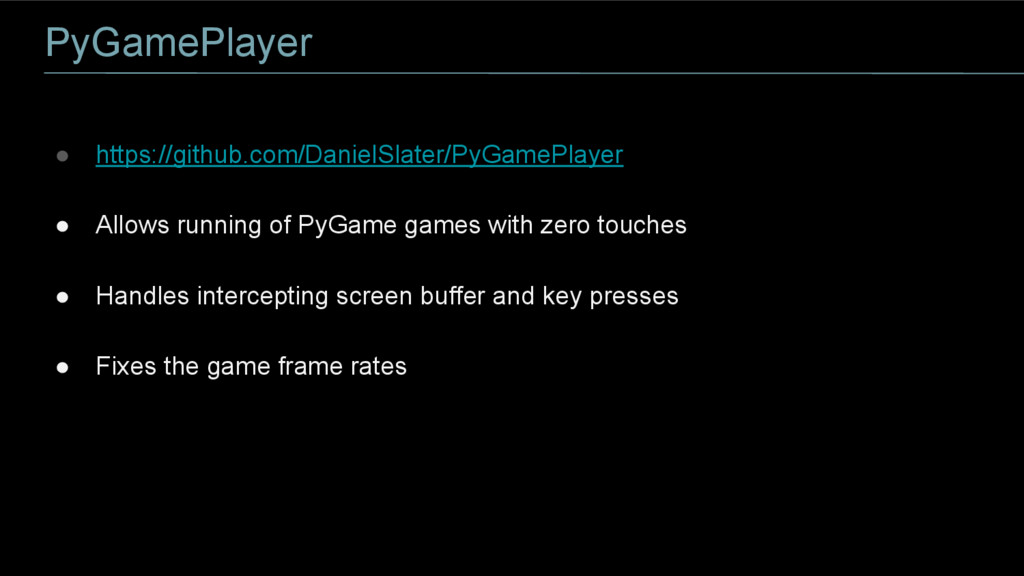
GitHub for this project is here https://github.com/DanielSlater/PyGamePlayer
There are 2 slides where I switch to code samples, the first is this one:
https://gist.github.com/DanielSlater/69c88b910bfe124eef0b
2nd:
https://github.com/DanielSlater/PyGamePlayer/blob/master/examples/pong_player.py
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}