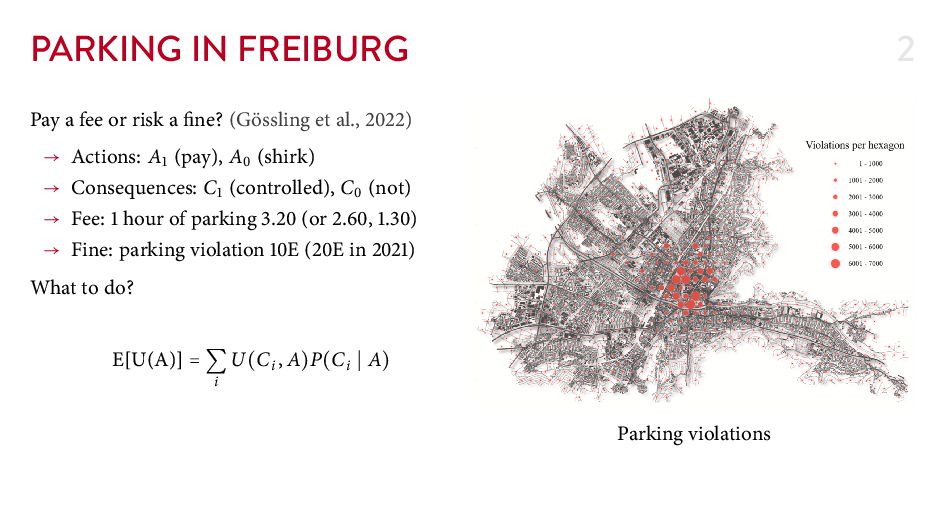
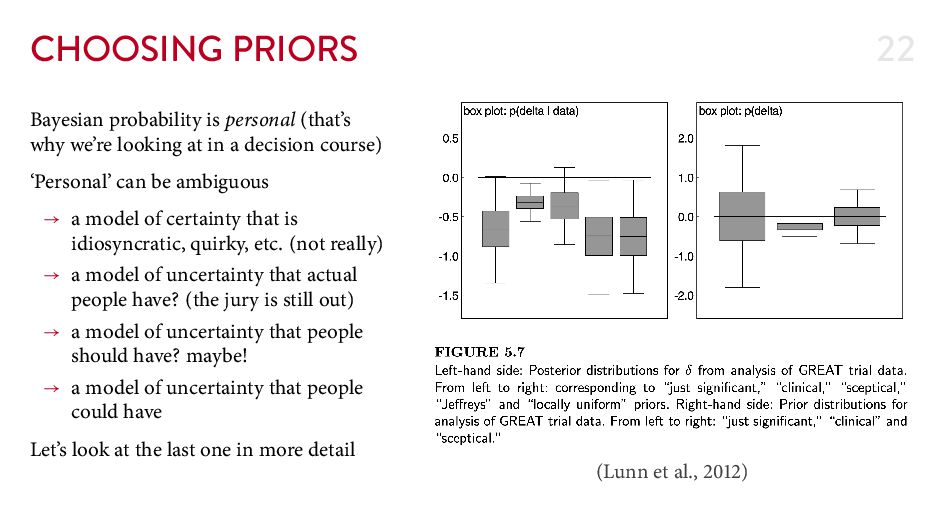
great ideas about chance.” Princeton University Press OCLC: ocn . Gössling, S., Humpe, A., Hologa, R., Riach, N., & Freytag, T. ( ). “Parking violations as an economic gamble for public space.” Transport Policy, , – . Lunn, D., Jackson, C., Best, N., omas, A., & Spiegelhalter, D. ( ). “ e BUGS book: A practical introduction to Bayesian analysis.” CRC Press. Pearl, J., Glymour, M., & Jewell, N. P. ( ). “Causal inference in statistics: A primer.” Wiley.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}