Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIコードエディタの基盤となるLLMのFlutter性能評価
Search
alquist
April 01, 2025
Programming
0
340
AIコードエディタの基盤となるLLMのFlutter性能評価
alquist
April 01, 2025
Tweet
Share
Other Decks in Programming
See All in Programming
dynamic!
moro
10
7.2k
スマホから Youtube Shortsを見られないようにする
lemolatoon
24
27k
Swift Concurrency - 状態監視の罠
objectiveaudio
2
510
Django Ninja による API 開発効率化とリプレースの実践
kashewnuts
0
1.2k
なぜGoのジェネリクスはこの形なのか? Featherweight Goが明かす設計の核心
ryotaros
7
1.1k
高度なUI/UXこそHotwireで作ろう Kaigi on Rails 2025
naofumi
4
3.8k
uniqueパッケージの内部実装を支えるweak pointerの話
magavel
0
970
(Extension DC 2025) Actor境界を越える技術
teamhimeh
1
250
いま中途半端なSwift 6対応をするより、Default ActorやApproachable Concurrencyを有効にしてからでいいんじゃない?
yimajo
2
400
Web Components で実現する Hotwire とフロントエンドフレームワークの橋渡し / Bridging with Web Components
da1chi
3
2k
詳しくない分野でのVibe Codingで困ったことと学び/vibe-coding-in-unfamiliar-area
shibayu36
3
4.8k
Conquering Massive Traffic Spikes in Ruby Applications with Pitchfork
riseshia
0
160
Featured
See All Featured
Context Engineering - Making Every Token Count
addyosmani
5
220
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
53k
The Straight Up "How To Draw Better" Workshop
denniskardys
237
140k
The Cost Of JavaScript in 2023
addyosmani
53
9k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
189
55k
Keith and Marios Guide to Fast Websites
keithpitt
411
23k
Mobile First: as difficult as doing things right
swwweet
224
10k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
9
590
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
46
7.7k
Documentation Writing (for coders)
carmenintech
75
5k
Large-scale JavaScript Application Architecture
addyosmani
514
110k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
32
2.3k
Transcript
AIコードエディタの基盤となる LLMのFlutter性能評価 関澤 瞭 2025/03/21
なぜFlutterの勉強会でLLM評価の話? 個人的にLLMそのもののDart/Flutter性能を上げていきたいから そのために… - 非アカデミア側でデータセット作成を進める必要がある - LLM研究者はFlutter単体には関心を持ちづらい(というか無い) - 自分が作りたいがFlutter歴が浅いので、色々な経験者から意見を募りたい
なぜFlutterの勉強会でLLM評価の話? モデルの評価プロセスを理解すると、より効果的な改善が可能になるから - アプリ開発者が個人でLLMのチューニングを行う時代 - 職種関係なく、R&DやML/DS職以外にも身近なものに - 個人がAIコードエディタを使い倒す上で、引き出しが増えるはず
「LLMを評価する」 とは
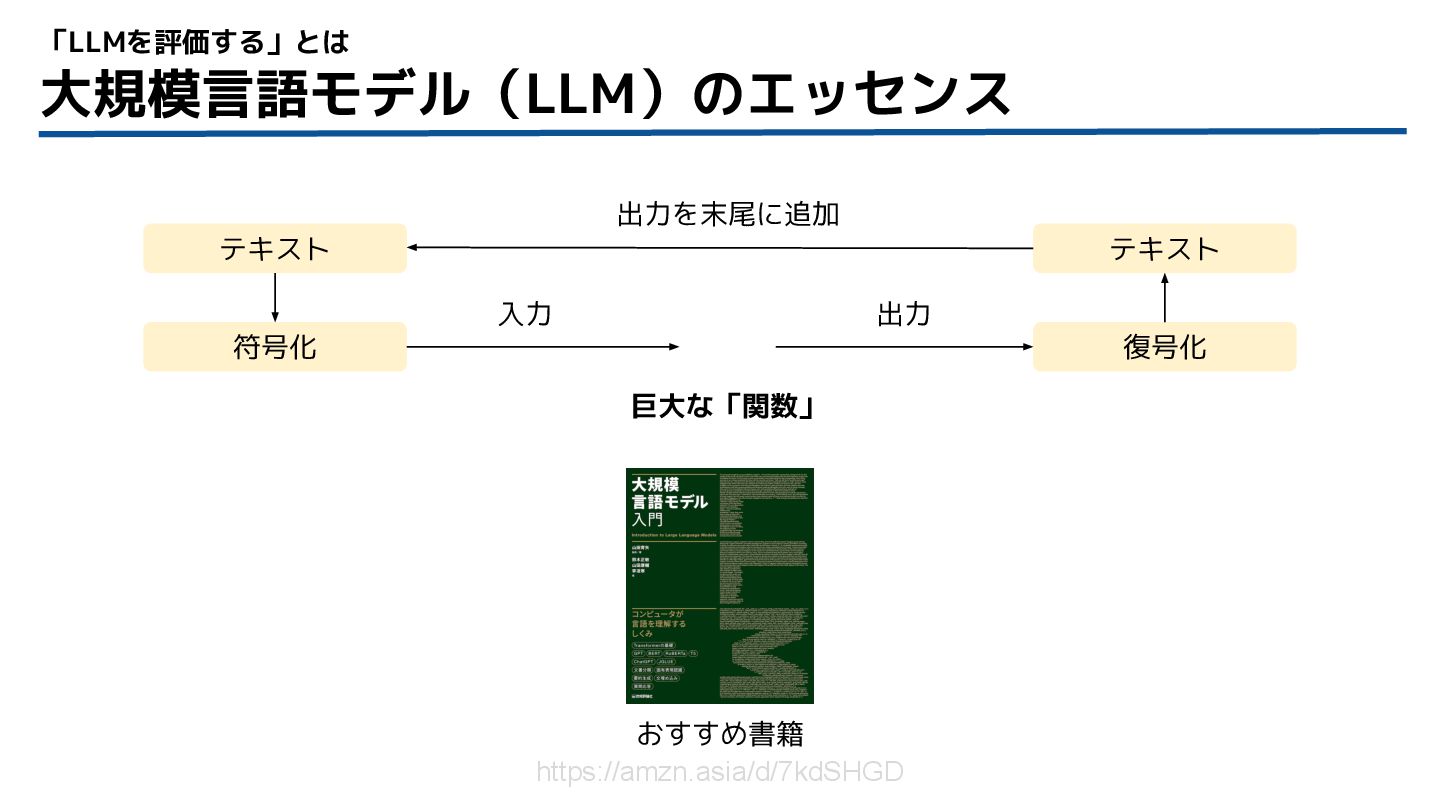
大規模言語モデル(LLM)のエッセンス 「LLMを評価する」とは おすすめ書籍 https://amzn.asia/d/7kdSHGD テキスト 符号化 テキスト 復号化 入力 出力
出力を末尾に追加 巨大な「関数」
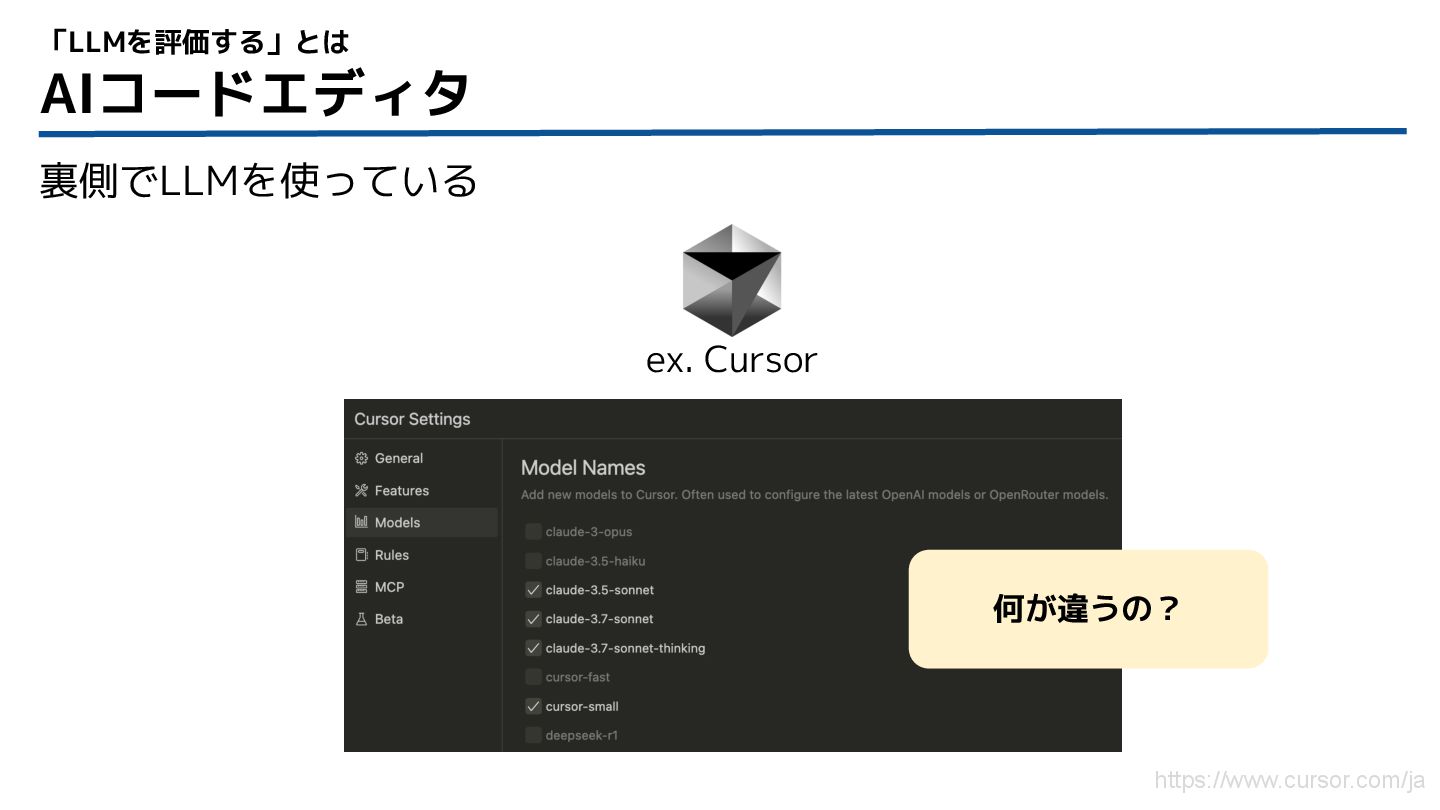
AIコードエディタ 裏側でLLMを使っている 「LLMを評価する」とは https://www.cursor.com/ja 何が違うの? ex. Cursor
性能評価の重要性 利用者目線 - 特定の用途で性能がいいモデルがあるのであれば、それを使いたい - モデルを導入する際に誰かに説明するためのデータ・資料が欲しい LLM開発者目線 - 作成したモデルが本当に使えるのか明らかにする -
作成したモデルが現状出来ないことは何なのか明らかにする 「LLMを評価する」とは https://speakerdeck.com/chokkan/jsai2024-tutorial-llm?slide=64
評価プロセスの大枠 「LLMを評価する」とは タスクを定義する 評価指標を定める データセットを作成する モデルの出力を分析する
評価プロセスの大枠 「LLMを評価する」とは タスクを定義する 評価指標を定める データセットを作成する モデルの出力を分析する
タスクを定義する ≒ 入出力を定義する 「LLMを評価する」とは 修正 実装 説明 検出 入力:実装の詳細 出力:コード
入力:修正方針&コード 出力:コード 入力:コード (&検出したいこと) 出力:コード&説明 入力:コード(&何を知りたいか) 出力:説明 開発におけるユースケース
評価プロセスの大枠 「LLMを評価する」とは タスクを定義する 評価指標・手法を定める データセットを作成する モデルの出力を分析する
評価手法を定める 1. 人手評価 a. タスク・分野の専門家 b. クラウドソーシング 2. 自動評価 a.
定量的な基準を実装(ex. BLEU, ROUGE) b. LLM-as-a-judge; GPT-4と人間の評価判断が80%以上一致 [Zheng et al., 23] 「LLMを評価する」とは 正しい答えを出しているか⇨1a, 2aが良さそう 指定のフォーマットに則っているか⇨2が良さそう 倫理的に問題がないか⇨1, 2bが良さそうだが2aでできることもありそう 出力: I have pen 正解:I have a pen
評価プロセスの大枠 「LLMを評価する」とは タスクを定義する 評価指標を定める データセットを作成する モデルの出力を分析する
データセットの作成 設定したタスクと評価指標・方法を踏まえて、データを作成・収集する 1. 人手 a. タスク・分野の専門家 b. クラウドソーシング 2. 自動
a. 大規模コーパスからクローリング b. テンプレートを用意し、単語や文章を埋めていく c. LLM Synthetic Dataset(LLMを用いた人工的データセット) 「LLMを評価する」とは
データセット品質の担保 - 分量 - 妥当なデータ数があるか - 正確性 - 間違ったラベリングがされていないか -
ラベルの偏り - ex. はい/いいえで答えるタスクで、答えが「はい」のデータが9割 - 網羅性 - タスクが持つ複数の要素をカバーできているか - ex. 「テストコード生成タスク」⇨単体/Widget/E2E/etc.. - データの多様性 - 特定の単語やパターンが繰り返されていないか 「LLMを評価する」とは
作成したデータセットの公開 GitHub Hugging Face Dataset https://huggingface.co/datasets
評価プロセスの大枠 「LLMを評価する」とは タスクを定義する 評価指標を定める データセットを作成する モデルの出力を分析する(割愛)
FlutterにおけるLLM 評価
Flutter固有タスクの候補 FlutterにおけるLLM評価 タスクを定義する 評価指標を定める データセットを作成する UI実装・修正 Riverpodを用いたロジックの実装・修正 Widgetテスト・E2Eテストの実装・修正 設計の変更・リアーキテクチャ ネイティブコードからDartへの変換
評価指標・手法の候補 FlutterにおけるLLM評価 UI実装・修正 - ビルドが通るかまで見る - snapshotツールと併用する Riverpodを用いたロジックの実装・修正 - Riverpodのバージョンまで見る
Widgetテスト・E2Eテストの実装・修正 - テストが通るかまで見る - snapshotツールと併用する タスクを定義する 評価指標・手法を定める データセットを作成する
データセットの候補 FlutterにおけるLLM評価 タスクを定義する 評価指標を定める データセットを作成する データの収集元 GitHubのpublic repo 各種packageのonboarding ここが一番悩んでいるので、
意見を募集しています…!
簡易実験
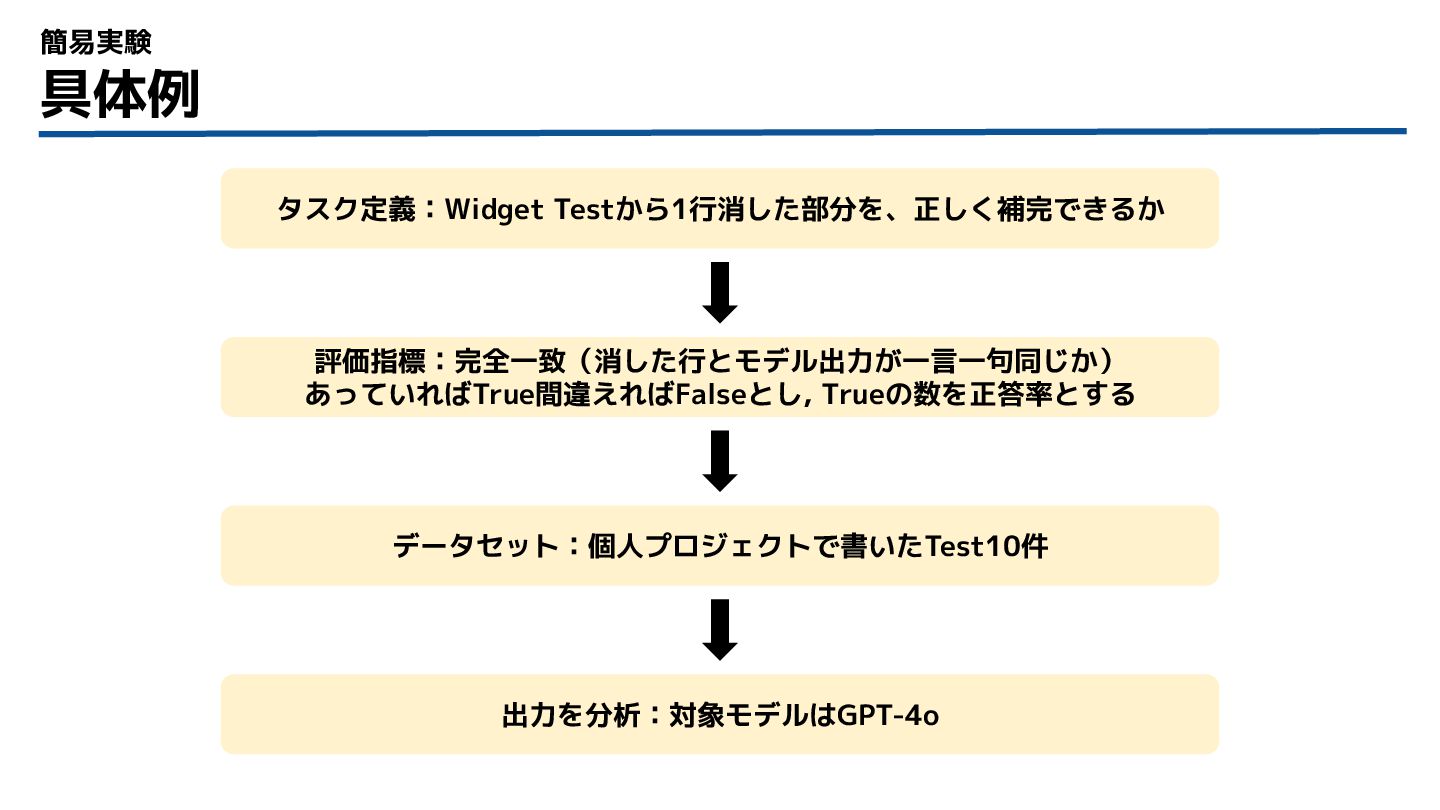
具体例 簡易実験 タスク定義:Widget Testから1行消した部分を、正しく補完できるか 評価指標:完全一致(消した行とモデル出力が一言一句同じか) あっていればTrue間違えればFalseとし, Trueの数を正答率とする データセット:個人プロジェクトで書いたTest10件 出力を分析:対象モデルはGPT-4o
結果 簡易実験 結果 90%成功した(さすが) 失敗した例 NotifierProviderのmockでoverrideWithValueを使おうとしていた 仮説 - テスト対象の元ファイルをcontextとして与えれば、providerの種類を間違え なさそう
- 学習データcutoffが2024春なので、riverpodの知識は更新されているはず
皆さんもやってみてください! 今回の簡易実験は各ステップに色々な穴があります ぜひどのように改善できるかを考えてみてください また、他のタスク設定や評価指標で実験した結果を是非公開してください😊 簡易実験
結言
- LLM評価について知ることで、AIコードエディタをより活用できる - LLMのFlutter性能を上げるのは、研究者ではなくFlutterコミュニティ - LLMにできないことは無限にあるはずで、より多くの個人が評価実験を 行い共有することで改善が加速する まとめ 結言
個人の展望 - Dart/Flutter性能評価ベンチマークの作成&公開 - より広範なモデルに対する評価実験 - AIコードエディタそのものの活用法の研究 結言
References - Zheng, Lianmin, et al. "Judging llm-as-a-judge with mt-bench
and chatbot arena." Advances in Neural Information Processing Systems 36 (2023): 46595-46623. - https://speakerdeck.com/chokkan/jsai2024-tutorial-llm
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}