for Geoinformatics, University of Münster | b soon: Hunter College, CUNY http://carsten.io | @carstenkessler Trust as a Proxy Measure for the Quality of VGI in the Case of OSM
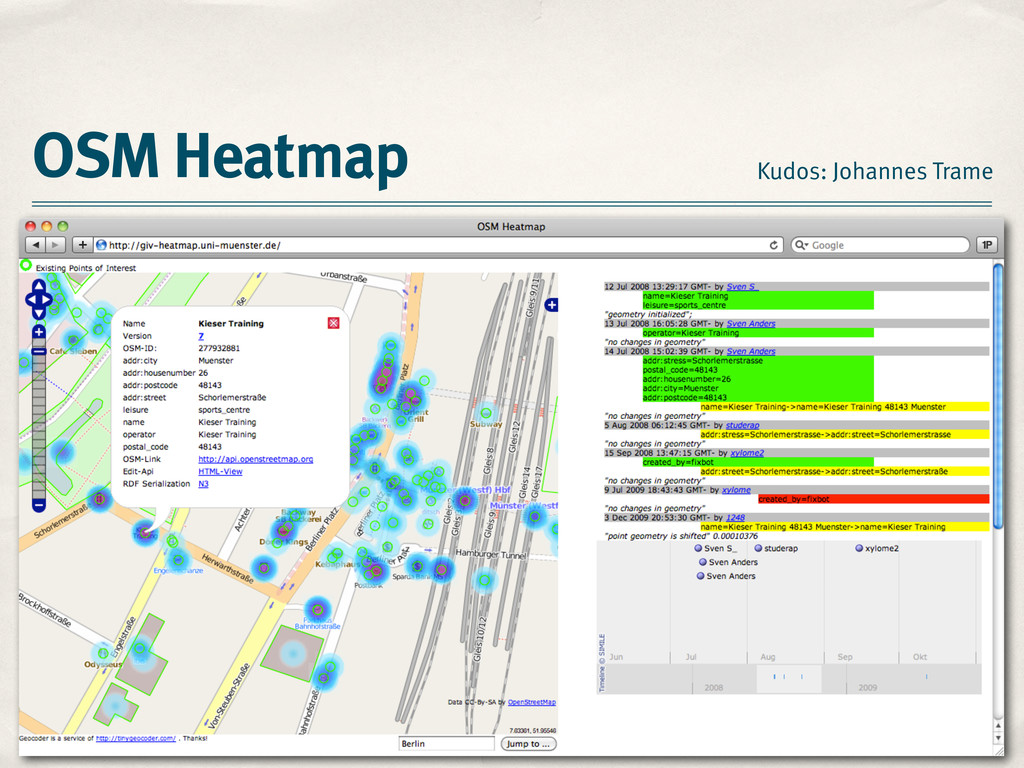
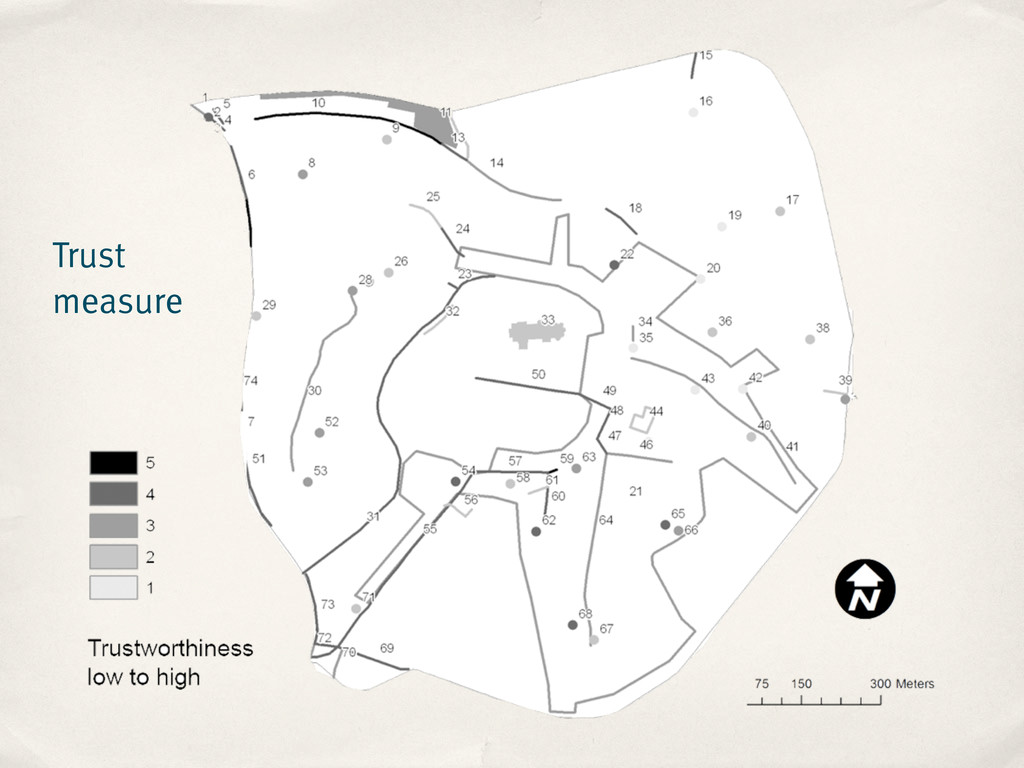
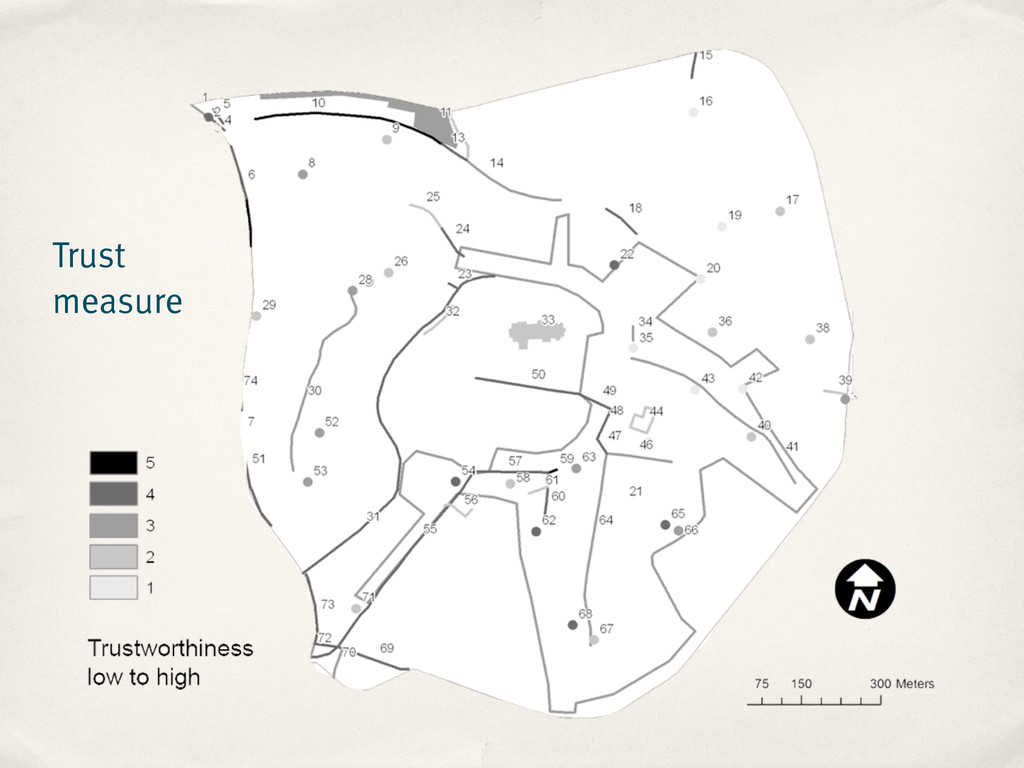
to which a data consumer can trust the quality of a feature ‣ Trust measure is based on a feature’s editing history ‣ Benefits ‣ Works at feature level ‣ Filter features by quality ‣ Spot problematic features
a feature in OpenStreetMap based on its editing history? amenity = university name = Institute for Geoinformatics amenity = university building = yes name = Institute for Geoinformatics v1 v2
a feature in OpenStreetMap based on its editing history? amenity = university name = Institute for Geoinformatics amenity = university building = yes name = Institute for Geoinformatics addr:city = Münster addr:country = DE addr:housenumber = 253 addr:street = Weseler Straße building = yes wheelchair = limited v1 v2 v3 …
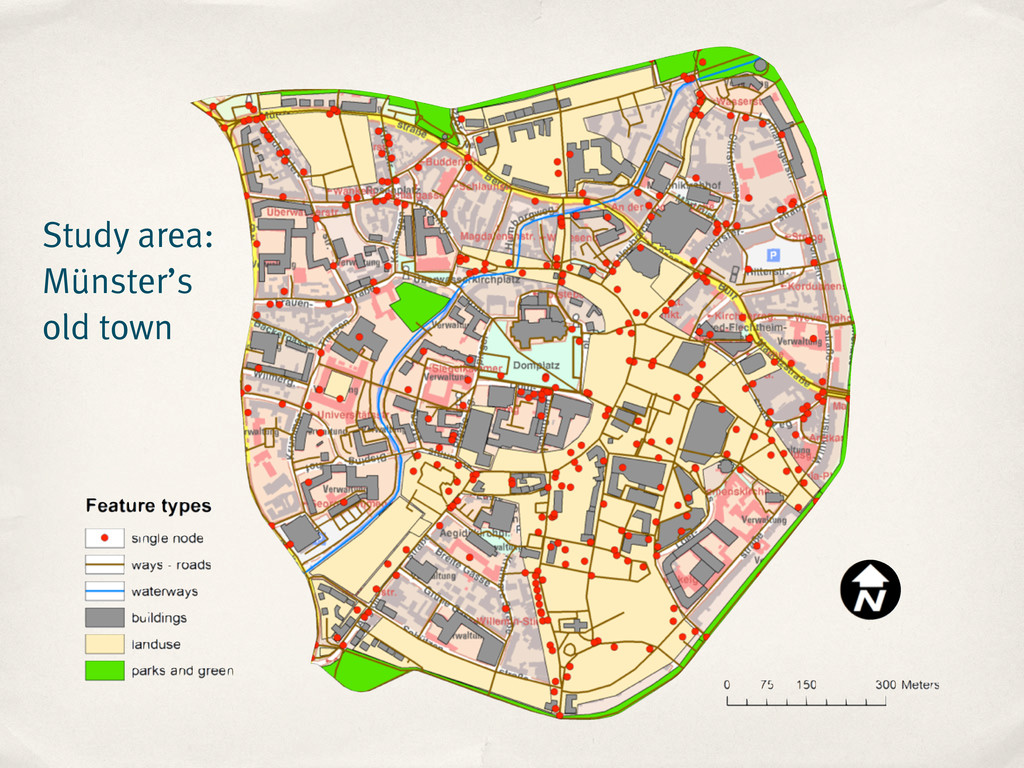
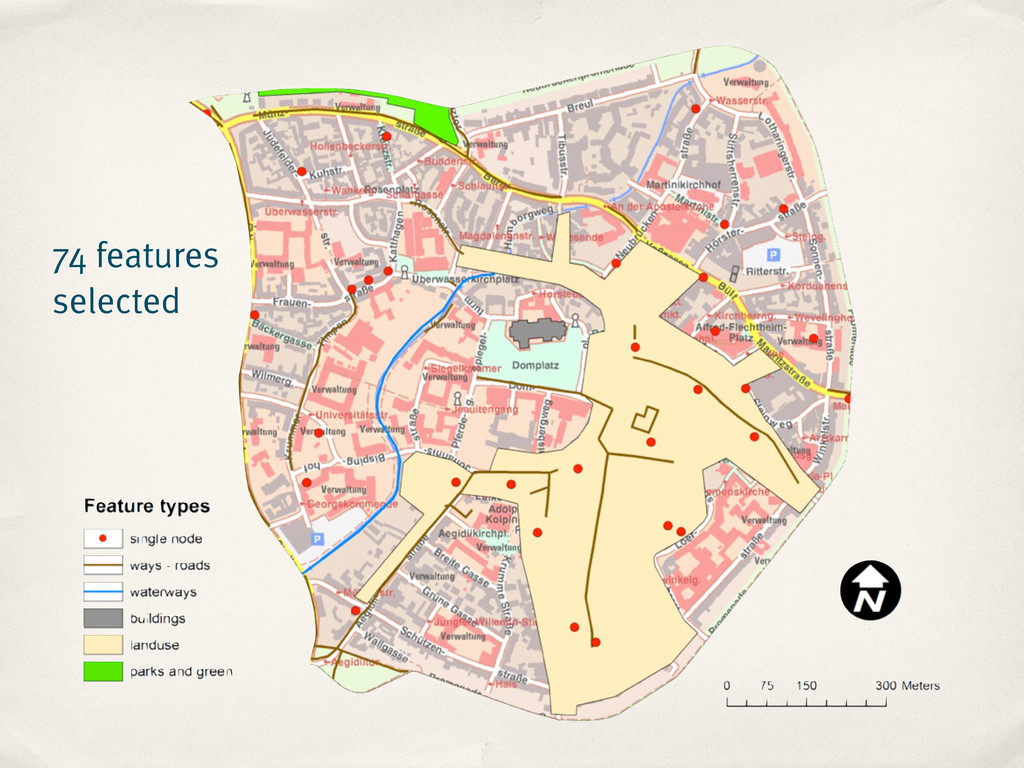
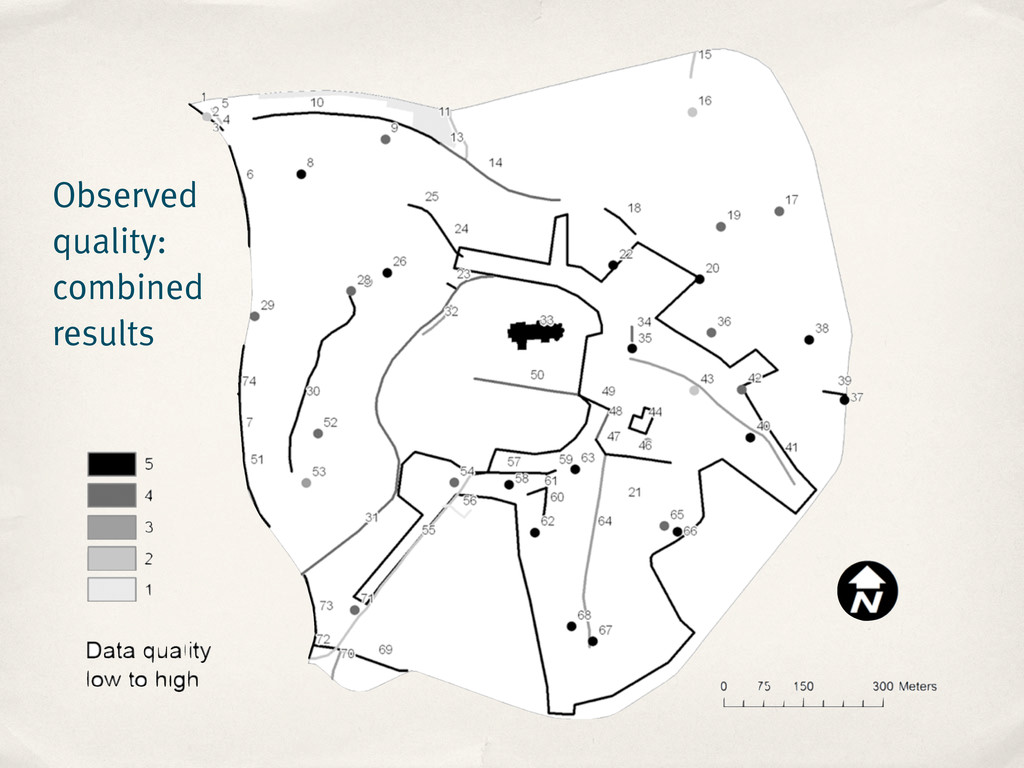
correctly positioned relative to the surrounding features? ‣ Results: ‣ 73 out of 74 features (~99%) ‣ Information completeness ‣ TF-IDF measure to identify relevant tags per main tag
correctly positioned relative to the surrounding features? ‣ Results: ‣ 73 out of 74 features (~99%) ‣ Information completeness ‣ TF-IDF measure to identify relevant tags per main tag ‣ ~37% tags missing (avg.)
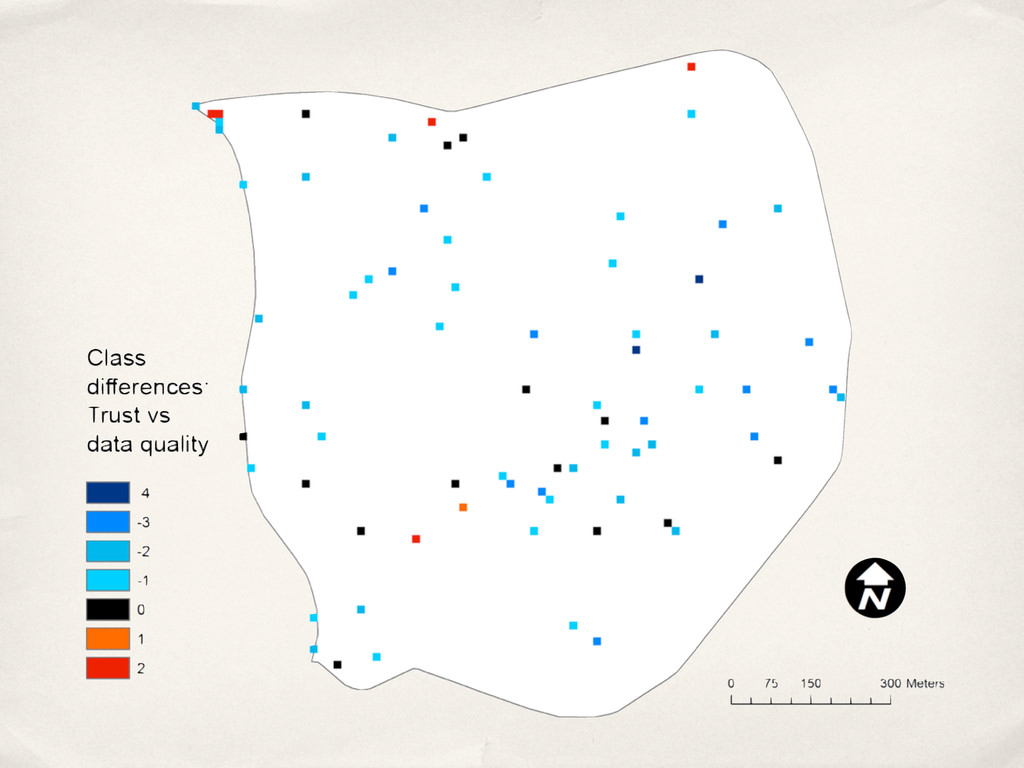
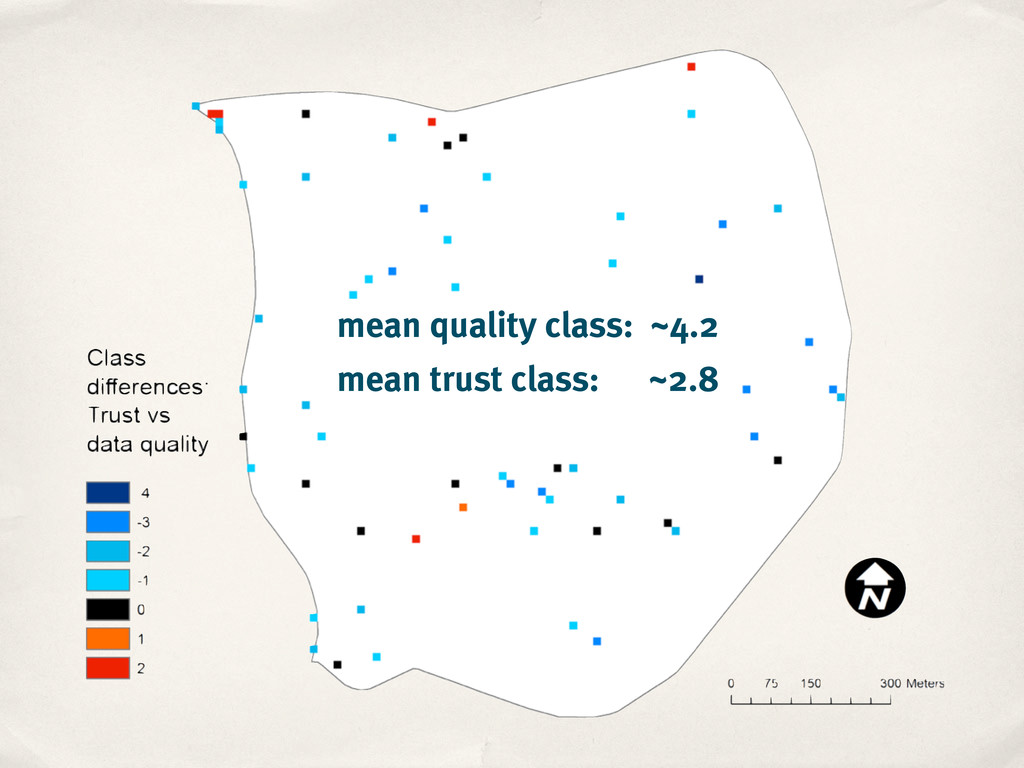
model: Classification, weighting, positive vs negative aspects, … ‣ Social aspects: Who has edited a feature? ‣ Repeat study without spatial focus ‣ How to scale the data collection?
model: Classification, weighting, positive vs negative aspects, … ‣ Social aspects: Who has edited a feature? ‣ Repeat study without spatial focus ‣ How to scale the data collection? ‣ Learn the trust model from the data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}