• Basically a reverse mapping between the stemmed form of a term to a collection of documents containing the term ...“search”: [3, 104, 238],... Tuesday, December 28, 2010
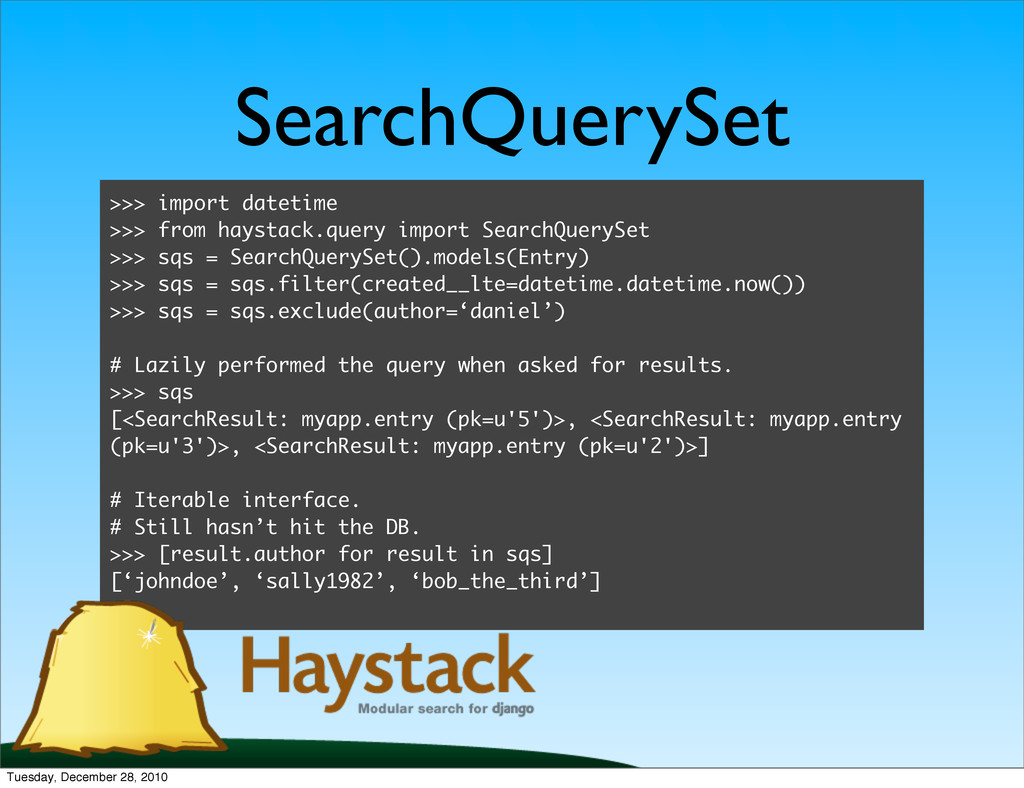
sqs = SearchQuerySet().models(Entry) >>> sqs = sqs.filter(created__lte=datetime.datetime.now()) >>> sqs = sqs.exclude(author=‘daniel’) # Lazily performed the query when asked for results. >>> sqs [<SearchResult: myapp.entry (pk=u'5')>, <SearchResult: myapp.entry (pk=u'3')>, <SearchResult: myapp.entry (pk=u'2')>] # Iterable interface. # Still hasn’t hit the DB. >>> [result.author for result in sqs] [‘johndoe’, ‘sally1982’, ‘bob_the_third’] Tuesday, December 28, 2010
for result in sqs] [‘John’, ‘Sally’, ‘Bob’] # More efficient loading from database (one query total). >>> [result.object.user.first_name for result in sqs.load_all()] [‘John’, ‘Sally’, ‘Bob’] Tuesday, December 28, 2010
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}