Future のシリアルな結合数が多すぎるとアウト 数十回のAPI 呼び出しの結果を集約して返す処理 Future はMonadOps なので、 とりあえずflatMap で結
合したくなる もちろんシリアルに処理されるから超遅い いわゆる「Applicative で十分パター ン」 ぽいのだけ れど、 使っているのはscala.concurrent.Future 結局実装をまるっと変えるはめになった。 実力不足 感があった
その他のハマった罠 Redis クライアントライブラリ(scala-redis) がデフォ ルトでスレッドセー フじゃなかった Akka のFault Torelance が難易度高い
でステー ト持っちゃったり Amazon Linux でJava 起動するとデフォルトのopen file limit が4096 だった(※ 知ってたらハマらない) AWS のAPI 性能がボトルネックになる箇所もあった
http://dev.classmethod.jp/server-side/play-framework-stress-test-pre-checklist/
PLAY とDEVOPS Play アプリをAWS 環境に継続的にデプロイしています。
大前提として、 ホットデプロイは目指していません。 AWS の仕組みをしっかり使えば、「 ホットデプロイじゃ ないから」 という理由で極端にデプロイが遅くなったり 煩雑になったりはしません。
AWS のDevOps なサー ビスたち AWS CloudFormation AWS Elastic Beanstalk AWS
CodeDeploy AWS OpsWorks
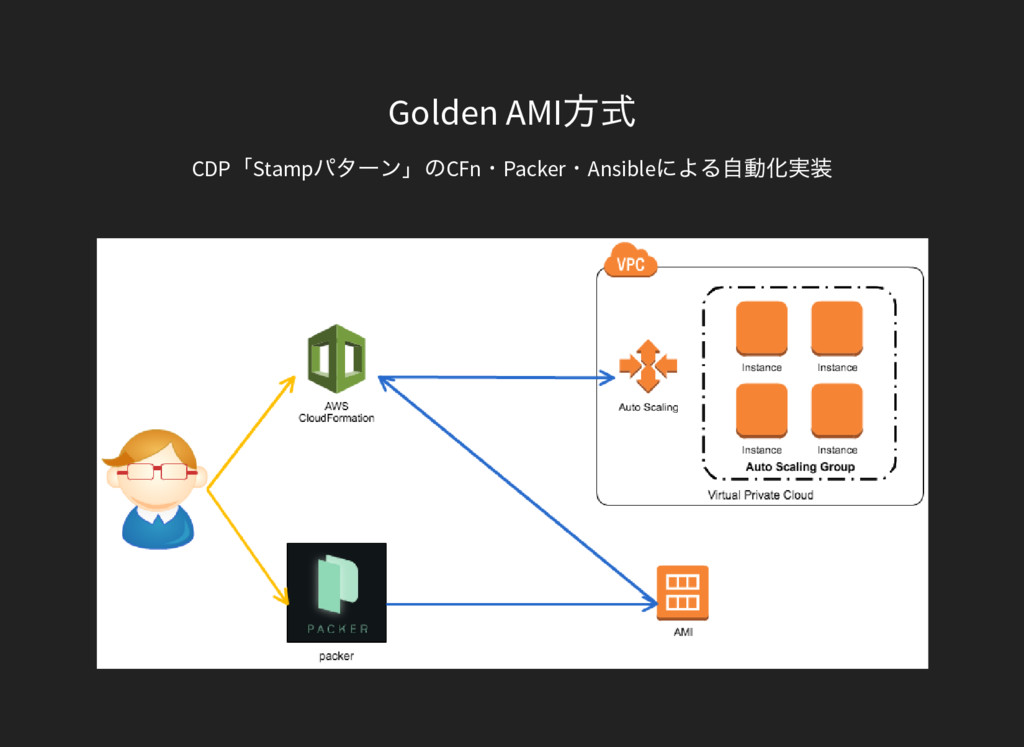
Golden AMI 方式 CDP「Stamp パター ン」 のCFn・Packer・Ansible による自動化実装
Golden AMI 方式 Packer にAnsible Playbook を実行させ、 アプリバンドル 済みAMI を作成
このAMI をGolden AMI と呼ぶ CFn により、AutoScaling Group のRolling Update で Golden AMI のインスタンスをデプロイする Infrastructure as Code
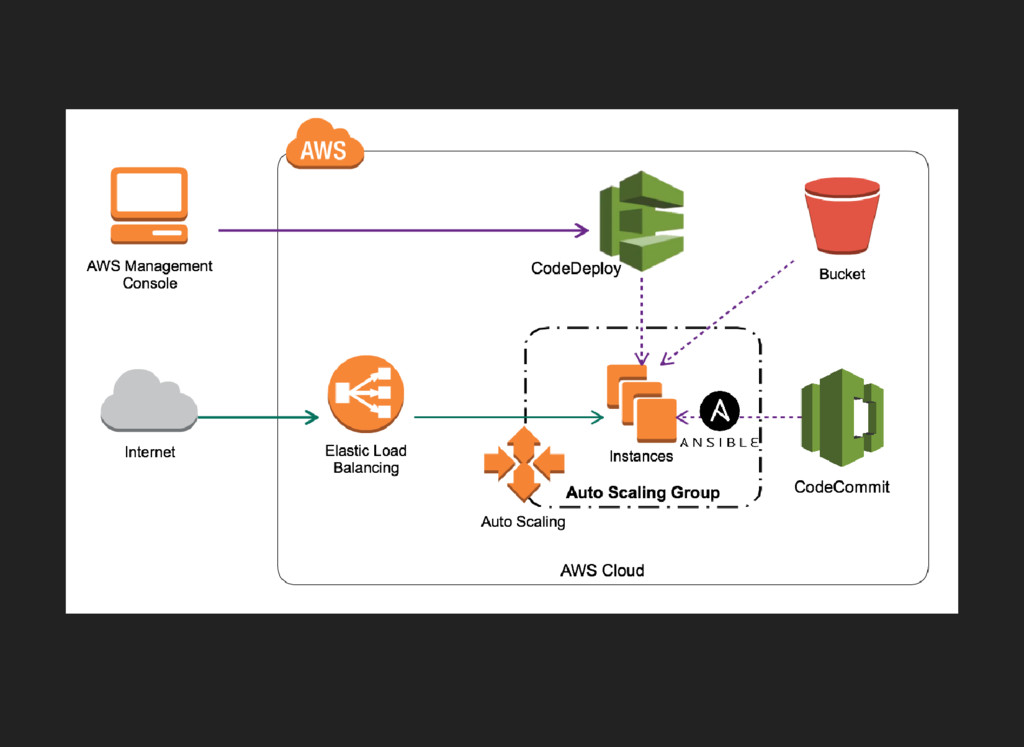
AWS CodeDeploy
CodeDeploy の利用 「Golden AMI 方式」 で作成したAnsible Playbook を流用 CodeDeploy を利用することでインスタンスの
Stop/Start なしでデプロイ アプリを再起動するshell script は自分で書く 速度的に優秀だが、 堅牢さでGolden AMI 方式に劣る http://aws.amazon.com/jp/documentation/codedeploy/
None
デプロイ方式 顧客がどの程度の堅牢さを求めているのかで変わる。 開発環境 ステー ジング環境 本番環境 案件A Ansible ※ Golden
AMI Golden AMI 案件B CodeDeploy Golden AMI Golden AMI 案件C CodeDeploy CodeDeploy CodeDeploy ※ Dynamic Inventory(ec2.py) の利用
顧客タイプとデプロイ 顧客の求めるセキュリティレベルによって、 DevOps の方法は変わってきます。 Golden AMI 方式は、 セキュリティに高い関心を持つ 顧客に提案します。 対してCodeDeploy
は、RTO や開発スピー ドに関心を 持っている顧客に適しています。
EB は使ってないの? 使っています。 ただし、JVM アプリのデプロイには使っていません。 Ruby on Rails で作成されたCMS( 管理画面)
などの デプロイに使っています。 EC2 インスタンスにどの程度のカスタマイズが必要か、 が大きな基準です。 ほとんどカスタマイズが要らない& アプリもそんなに複雑でないなら、EB がマッチします。 BCP の有無も一つ基準になるかもしれません。
どの方式でもCI サー ビスやJenkins から自動化できます。
今日のまとめ プッシュ通知のリター ンに耐える Play Framework 高負荷時の罠を知る Golden AMI 方式とCodeDeploy を使い分ける
AWS を駆使してDevOps と向き合う
ご清聴ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}