Сравнение скорости разработки и исполнения программ на языках С++ и python на примере развития проекта статистического анализа сигналов за последние несколько лет.
В докладе расскажу, как статистические вычисления были реконструированы от сложного, большого проекта на C++ со множеством низкоуровневых оптимизаций до простого кода на python, который оказался в 5 раз меньше по размеру и в 10 раз быстрее. Как не стать жертвой роста сложности, успеть распознать проблему вовремя и что делать для улучшения ситуации.
Упоминаются: C++, python, cython, numpy, MKL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
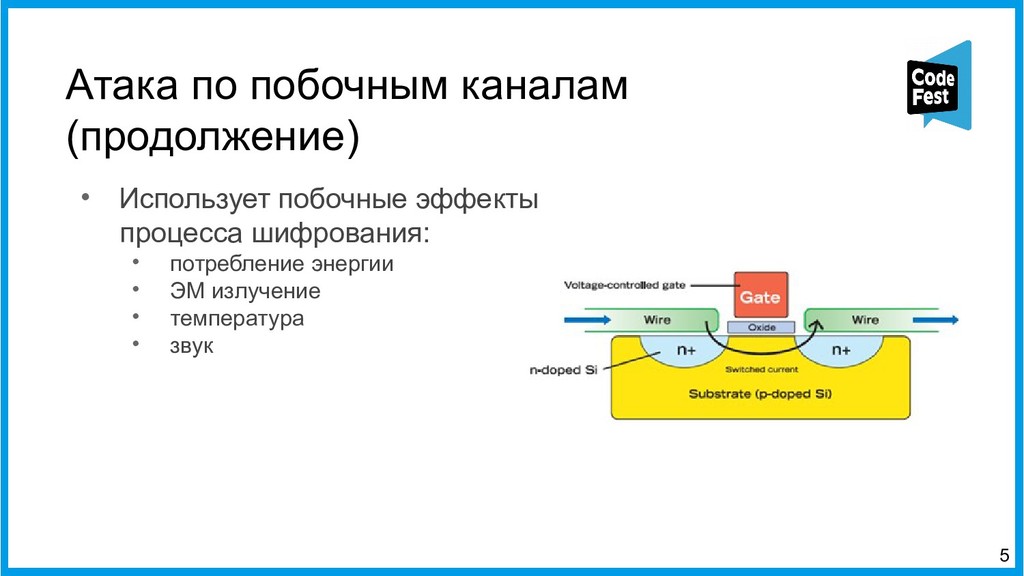{kind=link}
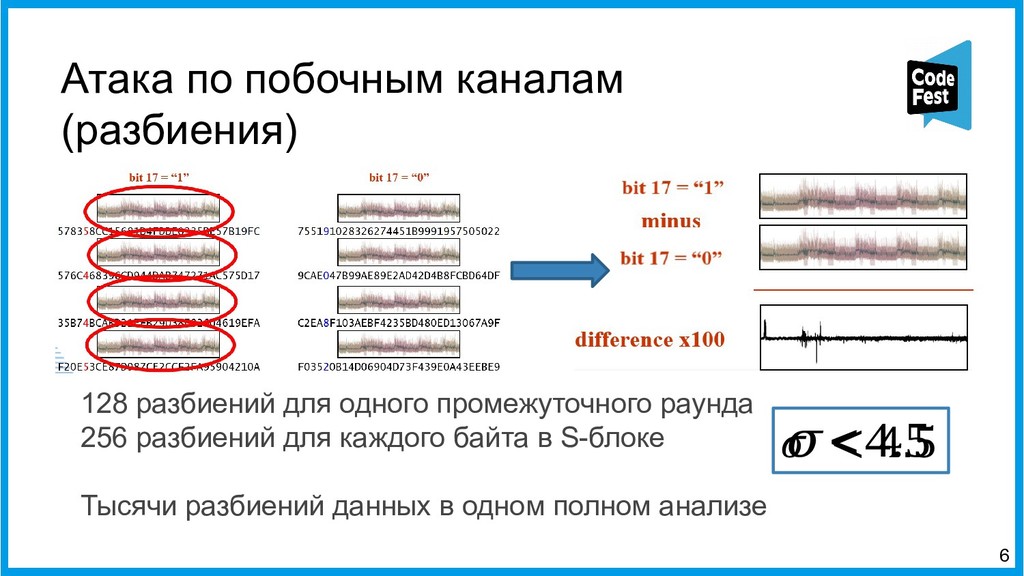{kind=link}
{kind=link}
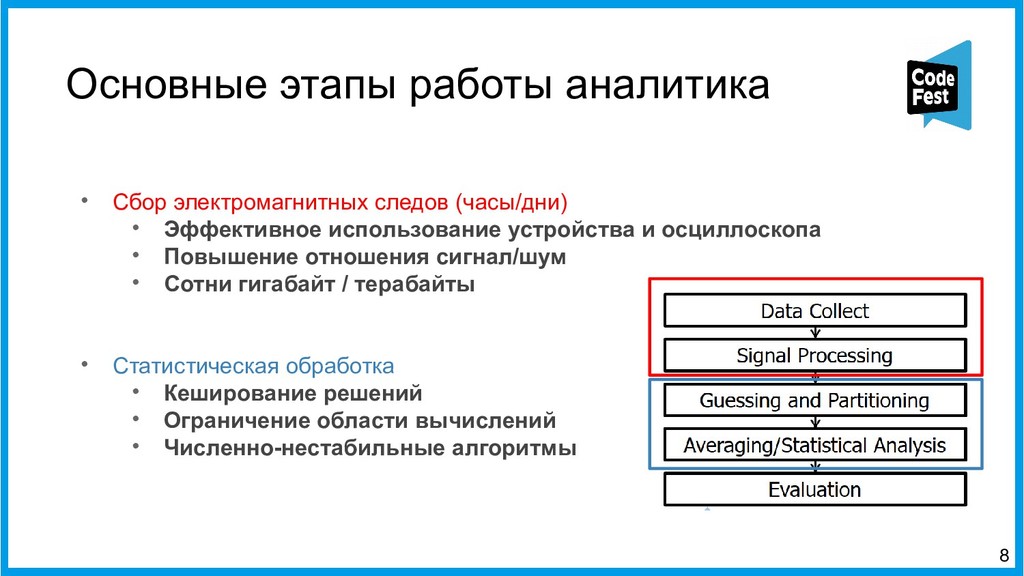{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@akss_nsk Anton Kochepasov Principal Engineer Rambus Вопросы? a.kochepasov [email protected]](https://files.speakerdeck.com/presentations/4425e4d403374eaaad757f469ed781a7/slide_24.jpg){kind=link}