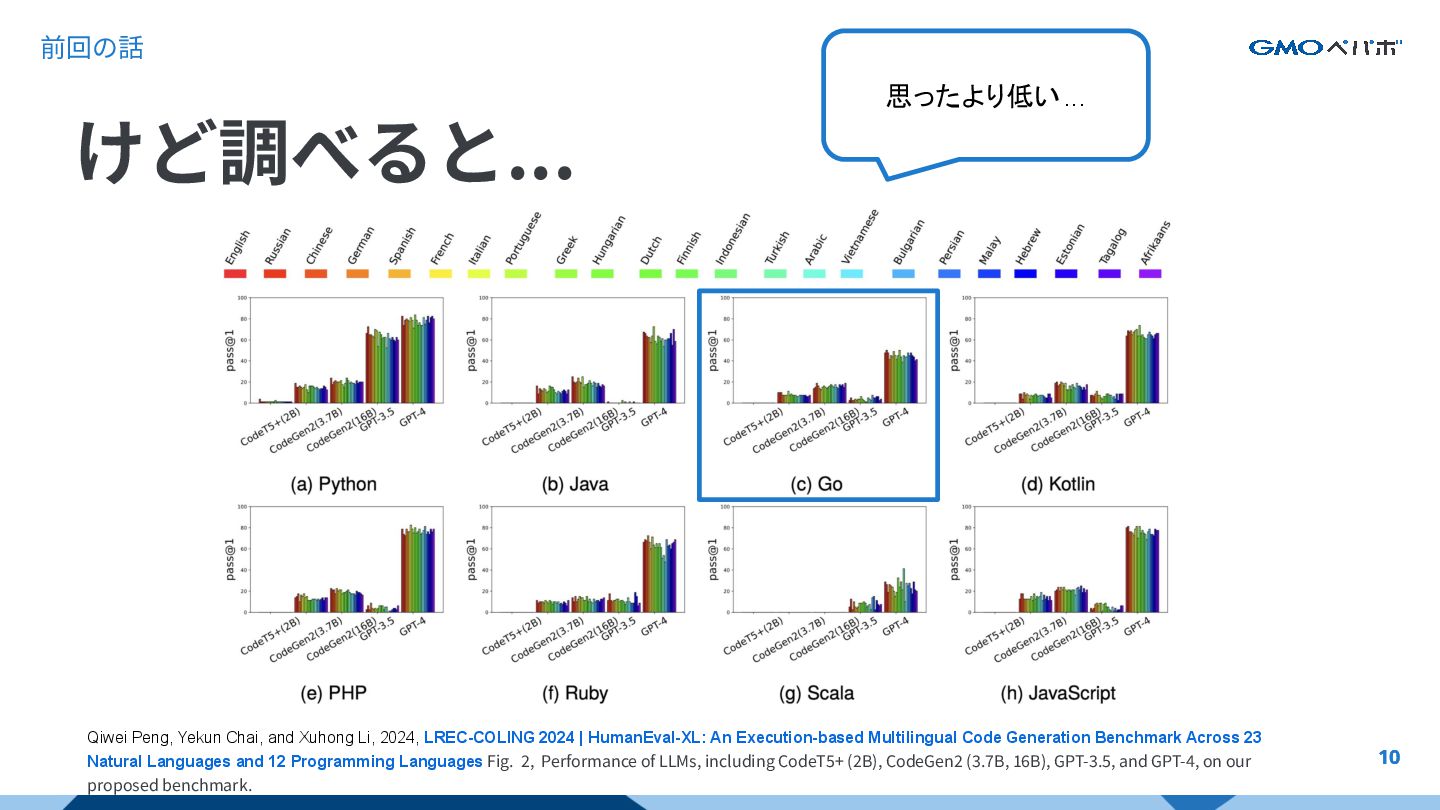
2024, LREC-COLING 2024 | HumanEval-XL: An Execution-based Multilingual Code Generation Benchmark Across 23 Natural Languages and 12 Programming Languages Fig. 2, Performance of LLMs, including CodeT5+ (2B), CodeGen2 (3.7B, 16B), GPT-3.5, and GPT-4, on our proposed benchmark. 思ったより低い... 前回の話
かを評価するもの SWE-bench SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez et al. 2024, https://arxiv.org/abs/2310.06770 https://github.com/SWE-bench/SWE-bench
強み SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez et al. 2024, https://arxiv.org/abs/2310.06770 https://github.com/SWE-bench/SWE-bench
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
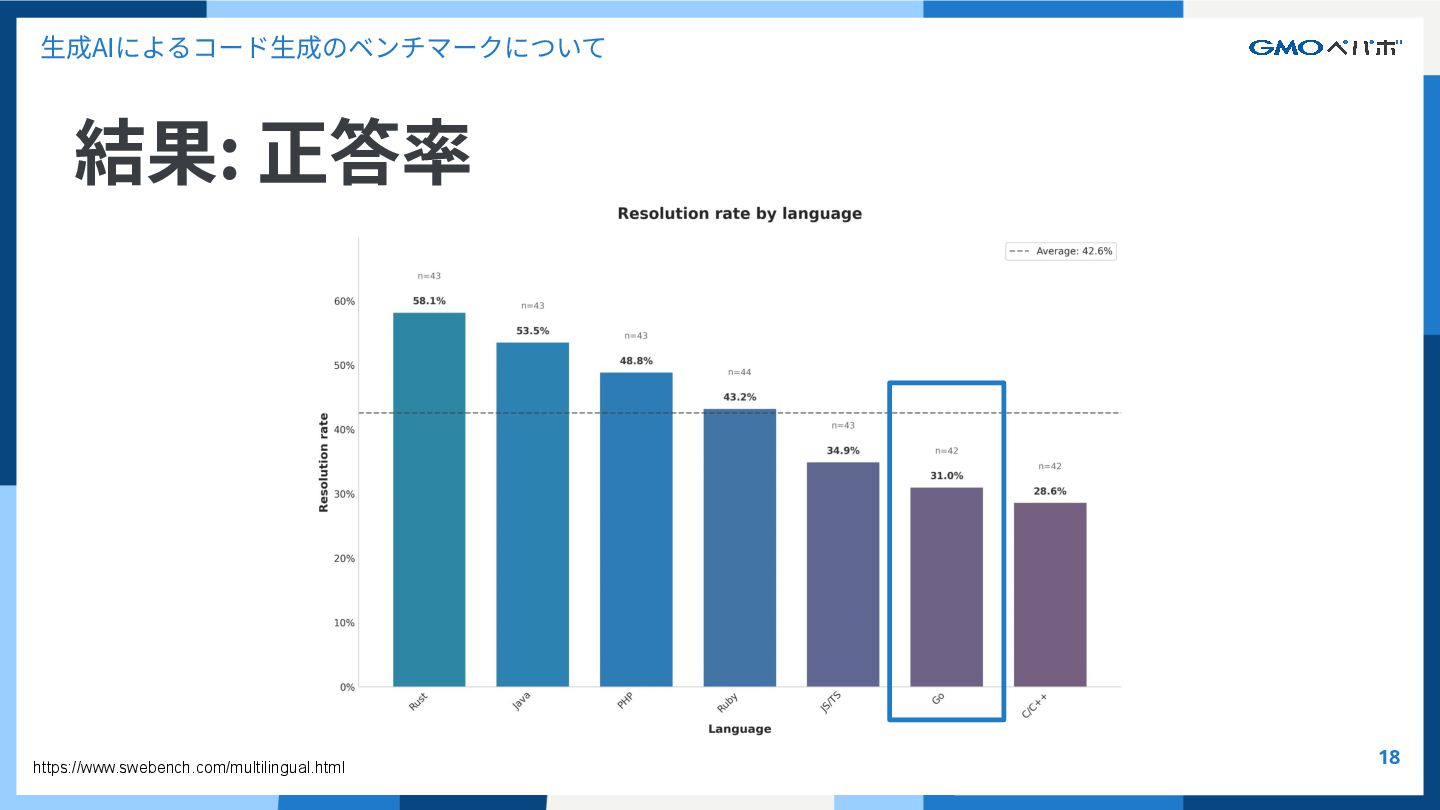{kind=link}
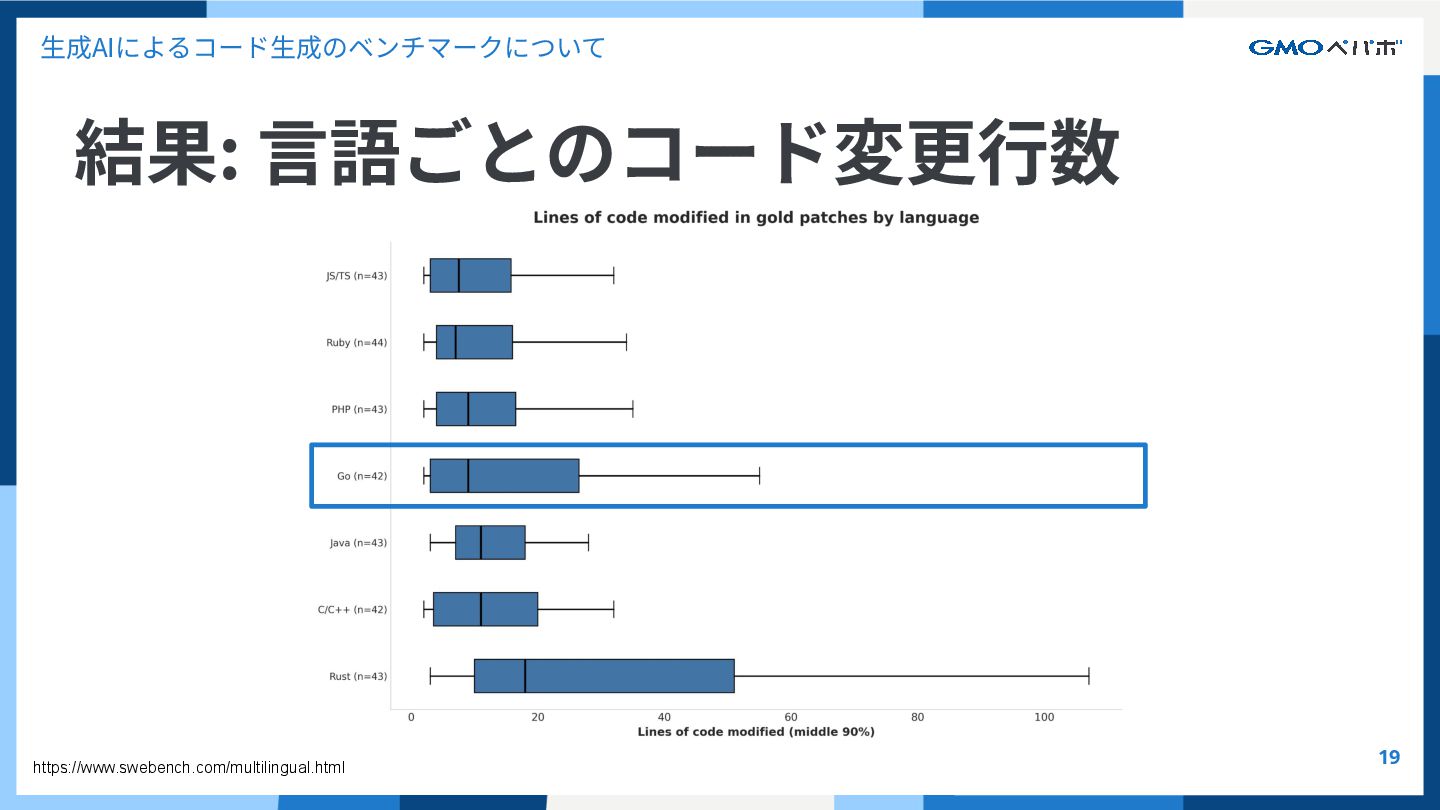{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
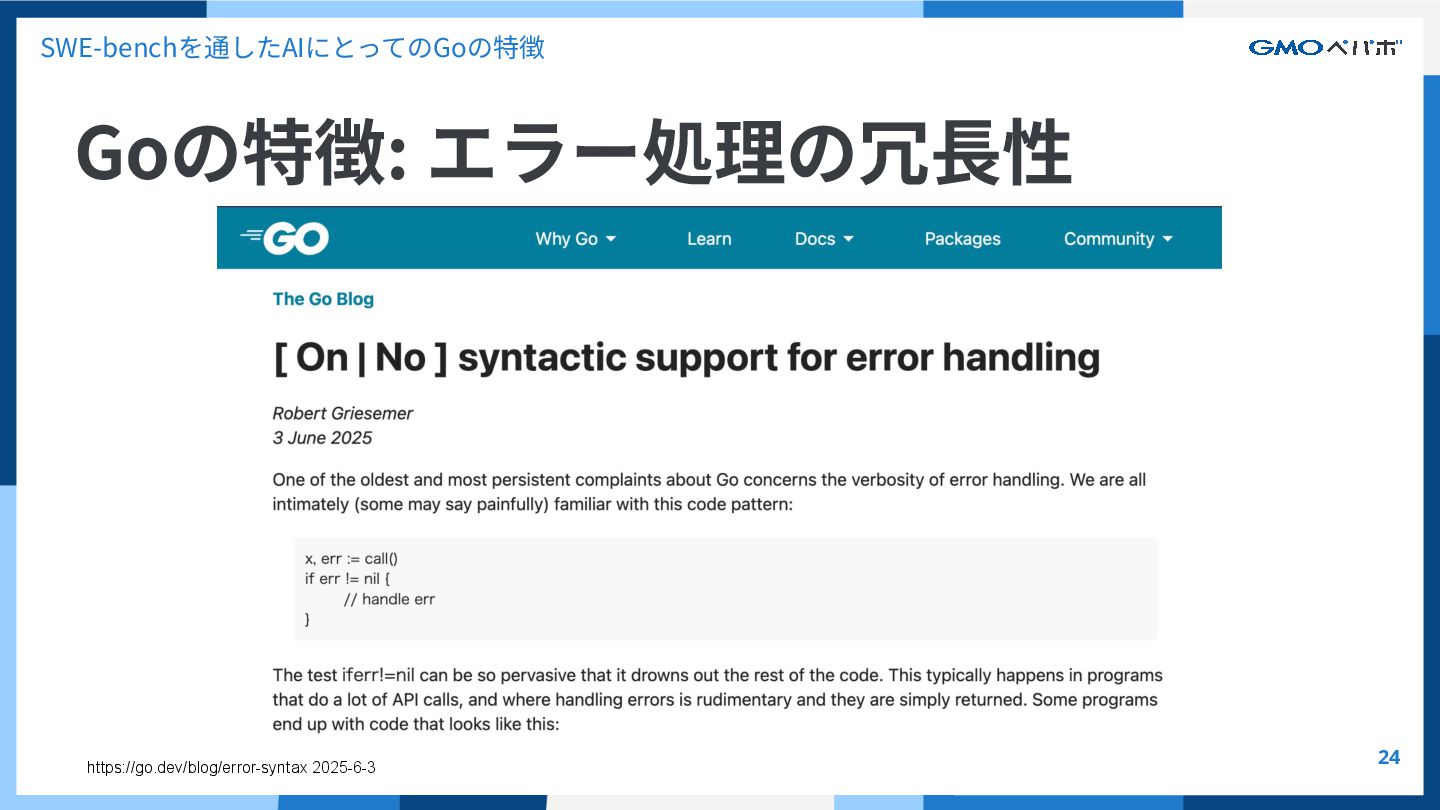{kind=link}
{kind=link}
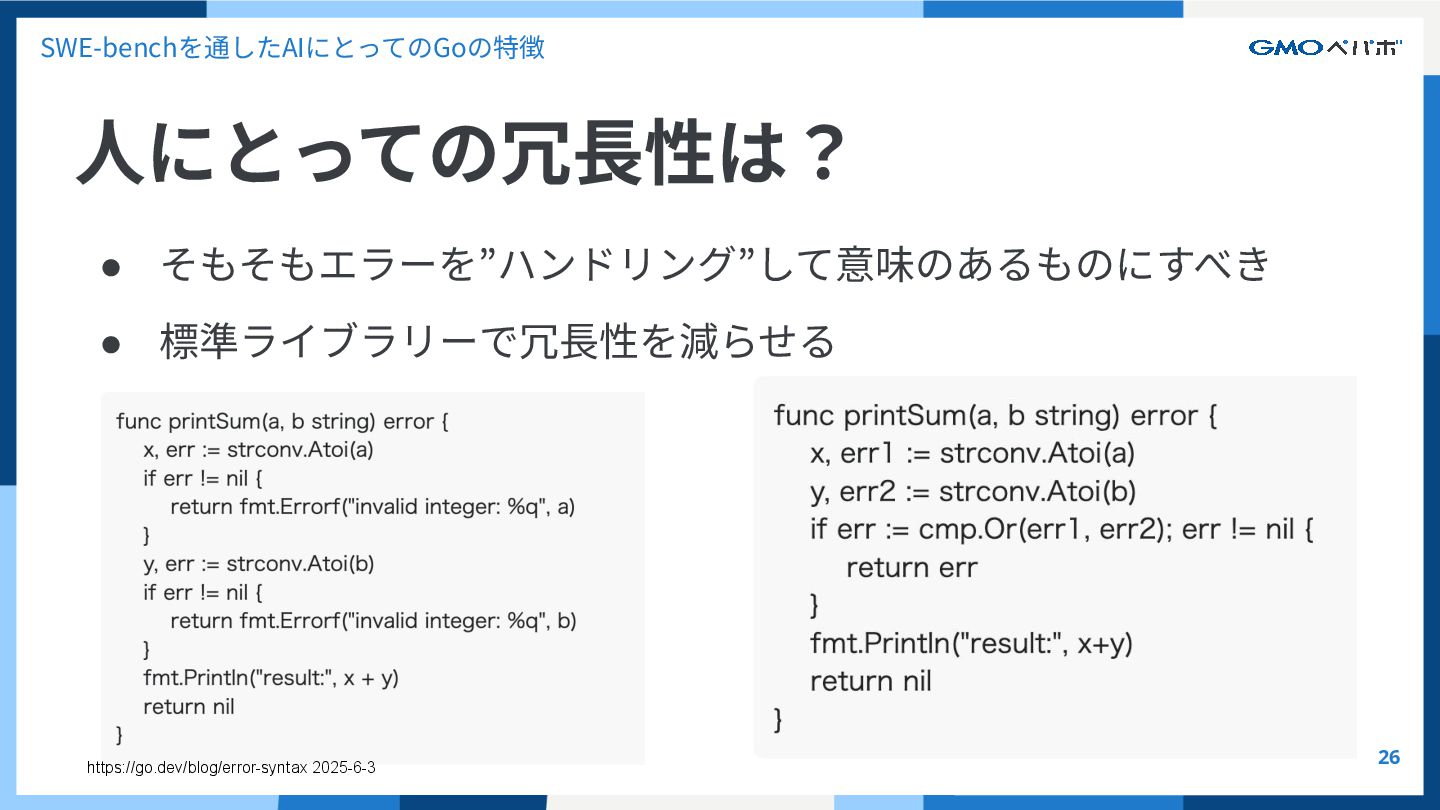{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}