Посмотрите выступление Константина: https://2018.codefest.ru/lecture/1294/
В докладе попытаюсь сравнить архитектуру и технические решения, используемые в современных SQL и NoSQL системах, в частности Couchbase, MongoDB, Cassandra, CockroachDB и, конечно, Tarantool. Как разбиваются данные, по диапазону, хэш функции, или bucket id? Как выбирается размер бакета? Какая хэш-функция используется? Как происходит перебалансировка при переполнении? Где хранится информация о распределении данных и их текущим местоположении? Есть ли выделенный программный компонент для роутинга запросов, или роутинг осуществляется самими узлами хранения? Ответы на эти вопросы, а также на вопрос *почему* разработчики приняли то или иное решение, плюсы и минусы различных подходов я раскрою в своём докладе. PS Несколько лет назад мы с Алексеем Рыбаком делали совместный доклад про шардинг с использованием MySQL или PostgreSQL. Видео и слайды доклада можно найти здесь: youtube хабрахабр Новый доклад - на старую тему, но совсем с другой стороны: я буду рассказывать про устройство готовых решений, а не про то, как приготовить решение самому.
![Sharding in modern [No]SQL databases Konstantin Osipov, CTO, Tarantool Novosibirsk,](https://files.speakerdeck.com/presentations/48f93fd9fc9e46c18ad31977de9be447/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
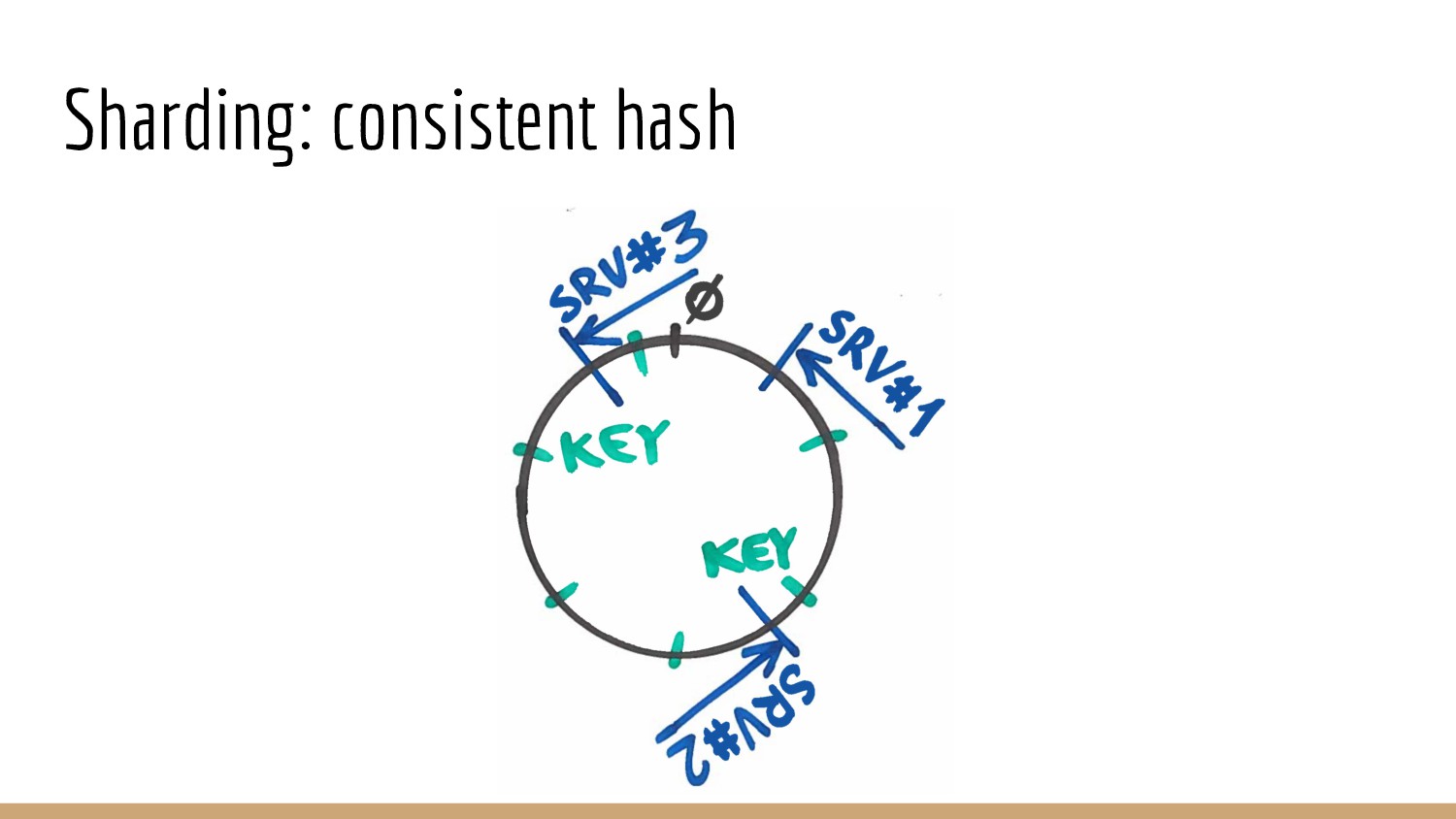{kind=link}
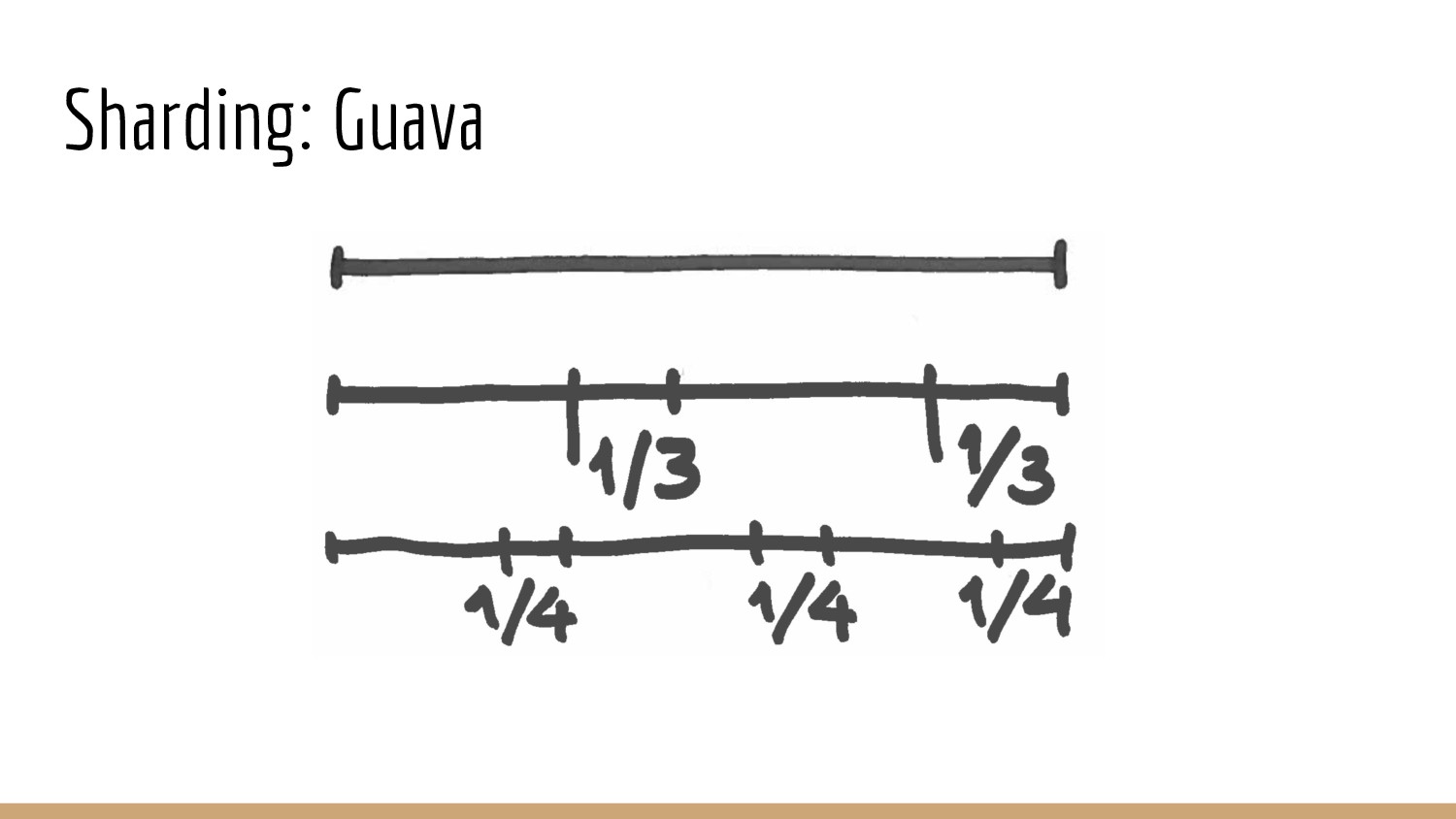{kind=link}
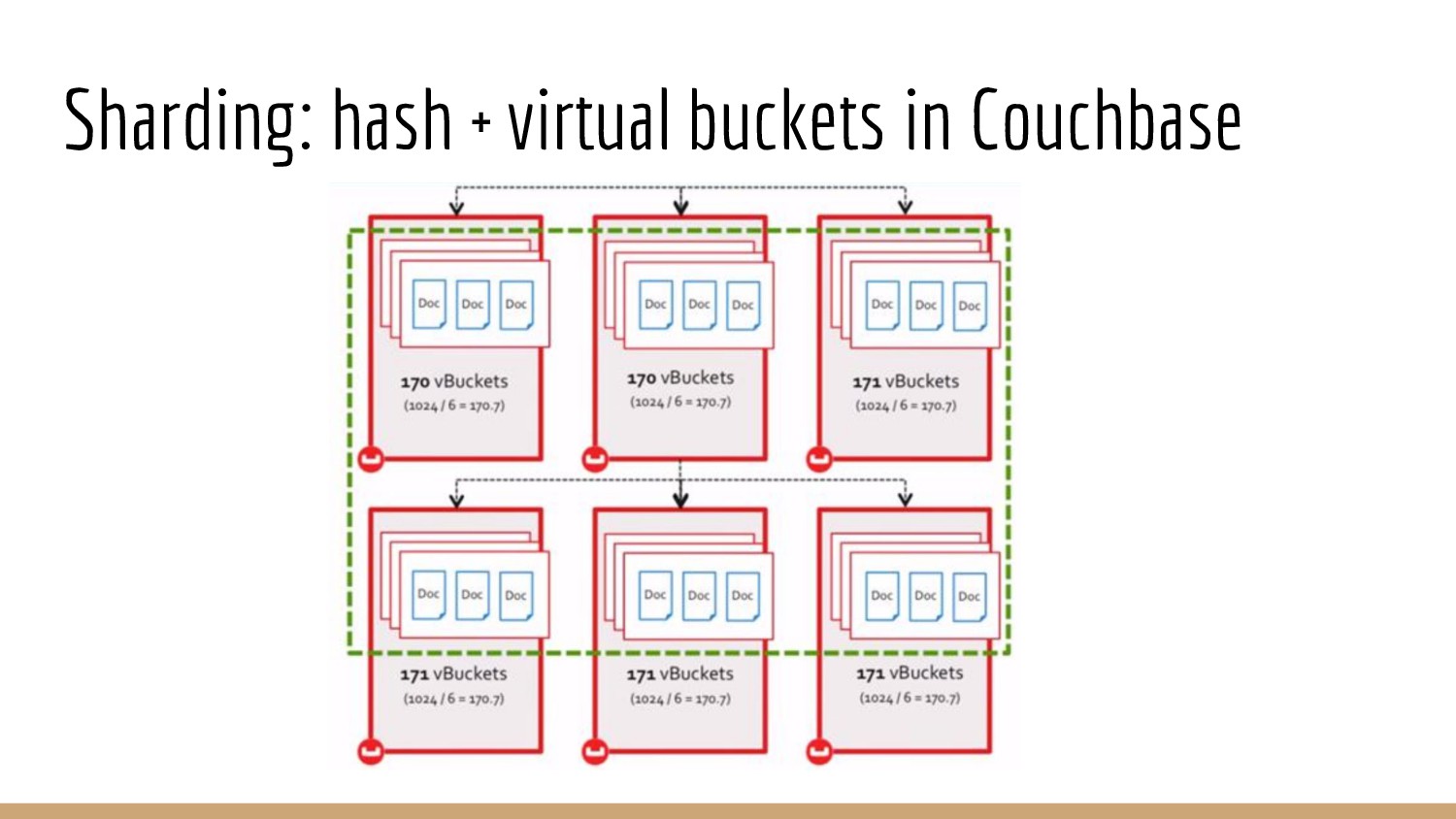{kind=link}
{kind=link}
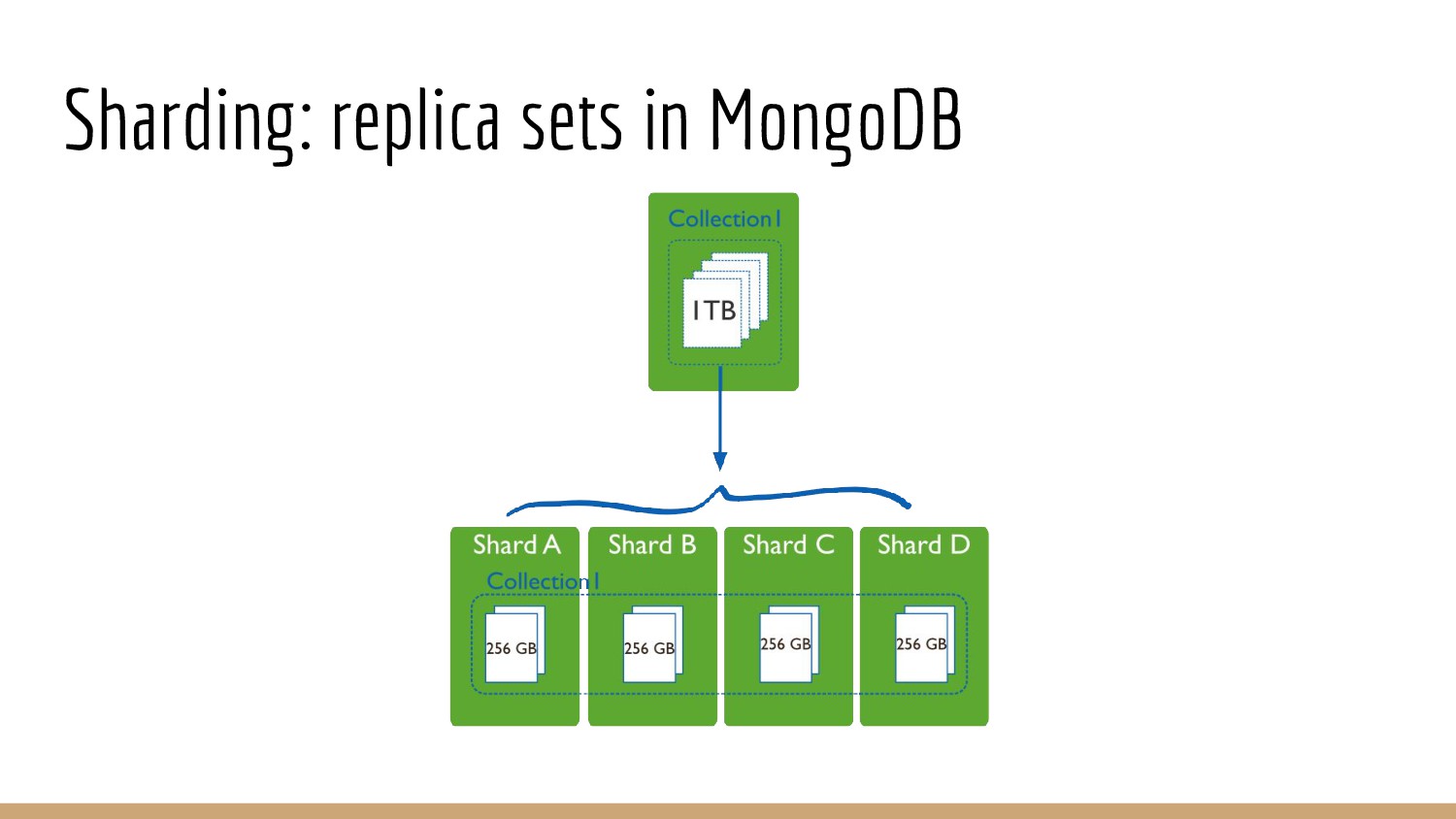{kind=link}
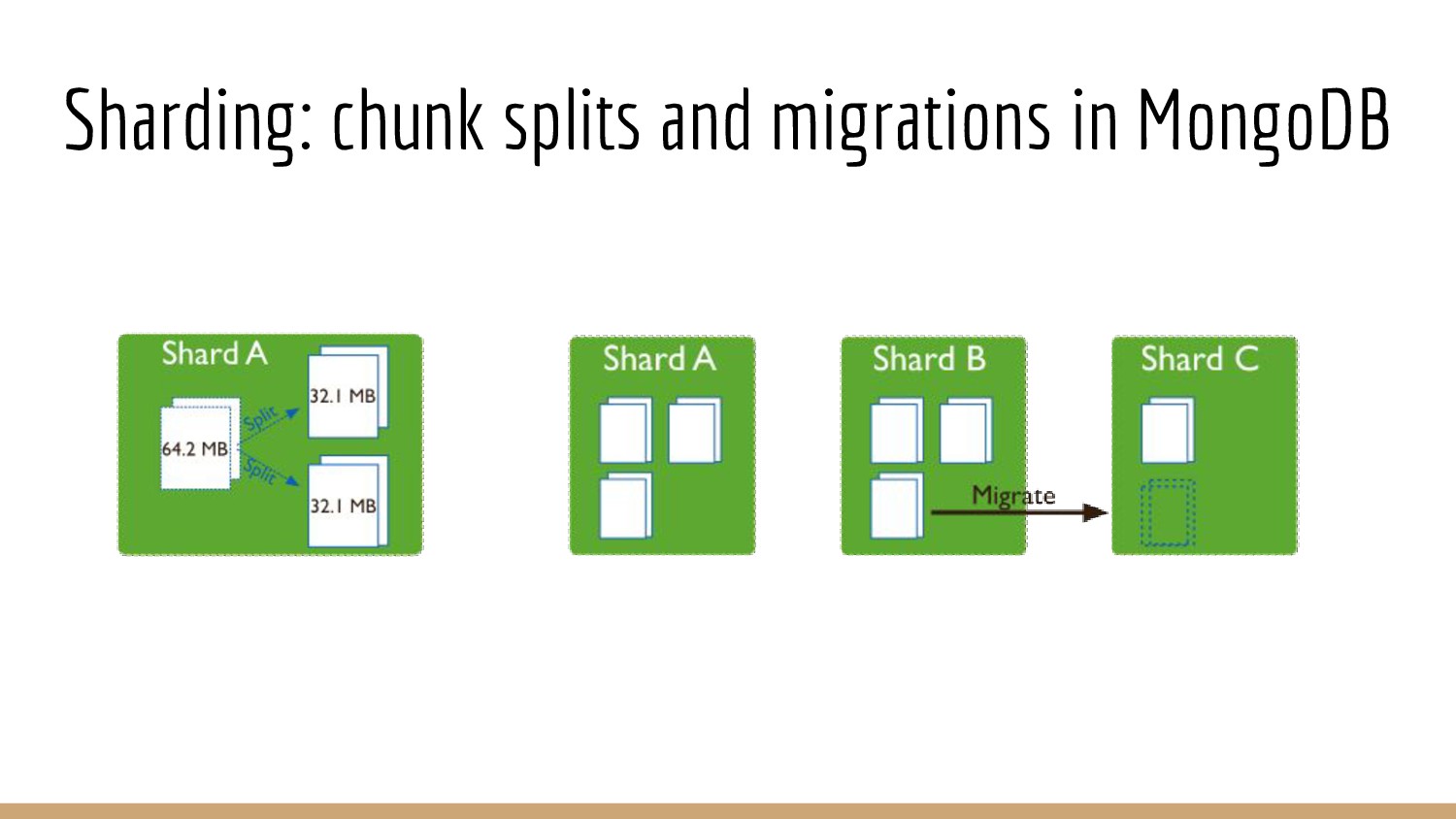{kind=link}
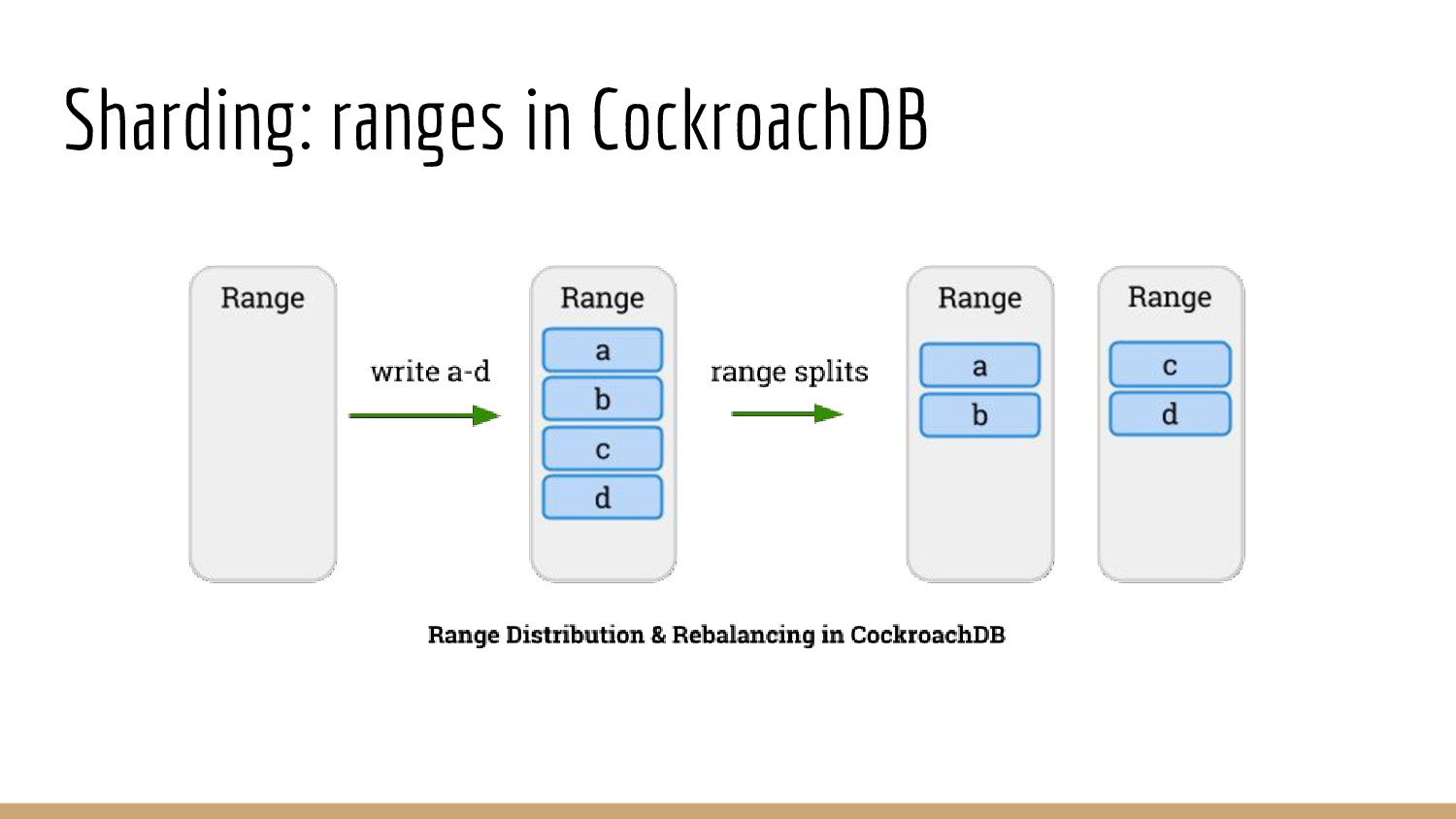{kind=link}
{kind=link}
{kind=link}
{kind=link}
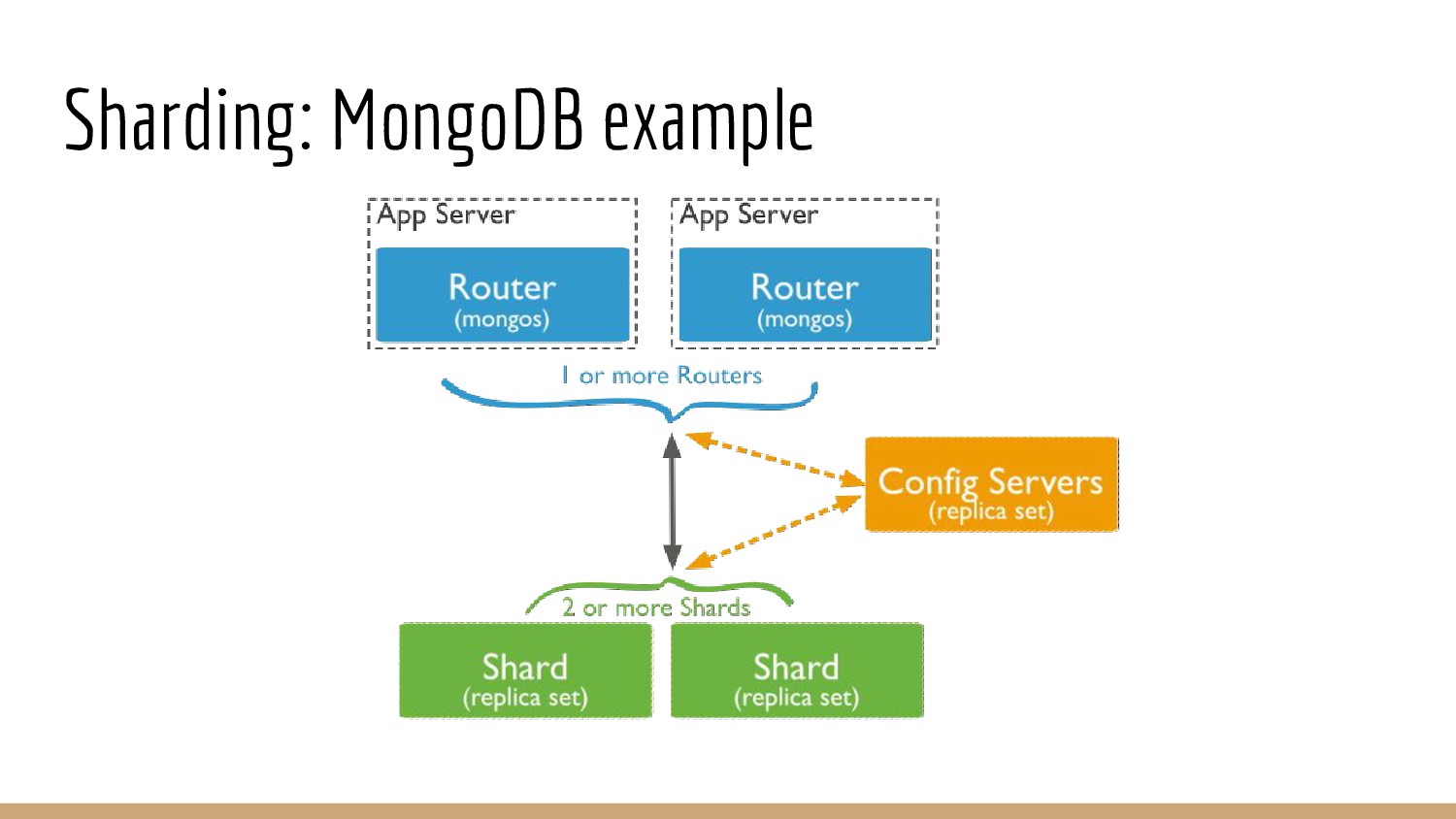{kind=link}
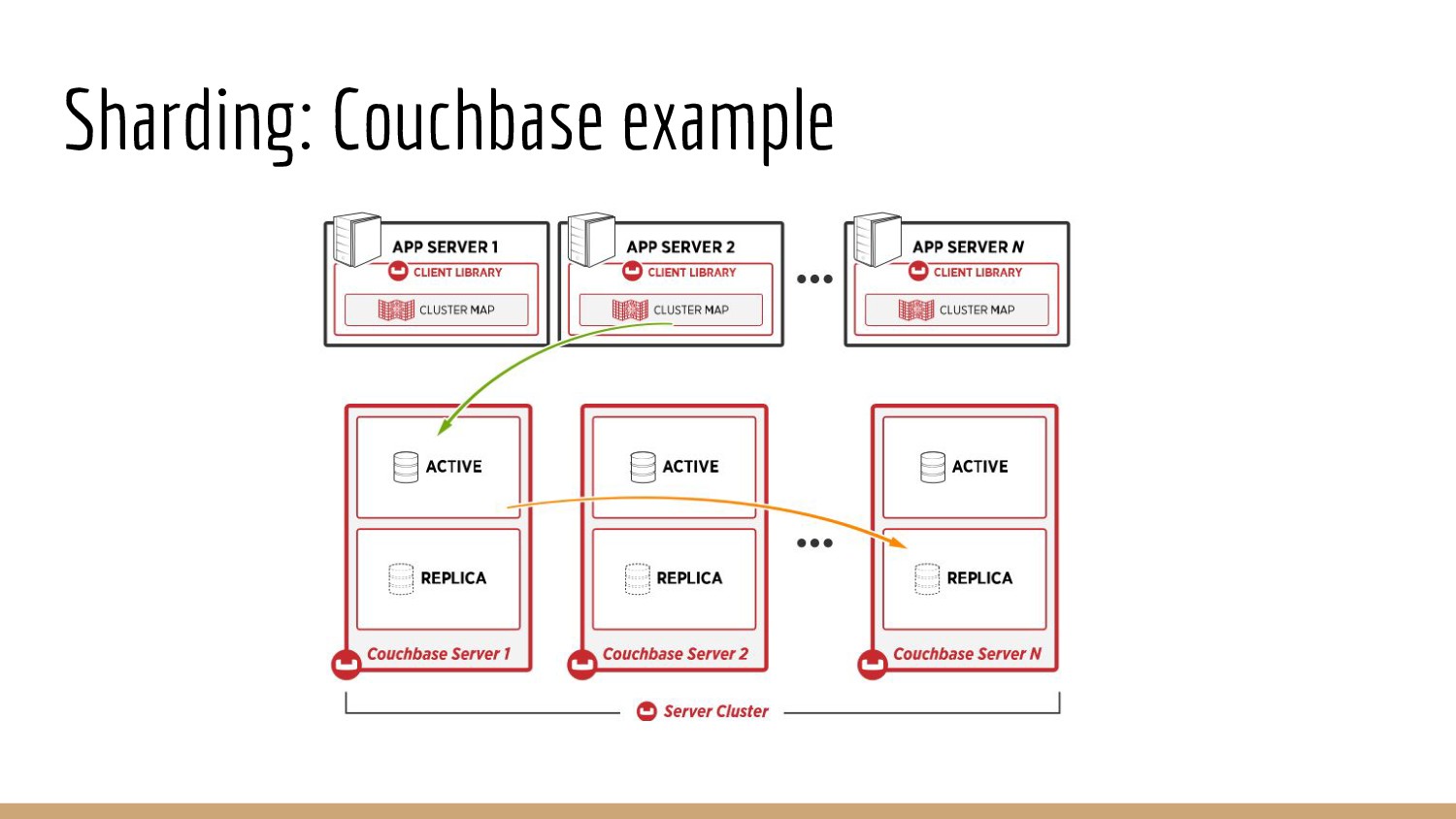{kind=link}
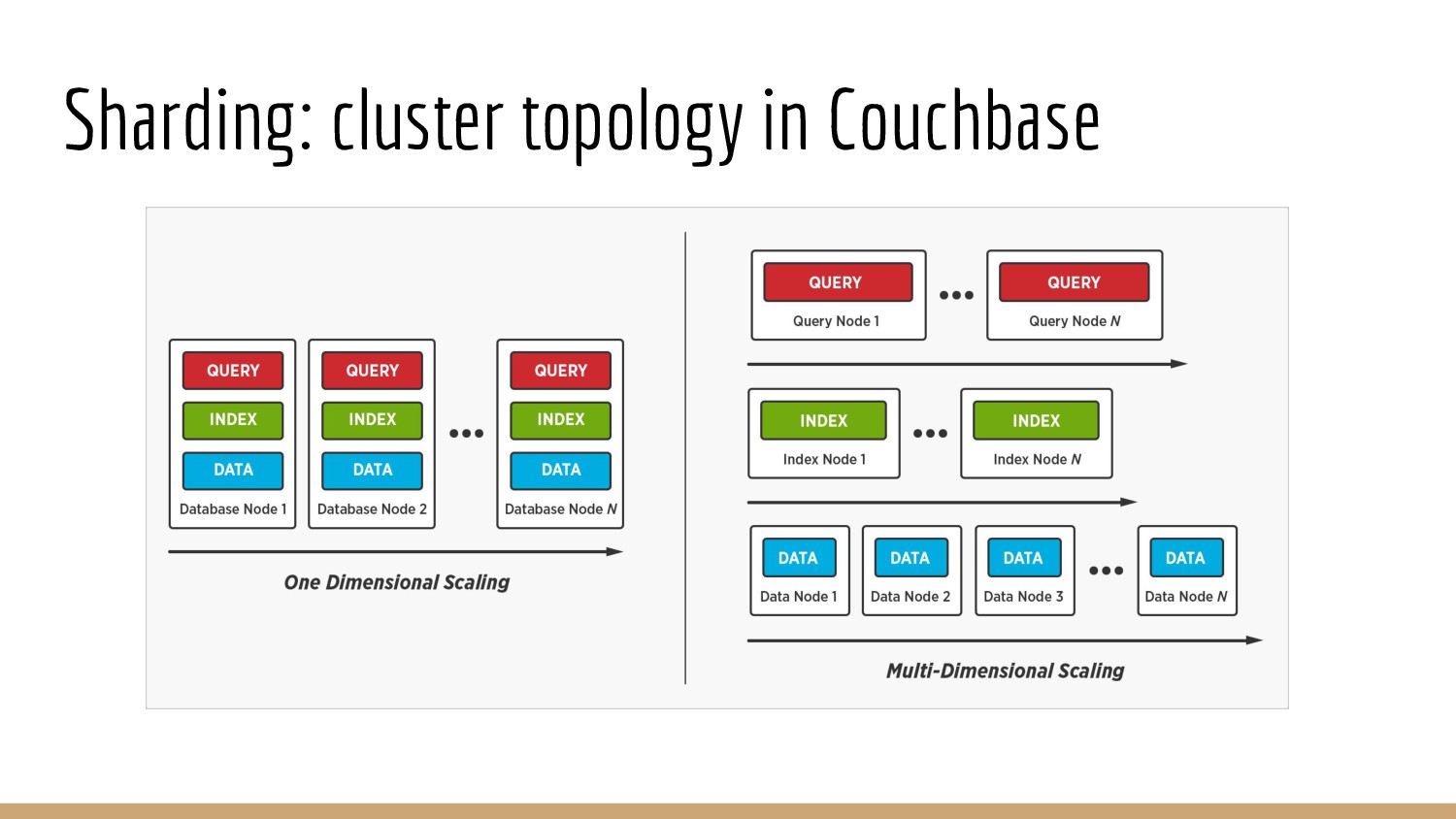{kind=link}
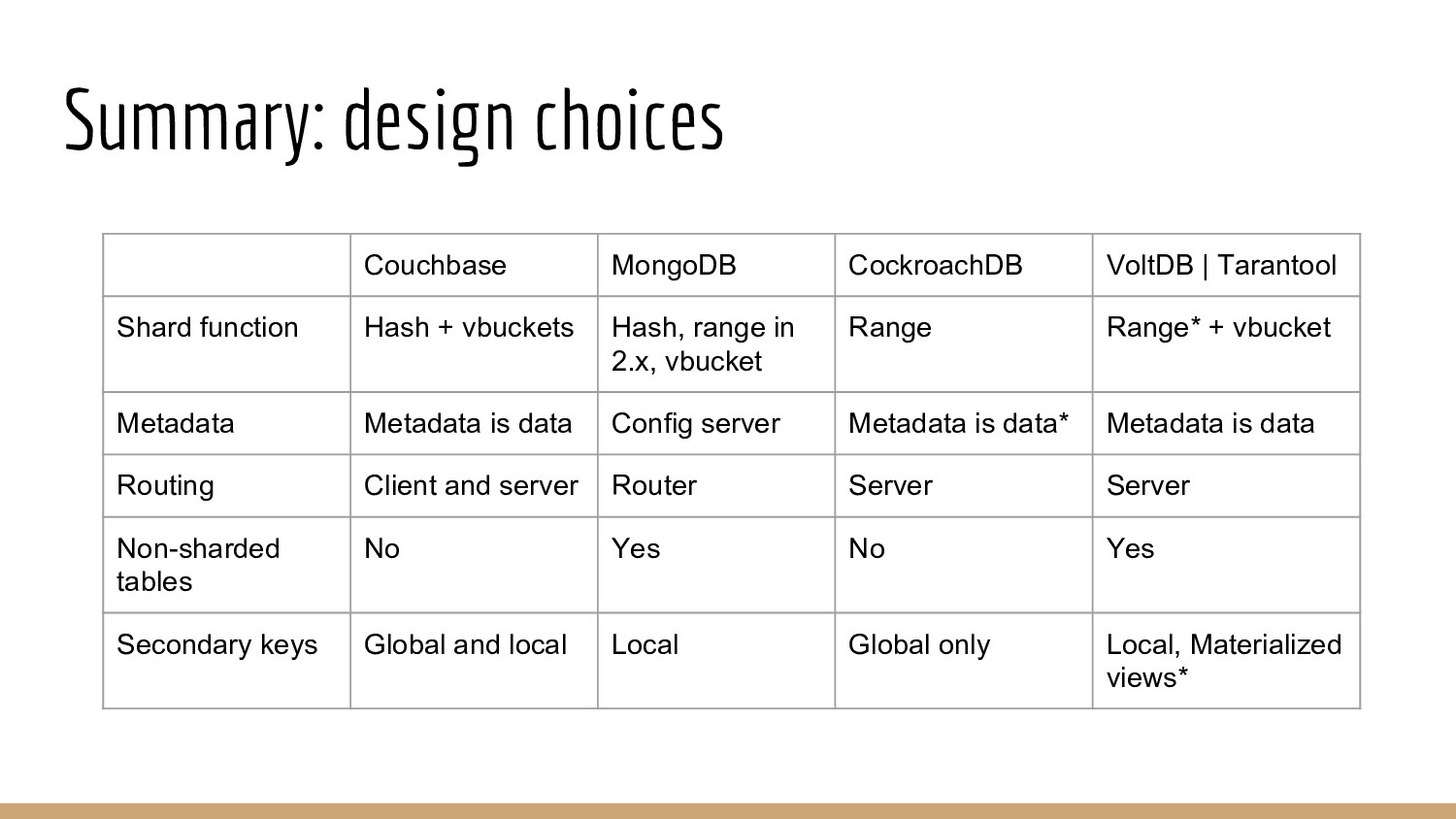{kind=link}
{kind=link}
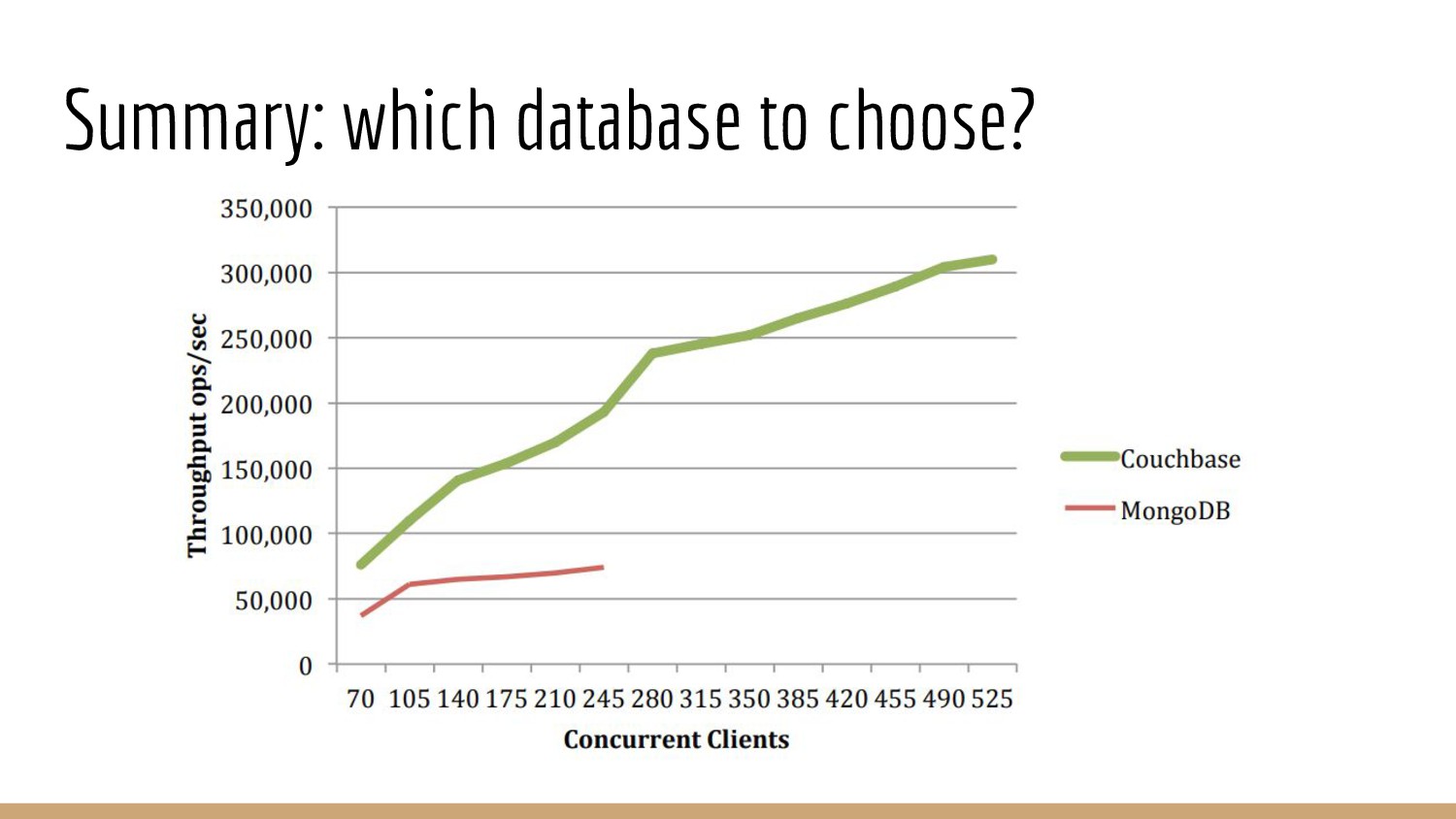{kind=link}
{kind=link}