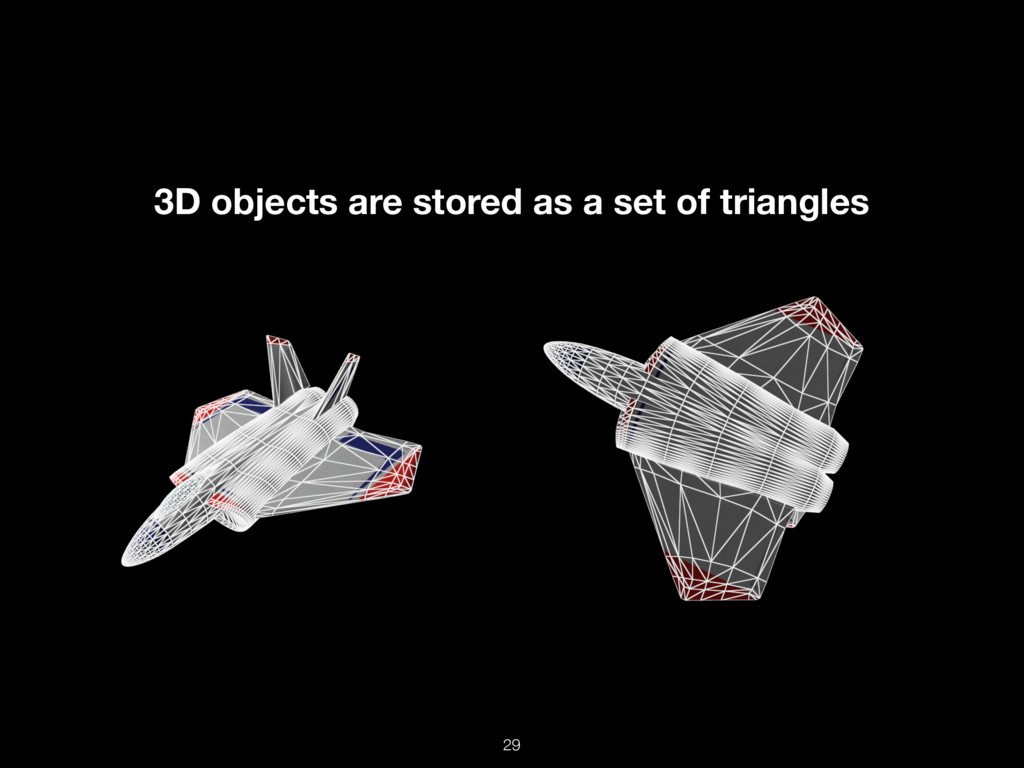
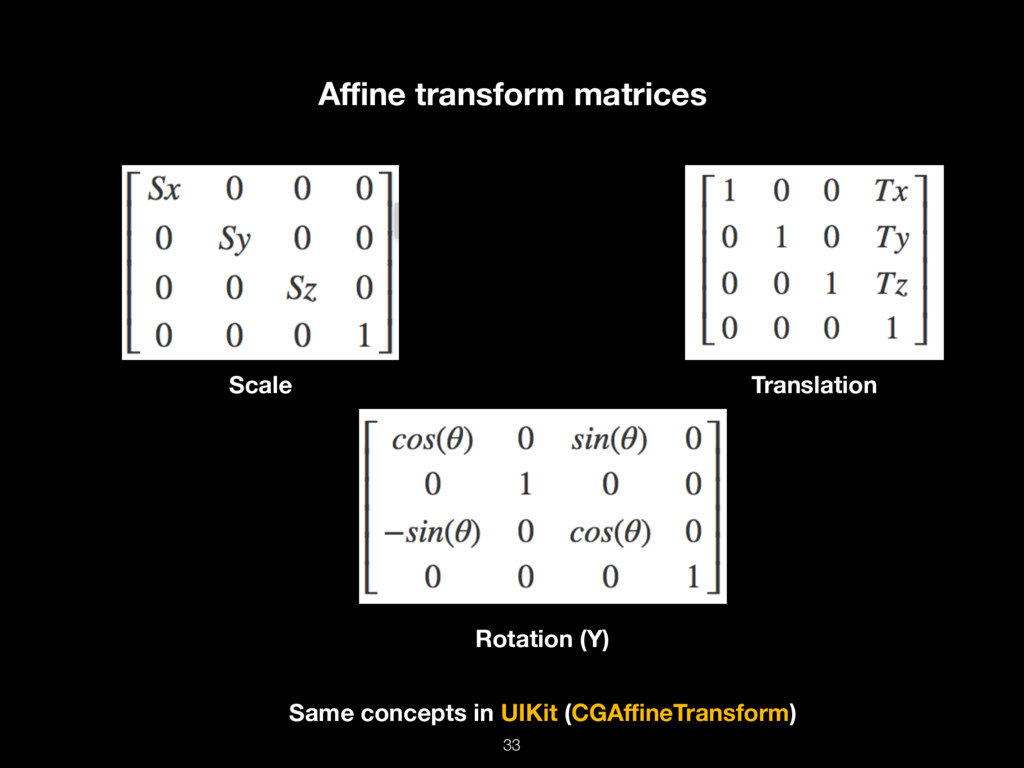
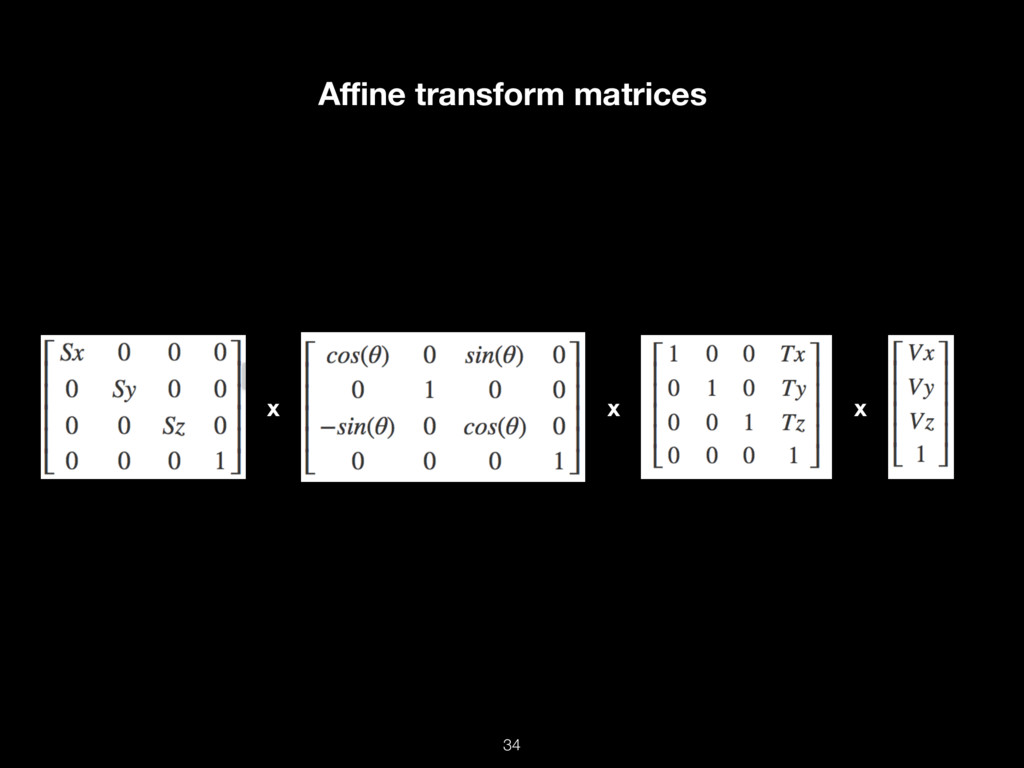
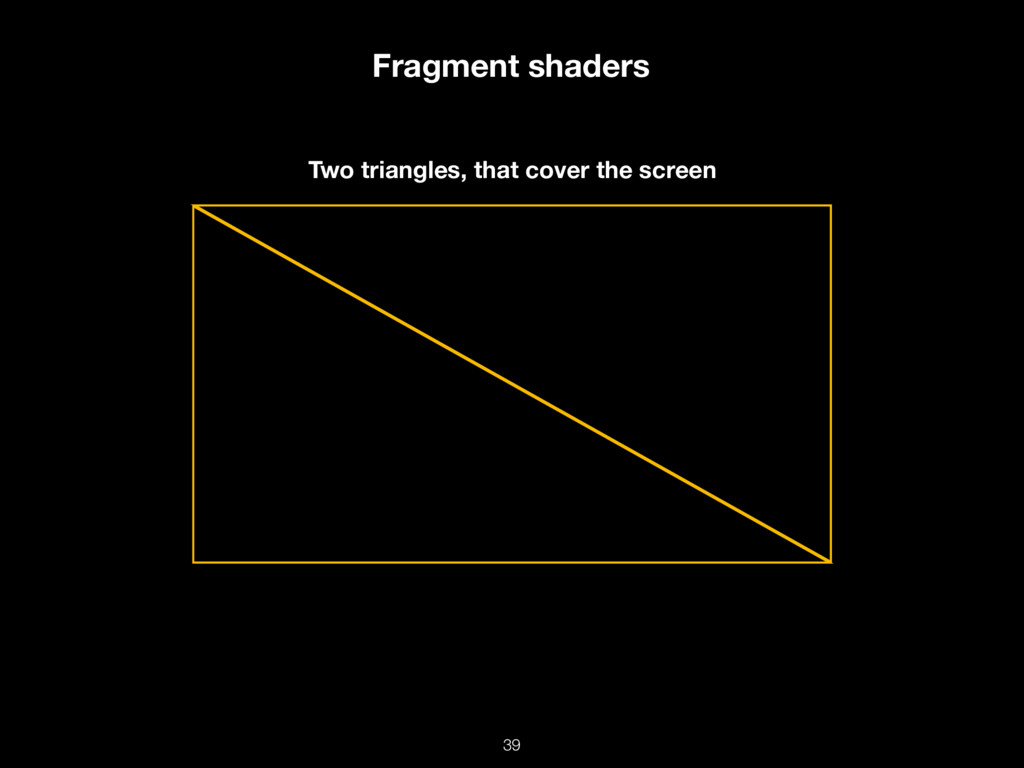
Современный мир не был бы таким, какой он есть, без GPU-вычислений. Современные консольные игры, VR, AR, криптовалюты, машинное обучение — всё это работает на горячих графических процессорах.
Однако среди мобильных разработчиков видеокарты не пользуются большой популярностью: многие думают, что это очень сложно, а некоторые вообще не замечают, что iPhone в принципе имеет видеокарту.
Этим докладом хотелось бы ознакомить широкие массы разработчиков с программированием графических процессоров, с прицелом на мобильные платформы и, конечно же, трендовые темы.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
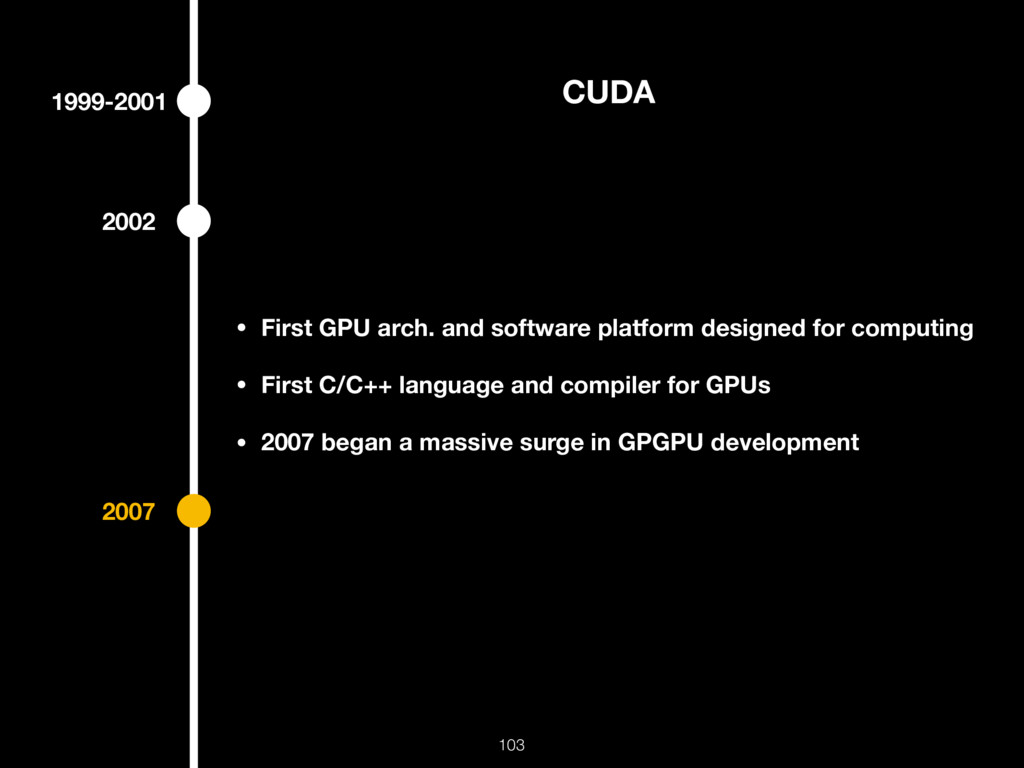{kind=link}
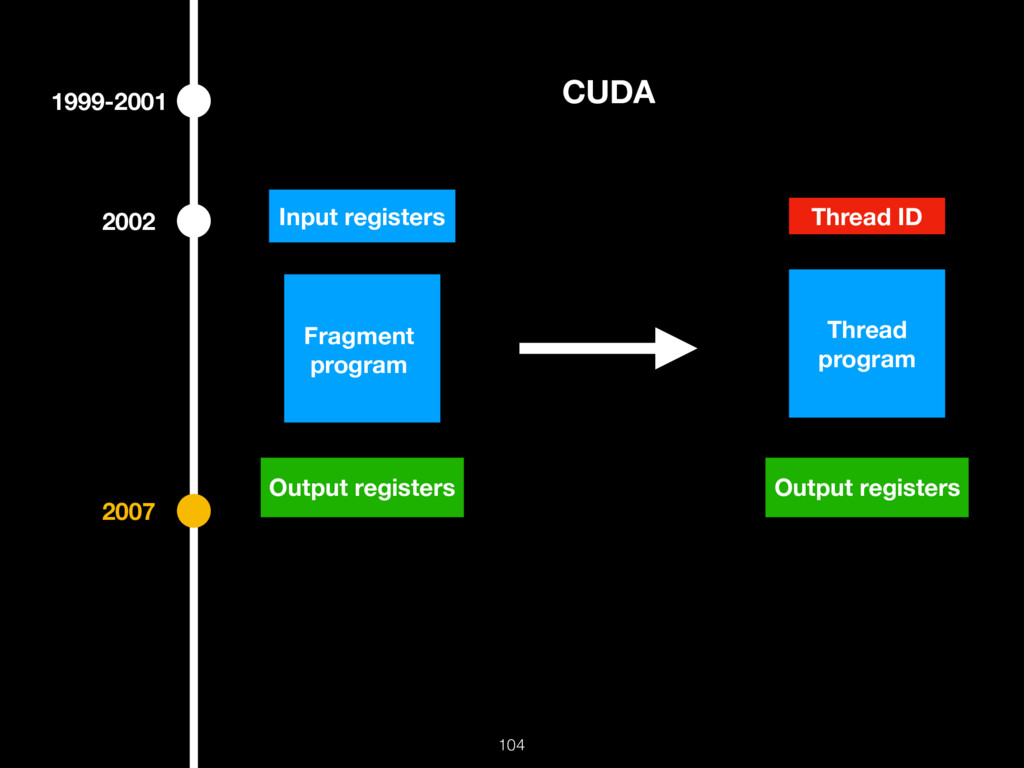{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![public class ArrayProcessor { public func process(array: [Float], multiplier: Float)](https://files.speakerdeck.com/presentations/632e9b7086224ba3845d57e73bb8a047/slide_111.jpg){kind=link}
![public class ArrayProcessor { public func process(array: [Float], multiplier: Float)](https://files.speakerdeck.com/presentations/632e9b7086224ba3845d57e73bb8a047/slide_112.jpg){kind=link}
![public class ArrayProcessor { public func process(array: [Float], multiplier: Float)](https://files.speakerdeck.com/presentations/632e9b7086224ba3845d57e73bb8a047/slide_113.jpg){kind=link}
![public class ArrayProcessor { public func process(array: [Float], multiplier: Float)](https://files.speakerdeck.com/presentations/632e9b7086224ba3845d57e73bb8a047/slide_114.jpg){kind=link}
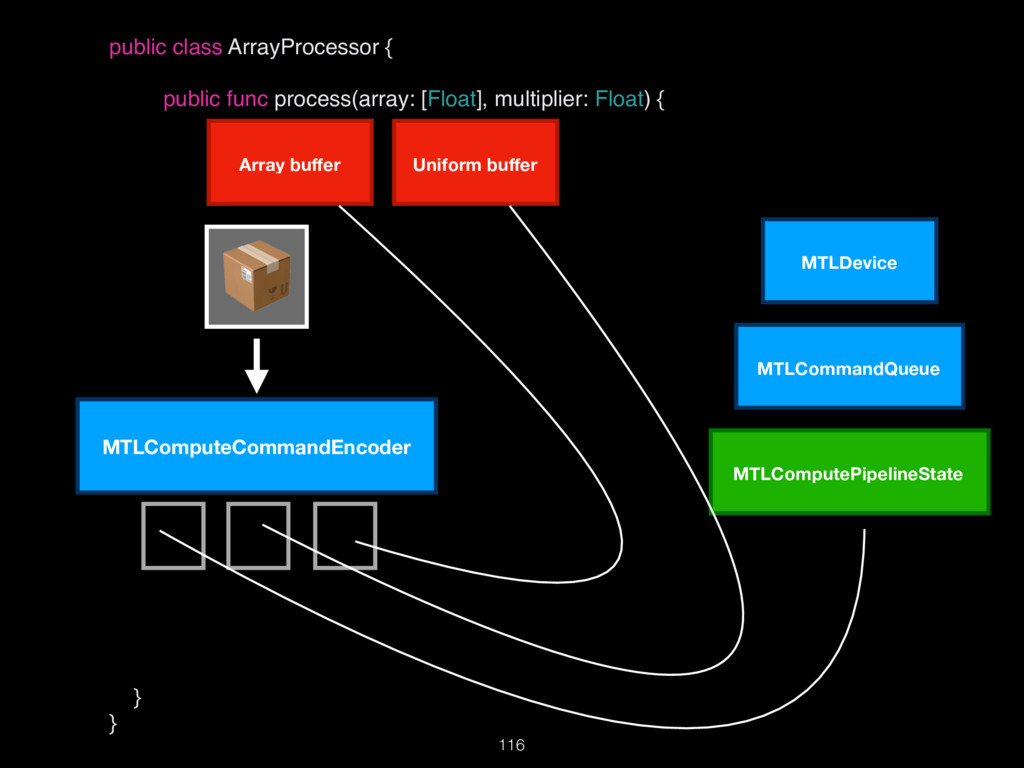{kind=link}
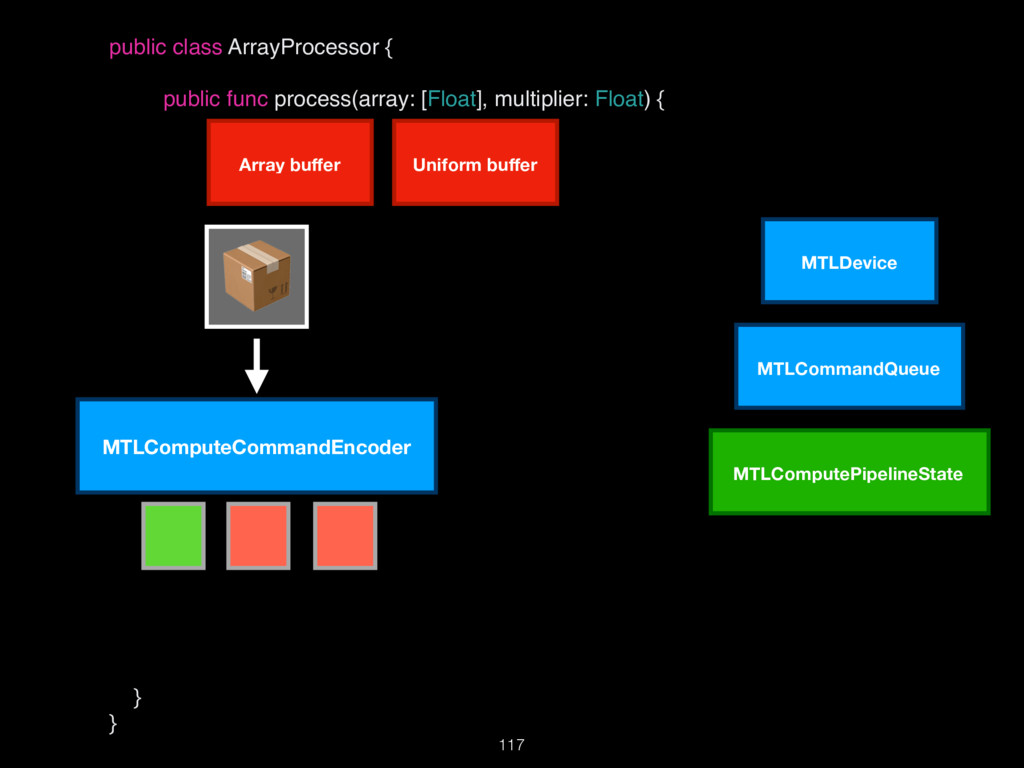{kind=link}
{kind=link}
{kind=link}
![Threads and threadgroups kernel void myKernel(uint2 threadgroup_position_in_grid [[ threadgroup_position_in_grid ]],](https://files.speakerdeck.com/presentations/632e9b7086224ba3845d57e73bb8a047/slide_119.jpg){kind=link}
![Threads and threadgroups kernel void myKernel(uint2 threadgroup_position_in_grid [[ threadgroup_position_in_grid ]],](https://files.speakerdeck.com/presentations/632e9b7086224ba3845d57e73bb8a047/slide_120.jpg){kind=link}
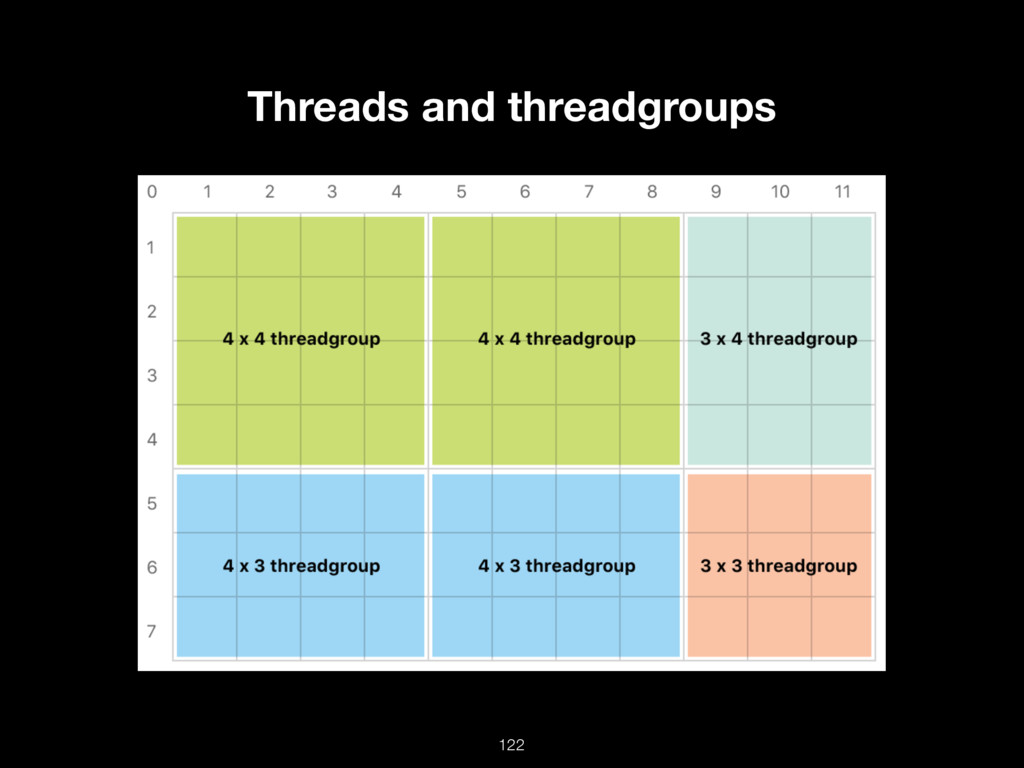{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
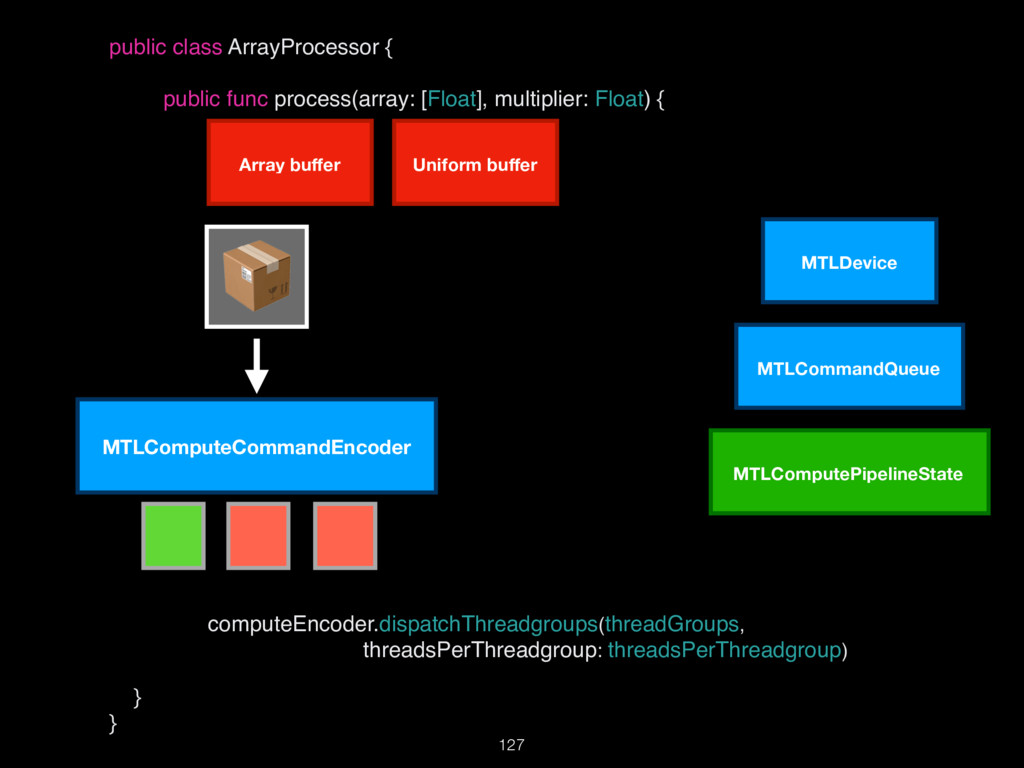{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
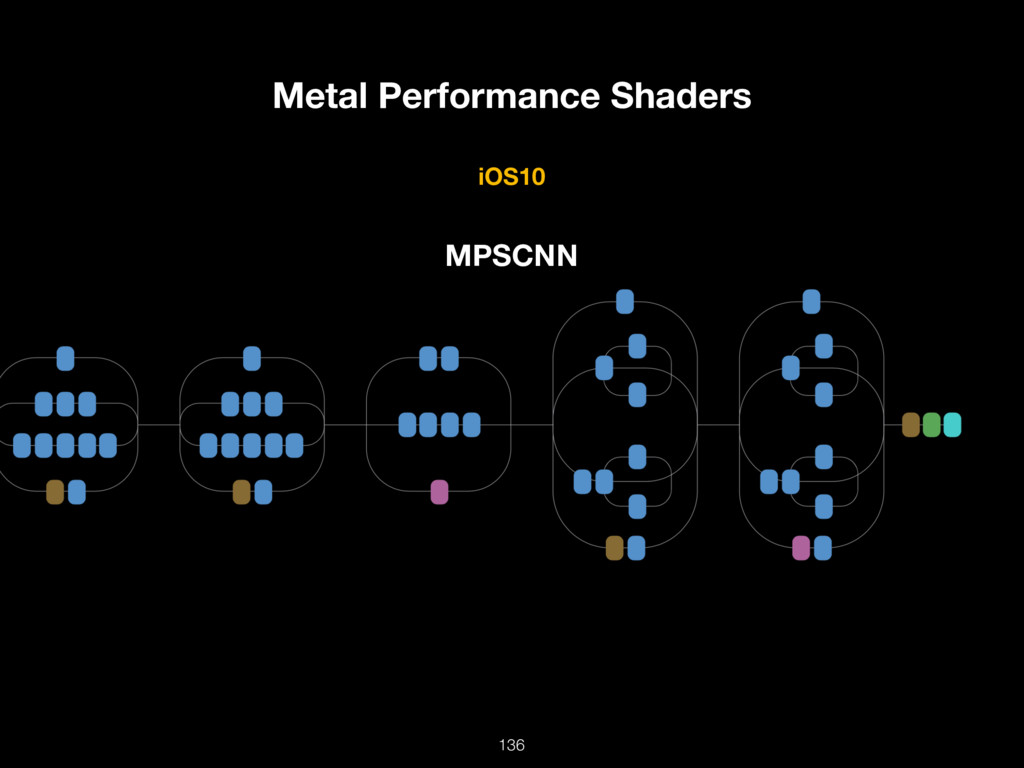{kind=link}
{kind=link}
{kind=link}
{kind=link}
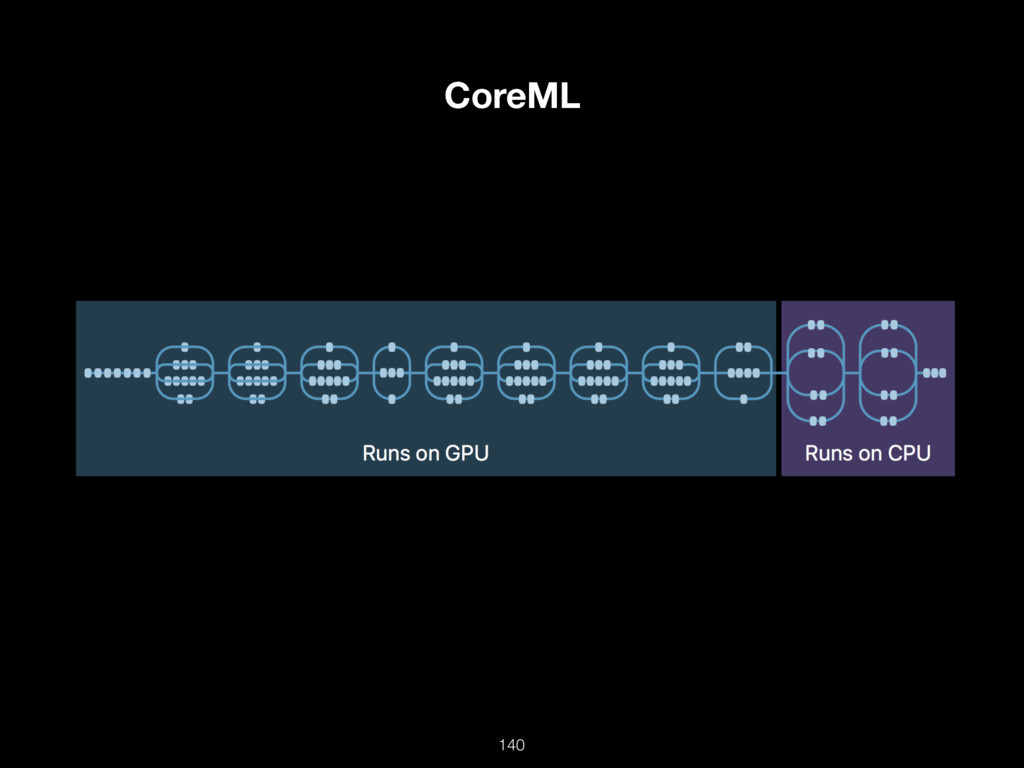{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! @s1ddok @s1ddok [email protected] 145](https://files.speakerdeck.com/presentations/632e9b7086224ba3845d57e73bb8a047/slide_144.jpg){kind=link}
{kind=link}