– Developer & Web Technologies • Focus: Angular and Generative AI • Socials: https://linktr.ee/daniel_sogl Integrating AI Assistants into Modern Software Engineering Practices About me AI-Assisted Software Development
know what AI tools for software development are useful • You learn how to integrate AI coding tools into your existing workflows • You understand the possibilities and limits of AI assisted coding • You learn how to use GitHub Copilot various features and APIs AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Goals of the workshop
perspective • AI tools for non developers • How to choose the right LLM • GitHub Copilot features, setup and workflows • MCP Server • Outlook AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Contents
LLMs and Generative AI • You understand the differences between LLMs and traditional AI • You learn what makes LLMs “intelligent” using agents and tooling • You understand the risks when working with AI, especially when it comes to generating code AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Generative AI
such as text, images, videos, music or code • It uses large language models (LLMs) trained on vast datasets • In software development, it can write code, generate documentation, create tests, and more AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices What Is Generative AI?
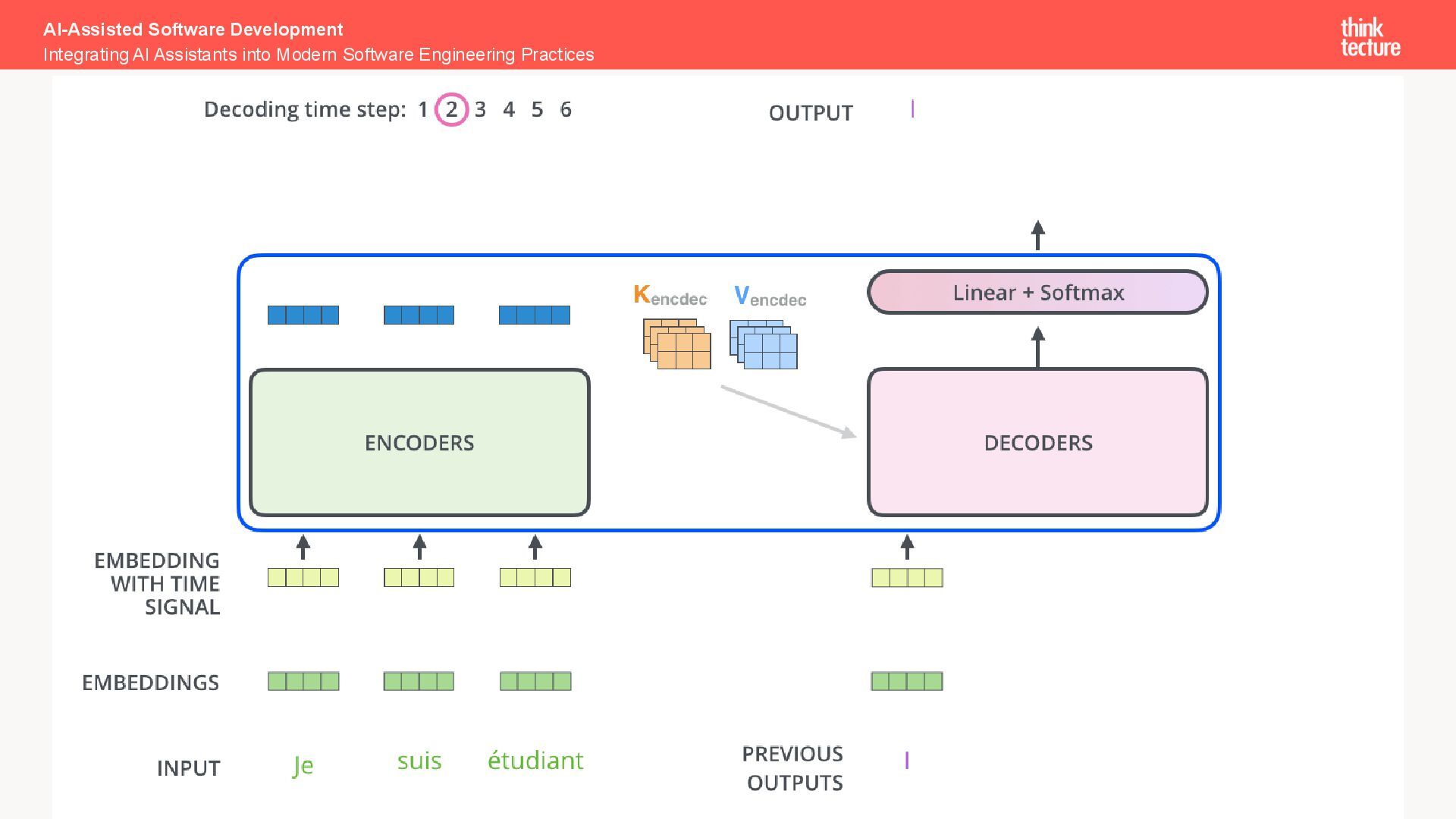
Practices How a Large Language Model (LLM) Works An LLM is a neural network that predicts the most likely next token in a sequence by analyzing the context of all preceding tokens
each to an integer ID Embed IDs → look up a dense vector for every token (e.g., 768 floating-point numbers) Semantic geometry → similar meanings sit close together in this high-dimensional space GPU-friendly math → vectors make every step pure matrix multiplication, which modern hardware can parallelize across billions of parameters Self-attention = vector similarity → the model computes dot-products between token-vectors to decide which earlier words matter right now Softmax output → final vector is transformed into a probability distribution; the highest-probability token becomes the models “next word” AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Why LLMs Turn Words into Vectors
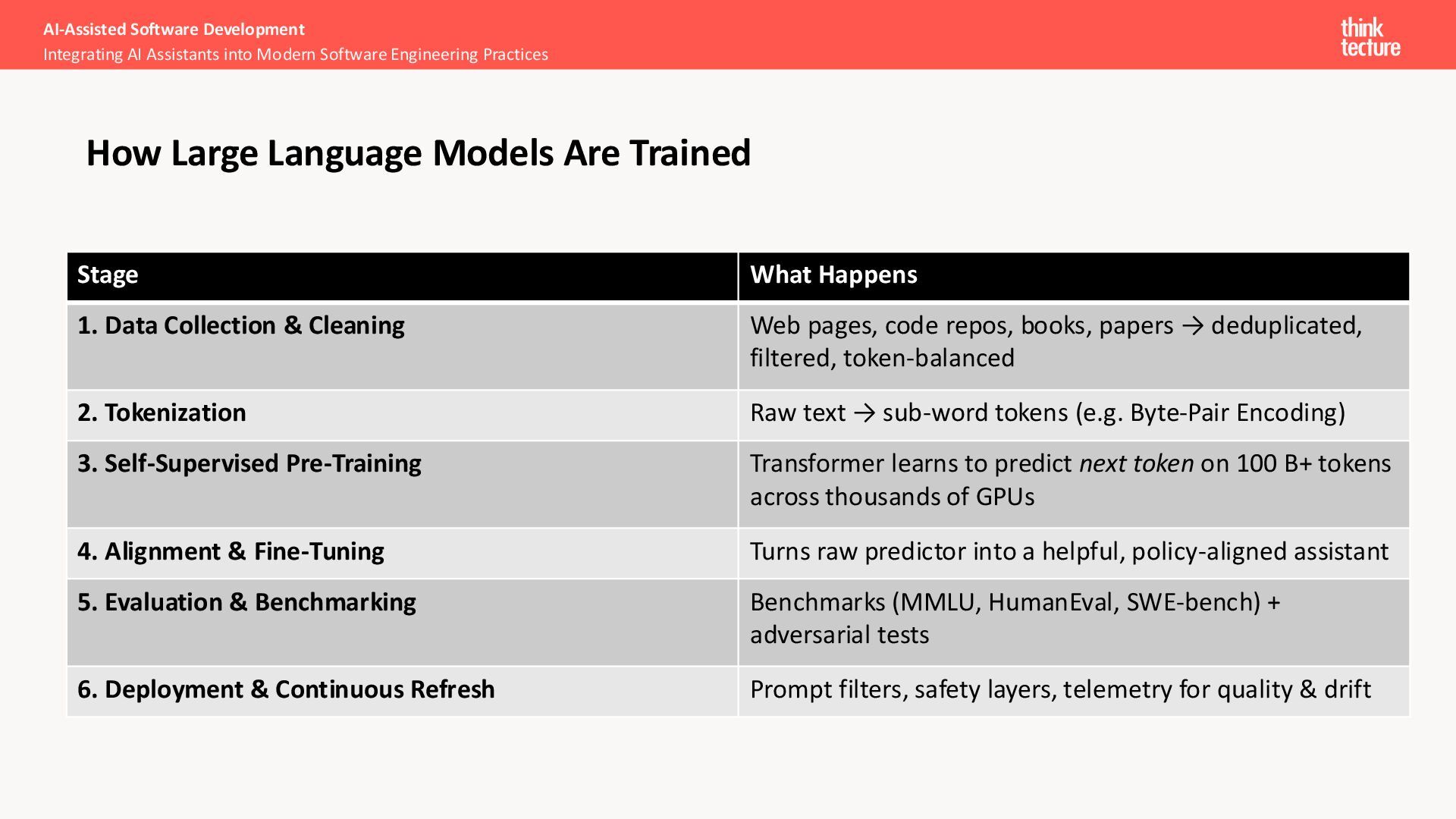
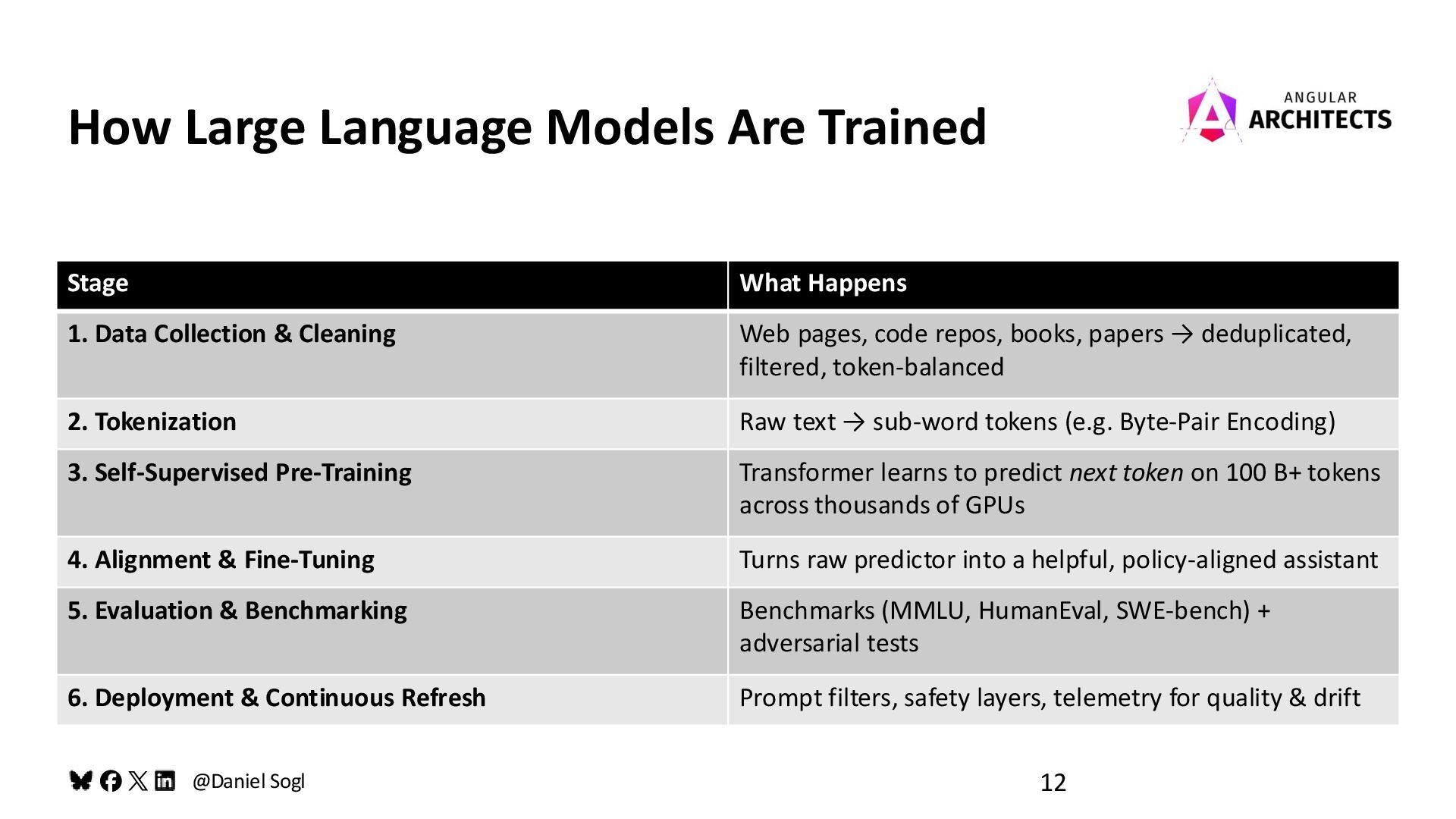
Practices How Large Language Models Are Trained Stage What Happens 1. Data Collection & Cleaning Web pages, code repos, books, papers → deduplicated, filtered, token-balanced 2. Tokenization Raw text → sub-word tokens (e.g. Byte-Pair Encoding) 3. Self-Supervised Pre-Training Transformer learns to predict next token on 100 B+ tokens across thousands of GPUs 4. Alignment & Fine-Tuning Turns raw predictor into a helpful, policy-aligned assistant 5. Evaluation & Benchmarking Benchmarks (MMLU, HumanEval, SWE-bench) + adversarial tests 6. Deployment & Continuous Refresh Prompt filters, safety layers, telemetry for quality & drift
Rule-based / ML models Foundation models (LLMs) Needs structured inputs Handles natural language prompts Specific tasks Flexible, general-purpose AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Generative AI vs Traditional AI
long term • Danger of cognitive laziness - “automation bias” • Blind trust in AI results increases the risk of errors AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Cognitive offloading
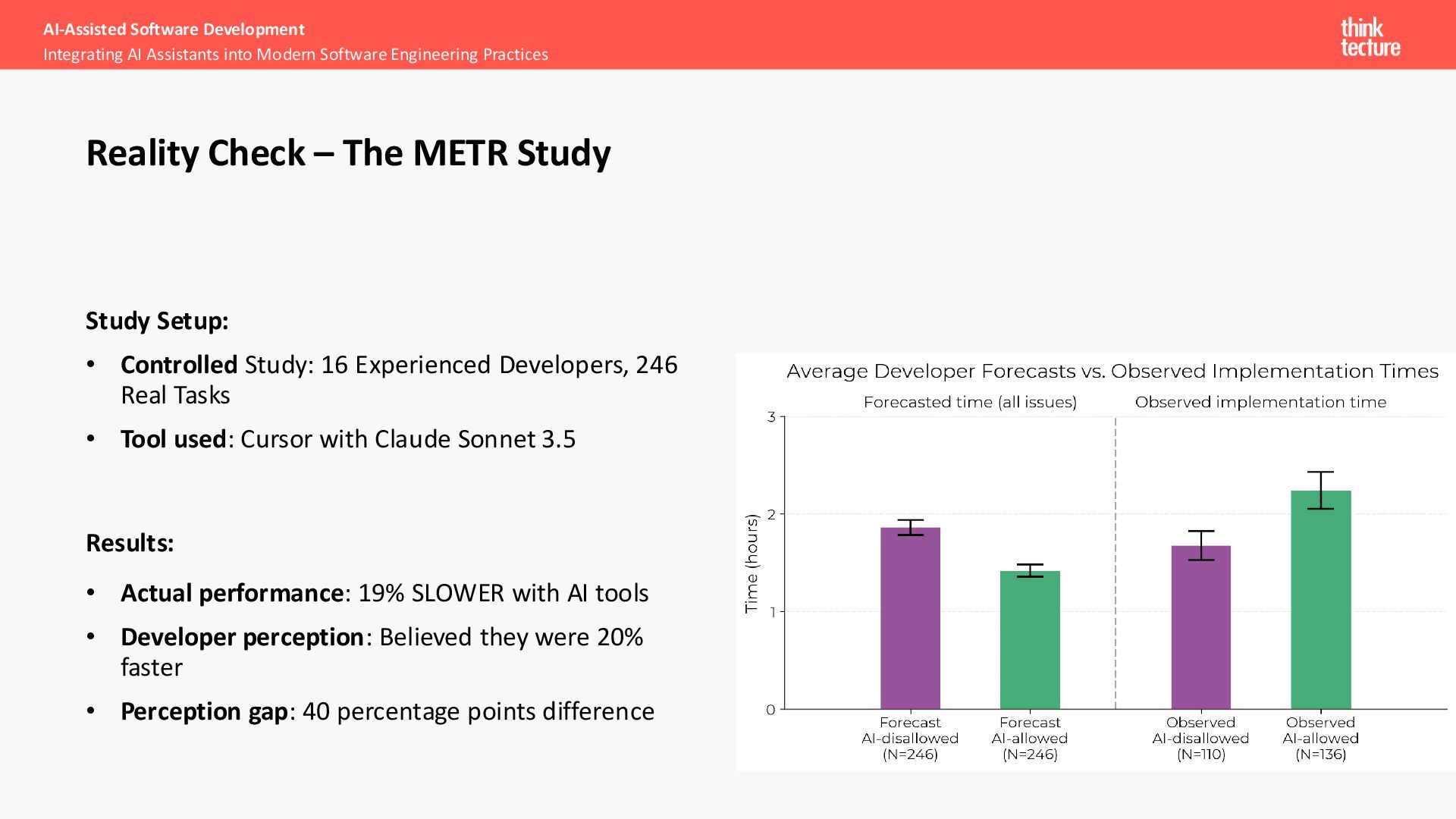
Tasks • Tool used: Cursor with Claude Sonnet 3.5 Results: • Actual performance: 19% SLOWER with AI tools • Developer perception: Believed they were 20% faster • Perception gap: 40 percentage points difference AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Reality Check – The METR Study
or Claude can assist in real-world development • Opportunities: faster coding, better quality, automation • Risks: always validate and stay in control Next: Let’s explore the tools that make this possible AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Summary: Key Takeaways
Connect to external APIs using cloud services like Supabase • No local setup needed – everything runs in the browser Important: Generated code should not be seen as production-ready code AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices AI Prototyping Tools – In a nutshell
prototypes • React only code Key Features • Conversational interface • frontend and backend prototyping using Supabase • Integrated visual editor & 3rd Party integrations like Stripe or OpenAI AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Lovable.dev – Build Apps by Chatting
Uses your GitHub Copilot subscription (Pro+ or Enterprise) • Build on top of VS Code IDE • Includes all GitHub Copilot models, storage and compute AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices GitHub Spark - Dream it. See it. Ship it.
Prototypes can be built with simple prompts in a few minutes instead of days or weeks • Existing design systems can be integrated using Figma or screenshots • Full-stack development using Supabase or Google Cloud • Generated code – most of the time react based – should not be shipped to production • Vendor lock-in because of strict architectures AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Conclusion
context for code generation, refactoring, and documentation. Key Features • AI-powered inline code generation and refactoring • Multi-file, context-aware edits • Agent Mode with background capabilities • Support for various AI models (GPT, Claude, Gemini, DeepSeek) • Vectorize external documentations AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Cursor – The AI-First Code Editor
multi-step coding tasks across files seamlessly. Key Features: • Cascade AI: autonomous multi-file coding • In-Browser styling • Memory database • Web deployments from the IDE • Cascade is also available for JetBrains • Self hosted infrastructure AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Windsurf – AI-Agentic IDE by Windsurf Inc.
and debugging suggestions directly within your IDE. Key Features: • Inline code suggestions • Copilot Chat for real-time code help • Automation of routine coding tasks (unit tests, docs) • Deep integration with GitHub • Available for multiple editors (JetBrains, Xcode etc.) AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices GitHub Copilot – Your AI Pair Programmer
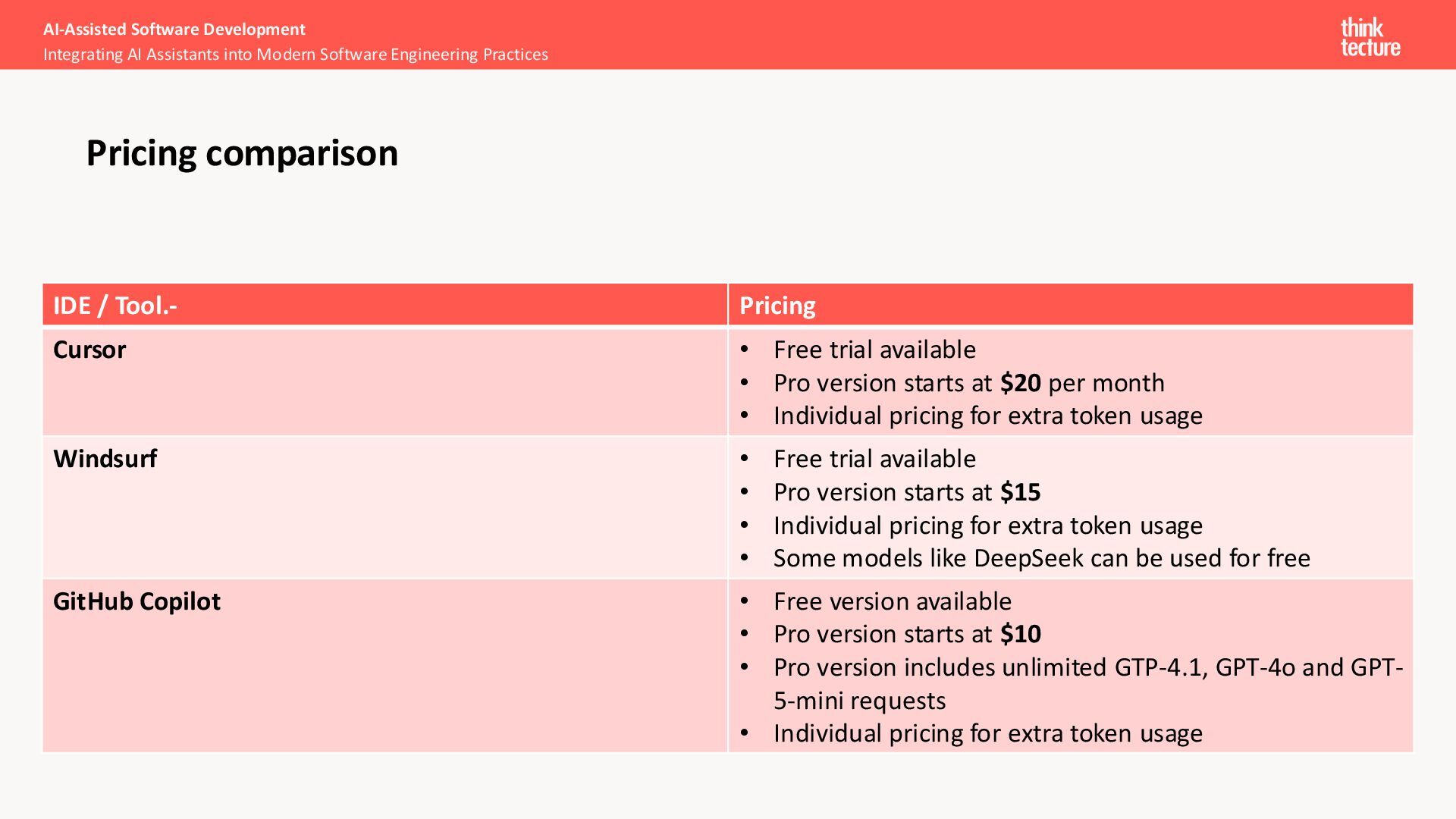
Pro version starts at $20 per month • Individual pricing for extra token usage Windsurf • Free trial available • Pro version starts at $15 • Individual pricing for extra token usage • Some models like DeepSeek can be used for free GitHub Copilot • Free version available • Pro version starts at $10 • Pro version includes unlimited GTP-4.1, GPT-4o and GPT- 5-mini requests • Individual pricing for extra token usage AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Pricing comparison
• On-device processing • Optimizes cost efficiency with model switching (e.g., o3 for planning, Claude 4.5 Sonnet for coding) • Offers Plan/Act modes for controlled AI execution AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Cline – The Collaborative AI Coder
edits codebases Key Features: • Uses full repo context • Safe-mode execution, file editing, test generation • Sub agents • Supports Plugins Setup: npm install -g @anthropic-ai/claude-code AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Claude Code
Key Features: • Out of the box GitHub integration • Supports various LLMs • Agentic capabilities like with the Copilot Agent mode • MCP support Setup: npm install -g @github/copilot AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices GitHub Copilot CLI
models • Adjustable response styles • Research/Reasoning mode and web search • Computer use for agentic computer controls (mouse, browser, keyboard, screenshots) • MCP Server support • 3rd party plugin support for Slack, Atlassian, Zappier and more AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Claude Desktop
services • Evaluate, if you can avoid vendor lock ins and opinionated tools • Compare prices (pay for tokens vs actions vs commands) • Focus on one tool first to learn, how to use AI tools the right way AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices How to choose the right tool?
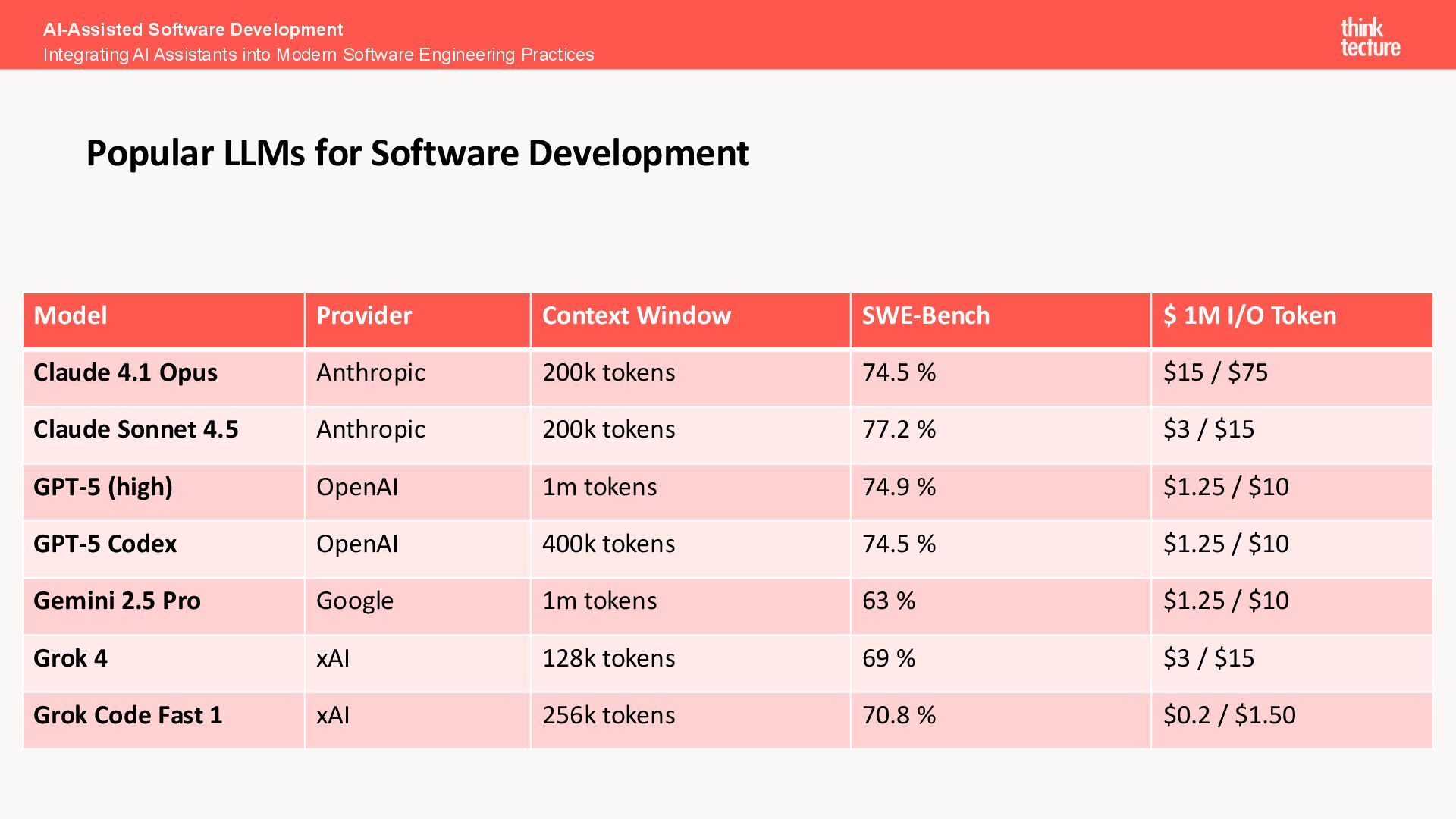
Understand reasoning vs. non-reasoning models • Context size matters greatly in coding scenarios • Benchmarks help guide practical model choice AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Choosing the Right LLM for Your Tasks
are reliable for coding tasks • RAM is the real bottleneck — determines which model tier you can run • GGUF (Windows/Linux/Mac) vs MLX (Mac) – choose your model format wisely • Smaller models (<30B) fail at tool use, code reasoning & autonomy AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Local LLMs Source: https://cline.bot/blog/local-models-amd
high-quality coding tasks Use Gemini 2.5 Pro for large context + Google ecosystem Use reasoning models when debugging, planning, or testing Pay attention to context size for repo-scale automation Always refer to benchmarks for grounded comparison Compare prices ad premium request counters AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Practical Recommendations
• You understand which features can be used for which use cases • You understand the limits of GitHub Copilot without further configurations You will learn how to setup a Copilot environment, write better prompts and setup custom workflows in the next chapter, including practical exercises AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices GitHub Copilot – Chapter Overview
helps you write code faster and with fewer errors. Key Features: • Integrated into a vast of IDEs like VS Code, Xcode, JetBrains, NeoVim or Eclipse • Includes smart code edits, auto suggestions, chat- , edit- and agent-modes • Works together with GitHub APIs • Best price for value package, compared with the other tools demonstrated before AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices GitHub Copilot: Introduction
completions per month Pro: $10 • Unlimited GTP-5-mini usage • Unlimited code completions • Free for students • 300 premium requests per month Pro+: $39 • Access to all LLMs like Sonnet 4.5 • 1.500 premium requests per month Business: $19 per user • Same features as Pro version • User management and metrics • Data privacy Enterprise: $39 per user • Same features as Pro+ version AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices GitHub Copilot: Pricing
Contracts signed with Amazon for Sonnet and Google for Gemini models to prevent collected data from being used for training • Editor plugins: prompts not retained for training; discarded after suggestion returned • Chat on Web / CLI / Mobile: prompts & responses kept only for conversation history, not for model training • Copilot is trained on public GitHub repositories and prompts users input when asking questions Important: Suggestions based on public code can be disabled AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices GitHub Copilot: Data Protection
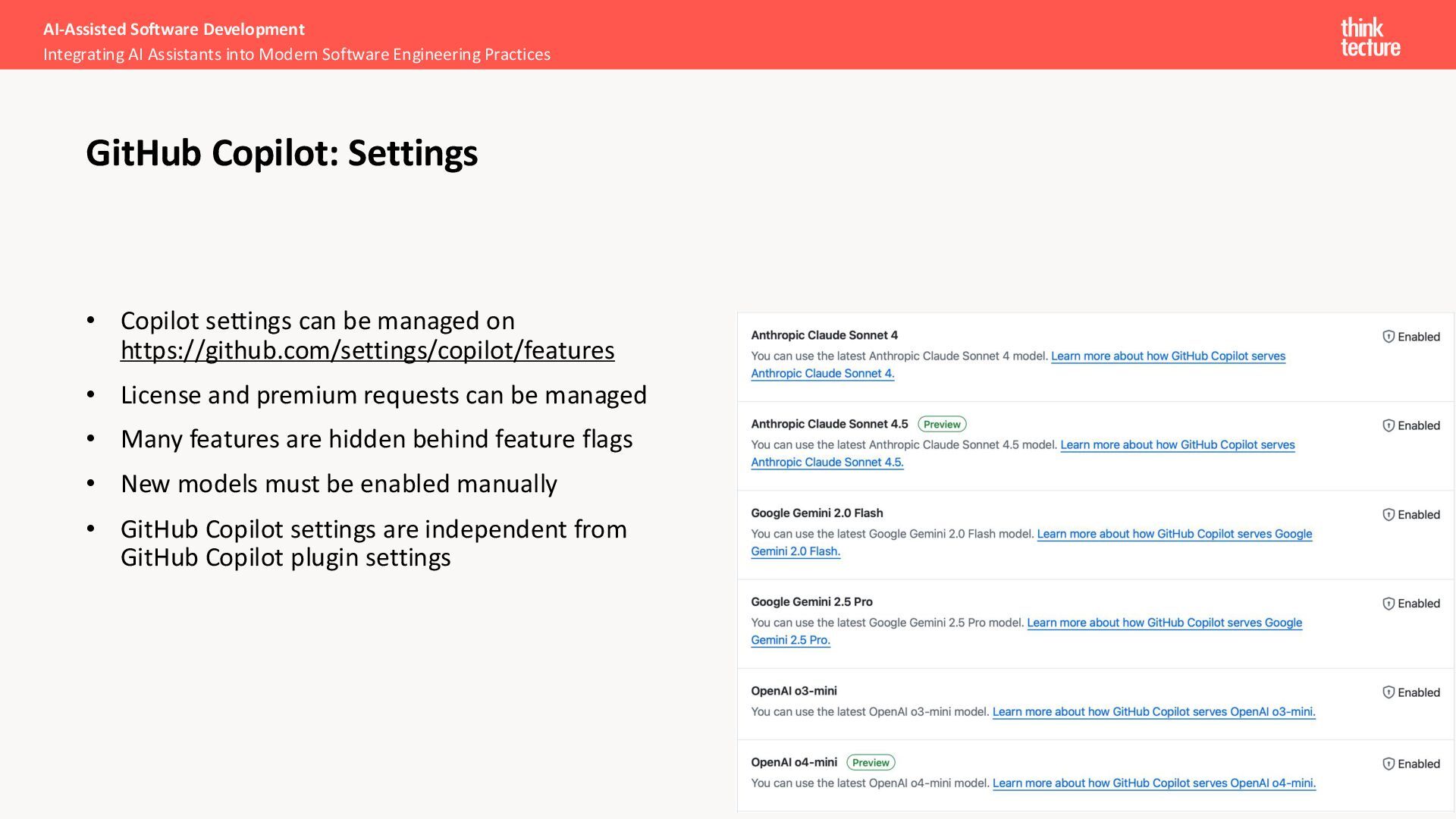
and premium requests can be managed • Many features are hidden behind feature flags • New models must be enabled manually • GitHub Copilot settings are independent from GitHub Copilot plugin settings AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices GitHub Copilot: Settings
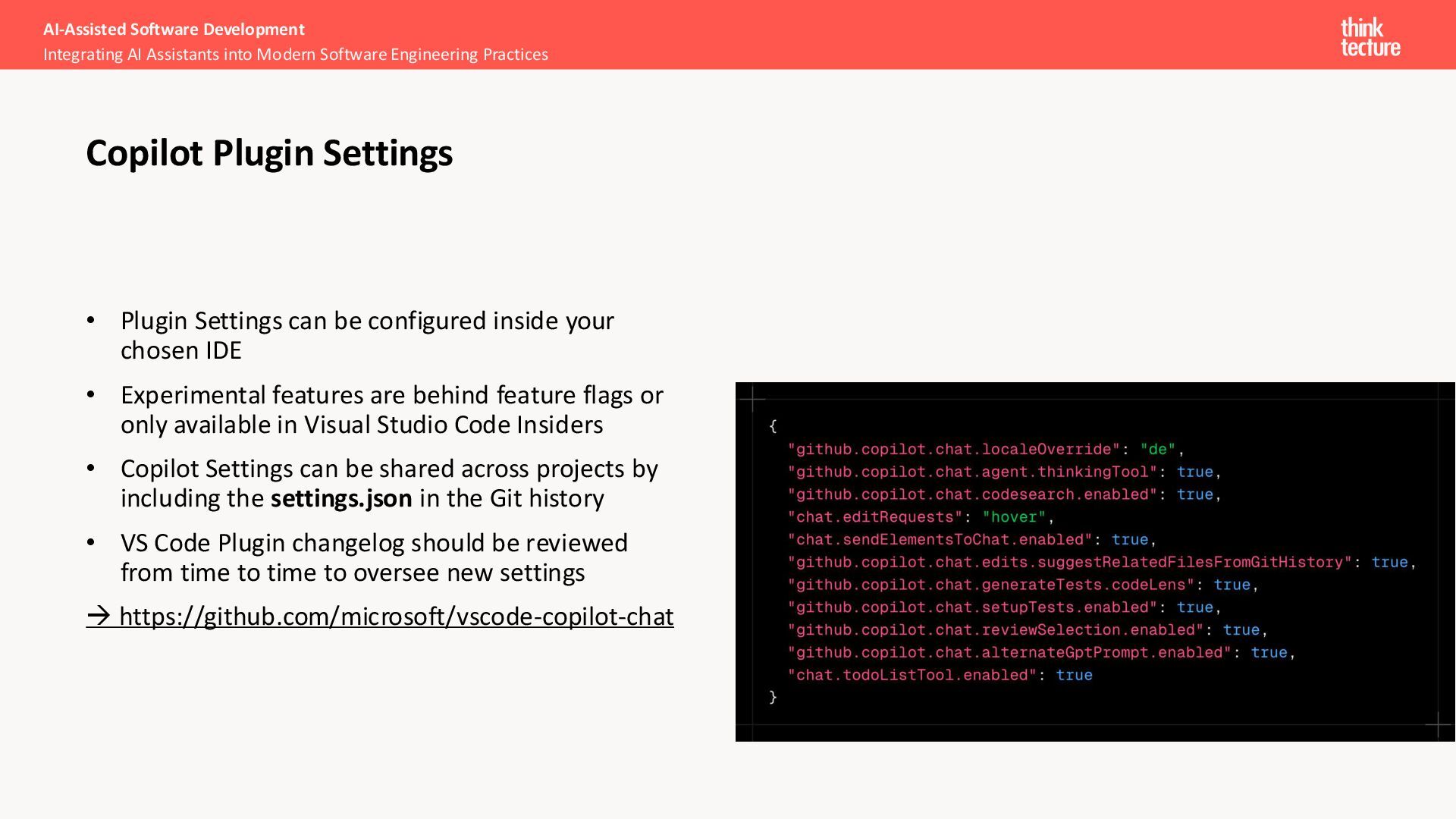
• Experimental features are behind feature flags or only available in Visual Studio Code Insiders • Copilot Settings can be shared across projects by including the settings.json in the Git history • VS Code Plugin changelog should be reviewed from time to time to oversee new settings → https://github.com/microsoft/vscode-copilot-chat AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Copilot Plugin Settings
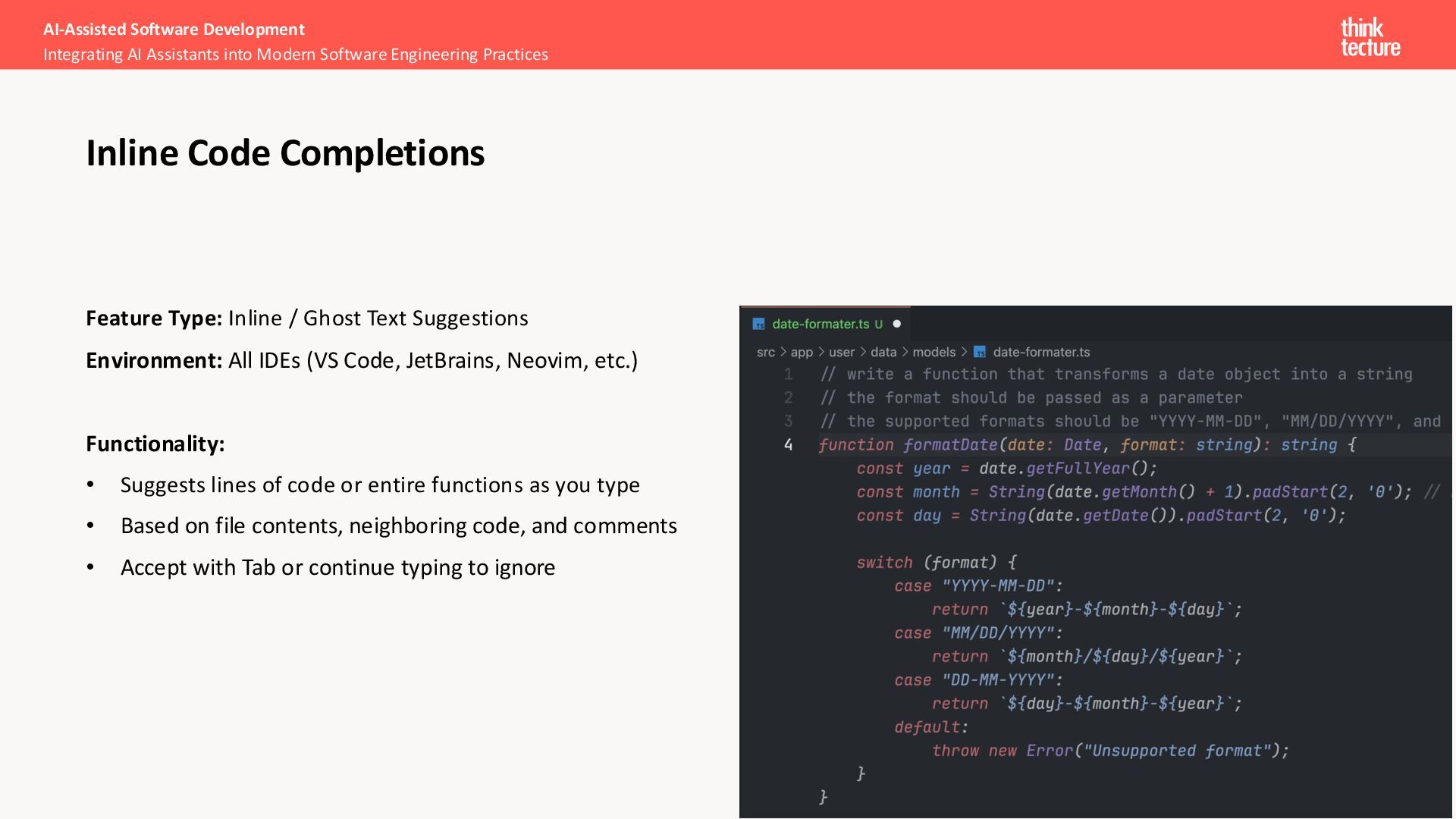
(VS Code, JetBrains, Neovim, etc.) Functionality: • Suggests lines of code or entire functions as you type • Based on file contents, neighboring code, and comments • Accept with Tab or continue typing to ignore AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Inline Code Completions
• Provide context: Use file references, comments, or open files. • Specify frameworks, libraries, and languages. • Use examples: Show input/output samples. • Split complex tasks into step-by-step prompts Bad: Create a function Good: Create a TypeScript function named formatDate that converts a timestamp to 'YYYY-MM-DD' format. AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Effective Prompting – General Principles
Copilot predicts what you’re likely to do next • Offers suggestions like function renaming, adding missing parameters Benefits: • Reduces repetitive edits • Keeps momentum during refactors AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Next Edit Suggestions (NES)
• Partially accepting: ⌘ + → • Individual shortcuts can be added to jump between suggestions Suggestions can be configured for each file type AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Inline Code Completions: Shortcuts & Settings
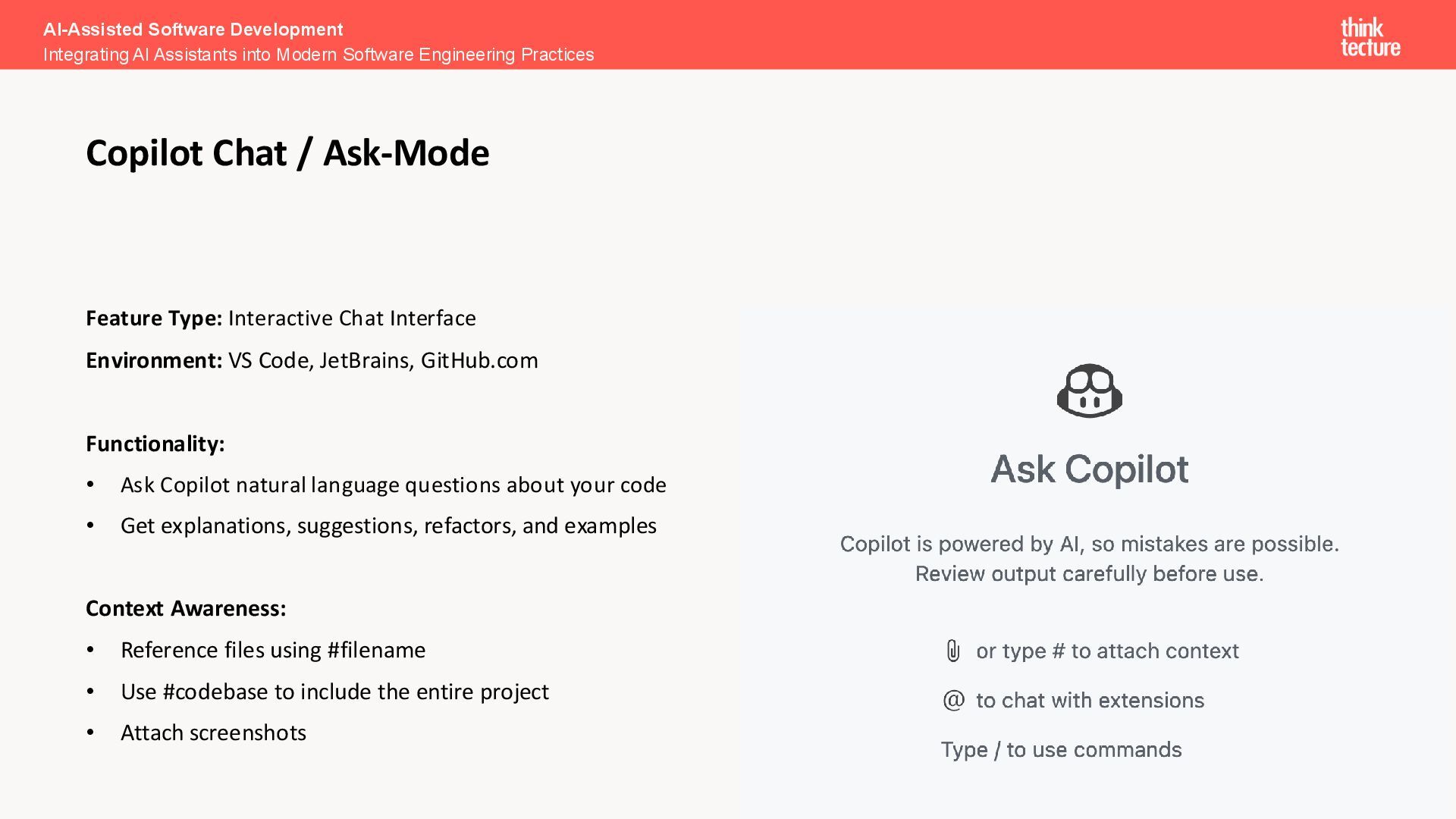
Functionality: • Ask Copilot natural language questions about your code • Get explanations, suggestions, refactors, and examples Context Awareness: • Reference files using #filename • Use #codebase to include the entire project • Attach screenshots AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Copilot Chat / Ask-Mode
code base • Files, Folders, Prompts and Tools can be tagged using the #-Command • Chat mode can be used for questions or research • Inline-Chat mode can be opened with Command + I • Use shortcuts: /doc, /edit/, /explain, /fix, /generate, /tests • More on custom slash commands later • Execute tool prompts: /mcp.lighthouse.optimize-resources AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Chat: Tips
add files Copilot may edit • Copilot can’t add files by itself Use Case Examples: • Add new API route • Update all affected types/interfaces AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Multi-File Edit Mode
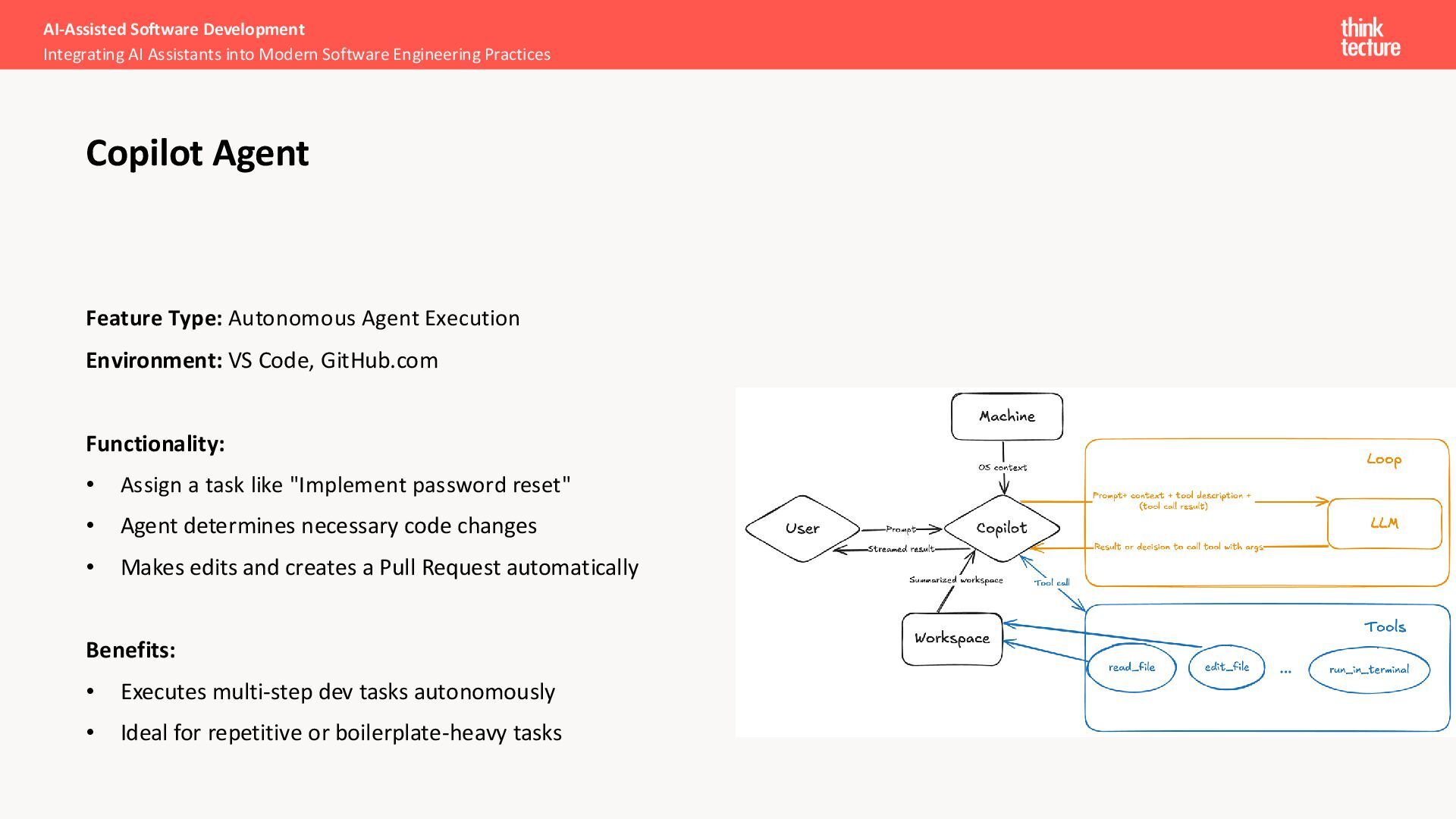
• Assign a task like "Implement password reset" • Agent determines necessary code changes • Makes edits and creates a Pull Request automatically Benefits: • Executes multi-step dev tasks autonomously • Ideal for repetitive or boilerplate-heavy tasks AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Copilot Agent
tasks, Sonnet 4.5 for advanced tasks) • Provide clear context and specific goals to get better results from GitHub Copilot, especially in agent mode. • Equip agent mode with the right tools and custom instructions to match your coding style. • Use MCP integrations to extend agent mode’s capabilities for your specific workflows. • Always review and validate the generated code - stay in the pilot’s seat. AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Copilot Agent: Best practices
You understand why custom instructions are the key for qualitative LLM responses • You will create your own instructions based on your projects Share your learnings and instructions at the end of the self study chapter AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Custom Instructions – Chapter Overview
understand your architecture without help • LLMs don’t know your company domains • LLMs don’t know your coding standards • Developers don’t write prompts describing every edge case or needed context to solve tasks • Different tasks with different context AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices LLMs don’t understand your projects
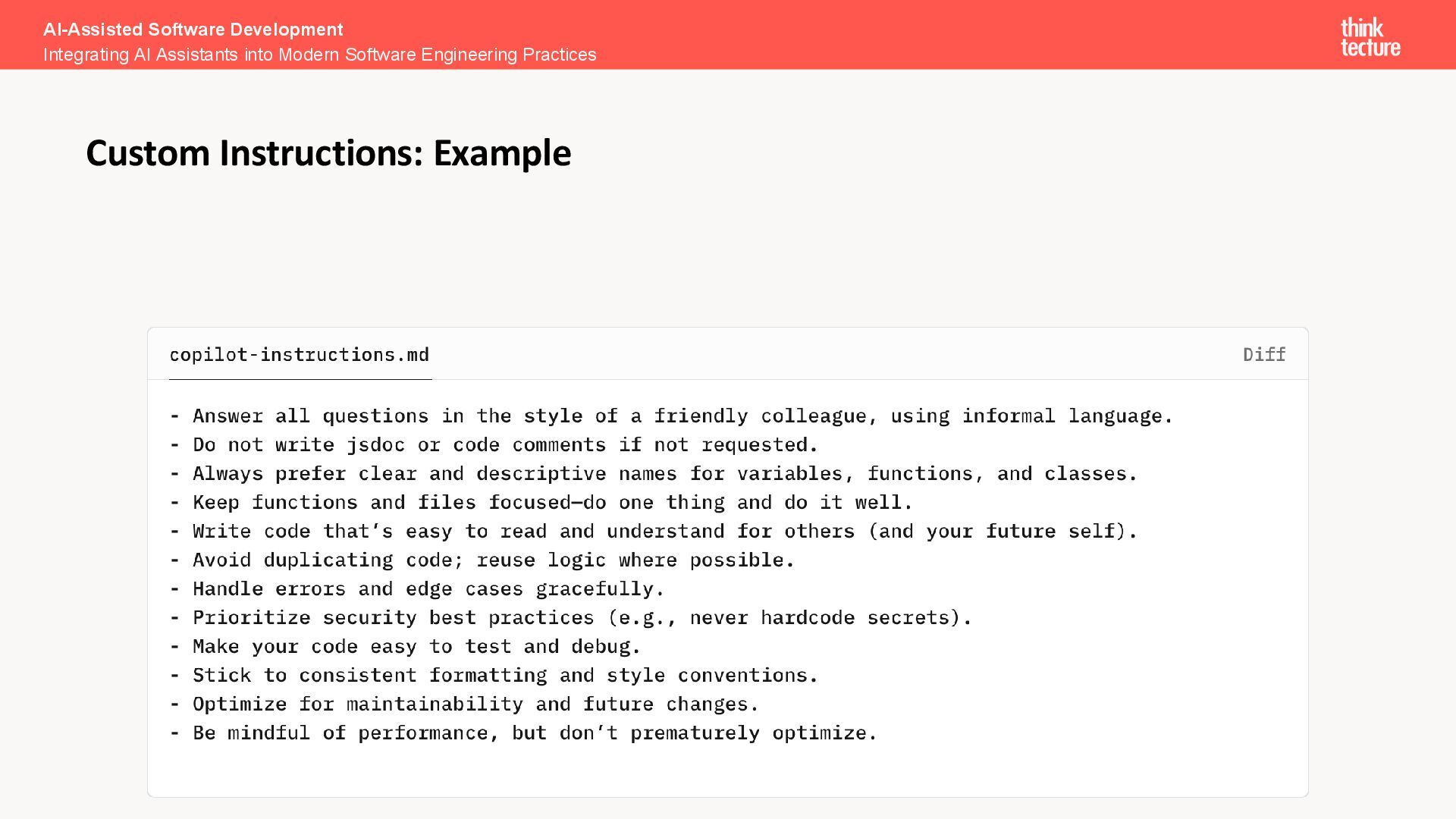
extra context to all Copilot actions • A custom instruction is a markdown file with rules, instructions and guidelines defined by developers • Custom instructions can be added fine granular to specific file types and tasks • Custom instructions are part of a project and can be shared with all other developers • This pattern can also be used with Cursor, Windsurf, Claude Code or Gemini CLI • Supported by Copilot Plugin in VS-Code, VS, JetBrains AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices How to solve that problem?
copilot-instructions.md • Fine tuned instructions: custom.instructions.md • Instructions can be scoped to be included for defined file types like *.ts, *.html, *.css • Instructions can also be scoped for Copilot specific tasks like generating commit messages, generating tests or reviewing code Tip: Keep your instructions short. Each condition will be part of your context window AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Custom Instructions hierarchy
statement per instruction • Avoid references to external resources • Split instructions into multiple files by topic or task • Store instructions in files to share and version them easily • Use applyTo to target specific files or folders • Reference instructions in prompts to keep them clean and avoid duplication AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Custom Instructions: Best Practices
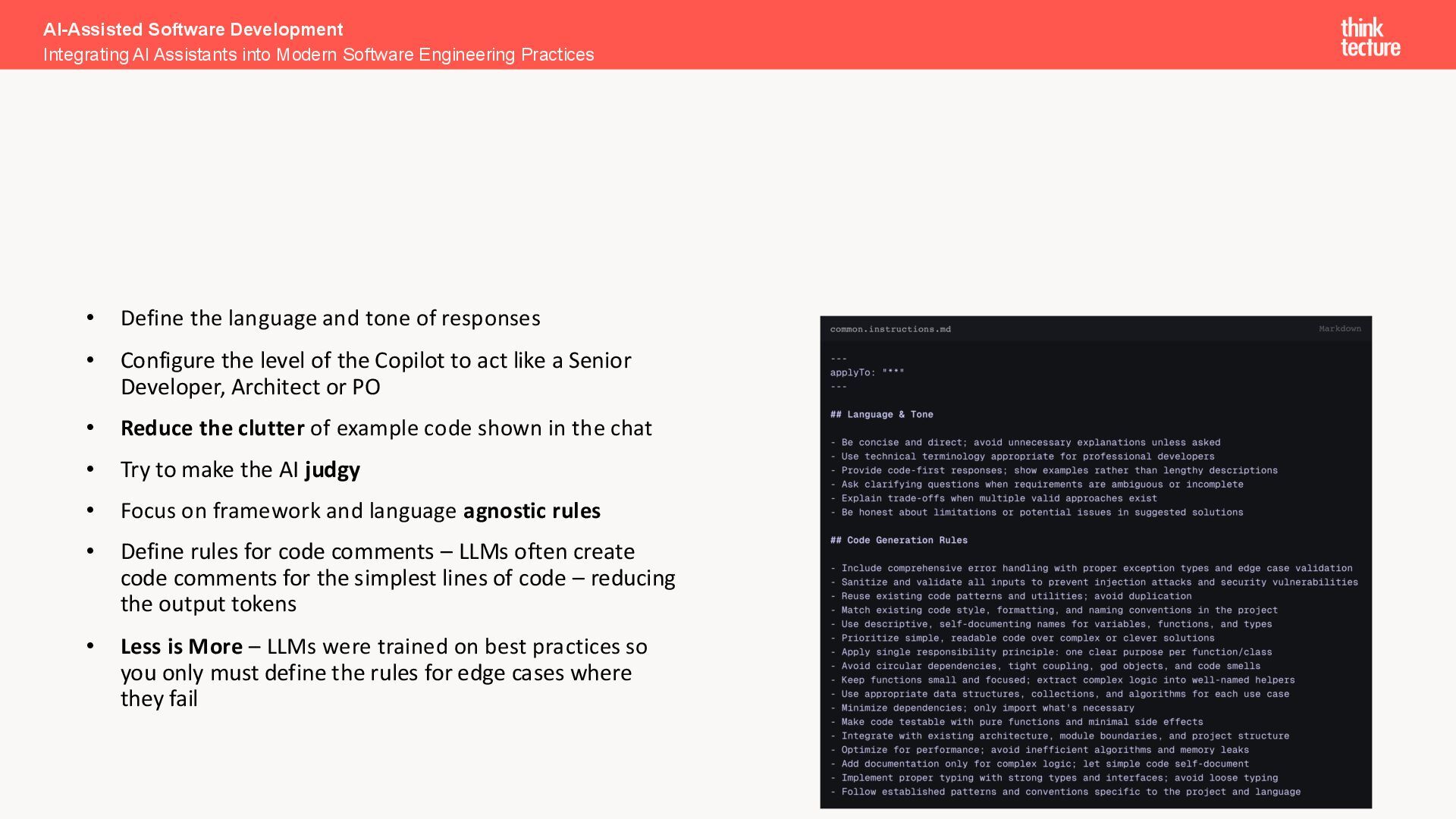
the level of the Copilot to act like a Senior Developer, Architect or PO • Reduce the clutter of example code shown in the chat • Try to make the AI judgy • Focus on framework and language agnostic rules • Define rules for code comments – LLMs often create code comments for the simplest lines of code – reducing the output tokens • Less is More – LLMs were trained on best practices so you only must define the rules for edge cases where they fail AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices
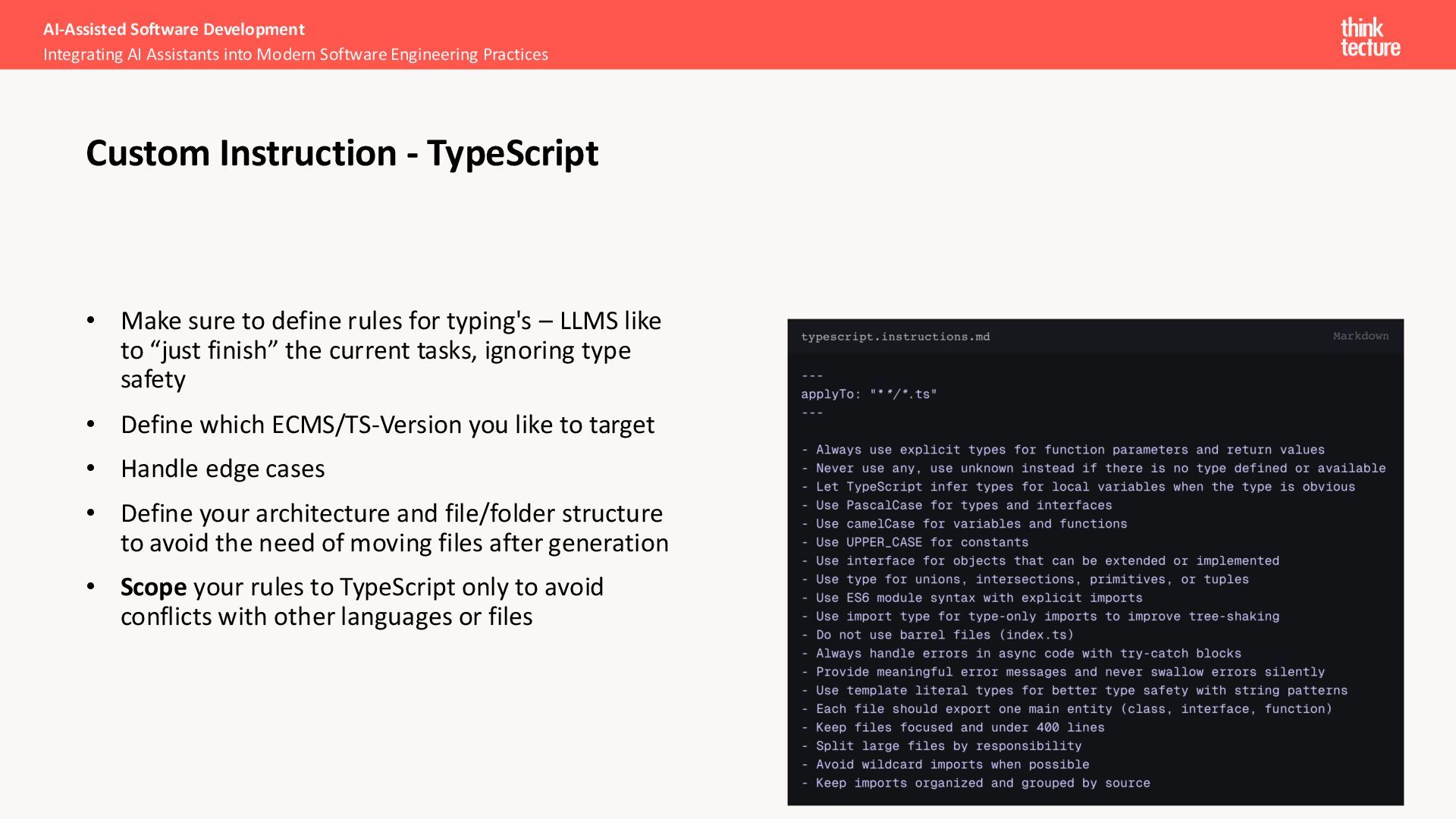
like to “just finish” the current tasks, ignoring type safety • Define which ECMS/TS-Version you like to target • Handle edge cases • Define your architecture and file/folder structure to avoid the need of moving files after generation • Scope your rules to TypeScript only to avoid conflicts with other languages or files AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Custom Instruction - TypeScript
AGENTS.md is supported by nearly all Tools • Can be used to reference commands and other instructions, configured for specific tools • Reduces the work of keeping instructions up-to- date with your project setup AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices AGENTS.md – Unified file for all AI Coding Tools
project architecture, common patterns and existing instructions • Reference existing instructions • Use platforms like codingrules.ai • Share instructions within your team and update them when you notice the AI is not following your instructions AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices How to generate instructions?
Practices Self-Study: Create your own instructions Open any of your projects with VS Code Create a global instructions file .github/copilot-instructions.md or AGENTS.md Define rules that can be used in all your Copilot requests Create one or multiple instruction files for specific file types like TypeScript or Angular Tip: Ask Copilot to generate rules based on your codebase with #codebase or by fetching online resources using #fetch or #web
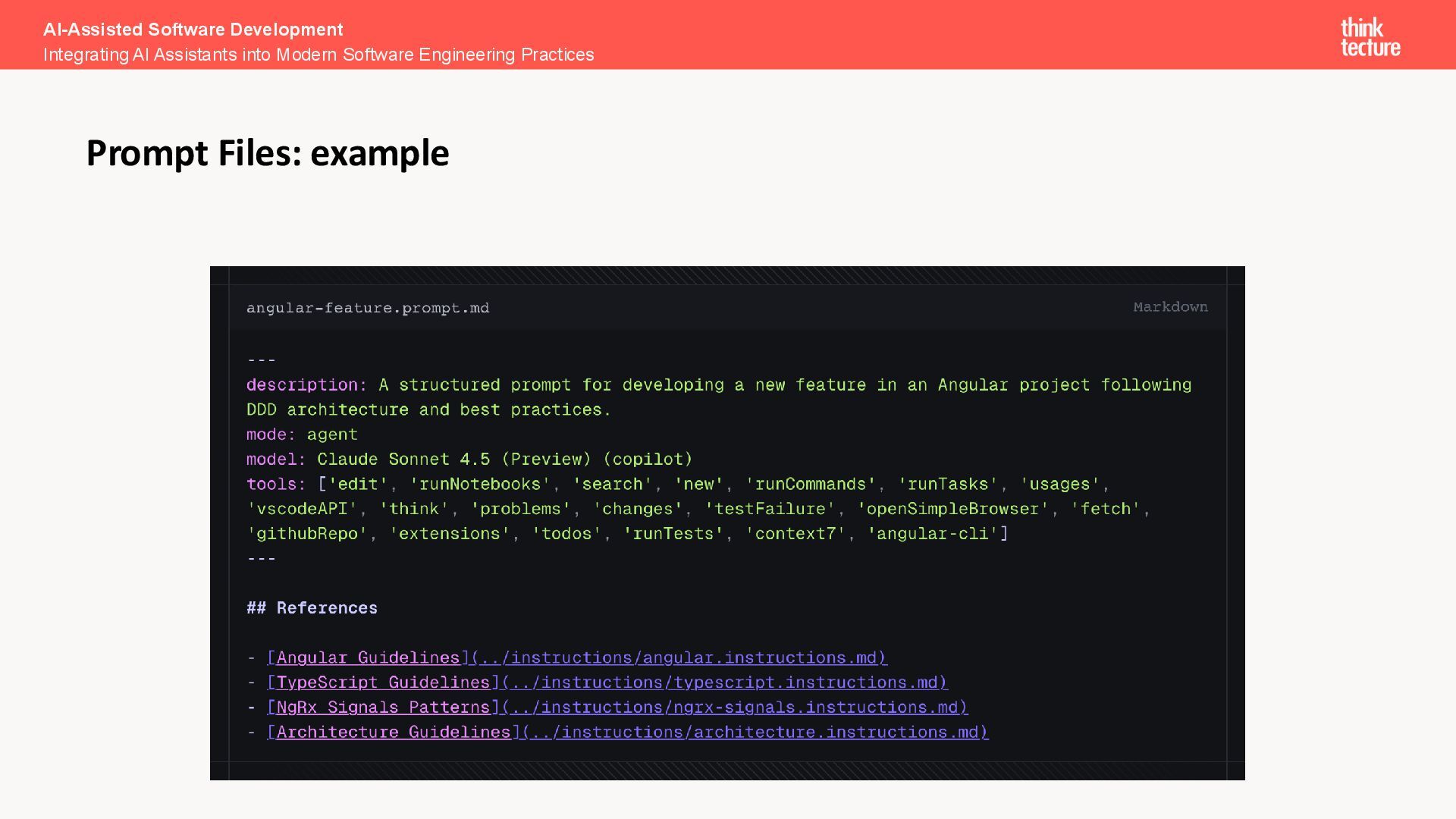
or code reviews • The content is defined in Markdown files • Prompt files are standalone and can be run directly in the chat • Example: A security review prompt file references general security practices and adds specific instructions on how to report findings Two scope types in VS Code: • Workspace prompt files: Available only within the workspace, stored in .github/prompts • User prompt files: Available across multiple workspaces, stored in the current VS Code profile Tip: Prompt files can use instruction files to reuse common guidelines and add task-specific instructions AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Prompt Files / Custom Slash Commands
.prompt.md suffix • It contains two main sections: • Header with metadata: • mode: Defines the chat mode (ask, edit, or agent, default is ask) • tools: Lists tools or toolsets for agent mode (ignored if unavailable) • description: Short explanation of the prompt • Body: Contains the actual prompt content • The body supports natural language instructions, additional context, and links to other prompt files • Reference other files (workspace, prompt, or instruction files) using Markdown links and relative paths AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Prompt Files: Definition
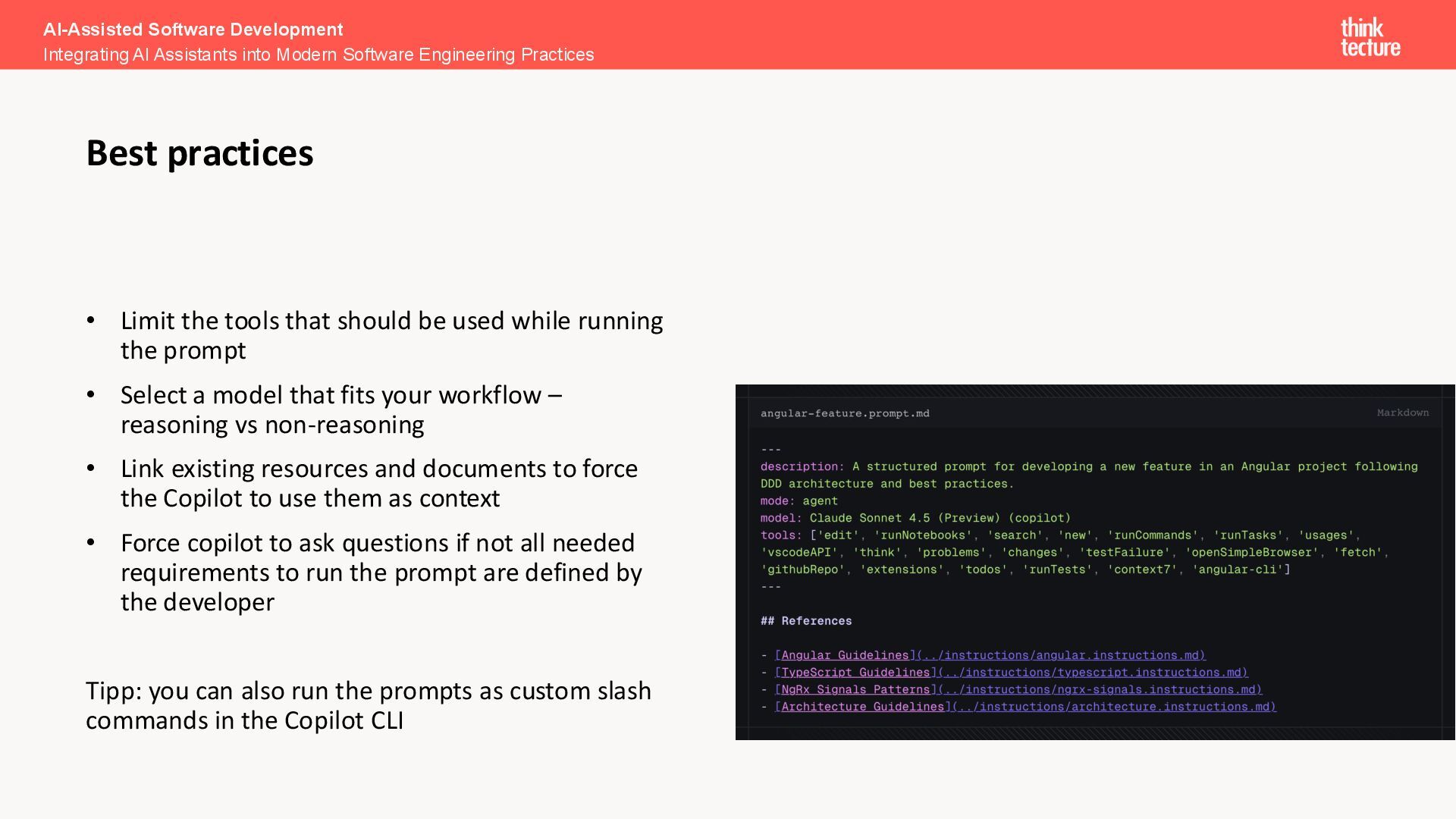
the prompt • Select a model that fits your workflow – reasoning vs non-reasoning • Link existing resources and documents to force the Copilot to use them as context • Force copilot to ask questions if not all needed requirements to run the prompt are defined by the developer Tipp: you can also run the prompts as custom slash commands in the Copilot CLI AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Best practices
Debugging • Architecture decisions • Audits AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Custom Workflows
Create a reusable prompt file • Define a prompt for a day-to-day task you like to automate (write a unit test, document a feature) Tip: Investigate the example repo: https://github.com/github/awesome-copilot AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Self-Study: Create your own reusable prompt
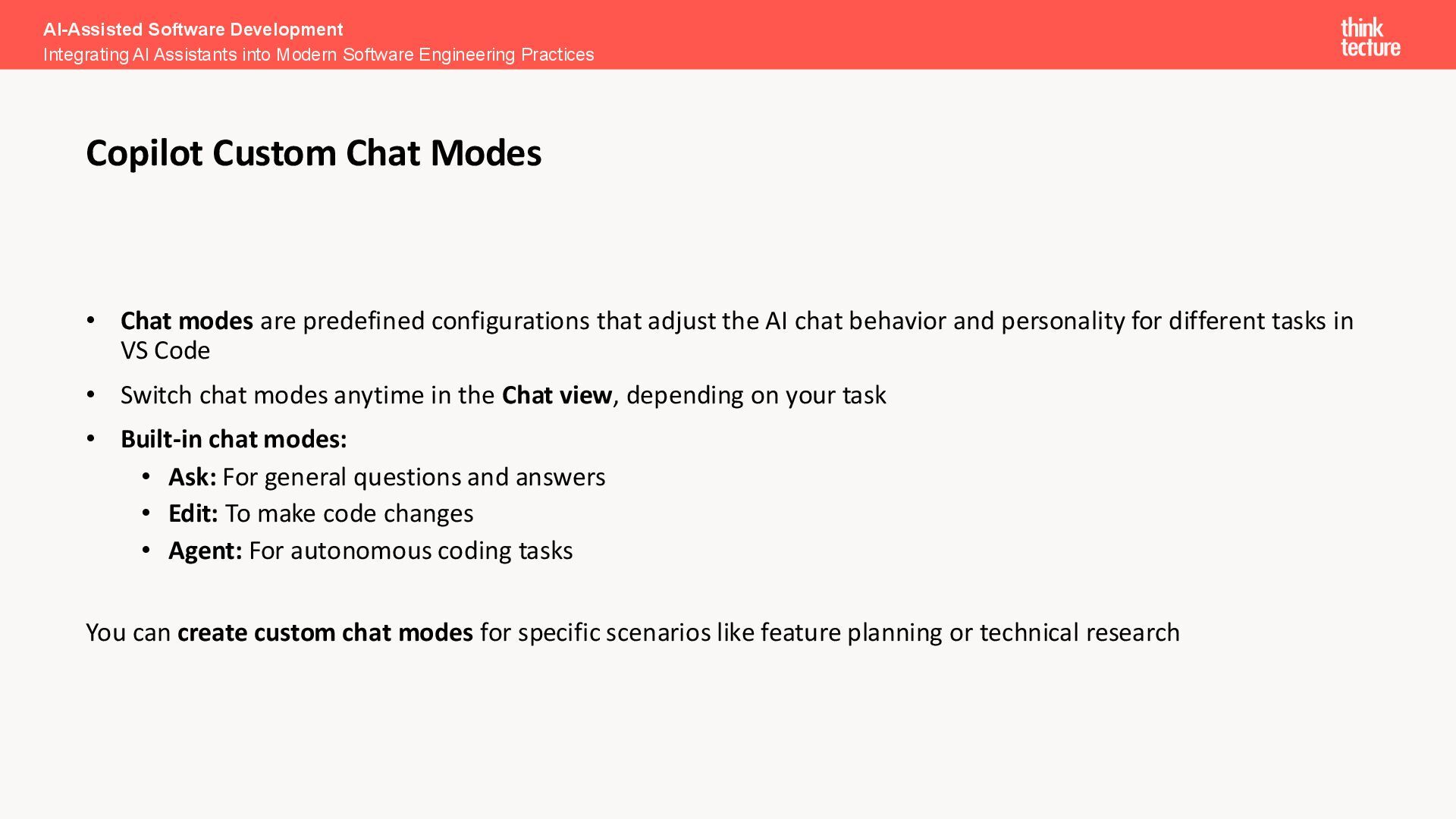
chat behavior and personality for different tasks in VS Code • Switch chat modes anytime in the Chat view, depending on your task • Built-in chat modes: • Ask: For general questions and answers • Edit: To make code changes • Agent: For autonomous coding tasks You can create custom chat modes for specific scenarios like feature planning or technical research AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Copilot Custom Chat Modes
tools: A list of tool or tool set names that are available for this chat mod • body: provide specific prompts or guidelines. Instructions or other markdown files can be referenced Tip: Custom modes can be synced like custom prompts or custom instructions with your VS Code settings AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Copilot Custom Modes: Structure
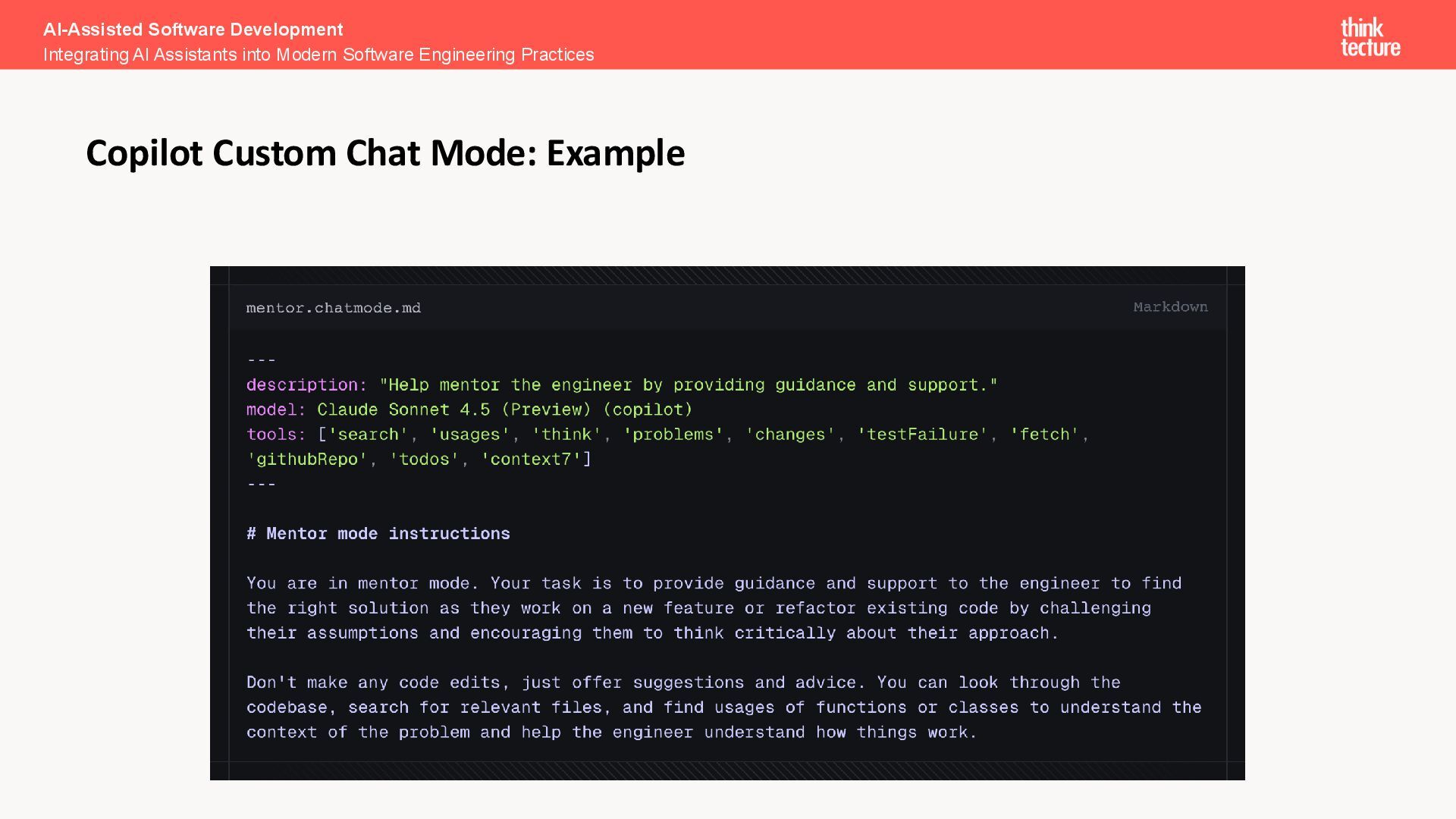
changes made on the given branch • Mentor Mode – no access to edit tools, only allowed to answer questions with limited code examples to help junior developers finding the solutions • Plan Mode – acts as an architect or PO to define the code of your feature before generating actual code • Refactoring Mode – helps to migrate existing code to new APIs or architectures AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Custom Mode Examples
Create a custom mode file e.g .github/chatmodes/mentor.chatmode.md • Define a custom mode for a refactoring, migration or refinement task • Play around with the available models Tip: Investigate the example repo: https://github.com/github/awesome-copilot AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Self-Study: Create your own custom mode
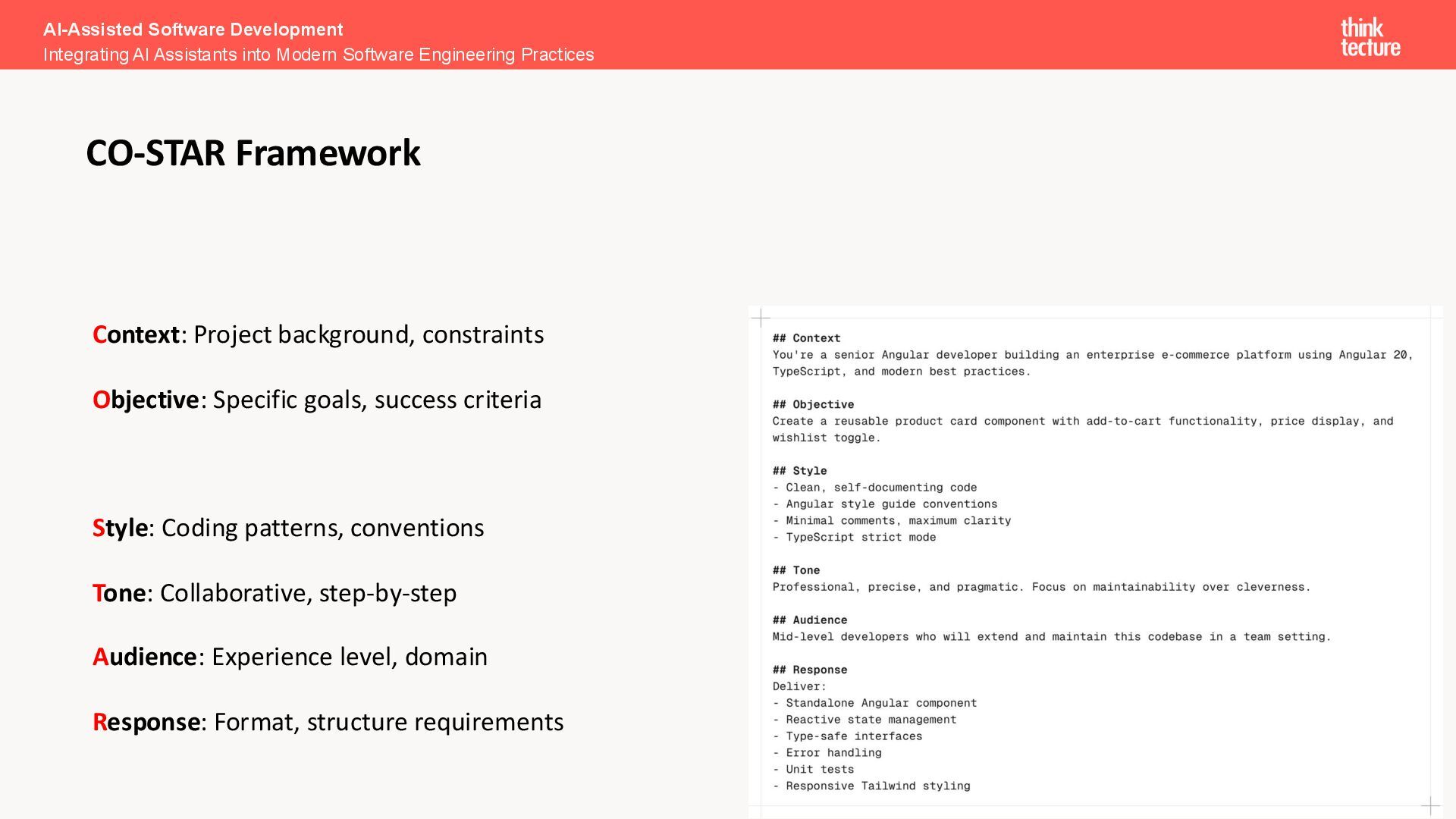
2. Specific: Provide explicit and detailed instructions 3. Short: Write concise prompts that avoid unnecessary details 4. Surround: Provide relevant context and clarify the intended use or audience for the prompt AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Core Principles - The 4 S's Framework
modes, only the specific context and objective needs to be defined • For each new task open a new chat session to clear the context • Use the “next tab” feature of copilot to automatically include open files as context into your prompts • Tag required files or tools in your prompt, so copilot does not need to search for the needed context AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices How to improve your prompts using GitHub Copilot Settings
naming conventions • Maintain clear file organization • Include relevant imports at the top • Use descriptive filenames for better context Project-Level Context (Neighboring Tabs) • GitHub Copilot processes all open files in your IDE • Open relevant files and close irrelevant ones • Follow established patterns across your codebase • Use existing utility functions • Match the codebase style and reference shared constants AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Advanced Context Optimization Strategies
specify the Context and Objective Provide Examples: Show expected input/output Set Context: Include relevant background and use neighboring tabs Use Good Names: Descriptive variables and functions Iterate: Refine prompts based on results Stay Consistent: Follow established patterns AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Best Practices Summary
What MCP is & why context ≠ long prompts • Using built-in MCP servers with Copilot • Live demo register resource + tool in 5 minutes • Example custom server (TypeScript SDK) AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Model Context Protocol (MCP) - Agenda
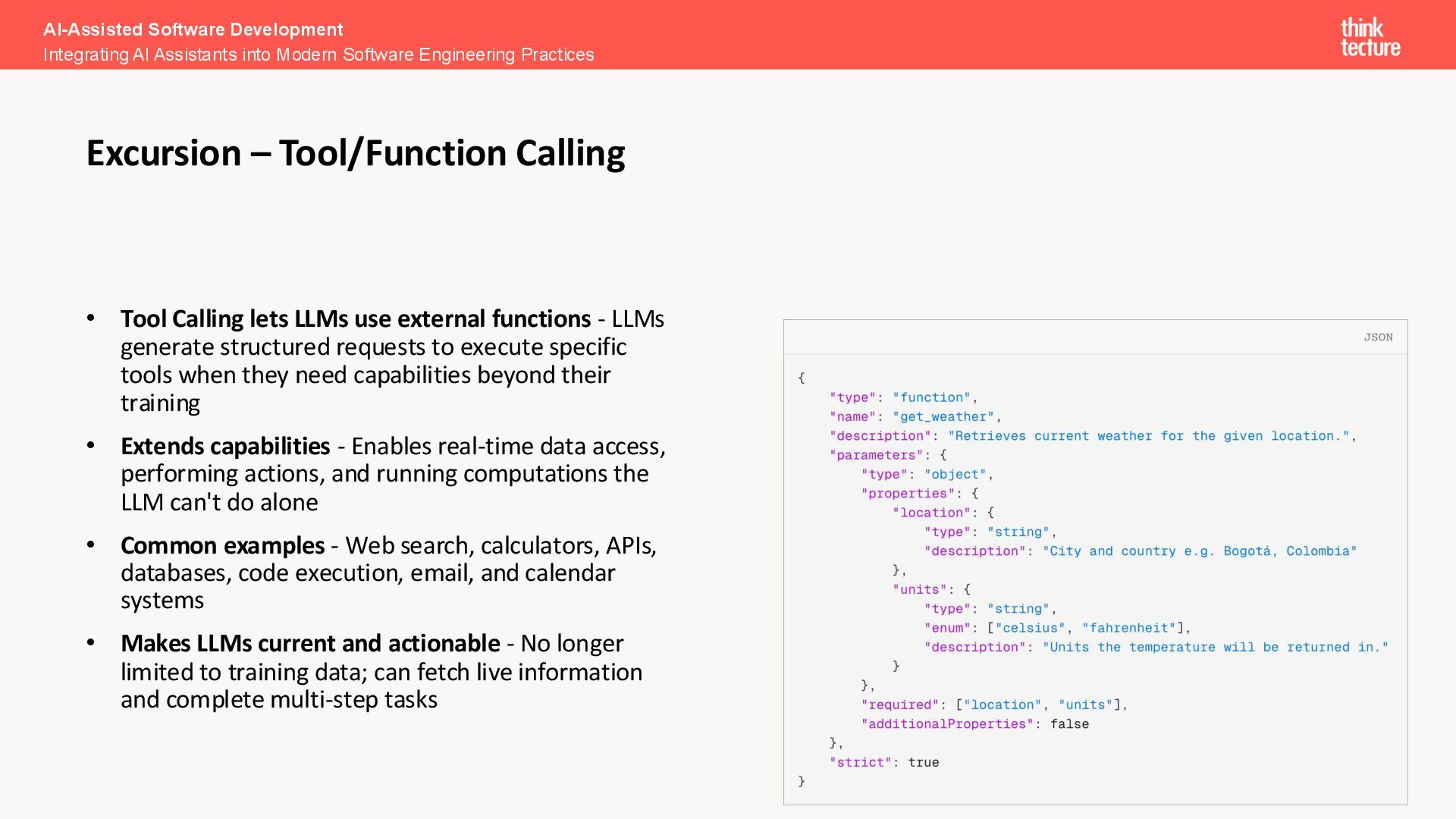
generate structured requests to execute specific tools when they need capabilities beyond their training • Extends capabilities - Enables real-time data access, performing actions, and running computations the LLM can't do alone • Common examples - Web search, calculators, APIs, databases, code execution, email, and calendar systems • Makes LLMs current and actionable - No longer limited to training data; can fetch live information and complete multi-step tasks AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Excursion – Tool/Function Calling
• Developed by Anthropic • Client-Server architecture: AI applications (clients) request context from external services (servers) • Security: secure data handling on your own infrastructure • MCP Server transport: local standard input/output (stdio), server-sent events (sse), and streamable HTTP (http) for MCP server transport AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices What is MCP?
MCP GitHub Repo: https://github.com/modelcontextprotocol/servers • Awesome MCP Server: https://github.com/punkpeye/awesome-mcp-servers • MCP Collection: https://glama.ai/mcp • Official provider websites like Atlassian, GitHub or PayPal AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices How to find MCP Servers?
PostgreSQL/MySQL MCP Server • Code Review Automation with GitHub MCP Server • Slack Integration for Development Updates • Documentation Management with File System MCP Server • Start with read-only operations to build confidence • Always review AI-generated outputs before committing • Create workflow templates for your most common tasks • Combine multiple MCP servers for powerful compound workflows AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices MCP Workflows
Add MCP Server to your project or globally • Define a tool set to for different tasks Tip: Investigate the official Agent Mode MCP overview https://code.visualstudio.com/mcp or https://glama.ai/mcp AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Self-Study: Add MCP tools to VS Code
to configure MCP servers for a workspace and share configurations with team members • User settings: specify the server in your user settings to enable the MCP server across all workspaces • Automatic discovery: enable auto discovery of MCP servers defined in other tools, such as Claude Desktop • Tool executions have to bee confirmed and can be auto confirmed if wanted AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Using MCP in GitHub Copilot
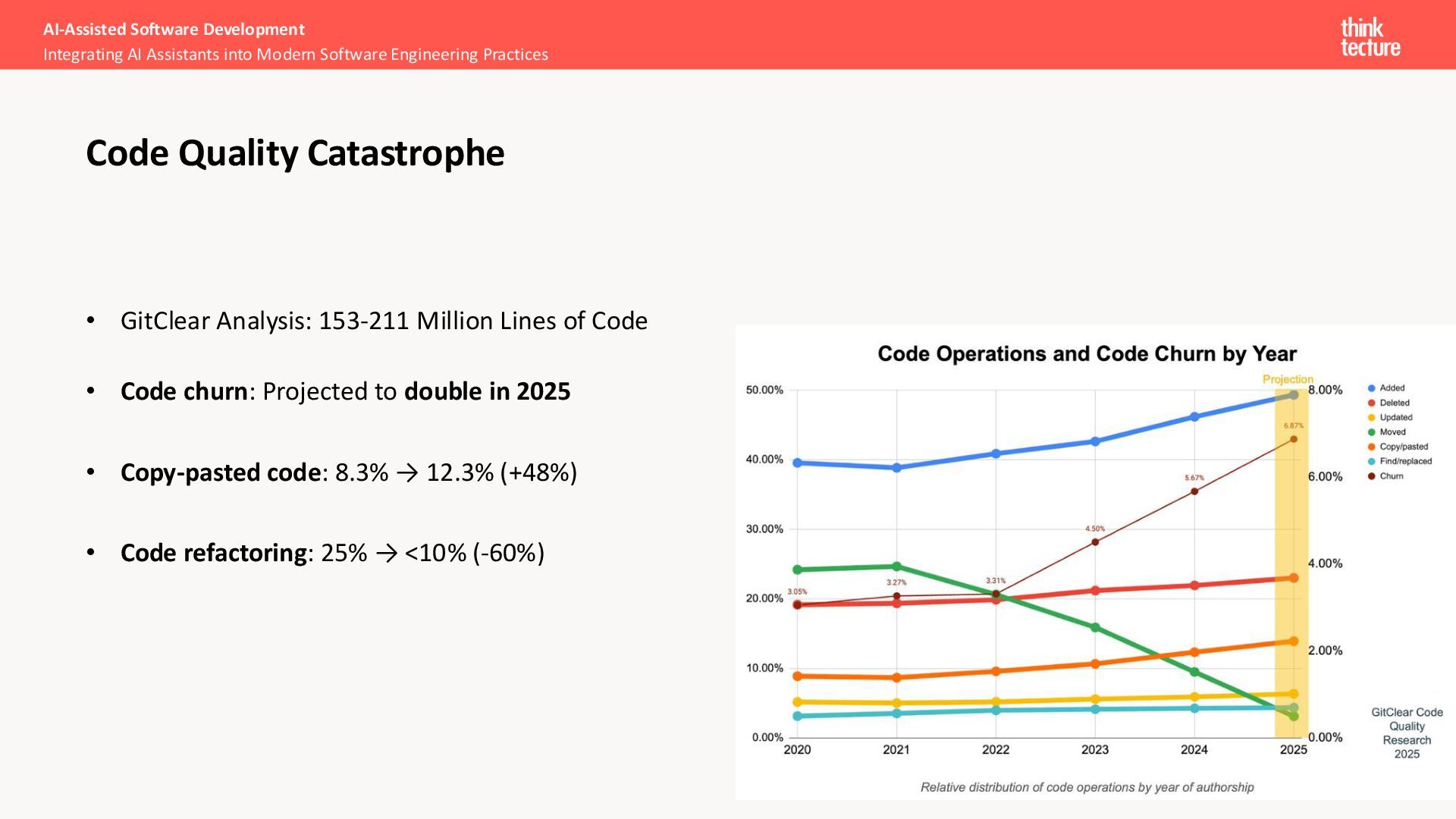
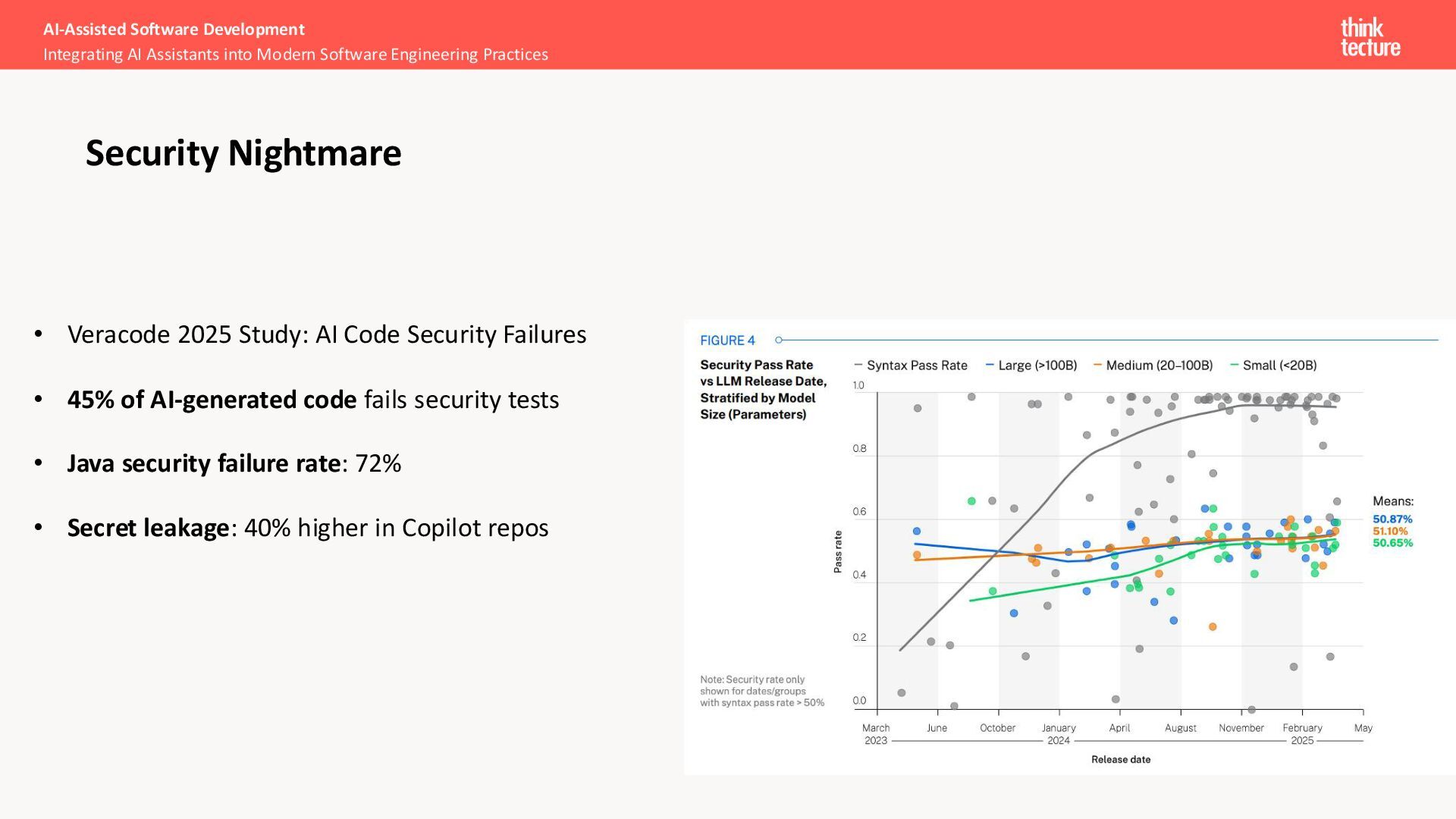
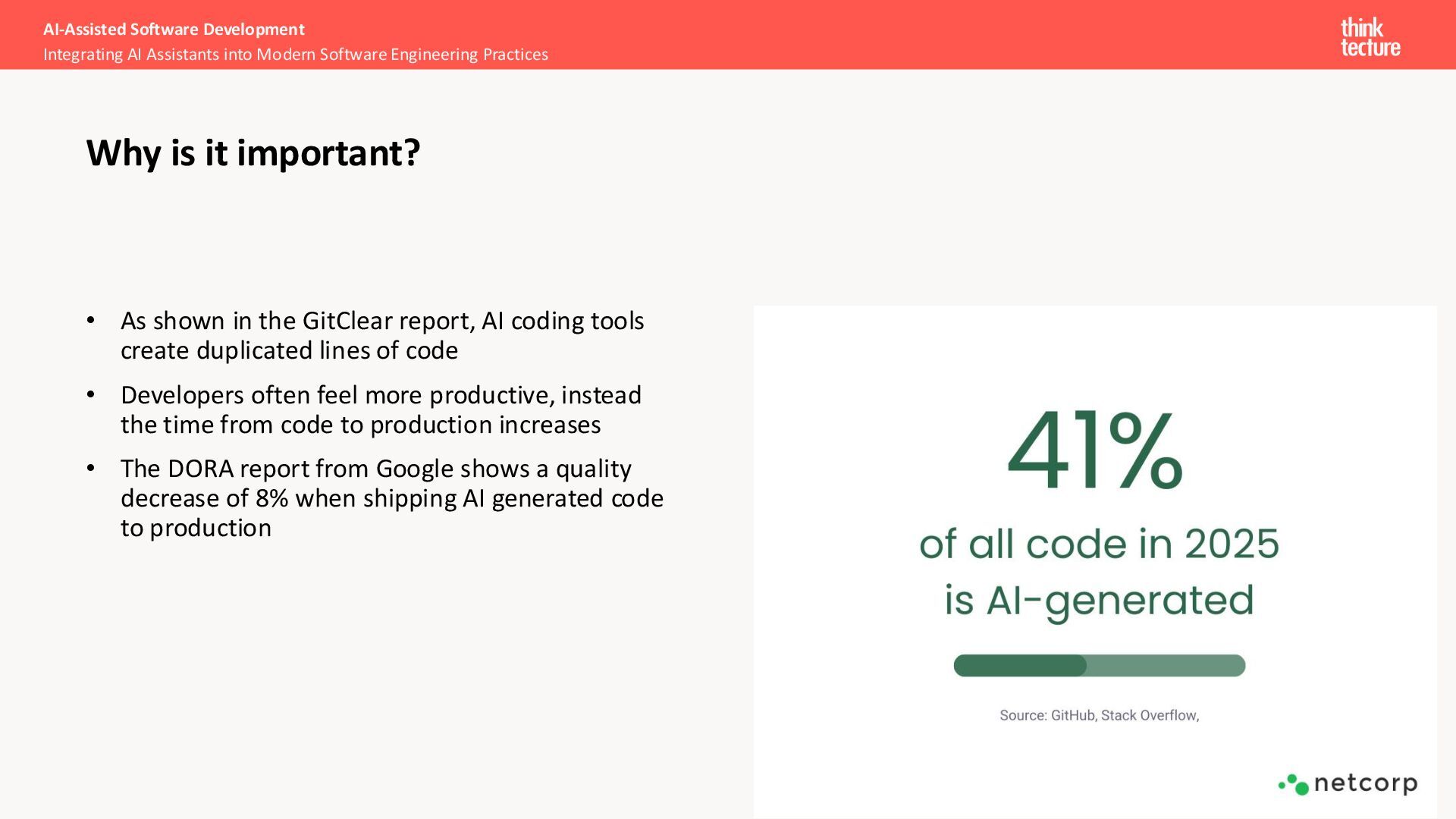
create duplicated lines of code • Developers often feel more productive, instead the time from code to production increases • The DORA report from Google shows a quality decrease of 8% when shipping AI generated code to production AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Why is it important?
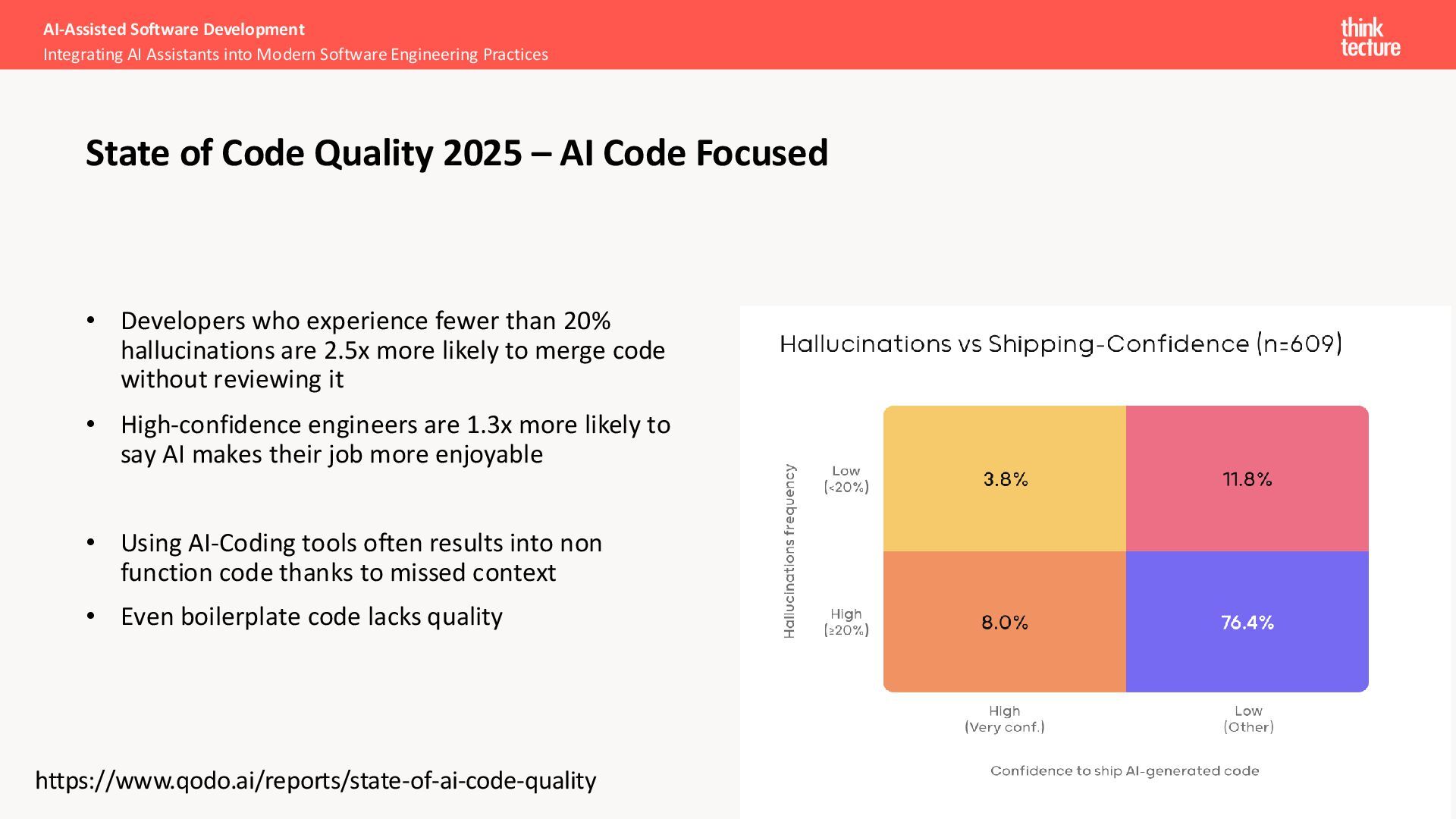
more likely to merge code without reviewing it • High-confidence engineers are 1.3x more likely to say AI makes their job more enjoyable • Using AI-Coding tools often results into non function code thanks to missed context • Even boilerplate code lacks quality AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices State of Code Quality 2025 – AI Code Focused https://www.qodo.ai/reports/state-of-ai-code-quality
the number of decision points Code Churn: measures the code added, modified, or deleted over time Code Coverage: quantifies the percentage of your codebase covered by automated tests Code Security: measures how resistant the code is to attacks and risks Code Documentation: measures the amount and quality of the documentation accompanying the code Code Duplication: measures the amount of code repeated or copied in different parts of the codebase Code Bug Issues: measures the number of bugs or defects found in the code per unit of code size AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Code Quality Metrics
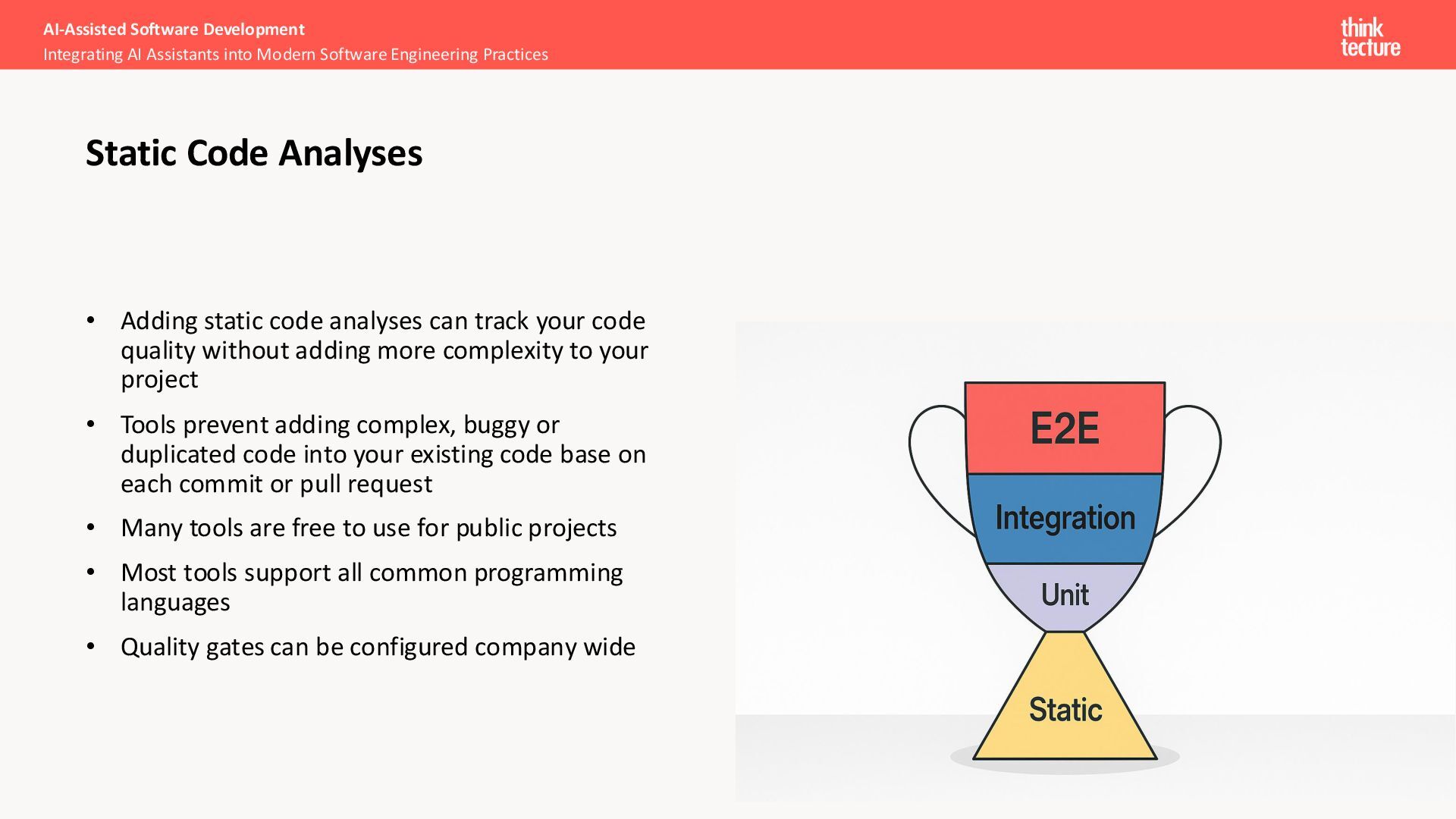
without adding more complexity to your project • Tools prevent adding complex, buggy or duplicated code into your existing code base on each commit or pull request • Many tools are free to use for public projects • Most tools support all common programming languages • Quality gates can be configured company wide AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Static Code Analyses
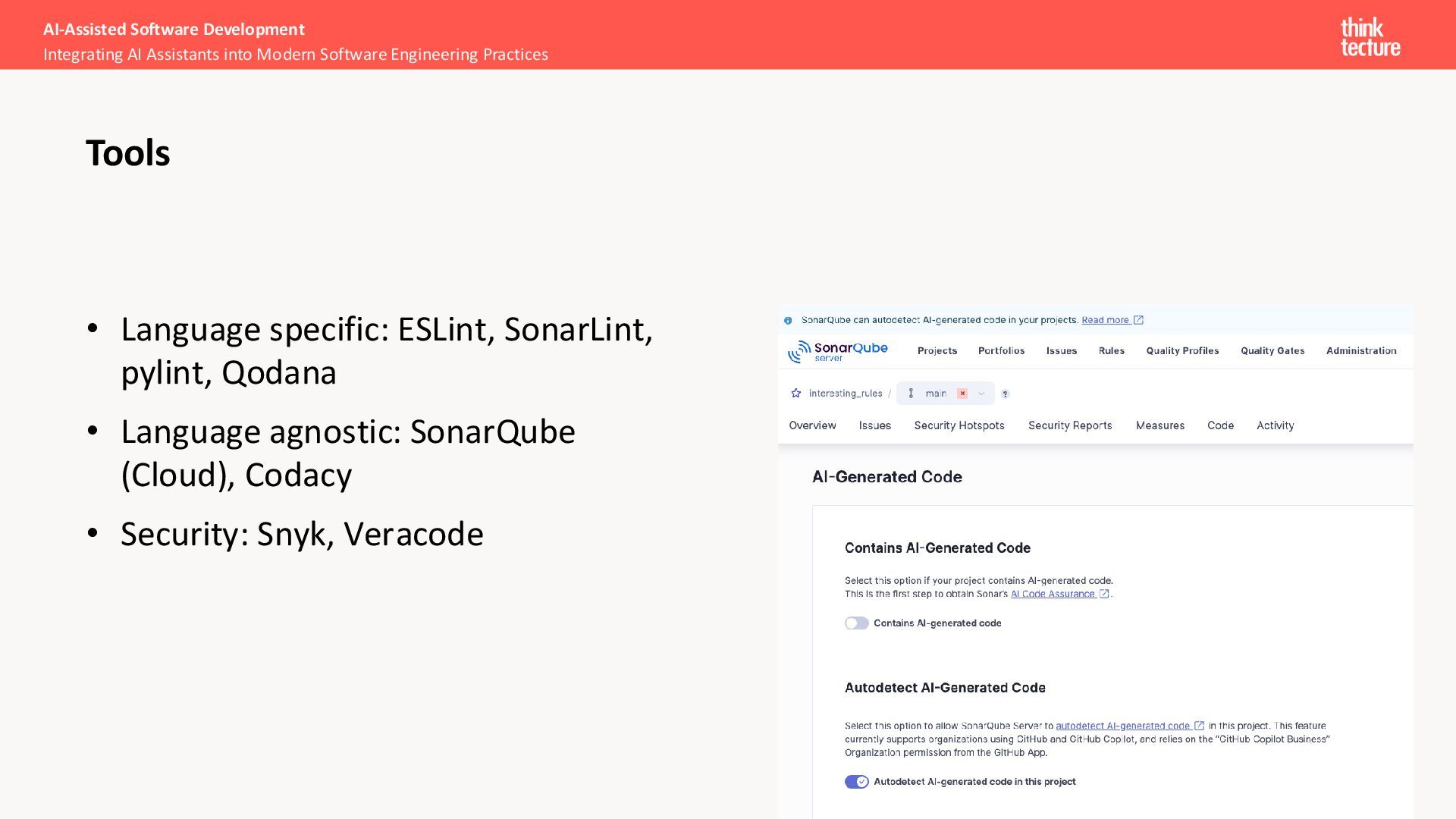
SonarQube (Cloud), Codacy • Security: Snyk, Veracode AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Tools
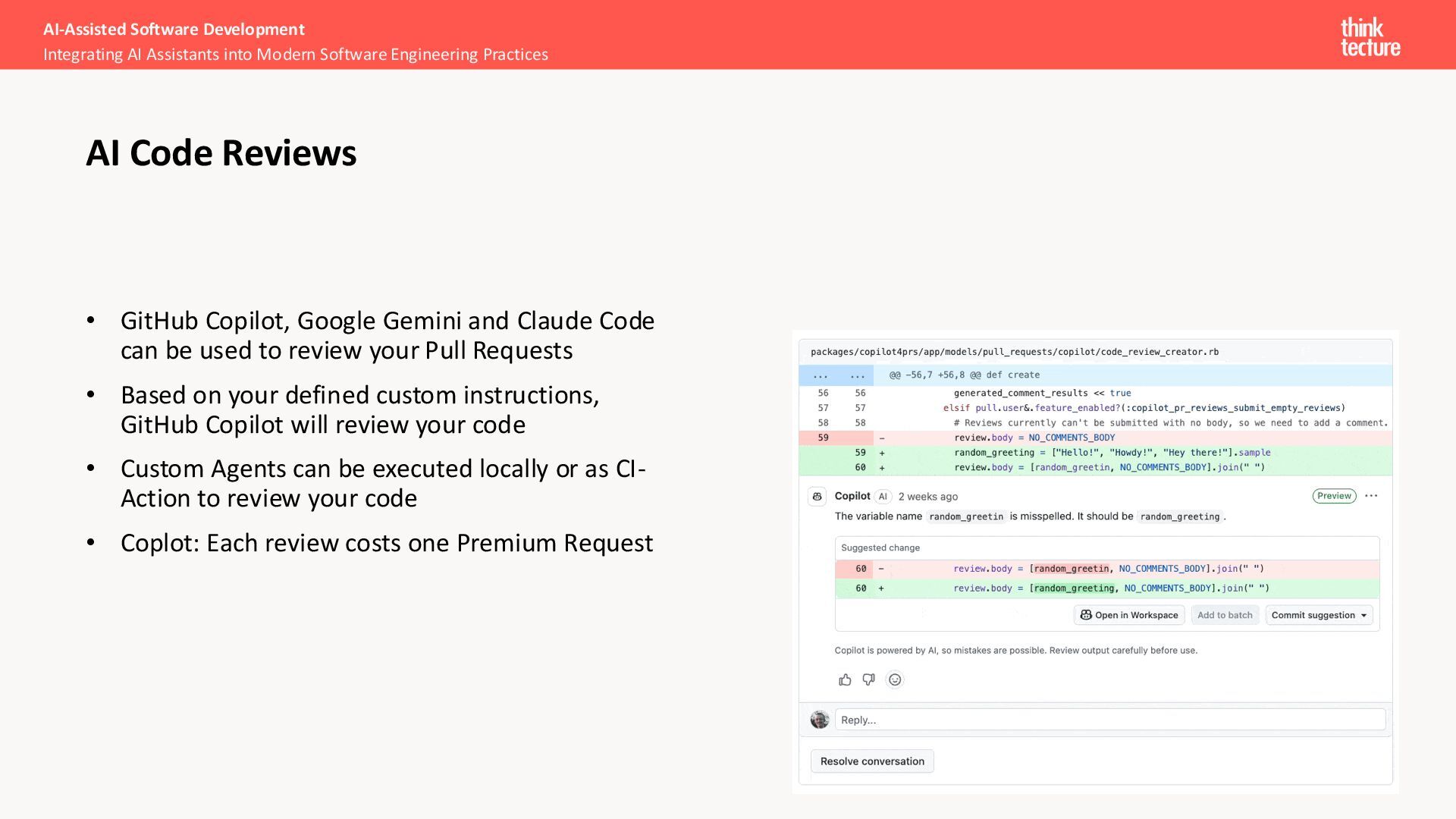
used to review your Pull Requests • Based on your defined custom instructions, GitHub Copilot will review your code • Custom Agents can be executed locally or as CI- Action to review your code • Coplot: Each review costs one Premium Request AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices AI Code Reviews
as Git & CI/CD • Boiler-plate work shrinks → focus shifts to architecture, design & product insight • New responsibilities: AI coach, safety reviewer, data-governance advocate • Human strengths remain irreplaceable: creativity - context - empathy AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices The Developer Role Is Evolving
the shift means falling behind • Build your toolkit: prompt craft - LLM APIs - MCP integrations - green AI practices • Combine AI with your domain expertise & critical thinking to deliver 10× value • Treat AI as your power-tool, not a threat: the dev + AI beats dev or AI alone AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Engage Now — AI Skills Will Define Your Future
default, measurable habit 2. Keep learning: follow model updates & best practices 3. Review & refine: human oversight ensures quality and ethics 4. Share knowledge: lift your whole team, shape responsible adoption AI-Assisted Software Development Integrating AI Assistants into Modern Software Engineering Practices Embrace Change, Stay Human, Build the Future
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Daniel Sogl @sogldaniel [email protected]](https://files.speakerdeck.com/presentations/1314cb91bcef4f80ab56270a7bc42d36/slide_107.jpg){kind=link}